- 1. ES 使用场景
- 2. ES 简介
- 3. ES 发展历程
- 4. ES 架构
- 5. ES 核心概念
- 6. ES Java Client
- 7. index alias 的应用
- 8. ES 核心操作
- 创建索引
- 删除索引
- 创建 index,指定 settings
- 获取 index 的 settings 信息
- 修改 index 的配置信息
- index 的配置分为两类:
- static(number of shards/index.shard.check_on_startup)
- dynamic(index 正常工作时,能修改的配置信息)
- index 开启状态,不允许执行
- 关闭 index
- 开启 index
- 获取 index 中的 mapping types
- 删除 mapping_type(不支持)
1. ES 使用场景
- Elasticsearch 是一个基于 Lucene 构建的开源、分布式、RESTful 接口全文检索引擎。
- Elasticsearch 也是一个分布式文档数据库。
- Elasticsearch 可以在很短的时间内存储、搜索大量数据。
- Elasticsearch 有很强的水平扩展能力。
3. ES 发展历程

4. ES 架构

5. ES 核心概念
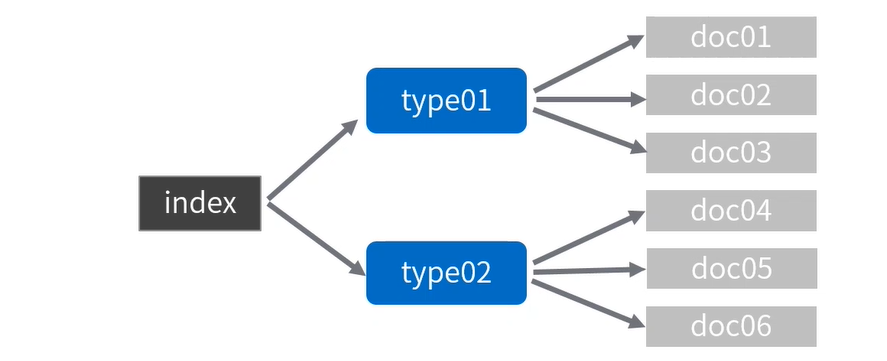
- 在 ES 最初的设计中,index 被当做类似 DB 的级别,能够对数据进行物理隔离,type 相当于数据库中的表,对数据进行逻辑划分,document 是 ES 中的一条数据记录。
- Java Low Level REST Client:低级别的 REST 客户端,通过 http 与集群交互,用户需自己编组请求 JSON 串,及解析响应 JSON 串。兼容所有 ES 版本。(https://www.elastic.co/guide/en/elasticsearch/client/java-rest/current/java-rest-low.html)
- Java High Level REST Client:高级别的 REST 客户端,基于低级别的 REST 客户端,增加了编组请求、解析响应等相关 api,High Level REST Client 中的操作 API 和 java client 大多数一样的。
- Java Client:ES 的发展规划中在 7.0 版本开始将废弃 TransportClient,8.0 版本中将完全移除 TransportClient,取而代之的是 High Level REST Client。
7. index alias 的应用
- 在 Elasticsearch 中给 index 起一个 alias(别名),能够非常优雅地解决两个索引无缝切换的问题。
- 可以使用同一个别名指向多个 index,可以实现同时查询多个索引的数据。
8. ES 核心操作
1. index 操作
删除索引
DELETE /songs_v3
创建 index,指定 settings
PUT /songs_v4 { “settings”: { “number_of_shards”: 6, “number_of_replicas”: 1 } }
获取 index 的 settings 信息
GET /songs_v4/_settings
修改 index 的配置信息
index 的配置分为两类:
static(number of shards/index.shard.check_on_startup)
dynamic(index 正常工作时,能修改的配置信息)
PUT /songs_v4/_settings { “number_of_replicas”: 2 }
index 开启状态,不允许执行
PUT /songs_v4/_settings { “index.shard.check_on_startup”: true }
关闭 index
POST /songs_v4/_close
开启 index
POST /songs_v4/_open
获取 index 中的 mapping types
GET /songs_v4/_mapping
删除 mapping_type(不支持)
DELETE /songs_v4/_mapping
<a name="f193004e"></a>#### 2. document 操作- 索引/查询/更新/删除 document、搜索 document、执行 script```java# 索引文档# 显示指定文档 IDPUT /songs_v4/_doc/5{"songName": "could this be love","singer": "Jennifer Lopez","lyrics": "Could This Be love, work up This Morning Just..."}# 随机生成文档 IDPOST /songs_v4/_doc{"songName": "could this be love","singer": "Jennifer Lopez","lyrics": "Could This Be love, work up This Morning Just..."}# 更新文档PUT /songs_v4/_doc/5{"songName": "could this be love","singer": "zp","lyrics": "Could This Be love, work up This Morning Just..."}# 根据 ID 明确查询某个文档GET /songs_v4/_doc/5# 根据 ID 删除文档DELETE /songs_v4/_doc/5# 搜索一个文档GET /songs_v4/_search?q=singer:JenniferGET /songs_v4/_mapping
