简介
布隆过滤器(Bloom Filter,下文简称BF)由Burton Howard Bloom在1970年提出,是一种空间效率
高的概率型数据结构。它专门用来检测集合中是否存在特定的元素。听起来是很稀松平常的需求,为什
么要使用BF这种数据结构呢?
基本
假如数据库里面有1000条订单号,我如何快速的知道A订单号在当前数据库有没有这匹配的,我把这数据库的1000条数据直接做了一个散列值(hash),当然这1000条数据是不重复的,.
然后我把这散列值加载到布隆过滤器(布隆过滤器可以理解是一个简单的Map,Map存值的时候是用二进制的数据来存的)
二进制
0101在内存里面只占4个位置,然而0101可以表示16个订单号,假如说16个订单,我就可以直接用0101这四位的二进制存起来了,这样就大大的节省了我的内存.
这样的话我40个位置就能表示160个订单,400个位置就能1600个订单 ….
布隆过滤器是一个叫“布隆”的人提出的,它本身是一个很长的二进制向量,既然是二进制的向量,那么显而易见的,存放的不是0,就是1。
现在我们新建一个长度为16的布隆过滤器,默认值都是0,就像下面这样:

现在需要添加一个数据:
我们通过某种计算方式,比如Hash1,计算出了Hash1(数据)=5,我们就把下标为5的格子改成1,就像下面这样:

我们又通过某种计算方式,比如Hash2,计算出了Hash2(数据)=9,我们就把下标为9的格子改成1,就像下面这样:

还是通过某种计算方式,比如Hash3,计算出了Hash3(数据)=2,我们就把下标为2的格子改成1,就像下面这样:

这样,刚才添加的数据就占据了布隆过滤器“5”,“9”,“2”三个格子。
可以看出,仅仅从布隆过滤器本身而言,根本没有存放完整的数据,只是运用一系列随机映射函数计算出位置,然后填充二进制向量。
这有什么用呢?比如现在再给你一个数据,你要判断这个数据是否重复,你怎么做?
你只需利用上面的三种固定的计算方式,计算出这个数据占据哪些格子,然后看看这些格子里面放置的是否都是1,如果有一个格子不为1,那么就代表这个数字不在其中。
但是有一个问题需要注意,如果这些格子里面放置的都是1,不一定代表给定的数据一定重复,也许其他数据经过三种固定的计算方式算出来的结果也是相同的。
比如我们需要判断对象是否相等,是不可以仅仅判断他们的哈希值是否相等的。
也就是说布隆过滤器只能判断数据是否一定不存在,而无法判断数据是否一定存在。
按理来说,介绍完了新增、查询的流程,就要介绍删除的流程了,但是很遗憾的是布隆过滤器是很难做到删除数据的,为什么?
你想想,比如你要删除刚才给你的数据,你把“5”,“9”,“2”三个格子都改成了0,但是可能其他的数据也映射到了“5”,“9”,“2”三个格子啊,这不就乱套了吗?
布隆顾虑器优缺点
优点
由于存放的不是完整的数据,所以占用的内存很少,而且新增,查询速度够快;
不需要存储数据本身,只用比特表示,因此空间占用相对于传统方式有巨大的优势,并且能够保密数据;
时间效率也较高,插入和查询的时间复杂度均为O(k);
哈希函数之间相互独立,可以在硬件指令层面并行计算。
缺点
- 误差:
需要注意的是,布隆过滤器会有误差,在100万条数据的情况下,guava的布隆过滤器误差率为0.01.
这个问题是hash算法的问题,Hash算法难免有一定的碰撞几率,所谓碰撞,即不同的输入值得到相同的Hash结果.
不支持删除元素
只能插入和查询元素,不能删除元素
举个例子,假设两个元素A和B都是集合中的元素,具有相同的Hash值,会映射到数组相同的位置。此时如果删除A,数组中对应的位置从1变为-,那么在判断B的时候发现B不在集合中了,得到了错误的结论
使用场景
在实际工作中,布隆过滤器常见的应用场景如下:
- 网页爬虫对 URL 去重,避免爬取相同的 URL 地址;
- 反垃圾邮件,从数十亿个垃圾邮件列表中判断某邮箱是否垃圾邮箱;
- Google Chrome 使用布隆过滤器识别恶意 URL;
- Medium 使用布隆过滤器避免推荐给用户已经读过的文章;
- Google BigTable,Apache HBbase 和 Apache Cassandra 使用布隆过滤器减少对不存在的行和列的查找。
除了上述的应用场景之外,布隆过滤器还有一个应用场景就是解决缓存穿透的问题。所谓的缓存穿透就是服务调用方每次都是查询不在缓存中的数据,这样每次服务调用都会到数据库中进行查询,如果这类请求比较多的话,就会导致数据库压力增大,这样缓存就失去了意义。
利用布隆过滤器我们可以预先把数据查询的主键,比如用户 ID 或文章 ID 缓存到过滤器中。当根据 ID 进行数据查询的时候,我们先判断该 ID 是否存在,若存在的话,则进行下一步处理。若不存在的话,直接返回,这样就不会触发后续的数据库查询。需要注意的是缓存穿透不能完全解决,我们只能将其控制在一个可以容忍的范围内。
设计思想
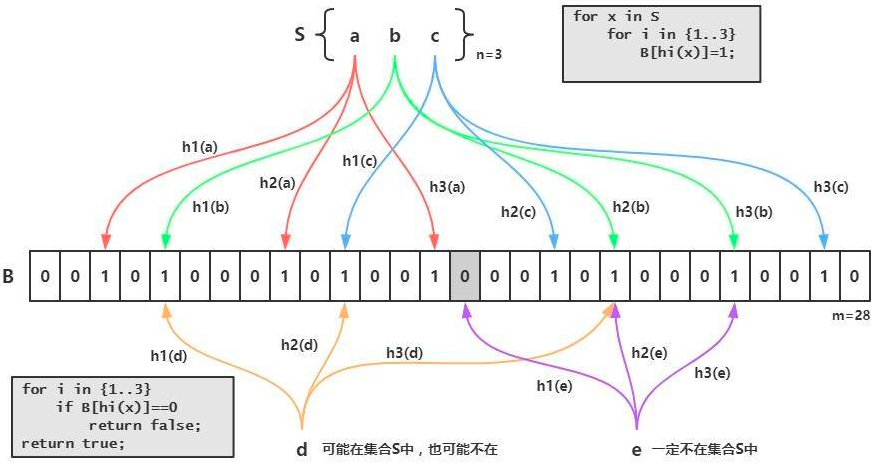
BF是由一个长度为m比特的位数组(bit array)与k个哈希函数(hash function)组成的数据结构。
位数组均初始化为0,所有哈希函数都可以分别把输入数据尽量均匀地散列。
它本身是一个很长的二进制向量,既然是二进制的向量,那么显而易见的,存放的不是0,就是1。
现在我们新建一个长度为16的布隆过滤器,默认值都是0,就像下面这样:
现在需要添加一个数据:
我们通过某种计算方式,比如Hash1,计算出了Hash1(数据)=5,我们就把下标为5的格子改成1,就像下面这样:

我们又通过某种计算方式,比如Hash2,计算出了Hash2(数据)=9,我们就把下标为9的格子改成1,就像下面这样:
还是通过某种计算方式,比如Hash3,计算出了Hash3(数据)=2,我们就把下标为2的格子改成1,就像下面这样:
这样,刚才添加的数据就占据了布隆过滤器“5”,“9”,“2”三个格子。
可以看出,仅仅从布隆过滤器本身而言,根本没有存放完整的数据,只是运用一系列随机映射函数计算
出位置,然后填充二进制向量。
这有什么用呢?比如现在再给你一个数据,你要判断这个数据是否重复,你怎么做?
你只需利用上面的三种固定的计算方式,计算出这个数据占据哪些格子,然后看看这些格子里面放置的
是否都是1,如果有一个格子不为1,那么就代表这个数字不在其中。这很好理解吧,比如现在又给你了
刚才你添加进去的数据,你通过三种固定的计算方式,算出的结果肯定和上面的是一模一样的,也是占
据了布隆过滤器“5”,“9”,“2”三个格子。
但是有一个问题需要注意,如果这些格子里面放置的都是1,不一定代表给定的数据一定重复,也许其
他数据经过三种固定的计算方式算出来的结果也是相同的。这也很好理解吧,比如我们需要判断对象是
否相等,是不可以仅仅判断他们的哈希值是否相等的。
也就是说布隆过滤器只能判断数据是否一定不存在,而无法判断数据是否一定存在。
按理来说,介绍完了新增、查询的流程,就要介绍删除的流程了,但是很遗憾的是布隆过滤器是很难做
到删除数据的,为什么?你想想,比如你要删除刚才给你的数据,你把“5”,“9”,“2”三个格子都改成了
0,但是可能其他的数据也映射到了“5”,“9”,“2”三个格子啊,这不就乱套了吗?

若有收获,就点个赞吧
0 人点赞
