参考课程:
参考资料:
Probabilistic Machine Learning: Advanced Topics by Kevin P. Murphy
1. motivation
distribution shift
问题:
- 加噪音影响部分模型的识别能力的问题
- 就是没有识别真正的和目标有关联的语义

我们通常的假设:training sets & testing set是 iid的
事实的情况是:通常是有distribution shift的,从概率上说就是![[Book] Chap 18: Beyond iid assumption - 图2](/uploads/projects/zitaoshuai@ygk615/2a86a40e8eaff4eb407b790df832723a.svg) ;从因果上理解,我们可以认为是发生了
;从因果上理解,我们可以认为是发生了latent variable的变化
应对方式:
主动应对:使用不同的数据集,尽量全。这是一些社会科学或者医学机器学习的做法
被动应对:使用一些工具尽可能地消除这方面的影响
下面介绍几种常见情形:
1.2 Covariate change
这个问题和上一个问题的不同之处在于,这里变的是我们能观察到的东西:协变量x
为什么说这会带来问题呢?回顾我们在因果推断中提到过的overlap的问题:我们的样本中T=1和 T=0的个数不应太小或者太大,对Y 也是一样。否则会带来观测不全面的问题。
那么对x也是如此:
如果我们训练的x中,x和 y的关系是线性的,在测试的部分是二次的,那么就是发生了covariate change。在计量经济学中,这叫做结构性差异,一般用邹氏检验识别。在因果或者说贝叶斯的角度讲,这个问题可以描述为![[Book] Chap 18: Beyond iid assumption - 图3](/uploads/projects/zitaoshuai@ygk615/e2bf4a96b11b6191fbcc68f6e47ed366.svg) ,但是
,但是![[Book] Chap 18: Beyond iid assumption - 图4](/uploads/projects/zitaoshuai@ygk615/c26fe3599c7b2a95d8e5fb1dc293acfd.svg) 发生了变化。
发生了变化。
1.3 Domain shift
用因果的语言描述,就是存在 latent variable Z,同时有![[Book] Chap 18: Beyond iid assumption - 图5](/uploads/projects/zitaoshuai@ygk615/55b13691c5c2d420da800f5a2af27688.svg) 的存在,因此
的存在,因此Z的变化会影响到X。我们上文中的牛的例子就是典型的 Domain shift的问题。
此外,Manifestation shift也属于domain shift,只是关注的点在于![[Book] Chap 18: Beyond iid assumption - 图6](/uploads/projects/zitaoshuai@ygk615/ab460abfb4f807f401508bc3d03c1431.svg) 发生了变化。
发生了变化。
1.4 Label / prior shift
这个主要是数据的标签含义不同,形式化地讲:![[Book] Chap 18: Beyond iid assumption - 图7](/uploads/projects/zitaoshuai@ygk615/e7268a9cf1e1e8bbd10489f46563d017.svg) 中的先验分布或者说
中的先验分布或者说![[Book] Chap 18: Beyond iid assumption - 图8](/uploads/projects/zitaoshuai@ygk615/713256ea663527e935c3763da8f500f0.svg) 发生了变化,因此会影响到我们的机器学习对后验分布的求解。
发生了变化,因此会影响到我们的机器学习对后验分布的求解。
例如,不同的数据来自不同的医院(这其实代表的是另一个变量,但是我们没有考虑进去,在计量经济学中我们称之为内生性问题),那么治愈率 Y就是不太一样的。
此外:concept shift和这个也是类似的,不同这一shift强调的是对标签的概念不同而造成的shift.
