一、Classic Networks
LeNet-5

该LeNet模型总共包含了大约6万个参数。值得一提的是,当时Yann LeCun提出的LeNet-5模型池化层使用的是average pool,而且各层激活函数一般是Sigmoid和tanh。现在,我们可以根据需要,做出改进,使用max pool和激活函数ReLU。
AlexNet
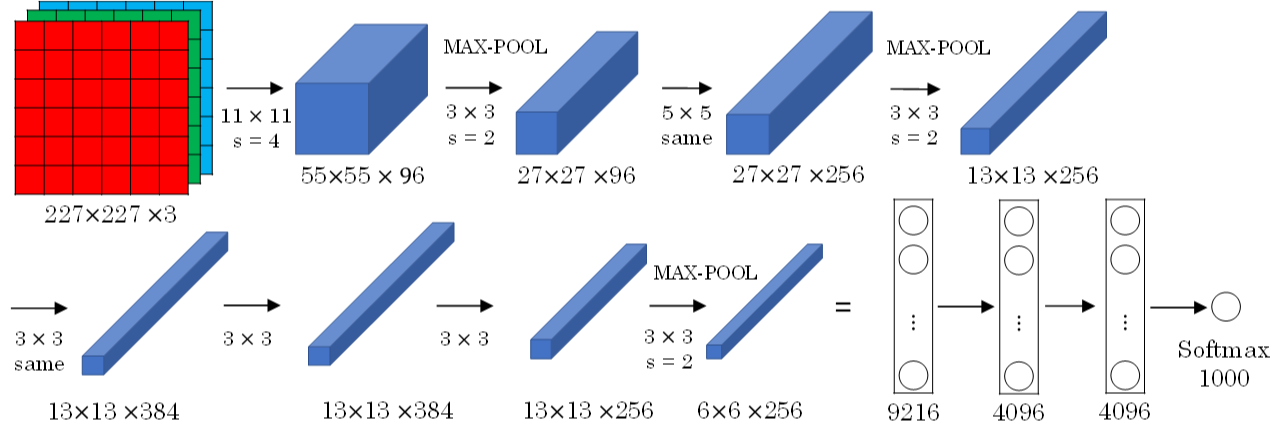
AlexNet模型与LeNet-5模型类似,只是要复杂一些,总共包含了大约6千万个参数。同样可以根据实际情况使用激活函数ReLU。原作者还提到了一种优化技巧,叫做Local Response Normalization(LRN)。 而在实际应用中,LRN的效果并不突出。
VGG-16
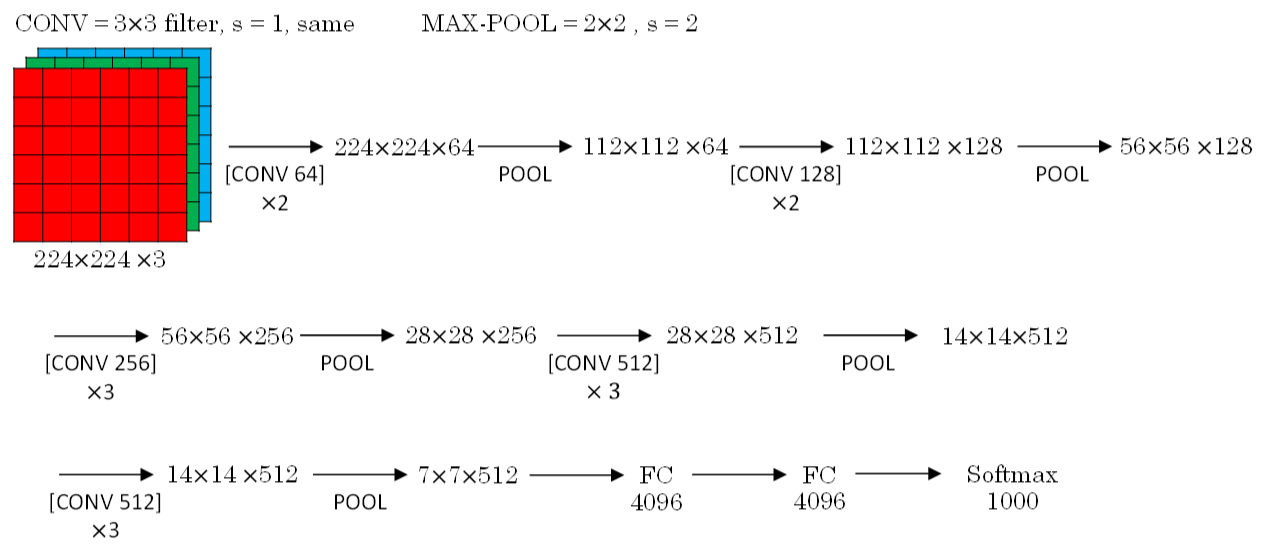
- CONV = 3x3 filters, s = 1, same
- MAX-POOL = 2x2, s = 2
二、ResNets
残差块
Residual Networks由许多隔层相连的神经元子模块组成,我们称之为Residual block。单个Residual block的结构如下图所示:
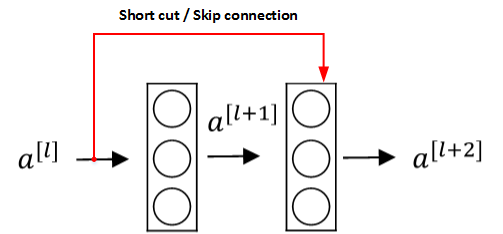

由多个Residual block组成的神经网络就是Residual Network。实验表明,这种模型结构对于训练非常深的神经网络,效果很好。另外,为了便于区分,我们把非Residual Networks称为Plain Network。
