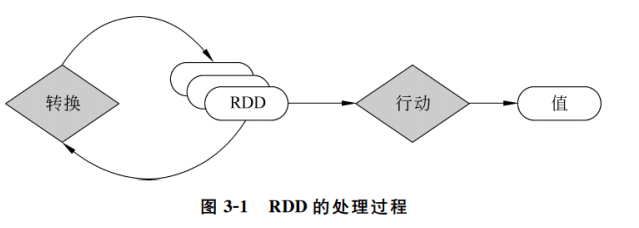
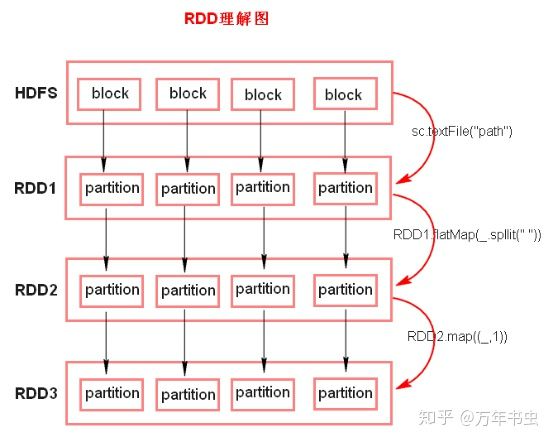
算子
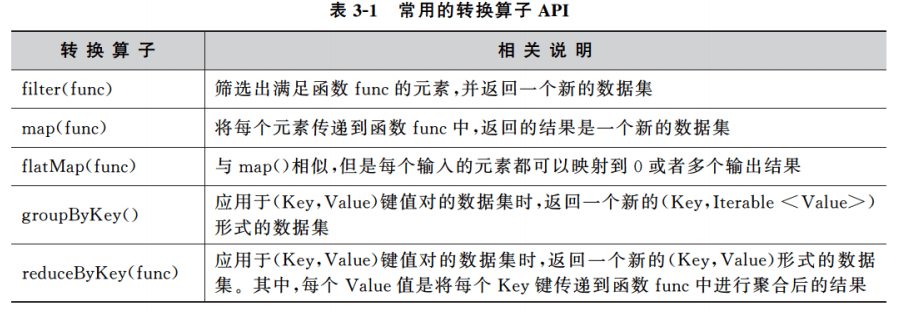
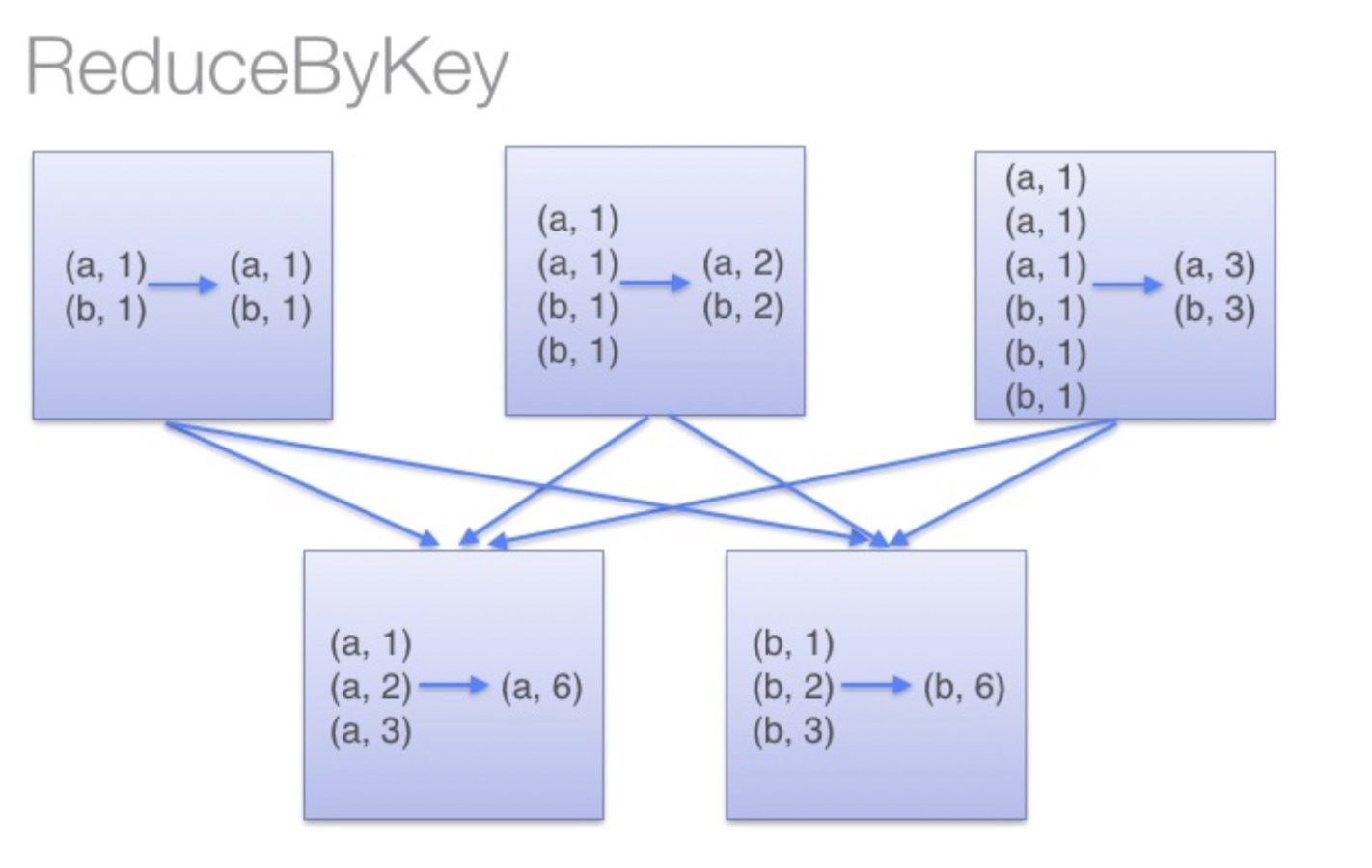
转换算子
action算子
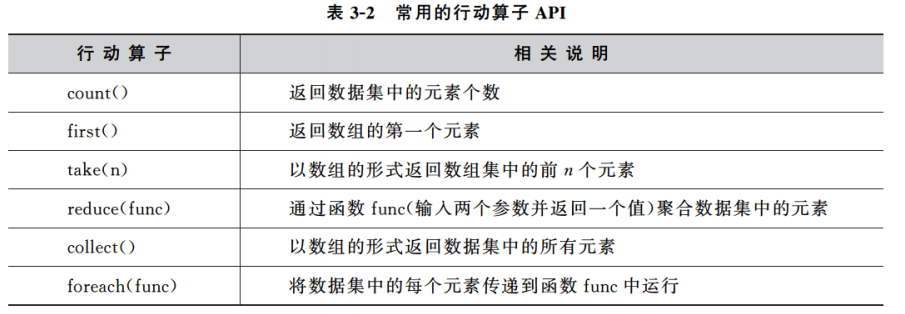
依赖关系(宽窄依赖)
- 窄依赖:
- 指父RDD的每一个分区最多被一个子RDD的分区所用,表现为一个父RDD的分区对应于一个子RDD的分区,和两个父RDD的分区对应于一个子RDD 的分区。