对于平常的应用程序开发来说,我们都很少关注程序的编译链接过程,对于使用 IDE 的人来说都是一个 build 按钮就把编译和链接的过程一步完成了。即使是使用命令行手动编译,简单的一句"gcc main.c"也包含了复杂的过程。
从源程序到可执行文件
了解这背后的具体编译过程更有助于我们在遇到各种编译错误的时候分析问题的本质,快速定位解决问题。下面我们就以经典的入门程序来一步步探索背后被隐藏的编译过程。力图还原案件背后那不为人知的真相……
假设我们有一个如下的程序,名称是 hello.c。
#include <stdio.h>/** 这是块注释*/int main() {// 这是行注释printf("hello world!\n");return 0;}
然后我们在 hello.c 文件所在的目录下通过命令行执行 gcc hello.c 命令,查看当前目录下,会生成一个 a.out 的可执行文件,通过 ./a.out 运行该可执行文件,程序正常输出 "hello wolrd!" 字符串。如下是我这边的执行结果。
zmant@PC-201807220249:~/test$ gcc hello.czmant@PC-201807220249:~/test$ ./a.outhello world!zmant@PC-201807220249:~/test$
其实上面 gcc hello.c 这个简单的命令总共包含了四个步骤:预处理,编译,汇编,链接。
下面我们就分别从这个四个步骤深入了解源代码文件到可执行文件之间都经历了些什么。
预处理
首先第一步就是要先对源代码进行预处理,预处理过程主要的工作就是处理那些源码代码文件中以 "#" 开头的预编译指令,比如 #include, #if, #define 等,预处理后的文件扩展名一般是 .i ,对应的预处理的指令:
gcc -E hello.c -o hello.i或者cpp hello.c -o hello.i
预处理的一些规则如下:
- 删除所有的注释
- 展开所有
#define宏定义 - 处理所有的条件预编译指令,比如
#if, #ifdef, #elif, #else, #endif - 递归的处理所有的
#include预编译指令,将被包含的文件插入到该预编译指令的位置 - 添加行号和文件名标志,比如
# 2 "hello.c" 2,便于编译器产生调试信息或错误警告 - 保留所有的
#pragram编译指令,因为编译指令需要编译器处理
