2016 年春天,围棋界受到了冲击。
这一年发生了顶级棋手完败于计算机的事件,这一事件给人工智能热潮添了一把火。取得比赛胜利的是 DeepMind 公司开发的 AlphaGo 程序,该程序使用了最新的机器学习技术。
现如今,人工智能和深度学习等词语时常在新闻中出现。为了理解这些词语,我们需要先了解一下什么是机器学习。
1 机器学习概要
什么是机器学习
机器学习指的是计算机根据给定的问题、课题或环境进行学习,并利用学习结果解决问题或课题等的一整套机制(图 1-1)。
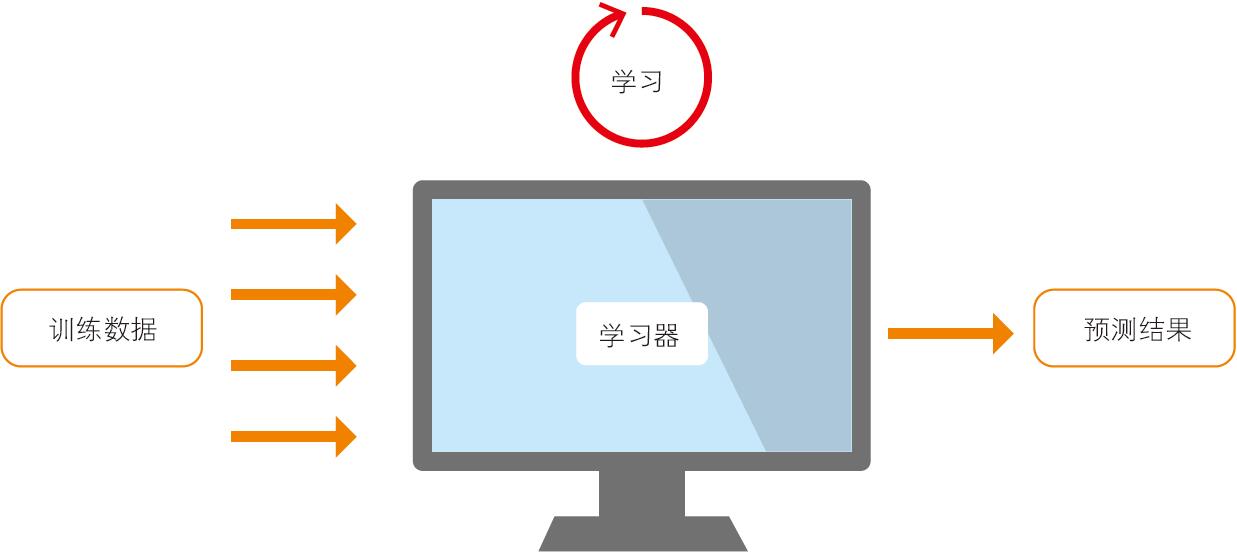
▲图 1-1 分类的示意图
与机器学习共同成为热门话题的还有人工智能和深度学习。这里梳理一下它们之间的关系(图 1-2)。人工智能的含义很广泛,是一个综合性系统。机器学习是实现人工智能的一种方法。也就是说,机器学习并非实现人工智能的唯一方法,但是近年来人工智能的研究一般使用机器学习。实现人工智能的方法还有很多,比如根据事先定好的规则进行数理统计预测等方法。
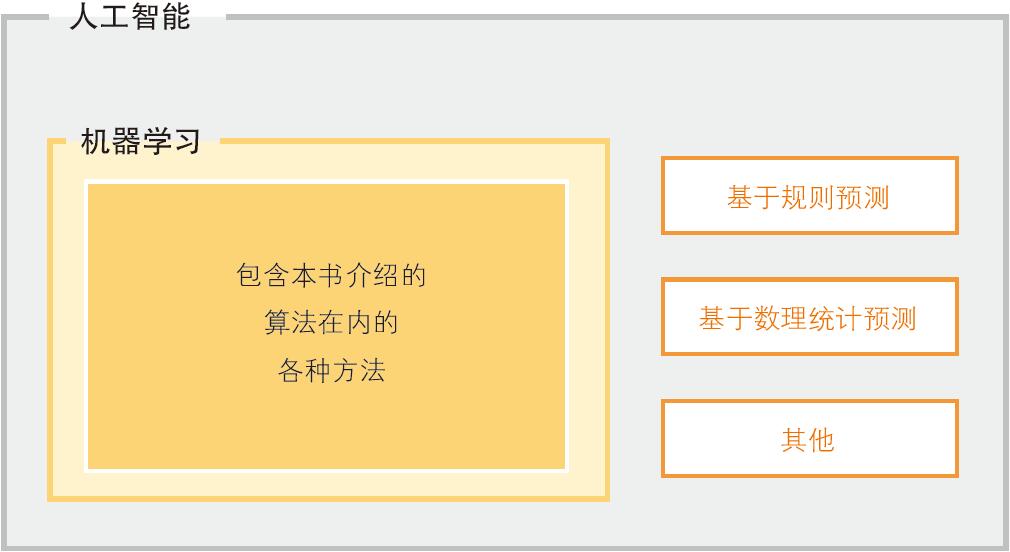
▲图 1-2 机器学习的包含关系
近年来,一种被称为深度学习的机器学习算法备受关注,以至于出现了这样的误解:提起人工智能,人们想到的就是深度学习。然而,深度学习只不过是机器学习算法的其中一种而已。深度学习在图像识别领域取得了划时代的成果,是当前热门的算法。目前在图像识别领域之外,深度学习也取得了许多成绩。
在进行机器学习时会用到各种各样的算法,需要根据机器学习对象的不同进行选择。本书的目标就是帮助读者学会选择合适的算法。在理解了各算法的特性后,读者就能实际处理机器学习问题了。
机器学习的种类
机器学习包含不同的种类。根据不同的输入数据,分类如下。
- 有监督学习
- 无监督学习
- 强化学习
下面我们依次详细地看一下。
有监督学习
有监督学习是将问题的答案告知计算机,使计算机进行学习并给出机器学习模型的方法。这种方法要求数据中包含表示特征的数据和作为答案的目标数据。
如图 1-3 所示,已有表示特征的身高和体重数据,作为答案的数据是性别(男/女)。我们向计算机提供这些数据的组合,使计算机进行学习并给出预测模型。然后,将新的身高和体重数据提供给模型,由模型预测出性别。
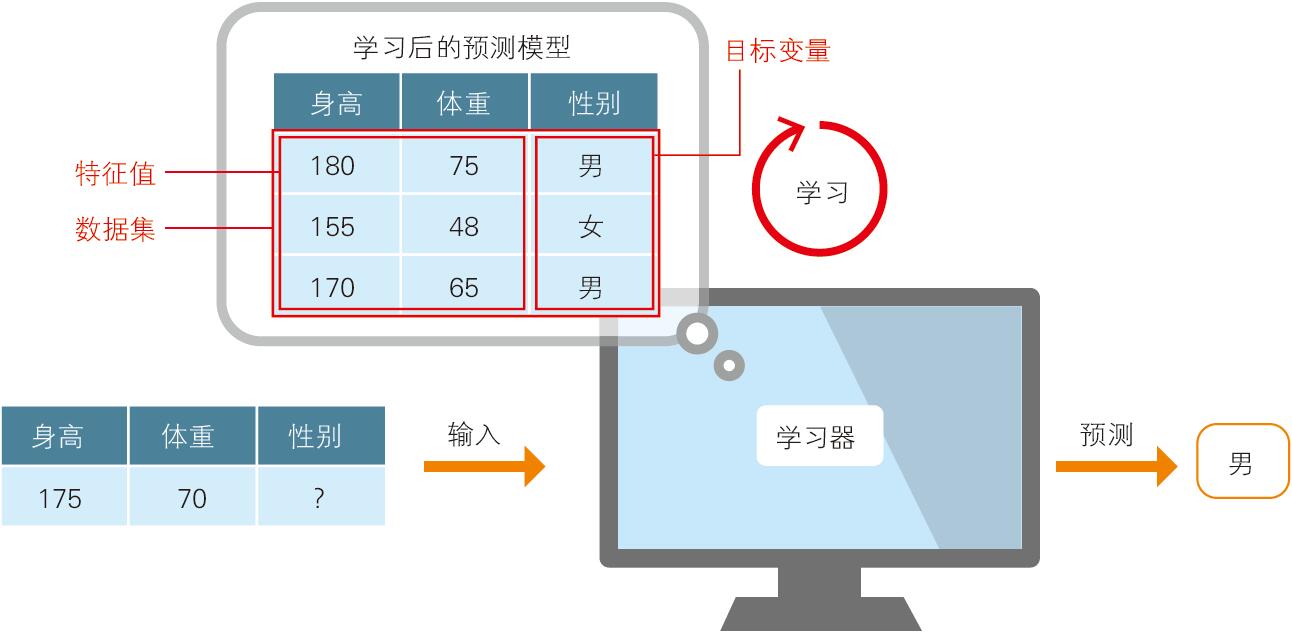
▲图 1-3 有监督分类的示意图
预测性别这样的类别的问题叫作分类问题。由于这次是将数据分类到两个类别中,所以叫二元分类;还有将数据分类到更多类别,比如 10 个类别的情况,这样的情况叫作多元分类。这种答案变量不是连续值,而是作为类别数据的离散值的问题就是分类问题(图 1-4)。

▲图 1-4 有监督学习的分类和回归的关系
此外,表示特征的数据叫作特征值或者特征变量,作为答案的数据叫作目标变量或者标签。
我们身边的一个分类问题的例子就是垃圾邮件过滤。用户判断邮件是否为垃圾邮件的过程就是打标签的过程,标签数据就是目标变量,邮件的发件人和内容则为特征值。打了标签的数据越多,机器学习的效果就越好,得到的结果的精度越高。
除了分类问题之外,有监督学习还包括回归问题。如图 1-5 所示,已有表示特征的性别和身高数据,以及答案数据——鞋的尺码。在分类问题中,男和女的标签分别被数值化为 0 和 1,这两个数值之间的大小关系是没有意义的。与之相对,鞋的尺码 26.5 cm 和 24 cm 之间的大小关系则是有意义的。对这样的数据进行预测的问题就是回归问题。在回归问题中,目标变量是作为连续值处理的,所以预测值有可能是 23.7 cm 这种不存在的尺码。
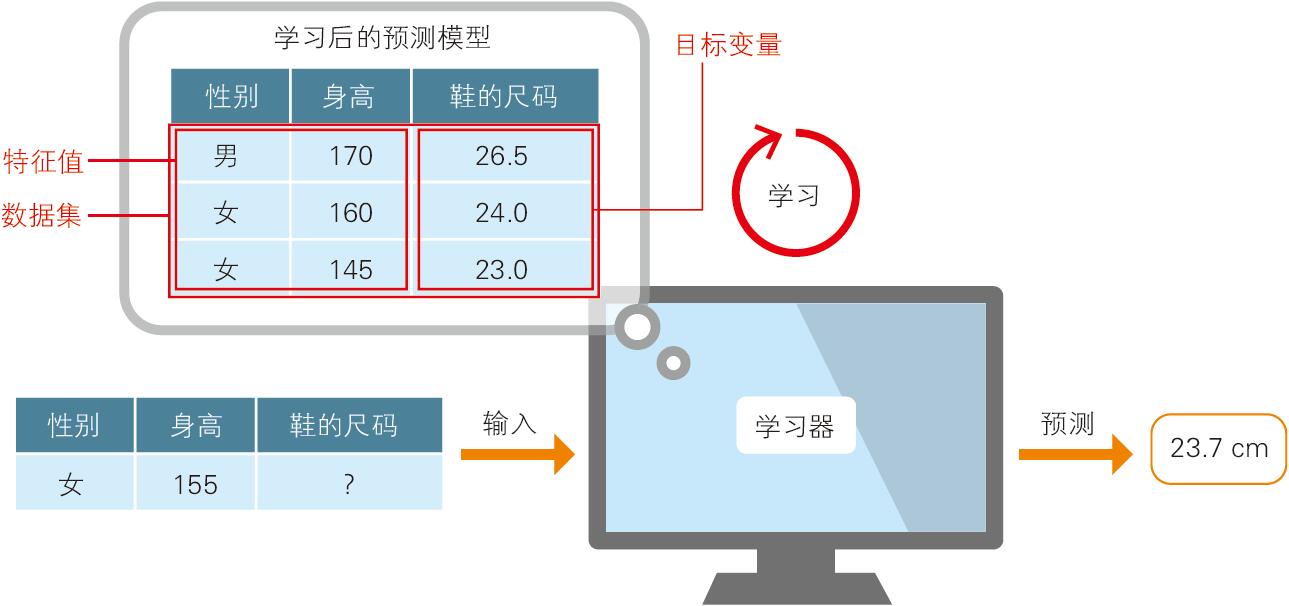
▲图 1-5 回归问题的示意图
第 2 章将详细介绍如表 1-1 所示的有监督学习的算法。
▼表 1-1 有监督学习算法与分类和回归的应用范围
| 算法编号 | 算法名 | 分类 | 回归 |
|---|---|---|---|
| 1 | 线性回归 | × | √ |
| 2 | 正则化 | × | √ |
| 3 | 逻辑回归 | √ | × |
| 4 | 支持向量机 | √ | √ |
| 5 | 支持向量机(核方法) | √ | √ |
| 6 | 朴素贝叶斯 | √ | × |
| 7 | 随机森林 | √ | √ |
| 8 | 神经网络 | √ | √ |
| 9 | KNN | √ | √ |
无监督学习
有监督学习是将特征值和目标变量(答案)作为一套数据进行学习的方法,而无监督学习的数据中没有作为答案的目标变量。
有人可能会产生疑问:没有答案,该如何去学习呢?无监督学习将表示特征的数据作为输入,通过将数据变形为其他形式或者找出数据中的部分集合,来理解输入数据的构造。此外,与有监督学习相比,无监督学习的结果难以解释,或者要求分析者基于经验加以主观的解释。有监督学习以“能否正确预测目标变量”为指标,相比之下,为了能够对结果进行解释,在进行无监督学习时,用户需要对输入数据的前提知识有一定程度的了解。
这里举一个无监督学习的例子。我们思考一下对某个中学的学生成绩进行分析的场景。假设各科目之间存在着这样的关联性:擅长数学的学生也擅长理科,但不擅长语文和文科。
