参考课程:
参考资料:
Probabilistic Machine Learning: Advanced Topics by Kevin P. Murphy
1. Introduction
主要的利用概率论的方法为:
- factorization
- averaging
PGM (Probabilistic graphical model): 通过定义一组变量的联合分布来利用概率来计算。其中节点往往代表变量,边会代表 CI(conditional independence)。有时候我们也会称之为依赖图。
2. Bayesian network
有向图DAG被称为贝叶斯网络,也有时候被称为信念网络 belief wetworks。
考虑联合分布
首先我们的节点只依赖于父节点,而不依赖与后代节点和父节点以外的前驱节点: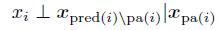
因此对于联合分布我们可以拆成这样的形式: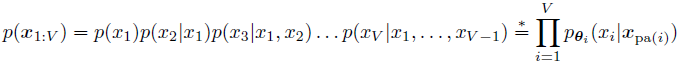
注意可能x1 ~ xv中只有对应的父节点在等式右边得以保留,其中右边的每一项乘积被称为 CPD(conditional probability distribution)。
回忆到如果有 k种状态的话,我们会有 ![[Book] Chap 4: 概率图模型 - 图3](/uploads/projects/zitaoshuai@ygk615/9dbdc5a0960a78aa597346c558ba3d40.svg) 个参数,但是在现在优化之后,我们只需要
个参数,但是在现在优化之后,我们只需要![[Book] Chap 4: 概率图模型 - 图4](/uploads/projects/zitaoshuai@ygk615/628491bd06b4a9c6f6ba529fc5a15802.svg) 个。这是因为由于条件独立性假定,我们只考虑了父节点作为估计 联合分布的量。
个。这是因为由于条件独立性假定,我们只考虑了父节点作为估计 联合分布的量。
例子: Markov model
对应的图示为:
这里我们利用 Markov assumption可以得到第一种情况: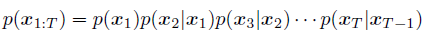
以及第二种情况为: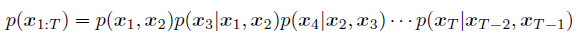
例子 student network
上面的例子较为简单,我们实际遇到的大多数是 student network,例如下面的这张图: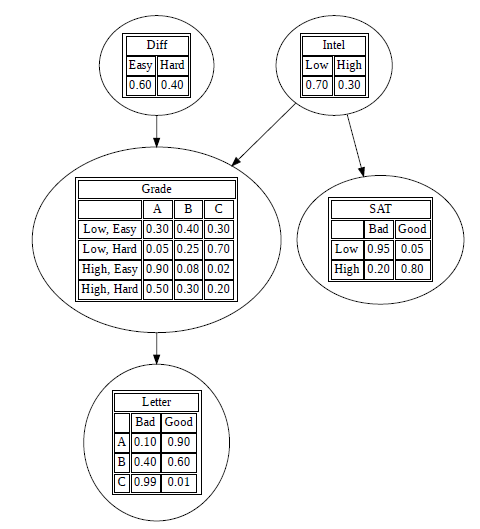
我们该怎么处理呢?首先其对应的联合分布式应为: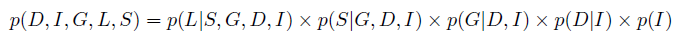
但是考虑到条件独立性我们应该做出简化: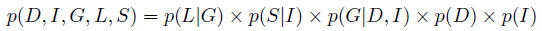
一些 causes之间的nagetive interaction被称为explaining away,或者说 Berkson's paradom。student network的参数量也是非常少的,仅仅只有![[Book] Chap 4: 概率图模型 - 图11](/uploads/projects/zitaoshuai@ygk615/6413506a3261f38d312b4a740666b0e1.svg)
