我们都知道c++中的多态是通过虚函数表机制来实现的,但你知道虚函数表机制是如何实现的么?虚函数表指针在类内中的布局是什么样的?类的内存布局是什么样的?类继承之后的布局又是什么样的?基类的析构函数必须要是虚函数么?基类构造函数可以是虚函数么?或者说它可以调用虚函数么?c++的 class 相比 c 的 struct 这种数据和方法分开的做法是否更耗内存或者有更多花费?……
如果这些问题你都了然于胸,那么这篇文章对你可能没有帮忙,否则的话,看完这篇文章相信你会有所收获的。
先从 C 说起
在 c 语言中,数据结构和在数据结构上操作的方法是分开的,如下,我们有一个 Person 结构体,以及用来打招呼的 hello() 函数。
typedef struct Person {int age;char* name;}Person;void hello(const Person* p) {printf("hello, I'm a person, my age is %d, my name is %s!\n", p->age, p->name);}int main() {Person p;p.age = 18;p.name = "xiaomin";hello(&p);return 0;}
我们可以看出上面的代码占用的堆栈大小就是 Person 结构体的大小,在x64的系统上是 16 字节,并且上面的代码就是实现这个功能最简单最高效也最省内存的方法了。也就是说,你找不到比上面更省内存或更高效的代码了。
我们来看一下在 c++ 中的实现,如下:
class Person {public:explicit Person(int age, char* name) {m_age = age;name = name;}void hello() {std::cout << "hello, I'm a person, my age is " << m_age<< ", my name is " << m_name << std::endl;}private:int m_age;char* m_name;};int main() {Person* p = new Person(18, "xiaomin");p->hello();}
看起来似乎要比 c 的实现要复杂一点,Person class 里面既有数据又有函数,它的内存占用是否要比等价的 c 语言要更高一点呢?事实上,得益于 C++ 的零开销抽象,上面两段代码的内存占用量以及执行速度都是没有任何区别的,但 C++ 的实现却可以享受到面对对象编程带来的一些好处。
如何查看类内的布局
为了后面更方便的推进,这里介绍三种查看对象布局的方式。分别是使用 clang,g++,gdb 来查看对象内存布的方法。
查看 cpp.cpp 文件中类的虚函数表布局
clang++ -Xclang -fdump-vtable-layouts cpp.cpp
结果如下:<br />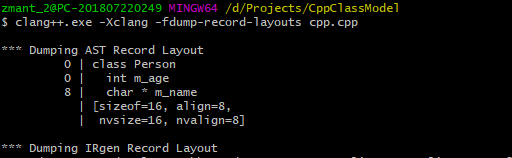2. 使用 g++ 查看对象布局的方法:```shell# g++ 版本在8.x之前,使用如下命令:g++ -fdump-class-hierarchy cpp.cpp# g++ 版本在8.x及之后版本,使用如下命令:g++ -fdump-lang-class cpp.cpp
g++会把结果保存在一个 .class 的文件中,结果如下: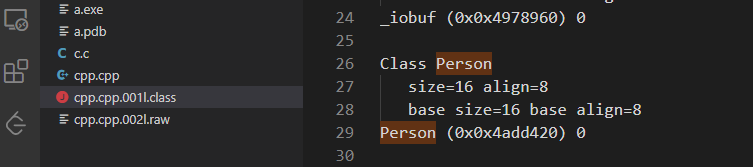
- 使用 gdb 查看对象布局的方法,该方法首先需要将 cpp 文件以 debug 的方式编译好,然后使用 gdb 调试它,先在对象实例化后的位置设置一个断点,然后 run 之后,按如下方式设置打印格式:
然后直接 print 对象即可。结果如下:set print object onset print vtbl onset print pretty on
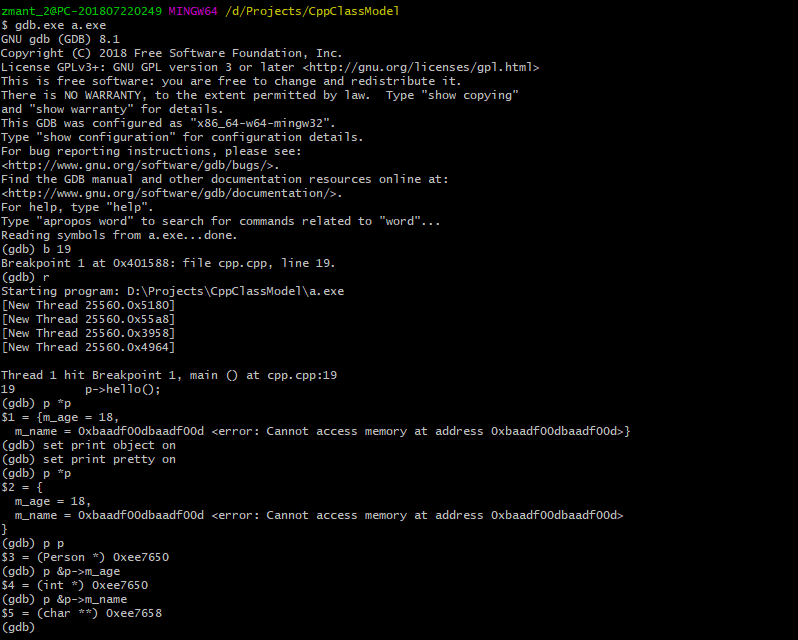
通过上面查看Personclass 对象内存布局就可以发现,它和 c 实现的Person结构体的内存布局是一致的,都是 16 字节大小,它的函数虽然是声明在类内的,但类成员函数并不占用类对象的内存,它其实和 c 一样都是存储在代码区的,并且多个对象共享同一份成员函数实现,而这其实是通过this指针实现的。
无继承的类对象布局
扩展上面的代码,我们把 hello() 函数写成虚函数,析构函数也定义成虚函数,如下:
class Person {public:explicit Person(int age, char* name) {m_age = age;name = name;}virtual ~Person() = default;virtual void hello() {printf("hello, I'm a person, my age is %d, my name is %s\n", m_age, m_name);}protected:int m_age;char* m_name;};
再打印它的内存布局,如下:
*** Dumping AST Record Layout0 | class Person0 | (Person vftable pointer)8 | int m_age16 | char * m_name| [sizeof=24, align=8,| nvsize=24, nvalign=8]*** Dumping IRgen Record Layout
相比于上面不带虚函数的类,带虚函数的类中在类的起始位置插入了一个虚函数表指针,其他都是一样的。我们再使用命令 clang.exe -Xclang -fdump-vtable-layouts cpp.cpp 打印其虚函数表的布局,如下:
VFTable for 'Person' (3 entries).0 | Person RTTI1 | Person::~Person() [scalar deleting]2 | void Person::hello()
可以看到,第一个索引位置保存的指针是 Person RTTI,也就是保存 Person 类的运行时类型信息的指针,然后是按虚函数声明的顺序依次保存对应的虚函数指针。比如,要是我们把虚析构函数放在虚函数 hello() 之后:
class Person {public:...virtual void hello() {printf("hello, I'm a person, my age is %d, my name is %s\n", m_age, m_name);}virtual ~Person() = default;protected:...};
那么打印的虚函数表布局则如下:
VFTable for 'Person' (3 entries).0 | Person RTTI1 | void Person::hello()2 | Person::~Person() [scalar deleting]
我们以第一个虚析构申明在前的代码画出它的内存布局,如下:
单继承下的类对象布局
继续扩展上面的代码,我们继承上面的 Person 类实现了一个 Student 类,如下:
class Person {...};class Student: public Person {public:Student(int age, char* name, char* major, float score):Person(age, name) {m_major = major;m_score = score;}~Student() = default;virtual void hello() override {printf("hello, I'm a student,my name is %s, my major is %s, my score is %f\n",m_name, m_major, m_score);}private:char* m_major;float m_score;};
打印它的内存布局,如下:
$ clang++.exe -Xclang -fdump-record-layouts cpp.cpp*** Dumping AST Record Layout0 | class Person0 | (Person vftable pointer)8 | int m_age16 | char * m_name| [sizeof=24, align=8,| nvsize=24, nvalign=8]*** Dumping AST Record Layout0 | class Student0 | class Person (primary base)0 | (Person vftable pointer)8 | int m_age16 | char * m_name24 | char * m_major32 | float m_score| [sizeof=40, align=8,| nvsize=40, nvalign=8]*** Dumping IRgen Record Layout
通过打印内存布局我们可以发现,派生类的布局是把基类整个内存布局(包括虚函数表指针)继承下来,然后再按声明的顺序依次添加派生类自己的成员变量到派生类对象布局之中。
通过 gdb 也可以看到如下的派生类布局,并且也能看到最后一个基类成员是和派生类第一个成员之间是紧挨着的,也就是说继承的时候其实是把基类成员依次拷贝到了派生类中: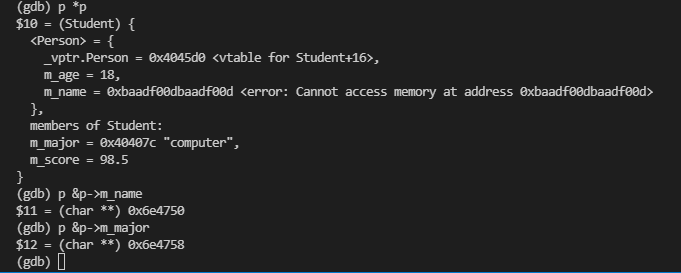
我们再打印它的虚函数表布局,如下:
clang -Xclang -fdump-vtable-layouts .\cpp.cppVFTable for 'Person' (3 entries).0 | Person RTTI1 | Person::~Person() [scalar deleting]2 | void Person::hello()VFTable for 'Person' in 'Student' (3 entries).0 | Student RTTI1 | Student::~Student() [scalar deleting]2 | void Student::hello()
基类 Person 和派生类 Student 的虚函数表中分别保存的是各自类中的虚函数实现,还可以看到,派生类中析构函数本身是没有申明为虚函数的,但它还是出现在了派生类的虚函数表中,所以,可以知道,基类中的析构函数为虚函数的情况下,派生类中的析构函数也一定是虚函数,编译器保证。

