memery usage查看数据占用大小
Redis数据结构
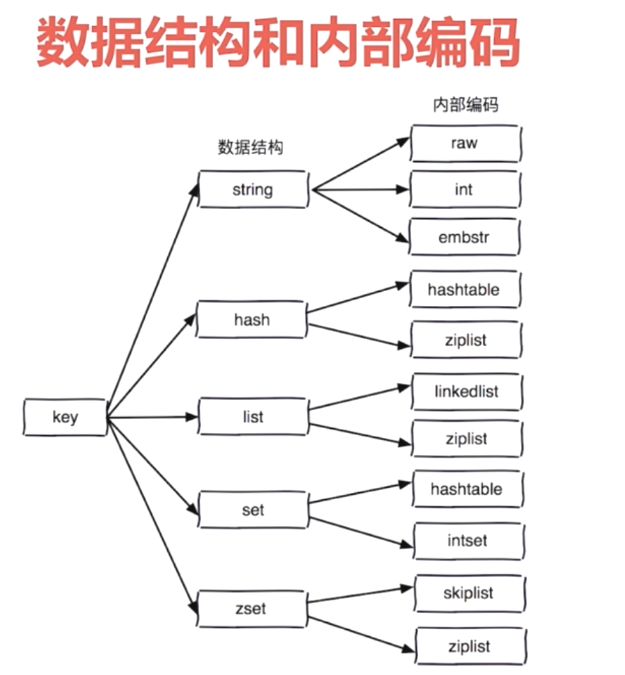
String

int:存储 8 个字节的长整型(long,2^63-1)- raw:大于44字节
- embstr:小于44个字节【在3.2版本之后,则变成了44字节为分界。】

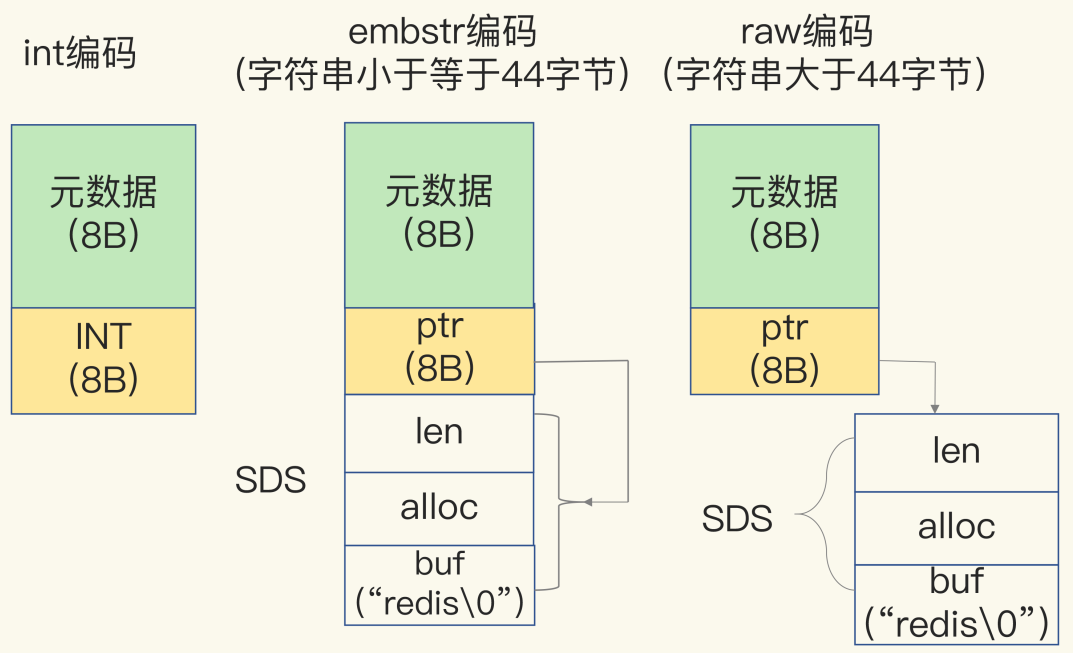
- 元数据是RedisObject对象头
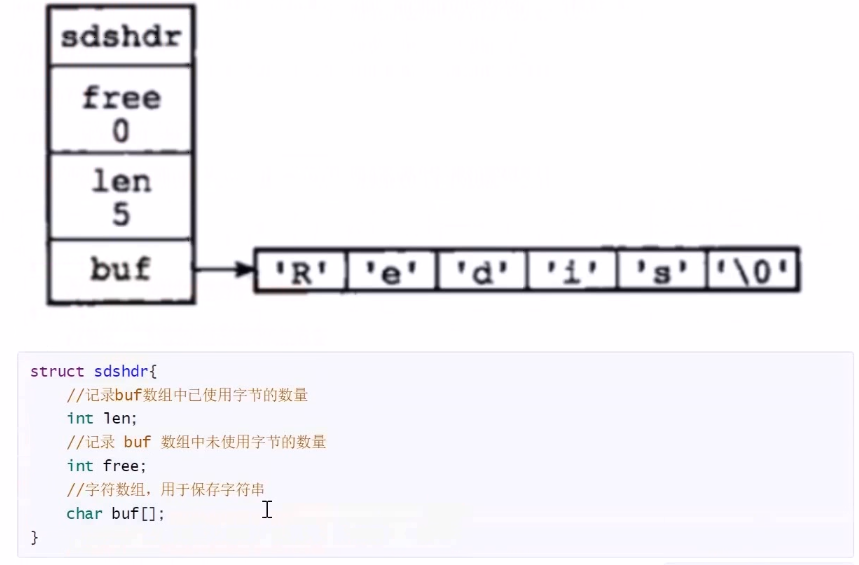