1.5 selection bias
这个有点像causal inference中的overlap的问题,我们希望采样分布是平衡的。或者说从计量经济学的角度讲,是满足条件独立性(CIA)的假设的。
2. Training time techniques
2.1 目标
我们希望训练一个在目标分布上具有最小期望风险的预测器: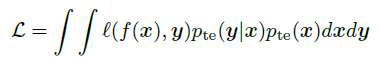
最好的情况:目标数据集有一些标签,那么我们可以用迁移学习来处理。
但是对于标签有问题(我们可以理解为受到latent变量的影响)的情况,我们常常难以处理。对于x呢我们可以多整点数据集。我们这里的假设是latent变量很难观测全。(或者说观察了就不是latent了,而是covariate)
2.2 Importance weighting
权重方面的想法,最 naive 的就是给每个数据点加权,依据为已知目标的数据分布,然后我们计算加权后的 loss就好。但是问题是我们不知道目标数据分布
因此我们的核心思想是给train test数据不同的标签 1 -1,因此我们可以有: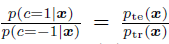
而我们的预测器是用train里面的数据,也就是 1 这个标签来的,因此我们有:![[Book] Chap 18: Beyond iid assumption - 图11](/uploads/projects/zitaoshuai@ygk615/53203b639c4f40edb657125557844017.svg)
从而我们有权重: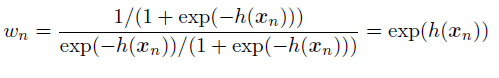
2.2.1 weighted conformal prediction
核心:加入一个得分机制来确认是否将训练集中的数据点选入,作为真正训练的数据: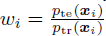
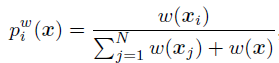
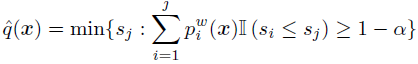
2.2.2 domain adaptation
这个情况下,我们有两个数据集:有标签的D1和没有标签的D2(事实上D2的标签我们是知道的)
我们用半监督学习的方法在两者的并集上训练,得到一个predictor,然后我们可以将D2的数据输入,然后用输出和真实标签对比。我们希望最优化的是下面的这个式子: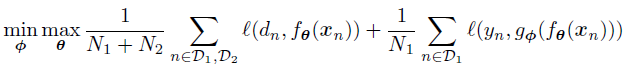
这样的想法可以保证我们学到的是通用的分布的信息,一般会有 ![[Book] Chap 18: Beyond iid assumption - 图17](/uploads/projects/zitaoshuai@ygk615/aed581f4254d6160230f23946357e6c1.svg) 的这样一个特征提取的过程。
的这样一个特征提取的过程。
2.2.3 domain randomization
2.2.4 data augmentation
这个是通过对已有数据集进行合理的变换来进行的。例如我们在CV的人脸识别中,可以对图片进行不同的几何变换;在NLP中,我们可以对句子删改一些我们认为没有因果的词句。(我觉得这算是 EMNLP了吧,好那啥)
2.2.5 unsupervised lable shift estimation
这里我们需要从贝叶斯的角度来考虑问题,考虑当前的分布是p,预测分布是q,因此我们希望的是:![[Book] Chap 18: Beyond iid assumption - 图18](/uploads/projects/zitaoshuai@ygk615/42c829e36f58c4e4cf429faf900070a8.svg)
关于估计的标签我们有如下的推导: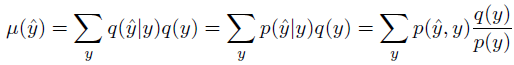