对于这样的输入数据,在使用无监督学习的代表性算法主成分分析(Principal Component Analysis,PCA)时,我们引入了新的轴,以说明被称为第一主成分的数据(关于 PCA,详见 3.1 节)。在第一主成分上的坐标可以解释为“小值表明该生擅长理科,大值表明该生擅长文科”,如表 1-2 所示,可以将数学、理科、语文、文科这 4 个特征值归纳在 1 个轴上加以展示。
▼表 1-2 PCA 的例子
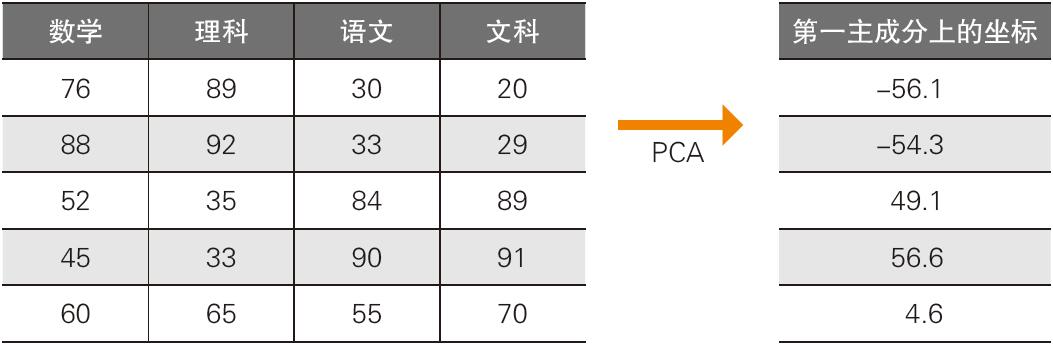
这个例子使用 PCA 通俗易懂地解释了分析结果,但是需要根据输入数据选择合适的算法。近年来,无监督学习的研究在图像和自然语言处理方面取得了进展,是当前备受瞩目的领域(图 1-6)。这里介绍的 PCA 属于降维算法。降维是以更少的特征值来理解数据的算法。无监督学习中也包括聚类算法。聚类是将数据分类为几个簇(相似数据的集合)的算法。人类很难直接理解多变量数据(由 3 个以上的变量构成的数据),通过聚类,数据能够以簇这种简单的形式进行展现。

▲图 1-6 无监督学习的降维和聚类的关系
第 3 章将详细介绍如表 1-3 所示的无监督学习的算法。通过表 1-3,还可以了解每个算法适合的任务。
▼表 1-3 无监督学习与降维和聚类的应用范围
| 算法编号 | 算法名 | 降维 | 聚类 |
|---|---|---|---|
| 10 | PCA | √ | × |
| 11 | LSA | √ | × |
| 12 | NMF | √ | × |
| 13 | LDA | √ | × |
| 14 | k-means 算法 | × | √ |
| 15 | 混合高斯模型 | × | √ |
| 16 | LLE | √ | × |
| 17 | t-SNE | √ | × |
强化学习
强化学习是以在某个环境下行动的智能体获得的奖励最大化为目标而进行学习的方法。本书未 涉及强化学习。
这里简单地介绍一下强化学习。在主机游戏(环境)中,玩家(智能体)为了获得赛点(奖励)并取得最终的胜利,会无数次地重复尝试。我们也可以把强化学习看作有监督学习的目标变量被作为奖励提供的情况。拿主机游戏的例子来说,由于全部场景下所有操作的组合实在太多,很难通过人力进行评估,所以可以将游戏的场景和操作作为特征值,将游戏赛点作为目标变量,玩家无须依赖人力,通过无数次的游戏即可自行收集特征值和目标变量的数据组。强化学习在重复地玩游戏、查看结果中不断学习更恰当的行动。
机器学习的应用
机器学习在各领域的应用都取得了较大进展,比如自动驾驶领域的研究就很有名。在文章的自动分类和自动翻译方面,机器学习成果颇丰。在医疗领域,机器学习对 X 射线影像的分析有助于疾病的早期发现。此外,很早之前人们就将机器学习应用在气象信息领域了。
近年来,随着计算机越来越便宜,数量越来越多,机器学习的研究也在不断加速。互联网产业的发达和物联网(Internet of Things,IoT)等技术的应用也为机器学习带来了丰富的数据。
根据数据的特性选择合适的算法,就会有前所未有的发现,这是机器学习领域有意思的地方。从下一节开始,我们将学习具体的机器学习步骤,目标是达到能对实际的数据应用机器学习的水平。
1.2 机器学习的步骤
机器学习具体要做哪些事情呢?本节的目标就是使读者了解机器学习的大致步骤。通过阅读本节,读者将对作为机器学习算法基础的处理流程有所理解,并学到机器学习的基本概念。
数据的重要性
在使用机器学习时,必须要有汇总并整理到一定程度的数据。以数据为基础,按规定的法则进行学习,最终才能进行预测。
没有数据,就不能进行机器学习。换言之,收集数据是首先要做的事情。
本节将说明机器学习的训练过程的一系列流程。为了便于理解,本节基于示例数据进行讲解,使用的是主流机器学习库 scikit-learn 包内置的数据,这个数据便于入手,可自由使用。
专栏 数据收集、数据预处理的重要性
在实际用机器学习解决问题之前,要先收集数据,有时还需要做问卷调查,甚至购买数据。然后,需要为收集到的数据人工标注答案标签,或者将其加工为机器学习算法易于处理的形式,删除无用的数据,加入从别的数据源获得的数据等。另外,基于平均值和数据分布等统计观点查看数据,或者使用各种图表对数据进行可视化,把握数据的整体情况也很重要。此外,有时还需要对数据进行正则化处理。
这些操作被称为数据预处理。有这样一种说法:机器学习工作80%以上的时间花在了数据预处理上。
专栏 scikit-learn 包
scikit-learn 是一个机器学习库,包含了各种用于机器学习的工具。
这个库以 BSD 许可证开源,谁都可以免费、自由地使用。在写作本书时(2019 年 3 月),它的最新版本是 0.20.3。scikit-learn 实现了许多有监督学习和无监督学习的算法,是一套包含了用于评估的工具、方便的函数、示例数据集等的工具套件。在机器学习领域,scikit-learn 已成为事实上的标准库,它具有两大优点:一是操作方法统一;二是易于在 Python 中使用。关于 Python 环境的设置和 scikit-learn 的安装方法,请参考第 5 章。
数据和学习的种类
前面说过,没有数据,就不能进行机器学习。具体来说,机器学习需要的是什么样的数据呢?