与Plain Network相比,Residual Network能够训练更深层的神经网络,有效避免发生发生梯度消失和梯度爆炸。
如果梯度消失, ,这就是identity function。从效果来说,相当于直接忽略了
,这就是identity function。从效果来说,相当于直接忽略了 之后的这两层神经层。这样,看似很深的神经网络,其实由于许多Residual blocks的存在,弱化削减了某些神经层之间的联系,实现隔层线性传递,而不是一味追求非线性关系,模型本身也就能“容忍”更深层的神经网络了。而且从性能上来说,这两层额外的Residual blocks也不会降低Big NN的性能。
之后的这两层神经层。这样,看似很深的神经网络,其实由于许多Residual blocks的存在,弱化削减了某些神经层之间的联系,实现隔层线性传递,而不是一味追求非线性关系,模型本身也就能“容忍”更深层的神经网络了。而且从性能上来说,这两层额外的Residual blocks也不会降低Big NN的性能。
如果Res block中a[l]和a[l+2]的唯独不同,通常引入矩阵
ResNet结构

三、Networks in Networks and 1x1 Convolutions
Min Lin, Qiang Chen等人提出了一种新的CNN结构,即1x1 Convolutions,也称Networks in Networks。这种结构的特点是滤波器算子filter的维度为1x1。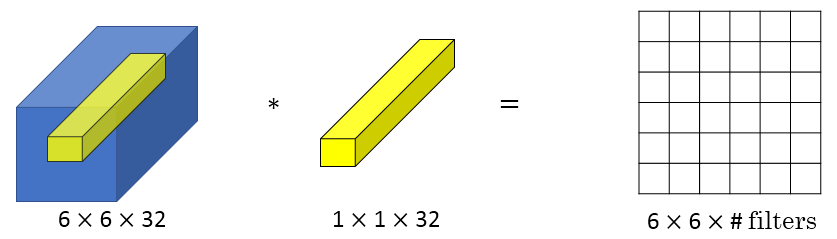
减少通道数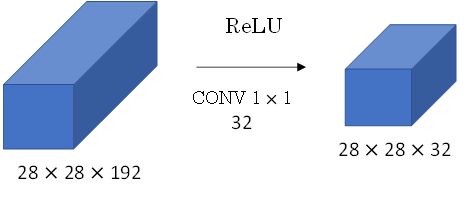
四、Inception Network