图中,map/filter和union属于第一类,对输入进行协同划分(co-partitioned)的join属于第二类。
- 宽依赖:
- 指子RDD的分区依赖于父RDD的所有分区,这是因为shuffle类操作,如图中的groupByKey和未经协同划分的join。

控制算子
RDD持久化:cache & persist
- cache() = persist() = persist(MEMORY)
- 性能提升

容错机制:checkpoint
- 用来容错
- cache免去checkpoint重新计算

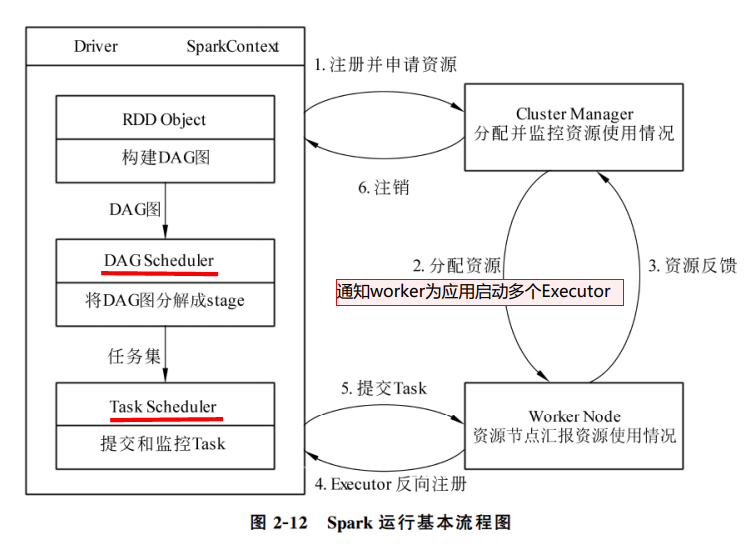
