第 1 章 机器学习与sklearn
本章将通过介绍sklearn(scikit-learn)为读者展现机器学习能解决的问题和解决这些问题的合理方案。sklearn是基于Python语言的机器学习工具,建立在NumPy、SciPy和Matplotlib三大工具包之上。在使用sklearn的过程中,建议阅读一下它的源代码,这样能够加深对算法的理解,提升编程水准。
sklearn提供了分类、回归、聚类和降维4个类别的经典模型。对于如何根据数据和任务来选择合适的方法,sklearn官网提供了一张经典的思维导图,如图1-1所示,其中的思路如下。
- 如果数据量小于50,一般是无法使用sklearn的机器学习算法建模的,因为机器学习需要借助统计数据才能完成。
- 如果数据有类别标签,请使用分类模型。
- 如果数据需要预测精确值,请使用回归模型。
- 如果想查看数据分布情况,可以考虑使用降维算法。
- 如果数据没有类别标签,可以使用聚类算法。

图 1-1 sklearn算法选择指导图
1.1 sklearn环境配置
如果你使用的Python环境是Anaconda,那么默认已经安装了sklearn。考虑到有些读者并没有使用Anaconda,这里还是介绍一下如何使用pip安装sklearn及其依赖库。
1.1.1 环境要求
本书中使用的sklearn版本号为0.21.3,该版本对环境有如下的要求:
- Python版本号大于等于3.5;
- NumPy版本号大于等于1.11.0;
- SciPy版本号大于等于0.17.0;
- joblib版本号大于等于0.11;
- Matplotlib版本号大于等于1.5.1;
- scikit-image版本号大于等于0.12.3;
- pandas版本号大于等于0.18.0。
如果你的Python版本是Python 3.4及以下,请使用sklearn 0.20以下的版本。
1.1.2 安装方法
安装sklearn时,只需执行以下命令:
pip install scikit-learn
此时pip会自动安装sklearn的依赖库。如果想批量指定依赖库的版本,可以写一个requirements.txt文件,其内容如下:
scipy==0.17.0joblib==0.11matplotlib==1.5.1scikit-image==0.12.3pandas==0.18.0
然后使用如下指令一次性安装:
pip install -r requirements.txt
至于NumPy库,如果你想提升计算性能,建议下载与自己的Python版本对应的NumPy库和MKL库。
1.1.3 修改pip源
在使用pip的过程中,经常会出现下载速度缓慢,或者干脆无法下载的情况。就像下面这样,速度非常慢,或者一直提示Retrying:
100% |████████████████████████████████| 5.9MB 13kB/sCollecting numpy>=1.11.0 (from scikit-learn->sklearn)Retrying (Retry(total=4, connect=None, read=None, redirect=None, status=None)) after connection brokenby 'ReadTimeoutError("HTTPSConnectionPool(host='pypi.org', port=443): Read timed out. (read timeout=15)")': /simple/numpy/
如果你在使用pip进行下载和安装的过程中出现了上述情况,那么尝试将pip源修改为国内源,可以大幅提高下载速度。
在Windows环境下修改pip源的方法如下。
(1) 在资源管理器中,输入%appdata%,会自动进入AppData/Roaming文件夹。
(2) 在这个文件夹中新建一个pip文件夹。
(3) 在pip文件夹下新建pip.ini文件。
(4) 在pip.ini文件中输入如下内容:
[global]index-url = https://pypi.tuna.tsinghua.edu.cn/simple
(5) 再次使用pip,即可享用国内源超高的下载速度:
H:\MachineLearning-Python >pip install numpyLooking in indexes: https://pypi.tuna.tsinghua.edu.cn/simpleCollecting numpyDownloading https://pypi.tuna.tsinghua.edu.cn/packages/bd/51/7df1a3858ff0465f760b482514f1292836f8be08d84aba411b48dda72fa9/numpy-1.17.2-cp37-cp37m-win_amd64.whl (12.8MB)100% |████████████████████████████████| 12.8MB 1.7MB/sInstalling collected packages: numpySuccessfully installed numpy-1.17.2
修改之后,速度直接提升至原来的一百多倍。若上述源的速度还是不够快,可以切换成其他国内源。目前,国内的pip源主要有下面几个。
- 阿里云:http://mirrors.aliyun.com/pypi/simple/。
- 豆瓣:http://pypi.douban.com/simple/。
- 清华大学:https://pypi.tuna.tsinghua.edu.cn/simple/。
- 中国科学技术大学:http://pypi.mirrors.ustc.edu.cn/simple/。
在Linux系统下修改pip源的操作和前面类似。以Ubuntu为例,只需执行以下指令:
mkdir ~/.pipvim ~/.pip/pip.conf
然后写入pip源的内容即可:
[global]index-url = https://pypi.tuna.tsinghua.edu.cn/simple
1.1.4 安装Jupyter Notebook
Jupyter Notebook是一种网页形式的编程工具,能够在网页中直接编写和运行代码,并实时显示代码的运行结果。同时Jupyter Notebook支持Markdown语法,可以将代码说明和代码混合在一起。
对于机器学习工作者来说,使用Jupyter Notebook一般出于以下3个目的。
- 编写小段需要图像展示的案例。
- 分阶段运行代码,检测代码中的错误(这对于计算机视觉算法来说尤其方便)。
- 在服务器上远程编写代码。给予 Jupyter Notebook的网页服务的特性,我们可以很轻松地在自己的计算机上访问服务器上运行的Jupyter Notebook。
