RawVec<T> 是什么?打开 Rust 的标准库网站也搜索不到这么个东西,所以我们为什么要去分析它呢?它值得我们去分析么?它又用在哪些场景呢?
起初我也不知道这个东西是从哪来,干什么用,以及要用到哪去,因为我原本只是想要分析 Vec<T> 的源码的, 结果 Vec<T> 的结构定义中除了一个表示长度的 usize 字段外,就只剩 RawVec<T> 这一个字段了,usize 字段自然没什么好分析的,所以你想要弄懂 Vec<T> 的底层实现,RawVec<T> 就是你必须要熟悉了解的东西了。 因为 Vec<T> 的内存分配,扩容机制等背后都是 RawVec<T> 在默默付出啊。
带着问题出发
在茫茫大海之上航行一个很重要的要求就是你得知道方向,否则迷失方向之后你可能就永远无法达到彼岸了,因为没有一个参照,辛辛苦苦大半天可能还是在附近转圈圈。
其实阅读源码应该也是同样的道理,一份源代码少则几百行,多则几千行,若再加上代码中对其他源码的引用,轻轻松松上万行啊。若你不想溺死在代码的海洋中,你同样需要在阅读源码的时候找准一个方向,当然这个方向不会是指南针,而是问题,也就是读完这些源码之后你希望弄明白的那些问题。
**
有了这些问题,你在阅读源码的时候才不会迷失方向,你才知道从哪些地方下手,你才会知道哪些东西是你应该重点关注的,哪些东西是可以一眼带过的。
所以,对于 RawVec<T> 的源码阅读分析,我希望弄明白下面几个问题:
RawVec<T>有哪些构造方式?它的默认构造会分配多大的内存?RawVec<T>的扩容机制是怎样的?也就是每次扩容的时候会扩大容量?RawVec<T>扩容应该可能会重新内存,那重新分配之后,原本的数据是拷贝过去的么?是否存在 C++ 那种扩容之后以前的迭代器失效的情况呢?RawVec<T>的内存释放之后,在它管理的内存上的数据是否也会自动调用 drop 进行释放呢?
RawVec 第一印象
得益于 Rust 丰富细致的文档,我们打开源码的一眼就可以直接通过它本身注释对它有个整体大概的印象,其实 RawVec<T> 就是一个底层实用工具,一个更符合人体工程学的在堆上进行内存分配,重分配以及释放而不必担心各种边边角角的情况被漏掉的一个底层实用工具。比如它有下面的一些保证:
- 对零大小类型或零长度的分配是直接调用
Unique::dangling(),并且对于Unique::dangling()的分配会避免调用内存释放动作。- 捕获所有可能会导致容量溢出的计算
- 防止 32-位 系统的内存分配超过 isize::MAX 个字节
- 防止长度过长而导致的溢出
- 对于不可靠的分配会调用
handle_alloc_error函数- 内部使用的是
ptr::Unique<T>从而会赋予用户Unique相关的好处
根据它的文档还可以了解到:
RawVec<T>并不会审视它所管理的那块内存。也就是说当RawVec发生drop的时候,它会释放它所管理的内存,但它不会尝试去drop内存上的内容。这些内容需要由使用RawVec<T>的用户自己去处理这些存储在RawVec内的数据。
这部分我们后面可以分析它的 drop 实现去确认。首先来看一下它的结构定义:
pub struct RawVec<T, A: AllocRef = Global> {ptr: Unique<T>,cap: usize,alloc: A,}
真是前路坎坷啊,又遇到了一个不认识的东西 Unique<T>,其实我们可以通过它修饰的字段名大概可以猜测出 Unique<T> 应该是一个智能指针似东西,并且是唯一拥有它所指向的数据的所有者,也就是一种独占指针。
Unique 是个啥子东西
我们找到 unique.rs 源码文件,首先根据它的文档,我们可以大致知道 Unique<T> 是对原始非空指针 *mut T 的一个包装,它表明了这个实例的所有者拥有它所指向的对象;但它和 *mut T 有几个不同的地方:
Unique<T>的行为表现的就像是类型T的一个实例,而*mut T则是指向T的一个可变裸指针。Unique<T>所指向的对象永远不可能为空,而*mut T可能为空。Unique<T>在T上是协变的,而*mut T在T上是不变的。
它在标准库中的定义:
pub struct Unique<T: ?Sized> {pointer: *const T,_marker: PhantomData<T>,}
真真是前路十八弯啊,又遇到了一个不认识的 PhantomData<T>,它又是干什么用的呢?我们直接搜索一下就可以发现它其实只在构造的地方出现过,其他地方根据看不到它的踪影,所以如果你现在还不了解它,直接先忽视它就好,不会影响你对 Unique<T> 功能的理解,想要了解的同学,推荐看《对 Rust 的 PhantomData 的理解》这篇博客。下面就直接开始了解 Unique<T> 本身。
unique.rs 这份源码非常简单,带上注释也不到 200 行,也都比较好理解,首先看下它有哪些构造函数。
impl<T: Sized> Unique<T> {#[inline]pub const fn dangling() -> Self {unsafe { Unique::new_unchecked(mem::align_of::<T>() as *mut T) }}}impl<T: ?Sized> Unique<T> {#[inline]pub const unsafe fn new_unchecked(ptr: *mut T) -> Self {unsafe { Unique { pointer: ptr as _, _marker: PhantomData } }}#[inline]pub fn new(ptr: *mut T) -> Option<Self> {if !ptr.is_null() {Some( Unique { pointer: ptr as _, _marker: PhantomData })} else {None}}}
可以看到主要有两个构造用的函数,分别是 new_unchecked(``ptr: *mut T``) 和 new(ptr: *mut T),区别就在于前者没有做判空检查,需要调用者自己保证,是 unsafe 的但也是 const 的,编译期即构造完成;后者做了判空检查,是 safe 的,如果传入的指针是空,则返回 None。
另外对所有具有固定大小的类型还实现了一个 dangling() 构造函数,它内部其实就是调用 new_unchecked 函数,但它本身是 safe 的,因为它给 new_unchecked 传入的值是 mem::align_of 的返回值的指针,永远不可能为空。
Unique<T> 提供的一些接口函数。
/// 获得内部 *mut T 的指针。#[inline]pub const fn as_ptr(self) -> *mut T {self.pointer as *mut T}/// 返回不可变引用/// 返回值的生命周期和 self 实例一致, 若需要更长的生命周期,可以使用 &*my_ptr.as_ptr() 的方式#[inline]pub unsafe fn as_ref(&self) -> &T {unsafe { &*self.as_ptr() }}/// 返回可变引用/// 返回值的生命周期和 self 实例一致, 若需要更长的生命周期,可以使用 &mut *my_ptr.as_ptr() 的方式#[inline]pub unsafe fn as_mut(&mut self) -> &mut T {// SAFETY: the caller must guarantee that `self` meets all the// requirements for a mutable reference.unsafe { &mut *self.as_ptr() }}/// 将内部类型转换成另一种类型#[inline]pub const fn cast<U>(self) -> Unique<U> {unsafe { Unique::new_unchecked(self.as_ptr() as *mut U) }}
另外它还实现了一些 trait,比如对于实现了 Send/Sync 的 T 类型 Unique<T> 也实现了 Send/Sync ,因为 Unique<T> 拥有它所引用的数据。还有其他的比如 Copy,Clone,From<&mut T> 等就不介绍了。