同时我们也有混淆矩阵(confusion matrix)来表示估计值与真实值相同的概率: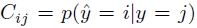
2.2.6 Distributionally robust optimization
我们希望优化一个差异性加权模型(或者说训练一个出来),目标函数为: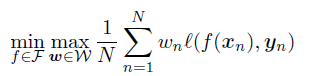
3. Test-time techniques for distribution shift
motivation:我们可能会无法预先得到test set,因此我们希望能在测试的时候检测到shift的发生。
因此,对于test-time 的情况,我们的决策过程应当是,先判断是不是 OOD的,再来进行预测。
3.1 two-sample testing method
我们可以检查![[Book] Chap 18: Beyond iid assumption - 图22](/uploads/projects/zitaoshuai@ygk615/19e0f76f3d9f054140a0caf9417e4cda.svg) 是否成立,具体而言我们用形如
是否成立,具体而言我们用形如MMD等等的距离来度量分布之间的差异。
由于x的位数比较大(我猜 motivation 是这样),我们最好假设 likelihood 是一样的(或者说![[Book] Chap 18: Beyond iid assumption - 图23](/uploads/projects/zitaoshuai@ygk615/ad5859d56da4e28e634d4b31070ea438.svg) ),这样我们就只需要检验先验的
),这样我们就只需要检验先验的![[Book] Chap 18: Beyond iid assumption - 图24](/uploads/projects/zitaoshuai@ygk615/f5a3ce7a39d22ecae4094c6c4d14274f.svg) 是一样的。
是一样的。
3.2 detect single OOD inputs
3.2.1 supervised ID/OOD
如果我们可以同时获得 labeled 的数据和 OOD 数据的话,我们就可以预测哪些是 unknown的,进而判断哪些样本是 OOD的。
3.2.2 Classification confidence methods
我们可以直接对输入数据的类型进行预测,判断是属于OOD的还是其他情况。这里的主要思想是用一个称作energy score的信心指标来进行处理。(这个小方向比较新,书中引用的文献主要是21,22年的)
3.2.3 conformal prediction
我感觉这些方法都挺综述性质的。这个方法需要定义很多指标,然后用 Top k 的思想去构建预测结果,并通过这个结果来判断输入是否是 OOD的。
3.2.4 unsupervised methods
3.2.5 selective prediction
对于输入数据有一个 confidence level,判断输入是否是 ood的
3.2.6 online adaptation
持续更新模型参数,已知输入流的 label 或者 数据增强的时候的信息,我们可以直接做一些 adaptation 。在不知道的时候,可以使用 entropy minimization 等方法来帮助我们更新参数。
4. Learning from multiple distributions
motivation:
源数据集由一个扩展至多个,但是这些数据的信息又不是全部都是很棒的,有的可能会少了标签或者其他异常情况: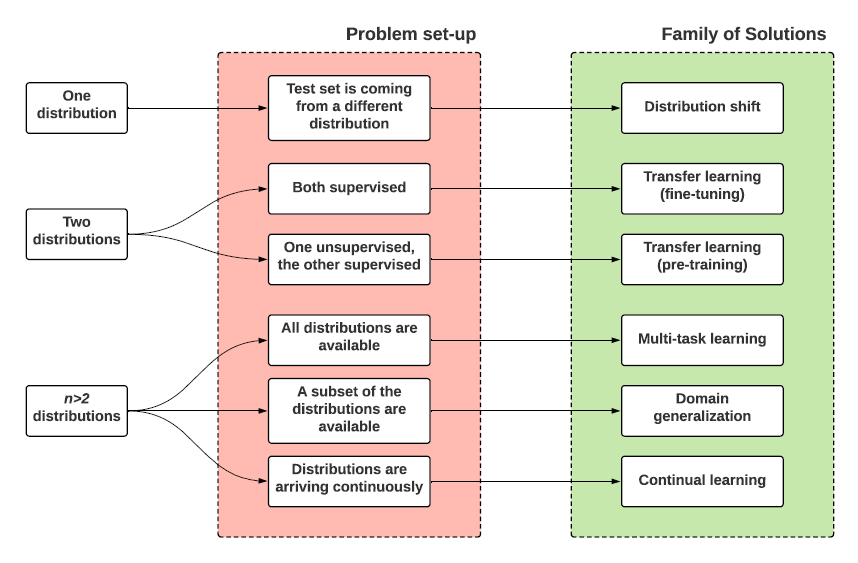
在这个问题下,我们仍然在源数据集下进行损失最小化。
4.1 transfer learning
