一、序列模型
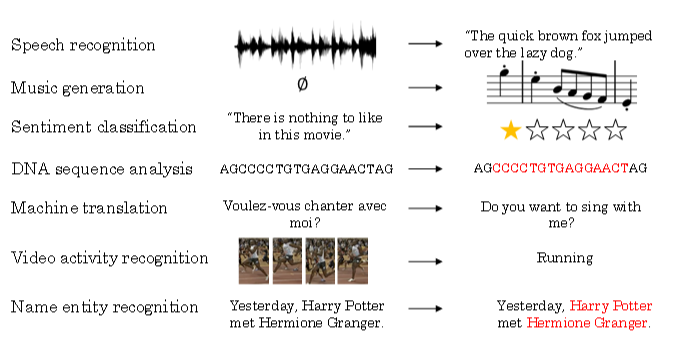
以命名实体识别为例,介绍序列模型的命名规则,示例:
Harry Potter and Hermione Granger invented a new spell.
该句话包含9个单词,输出y即为1 x 9向量,每位表征对应单词是否为人名的一部分,1表示是,0表示否。输出y为:
一般约定用 表示序列对应位置的输出,使用
表示序列对应位置的输出,使用 来表示输出序列的长度,输入同理
来表示输出序列的长度,输入同理
表示 的方法,先建立一个词汇库vocabulary,例如:
的方法,先建立一个词汇库vocabulary,例如:
使用one-hot编码,如果出现在词汇表之外的单词,可以用UNK或者其他字符表示
二、Recurrent Neural Network Model
结构
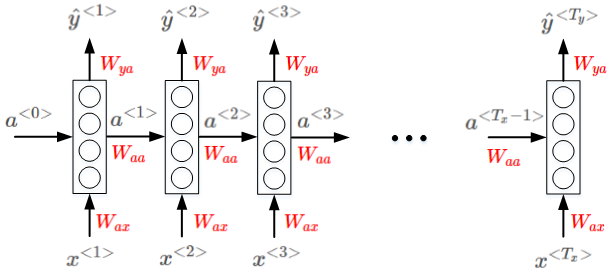
前向传播
RNN的正向传播(Forward Propagation)过程为:
反向传播

这种从右到左的求导过程被称为Backpropagation through time
三、Language model and sequence generation
语言模型是自然语言处理(NLP)中最基本和最重要的任务之一。使用RNN能够很好地建立需要的不同语言风格的语言模型。
什么是语言模型呢?举个例子,在语音识别中,某句语音有两种翻译:
- The apple and pair salad.
- The apple and pear salad.
很明显,第二句话更有可能是正确的翻译。语言模型实际上会计算出这两句话各自的出现概率。比如第一句话概率为 ,第二句话概率为
,第二句话概率为 。也就是说,利用语言模型得到各自语句的概率,选择概率最大的语句作为正确的翻译。概率计算的表达式为:
。也就是说,利用语言模型得到各自语句的概率,选择概率最大的语句作为正确的翻译。概率计算的表达式为:
首先,我们需要一个足够大的训练集,训练集由大量的单词语句语料库(corpus)构成。然后,对corpus的每句话进行切分词(tokenize)。做法就跟第2节介绍的一样,建立vocabulary,对每个单词进行one-hot编码。例如下面这句话:
The Egyptian Mau is a bread of cat.
每句话结束末尾,需要加上< EOS >作为语句结束符。另外,若语句中有词汇表中没有的单词,用< UNK >表示
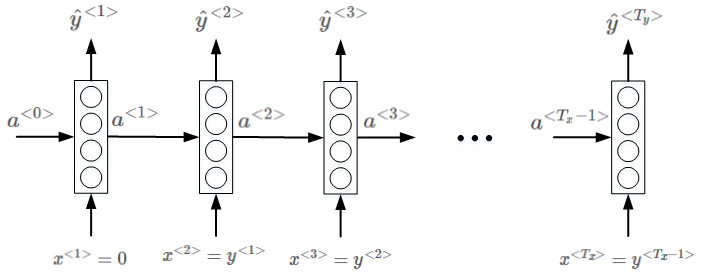
语言模型的RNN如图。Softmax输出层 表示出现该语句第一个单词的概率,softmax输出层y^<2>表示在第一个单词基础上出现第二个单词的概率,即条件概率,以此类推,最后是出现< EOS >的条件概率。
表示出现该语句第一个单词的概率,softmax输出层y^<2>表示在第一个单词基础上出现第二个单词的概率,即条件概率,以此类推,最后是出现< EOS >的条件概率。
单个元素的损失函数:
整个语句出现的概率等于语句中所有元素出现的条件概率乘积
以上介绍的是word level RNN,即每次生成单个word,语句由多个words构成。另外一种情况是character level RNN,即词汇表由单个英文字母或字符组成,如下所示:

Character level RNN与word level RNN不同的是,y^
四、Gated Recurrent Unit(GRU)
RNN的隐藏层单元结构如下图所示: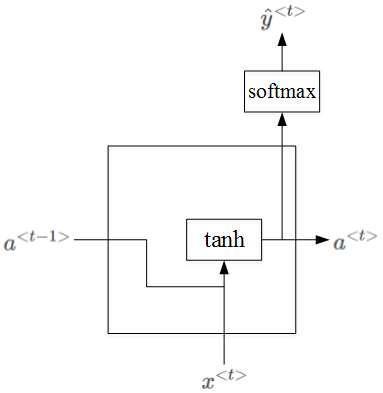

为了解决梯度消失问题,对上述单元进行修改,添加了记忆单元,构建GRU,如下图所示:
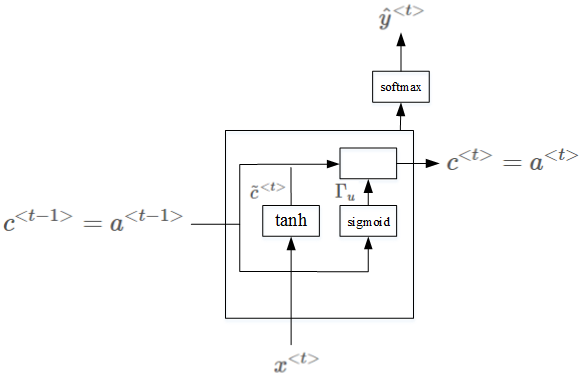
相应的表达式:
ΓuΓu意为gate,记忆单元。当Γu=1Γu=1时,代表更新;当Γu=0Γu=0时,代表记忆,保留之前的模块输出。这一点跟CNN中的ResNets的作用有点类似。因此,ΓuΓu能够保证RNN模型中跨度很大的依赖关系不受影响,消除梯度消失问题。
五、Long Short Term Memory(LSTM)
LSTM是另一种更强大的解决梯度消失问题的方法。它对应的RNN隐藏层单元结构如下图所示: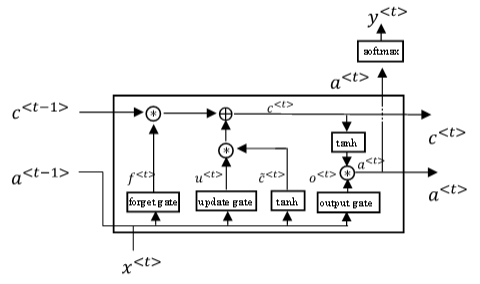

六、Bidirectional RNN
结构
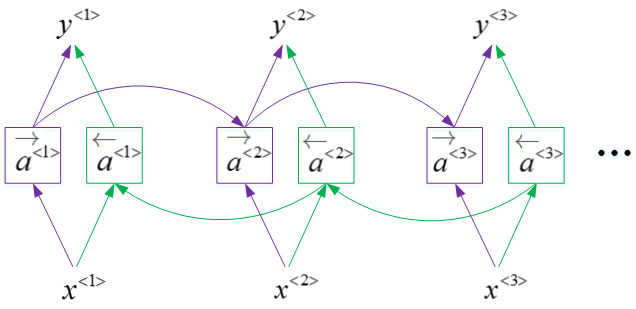
BRNN能够同时对序列进行双向处理,性能大大提高。但是计算量较大,且在处理实时语音时,需要等到完整的一句话结束时才能进行分析。

若有收获,就点个赞吧
0 人点赞