机器学习需要的是二维的表格形式的数据(根据解决问题的目的不同,存在例外的情况)。表格的列中含有表示数据本身特征的多种信息,行则是由多个信息构成的数据集。接下来,我们看一个更具体的例子:学校的某个社团有 4 名学生,下面的表 1-4 是每个学生的姓名、身高、体重、出生日期和性别信息的数据。
▼表 1-4 表格形式的学生数据
| 姓名 | 身高(cm) | 体重(kg) | 出生日期 | 性别 |
|---|---|---|---|---|
| 赵小刚 | 165 | 60 | 1995-10-02 | 男 |
| 钱小花 | 150 | 45 | 1996-01-20 | 女 |
| 孙小明 | 170 | 70 | 1995-05-29 | 男 |
| 李小芳 | 160 | 50 | 1995-08-14 | 女 |
我们思考一下用机器学习进行性别预测的问题。
因为要预测的是性别,所以性别列的男或女的数据就是预测对象。本书把预测对象的数据称为目标变量。不过,根据分类的场景的不同,有时也称为标签或类别标签数据,对应的英文单词为 target。
除了性别之外的 4 个列(姓名、身高、体重、出生日期)是用于预测的原始数据。本书将用于预测的原始数据称为特征值,根据场景的不同,有时也称为特征变量或输入变量,对应的英文单词为 feature。
了解示例数据
我们看一下 scikit-learn 包中内置的示例数据。这里显示了部分 鸢尾花(iris)数据(表 1-5)。Python 生态圈中用于处理数据的工具有 pandas,它常与 scikit-learn 搭配使用。关于使用 pandas 处理数据的方法,请参考后文的“使用 pandas 理解和处理数据”部分。
下面输出数据的基本信息。
▼示例代码
import pandas as pdfrom sklearn.datasets import load_irisdata = load_iris()X = pd.DataFrame(data.data, columns=data.feature_names)y = pd.DataFrame(data.target, columns=["Species"])df = pd.concat([X, y], axis=1)df.head()
▼表 1-5 部分鸢尾花数据
| sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) | Species | |
|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | 0 |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | 0 |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | 0 |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | 0 |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 | 0 |
列方向上有 sepal length(cm)、sepal width(cm)、petal length(cm)、petal width(cm)、Species 这 5 种信息,意思分别是鸢尾花的萼片长度、萼片宽度、花瓣长度、花瓣宽度、品种。前面 4 列是表示特征的特征值,最后 1 列是目标变量。在这个数据集中,目标变量的值为 0、1、2 这 3 个值之一。
本书在讲解的过程中使用了基于 scikit-learn 库编写的代码。下面将讲解 scikit-learn 的大致用法。不过本书不会全面讲解 scikit-learn 的功能。关于 scikit-learn 的详细信息,请参考官方文档和其他图书。
有监督学习(分类)的例子
本节将介绍基于有监督学习解决分类问题的实现方法。
下面依次来看例题和实现方法。
例题
例题采用的是美国威斯康星州乳腺癌数据集。这个数据集中包含 30 个特征值,目标变量的值为“良性”或者“恶性”。数据数量有 569 条,其中“恶性”(M)数据 212 条,“良性”(B)数据 357 条。换言之,这是根据 30 个特征值判断结果是恶性还是良性的二元分类问题。
下面看一下数据长什么样子(表 1-6)。
▼表 1-6 部分乳腺癌数据
| mean radius | mean texture | mean perimeter | mean area | mean smoothness | mean compactness | mean concavity | mean concave points | mean symmetry | mean fractal dimension | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 17.99 | 10.38 | 122.80 | 1001.0 | 0.118 40 | 0.277 60 | 0.3001 | 0.147 10 | 0.2419 | 0.078 71 |
| 1 | 20.57 | 17.77 | 132.90 | 1326.0 | 0.084 74 | 0.078 64 | 0.0869 | 0.070 17 | 0.1812 | 0.056 67 |
| 2 | 19.69 | 21.25 | 130.00 | 1203.0 | 0.109 60 | 0.159 90 | 0.1974 | 0.127 90 | 0.2069 | 0.059 99 |
| 3 | 11.42 | 20.38 | 77.58 | 386.1 | 0.142 50 | 0.283 90 | 0.2414 | 0.105 20 | 0.2597 | 0.097 44 |
| 4 | 20.29 | 14.34 | 135.10 | 1297.0 | 0.100 30 | 0.132 80 | 0.1980 | 0.104 30 | 0.1809 | 0.058 83 |
| … | worst radius | worst texture | worst perimeter | worst area | worst smoothness | worst compactness | worst concavity | worst concave points | worst symmetry | worst fractal dimension |
|---|---|---|---|---|---|---|---|---|---|---|
| … | 25.38 | 17.33 | 184.60 | 2019.0 | 0.1622 | 0.6656 | 0.7119 | 0.2654 | 0.4601 | 0.118 90 |
| … | 24.99 | 23.41 | 158.80 | 1956.0 | 0.1238 | 0.1866 | 0.2416 | 0.1860 | 0.2750 | 0.089 02 |
| … | 23.57 | 25.53 | 152.50 | 1709.0 | 0.1444 | 0.4245 | 0.4504 | 0.2430 | 0.3613 | 0.8758 |
| … | 14.91 | 26.50 | 98.87 | 567.7 | 0.2098 | 0.8663 | 0.6869 | 0.2575 | 0.6638 | 0.173 00 |
| … | 22.54 | 16.67 | 152.20 | 1575.0 | 0.1374 | 0.2050 | 0.4000 | 0.1625 | 0.2364 | 0.076 78 |
这份数据可以通过 scikit-learn 包读取。
▼示例代码
from sklearn.datasets import load_breast_cancerdata = load_breast_cancer()
