本章和第 3 章将介绍通过 Python 有效导入、存储和操作内存数据的主要技巧。这个主题非常广泛,因为数据集的来源与格式都十分丰富,比如文档集合、图像集合、声音片段集合、数值数据集合,等等。这些数据虽然存在明显的异构性,但是将所有数据简单地看作数字数组非常有助于我们理解和处理数据。
例如,可以将图像(尤其是数字图像)简单地看作二维数字数组,这些数字数组代表各区域的像素值;声音片段可以看作时间和强度的一维数组;文本也可以通过各种方式转换成数值表示,一种可能的转换是用二进制数表示特定单词或单词对出现的频率。不管数据是何种形式,第一步都是将这些数据转换成数值数组形式的可分析数据。
正因如此,有效地存储和操作数值数组是数据科学中绝对的基础过程。我们将介绍 Python 中专门用来处理这些数值数组的工具:NumPy 包和 Pandas 包(将在第 3 章介绍)。
本章将详细介绍 NumPy。NumPy(Numerical Python 的简称)提供了高效存储和操作密集数据缓存的接口。在某些方面,NumPy 数组与 Python 内置的列表类型非常相似。但是随着数组在维度上变大,NumPy 数组提供了更加高效的存储和数据操作。NumPy 数组几乎是整个 Python 数据科学工具生态系统的核心。因此,不管你对数据科学的哪个方面感兴趣,花点时间学习如何有效地使用 NumPy 都是非常值得的。
已经安装好 NumPy,可以导入 NumPy 并再次核实你的 NumPy 版本:
In[1]: import numpynumpy.__version__Out[1]: '1.11.1'
针对本章中介绍的 NumPy 功能,我建议你使用 NumPy 1.8 及之后的版本。遵循传统,你将发现 SciPy / PyData 社区中的大多数人都用 **np** 作为别名导入 NumPy:
In[2]: import numpy as np
在本章以及之后的内容中,我们都将用这种方式导入和使用 NumPy。
2.1 理解Python中的数据类型
要实现高效的数据驱动科学和计算,需要理解数据是如何被存储和操作的。本节将介绍在 Python 语言中数据数组是如何被处理的,并对比 NumPy 所做的改进。理解这个不同之处是理解本书其他内容的基础。
Python 的用户往往被其易用性所吸引,其中一个易用之处就在于动态输入。静态类型的语言(如 C 或 Java)往往需要每一个变量都明确地声明,而动态类型的语言(例如 Python)可以跳过这个特殊规定。例如在 C 语言中,你可能会按照如下方式指定一个特殊的操作:
/* C代码 */int result = 0;for(int i=0; i<100; i++){result += i;}
而在 Python 中,同等的操作可以按照如下方式实现:
# Python代码result = 0for i in range(100):result += i
注意这里最大的不同之处:在 C 语言中,每个变量的数据类型被明确地声明;而在 Python 中,类型是动态推断的。这意味着可以将任何类型的数据指定给任何变量:
# Python代码x = 4x = "four"
这里已经将 x 变量的内容由整型转变成了字符串,而同样的操作在 C 语言中将会导致(取决于编译器设置)编译错误或其他未知的后果:
/* C代码 */int x = 4;x = "four"; // 编译失败
这种灵活性是使 Python 和其他动态类型的语言更易用的原因之一。理解这一特性如何工作是学习用 Python 有效且高效地分析数据的重要因素。但是这种类型灵活性也指出了一个事实:Python 变量不仅是它们的值,还包括了关于值的类型的一些额外信息,本节接下来的内容将进行更详细的介绍。
2.1.1 Python整型不仅仅是一个整型
标准的 Python 实现是用 C 语言编写的。这意味着每一个 Python 对象都是一个聪明的伪 C 语言结构体,该结构体不仅包含其值,还有其他信息。例如,当我们在 Python 中定义一个整型,例如 x = 10000 时,x 并不是一个“原生”整型,而是一个指针,指向一个 C 语言的复合结构体,结构体里包含了一些值。查看 Python 3.4 的源代码,可以发现整型(长整型)的定义,如下所示(C 语言的宏经过扩展之后):
struct _longobject {long ob_refcnt;PyTypeObject *ob_type;size_t ob_size;long ob_digit[1];};
Python 3.4 中的一个整型实际上包括 4 个部分。
ob_refcnt是一个引用计数,它帮助 Python 默默地处理内存的分配和回收。ob_type将变量的类型编码。ob_size指定接下来的数据成员的大小。ob_digit包含我们希望 Python 变量表示的实际整型值。
这意味着与 C 语言这样的编译语言中的整型相比,在 Python 中存储一个整型会有一些开销,正如图 2-1 所示。
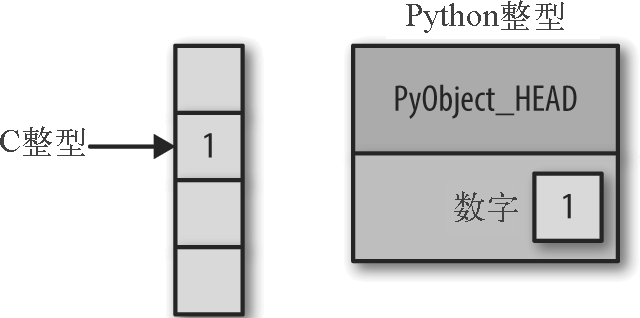
图 2-1:C 整型和 Python 整型的区别
这里 PyObject_HEAD 是结构体中包含引用计数、类型编码和其他之前提到的内容的部分。
两者的差异在于,C 语言整型本质上是对应某个内存位置的标签,里面存储的字节会编码成整型。而 Python 的整型其实是一个指针,指向包含这个 Python 对象所有信息的某个内存位置,其中包括可以转换成整型的字节。由于 Python 的整型结构体里面还包含了大量额外的信息,所以 Python 可以自由、动态地编码。但是,Python 类型中的这些额外信息也会成为负担,在多个对象组合的结构体中尤其明显。
2.1.2 Python列表不仅仅是一个列表
设想如果使用一个包含很多 Python 对象的 Python 数据结构,会发生什么? Python 中的标准可变多元素容器是列表。可以用如下方式创建一个整型值列表:
In[1]: L = list(range(10))LOut[1]: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]In[2]: type(L[0])Out[2]: int
或者创建一个字符串列表:
In[3]: L2 = [str(c) for c in L]L2Out[3]: ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9']In[4]: type(L2[0])Out[4]: str
因为 Python 的动态类型特性,甚至可以创建一个异构的列表:
In[5]: L3 = [True, "2", 3.0, 4][type(item) for item in L3]Out[5]: [bool, str, float, int]
但是想拥有这种灵活性也是要付出一定代价的:为了获得这些灵活的类型,列表中的每一项必须包含各自的类型信息、引用计数和其他信息;也就是说,每一项都是一个完整的 Python 对象。来看一个特殊的例子,如果列表中的所有变量都是同一类型的,那么很多信息都会显得多余——将数据存储在固定类型的数组中应该会更高效。动态类型的列表和固定类型的(NumPy 式)数组间的区别如图 2-2 所示。