Inception Network在单层网络上可以使用多个不同尺寸的filters,进行same convolutions,把各filter下得到的输出拼接起来。除此之外,还可以将CONV layer与POOL layer混合,同时实现各种效果。但是要注意使用same pool。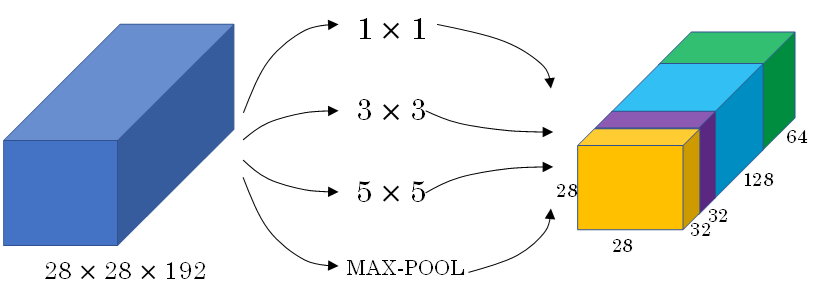
Inception Network在提升性能的同时,会带来计算量大的问题。例如下面这个例子: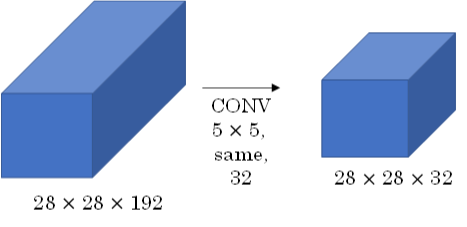
此CONV layer需要的计算量为:28x28x32x5x5x192=120m,我们可以引入1x1 Convolutions来减少其计算量,结构如下图所示: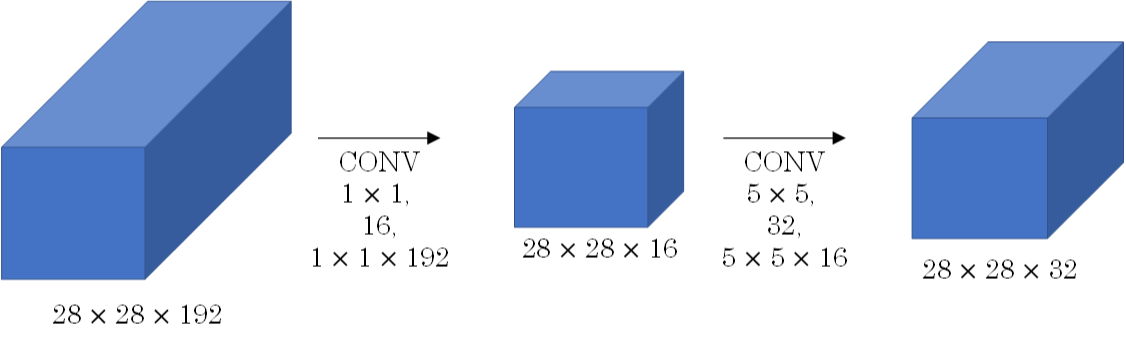
通常我们把该1x1 Convolution称为“瓶颈层”(bottleneck layer)。引入bottleneck layer之后,总共需要的计算量为:28x28x16x192+28x28x32x5x5x16=12.4m。明显地,虽然多引入了1x1 Convolution层,但是总共的计算量减少了近90%,效果还是非常明显的。
引入1x1 Convolution后的Inception module如下图所示: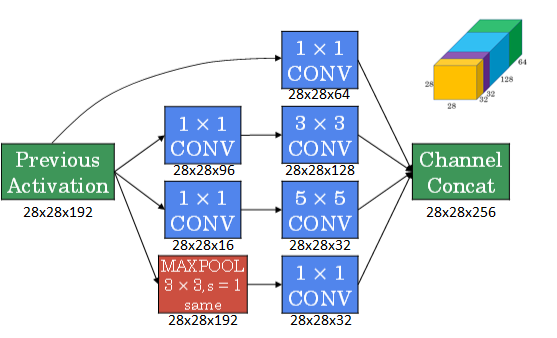
多个Inception modules组成Inception Network,效果如下图所示: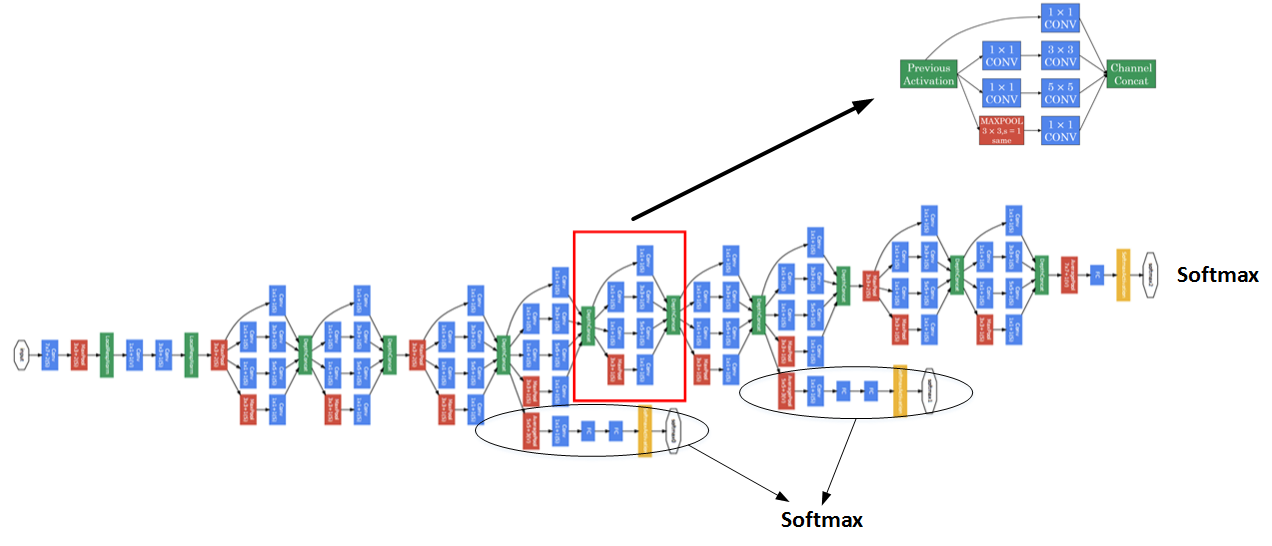

若有收获,就点个赞吧
0 人点赞
