1. 集群规划
1. 我们需要多大规模的集群
- 思考方向:
- 当前的数据量有多大?数据增长情况如何?
- 你的机器配置如何?cpu、多大内存、多大硬盘容量?
推算依据:
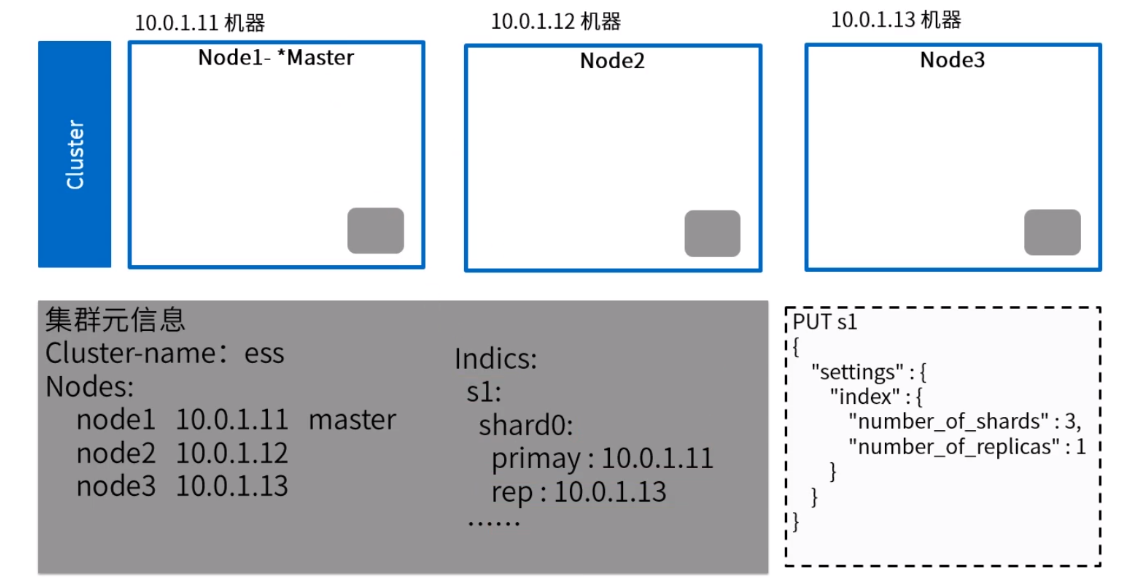
节点角色
- Master Node:设置
node.master: true时,节点可作为主节点。 - DataNode Node:设置
node.data: true时,可作为数据节点,默认值为 true。 - Ingest Node:默认都是预处理节点,配置
node.ingest: false来禁用。 - Coordinate Node:将上两个配置设置为 false 时,仅担任协调节点。
- Master Node:设置
如何分配?
为尽量避免脑裂,可配置:
discovery.zen.minimum_master_nodes: (有master资格节点数/2)+1。常用做法(中大规模集群):
思考问题
- 分片对应的存储实体是什么?
- 分片对应的存储实体是 Lucene 索引。
- 分片是不是越多越好,分片过多有什么影响?
- Lucene 索引,会消耗文件句柄、内存及 CPU 资源。
- 每个分片存储一部分词频统计信息,分片越多,每个分片存储的信息越少,计算出的得分与真实的得分偏差就会越大。
- 分片对应的存储实体是什么?
分片设置的可参考原则:
- Elasticsearch 推荐的最大 JVM 堆内存是 30-32G,所以把你的分片最大容量限制为 30G,然后再对分片数量做合理估算。例如,你认为的数据能达到 200GB,推荐你最多分配 7-8 个分片。
- 在开始阶段,一个好的方案是根据你的节点数量按照 1.5~3 倍的原则来创建分片。例如,如果你有 3 个节点,则推荐你创建的分片数最多不超过 9(3x3)个。当性能下降时,增加节点,ES 会平衡分片的放置。
- 对于基于日期的索引需求,并且对索引数据的搜索场景非常少。也许这些索引量将达到成百上千,但每个索引的数据量只有 1GB 甚至更小。对于这种类似场景,建议只需要为索引分配一个分片。
5. 分片应该设置几个副本?
思考
- 副本的用途是什么?备份数据,提高查询的并发度。
- 集群规模没变的情况下,副本过多会有什么影响? 占用磁盘存储,消耗写入性能(同步时间会更长),Lucene 索引消耗句柄、内存及 CPU 资源。
- 基本原则:

若有收获,就点个赞吧
0 人点赞