- 简单动态字符串(SDS)(redis中的字符串结构)
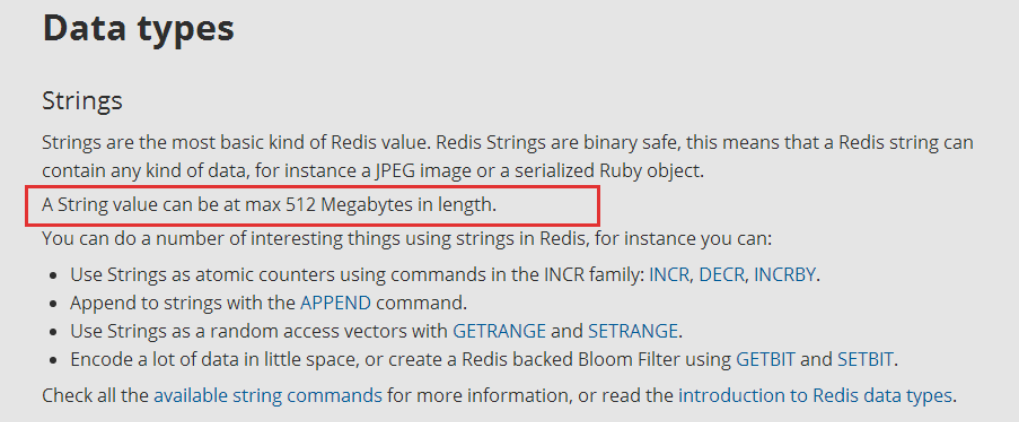
redis中string最大512M,redis中用int来修饰len字段,int为4个字节,也就是32位,那么最大能表示2^32次方。所以2^32/8/1024/1024=512m不存连接指针节省空间
- ziplist的每个节点的长度是可以不一样的

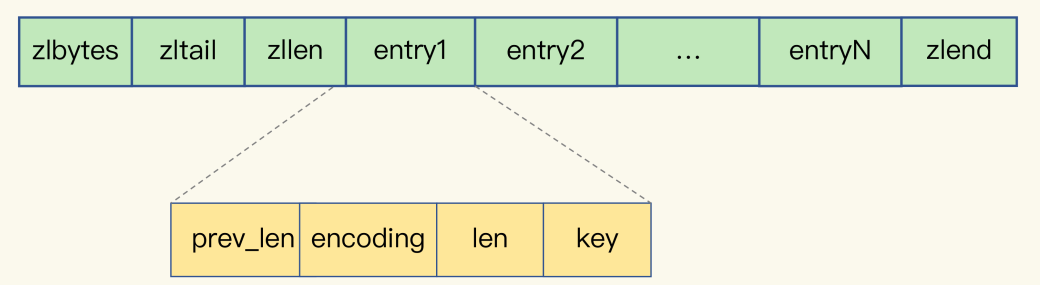
如何用ziplist保存hash?
- 遍历ziplist?而不是使用hash函数定位?
