count(* )、count(id)、count(1)
- MyISAM
将总数存在磁盘上,直接读取。(没有where 条件的) InnoDB
需要读出数据累加show table status 中的TABLE_ROWS 使用的是 采样估算出的数量。
优化器针对count(* )有特殊优化。
count(字段):判断null【null值不算】,读字段,累加
- count(主键):读主键,累加
- count(1):数1
- count( ):*不取值,按行累加(返回索引树中数据的个数)
FIND_IN_SET:判断字段包含
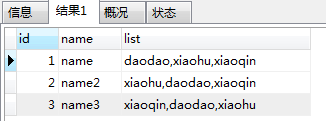 SELECT id,name,list from tb_test WHERE FIND_IN_SET(‘daodao’,list);
SELECT id,name,list from tb_test WHERE FIND_IN_SET(‘daodao’,list);
使用MYSQL查询数据表中某个字段包含某个数值_三生石的博客-CSDN博客_mysql查询包含某一字符串的值
【坑】not in 处理null的坑,并且not in不走索引
MySQL NOT IN的坑——注意null - 简书
原因是not in的实现原理是,对每一个table1.name和每一个table2.name(括号内的查询结果)进行不相等比较(!=)【所以不走索引】。
foreach name in table2:if table1.name != name:continueelse:return falsereturn true
而sql中任意!=null的运算结果都是false(!=null返回null),所以如果table2中存在一个null,not in的查询永远都会返回false,即查询结果为空。
正确做法:要将null在子查询中过滤掉。
is not null 和 !=null区别

解决is not null不走索引 & !=不走索引
x is not null
变为 x>0
UNION ALL操作符替代UNION
union all 没有去重语义,不需要临时表。UNION需要临时表。
随机取n个


大分页优化
子查询优化(索引覆盖)
SELECT id, value, LENGTH(stuffing) AS lenFROM t_limitORDER BYidLIMIT 150000, 10
优化后
SELECT l.id, value, LENGTH(stuffing) AS lenFROM (SELECT idFROM t_limitORDER BYidLIMIT 150000, 10) oJOIN t_limit lON l.id = o.idORDER BYl.id
因为Mysql总是early row lookup【遍历id每一步都读取整行的内容】,
因为使用的select * ?
不知道mysql为什么不做优化?哪里不好优化么?有人有相同的质疑:
[MySQL] Why does the limit use the early row lookup.
大分页方法二
一种方式当数据插入的时候就分配页码,到时候直接根据页码字段取数据。【百度贴吧】
每个商品各个供应商中的最高价(nice)
SELECT s1.article, s1.dealer, s1.priceFROM shop s1LEFT JOIN shop s2 ON s1.article = s2.article AND s1.price < s2.priceWHERE s2.article IS NULL ORDER BY s1.article;
MySQL :: MySQL 8.0 Reference Manual :: 3.6.4 The Rows Holding the Group-wise Maximum of a Certain Column
窗口函数[mysql 8]【分组排名】
rank(),dense_rank(),row_number()
分区函数Partition By的用法_程序员之道-CSDN博客

max min优化
- 针对全部数据max 和 min 有缓存结果,可直接获取。
- 针对条件查询max min,代替max函数,可以在索引字段使用 order by limit 1 方式返回最大最小值。
MySQL之查询:max()和min()函数与索引利用_u012393450的博客-CSDN博客
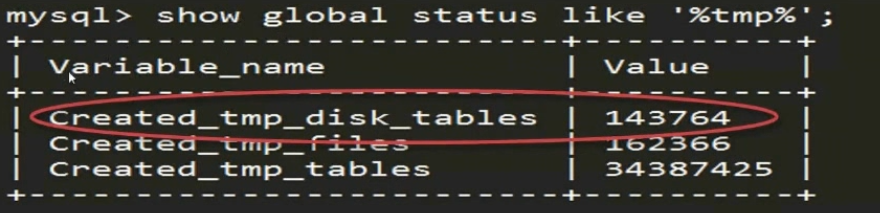
磁盘io高问题
原因