在实现层面,数组基本上包含一个指向连续数据块的指针。另一方面,Python 列表包含一个指向指针块的指针,这其中的每一个指针对应一个完整的 Python 对象(如前面看到的 Python 整型)。另外,列表的优势是灵活,因为每个列表元素是一个包含数据和类型信息的完整结构体,而且列表可以用任意类型的数据填充。固定类型的 NumPy 式数组缺乏这种灵活性,但是能更有效地存储和操作数据。
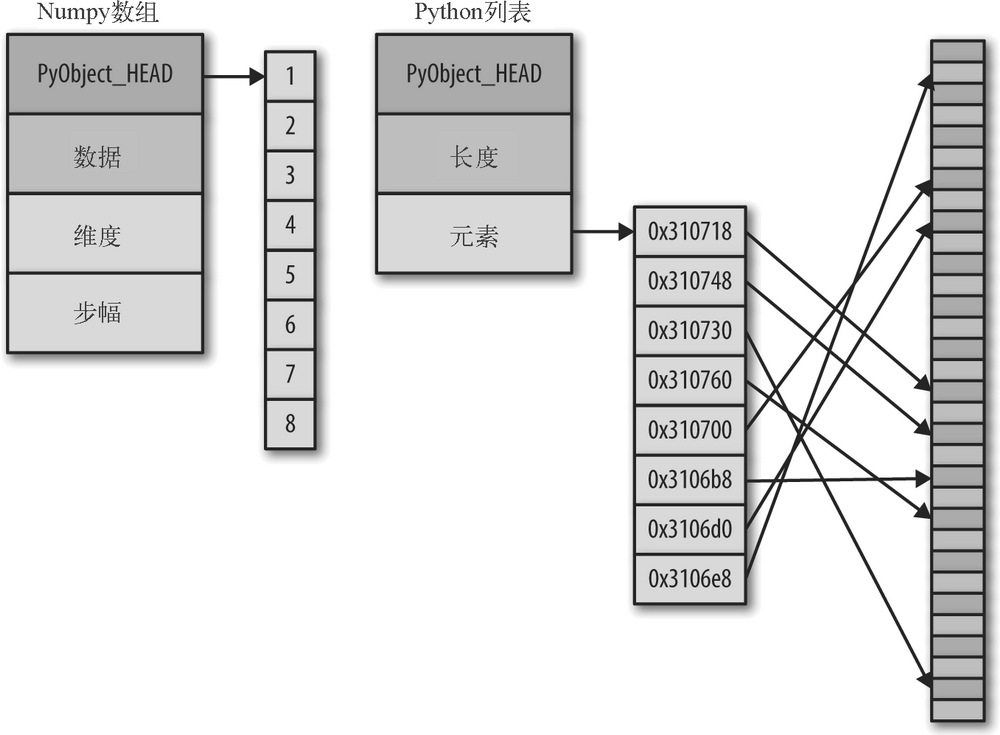
图 2-2:C 列表和 Python 列表的区别
- the hands-down simplest example when NumPy arrays beat lists is arithmetic
- more compact, especially when there’s more than one dimension
- faster than lists when the operation can be vectorized
- slower than lists when you append elements to the end
- usually homogeneous: can only work fast with elements of one type

2.1.3 Python中的固定类型数组
Python 提供了几种将数据存储在有效的、固定类型的数据缓存中的选项。内置的数组(array)模块(在 Python 3.3 之后可用)可以用于创建统一类型的密集数组:
In[6]: import arrayL = list(range(10))A = array.array('i', L)AOut[6]: array('i', [0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
这里的 'i' 是一个数据类型码,表示数据为整型。
更实用的是 NumPy 包中的 ndarray 对象。Python 的数组对象提供了数组型数据的有效存储,而 NumPy 为该数据加上了高效的操作。稍后将介绍这些操作,这里先展示几种创建 NumPy 数组的方法。
从用 np 别名导入 NumPy 的标准做法开始:
In[7]: import numpy as np
2.1.4 从Python列表创建数组
首先,可以用 np.array 从 Python 列表创建数组:

In[8]: # 整型数组:np.array([1, 4, 2, 5, 3])Out[8]: array([1, 4, 2, 5, 3])
请记住,不同于 Python 列表,NumPy 要求数组必须包含同一类型的数据。如果类型不匹配,NumPy 将会向上转换(如果可行)。这里整型被转换为浮点型:
In[9]: np.array([3.14, 4, 2, 3])Out[9]: array([ 3.14, 4. , 2. , 3. ])
如果希望明确设置数组的数据类型,可以用 dtype 关键字:
In[10]: np.array([1, 2, 3, 4], dtype='float32')Out[10]: array([ 1., 2., 3., 4.], dtype=float32)
最后,不同于 Python 列表,NumPy 数组可以被指定为多维的。以下是用列表的列表初始化多维数组的一种方法:
In[11]: # 嵌套列表构成的多维数组np.array([range(i, i + 3) for i in [2, 4, 6]])Out[11]: array([[2, 3, 4],[4, 5, 6],[6, 7, 8]])
内层的列表被当作二维数组的行。
2.1.5 从头创建数组
面对大型数组的时候,用 NumPy 内置的方法从头创建数组是一种更高效的方法。以下是几个示例: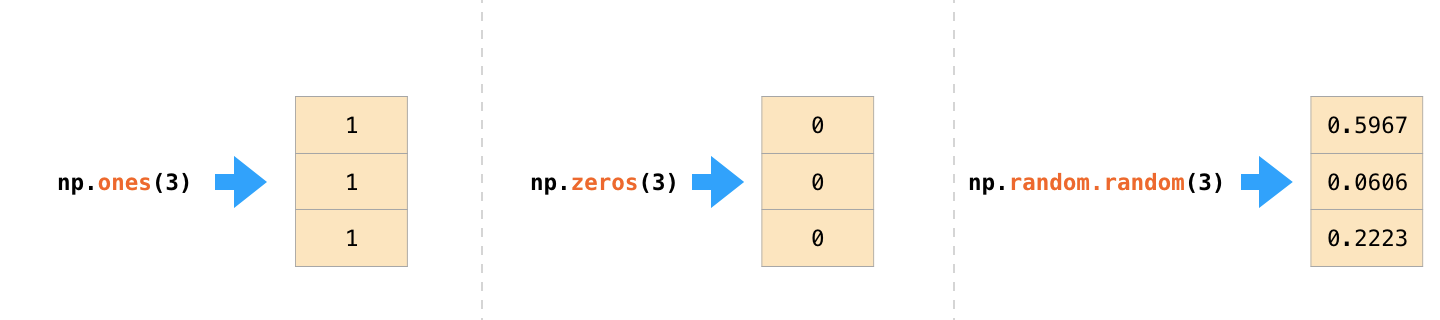

In[12]: # 创建一个长度为10的数组,数组的值都是0np.zeros(10, dtype=int)Out[12]: array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0])In[13]: # 创建一个3×5的浮点型数组,数组的值都是1np.ones((3, 5), dtype=float)Out[13]: array([[ 1., 1., 1., 1., 1.],[ 1., 1., 1., 1., 1.],[ 1., 1., 1., 1., 1.]])In[14]: # 创建一个3×5的浮点型数组,数组的值都是3.14np.full((3, 5), 3.14)Out[14]: array([[ 3.14, 3.14, 3.14, 3.14, 3.14],[ 3.14, 3.14, 3.14, 3.14, 3.14],[ 3.14, 3.14, 3.14, 3.14, 3.14]])In[15]: # 创建一个线性序列数组# 从0开始,到20结束,步长为2# (它和内置的range()函数类似)np.arange(0, 20, 2)Out[15]: array([ 0, 2, 4, 6, 8, 10, 12, 14, 16, 18])In[16]: # 创建一个5个元素的数组,这5个数均匀地分配到0~1np.linspace(0, 1, 5)Out[16]: array([ 0. , 0.25, 0.5 , 0.75, 1. ])In[17]: # 创建一个3×3的、在0~1均匀分布的随机数组成的数组np.random.random((3, 3))Out[17]: array([[ 0.99844933, 0.52183819, 0.22421193],[ 0.08007488, 0.45429293, 0.20941444],[ 0.14360941, 0.96910973, 0.946117 ]])In[18]: # 创建一个3×3的、均值为0、标准差为1的# 正态分布的随机数数组np.random.normal(0, 1, (3, 3))Out[18]: array([[ 1.51772646, 0.39614948, -0.10634696],[ 0.25671348, 0.00732722, 0.37783601],[ 0.68446945, 0.15926039, -0.70744073]])In[19]: # 创建一个3×3的、[0, 10)区间的随机整型数组np.random.randint(0, 10, (3, 3))Out[19]: array([[2, 3, 4],[5, 7, 8],[0, 5, 0]])In[20]: # 创建一个3×3的单位矩阵np.eye(3)Out[20]: array([[ 1., 0., 0.],[ 0., 1., 0.],[ 0., 0., 1.]])In[21]: # 创建一个由3个整型数组成的未初始化的数组# 数组的值是内存空间中的任意值np.empty(3)Out[21]: array([ 1., 1., 1.])