这段代码用于导入 scikit-learn 内置的读取数据集的函数,并将所读取的数据保存在变量 data 中。
接下来,从数据集中取出特征值赋给 X,取出目标变量赋给 y。
▼示例代码
X = data.datay = data.target
X 由多个特征值向量构成,我们将其作为矩阵处理,因此遵照惯例使用大写字母作为变量名。y 是目标变量的向量,其元素值的含义为:0 表示恶性(M),1 表示良性(B)。
X 是大小为 569 × 30 的数据,可将其看作 569 行 30 列的矩阵。虽然 y 是向量,但把它当作 569 行 1 列的矩阵后,X 和 y 的行就能一一对应了。比如特征值 X 的第 10 行与目标变量 y 的第 10 个元素相对应(图 1-7)。

▲图 1-7 与 **y** 的第 10个元素对应
要想详细了解这个数据集,需要具备相应的医学知识,但是这里我们仅将其作为数值,对其进行有监督学习的二元分类。特征值共有 30 个,分为平均值、误差值、最差值 3 类,每类包括 10 项,分别为半径、纹理、面积等。这次我们着眼于平均值、误差值、最差值这 3 类数据中的平均值(图 1-8)。
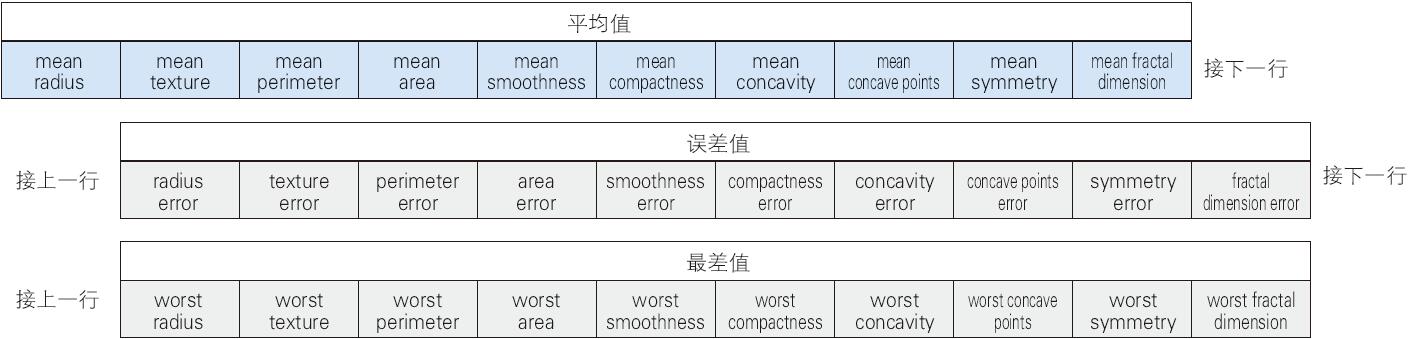
▲图 1-8 特征值的种类
▼示例代码
X = X[:, :10]
这行操作使得只有平均值被重新赋值给了变量 X,用作特征值的数据现在缩减到了 10 项。
实现方法
下面趁热打铁,基于美国威斯康星州乳腺癌数据集创建并训练进行二元分类的模型。这里使用的分类算法是逻辑回归。虽然算法名中有“回归”二字,却能用于分类,详细内容请参考 2.3 节。
▼示例代码
from sklearn.linear_model import LogisticRegressionmodel = LogisticRegression()
注意 在使用scikit-learn进行模型的初始化和训练时,读者有可能会看到输出的警告信息。警告信息是 FutureWarning,即对将来有可能会变更的功能的通知,在训练不收敛时有可能会出现。本书没有提及警告的输出,如果读者在实践中发现有警告输出,请根据警告内容采取相应的措施。
为了使用逻辑回归模型,上面的代码导入了 scikit-learn 的 LogisticRegression 类,然后创建了 LogisticRegression 类的实例,并将已初始化的模型赋给了 model。
▼示例代码
model.fit(X, y)
上面的代码使用 model(LogisticRegression 的实例)的 fit 方法训练模型,方法的参数是特征值 X 和目标变量 y。
在调用 fit 方法后,model 成为学习后的模型。
▼示例代码
y_pred = model.predict(X)
上面的代码使用学习后的模型 model 的 predict 方法对学习时用到的特征值 X 进行预测,并将预测结果赋给变量 y_pred。
评估方法
下面介绍分类的评估方法。
首先看一下正确率(详见第 4 章)。这里使用 scikit-learn 的 accuracy_score 函数查看正确率。
▼示例代码
from sklearn.metrics import accuracy_scoreaccuracy_score(y, y_pred)0.9086115992970123
代码的输出结果是学习后的模型预测的结果 y_pred 相对于作为正确答案的目标变量 y 的正确率。
这个验证通常应使用另外准备的一些不用于学习的数据来进行,否则会产生过拟合(overfitting)问题。过拟合是有监督学习的一个严重问题。有监督学习追求的是正确预测未知的数据,但是现在输出的正确率是使用学习时用过的数据计算出来的。这就意味着我们不知道模型对于未用于学习的未知数据的预测性能的好坏,不知道得到的学习后的模型是不是真正优秀。关于过拟合,详见 4.1 节的“模型的过拟合”部分。
关于评估方法,还有其他问题需要考虑。比如,只看正确率就能判断结果是否正确吗?根据数据的特性不同,有些情况下不能保证分类是正确的。这次用的数据中有“恶性”数据 212 条,“良性”数据 357 条,可以说是在一定程度上均衡的数据。
对于“良性”“恶性”极不均衡的数据,光看正确率无法判断结果是否正确。我们再以另外一组数据为例,看一下 30 岁~39 岁人群的癌症检测数据。通常来说,诊断为恶性的数据只占整体的百分之几,大多数人没有肿瘤或者肿瘤是良性的。对于这样的数据,如果模型将所有的样本都判断为良性的,那么尽管正确率很高,但光看正确率也不能正确评估这个模型(图 1-9)。
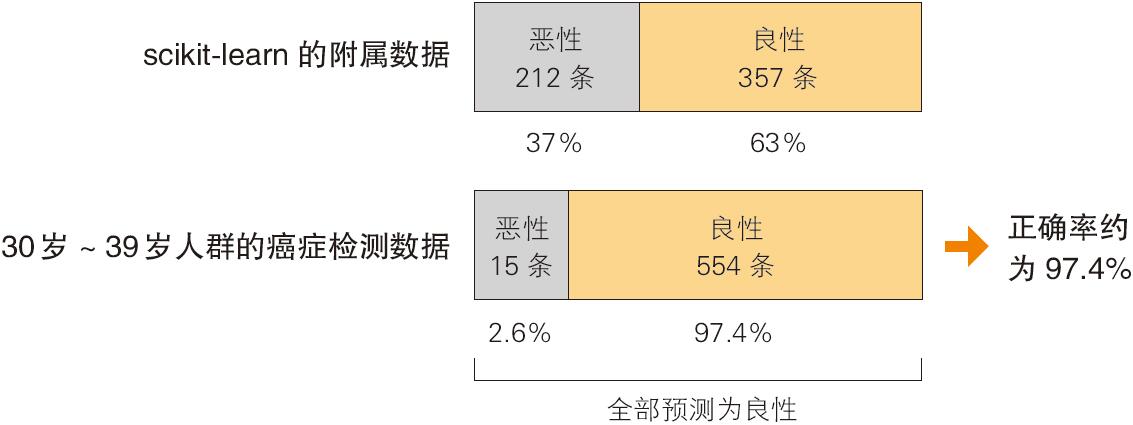
▲图 1-9 光看正确率无法正确评估模型
关于这些内容,第 4 章会详细介绍。
无监督学习(聚类)的例子
下面看一下无监督学习的聚类问题的实现方法的各个步骤。与前面一样,这里我们也使用 scikit-learn 包。
例题
例题采用的是 scikit-learn 包内置的与葡萄酒种类有关的数据集。这个数据集有 13 个特征值,目标变量是葡萄酒种类(表 1-7)。由于这次介绍的是无监督学习的聚类算法,所以不使用目标变量。简单起见,本次只使用 13 个特征值中的 alcohol(酒精度)和 color_intensity(色泽)两个特征值(表 1-8)。我们对这个数据集应用 k-means 聚类算法,将其分割为 3 个簇。
▼表 1-7 葡萄酒数据的特征值
| alcohol | malic_ acid | ash | alcalinity_ of_ash | magnesium | total_ phenols | flavanoids | nonflavanoid_ phenols | proanthocyanins | color_ intensity | hue | od280/ od315of diluted_ wines | proline | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 14.23 | 1.71 | 2.43 | 15.6 | 127.0 | 2.80 | 3.06 | 0.28 | 2.29 | 5.64 | 1.04 | 3.92 | 1065.0 |
| 1 | 13.20 | 1.78 | 2.14 | 11.2 | 100.0 | 2.65 | 2.76 | 0.26 | 1.28 | 4.38 | 1.05 | 3.40 | 1050.0 |
| 2 | 13.16 | 2.36 | 2.67 | 18.6 | 101.0 | 2.80 | 3.24 | 0.30 | 2.81 | 5.68 | 1.03 | 3.17 | 1185.0 |
| 3 | 14.37 | 1.95 | 2.50 | 16.8 | 113.0 | 3.85 | 3.49 | 0.24 | 2.18 | 7.80 | 0.86 | 3.45 | 1480.0 |
| 4 | 13.24 | 2.59 | 2.87 | 21.0 | 118.0 | 2.80 | 2.69 | 0.39 | 1.82 | 4.32 | 1.04 | 2.93 | 735.0 |
▼表 1-8 本次使用的两个特征值
| alcohol | color_intensity | |
|---|---|---|
| 0 | 14.23 | 5.64 |
| 1 | 13.20 | 4.38 |
| 2 | 13.16 | 5.68 |
| 3 | 14.37 | 7.80 |
| 4 | 13.24 | 4.32 |
下面使用 scikit-learn 包加载这个数据集。
▼示例代码
from sklearn.datasets import load_winedata = load_wine()
上面的代码用于导入 scikit-learn 内置的读取葡萄酒数据集的函数,并将读取的数据保存在变量 data 中。