Standalone 提交任务方式
spark02—Standalone模式两种提交任务方式 - 一个点一个点的个人空间 - OSCHINA - 中文开源技术交流社区
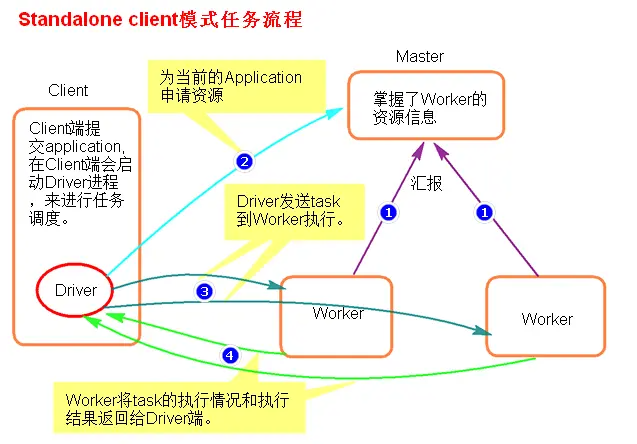
Standalone-client提交任务方式
./spark-submit
—master spark://node1:7077
—class org.apache.spark.examples.SparkPi
../examples/jars/spark-examples_2.11-2.2.1.jar
1000
或者