2.1.6 NumPy标准数据类型
NumPy 数组包含同一类型的值,因此详细了解这些数据类型及其限制是非常重要的。因为 NumPy 是在 C 语言的基础上开发的,所以 C、Fortran 和其他类似语言的用户会比较熟悉这些数据类型。
表 2-1 列出了标准 NumPy 数据类型。请注意,当构建一个数组时,你可以用一个字符串参数来指定数据类型:
np.zeros(10, dtype='int16')
或者用相关的 NumPy 对象来指定:
np.zeros(10, dtype=np.int16)
表2-1:NumPy标准数据类型
| 数据类型 | 描述 |
|---|---|
bool_ |
布尔值(真、True或假、 False),用一个字节存储 |
int_ |
默认整型(类似于 C 语言中的 long,通常情况下是 int64或 int32) |
intc |
同 C 语言的 int相同(通常是 int32或 int64) |
intp |
用作索引的整型(和 C 语言的 ssize_t相同,通常情况下是 int32或 int64) |
int8 |
字节(byte,范围从–128 到 127) |
int16 |
整型(范围从–32768 到 32767) |
int32 |
整型(范围从–2147483648 到 2147483647) |
int64 |
整型(范围从–9223372036854775808 到 9223372036854775807) |
uint8 |
无符号整型(范围从 0 到 255) |
uint16 |
无符号整型(范围从 0 到 65535) |
uint32 |
无符号整型(范围从 0 到 4294967295) |
uint64 |
无符号整型(范围从 0 到 18446744073709551615) |
float_ |
float64的简化形式 |
float16 |
半精度浮点型:符号比特位,5 比特位指数(exponent),10 比特位尾数(mantissa) |
float32 |
单精度浮点型:符号比特位,8 比特位指数,23 比特位尾数 |
float64 |
双精度浮点型:符号比特位,11 比特位指数,52 比特位尾数 |
complex_ |
complex128的简化形式 |
complex64 |
复数,由两个 32 位浮点数表示 |
complex128 |
复数,由两个 64 位浮点数表示 |
还可以进行更高级的数据类型指定,例如指定高位字节数或低位字节数;更多的信息可以在 NumPy 文档(http://numpy.org/)中查看。NumPy 也支持复合数据类型,这一点将会在 2.9 节中介绍。
2.2 NumPy数组基础
Python 中的数据操作几乎等同于 NumPy 数组操作,甚至新出现的 Pandas 工具(第 3 章将介绍)也是构建在 NumPy 数组的基础之上的。本节将展示一些用 NumPy 数组操作获取数据或子数组,对数组进行分裂、变形和连接的例子。本节介绍的操作类型可能读起来有些枯燥,但其中也包括了本书其他例子中将用到的内容,所以要好好了解这些内容!
我们将介绍以下几类基本的数组操作。
数组的属性
确定数组的大小、形状、存储大小、数据类型。
数组的索引
获取和设置数组各个元素的值。
数组的切分
在大的数组中获取或设置更小的子数组。
数组的变形
改变给定数组的形状。
数组的拼接和分裂
将多个数组合并为一个,以及将一个数组分裂成多个。
2.2.1 NumPy数组的属性
首先介绍一些有用的数组属性。定义三个随机的数组:一个一维数组、一个二维数组和一个三维数组。我们将用 NumPy 的随机数生成器设置一组种子值,以确保每次程序执行时都可以生成同样的随机数组:
In[1]: import numpy as npnp.random.seed(0) # 设置随机数种子x1 = np.random.randint(10, size=6) # 一维数组x2 = np.random.randint(10, size=(3, 4)) # 二维数组x3 = np.random.randint(10, size=(3, 4, 5)) # 三维数组
每个数组有 ndim(数组的维度)、shape(数组每个维度的大小)和 size(数组的总大小)属性:
In[2]: print("x3 ndim: ", x3.ndim)print("x3 shape:", x3.shape)print("x3 size: ", x3.size)x3 ndim: 3x3 shape: (3, 4, 5)x3 size: 60
另外一个有用的属性是 dtype,它是数组的数据类型(2.1 节讨论过):
In[3]: print("dtype:", x3.dtype)dtype: int64
其他的属性包括表示每个数组元素字节大小的 itemsize,以及表示数组总字节大小的属性 nbytes:
In[4]: print("itemsize:", x3.itemsize, "bytes")print("nbytes:", x3.nbytes, "bytes")itemsize: 8 bytesnbytes: 480 bytes
一般来说,可以认为 nbytes 跟 itemsize 和 size 的乘积大小相等。
2.2.2 数组索引

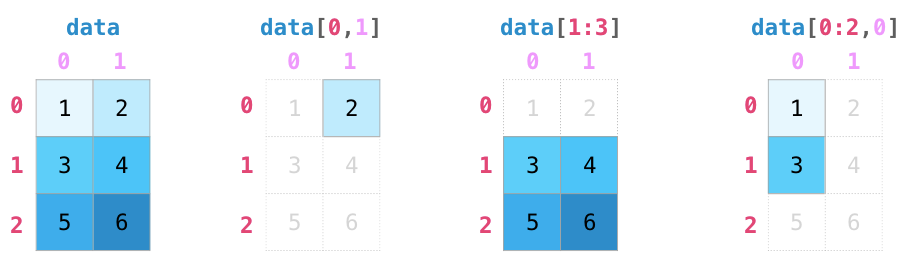
2.2.2.1 数组索引:获取单个元素
如果你熟悉 Python 的标准列表索引,那么你对 NumPy 的索引方式也不会陌生。和 Python 列表一样,在一维数组中,你也可以通过中括号指定索引获取第 i 个值(从 0 开始计数):
In[5]: x1Out[5]: array([5, 0, 3, 3, 7, 9])In[6]: x1[0]Out[6]: 5In[7]: x1[4]Out[7]: 7
为了获取数组的末尾索引,可以用负值索引:
In[8]: x1[-1]Out[8]: 9In[9]: x1[-2]Out[9]: 7
在多维数组中,可以用逗号分隔的索引元组获取元素:
In[10]: x2Out[10]: array([[3, 5, 2, 4],[7, 6, 8, 8],[1, 6, 7, 7]])In[11]: x2[0, 0]Out[11]: 3In[12]: x2[2, 0]Out[12]: 1In[13]: x2[2, -1]Out[13]: 7
也可以用以上索引方式修改元素值:
In[14]: x2[0, 0] = 12x2Out[14]: array([[12, 5, 2, 4],[ 7, 6, 8, 8],[ 1, 6, 7, 7]])
请注意,和 Python 列表不同,NumPy 数组是固定类型的。这意味着当你试图将一个浮点值插入一个整型数组时,浮点值会被截短成整型。并且这种截短是自动完成的,不会给你提示或警告,所以需要特别注意这一点!