motivation:D1~p1,D2~p2,测试集的分布和p2相同,我们希望最小化在p2上的 loss,关键在于 D1和 D2谁占比更大。
4.1.1 Pre-train and fine-tune
比较 naive 的做法是,先在D1 上做训练,在 adapt 一下,其中用衡量函数距离的正则项来表示模型之间的差距: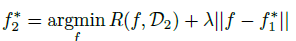
例如,距离可以被定义为:网络参数之间的欧式距离。
有如我们可以除去最后一层,更换上新的一层,然后只训练最后一层,这样就利用到了之前的训练结果。
4.2 Few-shot learning
这个话题主要是希望解决小样本的预测问题,特别得,对于每类只有一个样本的情况,我们称之为:one-shot learning
主要是用meta learning和 Prompt learning来解决
4.3 Prompt tuning
先在大样本上训练,在移到小的和task-specific的样本上。在这个过程中,我们希望模型的参数保持不变,只更新的增加的结构的参数。
4.4 Zero-shot learning
这里是目标类中的数据没有标签的情况,但是只要有好的 representation 就可能会容易处理。比如我们通过 feature 来构造编码,用这些编码来表示每个类,自然也可以生成出新的类,尽管我们不知道叫什么名字,但是他们这个类有了编码,可以用来识别。
具体可以是人为构造,也可以是通过embedder映射到一个低维的 emdedding空间,然后去做预测。
4.5 Multi-task learning
这个感觉为啥要特殊说明呢?我猜是不是需要处理不同分布上的冲突,比如在 A 集合效果好在 B 集合就容易效果差的问题,主要是在起到一种调和的作用?(书中提到的是 balance 的问题,应该差不多)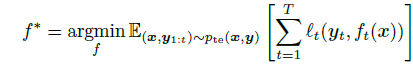
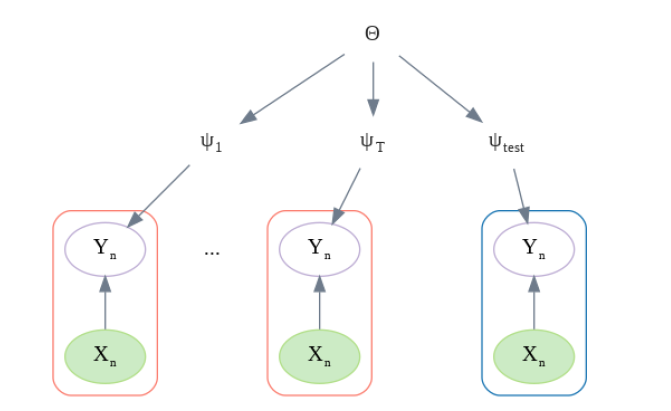
4.6 domain generalization
这里我们是把各个数据集混合在一起考虑,其 id 只起到标识作用,没有提供更多的信息。但是每个数据集又确实是有自己的分布的,这个任务的目标是为了在新的数据集上获得更低的期望损失: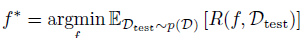
一种比较好的方法就是采用层次化的方法来学习:先有共同的先验 ![[Book] Chap 18: Beyond iid assumption - 图29](/uploads/projects/zitaoshuai@ygk615/7aa4a4122d500fb6cabcf37e1b8d6657.svg) ,然后有各个数据集 local 的
,然后有各个数据集 local 的![[Book] Chap 18: Beyond iid assumption - 图30](/uploads/projects/zitaoshuai@ygk615/4a2af570d2e17d763f7ef826705b9153.svg)
4.7 Invariant risk minimization
这个方法的核心是使用假设检验的办法来寻找一组有效的预测因子,保证在不同的环境中都和结果相关,有稳定的预测。
motivation:可能出现扰动的情况,不同环境中还有不同的扰动
因子比较好的做法就是考虑在所有环境中的最优表现:Invariant risk minimization,这个目标可以被表述为: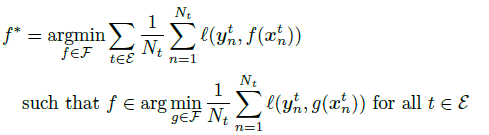
奇怪,我觉得还是没有感觉上面几个问题有什么特别大的区别,如果有的话就是考虑问题的方式不同。
5. Meta learning
这个玄学的概念是:学习使用什么算法来学习。具体而言,我们从一系列来自不同的数据分布的数据中学习meta learner。