通过 file hello.i 命令我们可以看到预处理后的 .i 文件其实还是一个源程序文件,一个文本文件。使用编辑器打开它可以看到预处理后的文件有 799 行之多,原因其实在于程序的第一行 #include <stdio.h>,这条预编译指令递归的把 stdio.h 这个文件中的所有内容都插入到 hello.i 这个文件中来了,其实里面的很多内容对于我们这个程序来说都是多余的,因为我们只用到了里面的 printf 这个函数而已。
因此如果我们把第一行去掉之后再进行预处理,得到的 .i 文件就只有短短的 15 行了。
# 1 "hello.c"# 1 "<built-in>"# 1 "<command-line>"# 31 "<command-line>"# 1 "/usr/include/stdc-predef.h" 1 3 4# 32 "<command-line>" 2# 1 "hello.c"int main() {printf("hello world!\n");return 0;}
当然这个文件直接用在后面的编译过程是会出错的,因为它找不到 printf 这个函数的声明,这里只是拿来展示一下预处理后的文件样式。
编译
预处理完成之后,就来到了整个程序构建过程中最核心也是最复杂的部分—编译。编译就是把预处理后的文件进行 词法分析,语法分析,语义分析,源代码优化,目标代码生成 以及 目标代码优化 之后产生汇编代码文件的过程。这部分内容涉及到编译原理的知识,这里先一笔带过,稍后会对再这部分会做一些简单的介绍。
利用我们刚刚生成的预处理后的文件 hello.i,使用 gcc 对应编译的指令:gcc -S hello.i -o hello.s,也可以直接对 C/C++ 源程序使用如上指令:gcc -S hello.c -o hello.s。同样通过 file hello.s 命令可以看到生成的文件是一个汇编源程序文件,也是一个文本文件,内容如下:
.file "hello.c".text.section .rodata.LC0:.string "hello world!".text.globl main.type main, @functionmain:.LFB0:.cfi_startprocpushq %rbp.cfi_def_cfa_offset 16.cfi_offset 6, -16movq %rsp, %rbp.cfi_def_cfa_register 6leaq .LC0(%rip), %rdicall puts@PLTmovl $0, %eaxpopq %rbp.cfi_def_cfa 7, 8ret.cfi_endproc.LFE0:.size main, .-main.ident "GCC: (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0".section .note.GNU-stack,"",@progbits