In[15]: x1[0] = 3.14159 # 这将被截短x1Out[15]: array([3, 0, 3, 3, 7, 9])
2.2.2.2 数组切片:获取子数组
正如此前用中括号获取单个数组元素,我们也可以用切片(slice)符号获取子数组,切片符号用冒号(:)表示。NumPy 切片语法和 Python 列表的标准切片语法相同。为了获取数组 x 的一个切片,可以用以下方式:
x[start:stop:step]
如果以上 3 个参数都未指定,那么它们会被分别设置默认值 start=0、stop= 维度的大小(_size of dimension_)和 step=1。我们将详细介绍如何在一维和多维数组中获取子数组。
- 一维子数组
In[16]: x = np.arange(10)xOut[16]: array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])In[17]: x[:5] # 前五个元素Out[17]: array([0, 1, 2, 3, 4])In[18]: x[5:] # 索引五之后的元素Out[18]: array([5, 6, 7, 8, 9])In[19]: x[4:7] # 中间的子数组Out[19]: array([4, 5, 6])In[20]: x[::2] # 每隔一个元素Out[20]: array([0, 2, 4, 6, 8])In[21]: x[1::2] # 每隔一个元素,从索引1开始Out[21]: array([1, 3, 5, 7, 9])
你可能会在步长值为负时感到困惑。在这个例子中,start 参数和 stop 参数默认是被交换的。
因此这是一种非常方便的逆序数组的方式:
In[22]: x[::-1] # 所有元素,逆序的Out[22]: array([9, 8, 7, 6, 5, 4, 3, 2, 1, 0])In[23]: x[5::-2] # 从索引5开始每隔一个元素逆序Out[23]: array([5, 3, 1])
- 多维子数组
多维切片也采用同样的方式处理,用逗号分隔。例如: ``` In[24]: x2
Out[24]: array([[12, 5, 2, 4], [ 7, 6, 8, 8], [ 1, 6, 7, 7]])
In[25]: x2[:2, :3] # 两行,三列
Out[25]: array([[12, 5, 2], [ 7, 6, 8]])
In[26]: x2[:3, ::2] # 所有行,每隔一列
Out[26]: array([[12, 2], [ 7, 8], [ 1, 7]])
最后,子数组维度也可以同时被逆序:
In[27]: x2[::-1, ::-1]
Out[27]: array([[ 7, 7, 6, 1], [ 8, 8, 6, 7], [ 4, 2, 5, 12]])
3. **获取数组的行和列**<br />一种常见的需求是获取数组的单行和单列。你可以将索引与切片组合起来实现这个功能,用一个冒号(`:`)表示空切片:
In[28]: print(x2[:, 0]) # x2的第一列
[12 7 1]
In[29]: print(x2[0, :]) # x2的第一行
[12 5 2 4]
在获取行时,出于语法的简洁考虑,可以省略空的切片:
In[30]: print(x2[0]) #等于x2[0, :]
[12 5 2 4]
4. **非副本视图的子数组**<br />关于数组切片有一点很重要也非常有用,那就是数组切片返回的是数组数据的**视图**,而不是数值数据的**副本**。这一点也是 NumPy 数组切片和 Python 列表切片的不同之处:在 Python 列表中,切片是值的副本。例如此前示例中的那个二维数组:
In[31]: print(x2)
[[12 5 2 4] [ 7 6 8 8] [ 1 6 7 7]]
从中抽取一个 2×2 的子数组:
In[32]: x2_sub = x2[:2, :2] print(x2_sub)
[[12 5] [ 7 6]]
现在如果修改这个子数组,将会看到原始数组也被修改了!结果如下所示:```pythonIn[33]: x2_sub[0, 0] = 99print(x2_sub)[[99 5][ 7 6]]In[34]: print(x2)[[99 5 2 4][ 7 6 8 8][ 1 6 7 7]]
这种默认的处理方式实际上非常有用:它意味着在处理非常大的数据集时,可以获取或处理这些数据集的片段,而不用复制底层的数据缓存。 
- 创建数组的副本
尽管数组视图有一些非常好的特性,但是在有些时候明确地复制数组里的数据或子数组也是非常有用的。可以很简单地通过copy()方法实现:
In[35]: x2_sub_copy = x2[:2, :2].copy()print(x2_sub_copy)[[99 5][ 7 6]]
如果修改这个子数组,原始的数组不会被改变:
In[36]: x2_sub_copy[0, 0] = 42print(x2_sub_copy)[[42 5][ 7 6]]In[37]: print(x2)[[99 5 2 4][ 7 6 8 8][ 1 6 7 7]]
2.2.3 数组的变形
另一个有用的操作类型是数组的变形。数组变形最灵活的实现方式是通过 reshape() 函数来实现。例如,如果你希望将数字 1~9 放入一个 3×3 的矩阵中,可以采用如下方法:
In[38]: grid = np.arange(1, 10).reshape((3, 3))print(grid)[[1 2 3][4 5 6][7 8 9]]
请注意,如果希望该方法可行,那么原始数组的大小必须和变形后数组的大小一致。如果满足这个条件,reshape 方法将会用到原始数组的一个非副本视图。但实际情况是,在非连续的数据缓存的情况下,返回非副本视图往往不可能实现。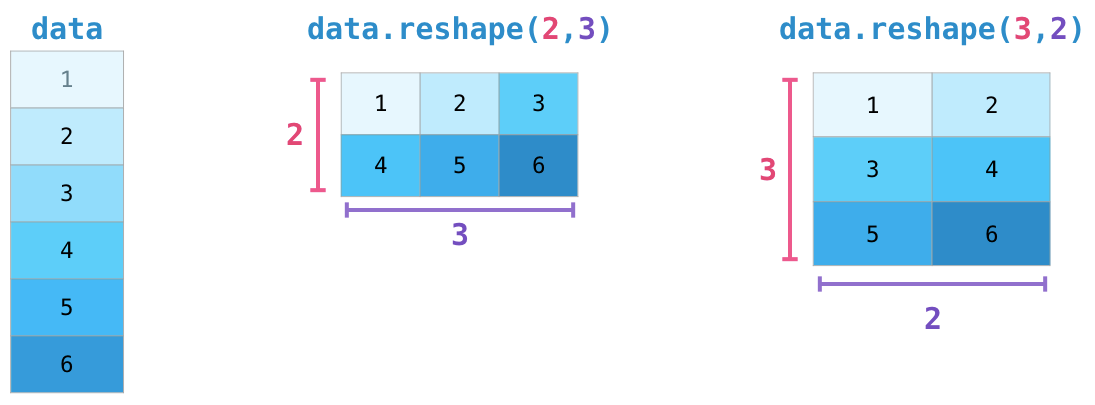
另外一个常见的变形模式是将一个一维数组转变为二维的行或列的矩阵。你也可以通过 reshape 方法来实现,或者更简单地在一个切片操作中利用 newaxis 关键字:
In[39]: x = np.array([1, 2, 3])# 通过变形获得的行向量x.reshape((1, 3))Out[39]: array([[1, 2, 3]])In[40]: # 通过newaxis获得的行向量x[np.newaxis, :]Out[40]: array([[1, 2, 3]])In[41]: # 通过变形获得的列向量x.reshape((3, 1))Out[41]: array([[1],[2],[3]])In[42]: # 通过newaxis获得的列向量x[:, np.newaxis]Out[42]: array([[1],[2],[3]])

2.2.4 数组拼接和分裂
以上所有的操作都是针对单一数组的,但有时也需要将多个数组合并为一个,或将一个数组分裂成多个。接下来将详细介绍这些操作。