总结下来就是,Unique<T> 只是对 *mut T 的一层抽象而已,本身没有做任何分配内存的操作,它指向的内存也都是外部调用者通过 new_unchecked 或 new 这两个构造函数的参数传入进来的,Unique<T> ,并且它也不负责释放它所指向的内存。所以说它是智能指针都是抬举它了。
到目前为止,我们总算是搞明白了 RawVec<T> 的结构体定义了。
pub struct RawVec<T, A: AllocRef = Global> {ptr: Unique<T>, // 指向它所管理的那块内存的首地址的一个指针cap: usize, // 已分配的内存的大小alloc: A, // 分配内存使用的分配器}
RawVec 的构造
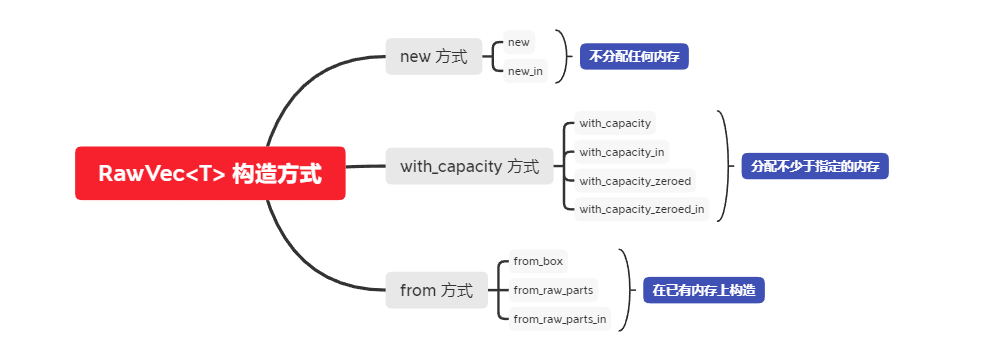
它的构造主要分为三种,一是不指定需要分配的容量大小;二是指定需要分配的容量大小;三是通过已分配好的内存容量直接构造。
第一种方式的构造方法主要是 new() 和 new_in(alloc: A),区别在于 new() 使用的是默认的 Global 分配器;而 new_in(alloc: A) 的话,调用者需要自己决定使用哪种分配器。
impl<T> RawVec<T, Global> {pub const fn new() -> Self {Self::new_in(Global)}...}...impl<T, A: AllocRef> RawVec<T, A> {pub const fn new_in(alloc: A) -> Self {Self { ptr: Unique::dangling(), cap: 0, alloc }}...}...
有了前面对 Unique<T> 的了解,从这里我们可以看到这种方式构造出的 RawVec<T> 并没有在堆上分配任何内存,它内部的指针指向的内存地址只是 Unique::dangling 的返回的地址,容量的大小也还是 0 。
第二种方式的构造方法主要是 with_capacity(cap: usize)、with_capacity_zeroded(cap: usize), 以及对应的带 _in 后缀的版本,和前面的 new 构造方式之间的差别一样,不带 _in 后缀的版本使用默认的分配器,带 _in 后缀的使用传入的分配器。这几个函数最终都是通过 allocate_in() 这个函数来分配内存的,所以我们直接看 allocate_in() 这个函数就好。
fn allocate_in(capacity: usize, init: AllocInit, mut alloc: A) -> Self {/// 参数说明:/// capacity: 需要分配的容量大小/// init: 内存分配时,如何进行初始化话,目前它只能是 Uninitialized 或 Zeroed/// alloc: 内存分配器///if mem::size_of::<T>() == 0 {Self::new_in(alloc)} else {let layout = match Layout::array::<T>(capacity) {Ok(layout) => layout,Err(_) => capacity_overflow(),};match alloc_guard(layout.size()) {Ok(_) => {}Err(_) => capacity_overflow(),}let memory = match alloc.alloc(layout, init) {Ok(memory) => memory,Err(_) => handle_alloc_error(layout),};Self {ptr: unsafe { Unique::new_unchecked(memory.ptr.cast().as_ptr()) },cap: Self::capacity_from_bytes(memory.size),alloc,}}}