汇编
汇编就是将编译生成的汇编代码转变成机器可以执行的指令,每一个汇编指令都对应一条机器指令。所以汇编的过程相对来说比较简单,没有复杂的语法,语义分析,也没有代码优化等。它仅仅只是根据汇编指令和机器指令的映射表依次翻译就可以了。
汇编对应的指令为:gcc -C hello.s -o hello.o 或者 as hello.s -o hello.o 。到目前为止,生成的文件就不再是文本文件了,也就是你无法再通过编辑器来查看生成的内容了。比如我们通过 file hello.o 可以看到如下内容:
zmant@PC-201807220249:~/test$ file hello.ohello.o: ELF 64-bit LSB shared object, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2, for GNU/Linux 3.2.0, BuildID[sha1]=4929e517885a8ac7ff58da69b24c00d8d5622654, not stripped
链接
链接通常都是一个让人比较费解的过程,为什么汇编的时候不直接生成可执行文件而是输出一个目标文件呢?链接的过程主要做了什么呢?
这其中一个主要的原因就是模块化。比如说要是没有链接这个过程,那对于一个大型程序来说,可能所有的功能模块都需要写在一个文件里面,那这个文件可能得有上百万行,对于这么大的一个文件维护的时候那简直是地狱难度的。也正是因为模块化的原因,现代计算机软件才能如此丰富。
到这里,我们终于可以使用 ld 链接器来手动产生一个可以运行的 a.out 程序了。如下:
zmant@PC-201807220249:~/test$ ld -static /usr/lib/x86_64-linux-gnu/crt1.o /usr/lib/x86_64-linux-gnu/crti.o /usr/lib/gcc/x86_64-linux-gnu/7/crtbeginT.o -L/usr/lib -L/lib -L/usr/lib/x86_64-linux-gnu hello.o --start-group -lgcc -lgcc_eh -lc --end-group -lgcc /usr/lib/gcc/x86_64-linux-gnu/7/crtend.o /usr/lib/x86_64-linux-gnu/crtn.ozmant@PC-201807220249:~/test$zmant@PC-201807220249:~/test$ ./a.outhello world!zmant@PC-201807220249:~/test$
