一、Word Representation
我们可以使用**特征表征(Featurized representation)**的方法对每个单词进行编码。也就是使用一个特征向量表征单词,特征向量的每个元素都是对该单词某一特征的量化描述,量化范围可以是[-1,1]之间。特征表征的例子如下图所示:
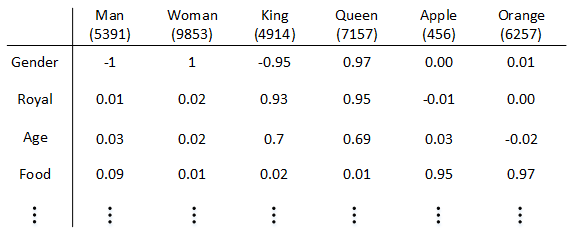
这种特征表征的优点是根据特征向量能清晰知道不同单词之间的相似程度,例如Apple和Orange之间的相似度较高,很可能属于同一类别。这种单词“类别”化的方式,大大提高了有限词汇量的泛化能力。这种特征化单词的操作被称为Word Embeddings,即单词嵌入。
在实际应用中,特征向量很多特征元素并不一定对应到有物理意义的特征,是比较抽象的。
每个单词都由高维特征向量表征,为了可视化不同单词之间的相似性,可以使用降维操作,例如t-SNE算法,将300D降到2D平面上。如下图所示: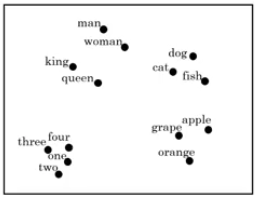
featurized representation的优点是可以减少训练样本的数目,前提是对海量单词建立特征向量表述(word embedding)。这样,即使训练样本不够多,测试时遇到陌生单词,例如“durian cultivator”,根据之前海量词汇特征向量就判断出“durian”也是一种水果,与“apple”类似,而“cultivator”与“farmer”也很相似。从而得到与“durian cultivator”对应的应该也是一个人名。这种做法将单词用不同的特征来表示,即使是训练样本中没有的单词,也可以根据word embedding的结果得到与其词性相近的单词,从而得到与该单词相近的结果,有效减少了训练样本的数量。
二、Properties of word embeddings
我们将“Man”的embedding vector与“Woman”的embedding vector相减:
类似地,我们将“King”的embedding vector与“Queen”的embedding vector相减:
相减结果表明,“Man”与“Woman”的主要区别是性别,“King”与“Queen”也是一样。
一般地,A类比于B相当于C类比于“?”,这类问题可以使用embedding vector进行运算。
根据 得
得 ,利用相似函数计算得出
,利用相似函数计算得出
关于相似函数,比较常用的是cosine similarity。
三、Learning word embeddings
Embedding matrix
假设某个词汇库包含了10000个单词,每个单词包含的特征维度为300,那么表征所有单词的embedding matrix维度为300 x 10000,用 来表示。某单词w的one-hot向量表示为
来表示。某单词w的one-hot向量表示为 ,维度为10000 x 1,则该单词的embedding vector表达式为:
,维度为10000 x 1,则该单词的embedding vector表达式为:

知道了,就能计算所有单词的embedding vector。可不作矩阵乘积,从中选取第w列即可。
word embeddings
的构建,举个简单的例子
I want a glass of orange (juice).
通过这句话的前6个单词,预测最后的单词“juice”。未知待求,每个单词可用embedding vector  表示。构建的神经网络模型结构如下图所示:
表示。构建的神经网络模型结构如下图所示:
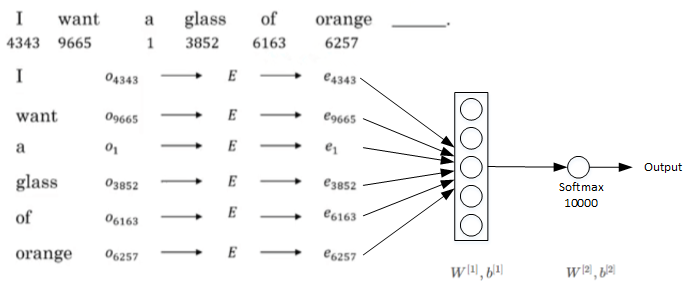
神经网络输入层包含6个embedding vactors,每个embedding vector维度是300,则输入层总共有1800个输入。Softmax层有10000个概率输出,与词汇表包含的单词数目一致。正确的输出label是“juice”。其中 为待求值。对足够的训练例句样本,运用梯度下降算法,迭代优化,最终求出embedding matrix 。
为待求值。对足够的训练例句样本,运用梯度下降算法,迭代优化,最终求出embedding matrix 。
为了让神经网络输入层数目固定,可以选择只取预测单词的前4个单词作为输入,例如该句中只选择“a glass of orange”四个单词作为输入。
一般地,我们把输入叫做context,输出叫做target。
关于context的选择有多种方法:
- target前n个单词或后n个单词,n可调
- target前1个单词
- target附近某1个单词(Skip-Gram)
四、Word2Vec
Skip-Gram模型
例:
I want a glass of orange juice to go along with my cereal.
Skip-Gram模型的做法是:首先随机选择一个单词作为context,例如“orange”;然后使用一个宽度为5或10(自定义)的滑动窗,在context附近选择一个单词作为target,可以是“juice”、“glass”、“my”等等。最终得到了多个context—target对作为监督式学习样本。
训练的过程是构建自然语言模型,经过softmax单元的输出为:

其中, 为target对应的参数,
为target对应的参数, 为content的embedding vector。
为content的embedding vector。
loss function:
这种算法计算量大,影响运算速度。主要因为softmax输出单元为10000个,y^计算公式中包含了大量的求和运算。解决的办法之一是使用hierarchical softmax classifier,即树形分类器。其结构如下图所示:
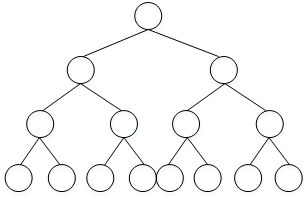
这种树形分类器是一种二分类。与之前的softmax分类器不同,它在每个数节点上对目标单词进行区间判断,最终定位到目标单词。这好比是猜数字游戏,数字范围0~100。我们可以先猜50,如果分类器给出目标数字比50大,则继续猜75,以此类推,每次从数据区间中部开始。这种树形分类器最多需要log Nlog N步就能找到目标单词,N为单词总数。
实际应用中,对树形分类器做了一些改进。改进后的树形分类器是非对称的,通常选择把比较常用的单词放在树的顶层,而把不常用的单词放在树的底层。这样更能提高搜索速度。
五、Negative Sampling

Negative sampling是另外一种有效的求解embedding matrix EE的方法。它的做法是判断选取的context word和target word是否构成一组正确的context-target对,一般包含一个正样本和k个负样本。
一般地,固定某个context word对应的负样本个数k一般遵循:
- 若训练样本较小,k一般选择5~20;
- 若训练样本较大,k一般选择2~5即可。