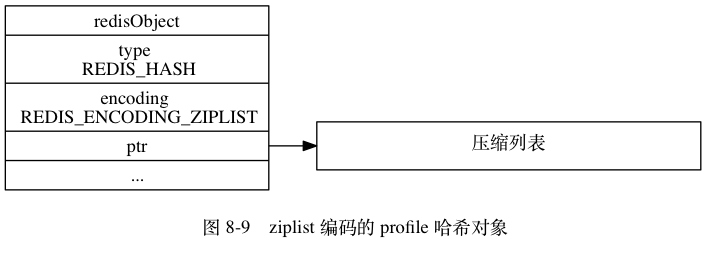
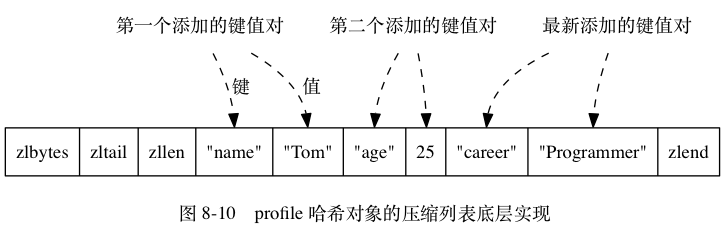
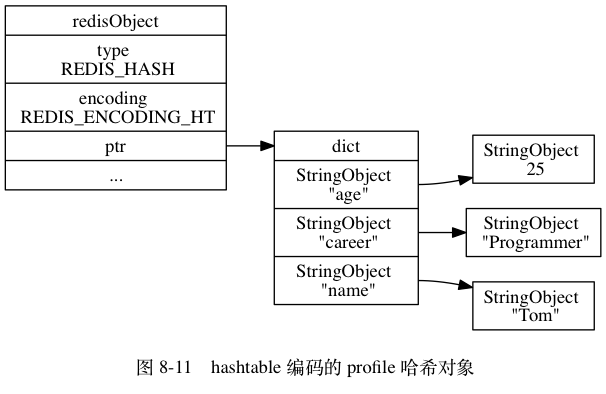
【优化】使用ziplist来优化String的存储空间【二级编码】


quickList
元素多就使用将链表和ziplist组合起来,形成quickList。

zset
当待新加的新的字符串长度超过zset_max_ziplist_value(默认值64)时或者ziplist保存的节点数量超过server.zset_max_ziplist_entries(默认值128)时使用skiplist。
redis zset 内部的实现原理_李意成的博客-CSDN博客_rediszset实现原理
hash
- 同上
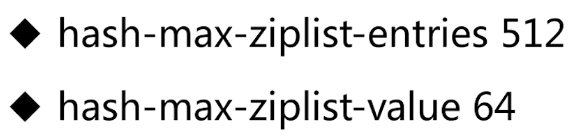
渐进式rehash。
渐进式 rehash 会在 rehash 的同时,保留新旧两个 hash 结构,查询时会同时查询两个 hash 结构,然后在后续的定时任务中以及 hash 操作指令中,循序渐进地将旧 hash 的内容一点点迁移到新的 hash 结构中。当搬迁完成了,就会使用新的hash结构取而代之。
渐进式rehash详细步骤:
1、为ht[1]分配空间,让字典同时持有ht[0]和ht[1]两个哈希表。
2、在字典中维持一个索引计数器变量rehashidx,并将它的值设置为0,表示rehash工作正式开始。
3、在rehash进行期间,每次对字典执行添加、删除、查找或者更新操作时,程序除了执行指定的操作以外,还会顺带将ht[0]哈希表在rehashidx索引上的所有键值对rehash到ht[1],当rehash工作完成之后,程序将rehashidx属性的值增1.