Jupyter Notebook的安装过程很简单,可以直接使用pip安装(Anaconda中自带Jupyter Notebook):
pip install jupyter
安装完成之后,在终端或cmd.exe中输入:
jupyter notebook
此时Jupyter Notebook会自动打开计算机中的默认浏览器,可以看到如图1-2所示的网页。

图 1-2 Jupyter Notebook
点击New→Python 3之后,就会自动创建一个Notebook,如图1-3所示。

图 1-3 Notebook
进入Notebook之后,就可以在代码块中编写代码了。如图1-4所示,借助“魔法命令”%matplotlib inline,就可以轻松地在Notebook中做图形展示了。

图 1-4 Jupyter Notebook编程示例
因为工具操作简单,这里不再赘述,本书后面用到Jupyter Notebook的部分会单独说明。
1.2 数据集
人工智能的核心在于数据支持,近几年人工智能技术的快速发展与大数据技术的发展密切相关,大数据技术可以通过数据采集、分析及挖掘等方式,从海量复杂数据中快速提取出有价值的信息,为机器学习算法提供牢固的基础。
在机器学习任务中,数据集有三大功能:训练、验证和测试。
- 训练最好理解,是拟合模型的过程,模型会通过分析数据、调节内部参数从而得到最优的模型效果。
- 验证即验证模型效果,效果可以指导我们调整模型中的超参数(在开始训练之前设置参数,而不是通过训练得到参数),通常会使用少量未参与训练的数据对模型进行验证,在训练的间隙中进行。
- 测试的作用是检查模型是否具有泛化能力(泛化能力是指模型对训练集之外的数据集是否也有很好的拟合能力)。通常会在模型训练完毕之后,选用较多训练集以外的数据进行测试。
所以在机器学习(尤其是深度学习)任务开始前,需要收集大量高质量的数据,对于个人开发者来说,数据只能来源于开源的数据集和自己编写爬虫程序采集到的数据集,收集数据是一个费时费力的过程。
为了方便初学者学习以及进行小规模的算法测试,sklearn提供了不少小型的标准数据集和一些规模略大的真实数据集。除这些数据集之外,sklearn还能够按照一定规则自己生成数据集。3种类型的数据集分别通过load***、fetch***和make***这3种函数形式获取,下面将对这几个接口做简单介绍。
1.2.1 自带的小型数据集
sklearn中最常用的数据集有3个:load_iris、load_boston和load_digits。
直接从sklearn.datasets中导入load_iris,得到的数据是字典形式,可以通过字典中的键值选择数据的各项属性。
load_iris是加载鸢尾花数据集的函数,该数据集包含了150条鸢尾花数据,其中包含的鸢尾花数据(在机器学习中,这种可以直接用于建模的数据叫作特征)有4种:
- 鸢尾花的花瓣长度(cm);
- 鸢尾花的花瓣宽度(cm);
- 鸢尾花的花萼长度(cm);
- 鸢尾花的花萼宽度(cm)。
标签是鸢尾花的种类,3个种类分别用0、1和2表示。下面是load_iris的使用方法:
>>> d = load_iris()>>> d.keys()dict_keys(['data', 'target', 'target_names', 'DESCR', 'feature_names', 'filename'])>>> # 鸢尾花的类别名>>> d['target_names']array(['setosa', 'versicolor', 'virginica'], dtype='<U10')>>> # 特征名称>>> d['feature_names']['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']>>> d['data'].shape(150, 4)>>> set(list(d['target'])){0, 1, 2}
在上述代码中,通过load_iris函数取出了鸢尾花数据并将其赋值给d,通过keys方法查看数据集中各个项目的名称,如鸢尾花的类别名(target_names)、特征名(feature_names)、数据(data)与标签(target)等。
load_boston是关于波士顿房屋特征与房价之间关系的数据集,包含13个房屋特征,是一个进行入门回归训练的好例子。下面是load_boston的使用方法:
>>> data = load_boston()>>> # 房屋特征名称>>> data['feature_names']array(['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD','TAX', 'PTRATIO', 'B', 'LSTAT'], dtype='<U7')>>> data['data'].shape(506, 13)
从上述代码中可以看到,load_boston中共有506个样本,每条数据中包含了房屋和房屋周边的13个重要信息,如城市犯罪率、环保指标、周边老房子的比例、是否临河等。
load_digits是一个比MNIST更小的手写数字图片数据集,里面的图片尺寸是8像素×8像素(后面将省略单位),通过如下代码可以查看手写数字图片:
>>> g = sklearn.datasets.load_digits()>>> plt.imshow(g['data'][0].reshape(8,8),cmap='gray')<matplotlib.image.AxesImage object at 0x7f07e42ddeb8>>>> plt.show()
输出图片如图1-5所示,因为是8×8的图片,所以看起来不是很清晰。

图 1-5 手写数字
1.2.2 在线下载的数据集
Fetch系列函数用于获取较大规模的数据集,这些数据集会自动从网上下载,得到的数据格式与load***一样,是字典形式。我们可以自定义下载目录,同时可以选择单独下载训练集或者测试集,常用的数据集如下。
- 人脸数据集:
fetch_olivetti_faces和fetch_lfw_people。 - 文本分类数据集:
fetch_20newsgroups。 - 房价回归数据集:
fetch_california_housing。
1.2.3 计算机生成的数据集
用sklearn生成的数据集可以用来测试一些基础的模型功能,比如多分类数据集、聚类数据集以及高斯分布数据集等。还有一些特殊形状的数据集,比如make_circles和make_moons等,示例如下:
>>> circle = make_circles()[0]>>> # 创建子图>>> plt.subplot(121)<matplotlib.axes._subplots.AxesSubplot object at 0x000000001719BE80>>>> # 绘制散点图>>> plt.scatter(circle[:,0],circle[:,1])<matplotlib.collections.PathCollection object at 0x000000002081D828>>>> moon = make_moons()[0]>>> plt.subplot(122)<matplotlib.axes._subplots.AxesSubplot object at 0x000000002081D048>>>> plt.scatter(moon[:,0],moon[:,1])<matplotlib.collections.PathCollection object at 0x0000000017171D30>>>> plt.show()
上述代码的作用是通过make_circles和make_moons函数生成两组坐标点数据,并使用plt.scatter函数将生成的坐标点绘制成散点图。生成的散点图如图1-6所示,其他数据集详情请参考sklearn官网。
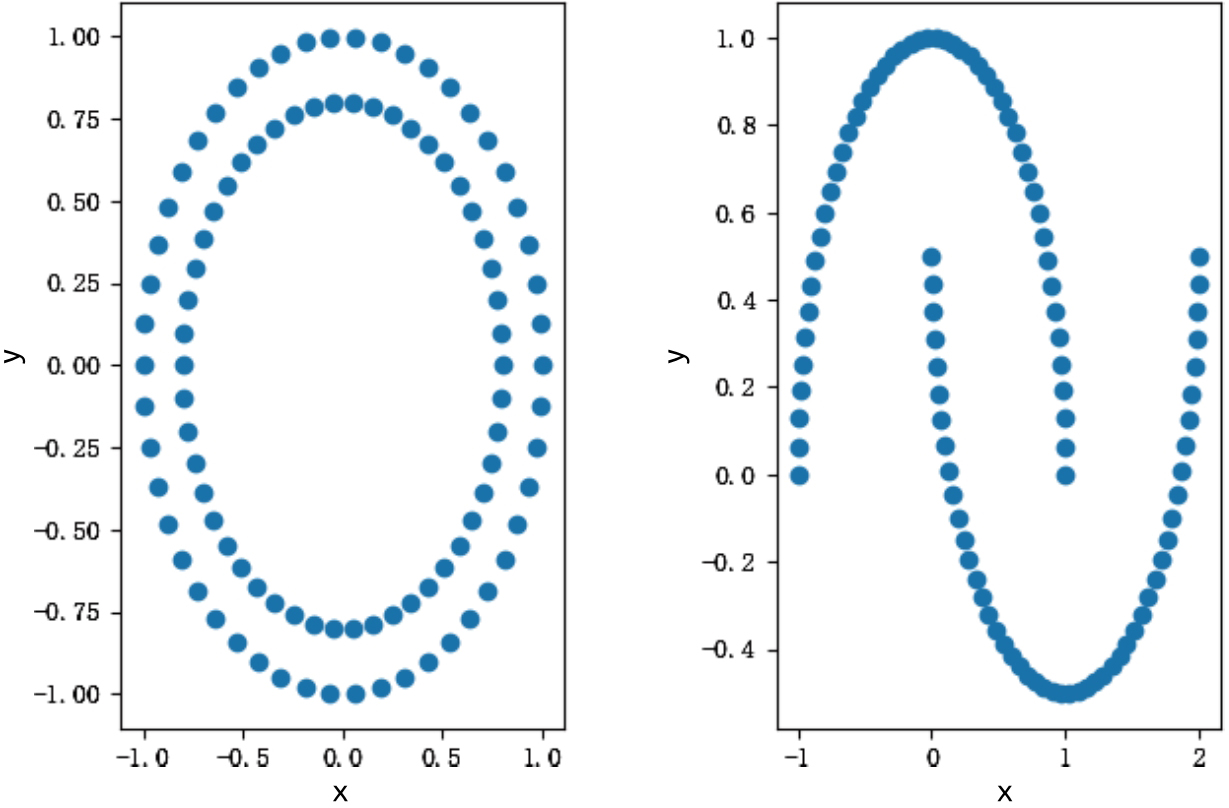
图 1-6 生成的散点图
1.3 分类
其实在生活中,我们不经意间就能完成一个分类任务,能轻易判断一个人是男的还是女的,一朵花是红色的还是黄色的……这种将一个事物归入特定类别的过程叫作分类。现在越来越多的智能手机开始支持垃圾短信识别、人脸识别等功能,这些都是机器学习完成分类任务的实例。
分类是机器学习中一种重要的方法,该方法能够将数据库中的数据记录映射到某个给定的类别,从而用于数据预测。分类问题是机器学习的基础,很多问题都可以转化成分类问题来解决,比如本书将会介绍的图像分割问题,就可以转化成像素级别的分类问题来求解。
分类器是机器学习中对样本进行分类的方法的统称。sklearn中提供了许多定义好的分类器,常用的几种模型及其优缺点如下。
K 近邻分类
:该方法的思路是,如果数据库中与某个样本最相似的
K
个样本大多数属于某一类别,那么这个样本也属于这个类别。- 缺点:K 值是一个超参数,需要人为指定,并且算法复杂度较高。
- 优点:这是一个无须训练的无参数模型。
逻辑回归
:一种广义的线性回归分析模型,线性回归是找到一条与数据最接近的线(或一个超平面),而逻辑回归是找到能够将不同类别数据分割开的线(或超平面)。- 缺点:容易受到噪声影响。
- 优点:模型简单,且可以使用梯度下降实现增量式训练。
朴素贝叶斯
:朴素贝叶斯算法是基于贝叶斯理论和特征条件独立性假设,利用概率统计知识对样本数据集进行分类的方法。- 缺点:使用了独立性假设,对于关联性较强的数据效果比较差。
- 优点:简化了概率计算,节约了时间和内存。
SVM(支持向量机)
:支持向量机也是一种广义线性分类器,模型的思路是寻找最大几何间隔的分类界面。- 缺点:计算速度较慢。
- 优点:受噪声影响较小。
决策树
:一种通过对数据进行归纳总结,生成分类规则的算法。- 缺点:训练比较耗时,容易过拟合。
- 优点:可解释性好,能适应各种形式的训练数据。
集成型的分类器
:如随机森林、GBDT、Adaboost等。集成分类器的思路是通过多个小型弱分类器组合成一个强分类器。- 缺点:训练速度较慢。
- 优点:模型精度较高,且不容易过拟合。
有这么多分类器,该如何选择呢?可以参考Fern在2014年发表的论文“Do we Need Hundreds of Classifiers to Solve Real World Classification Problems”,该论文使用了121种公开数据集对17个大类(朴素贝叶斯、决策树、神经网络、SVM、K 近邻分类、基于boosting/bagging/stacking的集成算法、逻辑回归等)中的179种分类模型进行测试,结果很具有参考意义。
为了让读者对sklearn中的分类模型建模有一个直观的认识,下面展示一下使用sklearn进行鸢尾花数据集分类的流程。
1.3.1 加载数据与模型
首先从sklearn.datasets中加载数据,然后从sklearn.linear_model中加载逻辑回归模型。加载并整理鸢尾花数据集和逻辑回归模型的代码如下:
>>> from sklearn.datasets import load_iris>>> # 导入逻辑回归模型>>> from sklearn.linear_model import LogisticRegression>>> import matplotlib.pyplot as plt>>> data = load_iris()>>> data.keys()dict_keys(['data', 'target', 'target_names', 'DESCR', 'feature_names', 'filename'])>>> x = data['data']>>> y = data['target']
上述代码从sklearn中的linear_model模块中导入了LogisticRegression类,并利用load_iris函数加载了鸢尾花数据集,加载数据集之后将数据集分为了特征x和标签y两个部分。
1.3.2 建立分类模型
这里选择的分类器是逻辑回归模型。逻辑回归中的所有参数都有预设的默认值,在对精度要求不高的情况下,直接使用默认参数即可。
下面是逻辑回归中的可选参数:
LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,intercept_scaling=1, l1_ratio=None, max_iter=100,multi_class='warn', n_jobs=None, penalty='l2',random_state=None, solver='warn', tol=0.0001, verbose=0,warm_start=False)
其中常用的参数有如下几个。
penalty:正则化参数,用于给损失函数(后面PyTorch部分会介绍到)添加惩罚项,避免模型过拟合。可以选择的有L1正则化和L2正则化,默认是L2。solver
:根据损失函数对模型参数进行调整的算法,有liblinear
、
lbfgs
、
newton-cg
和
sag
等4种选择。
liblinear:使用坐标轴下降法来迭代优化损失函数,因为L1正则项的损失函数不是连续可导的,所以只能使用这种方法。L2正则项的函数连续可导,所以4种方法都可以选择。lbfgs和newton-cg都属于牛顿迭代法,利用损失函数二阶导数矩阵(即海森矩阵)来迭代优化损失函数。sag:随机平均梯度下降,是梯度下降法的变种,和普通梯度下降法的区别是每次迭代仅用一部分样本来计算梯度。multi_class:有ovr和multinomial两种方式,ovr速度较快,精度略差,multinomial会进行多次分类,速度较慢,精度较高。