例子:Caussion Bayes nets
这个地方我们主要是给指向每个节点的边都赋予了权重,并且概率的计算只最后落在高斯分布上面的: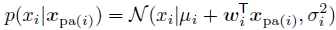
这个也可以重写为: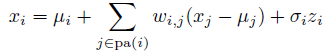
此外Cov还可以写成正交分解的形式: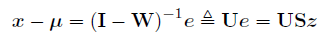
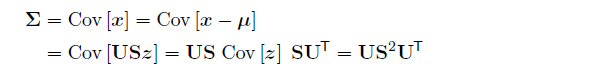
例子:Sigmoid belief net
这里我们考虑很像神经网络的概率图的模型:
首先是隐变量分层,且层间的节点互相之间没有决定关系的情况: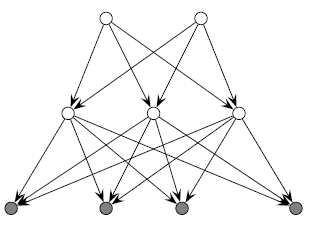
此时的联合分布应该计算为:
其中 x代表最后一层,z1 ,z2 分别代表前两层节点。具体而言,当我们使用 sogmoid激活函数时,我们有: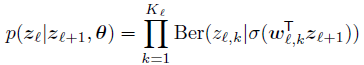
此外,我们还有 deep autoregressive network: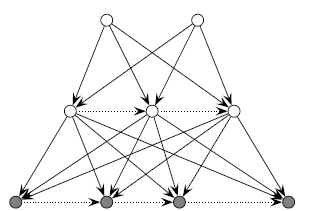
条件独立的性质
这里我们希望知道,什么时候具有如下的条件独立性:![[Book] Chap 4: 概率图模型 - 图20](/uploads/projects/zitaoshuai@ygk615/bb9003e09a50c23fd226788219860b0e.svg) ,因此引出
,因此引出 d-seperation的概念: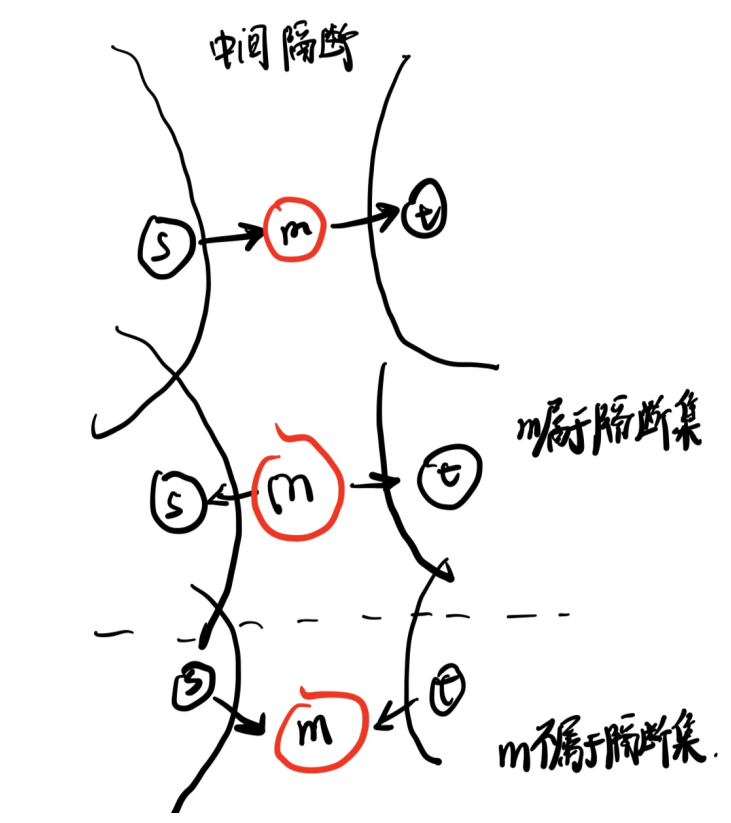
当 C是 A``B的隔断集的时候,上述的条件独立公式就成立。
这个也可以被称为是 global Markov property,我们常使用 Bayes ball algorithm来检验这个效应。具体而言,这个算法就是讲d-seperate set中的节点涂黑,然后看是否有路径(注意是无向的)会从A到B。这个路径不能撞到黑色的点,如果撞到则返回。
此外,我们还有一个常用结论:
(从三个结构的情况都可以推出来)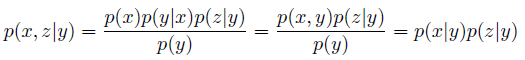
Explaining away
Explaining away效应可以解释为:在上述的 v-structure中,对v结构底部的孩子节点做 conditioning会导致父节点都独立。这个也叫Berkson's paradox。
local Markov property
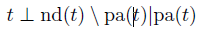
这里和全局马尔可夫性不同的是,nd(t)指的是除了后继节点以外的所有节点。
Markov blanket
这里我们关注,对于某个节点 t,我们是否能condition掉最少的节点,来让 t独立于其他节点。Markov blanket里面的节点可以看作 t的父节点,因此也称作 co-parent.