select需要加事务么?
mysql 查询需不需要加事务? - 知乎
多个select 放在一个事务里,会变成大事务。影响效率。
但是
只读事务 @Transactional(readOnly = true) 貌似有又优化?
例如Oracle对于只读事务,不启动回滚段,不记录回滚log。
统计每一行记录的平均大小
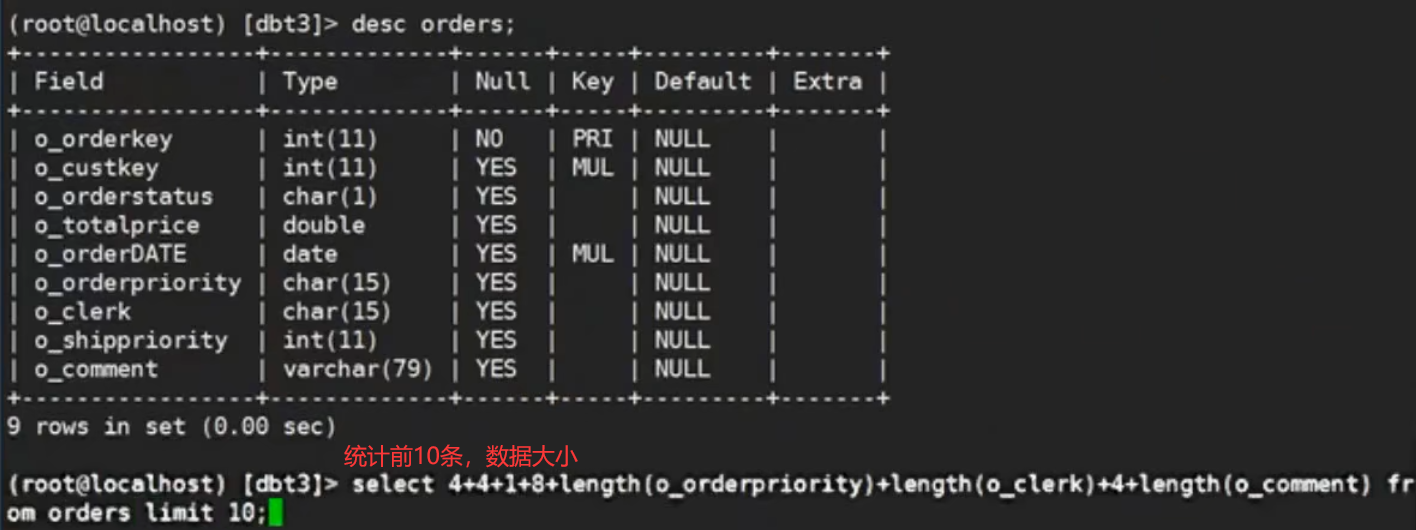

length()方法只能计算字符串类型。
求行号
方法一: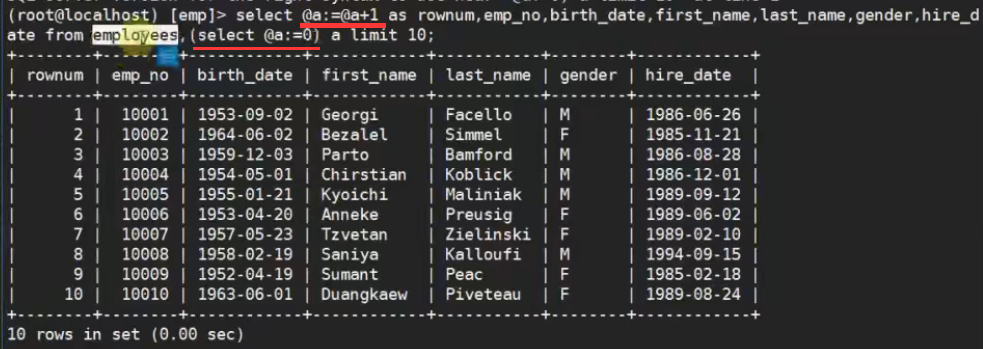
方法二:

若有收获,就点个赞吧
0 人点赞