看到这里,可能会有更多的疑惑了,crt1.o, crti.o, crtbeginT.o -lgcc, -lc 这都是些什么文件?为什么要把他们和 hello.o 链接起来程序才能正常运行呢?在分析这些问题之前,还是先简单介绍一下编译器是什么以及它做了些什么。
编译器都做了些什么
从最直观的角度讲,编译器就是将高级语言转变成底层机器指令的工具。之所以有这个转换的需求是因为高级语言是面向程序员的,人类更容易理解的,而底层机器指令是面向计算机硬件的,底层硬件能够识别处理的。比如面向某一种 CPU 编写的底层机器指令对另一种 CPU 来说可能就完全无法运行,需要完全重写才行。这当然是无法接受的,所以才有了高级语言,高级语言和底层硬件就完全是解耦的,高级语言编写完成之后只需要在不同的 CPU 指令架构下重新编译一下可以运行了。所以从这个角度讲,编译器就是位于高级语言和底层机器指令之间的一层抽象。
前面讲了,编译过程一般可以分为 6 步:词法分析,语法分析,语义分析,源代码优化,目标代码生成,目标代码优化。
根据产生的结果是否和机器有关,编译过程可以分为前端和后端两部分,编译器前端负责产生机器无关的中间代码,编译器后端负责产生和目标机器相关的代码。
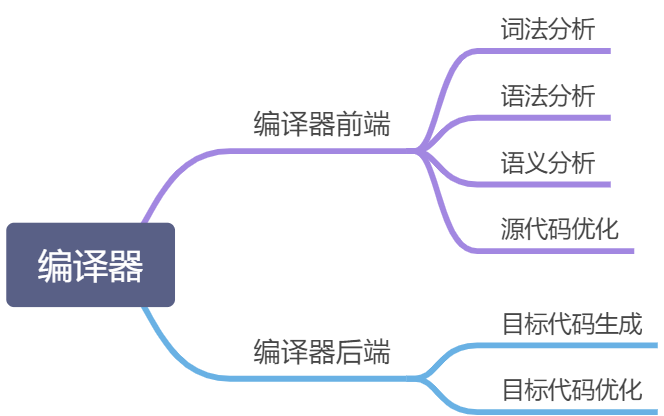
词法分析
我们就以如下的一段 C/C++ 代码为例来介绍整个过程。
arr[ idx ] = ( idx + 4 ) * ( 2 + 8 );
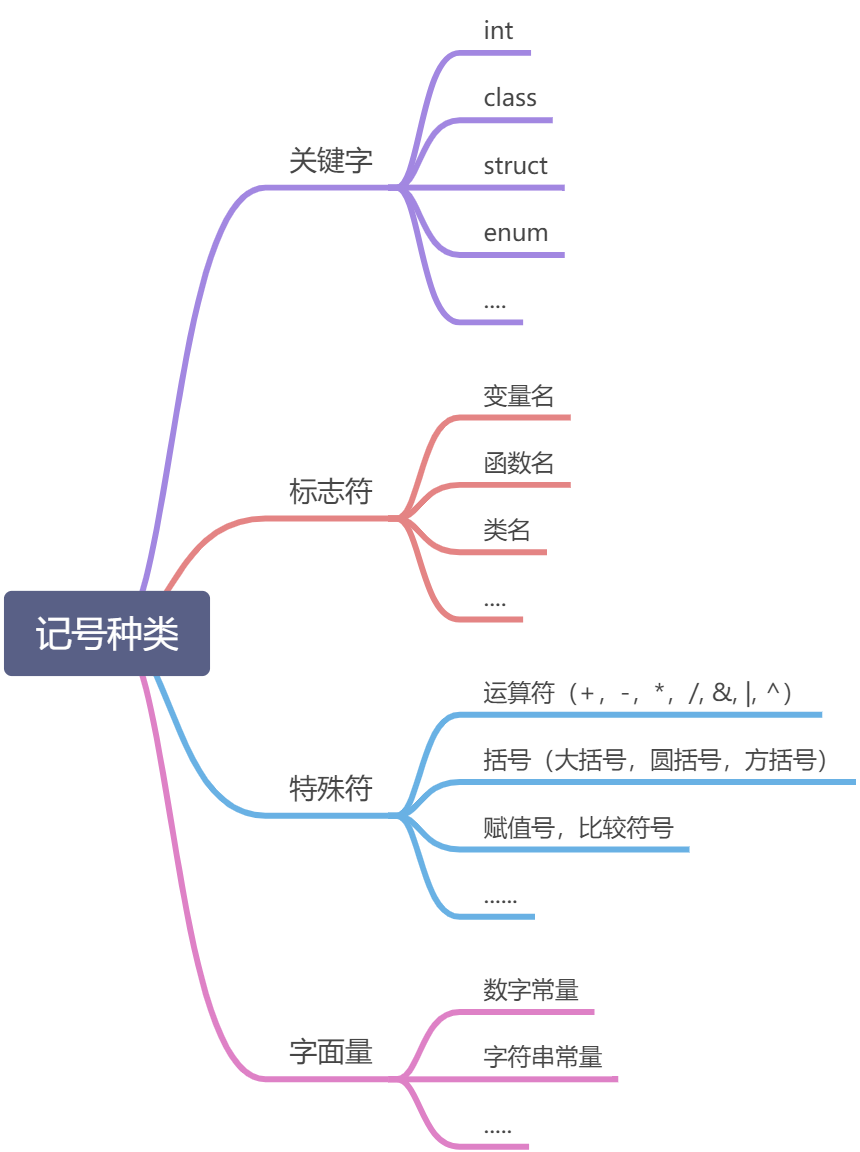
首先,源代码程序会先被输入到扫描器,扫描器的工作只是简单的进行词法分析,运用类似于有限状态机的算法可以很轻松的将源码的字符序列分割成一系列的记号(Token)。比如上面的程序经过扫描器之后被分割成下表:
| 记号 | 类型 |
|---|---|
| arr | 标志符 |
| [ | 左方括号 |
| idx | 标志符 |
| ] | 右方括号 |
| = | 赋值号 |
| ( | 左圆括号 |
| idx | 标志符 |
| + | 加号 |
| 4 | 数字常量 |
| ) | 右圆括号 |
| * | 乘号 |
| ( | 左圆括号 |
| 2 | 数字常量 |
| + | 右圆括号 |
| 6 | 数字常量 |