5.1 Meta learning as probabilistic inference
这里我们有 t 对测试集和训练集,并且有共享参数![[Book] Chap 18: Beyond iid assumption - 图33](/uploads/projects/zitaoshuai@ygk615/2a404d96750b522a3ab48276f2b75e6b.svg) 和私有参数
和私有参数![[Book] Chap 18: Beyond iid assumption - 图34](/uploads/projects/zitaoshuai@ygk615/9e75e468b2220c2192a6498296456653.svg) ,我们希望从所有的数据集中学习到前者,同时也希望估计后者的后验分布:
,我们希望从所有的数据集中学习到前者,同时也希望估计后者的后验分布:![[Book] Chap 18: Beyond iid assumption - 图35](/uploads/projects/zitaoshuai@ygk615/f6a38fda306ef385694e8fe55040e530.svg) ,这事因为每一类的数据都比较少。
,这事因为每一类的数据都比较少。
而对于每个任务我们有如下的后验预测: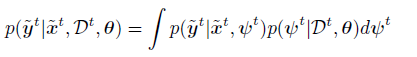
我们希望在每个数据集中求得一个最优的![[Book] Chap 18: Beyond iid assumption - 图37](/uploads/projects/zitaoshuai@ygk615/199ee62d336546883533a14a27ee9f6e.svg) 来满足以下条件
来满足以下条件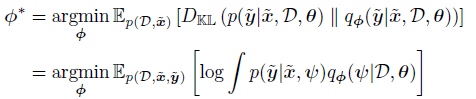
这里q可以通过MC采样来求。
最后有如下的优化目标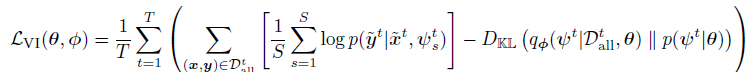
(说实话这里没有太懂。)
其余的不太感兴趣,感觉也不怎么相关,我就只列优化目标了(
5.2 Gradient-based meta-learning
![[Book] Chap 18: Beyond iid assumption - 图40](/uploads/projects/zitaoshuai@ygk615/b7f59649ec4e0f6ec29ffc1b9d7b0f39.svg) 开始已知计算梯度然后梯度下降,优化目标为:
开始已知计算梯度然后梯度下降,优化目标为: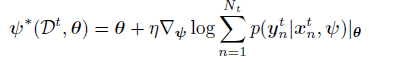
5.3 Metric-based few-shot learning

5.4 VERSA

5.5 Neural process

6. Continual learning
这个模型的想法是从一系列的不同分布的序列![[Book] Chap 18: Beyond iid assumption - 图45](/uploads/projects/zitaoshuai@ygk615/7597a96e56e149bd8ffe49b490695e5e.svg) 中学习,在每个时间点,系统收到一系列的有标签数据:
中学习,在每个时间点,系统收到一系列的有标签数据: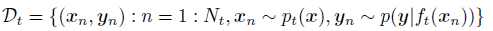
其中![[Book] Chap 18: Beyond iid assumption - 图47](/uploads/projects/zitaoshuai@ygk615/b00bbe2896c0dc41389ea73cdd8cb904.svg) 都是未知的(这里还有个假设是输入维度是不变的,事实上这也可以满足)
都是未知的(这里还有个假设是输入维度是不变的,事实上这也可以满足)
我们的学习器的目标是不断地在输入数据的情况下改进预测函数 f .