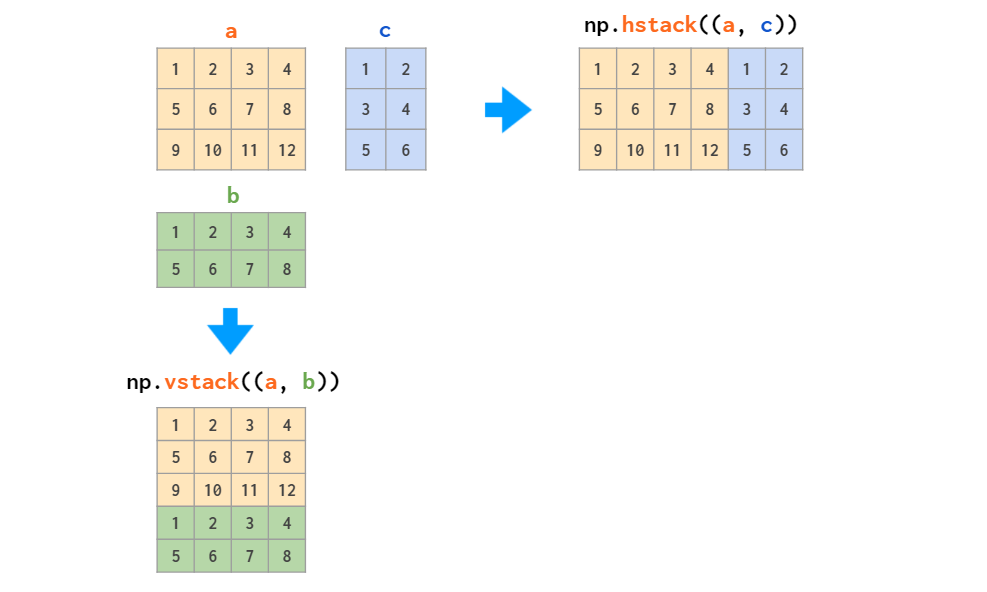
- 数组的拼接
拼接或连接 NumPy 中的两个数组主要由np.concatenate、np.vstack和np.hstack例程实现。np.concatenate将数组元组或数组列表作为第一个参数,如下所示: ``` In[43]: x = np.array([1, 2, 3])y = np.array([3, 2, 1])np.concatenate([x, y])
Out[43]: array([1, 2, 3, 3, 2, 1])
你也可以一次性拼接两个以上数组:
In[44]: z = [99, 99, 99] print(np.concatenate([x, y, z]))
[ 1 2 3 3 2 1 99 99 99]
`np.concatenate` 也可以用于二维数组的拼接:
In[45]: grid = np.array([[1, 2, 3], [4, 5, 6]])
In[46]: # 沿着第一个轴拼接 np.concatenate([grid, grid])
Out[46]: array([[1, 2, 3], [4, 5, 6], [1, 2, 3], [4, 5, 6]])
In[47]: # 沿着第二个轴拼接(从0开始索引) np.concatenate([grid, grid], axis=1)
Out[47]: array([[1, 2, 3, 1, 2, 3], [4, 5, 6, 4, 5, 6]])
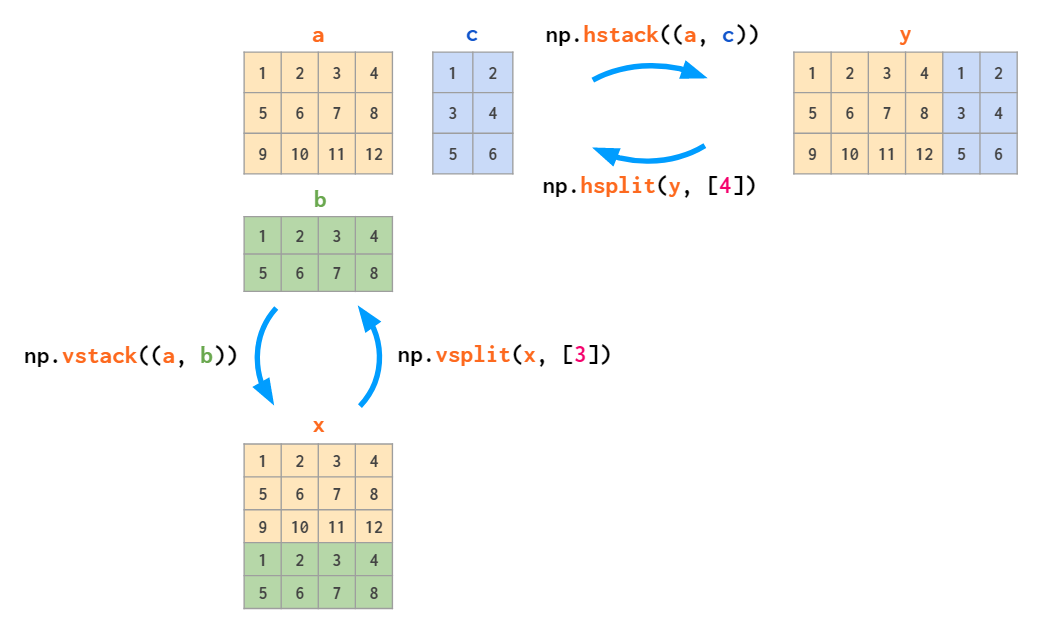
沿着固定维度处理数组时,使用 `np.vstack`(垂直栈)和 `np.hstack`(水平栈)函数会更简洁: <br />与之类似,`np.dstack` 将沿着第三个维度拼接数组。
In[48]: x = np.array([1, 2, 3]) grid = np.array([[9, 8, 7], [6, 5, 4]])
# 垂直栈数组np.vstack([x, grid])
Out[48]: array([[1, 2, 3], [9, 8, 7], [6, 5, 4]])
In[49]: # 水平栈数组 y = np.array([[99], [99]]) np.hstack([grid, y])
Out[49]: array([[ 9, 8, 7, 99], [ 6, 5, 4, 99]])
2. **数组的分裂**<br />与拼接相反的过程是分裂。分裂可以通过 `np.split`、`np.hsplit` 和 `np.vsplit` 函数来实现。可以向以上函数传递一个索引列表作为参数,索引列表记录的是分裂点位置:
In[50]: x = [1, 2, 3, 99, 99, 3, 2, 1] x1, x2, x3 = np.split(x, [3, 5]) print(x1, x2, x3)
[1 2 3] [99 99] [3 2 1]
值得注意的是,_N_ 分裂点会得到 _N_ + 1 个子数组。相关的 `np.hsplit` 和 `np.vsplit` 的用法也类似: <br />同样,`np.dsplit` 将数组沿着第三个维度分裂。
In[51]: grid = np.arange(16).reshape((4, 4)) grid
Out[51]: array([[ 0, 1, 2, 3], [ 4, 5, 6, 7], [ 8, 9, 10, 11], [12, 13, 14, 15]])
In[52]: upper, lower = np.vsplit(grid, [2]) print(upper) print(lower)
[[0 1 2 3] [4 5 6 7]] [[ 8 9 10 11] [12 13 14 15]]
In[53]: left, right = np.hsplit(grid, [2]) print(left) print(right)
[[ 0 1] [ 4 5] [ 8 9] [12 13]] [[ 2 3] [ 6 7] [10 11] [14 15]]
<a name="ff4e180c"></a>## 2.3 NumPy数组的计算:通用函数到目前为止,我们讨论了 NumPy 的一些基础知识。在接下来的几小节中,我们将深入了解 NumPy 在 Python 数据科学世界中如此重要的原因。明确点说,NumPy 提供了一个简单灵活的接口来优化数据数组的计算。NumPy 数组的计算有时非常快,有时也非常慢。使 NumPy 变快的关键是利用**向量化**操作,通常在 NumPy 的**通用函数**(ufunc)中实现。本节将介绍 NumPy 通用函数的重要性——它可以提高数组元素的重复计算的效率;然后,将会介绍很多 NumPy 包中常用且有用的数学通用函数。<a name="fc904b50"></a>### 2.3.1 缓慢的循环Python 的默认实现(被称作 CPython)处理起某些操作时非常慢,一部分原因是该语言的动态性和解释性——数据类型灵活的特性决定了序列操作不能像 C 语言和 Fortran 语言一样被编译成有效的机器码。目前,有一些项目试图解决 Python 这一弱点,比较知名的包括:PyPy 项目(http://pypy.org/),一个实时的 Python 编译实现;Cython 项目([http://cython.org](http://cython.org/)),将 Python 代码转换成可编译的 C 代码;Numba 项目(http://numba.pydata.org/),将 Python 代码的片段转换成快速的 LLVM 字节码。以上这些项目都各有其优势和劣势,但是比较保守地说,这些方法中还没有一种能达到或超过标准 CPython 引擎的受欢迎程度。Python 的相对缓慢通常出现在很多小操作需要不断重复的时候,比如对数组的每个元素做循环操作时。假设有一个数组,我们想**计算每个元素的倒数**,一种直接的解决方法是:```pythonIn[1]: import numpy as npnp.random.seed(0)def compute_reciprocals(values):output = np.empty(len(values))for i in range(len(values)):output[i] = 1.0 / values[i]return outputvalues = np.random.randint(1, 10, size=5)compute_reciprocals(values)Out[1]: array([ 0.16666667, 1. , 0.25 , 0.25 , 0.125 ])
这种实现方式可能对于有 C 语言或 Java 背景的人来说非常自然,但是如果测试一个很大量的输入数据运行上述代码的时间,这一操作将非常耗时,并且是超出意料的慢!我们将用 IPython 的 %timeit 魔法函数来测量:
