上一节我们体验了Dubbo调用链的完整流程,这一节我们来点深入的,看看Dubbo是如何通过Cluster组件做集群容错的。
Dubbo在分布式环境要解决的问题
为了避免单点故障,我们会把服务部署在多个服务器上,组成一个集群。像淘系营销优惠这样超高QPS的服务,还会堆更多的服务器。对于服务消费者来说,面对集群中这么多的可用节点不知所措,摆在眼前的就有两个主要问题:
- 寻址 如何决定哪个服务提供者进行调用?
- 异常处理 调用失败后怎么办?本地重试还是抛出异常?还是换一个节点重试呢?
对于Spring Cloud中的组件来说这都不是问题,直接集成Ribbon就好了,既有负载均衡还有重试。但是大阿里出品的Dubbo怎能食嗟来之食?吃口馒头赌口气,非得造个轮子出来!
Cluster组件和集群容错
为了处理这些问题,Dubbo定义了集群接口Cluster以及Cluster Invoker。集群Cluster用途是将多个服务提供者合并为一个Cluster Invoker,并将这个Invoker暴露给服务消费者。这样一来,服务消费者只需通过这个 Invoker 进行远程调用即可,至于具体调用哪个服务提供者,以及调用失败后如何处理等问题,现在都交给集群模块去处理。
集群模块是服务提供者和服务消费者的中间层,为服务消费者屏蔽了服务提供者的情况,这样服务消费者就可以专心处理远程调用相关事宜。比如发请求,接受服务提供者返回的数据等。
集群容错的工作流
在学习Cluster Invoker之前,我们先来熟悉一下集群容错的工作流程和核心组件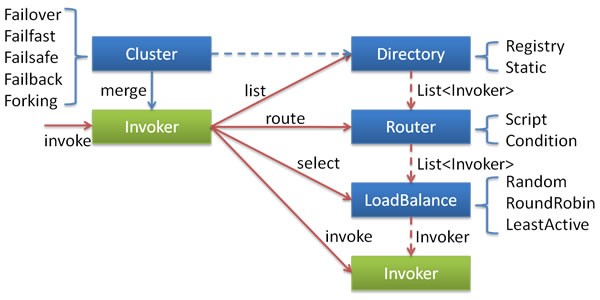
我们结合Dubbo开源文档提供的一幅图来看一下,我们分两个阶段来介绍集群的工作流程:
(1)消费者初始化阶段
这个阶段发生在服务消费者初始化期间,就是图片最左上角的merge操作。在这一步中,Cluster组件为服务消费者创建Cluster Invoker实例,消费者通过这个Invoker实例发起远程调用。
我们将在本小节后半部分具体介绍每个用于集群容错的Invoker实例,以及它的应用场景。
(2)消费者发起远程调用
以FailoverClusterInvoker为例,消费者发起远程调用主要分为三个步骤:
- Directory获取服务提供者 调用Directory服务获取所有Invoker,Directory的作用就如同它的字面意思一样,相当于是一个目录,大家可以把Directory理解为一个保存Invoker的数据结构。不仅如此,Directory还会探知注册中心的变动,并随之更新Invoker列表
- Router过滤 Directory在每次更新Invoker列表后,会调用Router的route方法将不符合路由规则的Invoker过滤掉
