参考课程:
参考资料:
Probabilistic Machine Learning: Advanced Topics by Kevin P. Murphy
1. 基本概念复习
现在我们有一个函数了,我们希望求他的期望。但是我们可能不知道pdf,就算知道,可能也不好算,不过我们可以看看如果条件都具备应该怎么算:
2. motivation
对于一个复杂的分布,我们希望通过采样的数据来估计这个分布。最简单的情况是,我们希望采样的数据是等概率的,这蕴含的是 这一条件。
这一条件。
3. 估计:均值和方差



4. 从分布中采样
我们已知一个分布,我们希望将其转化成均匀分布的情况,这样我们就可以将问题转化为上文讨论过的均匀分布的情况。具体而言,我们需要知道x和 服从均匀分布的 u存在怎么样的关系,同时我们需要知道x的分布是什么,这样我们就可以比较好地化归问题。
例:Beta分布


存在的局限或者说困难:

5. Rejection Sampling
相比于上一个简单的想法,rejection sampling主要的想法是,先构造分布生成一组随机数,然后根据一定的规则和分布从中挑选数据,符合的则保留,不符合的就拒绝。如下图所示:我们先根据p(x)生成一组随机数,我们这里选取的是高斯分布;随后我们选取适当的分布q(x),使得q(x)至少应该是和p(x)是同阶的,或者说q(x)乘以一个常数c后,可以大于等于p(x);我们再从q(x)中进行抽样,得到的s去乘以那个常数c,得到区间[0,cq(s)]也就是说构造出来的结果是可以大于我们的p(x)的;我们再从这个区间里面均匀分布采样得到u,最后根据u是否大于p(s)来确定是接收还是拒绝。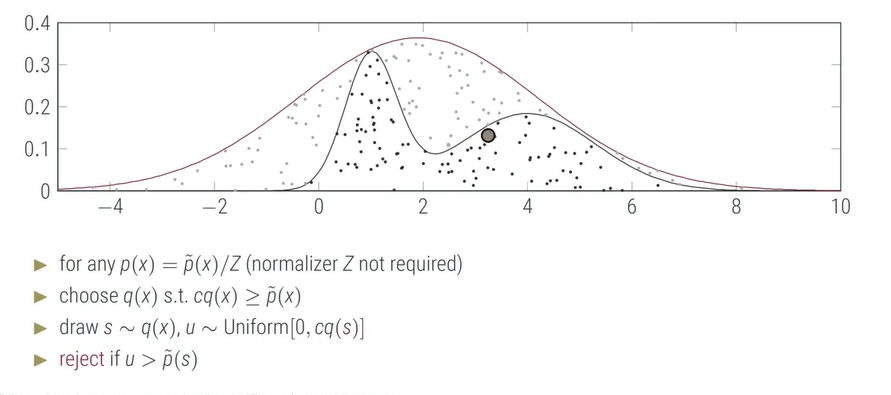
但是这也存在问题就是:拒绝率会指数上升。这是因为,首先我们计算最优的常数c,计算出的c可能会很小(由于likelihood需要用到所有采样数据,因此我们在计算c的时候需要考虑很多数据,这有时候会出现在指数的位置上从而导致c变得很小)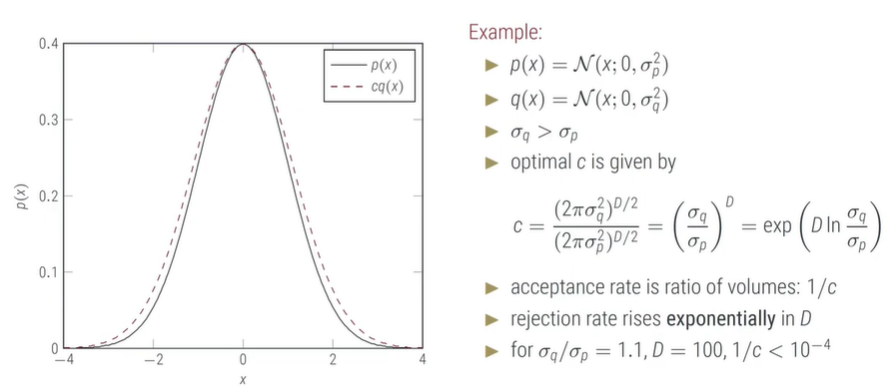
6. Importance Sampling
之前的问题主要在于比值的情况中,一点很小的差异会被指数放得很大,因此如果我们能把 变成一个系数或者说权重,然后再从
变成一个系数或者说权重,然后再从q(x)中进行抽样,只要x服从q(x)的分布的话,问题就会好很多。(我也不会证)
存在的问题:(我是真没懂啊)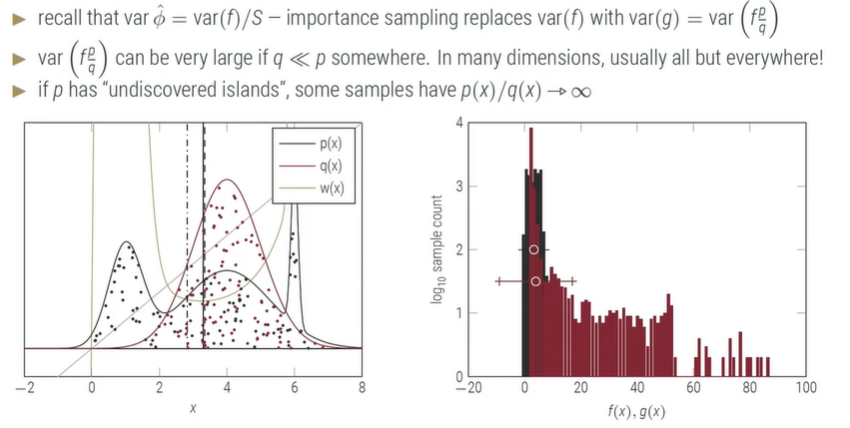


若有收获,就点个赞吧
0 人点赞