虚函数表中的函数顺序
我们扩展上面的代码,增加一个虚函数 sport ,如下:
class Person {public:......virtual ~Person() = default;virtual int sport() {}virtual void hello() {}protected:......};class Student: public Person {public:......//注意下面几个虚函数的顺序和基类不一致virtual void hello() override {}virtual int sport() override {}~Student() = default;private:......};
经过前面的分析,我们知道基类中虚函数表中的虚函数顺序就是其声明的顺序,那派生类中虚函数表中的顺序是什么样的呢?我们打印上面的虚函数表的顺序,如下:
clang -Xclang -fdump-vtable-layouts .\cpp.cppVFTable for 'Person' (4 entries).0 | Person RTTI1 | Person::~Person() [scalar deleting]2 | int Person::sport()3 | void Person::hello()VFTable for 'Person' in 'Student' (4 entries).0 | Student RTTI1 | Student::~Student() [scalar deleting]2 | int Student::sport()3 | void Student::hello()
从上面的结果可以看到,若派生类中全部都是 override 基类虚函数,那么派生类中的虚函数顺序就是基类中虚函数的声明顺序。
若我们在派生类按下面的方式声明一些虚函数,如下:
class Student: public Person {public:......//在基类虚函数之前新增一个虚函数virtual void hello(int) {}//下面几个虚函数在基类中存在virtual void hello() override {}virtual int sport() override {}~Student() = default;//在基类虚函数之后新增一个虚函数virtual void foo(int) {}private:......};
我们再打印一下虚函数表顺序:
clang -Xclang -fdump-vtable-layouts .\cpp.cppVFTable for 'Person' (4 entries).0 | Person RTTI1 | Person::~Person() [scalar deleting]2 | int Person::sport()3 | void Person::hello()VFTable for 'Person' in 'Student' (6 entries).0 | Student RTTI1 | Student::~Student() [scalar deleting]2 | int Student::sport()3 | void Student::hello()4 | void Student::hello(int)5 | void Student::foo(int)
从结果可以看到,派生类的虚函数表中总是先按顺序存储基类中声明的虚函数,然后再按顺序存储派生类自己声明的虚函数。
虚函数调用机制
对于前面的 Person 类和 Student 类,我们进行如下的调用:
int main() {Person* p = new Student(18, "xiaomin", "computer", 98.5);p->hello();}
上面我们的代码中申明了一个基类指针,但是它实际指向的是派生类类型。这种调用方式其实就是一种多态的体现,也就是说调用 hello() 函数后,具体输出什么内容是在运行时才能确定。因为它到底是调用基类的版本还是派生类的版本取决于它实际指向的类型。它实际指向基类则调用基类版本,它实际指向派生类则调用派生类版本。
实际上,对于上面的 p->hello() 函数的调用,编译器调用之后实际上可能是通过下面的方式进行的:
p->_vptr[2]()
首先,p 是一个指针,p 指向的内容是实际类型存储的内容,也就是说 p->_vptr 访问的是派生类 Student 的 _vptr。
然后,编译器编译的时候也能够知道 hello 声明的顺序是 2,所以它在遇到 p->hello() 的时候,就可以自动替换成 p->_vptr[2](),从而实现多态。
如果我们的 main 函数中有如下代码:
int main() {Person base(16, "xiaohong");Student stu(20, "xiaotian", "Computer", 98);Person* p = &base; // 基类指针指向基类p = &stu; // 基类指针指向派生类base = stu; //派生类变量转基类变量return 0;}