接着,仅从数据集中选择 alcohol 列和 color_intensity 列作为特征值赋给 X。这么做是为了在显示结果时,只用二维图形对结果进行可视化。
▼示例代码
X = data.data[:, [0, 9]]
特征值 X 是 178 行 2 列的数据。
实现方法
下面使用 k-means 算法实现聚类。
▼示例代码
from sklearn.cluster import KMeansn_clusters = 3model = KMeans(n_clusters=n_clusters)
上面的代码导入并使用了实现 k-means 算法的 KMeans 类。
初始化 KMeans 类,把它作为学习前的模型赋给变量 model。通过 n_clusters 参数,指示模型将数据分为 3 个簇。
▼示例代码
pred = model.fit_predict(X)
上面的代码用于向学习前的模型 model 的 fit_predict 方法传入特征值数据。预测结果赋给变量 pred。
下面看一下赋给 pred 的数据是如何聚类的。
查看结果
这里将聚类的结果可视化。
由于本次使用的特征值只有两种,所以绘制二维图形即可实现结果的可视化。图 1-10 是以图形展示的聚类结果。图形中每个数据点对应的是一种葡萄酒。从数据点的颜色可以看出每种酒属于哪个簇。3 个黄色的星星是各个簇的重心,是这 3 个簇的代表点。
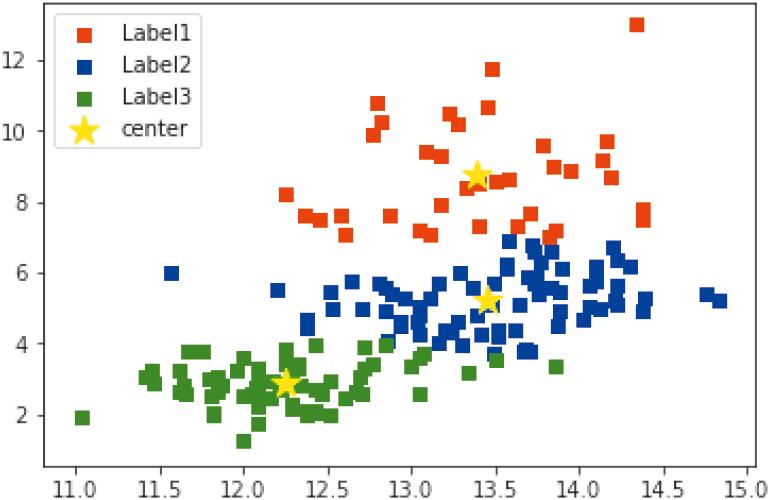
▲图 1-10 特征值的可视化
原本以酒精度、色泽变量表示的葡萄酒,现在以“属于哪个簇”这种简洁直观的形式展示了出来。此外,要想了解各个簇具有什么特征,只需查看作为代表点的重心的值即可。比如,第 3 个簇的特点是“酒精度低、色泽淡”。
通过 k-means 算法实现的聚类是以“将酒精度百分之多少以上的数据分到第 1 个簇”之类的规则进行聚类的,这些规则不是由人预先设置的,而是由算法自动进行聚类得出的。这一点很重要,说明这个算法具有通用性,可应用于葡萄酒之外的数据。
无监督学习的评估方法将在第 3 章介绍各个算法时进行说明,请参考相应内容。
可视化
可视化是利用图形等把握数据的整体情况的方法。在机器学习领域中,许多场景下需要进行可视化。有时用于了解数据的概况,有时用于以图形展示机器学习的结果。
这里介绍一下使用 Python 进行可视化的方法,书中也将展示作为可视化结果的图形等。
工具介绍
这里使用常用的 Python 可视化工具 Matplotlib。Matplotlib 具有许多可视化功能。在可视化时,为了使图形美观,需要编写多行 Python 代码来设置坐标轴、标签、布局和配色等。代码行数的增加容易让人觉得晦涩难懂,但其实用于输出图形的重要部分的代码只有寥寥几行。
在使用 Matplotlib 实现可视化后,我们就能很容易地把握数据的偏差和特征等信息,所以要掌握它的用法。
Python 的可视化工具不只有 Matplotlib,还有以下几种。
- pandas
pandas 是处理数组数据的库,也具有可视化功能。 - seaborn
seaborn 在Matplotlib的基础上强化了表现力,用起来更简单。 - Bokeh
Bokeh 使用了JavaScript,可用于显示动态图形。
在浏览器上显示
使用 Jupyter Notebook 可以简单地在浏览器上显示数据的可视化结果。
Jupyter Notebook 是在 Web 浏览器上运行 Python 等语言代码的环境(图 1-11)。
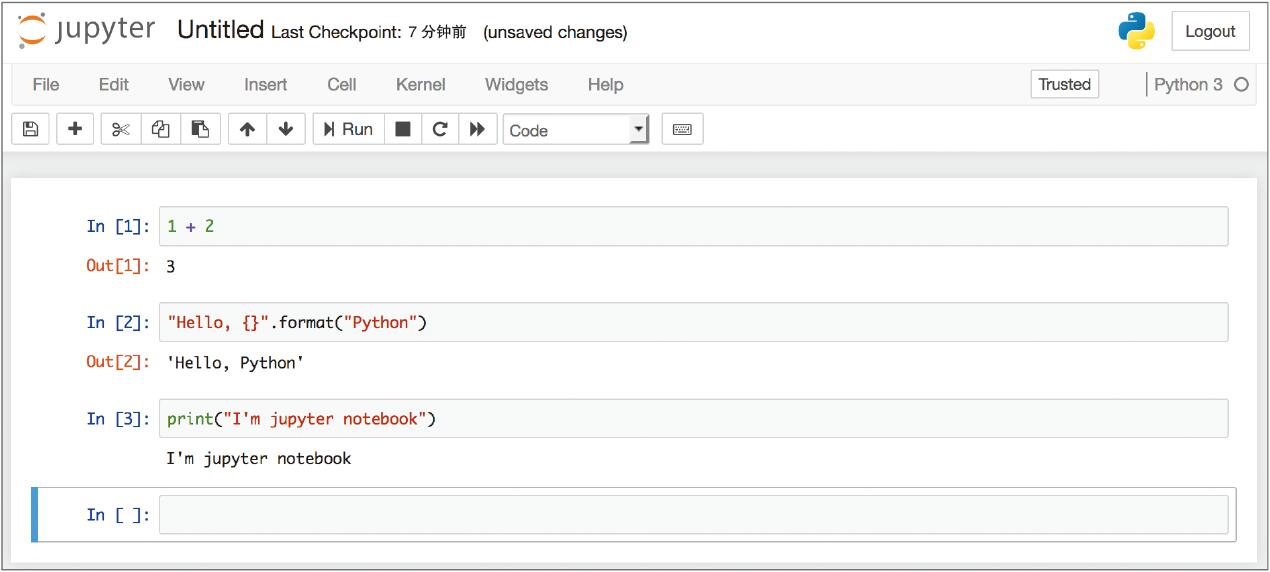
▲图 1-11 在 Jupyter Notebook 上运行 Python 代码
下面依次来看一下例题及其实现。
在 Jupyter Notebook 上运行 Python 程序,进行机器学习的实验。Jupyter Notebook 不仅能运行 Python,还可以作为 R 等语言的运行环境。
关于 Jupyter Notebook 的安装和环境设置方法,请参考第 5 章。
启动方法
在 Jupyter Notebook 安装成功后,就可以使用 jupyter 命令了。我们可以从命令提示行和终端运行 jupyter notebook 命令。
$ jupyter notebook
在命令运行后,浏览器将自动打开,显示已运行的当前目录的文件或文件夹(图 1-12)。在 Web 浏览器上的单元格内输入程序代码后,页面上将显示运行结果。运行结果为 notebook 格式的文件,以 .ipynb 扩展名保存。用户还可以在自己的计算机上打开其他人创建的 .ipynb 文件,按顺序执行每个单元格并查看其运行结果。也可以查看中间处理的变量,改变条件再次运行以查看不同的结果。此外,把这种文件提交到 GitHub 后,不仅可以分享运行结果,还可以在 GitHub 上以图形显示运行结果。
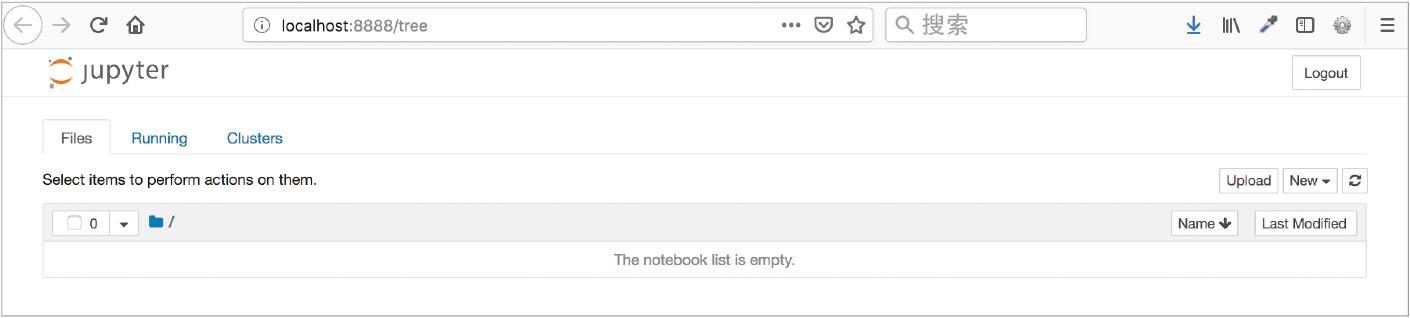
▲图 1-12 显示文件列表
用法
从右上角的 New 菜单选择 Python 3,可新建 notebook 格式的文件(图 1-13)。
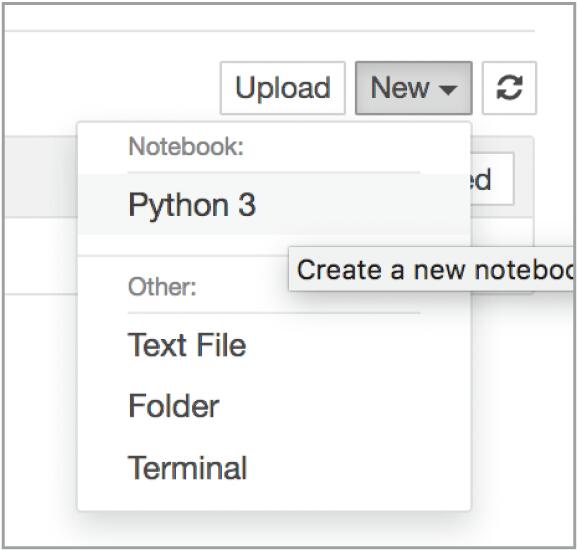
▲图 1-13 新建 notebook文件
Web 浏览器将打开新建的文件。
在叫作单元格的输入框里编写程序代码。此外,单元格有不同的种类,可通过界面上的 Code 和 Markdown 等下拉菜单决定单元格的作用。默认选项是 Code,系统将其识别为可运行的单元格(图 1-14)。
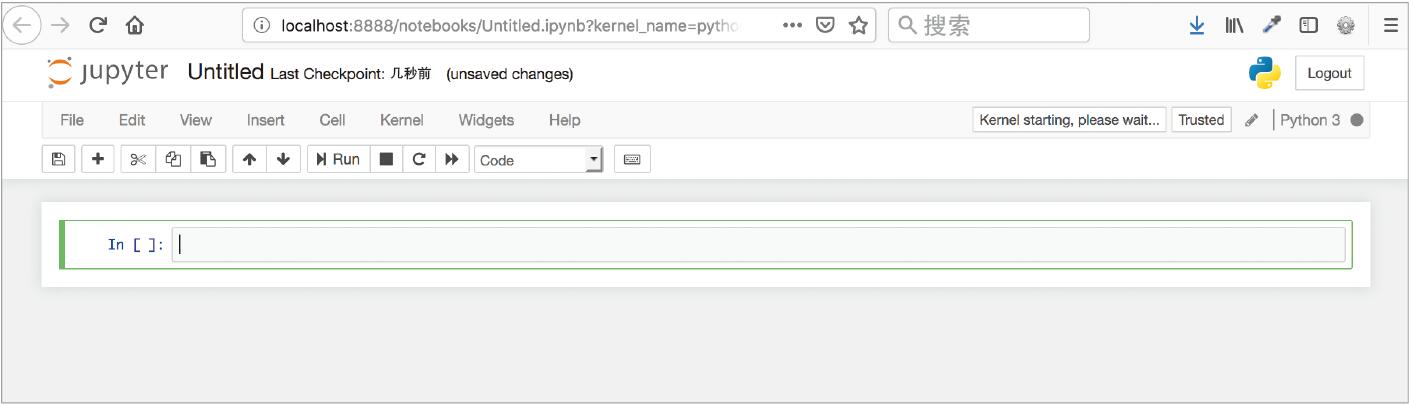
▲图 1-14 可运行的 notebook
在单元格内输入程序代码后,使用 Enter 键在单元格内换行,使用 Ctrl 和 Enter 组合键运行程序代码。另外,可使用 Shift 和 Enter 组合键运行程序代码,并移动到下一个单元格。
点击上部的标题 Untitled,可修改文件的标题(图 1-15)。Jupyter Notebook 会自动在此处确定的标题后附加扩展名 .ipynb,以此作为文件名创建文件。
▲图 1-15 修改 notebook的标题
从菜单选择 Save and Checkpoint,可保存当前的状态。
上面简要地介绍了 Jupyter Notebook 的使用方法。除此之外,它还有很多方便的用法,感兴趣的读者可参考官网、相关的文章和图书。
图形的种类和画法:使用 Matplotlib显示图形的方法
在页面上显示图形
在 Jupyter Notebook 页面上可显示图形。在 Code 单元格内,运行 %matplotlib inline 这个以 % 开始的“魔法”命令后,即使不运行后面将介绍的 show 方法,页面上也会输出图形(图 1-16)。
▲图 1-16 在 notebook内显示图形
下面看一下图 1-16 中的代码。
▼示例代码
import numpy as npimport matplotlib.pyplot as plt
上面的代码为了生成数据而导入了 numpy,为了显示图形而导入了 matplotlib。NumPy 是以数组形式处理数据并进行高效计算的 Python 第三方包。习惯上分别以别名 np 和 plt 调用 numpy 和 matplotlib 的 pyplot。
下面以 sin 曲线为例,显示其图形。
▼示例代码
x1 = np.linspace(-5, 5, 101)y1 = np.sin(x1)
x1中保存的是为显示 sin 曲线而生成的从 -5 到 5 的 101 个数据。y1中保存的是使用 NumPy 的sin函数生成的数据。
下面以用 Matplotlib 绘制 sin 曲线的图形为例进行说明。
最简单的显示图形的方法是 plt.plot(x1, y1)(图 1-17)。
▼示例代码
plt.plot(x1, y1)
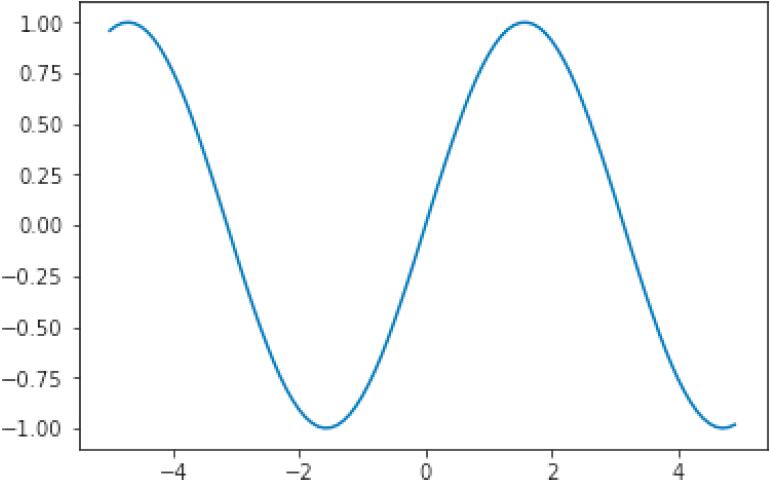
▲图 1-17 sin 曲线的图形