| ) | 右圆括号 |
词法分析产生的记号一般可以分为几类:关键字,标志符,字面量和特殊符号。
语法分析
前面词法分析部分就相当于是把一个句子分割成一个个单词,从而先判断这些分割后的单词是否合法。接下来的语法分析器的工作就是对前面产生的记号进行语法上的分析,从而产生语法树,简单的讲,语法树就是以表达式为节点的树。整个分析过程采用了上下文无关语法的分析手段。
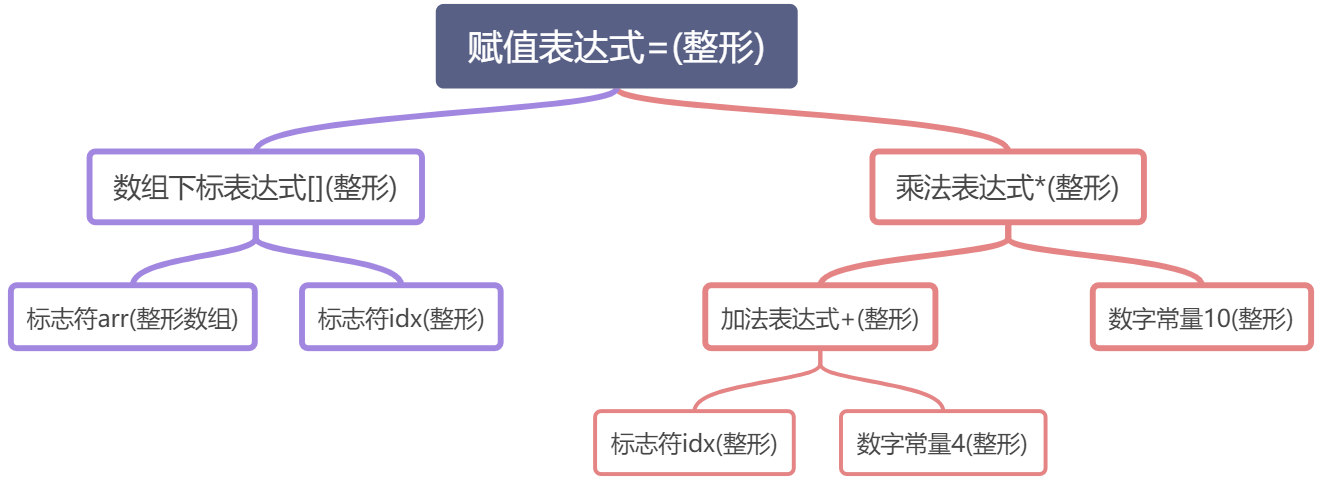
比如上面的那一行代码其实就是一个由赋值表达式,加法表达式,乘法表达式,数组表达式,括号表达式组成的一个复杂语句。它的语法树如下:
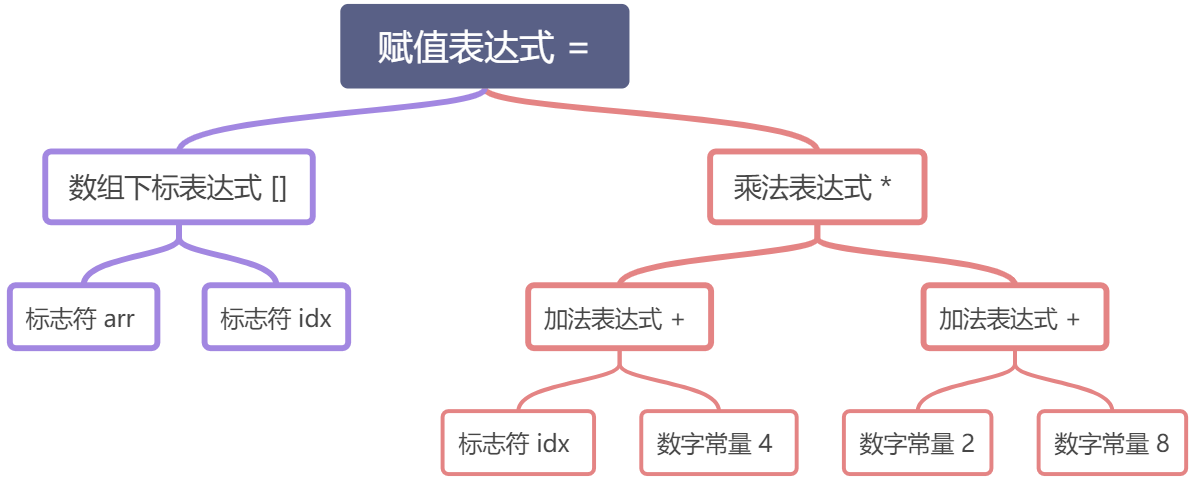 可以看到,整个语句被看作一个赋值表达式,赋值表达式左边是一个数组下标表达式,右边是一个乘法表达式;数组下标表达式又由两个符号表达式组成,等等。符号和数字是最小的表达式,它们不是由其他表达式组成的,所以它们通常都作为语法树的叶节点。
可以看到,整个语句被看作一个赋值表达式,赋值表达式左边是一个数组下标表达式,右边是一个乘法表达式;数组下标表达式又由两个符号表达式组成,等等。符号和数字是最小的表达式,它们不是由其他表达式组成的,所以它们通常都作为语法树的叶节点。
语义分析
再接下来就是语义分析,语法分析仅仅完成了对表达式的语法层面的分析,但它并不了解整个语句是否真正有意义。比如对两个指针做乘法是没有意义的,但在语法层面是合法的。编译器所能分析的语义是静态语义,也就是在编译期可以确定的语义,与之对应的是动态语义就只能在程序运行期才能确定的语义,比如除 0 是不合法的,是没有意义的,但它只能在运行期确认。
静态语义通常包括申明和类型的匹配,类型的转换等。比如,当一个浮点数被赋值给一个整型的时候,语义分析会发现这个类型不匹配需要报错(比如 Rust)或者做一个浮点数到整形的隐士类型转换工作(比如 C/C++ )。经过语义分析之后,整个语法树的表达式都会被标志了类型,若需要做隐士转换,语义分析程序会在语法树中对应节点插入相应的转换节点。
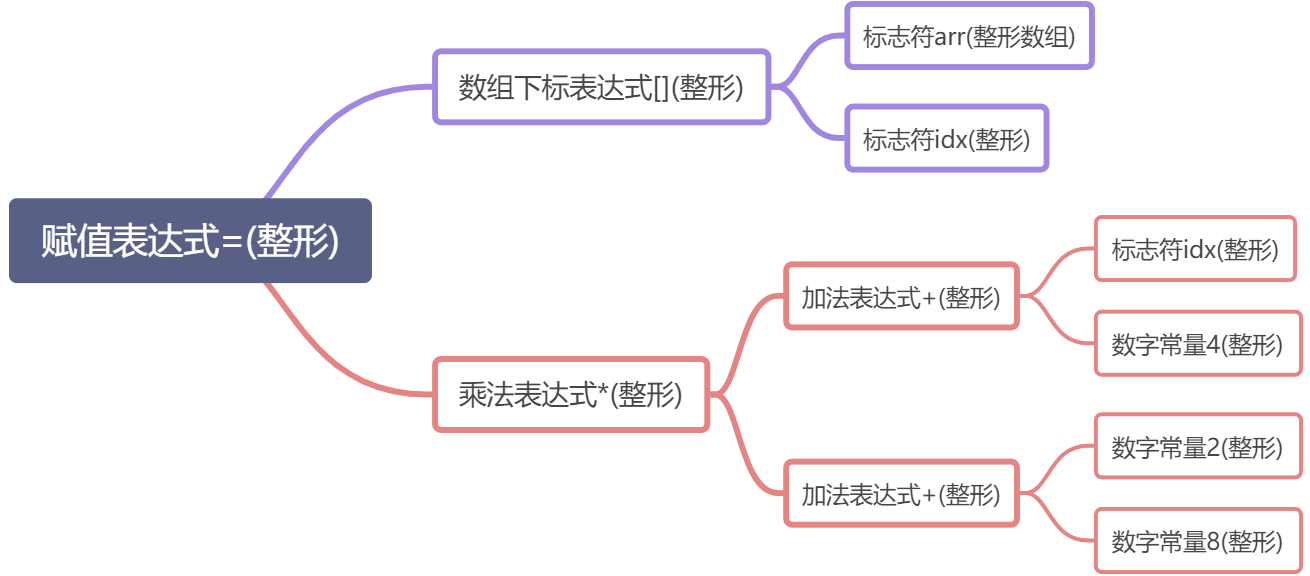
源代码优化
编译器发展到现在,已经具备了很多层次优化,这里语义分析完成之后往往就会有一个优化过程,这就是源代码优化器实现的,比如,上面的 2+8 这个加法表达式就可以被优化掉,因为这个表达式的值在编译期就可以被确定。类似的还有其他很多复杂的优化,比如去除多余的中间变量,不影响最终结果的前提下重新排列各个表达式的顺序等。