9. 映射详解
1. 映射(mapping)操作
# 创建 index 后,创建 mapping
PUT /books
PUT /books/_mapping
{
"properties": {
"bookName": {"type": "text"},
"content": {"type": "text"}
}
}
GET /books/_mapping
DELETE /books
# 创建 index,并指定 mapping
PUT /books
{
"mappings": {
"properties": {
"bookName": {"type": "text"},
"content": {"type": "text"}
}
}
}
GET /books/_mapping
DELETE /books
# 给 mapping 添加字段
PUT /books/_mappings
{
"properties": {
"author": {"type": "text"}
}
}
GET /books/_mapping
2. 映射方式
- ES 中支持静态映射、动态映射两种方式。
- 通过 dynamic 字段来指定 mapping 的动态效果,dynamic 字段可以有如下选项: | 选项 | 有新增字段的文档索引时 | | —- | —- | | true(默认值) | mapping 会被更新 | | false | mapping 不会被更新,新增字段的数据无法被索引,_source 会存储新字段 | | strict | 直接报错 |
3. 字段类型
官网描述:https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-types.html
4. 映射参数
官网描述:https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-params.html
5. 分词器
https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-analyzers.html
在 ES 中,一个分析器(Analyzer)由下面三种组件组合而成。
当我们需要对一个字段进行多种不同方式的索引时,可以使用 fields 多重字段定义。如一个字符串字段既需要进行 text 分词索引,也需要进行 keyword 关键字索引来支持排序、聚合;或需要用不同的分词器进行分词索引。
PUT my_index { "mappings": { "properties": { "city": { "type": "text", "fields": { "raw": { "type": "keyword" } } } } } }
PUT my_index/_doc/1
{
"city": "New York"
}
PUT my_index/_doc/2
{
"city": "York"
}
GET my_index/_search
{
"query": {
"match": {
"city": "york"
}
},
"sort": [
{
"city.raw": {
"order": "asc"
}
}
],
"aggs": {
"citys": {
"terms": {
"field": "city.raw"
}
}
}
}
7. doc_values、fielddata、index
- doc_values:大多数字段进行了反向索引,因此可以用于搜索,但排序、聚合、scripts 操作等需要正向索引。
- fielddata:大多数字段可利用 doc_values 来进行排序、聚合、scripts 等操作,但 doc_values 不支持 text 字段,text 字段利用 fielddata 机制来替代。(常驻内存,非常昂贵)
- index:doc_values 指定文档是否进行正向索引,index 指定文档是否进行反向索引。
反向索引,词 -> 文章 | 词 | 内容包含该词的文章 id | | —- | —- | | zp | {1,2,5,6,8} | | 钓鱼岛 | {2,3,9,11} | | 火锅 | {1,2,8,9} | | 中国 | {2,9} |
正向索引,文章 -> 词 | 文章 id | Age 字段包含的关键词 | | —- | —- | | 1 | 24 | | 2 | 28 | | 3 | 24 | | 4 | 28 |
8. store