因此我们引出 t的 full-conditiional: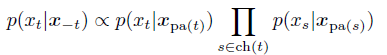
I-maps
我们定义:statement: 形如![[Book] Chap 4: 概率图模型 - 图25](/uploads/projects/zitaoshuai@ygk615/ef3cf32d405358c6efadbd1531c8515b.svg) 的条件独立式子
的条件独立式子I(G): 这些条件独立式子的集合
对于分布 p而言,可以表示他的条件独立式集合有很多,对应的G也有很多,只有保证满足分布 p需要的条件即可。
inference
干预的含义为:在一系列的 query nodesQ上面,我们有观察到的变量(节点)V,以及其余节点 R,然后我们根据先验和似然来计算后验。通常我们计算的都是posterior marginal。
例子:V = x 是和我们接收到的语音信号,R = r 可以被看作是一系列与信号有关、与语义没有直接关系的信息,Q = z 是我们希望知道的语音包含的语义信息。我们希望通过先验信息+接收到的V = x 中的似然信息来计算后验: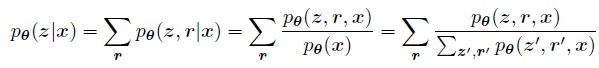
干预可以被视为得到信息、更新后验的一个过程。
learning
现在我们希望学习图中的参数,即后验分布:![[Book] Chap 4: 概率图模型 - 图27](/uploads/projects/zitaoshuai@ygk615/a9522aeff4a9a1cbf3215525d19ac0c5.svg)
我们的核心思想是把参数![[Book] Chap 4: 概率图模型 - 图28](/uploads/projects/zitaoshuai@ygk615/f99b37a112b96b2f2ae2a45e0658ab10.svg) 当作是另一个隐藏变量
当作是另一个隐藏变量
完整数据下的典型学习策略
已有:N个局部变量,这个我们是可以观察到的;2 个全局变量 x y,我们观察不到,只能表示出他们,全局变量是被所有数据共享的,和参数有关;
条件:局部变量在训练数据中被观察到
因此我们可以下面的联合分布的表示: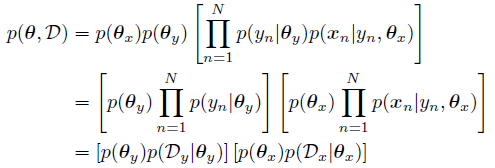
其中这里还设定 Dx``Dy可以估计出 x和 y。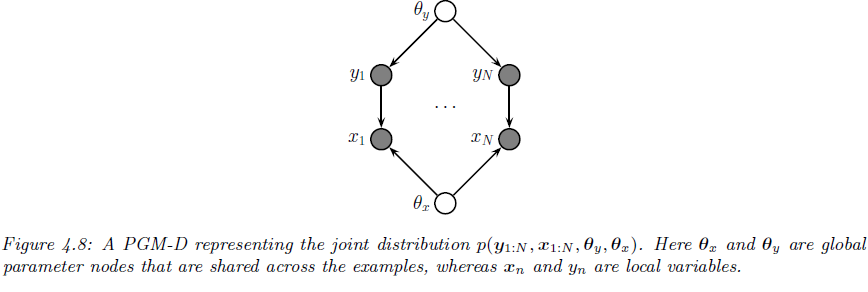