源代码优化后的语法树如上,可以看到 2+8 这个加法表达式被优化成 一个 数字常量表达式 10。
 其实直接在语法树上做优化是比较困难的,所以一般源代码优化器往往将整个语法树转换成中间代码,其实就是语法树的顺序表示,它已经非常接近目标代码了,不过它一般是跟目标机器和运行时环境无关的,比如,中间代码并不会包含数据的尺寸,变量地址和寄存器的名字等。
其实直接在语法树上做优化是比较困难的,所以一般源代码优化器往往将整个语法树转换成中间代码,其实就是语法树的顺序表示,它已经非常接近目标代码了,不过它一般是跟目标机器和运行时环境无关的,比如,中间代码并不会包含数据的尺寸,变量地址和寄存器的名字等。
中间代码有多重类型,常见的有:三地址码 和 P-码。
中间代码使得编译器可以分为前端和后端。编译器前端负责产生和机器无关的中间代码,编译器后端负责将中间代码转成目标机器代码。
目标代码生成和优化
源代码优化器产生了中间代码之后,下面的过程就属于编译器后端的了,主要包括目标代码生成器和目标代码优化器。这两个过程都十分依赖于目标机器,因为不同机器有着不同的字长,寄存器,各种数据类型等。
经过这一系列的步骤之后,源代码终于被编译成了目标代码。但是这个目标代码中有一个问题是:arr 和 idx 的地址还没有确定。如果 arr 和 idx 的定义和上面那段代码在同一个编译单元里面,那么编译器可以为 arr 和 idx 分配正确的空间,但如果是定义在其他模块呢?
事实上,定义在其他模块的全局变量和函数在最终运行时的绝对地址都要在最终链接的时候才能够确定下来。所以现代编译器可以将一个源代码文件编译成一个未链接的目标文件,然后由链接器最终将这些目标文件链接起来形成可执行文件。
链接器又是什么
前面简单提到了需要编译器的一个最主要的原因就是软件模块化的需求。为了更好的理解计算机程序的链接过程,我们简单的回顾计算机程序开发的历史一定会非常有益。
计算机程序开发并非从一开始就有着这么复杂的自动化编译,链接过程,原始的链接概念早在高级语言出现之前就已经存在了,最开始的时候,程序员先把一个程序写在纸上,用的都是机器语言,甚至连汇编语言都还没有。当程序需要运行时,程序员人工将他的程序写入到存储设备上,最原始的设备之一就是纸带,即在纸上打相应的孔。
比如,我们可以规定纸带上每一行有 8 个孔位,每个孔代表一位,穿孔表示 0,未穿孔表示 1。
假设有一种计算机,它的每条指令是一个字节,再假设它有一种跳转指令,它的高四位是 0001,表示是一个跳转指令,低四位存放的是跳转目的的绝对地址。有如下程序:
0 0001 01001 ...2 ...3 ...4 1000 01115 ...