- 默认情况下,_source 会存储文档所有的字段,当一个字段的 store 属性设置为 true 时,ES 会单独存储一份该字段。
- 使用场景,比如书籍,content 字段会保存几百万个字符,在几百万字符中提取 name、author 是很麻烦的事情,所以会考虑将 content 字段通过 store 存储。
PUT books { "mappings": { "properties": { "name": {"type": "text"}, "author": {"type": "text"}, "content": {"type": "text", "store": true} }, "_source": { "excludes": [ "content" ] } } }
9. 元字段
| 字段名 | 说明 |
|---|---|
| _index | 文档所属的 index |
| _id | 文档的 id |
| _type | 文档所属的 type |
| _uid | _type#_id 的组合 |
| _source | 文档的原生 json 字符串 |
| _all | 自动组合所有的字段值,已过时 |
| _field_names | 索引了每个字段的名称 |
| _parent | 指定文档之间父子关系,已过时 |
| _routing | 将一个文档根据路由存储到指定分片上 |
| _meta | 用于自定义元数据 |
10. 同步 DB 数据到 ES
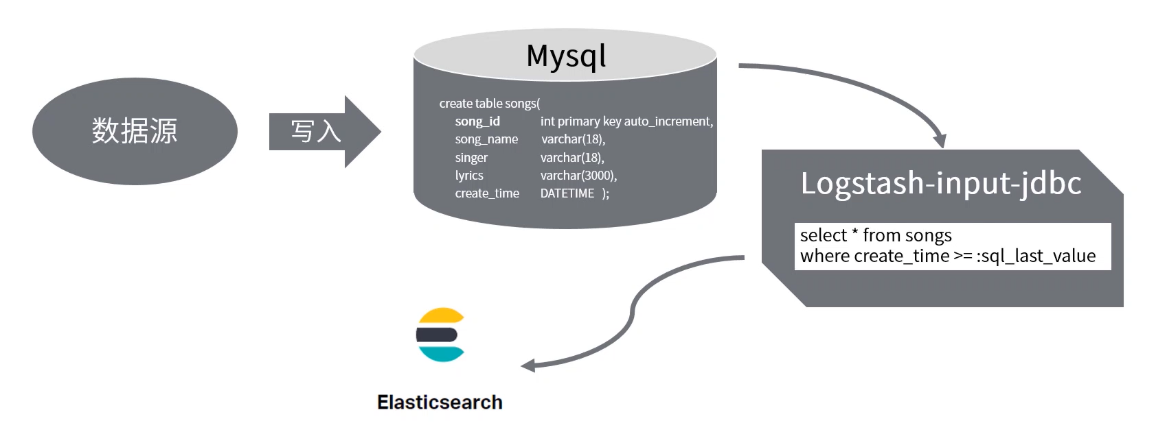
- 市面上讨论,将数据从 DB 同步到 ES 有 logstash-input-jdbc、go-mysql-elasticsearch、elasticsearch-jdbc,我们选用 logstash-input-jdbc 来实现数据迁移。
- 解压 logstash 安装包。
- 进入 bin 目录,执行命令:
./logstash -e 'input { stdin {} } output { stdout {} }'。 - 继续输入
HelloWorld,看到输出信息,即为安装成功。推出。 - 安装 ruby、gem。
修改 logstash 根目录下的 Gemfile 文件。(修改国内镜像)
source "http://gems.ruby-china.com"修改 logstash 根目录下的 Gemfile.lock 文件。(修改国内镜像)
GEM remote: http://gems.ruby-china.com安装 logstash-input-jdbc。
bin/logstash-plugin install logstash-input-jdbckibana 创建 songs_v11 索引。
PUT /songs_v11数据库创建 music 数据库,创建 songs 表
create database music; create table songs( song_id int primary key auto_increment, song_name varchar(18), singer varchar(18), lyrics varchar(3000), create_time datetime );配置 logstash-input-jdbc,创建 jdbc_conf 文件夹。
进入 jdbc_conf 文件夹,添加文件 jdbc.conf ``` input { stdin { } jdbc {
jdbc_connection_string => "jdbc:mysql://127.0.0.1:3306/music" jdbc_user => "music" jdbc_password => "music" jdbc_driver_library => "/root/mysql-connector-java-5.1.28.jar" jdbc_driver_class => "com.mysql.jdbc.Driver" jdbc_paging_enabled => "true" jdbc_page_size => "50000" statement => "select song_id, song_name, singer, lyrics, create_time from music.songs where create_time >= :sql_last_value" schedule => "* * * * *" type => "jdbc" lowercase_column_names => "false"} }
filter {}
output { elasticsearch { hosts => [“127.0.0.1:9200”] index => “songs_v11” document_id => “%{song_id}” template_overwrite => true } stdout { codec => json_lines } }
12. 启动 logstash
```shell
bin/logstash -f jdbc_conf/jdbc.conf
- 向 mysql 添加数据,然后查看 ES 索引看有没有数据。

若有收获,就点个赞吧
0 人点赞