从这张图我们可以知道先验是什么样的,当然先验并没有告诉我们![[Book] Chap 4: 概率图模型 - 图31](/uploads/projects/zitaoshuai@ygk615/9a61a0f3bf868e1aea904b536e02559b.svg) 是多少,因此我们需要通过已知的图的结构来进行
是多少,因此我们需要通过已知的图的结构来进行decompose 或者说 factorize,实际上我们有: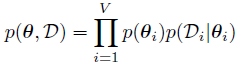
最后我们希望的是,通过似然来求一个优化: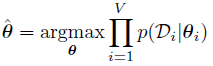
例1
我们用以下的例子来解释如何为 CPD计算 MLE: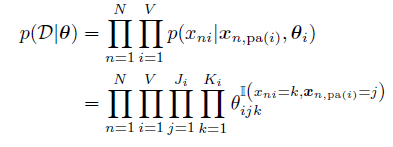
其中![[Book] Chap 4: 概率图模型 - 图35](/uploads/projects/zitaoshuai@ygk615/faef357ba541094408449783a992e1a5.svg) 的意义为:
的意义为: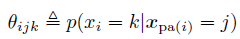
即是说,i代表第 i 个节点,j代表这个父节点(可以是向量)值为 j ,k代表这个节点值为 k。然后我们可以再设充分统计量 ![[Book] Chap 4: 概率图模型 - 图37](/uploads/projects/zitaoshuai@ygk615/dc97ff4d71b433d5f92f894d5da21066.svg) ,代表节点
,代表节点 i在状态 k且父节点在状态j时的次数。(这里值可以理解为状态)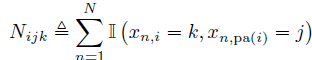
充分统计量原理
因此我们的 MLE可以估计为: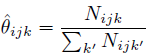
计算例子:
图:
观察数据与估计:
理解:
- 首先这里我们用图中节点单词的首字母作为简称,其中的数值表示一个状态,例如
G = 2可以理解为该课程的分数得了一个C,I = 1代表聪明。 - 以第一行为例,
ID为父节点,G为子节点,N有三个维度是因为G有三个取值,[1,1,1]代表给定I``D时G为0,1,2的时候的个数。此时N中的,i为节点G,k为0,1,2,时N的三个维度,j为I和D的取值 为了解决