In[2]: big_array = np.random.randint(1, 100, size=1000000)%timeit compute_reciprocals(big_array)1 loop, best of 3: 2.91 s per loop
完成百万次上述操作并存储结果花了几秒钟的时间!在手机都以 Giga-FLOPS(即每秒十亿次浮点运算)为单位计算处理速度时,上面的处理结果所花费的时间确实是不合时宜的慢。事实上,这里的处理瓶颈并不是运算本身,而是 CPython 在每次循环时必须做数据类型的检查和函数的调度。每次进行倒数运算时,Python 首先检查对象的类型,并且动态查找可以使用该数据类型的正确函数。如果我们在编译代码时进行这样的操作,那么就能在代码执行之前知晓类型的声明,结果的计算也会更加有效率。
2.3.2 通用函数介绍
NumPy 为很多类型的操作提供了非常方便的、静态类型的、可编译程序的接口,也被称作向量操作。你可以通过简单地对数组执行操作来实现,这里对数组的操作将会被用于数组中的每一个元素。这种向量方法被用于将循环推送至 NumPy 之下的编译层,这样会取得更快的执行效率。
比较以下两个结果:
In[3]: print(compute_reciprocals(values))print(1.0 / values)[ 0.16666667 1. 0.25 0.25 0.125 ][ 0.16666667 1. 0.25 0.25 0.125 ]
如果计算一个较大数组的运行时间,可以看到它的完成时间比 Python 循环花费的时间更短:
In[4]: %timeit (1.0 / big_array)100 loops, best of 3: 4.6 ms per loop
NumPy 中的向量操作是通过通用函数实现的。通用函数的主要目的是对 NumPy 数组中的值执行更快的重复操作。
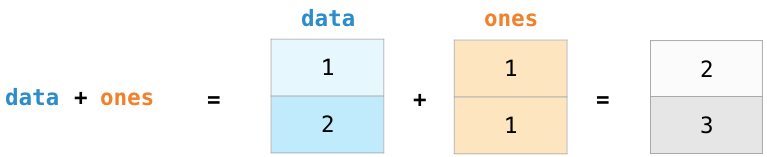
它非常灵活,前面我们看过了标量和数组的运算,但是也可以对两个数组进行运算:
In[5]: np.arange(5) / np.arange(1, 6)Out[5]: array([ 0. , 0.5 , 0.66666667, 0.75 , 0.8 ])

通用函数并不仅限于一维数组的运算,它们也可以进行多维数组的运算:
In[6]: x = np.arange(9).reshape((3, 3))2 ** xOut[6]: array([[ 1, 2, 4],[ 8, 16, 32],[ 64, 128, 256]])
通过通用函数用向量的方式进行计算几乎总比用 Python 循环实现的计算更加有效,尤其是当数组很大时。只要你看到 Python 脚本中有这样的循环,就应该考虑能否用向量方式替换这个循环。
2.3.3 探索NumPy的通用函数
通用函数有两种存在形式:一元通用函数(unary ufunc)对单个输入操作,二元通用函数(binary ufunc)对两个输入操作。我们将在以下的介绍中看到这两种类型的例子。
- 数组的运算
NumPy 通用函数的使用方式非常自然,因为它用到了 Python 原生的算术运算符,标准的加、减、乘、除都可以使用:
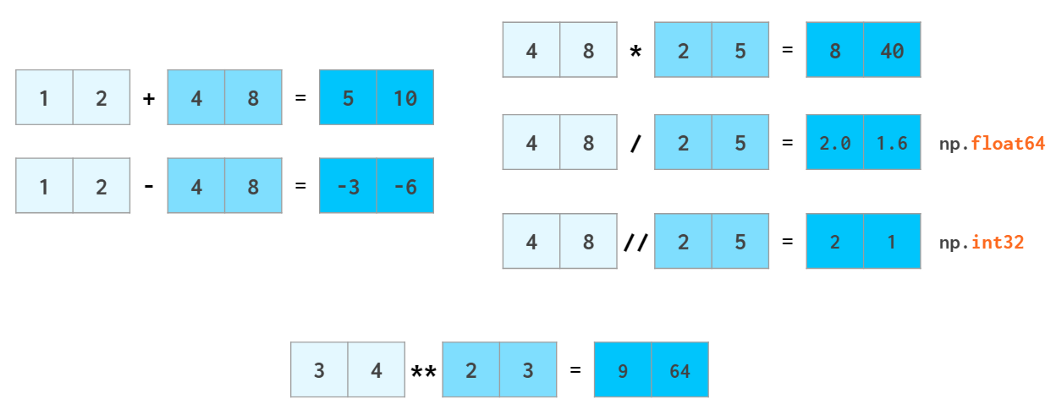
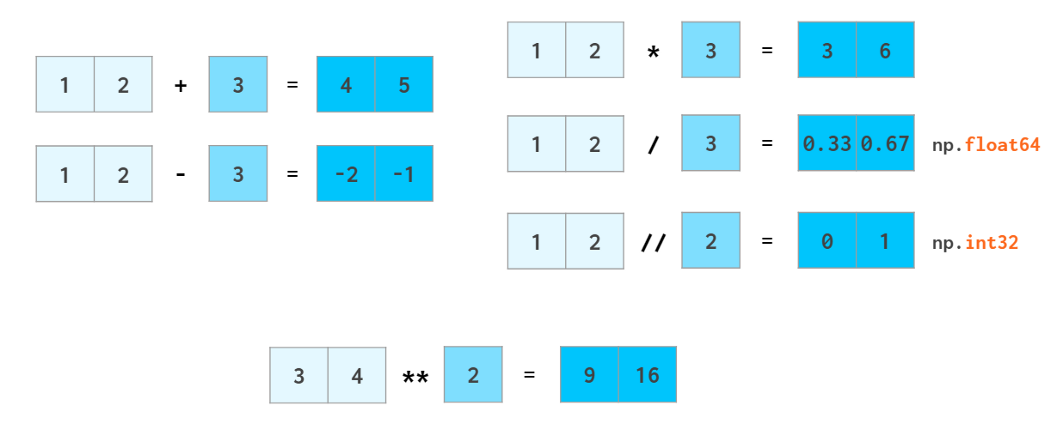
In[7]: x = np.arange(4)print("x =", x)print("x + 5 =", x + 5)print("x - 5 =", x - 5)print("x * 2 =", x * 2)print("x / 2 =", x / 2)print("x // 2 =", x // 2) #向下整除运算x = [0 1 2 3]x + 5 = [5 6 7 8]x - 5 = [-5 -4 -3 -2]x * 2 = [0 2 4 6]x / 2 = [ 0. 0.5 1. 1.5]x // 2 = [0 0 1 1]
还有求负数、** 表示的指数运算符和 % 表示的模运算符的一元通用函数:
In[8]: print("-x = ", -x)print("x ** 2 = ", x ** 2)print("x % 2 = ", x % 2)-x = [ 0 -1 -2 -3]x ** 2 = [0 1 4 9]x % 2 = [0 1 0 1]
你可以任意将这些算术运算符组合使用。当然,你得考虑这些运算符的优先级:
In[9]: -(0.5*x + 1) ** 2Out[9]: array([-1. , -2.25, -4. , -6.25])
所有这些算术运算符都是 NumPy 内置函数的简单封装器,例如 + 运算符就是一个 add 函数的封装器:
In[10]: np.add(x, 2)Out[10]: array([2, 3, 4, 5])
表 2-2 列出了所有 NumPy 实现的算术运算符。
表2-2:NumPy实现的算术运算符
| 运算符 | 对应的通用函数 | 描述 |
|---|---|---|
+ |
np.add |
加法运算(即 1 + 1 = 2) |
- |
np.subtract |
减法运算(即 3 - 2 = 1) |
- |
np.negative |
负数运算( 即 -2) |
* |
np.multiply |
乘法运算(即 2 \\* 3 = 6) |
/ |
np.divide |
除法运算(即 3 / 2 = 1.5) |
// |
np.floor_divide |
向下整除运算(floor division,即 3 // 2 = 1) |
** |
np.power |
指数运算(即 2 ** 3 = 8) |
% |
np.mod |
模 / 余数( 即 9 % 4 = 1) |
另外,NumPy 中还有布尔 / 位运算符,这些运算符将在 2.6 节中进一步介绍。
- 绝对值
正如 NumPy 能理解 Python 内置的运算操作,NumPy 也可以理解 Python 内置的绝对值函数:
``` In[11]: x = np.array([-2, -1, 0, 1, 2])abs(x)
Out[11]: array([2, 1, 0, 1, 2])
对应的 NumPy 通用函数是 `np.absolute`,该函数也可以用别名 `np.abs` 来访问:
In[12]: np.absolute(x)
Out[12]: array([2, 1, 0, 1, 2])
In[13]: np.abs(x)
Out[13]: array([2, 1, 0, 1, 2])
这个通用函数也可以处理复数。当处理复数时,绝对值返回的是该复数的模(magnitude):
In[14]: x = np.array([3 - 4j, 4 - 3j, 2 + 0j, 0 + 1j]) np.abs(x)
Out[14]: array([ 5., 5., 2., 1.])