LoadBalance负载均衡 从Directory获取到Invoker列表后,通过LoadBalance策略从中选择一个Invoker,然后将请求参数递交给这个Invoker发起真实调用
Cluster Invoker大集合
Dubbo提供了六种集群容错方案,我们今天主要介绍以下五种,还特意留了一个当做支线剧情,让同学们自己去阅读源码学习(BroadcastCluster)。
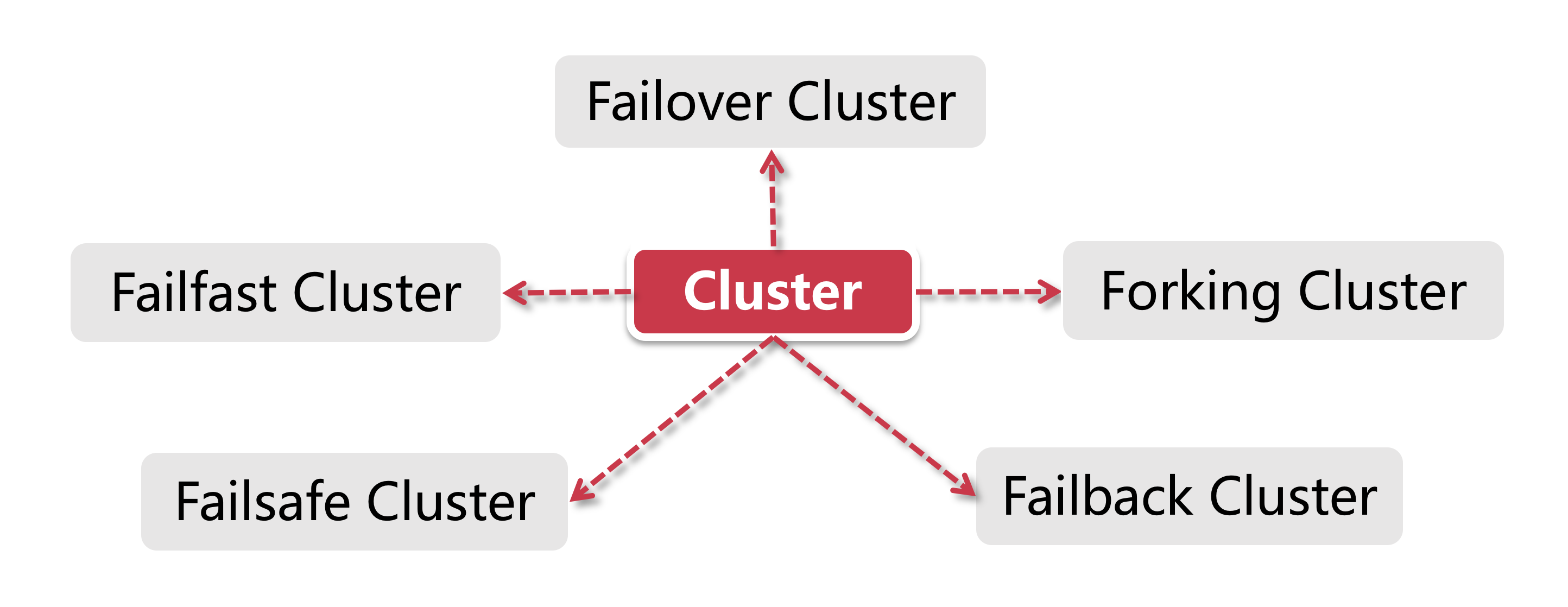
我们先来理一理Cluster和Cluster Invoker之间的关系。前面我们提到过,Cluster只是用来创建Cluster Invoker给消费者进行调用的,所以Cluster本身的代码非常简单。我们以FailoverCluster为例,它只包含了短短几行代码:public class FailoverCluster implements Cluster {public static final String NAME = "failover";public FailoverCluster() {}public <T> Invoker<T> join(Directory<T> directory) throws RpcException {return new FailoverClusterInvoker(directory);}}
同学们可以看到,它仅仅就是创建一个FailoverClusterInvoker对象返回,没有其他逻辑。不单FailoverCluster如此,其他的几个Cluster也都是这副样子。接下来,我们就挨个看一看这五种Cluster Invoker都发挥了什么作用
FailoverClusterInvoker - 指定重试次数
FailoverClusterInvoker在调用失败时,会自动切换 Invoker 进行重试。它是Dubbo默认的Cluster Invoker,所以我们重点介绍下。它的流程大致如下:
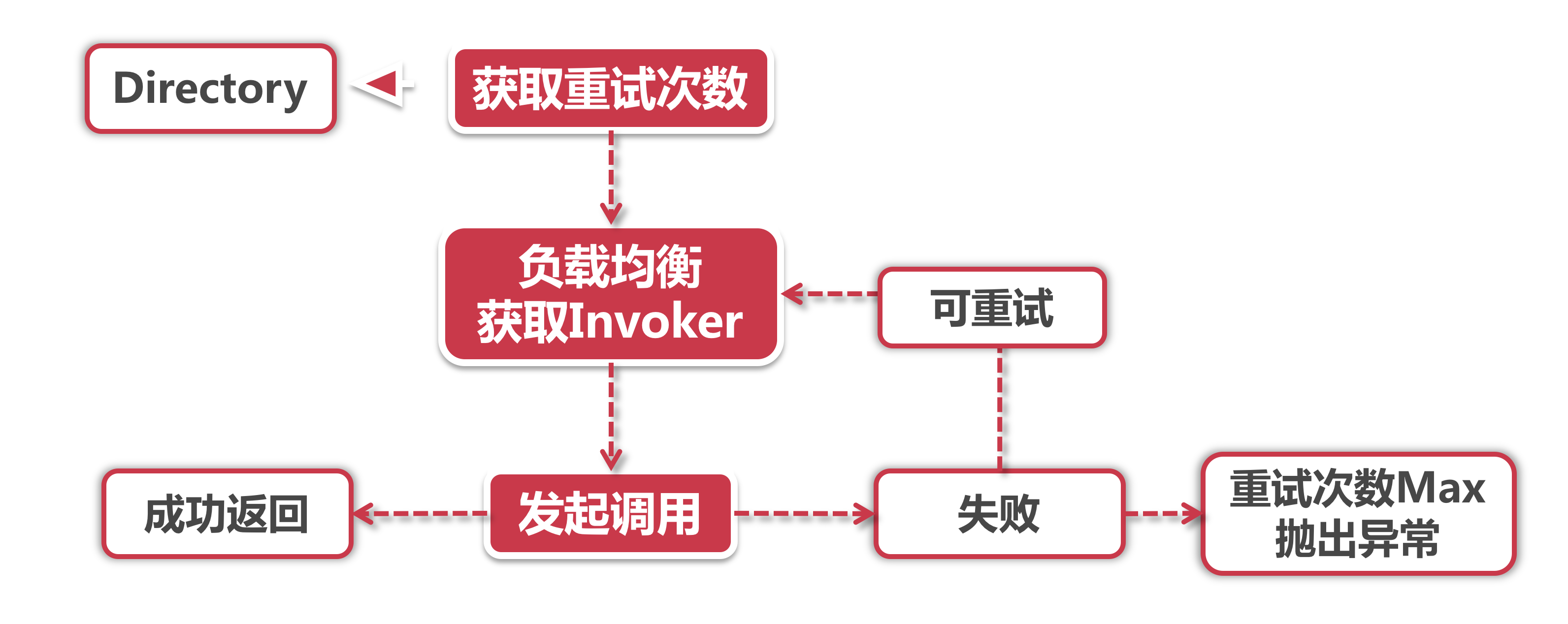
- 首先从Directory中获取重试次数
- 根据重试次数进行循环调用,每次重试都从负载均衡组件中获取一个Invoker。如果调用失败,则把异常记录下来然后进行重试,如果重试次数达到上限了,那么就直接抛出异常
在负载均衡调用之前,FailoverClusterInvoker对Invoker的选择还动了一点小手脚。这里引入了一种叫“粘滞连接”的优化方案,这名词听着很稀奇,所谓粘滞连接是指让服务消费者尽可能的调用同一个服务提供者,除非该提供者挂了再进行切换。大家只要记住粘滞连接的含义,就能很顺利的理解这个方法的用途。
粘滞连接检测方案代码不多但是理解起来相当绕。我来贴一段代码大家感受一下:
protected Invoker<T> select(LoadBalance loadbalance, Invocation invocation,List<Invoker<T>> invokers, List<Invoker<T>> selected) throws RpcException {if (invokers == null || invokers.isEmpty())return null;String methodName = invocation == null ? "" : invocation.getMethodName();// 获取 sticky 配置,sticky 表示粘滞连接。所谓粘滞连接是指让服务消费者尽可能的// 调用同一个服务提供者,除非该提供者挂了再进行切换boolean sticky = invokers.get(0).getUrl().getMethodParameter(methodName,Constants.CLUSTER_STICKY_KEY, Constants.DEFAULT_CLUSTER_STICKY);// 检测 invokers 列表是否包含 stickyInvoker,如果不包含,// 说明 stickyInvoker 代表的服务提供者挂了,此时需要将其置空if (stickyInvoker != null && !invokers.contains(stickyInvoker)) {stickyInvoker = null;}// 在 sticky 为 true,且 stickyInvoker != null 的情况下。如果 selected 包含// stickyInvoker,表明 stickyInvoker 对应的服务提供者可能因网络原因未能成功提供服务。// 但是该提供者并没挂,此时 invokers 列表中仍存在该服务提供者对应的 Invoker。if (sticky && stickyInvoker != null && (selected == null || !selected.contains(stickyInvoker))) {// availablecheck 表示是否开启了可用性检查,如果开启了,则调用 stickyInvoker 的// isAvailable 方法进行检查,如果检查通过,则直接返回 stickyInvoker。if (availablecheck && stickyInvoker.isAvailable()) {return stickyInvoker;}}// 如果线程走到当前代码处,说明前面的 stickyInvoker 为空,或者不可用。// 此时继续调用 doSelect 选择 InvokerInvoker<T> invoker = doSelect(loadbalance, invocation, invokers, selected);// 如果 sticky 为 true,则将负载均衡组件选出的 Invoker 赋值给 stickyInvokerif (sticky) {stickyInvoker = invoker;}return invoker;}