然后我们通过 gdb 调试,如下:
(gdb) p base$1 = (Person) {_vptr.Person = 0x4045a0 <vtable for Person+16>,m_age = 16,m_name = 0x8 <error: Cannot access memory at address 0x8>}(gdb) p stu$2 = (Student) {<Person> = {_vptr.Person = 0x4045d0 <vtable for Student+16>,m_age = 20,m_name = 0x401610 <__do_global_dtors> "H(H\213\005\365\031"},members of Student:m_major = 0x404085 "Computer",m_score = 98}////////// 基类指针指向基类 //////////////(gdb) p *p$3 = (Person) {_vptr.Person = 0x4045a0 <vtable for Person+16>,m_age = 16,m_name = 0x8 <error: Cannot access memory at address 0x8>}(gdb) n38 base = stu;////////// 基类指针指向派生类 //////////////(gdb) p *p$4 = (Student) {<Person> = {_vptr.Person = 0x4045d0 <vtable for Student+16>,m_age = 20,m_name = 0x401610 <__do_global_dtors> "H(H\213\005\365\031"},members of Student:m_major = 0x404085 "Computer",m_score = 98}(gdb) n39 return 0;////////// 派生类变量转成基类变量 //////////////(gdb) p base$5 = (Person) {_vptr.Person = 0x4045a0 <vtable for Person+16>,m_age = 20,m_name = 0x401610 <__do_global_dtors> "H(H\213\005\365\031"}(gdb)
可以发现,因为对指针的访问其实就是访问它指向的实际内容,所以再加上虚函数表,我们就可以实现多态了。而普通变量之所以不行,是因为派生类转换成基类之后,派生类的虚函数表指针并不会赋值给基类的虚函数表指针(注意看上面第47行还是第3行的内容)。这种行为是符合直觉的,因为派生类转成基类之后,它就是一个基类类型了,不再和派生类有任何联系了。
多继承下类对象布局
我们继续往下扩展上面的代码,我们新加一个基类 Learn 来代表学习,然后 Student 除了需要继承 Person 之外,还需要继承 Learn,如下:
class Learn {public:Learn(int a, int b):m_a(a), m_b(b) {}virtual ~Learn() = default;virtual void study() {}private:int m_a;int m_b;};class Student: public Person, public Learn {public:Student(int age, char* name, char* major, float score):Person(age, name),Learn(1,2) {m_major = major;m_score = score;}virtual void hello(int) {}virtual void hello() override {}virtual int sport() override {}~Student() = default;virtual void foo(int) {}virtual void study() override {}};
再来打印它的内存布局,如下:
clang -Xclang -fdump-record-layouts cpp.cpp*** Dumping AST Record Layout0 | class Person0 | (Person vftable pointer)8 | int m_age16 | char * m_name| [sizeof=24, align=8,| nvsize=24, nvalign=8]*** Dumping AST Record Layout0 | class Learn0 | (Learn vftable pointer)8 | int m_a12 | int m_b| [sizeof=16, align=8,| nvsize=16, nvalign=8]*** Dumping AST Record Layout0 | class Student0 | class Person (primary base)0 | (Person vftable pointer)8 | int m_age16 | char * m_name24 | class Learn (base)24 | (Learn vftable pointer)32 | int m_a36 | int m_b40 | char * m_major48 | float m_score| [sizeof=56, align=8,| nvsize=56, nvalign=8]