4、随着字典操作的不断执行,最终在某个时间点上,ht[0]的所有键值对都会被rehash至ht[1],这时程序将rehashidx属性的值设置为-1,表示rehash操作已完成。
渐进式rehash的好处在于它采取分而治之的方式,将rehash键值对所需的计算工作均摊到对字典的每个添加、删除、查找和更新操作上,从而避免了集中式rehash而带来的庞大计算量。
————来自《redis设计与实现》
hash优化,大hash拆分为小hash。
因为ziplist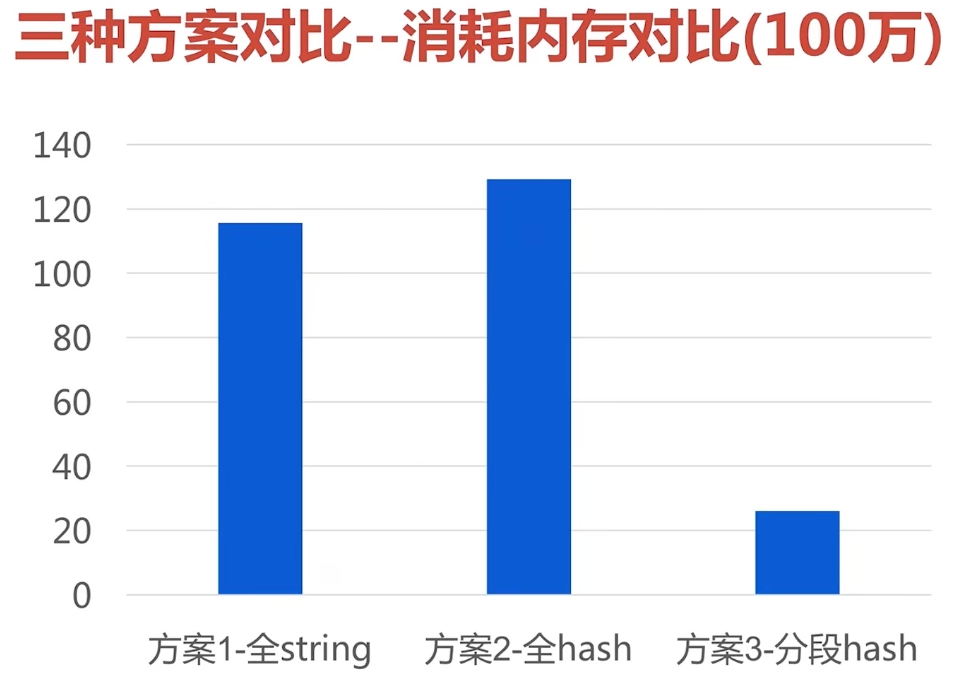
查
按前缀查key【keys、scan】
- keys:没有 offset、limit 参数,一次性吐出所有满足条件的 key
Redis 为了解决这个问题,它在 2.8 版本中加入了大海捞针的指令——scan。scan 相比 keys 具备有以下特点:
- 通过游标分步进行的,不会阻塞线程
- 提供 limit 参数
- 返回的结果可能会有重复可能会有重复可能会有重复,需要客户端去重复,这点非常重要;
- 数据修改不一定能遍历到。
- 单次返回的结果是空的并不意味着遍历结束,而要看返回的游标值是否为零。
bigkey & hotkeys发现
- redis-cli —bigkeys命令
redis-cli -h 127.0.0.1 -p 7001 –bigkeys
redis-cli -h 127.0.0.1 -p 7001 –bigkeys -i 0.1 #当心这个指令会大幅抬升 Redis 的 ops 导致线上报警,还可以增加一个休眠参数 -i 0.1
- redis-cli –hotkeys就能找出热点Key
- 原理:scan + object freq xx
- 惹不起的 Redis 热点 key(一):寻找热点 key - 开发者头条
删除
【4.0】【删除大key】unlink异步删除
redis 4.0 命令:unlink
后台起线程删除
6.0之后设置lazyfree-lazy-user-del直接用del?
