1、支付宝红包码
这个给了我一个黑科技的赶脚。现在还没有搞清楚如何玩转的(#TODO#)。
先说技术实现:
1:这块应该是新业务,新系统部署;
2:需要用户自己去点击申请才能得到红包码和收钱码,所以这个系统不是默认初始化对所有支付宝用户的;
3:红包码和收钱码是有产品版本信息的(红包码和收钱码都是一个产品),二维码扫到的信息是:一个连接(支付宝)+一串字符识别码(用户信息产品信息关联生成的一个加密字符串,这个还可以理解实现)。
4:重点,推出的文字复制(遭微信屏蔽,支付宝的妙招反击,可见,竞争是科技的源动力。。。),打开支付宝,识别用户和产品信息。(两眼星星,好厉害)。
恩,就谈谈4。这里面没有特别的标识可以去截取数据字符串(初期版本是数字+英文+特殊符号,然后是繁体中文,简体中文,数字,英文)我尝试只保留这串字符,是可以识别的。所以,黑科技-1):如何截取红包码的字符串?然后这个字符串是如何确保不重复的,黑科技-2):生成红包码的规则?上面这两是凭借我匮乏的知识量,所没有想透的地方。
###系统架构:应该是使用了大数据的框架,比如hadoop,使用了NoSql技术支持,属于多中心,分布式的系统服务。然后用户发起申请后,进行的数据生成。产品大类分为红包码和收钱码,每个大类的产品又分为N个版本,每个版本的生成码值规则(二维码、文字码)可配置,全局唯一,与用户、产品、产品版本一一对应,长度也不能太长,否则影响用户体验,所以长度肯定受限。系统的快速响应就是用缓存技术了,所以对硬件的内存要求应该会很高。
###码值规则:前期方案大体是英文大小写+数字+特殊符号组成;后来由于营销策略太好,业务量迅猛增加,启动第二方案(汉语言的博大精深,总数超过八万),这下随便组合应付几十亿的客户总没问题的。
然后业务驱动:
给了用户微薄利益的诱惑,主动帮助扩大品牌影响力,占领市场份额,真是超赞!!!然后迅速消化用户流量数据,形成生态链(APP占领市场、广告植入、线下实体店整合、资金流入、其他诸如余利宝,网商贷,商城等业务等等)。我好佩服这个产品思维的的脑袋。。。给你五十二个赞!!!!!!
2、天猫淘宝的产品搜索引擎
应该是使用的搜索引擎,在具体去请求分库的数据。具体方案有待研究。(#TODO#)
本人只接触过Apache的Lucene。。。完全没有他们的设计概念
下面是阿里公众号发出来的搜索引擎系统。。。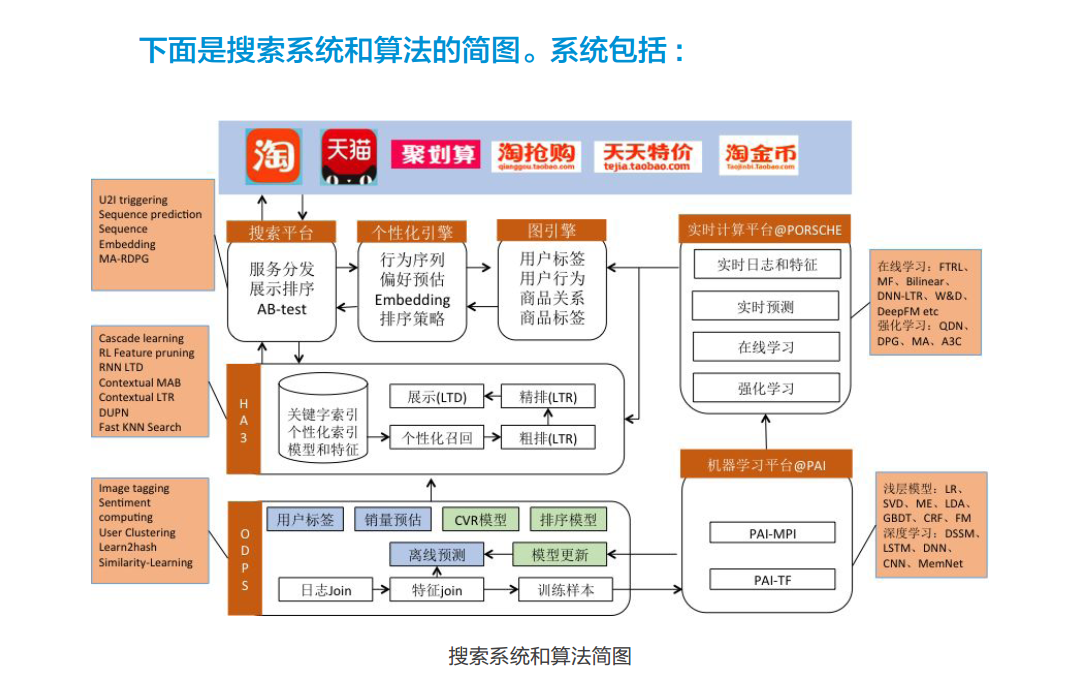
3、天猫淘宝的用户操作行为
比如:浏览商品,加购物车、订单、支付流水等,这块的业务数据量巨大。听之前某位在支付宝供过职的朋友说是支付订单是存储在数据库的JSON串报文?这个量也是很大的,报怀疑态度!!!
在没有NoSQL,比如mongodb等支持大数据高速存取,持久化的数据库之前,理论上的方案应该是将数据持久化到硬盘日志文件内。然后当需要统计某些数据,比如用户的旅游,支付地点,产品类目,总额等信息时,应该是在一个系统内进行文件读入,解析出的数据(解析出的数据要落库),这个是存在泄露风险的。
用户访问大数据统计时,可能存在一个同意授权的按钮。然后去处理拉取用户一年的数据并进行统计计算,应该不是在用户点击当时才去做的(不排除有高并发支持,毕竟有个用户查看步骤的过程时间)。
用户的访问商品,感兴趣的事物,都会被统计并反馈在商品推荐列表中,这类的行为数据应该是默认直接统计的。换言之,用户使用了这个平台,那么就已经授权了平台在不违反法律法规的情况下,对用户信息在当前平台公司的任意操作。
大数据来临之后,可以支持高并发,大数据存储查询,这些行为数据都可以迁入到大数据架构中进行玩转。
4、秒杀系统
主要的思想就是分流,前端分流,网关分流、服务端分流、入参校验分流、缓存分流、阻塞队列分流、数据库数据分离,直到最后持久化的操作进行最少的请求。

若有收获,就点个赞吧
0 人点赞