zero-count的问题,我们需要给存在0的行,每个k对应的位置都加一个1(在真实的数据中加入),而![[Book] Chap 4: 概率图模型 - 图42](/uploads/projects/zitaoshuai@ygk615/d1e8dae843726069ffdd7321e7ee9479.svg) 是分子考虑了,但是分母没考虑(这是因为这里是采样估计量,而不是用真实的来算的)。因此除了
是分子考虑了,但是分母没考虑(这是因为这里是采样估计量,而不是用真实的来算的)。因此除了[I,D] = [0,0]那组以外,每组都加了一个[1,1,1],然后我们就可以进一步计算后面两列的结果了。当然[1,1,1]只是一种比较特殊的情况,迪利克雷![[Book] Chap 4: 概率图模型 - 图43](/uploads/projects/zitaoshuai@ygk615/14e1298ca19a0c7b2184e4da5a81d6ed.svg) ,是给所有的
,是给所有的 k都加1,也可以采用其他的分布。不完备数据下的学习策略
motivation:
曾经的方法需要知道所有节点的信息,但是我们的数据却是不完全的: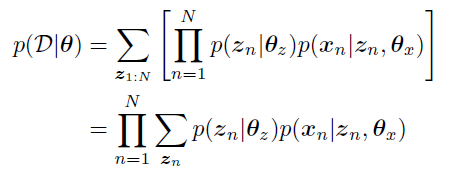
因此我们考虑使用EMSGD来解决这一问题。**EM**
我们的基本思想是推断潜在的变量和估计已有的参数:在
E阶段,我们返回的是expected sufficient statistics
由于在完全数据情况下我们得到的是: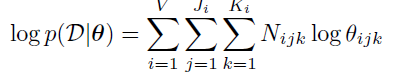
因此我们希望估计到这个,因此我们返回如下的估计量: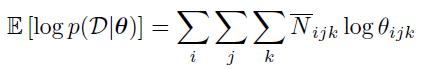
其中: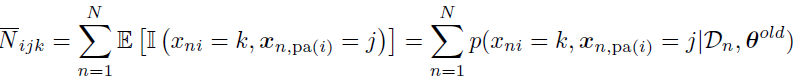
在这个式子中我们的p被称为 family marginal,我们可以用 GM inference algorithm计算得到;N被称为ESS,我们在E阶段得到。
- 那么在
M阶段,我们可以用下面的估计方法得到估计量:
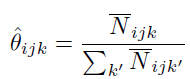
**SGD**EM算法 adapt 到大的数据集上去的时候,我们会用到 SGD来优化。
Plate notation
对于iid中得到的变量,我们可以简化表达,例如:
例1:factor analysis
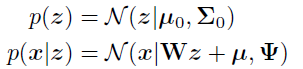
在给出上面的表达式的时候,以上两者是等价的。
例2:Naive Bayesian Classifier
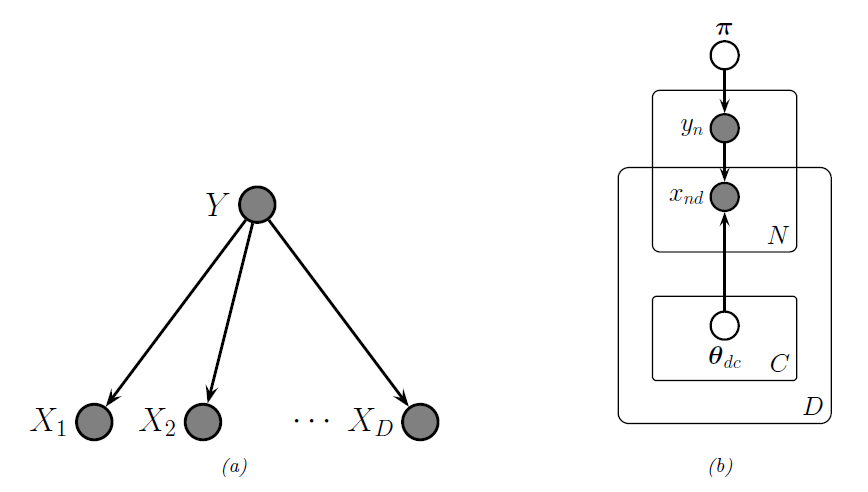