函数中第一行先判断了一下当前类型 T 的字节大小,如果是零大小的类型,就直接调用 new_in() 函数,并不需要分配任何内存;否则就继续下面的。
下面的那段代码则是使用 Layout::array::<T>(capacity) 函数构建了一个用来描述如何在堆上申请一块可以容纳 capacity 个 T 类型数据的连续内存的 Layout 对象,失败则直接进行 panic 处理。
let layout = match Layout::array::<T>(capacity) {Ok(layout) => layout,Err(_) => capacity_overflow(), // 内部直接调用 panic 函数};
再之后的 alloc_guard() 部分则是对需要分配的内存大小进一步检查。
fn alloc_guard(alloc_size: usize) -> Result<(), TryReserveError> {if mem::size_of::<usize>() < 8 && alloc_size > isize::MAX as usize {// 这里表示对于 32 为一下的系统,分配的内存若超过 4GB 则发生内存溢出错误Err(CapacityOverflow)} else {Ok(())}}
可以看到对于64-位系统来说,它是直接返回 Ok(()) 的,因为 Rust 中从不会分配超过 isize::MAX 字节的内存对象。而对32-位和16-位做了一个额外的保护是以防运行的平台可能使用全部的 4GB 用户空间。
再之后就是使用分配器按照 Layout 指定的布局方式进行内存分配。分配成功之后则返回一个 MemoryBlock 对象,否则进入 handle_alloc_error 进行错误处理。
// layout 指定了内存分配的大小,对齐方式等// init 表示如何对分配的内存进行初始化,比如 with_capacity_zeroed, 则会初始化为 0let memory = match alloc.alloc(layout, init) {Ok(memory) => memory,Err(_) => handle_alloc_error(layout),};
然后进行最后一步,返回构造完成的 RawVec 对象;
Self {// 把已分配的内存块的首地址传入 Unique 中进行管理ptr: unsafe { Unique::new_unchecked(memory.ptr.cast().as_ptr()) },// 通过已分配内存块的总大小除于类型 T 的大小,得到 Vec 的容量。cap: Self::capacity_from_bytes(memory.size),alloc,}
第三种构造方式主要有 from_raw_parts(),from_box(),from_raw_parts_in(),因为这几种构造的内存都是外部传入的,不涉及到内存分配,所以没有什么需要特别说明的,下面代码展示了它们的实现。
/// `Box<[T]>` 到 `RawVec<T>` 的转换pub fn from_box(slice: Box<[T]>) -> Self {unsafe {let mut slice = ManuallyDrop::new(slice);RawVec::from_raw_parts(slice.as_mut_ptr(), slice.len())}}pub unsafe fn from_raw_parts(ptr: *mut T, capacity: usize) -> Self {unsafe { Self::from_raw_parts_in(ptr, capacity, Global) }}pub unsafe fn from_raw_parts_in(ptr: *mut T, capacity: usize, a: A) -> Self {Self { ptr: unsafe { Unique::new_unchecked(ptr) }, cap: capacity, alloc: a }}
看完它的构造过程,其实前面的第一个问题我们就已经知道答案了。
RawVec<T> 有哪些构造方式?它的默认构造会分配多大的内存?