Since Redis 6.0, there’s a new configuration: lazyfree-lazy-user-del. You can set it to be yes, and Redis will run the DEL command as if running a UNLINK command. redis - Is the UNLINK command always better than DEL command? - Stack Overflow
【删除大list】ltrim + del
vi delete_list.sh#!/bin/bash#循环删除listlist_len=`redis-cli -p 6379 llen key_name`while true;doif [ $list_len -ge 3000 ];thenredis-cli -p 6379 ltrim key_name 0 -3000sleep 0.5list_len=`redis-cli -p 6379 llen key_name`elseredis-cli -p 6379 del key_nameexitfidone
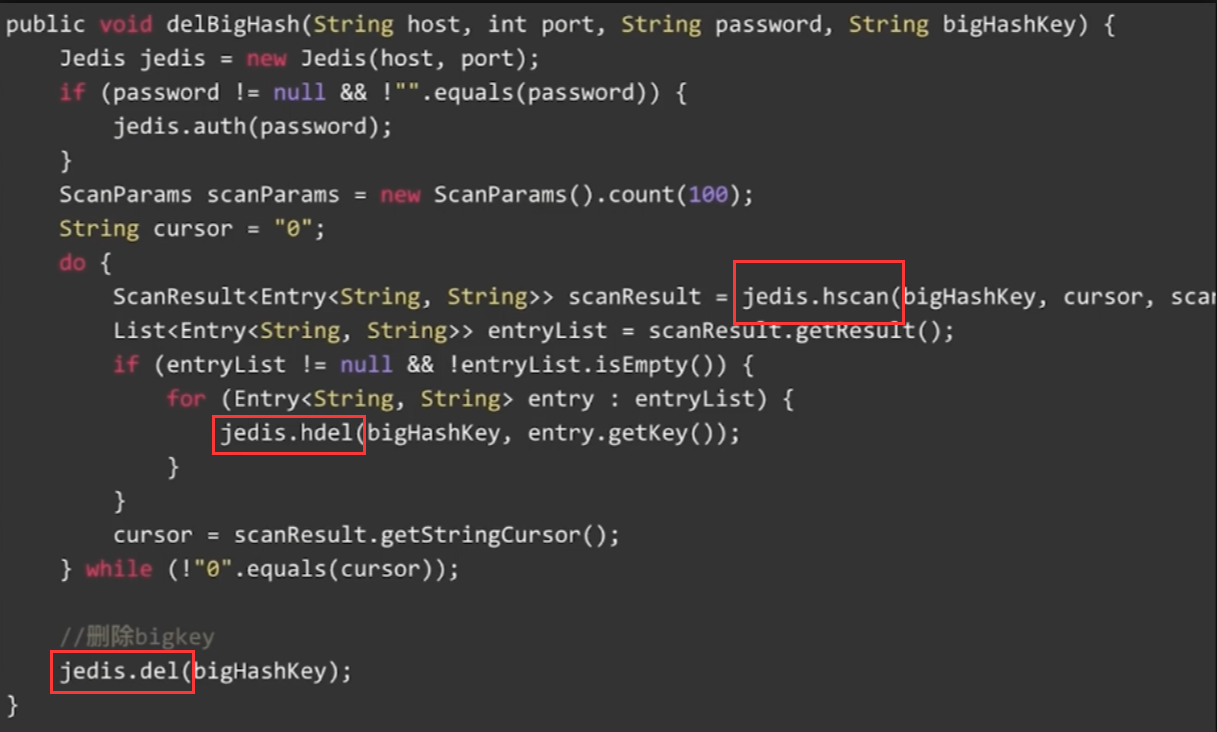
【4.0之前】【删除大hash】hscan + hdel + del
过期策略
- 定时遍历
-
定时扫描策略
选20个key,删除其中过期的
- 如果过期的key超过1/4,重复步骤1.
从节点过期策略
主节点过期回在aof中加一条del指令,同步到从节点。RedisTemplate序列化配置
《Java 业务开发常见错误 100 例》-极客时间热点key分散到多个redis节点上
《Java 业务开发常见错误 100 例》-极客时间
hotkey是将list类型的数据分散到多个节点上。
String类型的hotkey,可以使用应用层前置缓存。
有赞透明多级缓存解决方案(TMC)
redis面试
Redis阻塞点
- 集合的全量查询、聚合
- bigkey 删除(释放内存)
- 清空数据(FLUSHDB)
- 从库接收RDB后要FLUSHDB
- AOF 日志同步写
- 从库加载 RDB 文件(RDB太大)
- Redis Cluster 同步迁移 bigkey (后续有解决方案)
redis优化
redis系统优化

【好文】Redis为什么变慢了?一文讲透如何排查Redis性能问题
- 绑定cpu
- 关闭swap
- sudo swapoff -a
- echo vm.swappiness={bestvalue}>>/etc/sysctl.conf
- 关闭内存大页
- echo never > /sys/kernel/mm/transparent_hugepage/enabled
- 加速fork(写时复制)

- add ‘vm.overcommit_memory = 1’ to /etc/sysctl.conf
- 默认是0,内存紧张情况,bgsave可能会失败
其他优化
禁用monitor命令