./spark-submit
—master spark://node1:7077
—deploy-mode client
—class org.apache.spark.examples.SparkPi
../examples/jars/spark-examples_2.11-2.2.1.jar
100
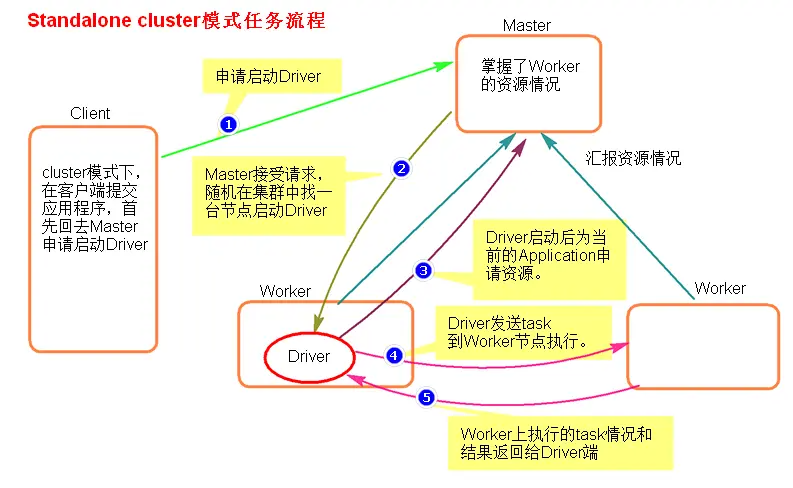
Standalone-cluster提交任务方式
./spark-submit
—master spark://node1:7077
—deploy-mode cluster
—class org.apache.spark.examples.SparkPi