下面介绍使用 Matplotlib 绘制图形的代码的标准写法。前面只是简单地调用了 plt.plot,这种做法没有明确输出对象,只是声明“在这里绘图”,比较粗糙。严密的做法应为先创建要绘制的对象,再输出图形,代码及图形如下(图 1-18)。
▼示例代码
fig, ax = plt.subplots()ax.set_title("Sin")ax.set_xlabel("rad")ax.plot(x1, y1)handles, labels = ax.get_legend_handles_labels()ax.legend(handles, labels)plt.show()
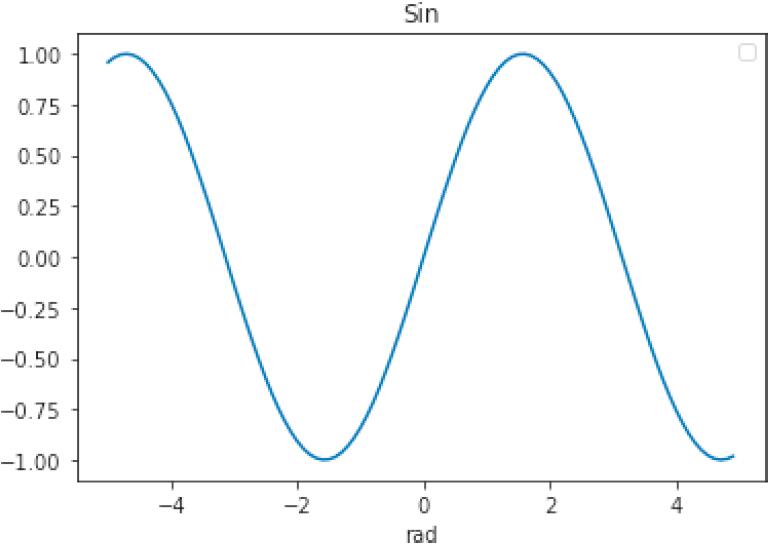
▲图 1-18 先创建对象再输出图形
上面的代码包含了显示标签和坐标轴名称等信息的处理,因此变成了 7 行,但其中用于显示图形的主要代码只有 ax.plot(x1, y1) 一行。虽然这种方法更受欢迎,不过如果要输出简单的图形,可以使用 plt.plot(x1, y1) 形式。请记住,方法共有两种:一种是 plt.plot 这种简易方法;另一种是 ax.plot 这种严密地面向对象进行声明的方法。最后运行 plt.show()。如果已运行魔法命令 %matplotlib inline,那就不用特意调用 show 了。为了使代码在 Jupyter Notebook 之外的环境中也能输出图形,这里特意编写了这一行代码。不管写不写这行代码,图形都会在 Jupyter Notebook 中显示。
绘制各种图形
首先生成用于显示图形的数据。
▼示例代码
x2 = np.arange(100)y2 = x2 * np.random.rand(100)
x2 中保存的是元素为“从 0 到 99 的整数”的数组。 y2 中保存的是元素为“在从 0 到 1 的范围内随机选出的 100 个数据”的数组与刚才的变量 x2 相乘的结果。
下面将使用这两个变量绘制各种图形。
接下来要展示的是通过 plt 变量声明图形形式的简易方法的示例。对于前面代码中明示图形位置的 ax 变量,我们也可以用同样的方式输出其图形。
● 散点图
使用 scatter 方法绘制散点图。
▼示例代码
plt.scatter(x2, y2)
x2 和 y2 的散点图如图 1-19 所示。
▲图 1-19 散点图
● 直方图
使用 hist 方法绘制直方图。
▼示例代码
plt.hist(y2, bins=5)
设 y2 的直方图的 bin 为 5,输出的图形如图 1-20 所示。
▲图 1-20 直方图
● 柱状图
使用 bar 方法绘制柱状图。
▼示例代码
plt.bar(x2, y2)
输出的柱状图如图 1-21 所示。
▲图 1-21 柱状图
● 折线图
使用 plot 方法绘制折线图。
▼示例代码
plt.plot(x2, y2)
x2 和 y2 的折线图如图 1-22 所示。

▲图 1-22 折线图
● 箱形图
使用 boxplot 方法绘制箱形图。
▼示例代码
plt.boxplot(y2)
用箱形图输出 y2 的数据,如图 1-23 所示。箱形图是查看数据分布的优秀的可视化方法。
▲图 1-23 箱形图
红酒数据集
下面对 scikit-learn 内置的红酒数据进行可视化。
▼示例代码
from sklearn.datasets import load_winedata = load_wine()
加载与红酒有关的数据,并将数据保存在变量 data 中。
▼示例代码
x3 = data.data[:, [0]]y3 = data.data[:, [9]]
将要显示的索引为 0 的 alcohol(酒精度)和索引为 9 的 color_intensity(色泽)数据分别赋值给 x3 和 y3。
下面输出散点图(图 1-24)。
▼示例代码
plt.scatter(x3, y3)
▲图 1-24 红酒数据集的散点图
下面输出 y3 的直方图(图 1-25)。
▼示例代码
plt.hist(y3, bins=5)
▲图 1-25 y3 的直方图
通过可视化查看与红酒数据集相关的两个图形,我们可以了解数据的特性。
使用 pandas 理解和处理数据
注意 在进行机器学习时,有时会查看特征值、对数据进行取舍选择或再加工等。下面将介绍如何使用 pandas 库的数据可视化的方便功能去了解数据的情况。已经知道 pandas 基本用法的读者和想先了解机器学习算法的读者,跳过这一部分也没关系。
下面介绍使用 pandas 库进行数据可视化的方便功能。
▼示例代码
import pandas as pd
上面的代码导入了常用于机器学习数据的变形等操作的 pandas。与 numpy 的 np 一样,习惯上用 pd 来调用它。
▼示例代码
from sklearn.datasets import load_winedata = load_wine()df_X = pd.DataFrame(data.data, columns=data.feature_names)
然后将红酒数据转换为 pandas 的 DataFrame。
DataFrame 可以方便地处理像 Excel 工作表那样的二维数据。df_X 是 DataFrame 形式的特征值。
下面的代码调用 head 方法输出了数据集前 5 行的数据(表 1-9),用于查看数据集中包含了什么样的数据。
▼示例代码
df_X.head()
▼表 1-9 红酒数据
| alcohol | malic_ acid | ash | alcalinity_ of_ash | magnesium | total_ phenols | flavanoids | nonflavanoid_ phenols | proanthocyanins | color_ intensity | hue | od280/ od315of diluted_ wines | proline | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 14.23 | 1.71 | 2.43 | 15.6 | 127.0 | 2.80 | 3.06 | 0.28 | 2.29 | 5.64 | 1.04 | 3.92 | 1065.0 |
| 1 | 13.20 | 1.78 | 2.14 | 11.2 | 100.0 | 2.65 | 2.76 | 0.26 | 1.28 | 4.38 | 1.05 | 3.40 | 1050.0 |
| 2 | 13.16 | 2.36 | 2.67 | 18.6 | 101.0 | 2.80 | 3.24 | 0.30 | 2.81 | 5.68 | 1.03 | 3.17 | 1185.0 |
| 3 | 14.37 | 1.95 | 2.50 | 16.8 | 113.0 | 3.85 | 3.49 | 0.24 | 2.18 | 7.80 | 0.86 | 3.45 | 1480.0 |
| 4 | 13.24 | 2.59 | 2.87 | 21.0 | 118.0 | 2.80 | 2.69 | 0.39 | 1.82 | 4.32 | 1.04 | 2.93 | 735.0 |
接着将红酒数据的目标变量转换为 pandas 的 DataFrame。
▼示例代码
df_y = pd.DataFrame(data.target, columns=["kind(target)"])
接下来看一下转换后的数据。做法和刚才相同:调用 head 方法。从表 1-10 中可以看出,df_y 是名副其实的目标变量数据。
▼示例代码
df_y.head()
▼表 1-10 红酒数据的目标变量
| kind(target) | |
|---|---|
| 0 | 0 |
| 1 | 0 |
| 2 | 0 |
| 3 | 0 |
| 4 | 0 |
为了便于使用,我们将这些数据合并在一起。下面使用 pandas 的 concat 将特征值 df_X 和目标变量 df_y 合并。