- Redis危险命令重命名、禁用 - 王恒志 - 博客园
击穿、雪崩、穿透
击穿
- Redis危险命令重命名、禁用 - 王恒志 - 博客园
缓存永不过期,主动更新缓存
-
雪崩
Springboot @Cacheable缓存失效时间带随机数改造_摩戈的博客-CSDN博客_cacheable随机数缓存时间
解决缓存穿透
缓存null,ttl设置短点
- spring cache:cache-null-values: true # 是否缓存空结果,防止缓存穿透,默以为true
-
解决缓存一致性

双删不行就三删
-
redis 6.0新特性
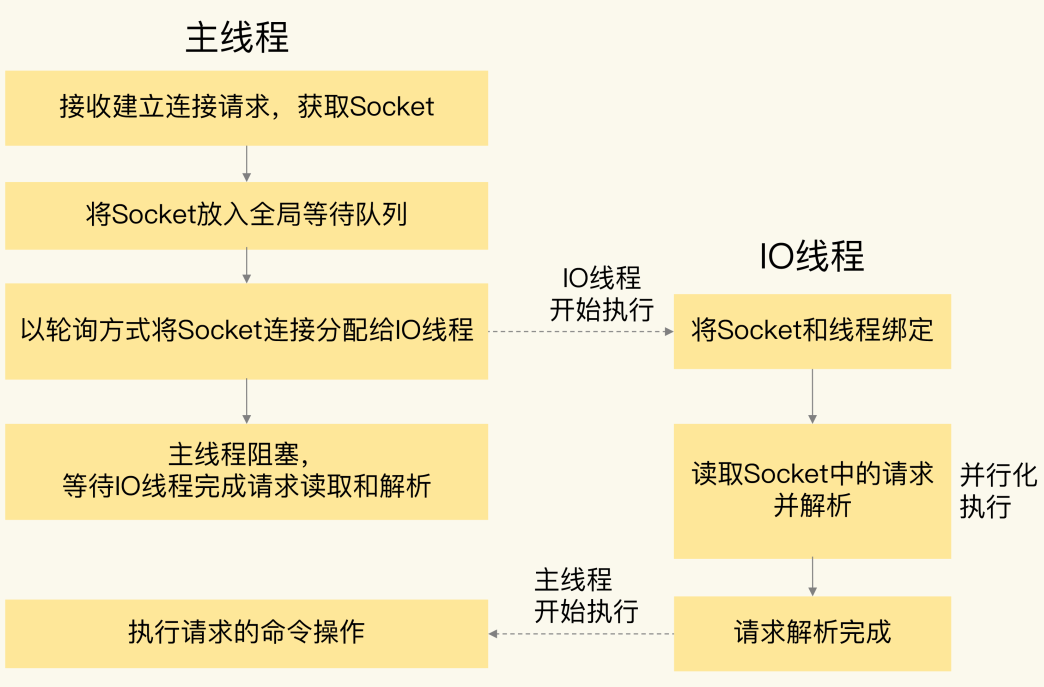
多个IO线程来处理网络请求
- io-threads-do-reads yes
- io-threads 6
- 默认只开启多线程「写」client socket,如果要开启多线程「读」,还需配置 io-threads-do-reads = yes
服务端协助的客户端缓存
-
有多路复用了还用多线程io么?
多线程io从epoll记录的socket中将数据从内核读取到用户态。(就加速了这一点么?(应该还有多线程请求解析也加快了))
从网络另一头发的数据包需要先解序列化成 Redis 内部其他模块可以理解的命令,这个过程就是 Redis 6.0 引入多线程来并发处理的
acl
Client-Side-Caching
Spring Data Redis
RedisTemplate默认Lettuce原因:
redis使用lua脚本
配置script:
@Beanpublic DefaultRedisScript<Long> stockScript() {DefaultRedisScript<Long> redisScript = new DefaultRedisScript<>();//放在和application.yml 同层目录下redisScript.setLocation(new ClassPathResource("stock.lua"));redisScript.setResultType(Long.class);return redisScript;}
使用script:
@Resourceprivate DefaultRedisScript defaultRedisScript;Long amount = (Long) redisTemplate.execute(defaultRedisScript, keys);
redis事务
redis事务就是exec的时候 全部执行队列中的命令(不管是否失败)
- multi:开启队列
- exec:执行队列
- discard:清空队列
- watch:监控
- unwatch
事务中的
- 语法错误(编译错误),则队列清空。
- 类型错误(运行时错误),则跳过错误命令继续执行队列中的命令。
watch:
- 发现watch变化,清空队列。(在exec之前)

redis订阅发布
新订阅者无法获取之前的消息。

若有收获,就点个赞吧
0 人点赞