../examples/jars/spark-examples_2.11-2.2.1.jar
100
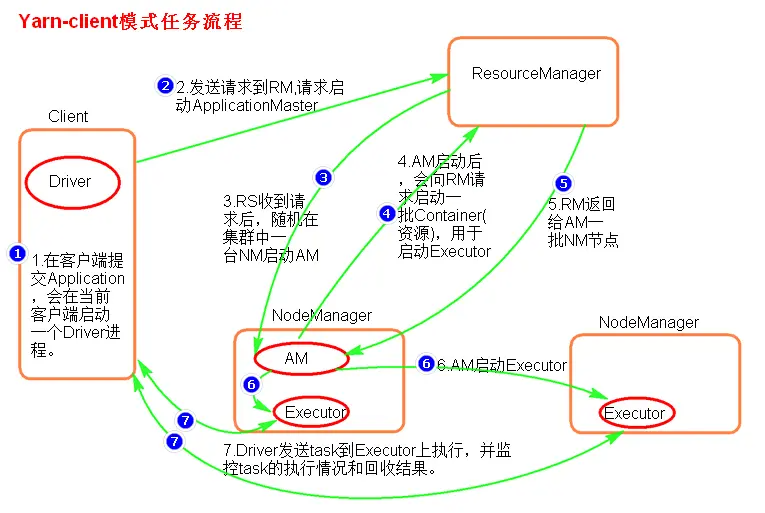
Yarn模式两种提交任务方式
yarn client
./spark-submit —master yarn —class xxx.jar 或者 ./spark-submit —master yarn–client —class xxx.jar 或者 ./spark-submit —master yarn —deploy-mode client —class xxx.jar