3. Extensions of Bayes nets
probabilistic circuit
主要包含:arithmetic circuitssum-product networks:
我们可以理解为一个有向树模型的图,我们可以用类似编译原理里面的知识来理解,terminal节点表示单变量的概率分布,非T节点则表示联合分布。这个结构主要是平衡了context-specific independence 的影响,从而减少了额外干预的复杂度。
Relational probability models
我们以下面的例子来说明:
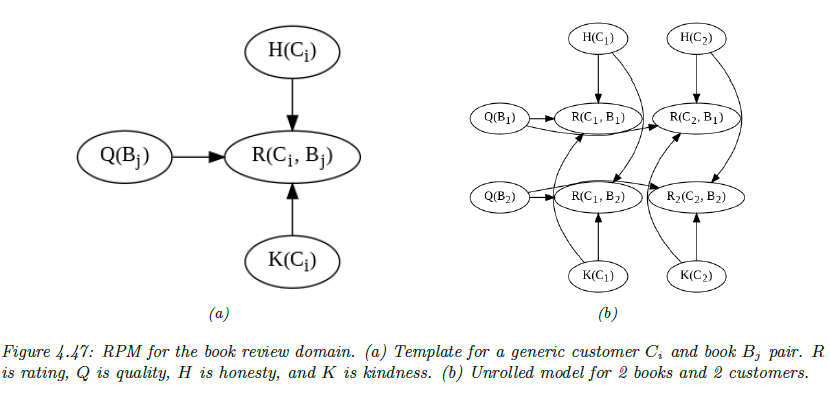
第一步我们画出上面的关系图
第二步我们给出先验分布:
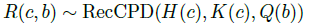
但是很多时候会有我们难以区选择哪个 book,所以我们需要更多的变量来标识。其实这也引出其他的问题,我们有时候需要条件独立性,那其实也是引入新的变量。这种变量我觉得可以都当作 latent 变量。不过挺遗憾的是,多数情况下,我们很难考虑完全所有的这样的变量。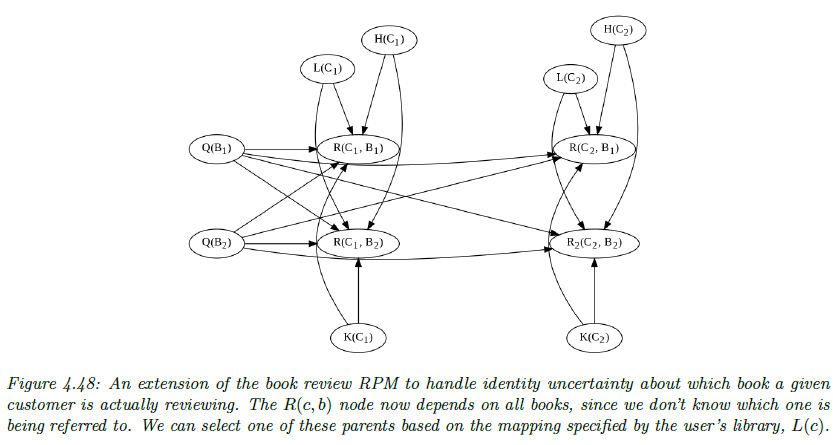
备注:有点没太搞懂这些模型提出来有什么意思,也可能是我先了解的因果图,所以认为这种铺垫性工作是自然的。
Open-universe probability models
之前我们的研究是基于closed world assumption,在多数情况下是不现实的,我们总是难以考虑完全所有的变量,所有的对象。
这里的 OUPM模型主要在于他可以生成新的对象和新的指标。
Programs as probability models
3. Structural causal model(SCM)
overview
内生:V
外生:U
关系函数:F
我们最直接的表达就是下面的SCM
当然上面的模型可以进一步转化为SEM: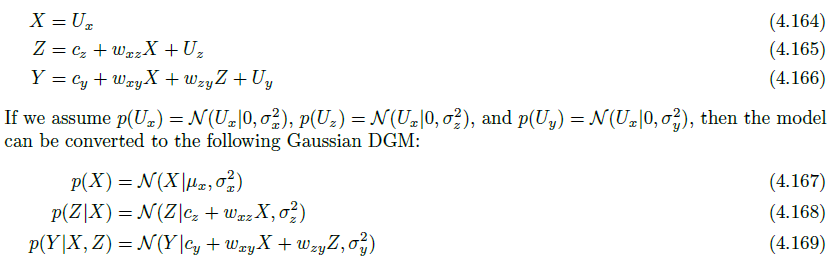
但是注意到,这里SEM是参数化、线性主导的,因此往往不是我们的深度学习里面需要的样子,这是计量经济学中所常用的。
Do operation
最简单的理解就是对 x做 do 操作后,x的值就被设定了,也因此我们需要剪去指向 x的边。![[Book] Chap 4: 概率图模型 - 图60](/uploads/projects/zitaoshuai@ygk615/bde16e275f675d87f84a5a18fe728800.svg) 也不等于