▼示例代码
df = pd.concat([df_X, df_y], axis=1)
输出数据的前几行看看。下面的代码使用 head 方法输出了合并结果的前 5 行(表 1-11)。这样就得到了包含特征值和目标变量的数据。
▼示例代码
df.head()
▲表 1-11 红酒数据的特征值和目标变量
| alcohol | malic_ acid | ash | alcalinity_ of_ash | magnesium | total_ phenols | flavanoids | nonflavanoid_ phenols | proanthocyanins | color_ intensity | hue | od280/ od315of diluted_ wines | proline | kind (target) | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 14.23 | 1.71 | 2.43 | 15.6 | 127.0 | 2.80 | 3.06 | 0.28 | 2.29 | 5.64 | 1.04 | 3.92 | 1065.0 | 0 |
| 1 | 13.20 | 1.78 | 2.14 | 11.2 | 100.0 | 2.65 | 2.76 | 0.26 | 1.28 | 4.38 | 1.05 | 3.40 | 1050.0 | 0 |
| 2 | 13.16 | 2.36 | 2.67 | 18.6 | 101.0 | 2.80 | 3.24 | 0.30 | 2.81 | 5.68 | 1.03 | 3.17 | 1185.0 | 0 |
| 3 | 14.37 | 1.95 | 2.50 | 16.8 | 113.0 | 3.85 | 3.49 | 0.24 | 2.18 | 7.80 | 0.86 | 3.45 | 1480.0 | 0 |
| 4 | 13.24 | 2.59 | 2.87 | 21.0 | 118.0 | 2.80 | 2.69 | 0.39 | 1.82 | 4.32 | 1.04 | 2.93 | 735.0 | 0 |
接下来,通过可视化和数理统计来分析这份数据。
图 1-26 是以直方图的形式输出的 alcohol 列的数据。由于下面的代码没有指定 bins 参数,所以程序使用默认的参数值 10,输出了有 10 个区间的直方图。
▼示例代码
plt.hist(df.loc[:, "alcohol"])
▲图 1-26 有 10个区间的直方图
图 1-27 是以箱形图显示的同一个 alcohol 列的数据。接下来开始使用 pandas 的统计功能。
▼示例代码
plt.boxplot(df.loc[:, "alcohol"])
▲图 1-27 以箱形图显示的 alcohol 列的数据
下面的代码使用 corr 方法汇总计算并输出了相关系数(表 1-12)。相关系数越接近于 1,越表明数据之间是正相关关系;越接近于 -1,越表明数据之间是负相关关系。换言之,如果相关系数在 0 左右,表明数据列之间的相关性很低。
▼示例代码
df.corr()
▼表 1-12 相关系数
| alcohol | malic_ acid | ash | alcalinity_ of_ash | magnesium | total_ phenols | flavanoids | nonflavanoid_ phenols | proanthocyanins | color_ intensity | hue | od280/ od315of diluted_ wines | proline | kind (target) | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| alcohol | 1.000 000 | 0.094 397 | 0.211 545 | -0.310 235 | 0.270 798 | 0.289 101 | 0.236 815 | -0.155 929 | 0.136 698 | 0.546 364 | -0.071 747 | 0.072 343 | 0.643 720 | -0.328 222 |
| malic_acid | 0.094 397 | 1.000 000 | 0.164 045 | 0.288 500 | -0.054 575 | -0.335 167 | -0.411 007 | 0.292 977 | -0.220 746 | 0.248 985 | -0.561 296 | -0.368 710 | -0.192 011 | 0.437 776 |
| ash | 0.211 545 | 0.164 045 | 1.000 000 | 0.443 367 | 0.286 587 | 0.128 980 | 0.115 077 | 0.186 230 | 0.009 652 | 0.258 887 | -0.074 667 | 0.003 911 | 0.223 626 | -0.049 643 |
| alcalinity_of_ash | -0.310 235 | 0.288 500 | 0.443 367 | 1.000 000 | -0.083 333 | -0.321 113 | -0.351 370 | 0.361 922 | -0.197 327 | 0.018 732 | -0.273 955 | -0.276 769 | -0.440 597 | 0.517 859 |
| magnesium | 0.270 798 | -0.054 575 | 0.286 587 | -0.083 333 | 1.000 000 | 0.214 401 | 0.195 784 | -0.256 294 | 0.236 441 | 0.199 950 | 0.055 398 | 0.066 004 | 0.393 351 | -0.209 179 |
| total_phenols | 0.289 101 | -0.335 167 | 0.128 980 | -0.321 113 | 0.214 401 | 1.000 000 | 0.864 564 | -0.449 935 | 0.612 413 | -0.055 136 | 0.433 681 | 0.699 949 | 0.498 115 | -0.719 163 |
| flavanoids | 0.236 815 | -0.411 007 | 0.115 077 | -0.351 370 | 0.195 784 | 0.864 564 | 1.000 000 | -0.537 900 | 0.652 692 | -0.172 379 | 0.543 479 | 0.787 194 | 0.494 193 | -0.847 498 |
| nonflavanoid_ phenols | -0.155 929 | 0.292 977 | 0.186 230 | 0.361 922 | -0.256 294 | -0.449 935 | -0.537 900 | 1.000 000 | -0.365 845 | 0.139 057 | -0.262 640 | -0.503 270 | -0.311 385 | 0.489 109 |
| proanthocyanins | 0.136 698 | -0.220 746 | 0.009 652 | -0.197 327 | 0.236 441 | 0.612 413 | 0.652 692 | -0.365 845 | 1.000 000 | -0.025 250 | 0.295 544 | 0.519 067 | 0.330 417 | -0.499 130 |