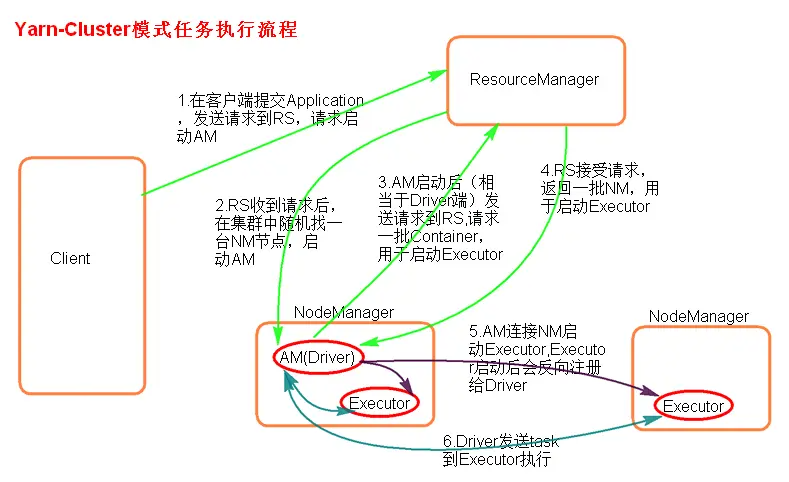
yarn cluster
./spark-submit —master yarn-cluster —class xxx.jar 或者 ./spark-submit —master yarn —deploy-mode cluster —class xxx.jar
Job-Stage-Task之间的关系
理解Spark中Job-Stage-Task之间的关系 - 简书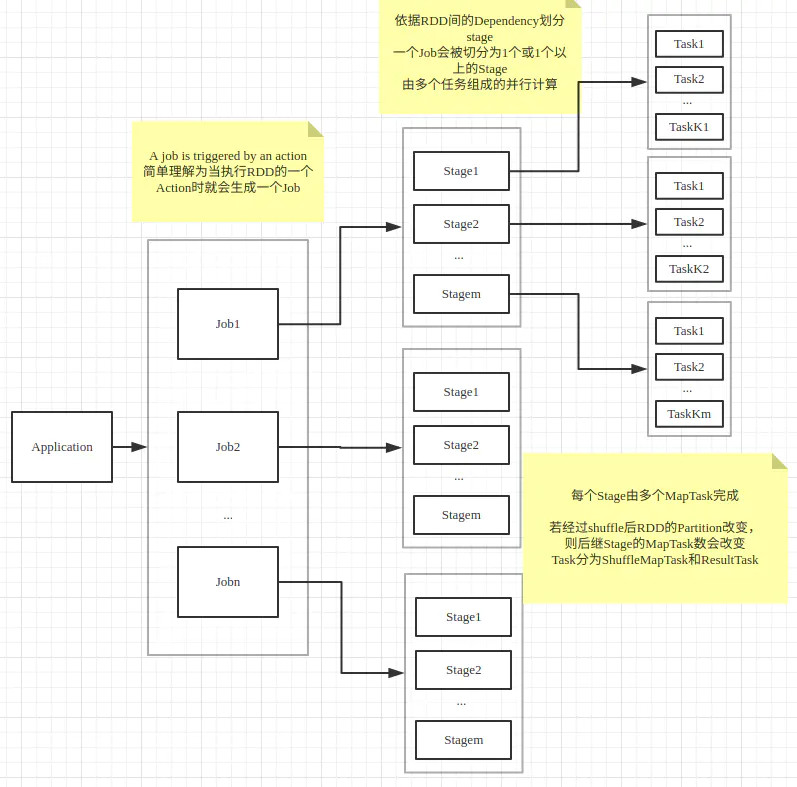
- 一个action rdd对应一个job
- job根据wide dependency划分位不同stage