也不等于 ![[Book] Chap 4: 概率图模型 - 图61](/uploads/projects/zitaoshuai@ygk615/dc9bd0c21ac754c15d590b22d2744c6e.svg) ,因为 do 操作是改变了因果图的结构的。这也是我们强调 do 是操作,而后者是观察,观察条件概率的原因。
,因为 do 操作是改变了因果图的结构的。这也是我们强调 do 是操作,而后者是观察,观察条件概率的原因。
Estimating
最直接的想法是,我们希望估计某个操作的平均影响是怎么样的,因此我们引入average treatment effect(ATE):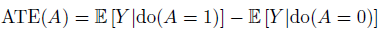
对于SCM我们往往不能代入方程这么简单地来解决,下面我们主要讨论 SEM的情况。
Direct effect
从 SEM角度出发的估计,我们可以直接代入方程然后来考虑: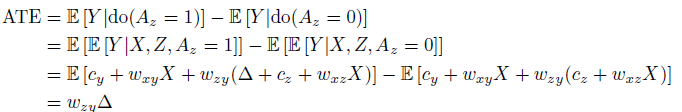
区分 & 经典因果三层级
Indirect effect
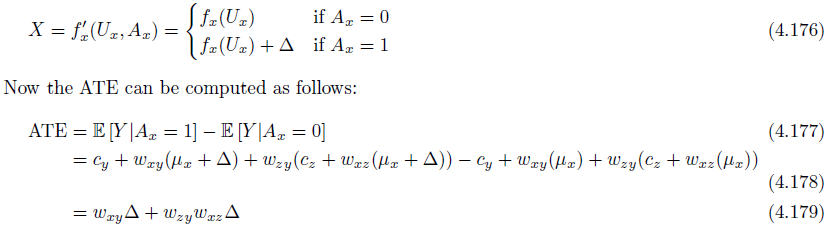
Conterfactual
反事实的情景下,我们希望考虑: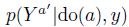
具体而言,这是指现有的是对 y 执行了 do(a) 操作的样本,我们希望考虑如果执行 do(a’) 操作,会是什么结果。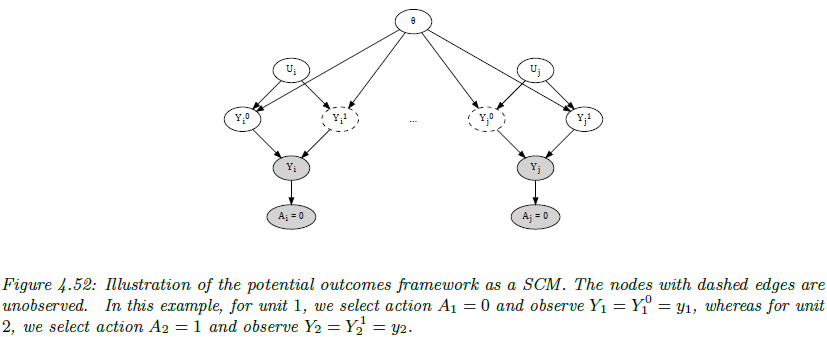
最后我们还需要一个假设:SUTVA(stable unit treatment value assumption)
这需要我们考虑,对个体j进行操作是否会影响到个体i。
另外,注意反事实是对个体而言的。
我们对反事实的估计步骤如下:
- 用给出的观察到的真实的信息计算后验:
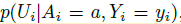
- 我们用干预的方法改变图 G 的因果机制,即是说我们将 do 操作中的
a更换为a' - 我们通过修改后的图
G'来计算反事实效应。
这样说比较抽象,继续看图4.52,我们可以通过”拷贝”其他的无关的变量和参数来得到一个孪生模型。就是说有的拷贝的子图的参数不完整,但是合理选取数据可以避免使用到这些参数,然后我们可以拼接一下。有点像X-learner的一个想法。

若有收获,就点个赞吧
0 人点赞