6.1 domain shift
例子: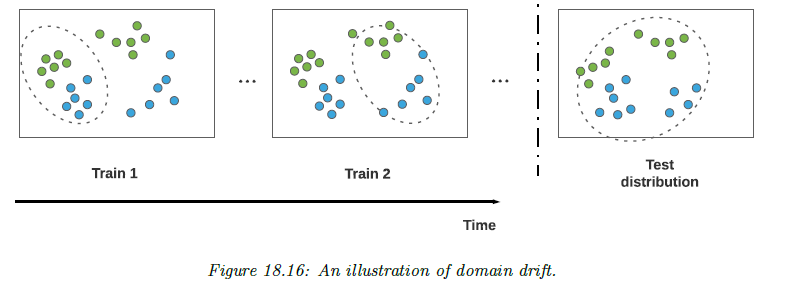
这里的问题是每次输入的 domain 都不一样,可能的问题是每一块数据对应的函数都不同。
6.2 concept drift
例子: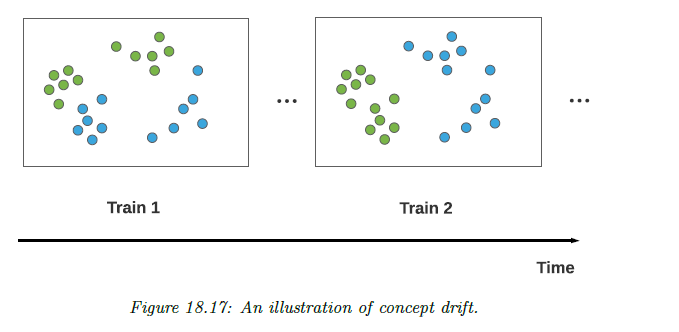
这里的问题是 concept 发生了变化,可以理解为 latent 变量的影响下,同样的 x ,带来了不同的 y。
6.3 task incremental learning
特点:每个时间点输入的数据的标签都是不同的,每个时间节点的数据输入都可以被看作是不同的任务,不过我们有一个静态的确定的 f 等待我们去学习。
根据是否有给出boundaries来确定是 discrete task-agnostic还是 task-aware continual learning问题
6.4 Problems
Catastrophic forgetting
这个主要是指随着时间推移,新的数据涌入,之前的数据上的结果会下降: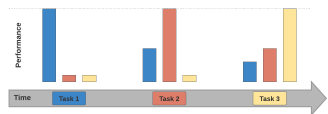
可塑性低
与之相反的问题就是可塑性低:(感觉两个似乎不会同时出现)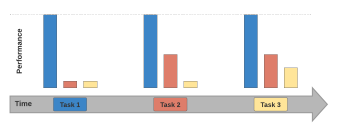
有人做实验证明了针对每个任务分开训练和使用 incremental training的效果一样好。
关于 transfer的评估指标是: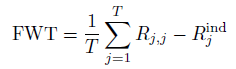
这里![[Book] Chap 18: Beyond iid assumption - 图53](/uploads/projects/zitaoshuai@ygk615/8c9853c0ff5e1d4245c9ca578891761e.svg) 代表在 task i 上面训练的模型在 task j 上面的表现结果
代表在 task i 上面训练的模型在 task j 上面的表现结果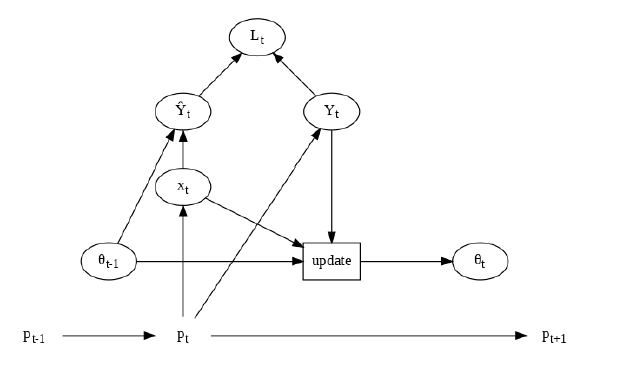
处理方法
为了解决第二个问题,有如下的几种方法:
为了解决第二个问题,有如下的几种方法:

若有收获,就点个赞吧
0 人点赞