- 每个stage可能存在多个task,不同task处理不同数据。
- 一般一个partition对应一个task
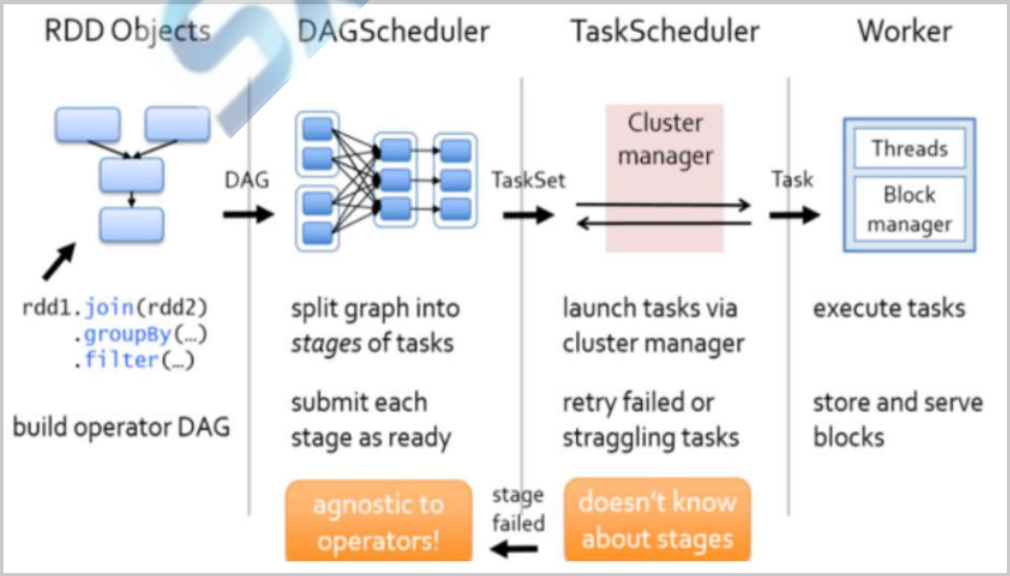
Spark资源调度和任务调度
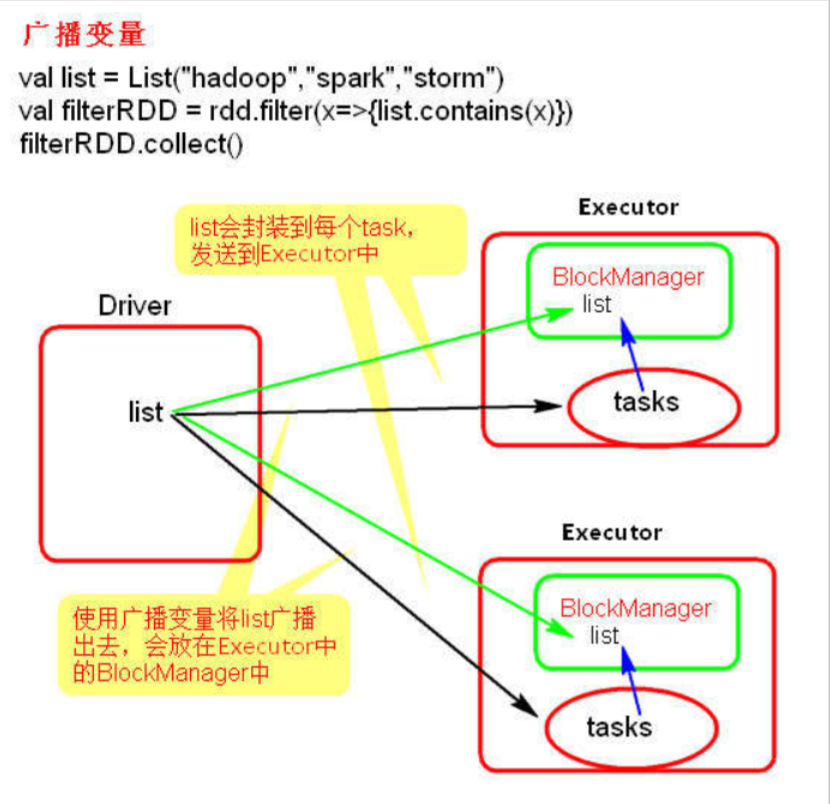
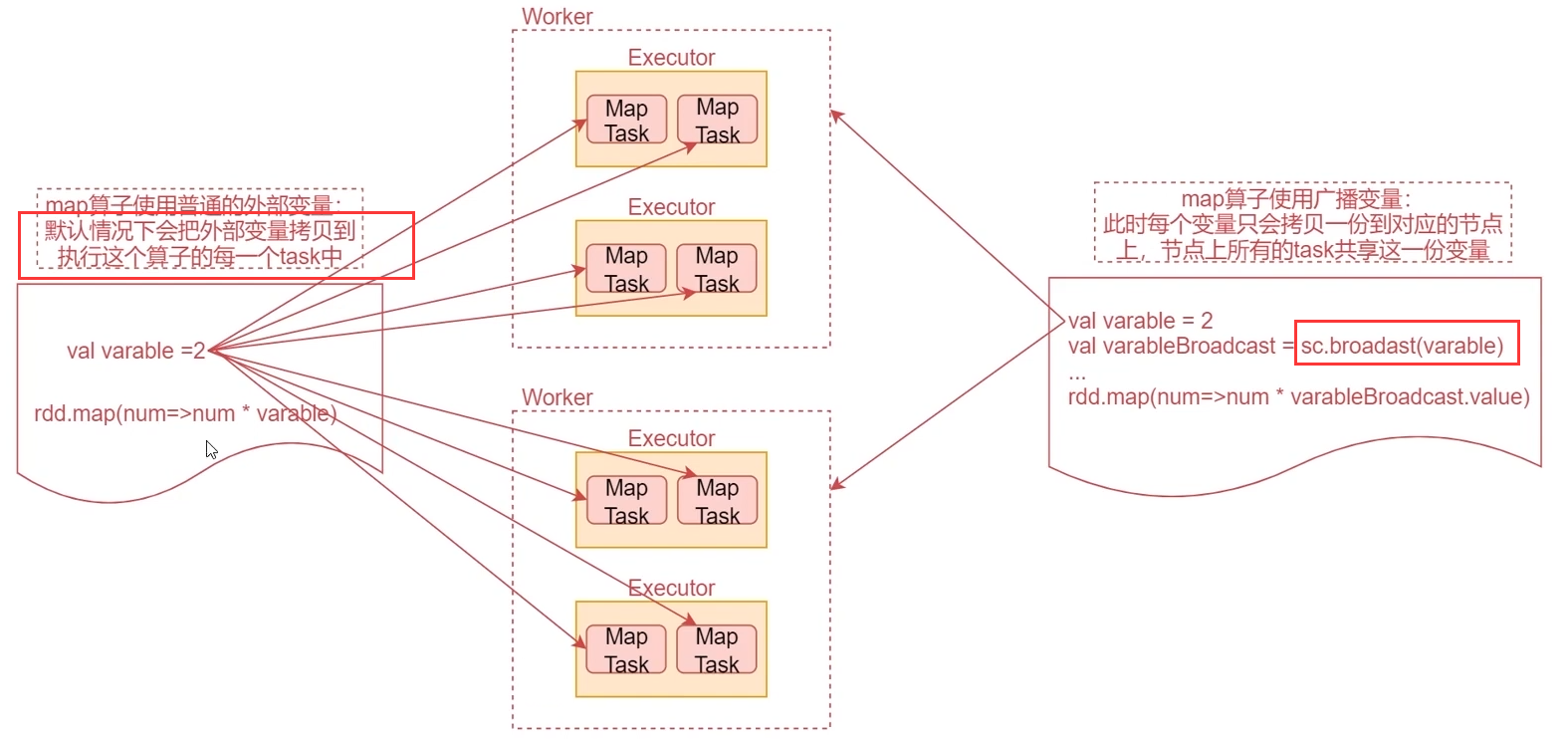
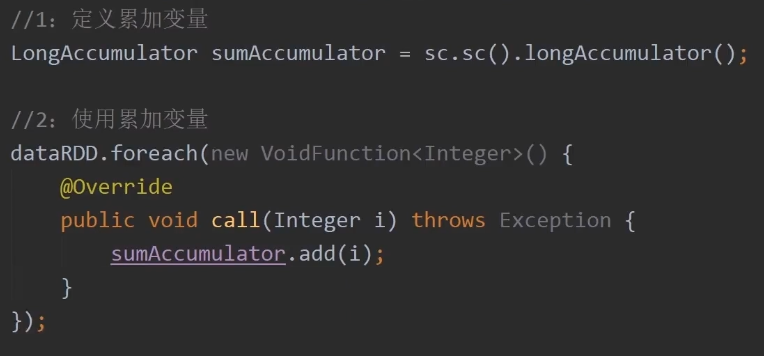
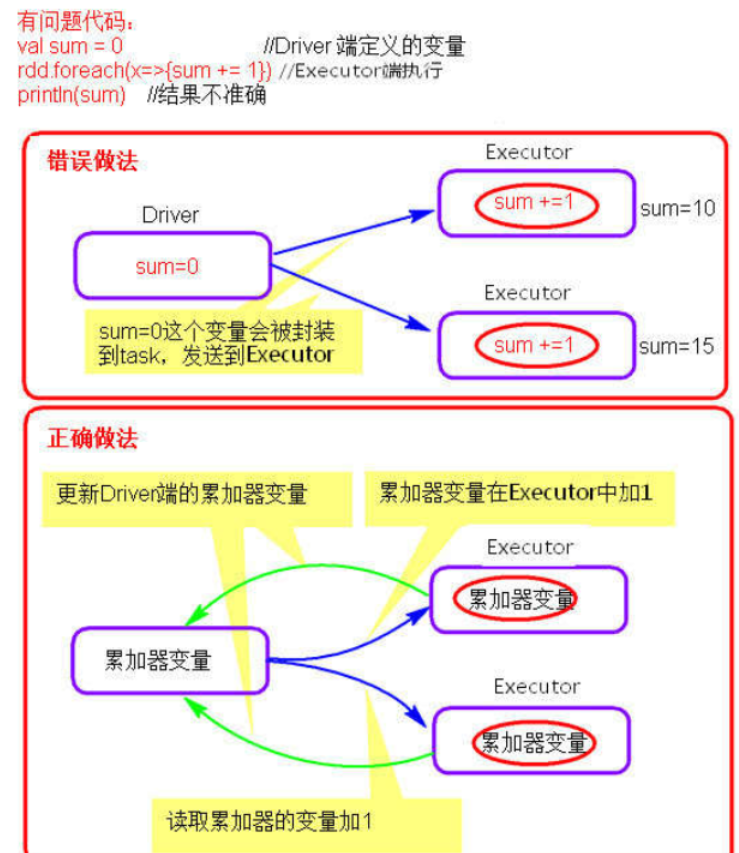
shuffle
