参考课程:
参考资料:
Probabilistic Machine Learning: Advanced Topics by Kevin P. Murphy
1. Structural time series model
STS的核心思想是用观察到的数据来作为待预测数据的组成部分: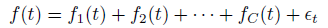
方程右边都是隐藏的、当期的过程,一般是由linear Gaussian state-space model来刻画的。总体上讲,以往的ARMA等模型可以等价视作是用STS来刻画的。(但是我们这里并不用自回归等等来进行刻画)
但是我们的STS会更广义一些,我们会使用到non-linear ,non-Gaussion等等拓展。
local level model
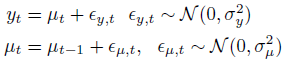
Local linear model

又叫做 local linear trend model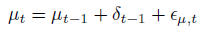
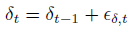
对应的因果图为: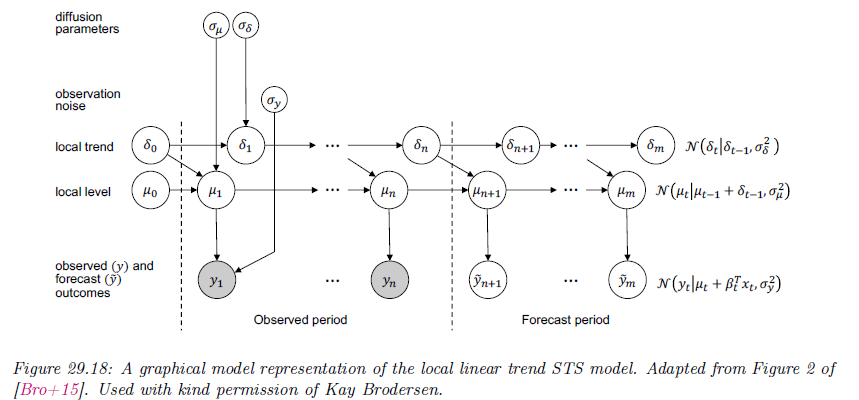
我们也可以写成自回归的格式: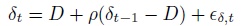
这被称作semilocal linear trend
Adding covariates
从SEM的角度讲,我们的方程可能不是时变的,加协变量之后,那么可以写成如下这个形式: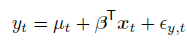
但是在这种情况下,我们要预测未来的y ,首先要知道未来的x。
最自然的可能有这种效应的是季节性效应,![[Book] Chap 29: 时间序列预测 - 图9](/uploads/projects/zitaoshuai@ygk615/09d9d48a667d07b46c60ccfef9a9ef2e.svg)
对于一个周期为S期的季节性效应我们可以写成: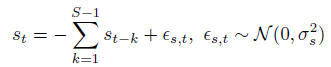
对于以上讨论的情况,我们有下面的图来总结: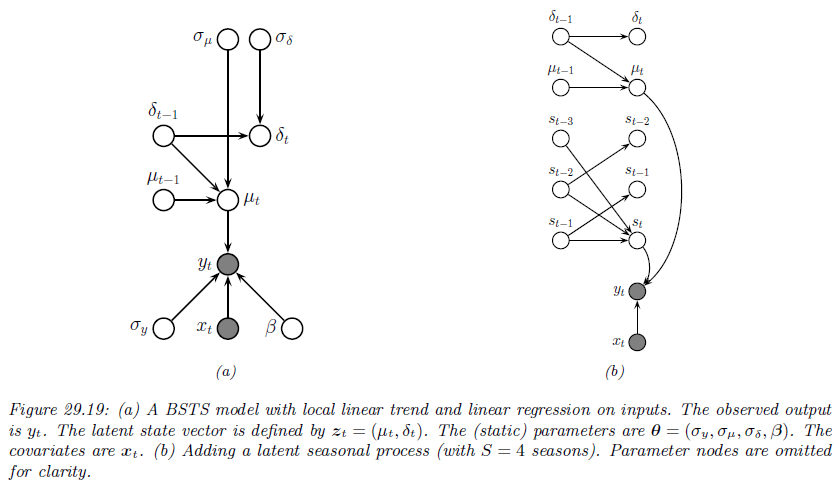