它的第一条指令就是跳转指令,跳到绝对地址是 4 的地方,当时的程序再找来一条纸带把上面的程序按照 0 打孔,1 不打孔的方式输入到纸带上后放入计算机中运行即可。
但是问题很快就来了,程序并不是写好就永远不变的,它可能会经常被修改。比如我们在第一条指令之后,第五条指令之前插入一条或多条指令,那么插入指令之后的所有指令的绝对地址都会相应的往后移动,那么第一条指令的跳转目的地址就需要相应的做修改,在这个过程中,程序员需要人工重新计算每个子程序或跳转的目标地址然后再次找一个纸带输入上去,这显然是十分耗时又繁琐且容易出错的。这种重新计算各个目标地址的过程被叫做重定位。
如果我们有多条纸带的程序,这些程序之间可能会有类似跨纸带之间的跳转,这种情况下修改某一处指令导致的目标地址变化将更为严重,极端情况下可能会导致所有纸带都得重新计算目标地址再重新打孔,不仅繁琐还非常费纸,一点也不环保。
随着程序规模越来越大,这个问题就变得越来越严重。所以不堪忍受的先驱者发明了汇编语言,这相比机器语言是一个非常大的进步。汇编语言使用各种接近人类的语言符号来帮助记忆,比如,采用 jmp 比记住 0001XXXX 是跳转指令显然要容易的多。还可以使用符号来标记位置,使得人们从具体的指令地址中解放出来,比如前面的程序,我们把第 5 条开始的程序记作 foo,那么上面程序中第一条指令就是:jmp foo。
这样一来,不管这个 “foo” 之前插入或减少多少条指令导致 “foo”目标地址发生了变化,汇编器在每次汇编的时候回重新计算“foo”这个符号的地址,然后把所有引用到“foo”的指令都修正到这个正确的地址上,整个过程不再需要人工参与。符号这个概念就是随汇编语言的普及迅速被使用,它表示一个地址,这个地址可能是一段子程序的起始地址,也可以是一个变量的起始地址。
有了汇编之后,软件规模越来越大,把一个大规模的程序拆分成各个小模块就很有必要了,软件模块化使得代码更容易阅读,理解和重用,并且每个模块都可以单独开发,编译,测试,改变部分代码也不需要编译整个程序等。
软件拆分之后,各个模块之间如何通信就是一个需要解决的问题了。最常见的模块之间的通信有两种方式,一是模块间的函数调用,二是模块间的变量访问。其实这两种方式都是利用符号的地址进行的,所以其实可以归结为一种方式,就是模块间符号的引用。这种把源代码分别按照模块独立编译再根据需要组装起来的过程就是链接。
链接的主要内容就是把各个模块之间相互引用的部分处理好,使得各个模块间能够正确衔接;链接器的工作其实跟前面所描述的“程序员人工计算地址”本质上是一样的。只是现代高级语言的诸多特性使得链接器更为复杂,功能更为强大,但原理上无非就是把一些指令对其他符号地址的引用加以修正。
比如我们在程序模块 main.c 中使用另外一个模块 func.c 中的 foo 函数,我们在 main.c 模块中每一处调用 foo 的地方都必须确切知道 foo 这个符号的地址,但是由于每个模块都是单独编译的,在编译器编译 main.c 模块的时候它并不知道 foo 符号的地址,所以它暂时把这些调用到 foo 的指令的目标地址搁置,等待最后链接的时候由链接器将这些指令的地址修正。如果没有链接器,我们就必须手动修正每个调用到 foo 的指令,填入正确的 foo 符号地址。使用链接器之后,链接器就在你指定那些目标文件或库中进行查找,然后会在 func.c 模块中找到对应的 foo 符号的地址然后修正。
本文是看了《程序员的自我修炼——链接、装载与库》的笔记,这本我读起来非常不错,对于编译过程,编译后的目标文件的格式等都有做详细说明,推荐阅读。
整理不易~都看到这里,不打算打赏一下作者么~~

若有收获,就点个赞吧
0 人点赞