class_weight:用于应对样本类别不平衡的情况,可以设置为balanced,模型会自动根据对应类别的样本数量计算应该分配的权重。部分业务场景会特别看重模型对某个特定类别的识别能力,这时可以通过class_weight来调节。sample_weight:与class_weight类似,可以在样本不平衡的情况下与class_weight协同作用。
使用默认参数创建逻辑回归模型只需要如下代码:
>>> clf = LogisticRegression()
1.3.3 模型的训练及预测
sklearn中对模型进行了统一的接口封装,几乎所有的模型训练都只需要调用fit方法,即使对模型内部原理一无所知,也可以轻松使用。
与训练模型类似,只需要调用predict方法即可得到模型根据输入x得到的预测结果。模型训练和预测的代码如下:
>>> clf.fit(x,y)>>> y_pred = clf.predict(x)
1.3.4 模型评价
模型训练和预测都完成之后,就需要对模型进行评价了,在模型评价指标中最常用也最容易计算的就是准确率accuracy:
>>> accuracy = sum(y_pred == y) / len(y)>>> accuracy0.96
但是,准确率在样本不平衡的情况下不能真实地反映模型的效果,比如样本中有1个10和90个0,那么模型只需要将所有样本都预测成0就可以获得90%的准确率了,这显然是不合理的。所以在分类模型中,通常会综合考虑多个指标,sklearn中提供了classification_report函数来评价分类模型的效果,代码如下:
>>> from sklearn.metrics import classification_report>>> classification_report(... y, y_pred, target_names=["setosa", "versicolor", "virginica"]... )
得到的结果如下:
precision recall f1-score supportsetosa 1.00 1.00 1.00 50versicolor 0.98 0.90 0.94 50virginica 0.91 0.98 0.94 50accuracy 0.96 150macro avg 0.96 0.96 0.96 150weighted avg 0.96 0.96 0.96 150
其中比较常用的指标有3个:precision(精确率)、recall(召回率)和f1-score(平衡F分数)。为了让大家更好地理解这3个指标,我们先介绍4种分类情况。
TP:正例被预测为正例。FP:负例被预测为正例。FN:正例被预测为负例。TN:负例被预测为负例。
以鸢尾花setosa为例,TP表示这朵花本来是setosa,被预测成了setosa;FP表示这朵花本来不是setosa,被预测成了setosa;FN表示这朵花本来是setosa,被预测成了别的花;TN表示这朵花本来不是setosa,预测结果也不是setosa。
precision和recall的计算公式如下:
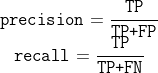
借助以上概念,我们也可以将准确率表示出来:
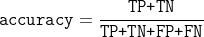
f1-score是precision和recall的调和平均值,公式为:

可以综合反映两个指标的好坏。
当分类模型中的类别数量不太多时,可以通过混淆矩阵来更加直观地查看分类情况,得到混淆矩阵之后,可以利用matplotlib将混淆矩阵以图片的形式画出,计算并绘制混淆矩阵的代码如下:
>>> from sklearn.metrics import confusion_matrix>>> c = confusion_matrix(y,y_pred)>>> # 横纵坐标轴刻度>>> xlocations = [0,1,2]>>> ylocations = xlocations>>> labels = data['target_names']>>> # 使用文字替换刻度>>> plt.xticks(xlocations,labels)([<matplotlib.axis.XTick object at 0x7f47e01fe240>, <matplotlib.axis.XTick object at 0x7f47e01f5b38>, <matplotlib.axis.XTick object at 0x7f47e01f5860>], <a list of 3 Text xticklabel objects>)>>> plt.yticks(ylocations,labels)([<matplotlib.axis.YTick object at 0x7f47e0203080>, <matplotlib.axis.YTick object at 0x7f47e01fe8d0>, <matplotlib.axis.YTick object at 0x7f47e01f5898>], <a list of 3 Text yticklabel objects>)>>> # 设置坐标轴名称>>> plt.ylabel("True label")Text(0, 0.5, 'True label')>>> plt.xlabel("Predict label")Text(0.5, 0, 'Predict label')>>> plt.imshow(c)<matplotlib.image.AxesImage object at 0x7f47e01f54e0>>>> plt.show()
混淆矩阵展示如图1-7所示,横轴是预测标签,纵轴是真实标签。其中颜色最浅的部分是出现频次最多的情况,颜色最深的部分是出现频次最低的情况。我们可以看到,setosa品种分类情况最好,几乎所有的setosa品种的鸢尾花都被正确分类了。versicolor品种的鸢尾花分类效果最差,有不少versicolor鸢尾花被分类成了virginica鸢尾花。
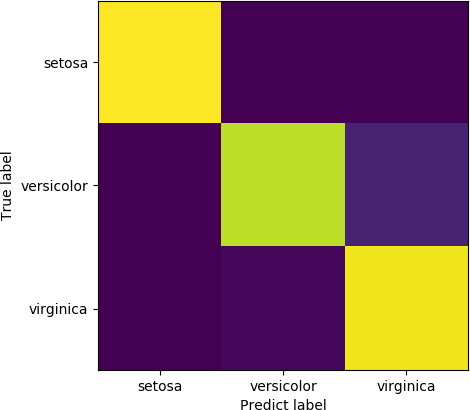
图 1-7 混淆矩阵
1.4 回归
回归是研究一组随机变量(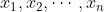 )和另一组随机变量(
)和另一组随机变量(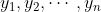 )之间关系的统计分析方法。分类问题预测的是样本所属的有限个类别,其预测目标是离散的,而回归问题预测的是样本的某项属性值,此属性值的取值范围可能有无限多个,其预测目标是连续的。比如在天气预报中,预测明天是晴天还是雨天,是一个分类问题,而预测明天的气温是多少度,就是一个回归问题了。