我们考虑联合起来的效应如图所示: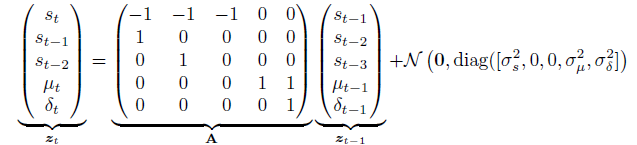
以上所有的情况我们可以总结为如下的预测式子: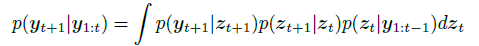
Causal impact of a time series intervention
有了因果图之后,我们就有了对时间序列中的 latent的变量施加干预的方法了。具体而言,我们希望研究的是,在某一时间点如果不对某一变量施加干预,会产生怎么样的结果。例如,在某一时刻 t处,我们投放了广告,我们观测到了投放广告后的点击量,但是我们希望知道这个投放带来了什么效果,因此我们需要知道如果不投放广告,点击量会是怎么样的,所以我们要研究反事实效应。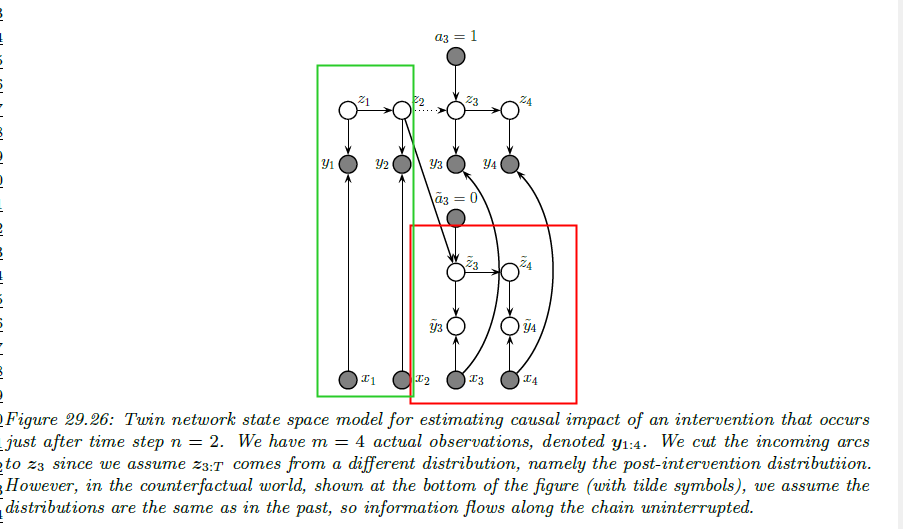
首先我们来看,这张图中我们在 n=2处施加了一个干预,因此施加之后,我们观测不到红色框中的数据,这是反事实的;在施加之前我们观测的是绿色框的。同时注意到,我们的 x是始终在给 y干预的,因此我们的孪生图的这部分参数是相同的。
随后我们可以计算反事实的分布如下: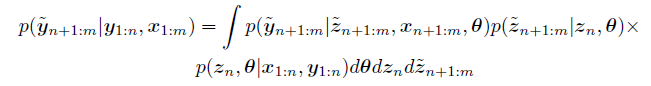
分别解释如下:
第一项:给定参数![[Book] Chap 29: 时间序列预测 - 图16](/uploads/projects/zitaoshuai@ygk615/26bde7cbffa25109c96f4d718b38a032.svg) ,我们计算反事实的
,我们计算反事实的 yhat
第二项是计算在之前干预前的 z和 theta给定的情况下,干预后的zhat的分布函数。
这两个可以由孪生图来计算得到,因此实际上我们可以改写成:![[Book] Chap 29: 时间序列预测 - 图17](/uploads/projects/zitaoshuai@ygk615/6e0472da330d3fec8f6e46dc294c2305.svg)
对于最后一项,我们有: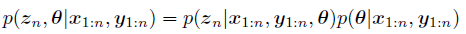
这里是用干预前的来算。这里的第一项用 kalman smothing来计算,第二项用 MCMC或者变分推断来计算。
其实我们这里还隐藏了一些假设:
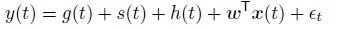
神经网络预测方法

若有收获,就点个赞吧
0 人点赞