3. **三角函数**<br />NumPy 提供了大量好用的通用函数,其中对于数据科学家最有用的就是三角函数。首先定义一个角度数组:
In[15]: theta = np.linspace(0, np.pi, 3)
现在可以对这些值进行一些三角函数计算:
In[16]: print(“theta = “, theta) print(“sin(theta) = “, np.sin(theta)) print(“cos(theta) = “, np.cos(theta)) print(“tan(theta) = “, np.tan(theta))
theta = [ 0. 1.57079633 3.14159265] sin(theta) = [ 0.00000000e+00 1.00000000e+00 1.22464680e-16] cos(theta) = [ 1.00000000e+00 6.12323400e-17 -1.00000000e+00] tan(theta) = [ 0.00000000e+00 1.63312394e+16 -1.22464680e-16]
这些值是在机器精度内计算的,所以有些应该是 0 的值并没有精确到 0 。逆三角函数同样可以使用:
In[17]: x = [-1, 0, 1] print(“x = “, x) print(“arcsin(x) = “, np.arcsin(x)) print(“arccos(x) = “, np.arccos(x)) print(“arctan(x) = “, np.arctan(x))
x = [-1, 0, 1] arcsin(x) = [-1.57079633 0. 1.57079633] arccos(x) = [ 3.14159265 1.57079633 0. ] arctan(x) = [-0.78539816 0. 0.78539816]
4. **指数和对数**<br />NumPy 中另一个常用的运算通用函数是指数运算:
In[18]: x = [1, 2, 3] print(“x =”, x) print(“e^x =”, np.exp(x)) print(“2^x =”, np.exp2(x)) print(“3^x =”, np.power(3, x))
x = [1, 2, 3] e^x = [ 2.71828183 7.3890561 20.08553692] 2^x = [ 2. 4. 8.] 3^x = [ 3 9 27]
指数运算的逆运算,即对数运算也是可用的。最基本的 `np.log` 给出的是以自然常数(e)为底数的对数。如果你希望计算以 2 为底数或者以 10 为底数的对数,可以按照如下示例处理:
In[19]: x = [1, 2, 4, 10] print(“x =”, x) print(“ln(x) =”, np.log(x)) print(“log2(x) =”, np.log2(x)) print(“log10(x) =”, np.log10(x))
x = [1, 2, 4, 10] ln(x) = [ 0. 0.69314718 1.38629436 2.30258509] log2(x) = [ 0. 1. 2. 3.32192809] log10(x) = [ 0. 0.30103 0.60205999 1. ]
<a name="4983ac8a"></a>### 2.3.4 高级的通用函数特性很多 NumPy 用户在没有完全了解通用函数的特性时就开始使用它们,这里将介绍一些通用函数的特殊性质。1. **指定输出**<br />在进行大量运算时,有时候指定一个用于存放运算结果的数组是非常有用的。不同于创建临时数组,你可以用这个特性将计算结果直接写入到你期望的存储位置。所有的通用函数都可以通过 `out` 参数来指定计算结果的存放位置:
In[24]: x = np.arange(5) y = np.empty(5) np.multiply(x, 10, out=y) print(y)
[ 0. 10. 20. 30. 40.]
这个特性也可以被用作数组视图,例如可以将计算结果写入指定数组的每隔一个元素的位置:
In[25]: y = np.zeros(10) np.power(2, x, out=y[::2]) print(y)
[ 1. 0. 2. 0. 4. 0. 8. 0. 16. 0.]