)之间关系的统计分析方法。分类问题预测的是样本所属的有限个类别,其预测目标是离散的,而回归问题预测的是样本的某项属性值,此属性值的取值范围可能有无限多个,其预测目标是连续的。比如在天气预报中,预测明天是晴天还是雨天,是一个分类问题,而预测明天的气温是多少度,就是一个回归问题了。
在sklearn中,也提供了众多的回归模型,其中常用的回归模型有:线性回归、岭回归、LASSO回归、SVR、回归决策树等。
1.4.1 线性回归
下面以1.2.1节中提到的波士顿房价数据集演示线性回归模型的建模流程,基本与分类模型一致:
>>> from sklearn.datasets import load_boston>>> from sklearn.linear_model import LinearRegression>>> data = load_boston()>>> clf = LinearRegression()>>> x = data['data']>>> y = data['target']>>> # 训练模型... clf.fit(x,y)LinearRegression(copy_X=True, fit_intercept=True, n_jobs=None, normalize=False)>>> # 只预测一部分值便于画图... y_pred = clf.predict(x[:20])>>> # 绘制房价曲线... plt.figure(figsize=(10,5))<Figure size 1000x500 with 0 Axes>>>> plt.plot(y_pred,linestyle = '--',color = 'g')[<matplotlib.lines.Line2D object at 0x0000000011A284A8>]>>> plt.plot(y[:20],color = 'r')[<matplotlib.lines.Line2D object at 0x000000001384BB00>]>>>>>> plt.show()
上述代码利用load_boston函数导入了波士顿房价数据集,并将数据集分成了x和y两个部分,整理好数据集之后,利用LinearRegression类中的fit和predict方法完成了线性回归模型的训练与预测,并将预测结果绘制成折线图展示出来。预测结果的折线图如图1-8所示。
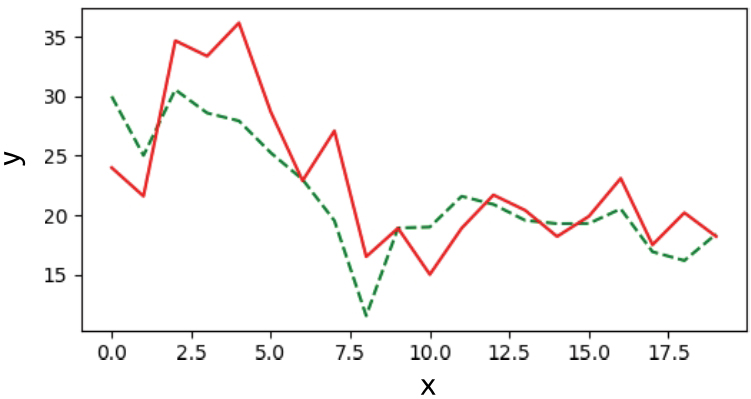
图 1-8 房价预测曲线
我们可以看到,预测出来的房价(虚线)和真实房价(实线)之间的整体趋势相近,但是部分点有较大差距。为了更精确地描述回归模型的建模效果,我们需要有确定的评价指标。
1.4.2 回归模型评价
常用的回归模型的评价指标有3个。
均方误差(
mean_squared_error)。预测值与真实值之间的误差的平方的平均值,其公式如下:
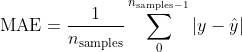
决定系数(
r2_score)。决定系数的分母为原始数据的离散程度,分子为预测数据与原始数据之间的误差,二者相除可以消除原始数据离散程度的影响。决定系数用于表示回归值对真实值的拟合程度,其值越接近于1,表示拟合效果越好,其公式如下:}(y,{\hat%20y}%29=1-\dfrac{\sum\nolimits2}{\sum\nolimits2})
在sklearn中使用3个评价指标的示例代码如下:
from sklearn.metrics import mean_squared_error,mean_absolute_error,r2_scorey_pred = clf.predict(x)print("MSE",mean_squared_error(y_pred,y))print("MAE",mean_absolute_error(y_pred,y))print("r2_score",r2_score(y_pred,y))
结果如下:
MSE 21.894831181729202MAE 3.2708628109003137r2_score 0.6498212316698562
1.5 聚类
聚类指的是将数据集合中相似的对象分成多个类的过程,与分类不同的是,聚类的训练数据是没有类别标签的,这种没有预设标签的机器学习任务被称为非监督学习,而分类和回归这种有标签的机器学习任务称为监督学习。
在聚类任务中,预先并不知道有多少个类别、每个类别是什么,我们的目的只是将相似的样本归入同一类,不同的样本归入不同的类,组内的样本相似度越大,组间的样本相似度越小,聚类效果就越好。
在商铺价格评估的研究项目中,会根据商铺的地理位置将商铺划入不同的商圈,然而商圈的边界往往是不规则的,很难人工划定,这时就可以使用无监督学习的方式,根据商铺距离商业中心的距离或交通时间等属性进行聚类,在一个城市中划分出几个不同的商圈。
sklearn中提供的聚类算法有:K-means、Affinity Propagation、Meanshift、DBSCAN、Gaussian Mixtures等,下面介绍两种比较常用的聚类算法,分别是K-means和DBSCAN。
1.5.1 K-means
K-means聚类算法是一种迭代求解的聚类分析算法。K-means算法需要预先设定总类别数量n_clusters。如果类别数量设置得不够好的话,最终的聚类结果可能会不太理想。
K-means的训练思路如下。
(1) 随机选定n_clusters个中心点(因为K-means的聚类效果受初始点的位置影响很大,所以可以使用特殊的初始化策略,如K-means++)。
(2) 将数据集中的数据根据到各中心点的距离归入不同聚类(靠近哪个中心点就归为哪一类)。
(3) 根据聚类结果重新计算每个聚类的中心点。
(4) 重复第(2)步~第(3)步,直到每个聚类的内部元素不再变化为止,最后得到的所有中心点坐标即为训练得到的模型参数。
1.5.2 DBSCAN
DBSCAN是一种基于密度的聚类算法,不需要设置类别数量,但是需要设置类内样本的最大可接受距离,这个算法对空间样本聚类效果较好。另外,DBSCAN聚类过程中不一定能把所有的样本都划入到聚类中去,可能会存在一些无法聚类的离群点。
DBSCAN的训练思路如下。
(1) 先设定好DBSCAN中的最短聚类距离eps,从数据集中任一点开始,寻找周围到此点距离小于eps的点,加入当前聚类。
(2) 加入新的数据点之后,再从新的数据点出发继续寻找距离小于eps的点,如此循环往复。
(3) 如果当前点的eps半径范围内没有未加入聚类的数据点,则跳到当前聚类外任意未被聚类的点,继续搜索新的聚类。
(4) 对于周围eps范围内没有任何数据点的数据,归为离群点。
1.5.3 聚类实例
为了展示两种算法的区别,这里分别选择make_moons和make_blobs生成的数据集进行聚类演示,代码如下:
>>> import matplotlib.pyplot as plt>>> from sklearn.datasets import make_moons,make_blobs>>> from sklearn.cluster import KMeans,DBSCAN>>> # 创建数据集>>> # data = make_moons()... data = make_blobs(centers = 2)>>> model_km = KMeans(n_clusters=2)>>> model_db = DBSCAN()>>> x = data[0]>>> # 模型预测>>> y_pred_km = model_km.fit_predict(x)>>> y_pred_db = model_db.fit_predict(x)>>> markers = ["x","s","^","h","*","<"]>>> colors = ['r','g','b','y','o','tomato']>>> plt.subplot(121)<matplotlib.axes._subplots.AxesSubplot object at 0x000000000D8A8668>>>> plt.title("KMeans")Text(0.5, 1.0, 'KMeans')>>> for i,y in enumerate(y_pred_km):... plt.scatter(x[i,0],x[i,1],marker=markers[y],color = colors[y])...>>> plt.subplot(122)<matplotlib.axes._subplots.AxesSubplot object at 0x000000000FB7ECF8>>>> plt.title("DBSCAN")Text(0.5, 1.0, 'DBSCAN')>>> for i,y in enumerate(y_pred_db):... if y != -1:... plt.scatter(x[i,0],x[i,1],marker=markers[y],color = colors[y])...... else:... plt.scatter(x[i,0],x[i,1],marker=markers[y],color = "black")
上述代码使用了make_moons和make_blob函数生成的数据集进行了聚类实验,利用生成的数据集训练了两个聚类模型——K-means模型和DBSCAN模型,利用聚类模型对数据进行了聚类,最后将属于不同聚类的数据使用不同的标记在图中绘出,结果如图1-9和图1-10所示。
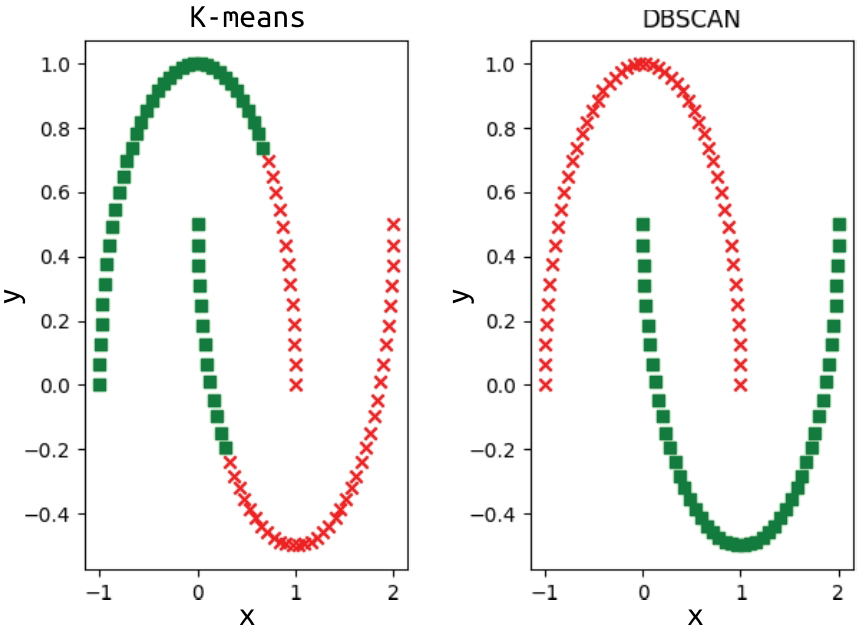
图 1-9 make_moons聚类结果1
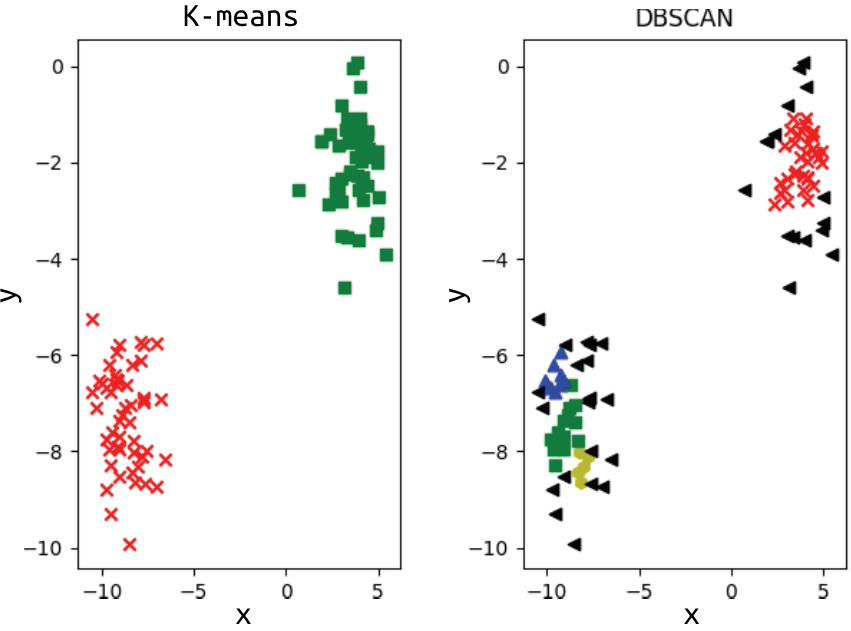
图 1-10 make_blobs聚类结果2
从图1-9和图1-10中可以看出以下两点。
- K-means比较适合对呈团聚形态的数据进行聚类,对形状不规则的数据进行聚类的效果较差。
- DBSCAN对数据的聚集形式有较好的适应性,但是DBSCAN的距离阈值设置不合理的话,难以得到很好的聚类效果。这一点跟K-means的聚类中心数量选择比较类似,都依赖于对样本的了解。
1.6 降维
降维算法即将高维数据投射到低维空间,并尽可能地保留最多的信息。这类算法既可以用于去除高维数据的冗余信息,也可以用于数据的可视化。比如我们可以使用降维算法将鸢尾花数据集的数据分布情况直观地展现出来。鸢尾花数据本身有4个特征,也就是一个四维空间的数据,因为四维空间是无法直接观测的,所以需要将数据降到三维空间才可以查看。
1.6.1 PCA降维
首先可以尝试使用最常用的降维方法PCA(主成分分析)对鸢尾花数据集进行降维展示,将数据集从四维降到三维的代码如下:
>>> from sklearn.datasets import load_iris>>> from sklearn.decomposition import PCA>>> from mpl_toolkits.mplot3d import Axes3D>>> data = load_iris()>>> x = data['data']>>> y = data['target']>>> # n_components表示主成分维度>>> pca = PCA(n_components=3)>>> # 将数据降成三维>>> x_3d = pca.fit_transform(x)>>> fig = plt.figure()>>> plt.subplot(121)<matplotlib.axes._subplots.AxesSubplot object at 0x000000000FDA3860>>>> ax = Axes3D(fig)>>> for i,item in enumerate(x_3d):... ax.scatter(item[0],item[1],item[2],color = colors[y[i]],marker = markers[y[i]])...>>> plt.show()
上述代码中的fit_transform方法将模型训练和数据转换合并在一起,方便调用。降维后,三维鸢尾花数据如图1-11所示。
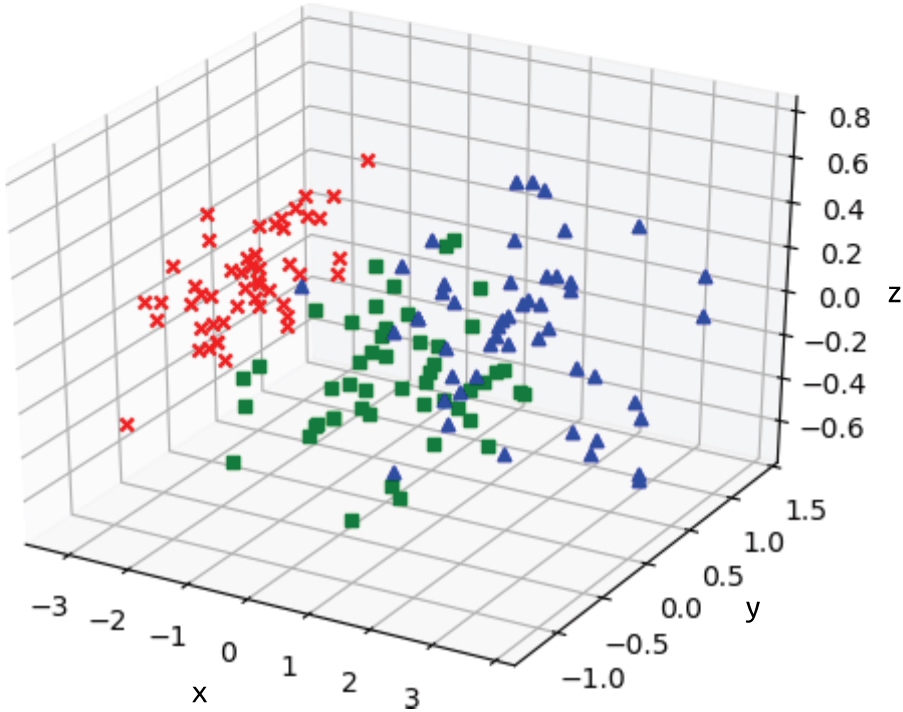
图 1-11 使用PCA将鸢尾花数据集降维至三维
在图1-11所示的三维空间中我们可以看到,鸢尾花数据的3个类别之间呈现出相互分离的状态,可以较容易地找到数据的分类界面。
接下来继续把数据降到二维空间,查看有何变化,将鸢尾花数据集从四维降到二维的代码如下,降维后的结果如图1-12所示:
>>> pca2d = PCA(n_components=2)>>> x_2d = pca2d.fit_transform(x)>>> plt.figure()<Figure size 640x480 with 0 Axes>>>> for i,item in enumerate(x_2d):... plt.scatter(item[0],item[1],color = colors[y[i]],marker = markers[y[i]])...>>> plt.show()
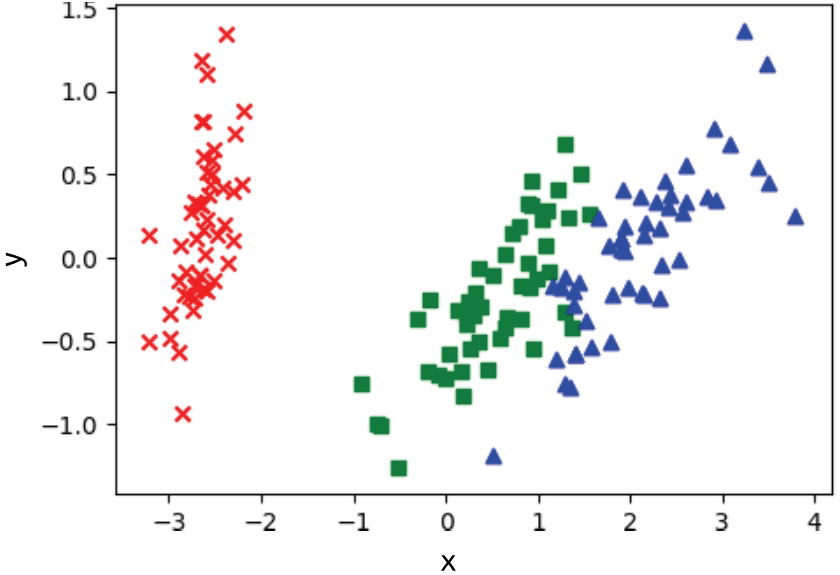
图 1-12 使用PCA将鸢尾花数据集降维至二维
从图1-12可以看到,降到二维之后,鸢尾花数据集仍然具有很好的可分性,这就达到了降维过程中尽量保留有用信息的要求。
最后再尝试把数据降到一维,从四维降到一维的代码如下,降维后的结果如图1-13所示:
>>> pca1d = PCA(n_components=1)>>> x_1d = pca1d.fit_transform(x)>>> plt.figure()<Figure size 640x480 with 0 Axes>>>> for i,item in enumerate(x_1d):... plt.scatter(item[0],0,color = colors[y[i]],marker = markers[y[i]])...>>> plt.show()
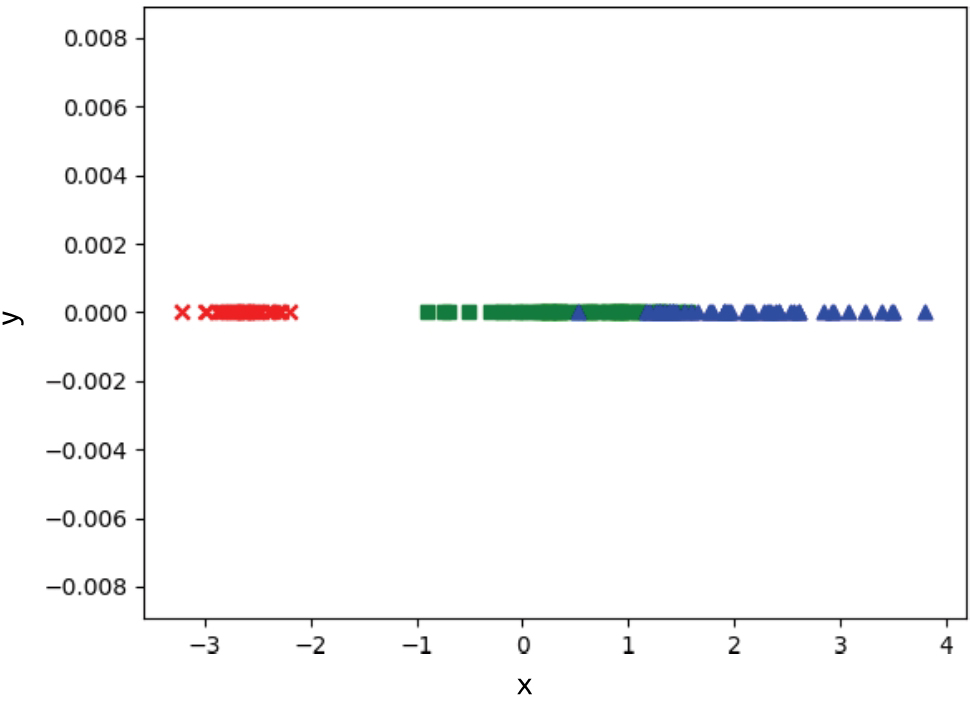
图 1-13 使用PCA将鸢尾花数据集降维至一维
从图1-13中可以看到,降到一维之后,鸢尾花数据集中的两个分类出现了比较明显的交叠现象,不能通过某个阈值将数据很好地进行分类。
1.6.2 LDA降维
除了PCA,sklearn还提供了一个降维方法:LDA(线性判别分析)。使用LDA也可以对鸢尾花数据集进行降维可视化。
因为LDA只能将数据降维到 [1, 类别数-1),所以在鸢尾花任务中,无法使用LDA将数据降维到三维,最高只能做二维展示。降维展示代码如下,降维结果如图1-14所示:
>>> from sklearn.discriminant_analysis import LinearDiscriminantAnalysis as LDA>>> lda = LDA(n_components=2)>>> x_2d = lda.fit_transform(x,y)>>> plt.figure()<Figure size 640x480 with 0 Axes>>>> for i,item in enumerate(x_2d):... plt.scatter(item[0],item[1],color = colors[y[i]],marker = markers[y[i]])...>>> plt.show()

图 1-14 使用LDA将鸢尾花数据集降维至二维
对比图1-14与图1-12,也可以看出,使用LDA降维之后的数据比使用PCA降维之后的数据的可分性更好。
那么继续做一维降维,会得到什么样的效果呢?以下是使用LDA进行四维转一维的代码,降维结果如图1-15所示:
>>> lda = LDA(n_components=1)>>> x_1d = lda.fit_transform(x,y)>>> plt.figure()<Figure size 640x480 with 0 Axes>>>> for i,item in enumerate(x_1d):... plt.scatter(item[0],0,color = colors[y[i]],marker = markers[y[i]])...>>> plt.show()
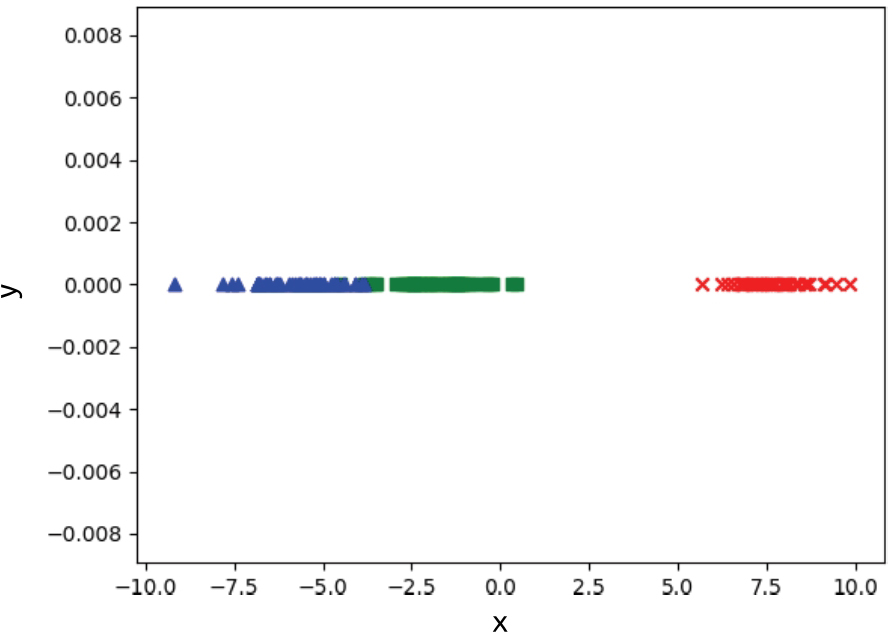
图 1-15 使用LDA将鸢尾花数据集降维至一维
从图1-15中可以看到,将鸢尾花数据集降维到一维之后,虽然有两个类别相距较近,但是几乎看不出来任何重叠。
两种方法最大的区别是PCA是无监督学习算法,而LDA是监督学习算法,这一点从二者fit_transform方法的输入参数可以看出。
PCA的降维原则是保留方差较大的维度,降维方差较小的维度,而LDA的降维原则是保证降维后,类内方差最小,类间方差最大。因此,LDA降维之后的数据可分性较强。可见,在有标签的情况下,应该尽量使用LDA进行降维或者可视化。
1.7 模型验证
在训练完模型之后,需要对模型进行评价,决定是否采用训练后的模型。本书前面的例子都是直接在训练数据上验证模型,这种方法存在一个很严重的问题:模型有可能过拟合。
什么情况下会出现过拟合呢?过拟合常常出现在以下3种情况下:
- 数据有噪声;
- 数据集过小;
- 模型太复杂。
在解决过拟合问题之前,需要有一个判断过拟合的依据,就是使用训练集之外的数据进行验证。
在sklearn中,有两种常用的验证方法:留出验证法和交叉验证法。
留出验证法的操作方式是在训练之前,从总数据集中按一定规则(或随机)抽取一部分数据作为验证数据集,然后在模型训练完成之后,在验证集上对模型的预测效果进行验证。
如果模型在训练集上的效果非常好,但是在验证集上的效果很差,就说明模型出现了过拟合现象。
sklearn中的留出验证法可以通过sklearn.model_selection.train_test_split函数实现。下面是一个模型过拟合的例子(此例使用Jupyter Notebook编写):
In:import numpy as npfrom sklearn.model_selection import train_test_split# 导入线性模型和多项式特征构造模块from sklearn import linear_modelfrom sklearn.preprocessing import PolynomialFeaturesfrom sklearn.metrics import r2_scoreimport matplotlib.pyplot as plt%matplotlib inline
接下来需要生成20个样本点,并加入一些随机扰动,生成数据的代码如下:
In:# 样本数量n_samples = 20x = np.array([i+2 for i in range(n_samples)]) * 4# 在log函数曲线上加入随机噪声y = 3 * np.log(x) + np.random.randint(0,3,n_samples)plt.scatter(x,y)
生成的样本如图1-16所示。

图 1-16 生成数据
然后对数据集进行划分,留出一部分验证集,其中test_size是验证集在总数据集中的占比:
In:x_train,x_test,y_train,y_test = train_test_split(x,y,test_size = 0.3)
下面使用二项式拟合的方式来拟合这个模型。在sklearn中,二项式拟合的实现方法是先将训练特征转换为二项式特征,然后再使用线性回归模型进行拟合,相关代码如下:
In:def poly_fit(degree):poly_reg =PolynomialFeatures(degree=degree)# 转换成二次特征x_ploy_train = poly_reg.fit_transform(x_train.reshape(-1,1))# 对x_test进行同样的转换x_ploy_test = poly_reg.transform(x_test.reshape(-1,1))clf = linear_model.LinearRegression()clf.fit(x_ploy_train,y_train.reshape(-1,1))# 创建子图,绘制训练集上的预测结果plt.subplot(121)y_train_pred = clf.predict(x_ploy_train)sorted_indices = np.argsort(x_train)plt.plot(x_train[sorted_indices],y_train_pred[sorted_indices])plt.scatter(x_train,y_train)# 创建子图,绘制验证集上的预测结果plt.subplot(122)y_test_pred = clf.predict(x_ploy_test)# 同时对x_test和y_test_pred进行排序sorted_indices = np.argsort(x_test)plt.plot(x_test[sorted_indices],y_test_pred[sorted_indices])plt.scatter(x_test,y_test)# 计算r2_scoreprint("Train R2 score",r2_score(y_train_pred,y_train))print("Test R2 score",r2_score(y_test_pred,y_test))
然后逐步提高多项式的次数,观察模型效果与多项式次数之间的关系。二次多项式拟合代码如下,结果如图1-17所示:
In:poly_fit(2)Out:Train R2 score 0.8102748526150807Test R2 score 0.7661602866338544
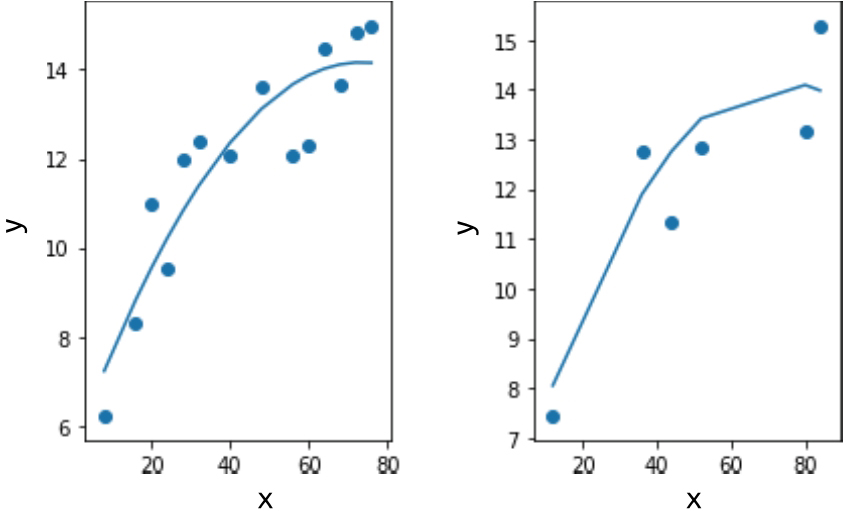
图 1-17 二次多项式拟合结果
五次多项式拟合代码如下,结果如图1-18所示:
In:poly_fit(5)Out:Train R2 score 0.9087433750748772Test R2 score 0.8326903541105737
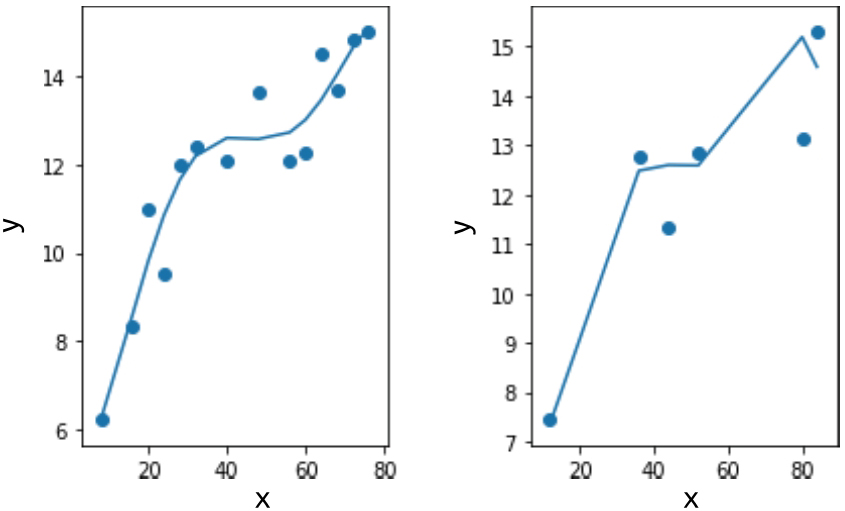
图 1-18 五次多项式拟合结果
十次多项式拟合代码如下,结果如图1-19所示:
In:poly_fit(10)Out:Train R2 score 0.9176237285551411Test R2 score -0.13339572778788056

图 1-19 十次多项式拟合结果
上述案例使用train_test_split将数据集划分为两个部分,训练集和验证集。然后在训练集上进行模型训练,训练完成后,分别计算训练集和验证集上的模型指标。
结果发现,随着模型复杂度的提升(多项式特征次数越来越高),模型在训练集上的表现(R2 Score)越来越好,在验证集上的效果却是先变好再变坏。这就是模型过拟合的表现。
交叉验证法可以理解为留出验证法的升级版,以sklearn中的KFold检验为例,其算法步骤如下。
(1) 将数据集划分为n个互斥子集。
(2) 以其中一个子集作为验证集,其他子集作为训练集,训练模型。
(3) 选择另一个子集作为验证集,其他子集作为训练集,再训练模型。
(4) 如此进行n次训练和测试,得到n个结果。
在发现模型过拟合后,可以尝试通过如下几个方法解决过拟合的问题:
- 重新清洗数据;
- 增加数据量;
- 采用正则化方法;
- 选择合适的模型。
1.8 模型持久化
我们训练好了一个机器学习模型后,就会希望以后不用重复训练过程也可以使用这个模型,在这种情况下,可以使用模型持久化工具保存模型。常用于保存sklearn模型的工具有两个,一个是joblib工具,一个是可以用来保存Python对象的pickle库。
1.8.1 joblib
使用joblib保存模型需要用到joblib.dump函数,保存一个逻辑回归模型的代码如下:
>>> import joblib>>> from sklearn.linear_model import LogisticRegression>>> x = [[0,0],[1,1]]>>> y = [0,1]>>> clf = LogisticRegression()>>> clf.fit(x,y)LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,intercept_scaling=1, l1_ratio=None, max_iter=100,multi_class='warn', n_jobs=None, penalty='l2',random_state=None, solver='warn', tol=0.0001, verbose=0,warm_start=False)>>> # 保存模型>>> joblib.dump(clf,"lr.m")['lr.m']
从保存的模型文件中加载模型需要用到joblib.load函数,加载模型并进行预测的代码如下:
>>> clf = joblib.load("lr.m")>>> clf.predict(x)array([0, 1])
1.8.2 pickle
使用pickle库保存模型需要使用pickle.dumps函数对模型进行处理,然后把它写入一个二进制文件,具体代码如下:
>>> from sklearn.linear_model import LogisticRegression>>> x = [[0,0],[1,1]]>>> y = [0,1]>>> clf = LogisticRegression()>>> clf.fit(x,y)LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,intercept_scaling=1, l1_ratio=None, max_iter=100,multi_class='warn', n_jobs=None, penalty='l2',random_state=None, solver='warn', tol=0.0001, verbose=0,warm_start=False)>>> import pickle>>> s = pickle.dumps(clf)>>> # 以二进制形式打开文件,然后写入对象信息>>> f = open("lr.pkl","wb")>>> f.write(s)826>>> f.close()
加载模型时需要先打开保存了模型的二进制文件,然后用pickle.load函数对其进行处理,具体代码如下:
>>> g = open("lr.pkl","rb")>>> s = g.read()>>> clf = pickle.loads(s)>>> clf.predict(x)array([0, 1])
有了模型持久化工具,就可以实现“一次训练,永久使用”了。
1.9 小结
本章介绍了sklearn这一经典的机器学习库,对其中的分类、回归、聚类和降维四大类算法做了浅显的介绍。我希望读者在阅读完本章之后,能够做到以下几点。
- 对机器学习有一个基本的认识。
- 对上述几大类机器学习算法的异同有所了解。
- 理解机器学习中的模型验证思路。

若有收获,就点个赞吧
0 人点赞
