String组成
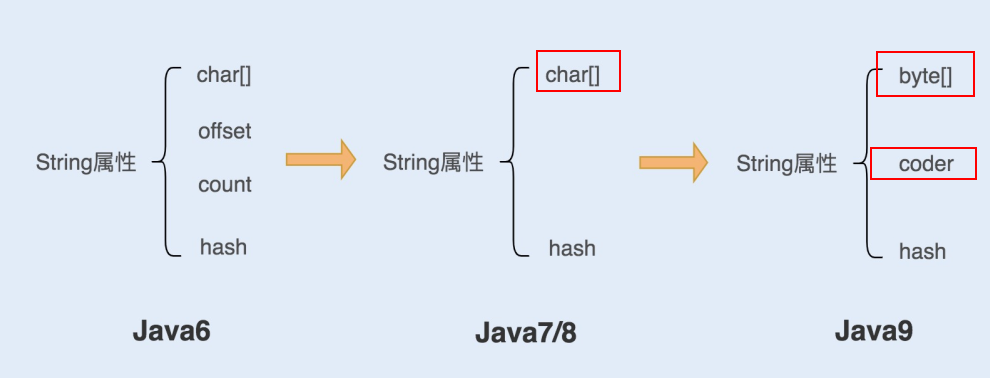
- final数组:防止被修改
- hash:缓存字符串hash码
- offset
- coder
offset
jdk6 String这个offset是干嘛的?
This is the first char to use from the array.It has been introducted because some operations like substring create a new String using the original char array using a different offset. What does offset in java.lang.String holds? - Stack Overflow
// Package private constructor which shares value array for speed.String(int offset, int count, char value[]) {this.value = value;this.offset = offset;this.count = count;}public String substring(int beginIndex, int endIndex) {if (beginIndex < 0) {throw new StringIndexOutOfBoundsException(beginIndex);}if (endIndex > count) {throw new StringIndexOutOfBoundsException(endIndex);}if (beginIndex > endIndex) {throw new StringIndexOutOfBoundsException(endIndex - beginIndex);}return ((beginIndex == 0) && (endIndex == count)) ? this:new String(offset + beginIndex, endIndex - beginIndex, value);}
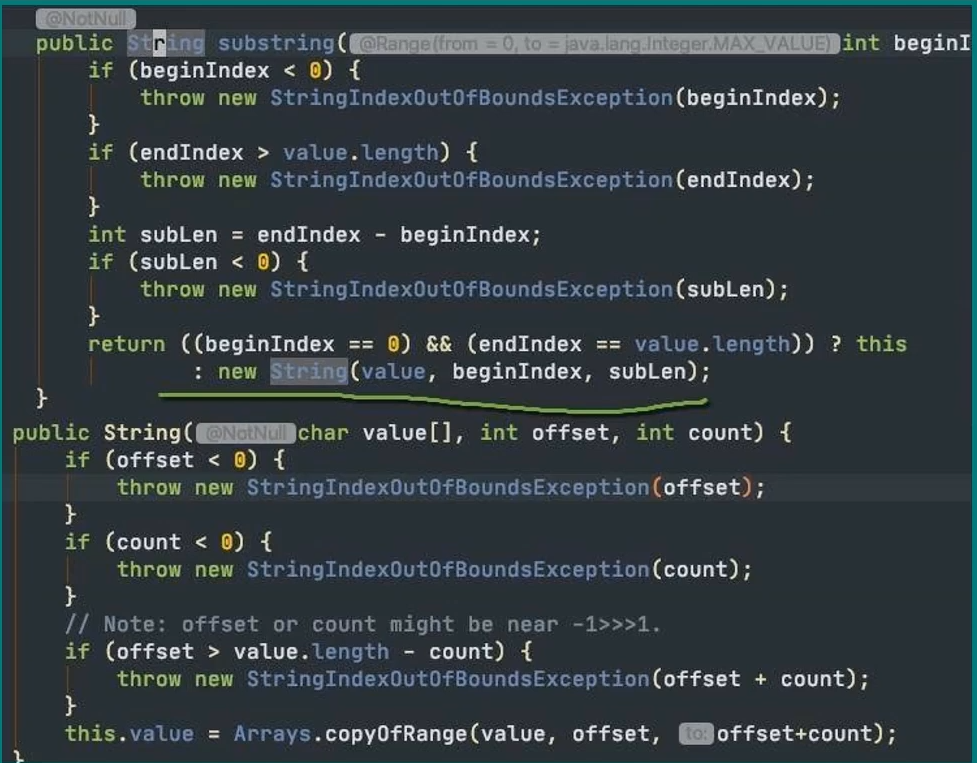
- jdk6 substring与原String 是共享 Char[] 的。
offset 和count 标记了这个substring 在原来Char[]中的位置。
看似节约空间,但是会有内存泄露问题。
- java7 不再共享char[],使用Arrays.copyOfRange()
java9 char[] 变为byte[],同时增加一个coder编码格式。
coder【utf16】
coder = 0 ,latin-1字符。
coder = 1,代表utf16编码
【为什么不用utf8呢?参见:Java 为什么使用 UTF-16 而不是更节省内存的 UTF-8? - 知乎】构造方法
构造string使用Arrays.copyOf,防止将引用传递进来

substring()
String编码-如何正确的逐字符遍历字符串
通常遍历一个字符串
public static void main(String[] args) {//𤭢,复制到idea后自动就变为utf16编码了String a = "\uD852\uDF62";System.out.println("String:" + a);System.out.println("String length:" + a.length());char[] chars1 = a.toCharArray();for (int i = 0; i < chars1.length; i++) {System.out.println(chars1[i]);}}
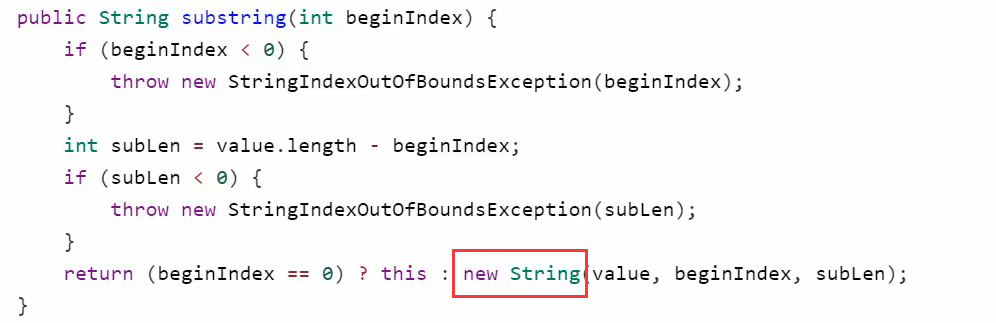
输出:String:𤭢String length:2??
为什么 String lenght是2呢?