FailbackClusterInvoker - 后台定时重试
FailbackClusterInvoker会在调用失败后,返回一个空结果给服务提供者,并通过定时任务对失败的调用进行重传,因此特别适合执行某些“通知”类型的任务。
大家在使用这个Invoker的时候要特别注意它的“定时任务重传”功能,因为大部分情况下我们并不期望Dubbo在后台偷偷摸摸发起重试,毕竟这时候消费者对这个事件是感知不到的。
FailbackClusterInvoker的流程从前到后主要有三个步骤:
- doInvoker 发起首次远程调用,如果调用失败则添加调用信息到addFailed方法中,同时返回给消费者一个空的RpcResult对象
- addFailed 创建定时任务,每隔5秒执行一次,调用retryFailed方法对失败任务进行重试。这个定时任务只会创建一次,任务启动后新添加的失败请求依然会被重试
- retryFailed 失败重试的主要逻辑都在这里,它保存了一个失败者名单,挨个执行方法,如果执行成功则从名单中移除
FailbackClusterInvoker的后台重试列表只是保存在内存中的一个Map结构,一旦服务器重启之后就不会重试了。个人建议慎选这个策略,这种后台重试的机制是消费者无法感知并且不能控制的,可能会带来无法预知的结果,而且在某些极端场景下(比如服务雪崩)可能会增加系统的压力。
FailfastClusterInvoker - 早死早超生
这个方法比较省心,只会进行一次调用,失败后立即抛出异常。老师再也不用担心服务没有实现幂等性了。
FailsafeClusterInvoker - 睁一只眼闭一只眼
这个方法比上面那个更省心,它也只会发起一次调用,但是失败后不会抛出异常。而是打印一行错误日志,然后返回一个空的RpcResult对象。
ForkingClusterInvoker - 百万雄师过大江
ForkingClusterInvoker简直就像开启了狂暴模式,它会通过线程池开启多个线程,对服务提供者同时发起调用,任意一个线程返回成功就会立即结束方法。考虑到它这种百万雄师过大江的方式对服务器的负载能力简直是一种噩梦,因此它的适用场景极度局限,只能应用在某些对Timing要求极高的场景(最好是Read操作,即便是实现了幂等性的Write也不要使用这个策略,浪费资源)。
小结
这一小节我们了解了Dubbo的Cluster和Cluster Invoker组件,对其中内置的集群容错方案做了了解。下一节我们去看看Dubbo是如何做负载均衡的。

若有收获,就点个赞吧
0 人点赞