| color_intensity | 0.546 364 | 0.248 985 | 0.258 887 | 0.018 732 | 0.199 950 | -0.055 136 | -0.172 379 | 0.139 057 | -0.025 250 | 1.000 000 | -0.521 813 | -0.428 815 | 0.316 100 | 0.265 668 |
| hue | -0.071 747 | -0.561 296 | -0.074 667 | -0.273 955 | 0.055 398 | 0.433 681 | 0.543 479 | -0.262 640 | 0.295 544 | -0.521 813 | 1.000 000 | 0.565 468 | 0.236 183 | -0.617 369 |
| od280/od315_ of_diluted_wines | 0.072 343 | -0.368 710 | 0.003 911 | -0.276 769 | 0.066 004 | 0.699 949 | 0.787 194 | -0.503 270 | 0.519 067 | -0.428 815 | 0.565 468 | 1.000 000 | 0.312 761 | -0.788 230 |
| proline | 0.643 720 | -0.192 011 | 0.223 626 | -0.440 597 | 0.393 351 | 0.498 115 | 0.494 193 | -0.311 385 | 0.330 417 | 0.316 100 | 0.236 183 | 0.312 761 | 1.000 000 | -0.633 717 |
| kind(target) | -0.328 222 | 0.437 776 | -0.049 643 | 0.517 859 | -0.209 179 | -0.719 163 | -0.847 498 | 0.489 109 | -0.499 130 | 0.265 668 | -0.617 369 | -0.788 230 | -0.633 717 | 1.000 000 |
下面再介绍一个查看数据情况的方法。
describe 方法用于输出每列的统计信息。输出的统计信息从上到下依次为行数、平均值、标准差、最小值、25 百分位数、中位数、75 百分位数、最大值(表 1-13)。从统计信息可以看出每列包含的数据具有何种特性、有没有缺损等信息。
▼示例代码
df.describe()
▼表 1-13 统计信息
| alcohol | malic_ acid | ash | alcalinity_ of_ash | magnesium | total_ phenols | flavanoids | nonflavanoid_ phenols | proanthocyanins | color_ intensity | hue | od280/ od315of diluted_ wines | proline | kind (target) | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 178.000 000 | 178.000 000 | 178.000 000 | 178.000 000 | 178.000 000 | 178.000 000 | 178.000 000 | 178.000 000 | 178.000 000 | 178.000 000 | 178.000 000 | 178.000 000 | 178.000 000 | 178.000 000 |
| mean | 13.000 618 | 2.336 348 | 2.366 517 | 19.494 944 | 99.741 573 | 2.295 112 | 2.029 270 | 0.361 854 | 1.590 899 | 5.058 090 | 0.957 449 | 2.611 685 | 746.893 258 | 0.938 202 |
| std | 0.811 827 | 1.117 146 | 0.274 344 | 3.339 564 | 14.282 484 | 0.625 851 | 0.998 859 | 0.124 453 | 0.572 359 | 2.318 286 | 0.228 572 | 0.709 990 | 314.907 474 | 0.775 035 |
| min | 11.030 000 | 0.740 000 | 1.360 000 | 10.600 000 | 70.000 000 | 0.980 000 | 0.340 000 | 0.130 000 | 0.410 000 | 1.280 000 | 0.480 000 | 1.270 000 | 278.000 000 | 0.000 000 |
| 25% | 12.362 500 | 1.602 500 | 2.210 000 | 17.200 000 | 88.000 000 | 1.742 500 | 1.205 000 | 0.270 000 | 1.250 000 | 3.220 000 | 0.782 500 | 1.937 500 | 500.500 000 | 0.000 000 |
| 50% | 13.050 000 | 1.865 000 | 2.360 000 | 19.500 000 | 98.000 000 | 2.355 000 | 2.135 000 | 0.340 000 | 1.555 000 | 4.690 000 | 0.965 000 | 2.780 000 | 673.500 000 | 1.000 000 |
| 75% | 13.677 500 | 3.082 500 | 2.557 500 | 21.500 000 | 107.000 000 | 2.800 000 | 2.875 000 | 0.437 500 | 1.950 000 | 6.200 000 | 1.120 000 | 3.170 000 | 985.000 000 | 2.000 000 |
| max | 14.830 000 | 5.800 000 | 3.230 000 | 30.000 000 | 162.000 000 | 3.880 000 | 5.080 000 | 0.660 000 | 3.580 000 | 13.000 000 | 1.710 000 | 4.000 000 | 1680.000 000 | 2.000 000 |
下面使用 pandas 的功能将所有列之间的关系可视化(图 1-28)。
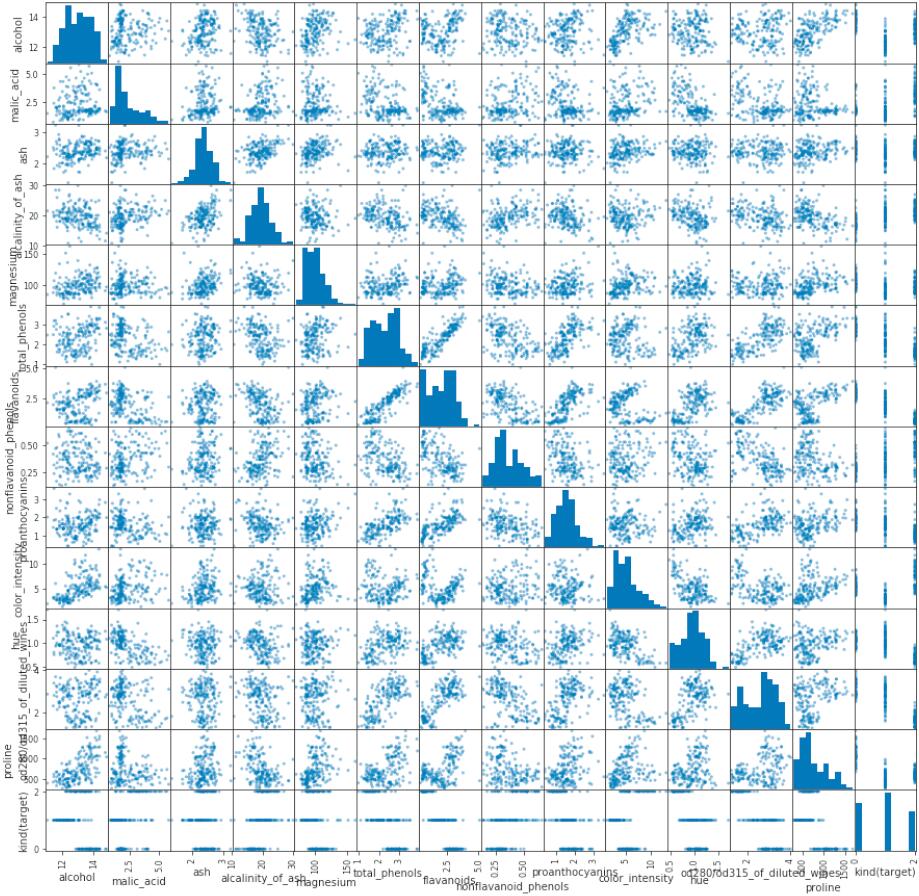
▲图 1-28 各列的关联性
使用 scatter_matrix 输出散点图矩阵。这里将 14 列全都输出了出来(图 1-28)。
▼示例代码
from pandas.plotting import scatter_matrix_ = scatter_matrix(df, figsize=(15, 15))
下面只查看部分列的关联性。
下列代码输出的是从所有散点图矩阵中选出的索引为 0 的列、索引为 9 的列和最后一列的关联性(图 1-29)。通过像这样减少散点图矩阵输出的列,能够看出更细致的情况。
▼示例代码
_ = scatter_matrix(df.iloc[:, [0, 9, -1]])
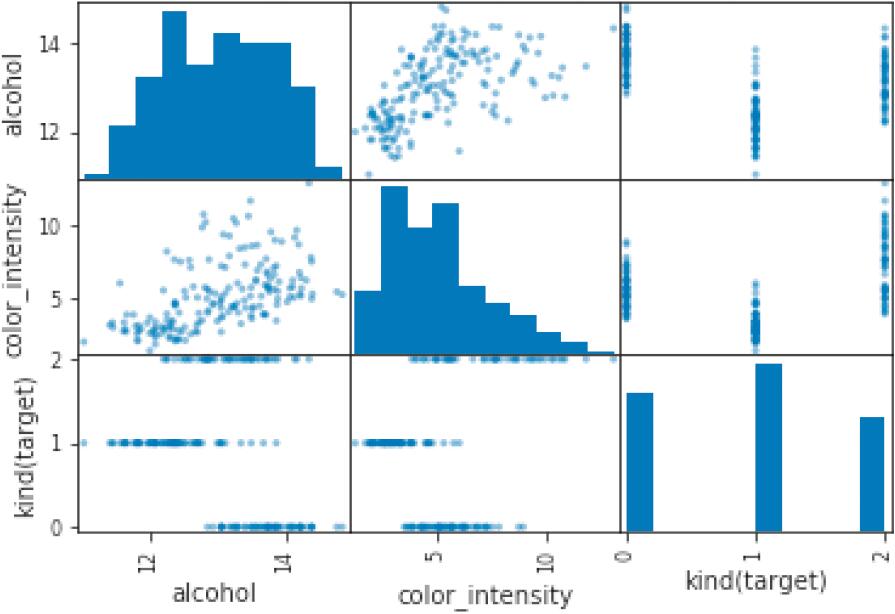
▲图 1-29 显示重要的关联性
本章小结
本章前半部分介绍了机器学习的基础内容:机器学习包括有监督学习和无监督学习等,存在与分类问题、回归问题、降维和聚类对应的算法。
后半部分介绍了机器学习库 scikit-learn,并列举了有监督学习(分类)和无监督学习(聚类)的实现示例。最后,我们了解了使用可视化工具 Matplotlib 显示图形的方法。到这里,事前准备工作就结束了。从下一章开始,我们将正式学习机器学习的算法。

若有收获,就点个赞吧
0 人点赞