因为java String中存储是通过Char[] 来存储(Java 9 是通过Byte[])。存储的编码是utf16。(为什么是utf16)
附上unicode到utf16的转换关系:
属于“基本平面字符”的unicode和utf16二进制是一样的占用16位(一个char可以表示)。
但𤭢字属于“增补平面字符”,转为utf16需要32位(两个char)。
如何才能正确按字符遍历字符串呢?
public static void main(String[] args) {String a = "\uD852\uDF62";System.out.println("String:" + a);System.out.println("String length:" + a.length());for (int offset = 0; offset < a.length();) {//从offset开始获取字符,返回字符对应的unicodeint ch_unicode = a.codePointAt(offset);//查看字符unicode对应的二进制System.out.println("ch_unicode:" + Integer.toBinaryString(ch_unicode));//根据unicode编码 转为char[]存储(utf16格式)。char[] chars_utf16 = Character.toChars(ch_unicode);//遍历输出string中的char[]对应的二进制for (int i = 0; i < chars_utf16.length; i++) {System.out.println("utf16_char " + i + ":" + Integer.toBinaryString(chars_utf16[i]));}//将chars转为StringString s = String.valueOf(chars_utf16);System.out.println("完整字符:" + s);//增加offsetoffset += Character.charCount(ch_unicode);}}
- String.codePointAt():The codePointAt() method returns a non-negative integer that is the Unicode code point value.
- Character.toChars():根据unicode转为utf16
- String.valueOf(chars_utf16);:根据utf16数组转为String
输出:String:𤭢String length:2ch_unicode:10 0100 1011 0110 0010 -> 对应 𤭢 的unicode值U+24B62utf16_char 0:1101 1000 0101 0010 -> 对应 String a = "\uD852\uDF62"; 中的D852utf16_char 1:1101 1111 0110 0010 -> 对应DF62完整字符:𤭢
- java乱码 java使用的编码是utf-8还是utf-16还是unicode_u014631304的博客-CSDN博客_java utf-16
- Java 为什么使用 UTF-16 而不是更节省内存的 UTF-8? - 知乎
- 一次性搞清楚unicode、codepoint、代码点、UTF_qlql489的专栏-CSDN博客_codepoint
- 刨根究底字符编码之十四——UTF-16究竟是怎么编码的 - 知乎
String.intern()
JVM内存结构因为有字符串常量池,所以String类是final的?
equals() compareTo() 区别
java.lang.Comparable#compareTo
- 可返回正数、0、负数
java.lang.Object#equals
- 返回bool
String的HashCode()


若有收获,就点个赞吧
0 人点赞