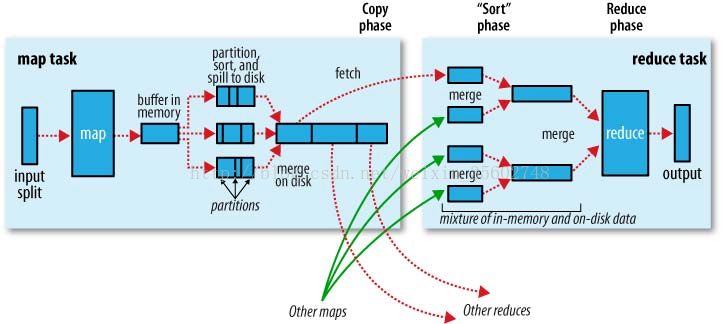
Spark中的Spark Shuffle详解 - 大葱拌豆腐 - 博客园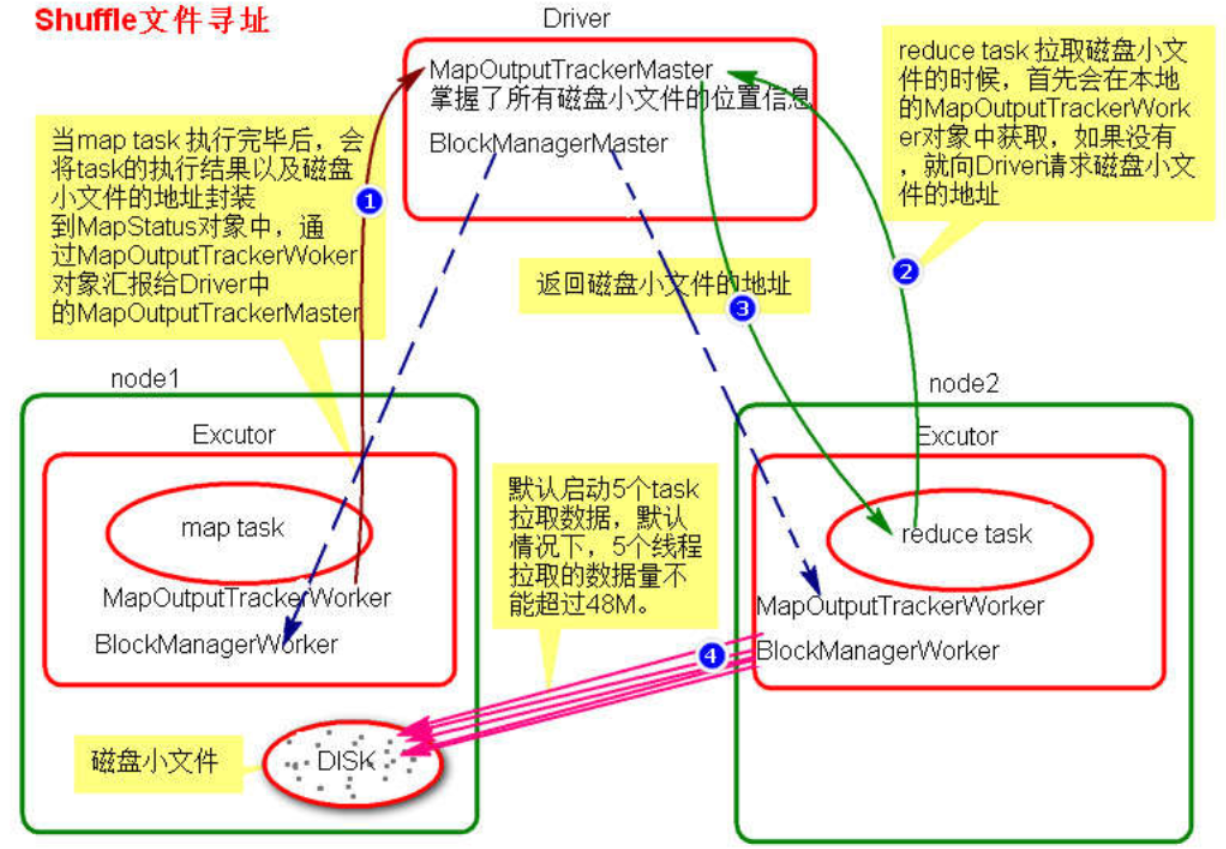
spark内存管理
- 默认使用统一内存管理
- spark.memory.useLegacyMode设置为true使用静态内存管理。
- 静态内存管理
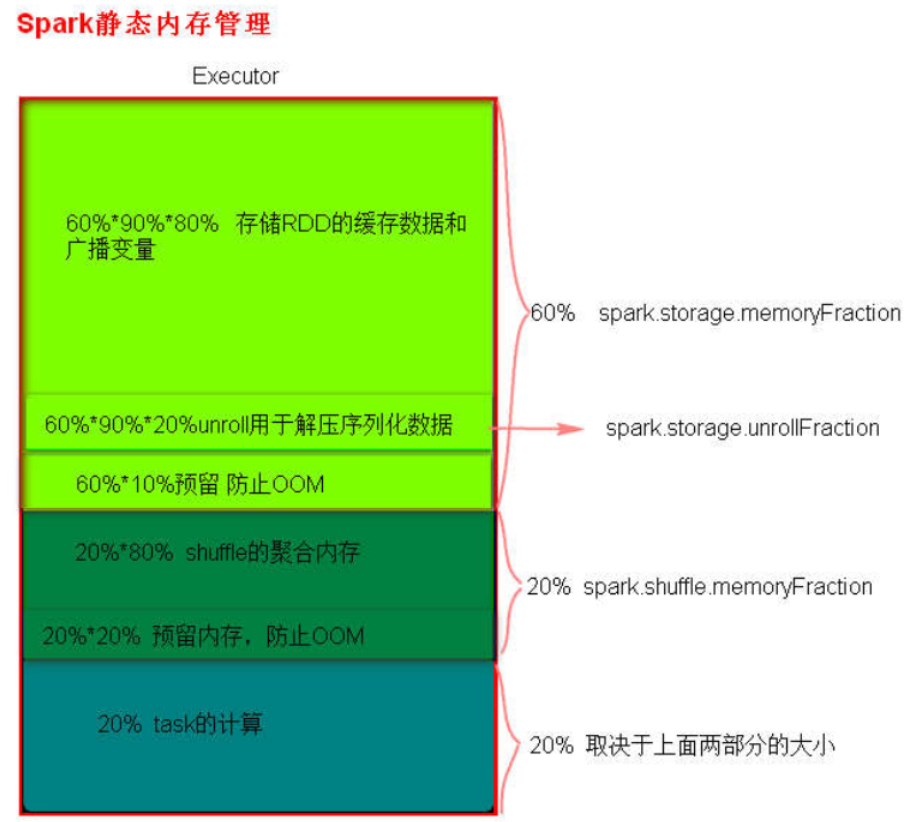
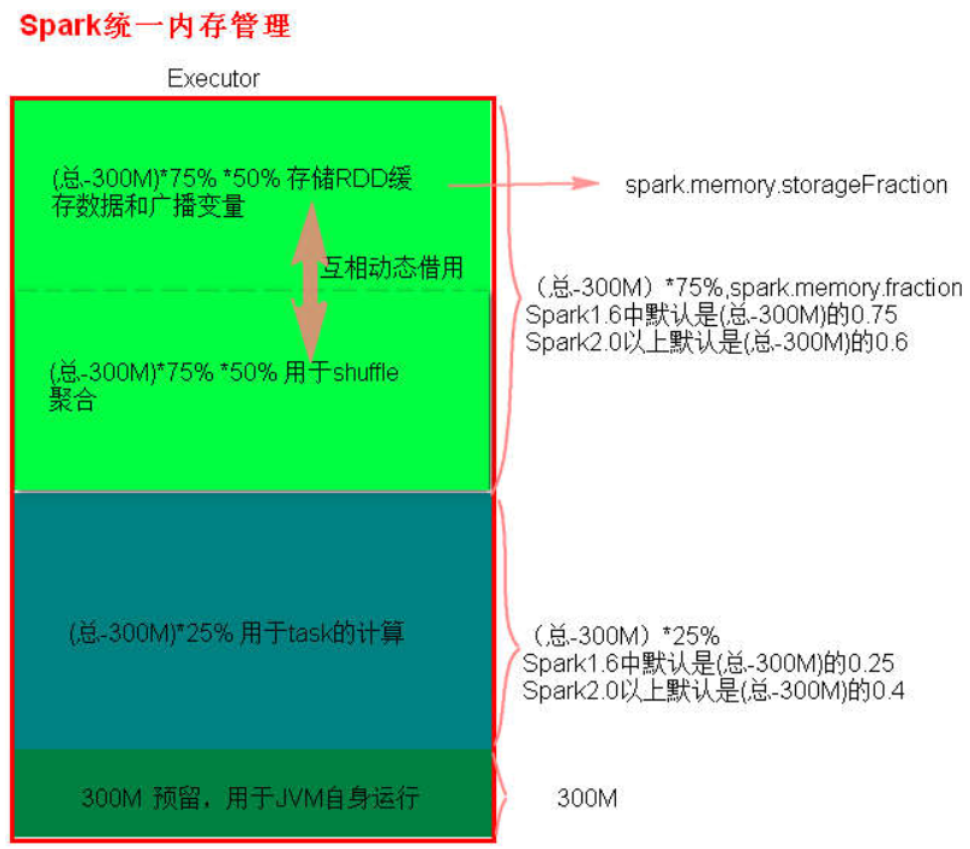
- 统一内存管理

若有收获,就点个赞吧
0 人点赞