很明显,negative sampling某个固定的正样本对应k个负样本,即模型总共包含了k+1个binary classification。对比之前介绍的10000个输出单元的softmax分类,negative sampling转化为k+1个二分类问题,计算量要小很多,大大提高了模型运算速度。
选择负样本单词的方法,可以使用随机选取。一种更好的方法,更具该词出现的频率进行选择:
 表示单词
表示单词 在单词表中出现的概率
在单词表中出现的概率
六、GloVe word vectors
GloVe算法引入了一个新的参数:
 : 表示i出现在j之前的次数,即i和j同时出现的次数。
: 表示i出现在j之前的次数,即i和j同时出现的次数。
//TODO
看不懂了………….继续学习
七、Sentiment Classification
情感分类问题的一个主要挑战是缺少足够多的训练样本。而Word embedding恰恰可以帮助解决训练样本不足的问题。
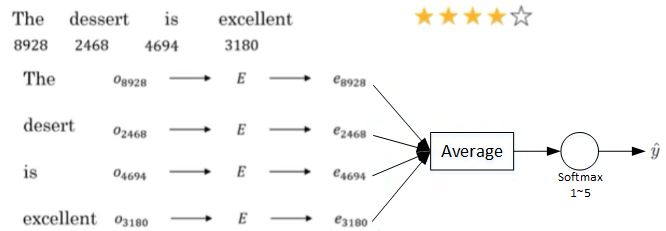
如上图所示,这句话的4个单词分别用embedding vector表示。e8928,e2468,e4694,e3180计算均值,这样得到的平均向量的维度仍是300。最后经过softmax输出1~5星。这种模型结构简单,计算量不大,不论句子长度多长,都使用平均的方式得到300D的embedding vector。该模型实际表现较好。
此种方式忽略了位置信息。
使用RNN
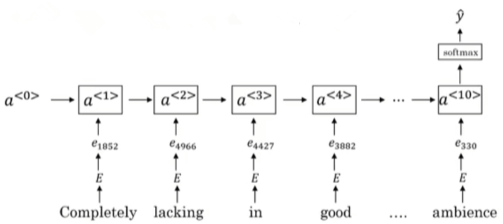
该RNN模型是典型的many-to-one模型,考虑单词出现的次序,能够有效识别句子表达的真实情感。
八、Debiasing word embeddings
以性别偏见为例,我们来探讨下如何消除word embeddings中偏见。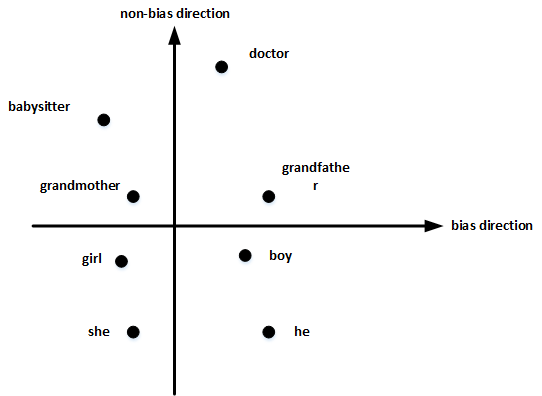
首先,确定偏见bias的方向。方法是对所有性别对立的单词求差值,再平均。上图展示了bias direction和non-bias direction。

然后,单词中立化(Neutralize)。将需要消除性别偏见的单词投影到non-bias direction上去,消除bias维度,例如babysitter,doctor等。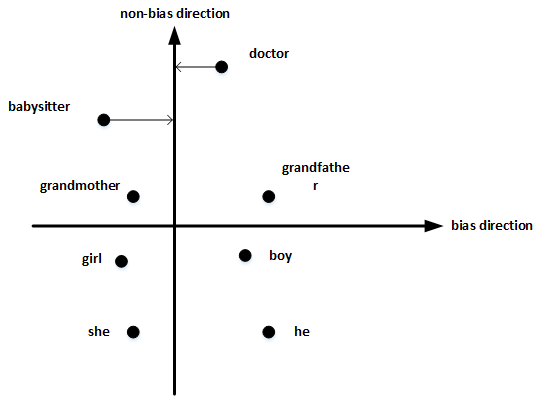
最后,均衡对(Equalize pairs)。让性别对立单词与上面的中立词距离相等,具有同样的相似度。例如让grandmother和grandfather与babysitter的距离同一化。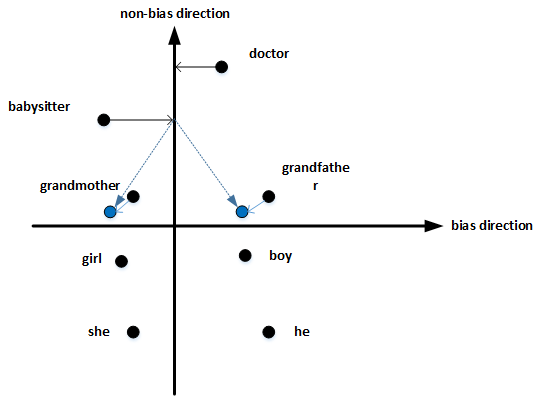
**
**

若有收获,就点个赞吧
0 人点赞