RawVec
主要有三种类型的构造方式,一是默认的构造,不分配任何的内存块,二是指定需要内存容量的构造,会分配不少于指定容量的内存块,三是在已有的内存块上进行构造。
RawVec 的扩容
一块内存分配好之后这块内存的大小就确定下来了。但是随着程序的运行,我们很有可能会一直往里面添加新的数据,当添加的数据已经填满那块内存的容量时,再添加数据就需要先对原来那块内存进行扩容操作了。 RawVec 的扩容操作位于 grow_amortized 函数。
fn grow_amortized(&mut self, len: usize, additional: usize) -> Result<(), TryReserveError> {/// 参数说明:/// len: 当前已使用的单位内存块数量/// additional: 新增的单位内存块数量///debug_assert!(additional > 0);if mem::size_of::<T>() == 0 {return Err(CapacityOverflow);}let required_cap = len.checked_add(additional).ok_or(CapacityOverflow)?;let cap = cmp::max(self.cap * 2, required_cap);let elem_size = mem::size_of::<T>();let min_non_zero_cap = if elem_size == 1 {8} else if elem_size <= 1024 {4} else {1};let cap = cmp::max(min_non_zero_cap, cap);let new_layout = Layout::array::<T>(cap);let memory = finish_grow(new_layout, self.current_memory(), &mut self.alloc)?;self.set_memory(memory);Ok(())}
函数首先断言了新增的大小应该大于 0,然后判断内部保存的类型大小是否为0,若为零大小类型,调用此函数则直接报 CapacityOverflow 错误,因为对于零大小类型的容量已经是 usize::MAX 了。
随后部分主要确定扩容之后的容量的大小是多少。
let required_cap = len.checked_add(additional).ok_or(CapacityOverflow)?;// self.cap * 2 保证不会溢出,因为 cap 的值绝对小于 isize::MAX,但 cap 的类型是 usize::MAX。let cap = cmp::max(self.cap * 2, required_cap);// 下面这部分是保证新增的容量不至于太小,这样也会影响性能。// 下面这部分是保证至少可以扩容 8 字节。let elem_size = mem::size_of::<T>();let min_non_zero_cap = if elem_size == 1 {8} else if elem_size <= 1024 {4} else {1};let cap = cmp::max(min_non_zero_cap, cap);// 扩容后新的 Layoutlet new_layout = Layout::array::<T>(cap);let memory = finish_grow(new_layout, self.current_memory(), &mut self.alloc)?;// 把扩容后的内存块 memory 设置到 RawVec 中self.set_memory(memory);
看到这里对于我们的第二个问题也就知道答案了。
RawVec<T> 的扩容机制是怎样的?也就是每次扩容的时候会扩大容量?
总结下来就是,它的扩容策略是这样的:首先是按原本容量的两倍进行扩容,若原本容量的两倍不能满足要求,则按请求新增的容量大小进行扩容,也就是以请求的为准,并且保证每次扩容的字节不少于 8 字节。
确定扩容后的容量大小之后就是对内存块实际进行扩容操作了。
fn finish_grow<A>(new_layout: Result<Layout, LayoutErr>,current_memory: Option<(NonNull<u8>, Layout)>,alloc: &mut A,) -> Result<MemoryBlock, TryReserveError>whereA: AllocRef,{/// 参数说明:/// new_layout: 新的需要分配的内存块的 Layout 描述对象/// current_memory: 当前已分配的内存块的首地址和其 Layout 描述对象的元组/// alloc: 内存分配器///let memory = if let Some((ptr, old_layout)) = current_memory {unsafe { alloc.grow(ptr, old_layout, new_layout.size(), MayMove, Uninitialized) }} else {alloc.alloc(new_layout, Uninitialized)}.map_err(|_| AllocError { layout: new_layout, non_exhaustive: () })?;Ok(memory)}
可以看到,如果当前的内存块是合法的,则会通过 grow() 函数直接在当前内存块进行扩展,否则就通过 alloc() 函数重新分配对应大小的内存块。
RawVec 的析构
我们知道 Rust 是没有析构函数这个概念了,Rust 是通过 Drop trait 来实现 C++ 中析构函数的功能的,所以我们想要了解 RawVecDrop 实现就好了,如下:
unsafe impl<#[may_dangle] T, A: AllocRef> Drop for RawVec<T, A> {/// Frees the memory owned by the `RawVec` *without* trying to drop its contents.fn drop(&mut self) {if let Some((ptr, layout)) = self.current_memory() {unsafe { self.alloc.dealloc(ptr, layout) }}}}
可以看到,RawVec<T> 只负责释放它自己分配的那块内存,至于那块内存中保存的数据,它是不负责释放的,这些数据需要 RawVec<T> 的用户自己去释放。这也就是前面第四个问题的答案了。
都看到这了,输出不易,读完若有收到请多多打赏~~~赠人玫瑰~手留余香~

若有收获,就点个赞吧
0 人点赞