可以看到,派生类分别把它继承的基类成员依次按顺序在派生类中进行申明(包括各基类的虚函数表指针),然后再依次声明派生类自己的成员变量。基类在派生类中的顺序就是按继承列表从左到右的顺序进行的。
就是说如果我们继承的时候按下面的顺序:
class Student: public Learn, public Person {};
则 Student 派生类对应的内存布局如下:
clang -Xclang -fdump-record-layouts cpp.cpp*** Dumping AST Record Layout0 | class Student0 | class Learn (primary base)0 | (Learn vftable pointer)8 | int m_a12 | int m_b16 | class Person (base)16 | (Person vftable pointer)24 | int m_age32 | char * m_name40 | char * m_major48 | float m_score| [sizeof=56, align=8,| nvsize=56, nvalign=8]
我们再打印这几个类的虚函数表,如下:
VFTable for 'Person' (4 entries).0 | Person RTTI1 | Person::~Person() [scalar deleting]2 | int Person::sport()3 | void Person::hello()VFTable for 'Learn' (3 entries).0 | Learn RTTI1 | Learn::~Learn() [scalar deleting]2 | void Learn::study()VFTable for 'Person' in 'Student' (6 entries).0 | Student RTTI1 | Student::~Student() [scalar deleting]2 | int Student::sport()3 | void Student::hello()4 | void Student::hello(int)5 | void Student::foo(int)VFTable for 'Learn' in 'Student' (3 entries).0 | Student RTTI1 | Student::~Student() [scalar deleting][this adjustment: -24 non-virtual]2 | void Student::study()
可以看到,因为派生类 Student 同时继承了带有虚函数的基类 Person,Learn,所以 Student 具有两个虚函数表指针。虚函数的顺序其实和单继承是一样的,都是先存储基类虚函数,在存储派生类新增的虚函数。但是现在因为派生类有两个虚函数表指针,那派生类新增的虚函数是存储在哪个虚函数表指针中呢?
从上面打印的语句就可以看出,答案就是存储在派生类的第一个虚函数表指针中,我们再把上面的继承顺序改成如下:
class Student: public Learn, public Person {};
就可以得到下面的虚函数表内存:
VFTable for 'Learn' (3 entries).0 | Learn RTTI1 | Learn::~Learn() [scalar deleting]2 | void Learn::study()VFTable for 'Person' (4 entries).0 | Person RTTI1 | Person::~Person() [scalar deleting]2 | int Person::sport()3 | void Person::hello()VFTable for 'Learn' in 'Student' (5 entries).0 | Student RTTI1 | Student::~Student() [scalar deleting]2 | void Student::study()3 | void Student::hello(int)4 | void Student::foo(int)VFTable for 'Person' in 'Student' (4 entries).0 | Student RTTI1 | Student::~Student() [scalar deleting][this adjustment: -16 non-virtual]2 | int Student::sport()3 | void Student::hello()
好了,以上就是本篇的所有内容,对于其余类对象的布局是如何的,相信学会了上面的方法,你已经有能力可以自己去探索了。

若有收获,就点个赞吧
0 人点赞