如果这里写的是 `y[::2] = 2 ** x`,那么结果将是创建一个临时数组,该数组存放的是 `2 ** x` 的结果,并且接下来会将这些值复制到 `y` 数组中。对于上述例子中比较小的计算量来说,这两种方式的差别并不大。但是对于较大的数组,通过慎重使用 `out` 参数将能够有效节约内存。2. **聚合**<br />二元通用函数有些非常有趣的聚合功能,这些聚合可以直接在对象上计算。例如,如果我们希望用一个特定的运算 **reduce** 一个数组,那么可以用任何通用函数的 `reduce` 方法。一个 `reduce` 方法会对给定的元素和操作重复执行,直至得到单个的结果。<br />例如,对 `add` 通用函数调用 `reduce` 方法会返回数组中所有元素的和:
In[26]: x = np.arange(1, 6) np.add.reduce(x)
Out[26]: 15
同样,对 `multiply` 通用函数调用 `reduce` 方法会返回数组中所有元素的乘积:
In[27]: np.multiply.reduce(x)
Out[27]: 120
如果需要存储每次计算的中间结果,可以使用 `accumulate`:
In[28]: np.add.accumulate(x)
Out[28]: array([ 1, 3, 6, 10, 15])
In[29]: np.multiply.accumulate(x)
Out[29]: array([ 1, 2, 6, 24, 120])
请注意,在一些特殊情况中,NumPy 提供了专用的函数(`np.sum`、`np.prod` ),它们也可以实现以上 `reduce` 的功能,这些函数将在 2.4 节中具体介绍。<a name="d6205d09"></a>## 2.4 聚合:最小值、最大值和其他值当你面对大量的数据时,第一个步骤通常都是计算相关数据的概括统计值。最常用的概括统计值可能是均值和标准差,这两个值能让你分别概括出数据集中的“经典”值,但是其他一些形式的聚合也是非常有用的(如求和、乘积、中位数、最小值和最大值、分位数,等等)。NumPy 有非常快速的内置聚合函数可用于数组,我们将介绍其中的一些。<br /><br /><a name="6f348446"></a>### 2.4.1 数组值求和先来看一个小例子,设想计算一个数组中所有元素的和。Python 本身可用内置的 `sum` 函数来实现:
In[1]: import numpy as np
In[2]: L = np.random.random(100) sum(L)
Out[2]: 55.61209116604941
它的语法和 NumPy 的 `sum` 函数非常相似,并且在这个简单的例子中的结果也是一样的:
In[3]: np.sum(L)
Out[3]: 55.612091166049424
但是,因为 NumPy 的 `sum` 函数在编译码中执行操作,所以 NumPy 的操作计算得更快一些:
In[4]: big_array = np.random.rand(1000000) %timeit sum(big_array) %timeit np.sum(big_array) 10 loops, best of 3: 104 ms per loop 1000 loops, best of 3: 442 μs per loop
但是需要注意,`sum` 函数和 `np.sum` 函数并不等同,这有时会导致混淆。尤其是它们各自的可选参数都有不同的含义,`np.sum` 函数是知道数组的维度的,这一点将在接下来的部分讲解。<a name="c9aa5680"></a>### 2.4.2 最小值和最大值同样,Python 也有内置的 `min` 函数和 `max` 函数,分别被用于获取给定数组的最小值和最大值:
In[5]: min(big_array), max(big_array)
Out[5]: (1.1717128136634614e-06, 0.9999976784968716)
NumPy 对应的函数也有类似的语法,并且也执行得更快:
In[6]: np.min(big_array), np.max(big_array)
Out[6]: (1.1717128136634614e-06, 0.9999976784968716)
In[7]: %timeit min(big_array) %timeit np.min(big_array)
10 loops, best of 3: 82.3 ms per loop 1000 loops, best of 3: 497 μs per loop
对于 `min`、`max`、`sum` 和其他 NumPy 聚合,一种更简洁的语法形式是数组对象直接调用这些方法:
In[8]: print(big_array.min(), big_array.max(), big_array.sum())
1.17171281366e-06 0.999997678497 499911.628197
当你操作 NumPy 数组时,确保你执行的是 NumPy 版本的聚合。1. **多维度聚合**<br />一种常用的聚合操作是沿着一行或一列聚合。例如,假设你有一些数据存储在二维数组中:
In[9]: M = np.random.random((3, 4)) print(M)
[[ 0.8967576 0.03783739 0.75952519 0.06682827] [ 0.8354065 0.99196818 0.19544769 0.43447084] [ 0.66859307 0.15038721 0.37911423 0.6687194]]
默认情况下,每一个 NumPy 聚合函数将会返回对整个数组的聚合结果:
In[10]: M.sum()
Out[10]: 6.0850555667307118
<br />聚合函数还有一个参数,用于指定沿着哪个**轴**的方向进行聚合。例如,可以通过指定 `axis=0` 找到每一列的最小值:
In[11]: M.min(axis=0)
Out[11]: array([ 0.66859307, 0.03783739, 0.19544769, 0.06682827])
这个函数返回四个值,对应四列数字的计算值。同样,也可以找到每一行的最大值:
In[12]: M.max(axis=1)
Out[12]: array([ 0.8967576 , 0.99196818, 0.6687194])
其他语言的用户会对轴的指定方式比较困惑。`axis` 关键字指定的是**数组将会被折叠的维度**,而不是将要返回的维度。因此指定 `axis=0` 意味着第一个轴将要被折叠——对于二维数组,这意味着每一列的值都将被聚合。 <br />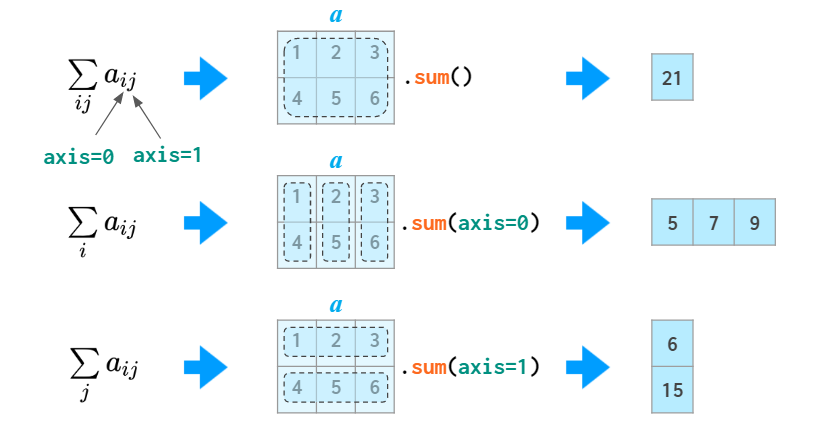<br />2. **其他聚合函数**<br />NumPy 提供了很多其他聚合函数,但是这里不会详细地介绍它们。<br />**表2-3:NumPy中可用的聚合函数**| 函数名称 | NaN安全版本 | 描述 || --- | --- | --- || `np.sum` | `np.nansum` | 计算元素的和 || `np.prod` | `np.nanprod` | 计算元素的积 || `np.mean` | `np.nanmean` | 计算元素的平均值 || `np.std` | `np.nanstd` | 计算元素的标准差 || `np.var` | `np.nanvar` | 计算元素的方差 || `np.min` | `np.nanmin` | 找出最小值 || `np.max` | `np.nanmax` | 找出最大值 || `np.argmin` | `np.nanargmin` | 找出最小值的索引 || `np.argmax` | `np.nanargmax` | 找出最大值的索引 || `np.median` | `np.nanmedian` | 计算元素的中位数 || `np.percentile` | `np.nanpercentile` | 计算基于元素排序的统计值 || `np.any` | `N/A` | 验证是否存在元素为真 || `np.all` | `N/A` | 验证所有元素是否为真 |<a name="dde3493f"></a>## 2.5 数组的计算:广播我们在前一节中介绍了 NumPy 如何通过通用函数的**向量化**操作来减少缓慢的 Python 循环,另外一种向量化操作的方法是利用 NumPy 的广播功能。广播可以简单理解为用于不同大小数组的二元通用函数(加、减、乘等)的一组规则。<a name="f43e8b9b"></a>### 2.5.1 广播的介绍前面曾提到,对于同样大小的数组,二元运算符是对相应元素逐个计算:
In[1]: import numpy as np
In[2]: a = np.array([0, 1, 2]) b = np.array([5, 5, 5]) a + b
Out[2]: array([5, 6, 7])
广播允许这些二元运算符可以用于不同大小的数组。例如,可以简单地将一个标量(可以认为是一个零维的数组)和一个数组相加:
In[3]: a + 5
Out[3]: array([5, 6, 7])
我们可以认为这个操作是将数值 5 扩展或重复至数组 `[5, 5, 5]`,然后执行加法。NumPy 广播功能的好处是,这种对值的重复实际上并没有发生,但是这是一种很好用的理解广播的模型。我们同样也可以将这个原理扩展到更高维度的数组。观察以下将一个一维数组和一个二维数组相加的结果:
In[4]: M = np.ones((3, 3)) M
Out[4]: array([[ 1., 1., 1.], [ 1., 1., 1.], [ 1., 1., 1.]])
In[5]: M + a
Out[5]: array([[ 1., 2., 3.], [ 1., 2., 3.], [ 1., 2., 3.]])
这里这个一维数组就被扩展或者广播了。它沿着第二个维度扩展,扩展到匹配 `M` 数组的形状。以上的这些例子理解起来都相对容易,更复杂的情况会涉及对两个数组的同时广播,例如以下示例:
In[6]: a = np.arange(3) b = np.arange(3)[:, np.newaxis]
print(a)print(b)
[0 1 2] [[0] [1] [2]]
In[7]: a + b
Out[7]: array([[0, 1, 2], [1, 2, 3], [2, 3, 4]])
正如此前将一个值扩展或广播以匹配另外一个数组的形状,这里将 `a` 和 `b` 都进行了扩展来匹配一个公共的形状,最终的结果是一个二维数组。以上这些例子的几何可视化如图 2-4 所示。**图 2-4:NumPy 广播的可视化**浅色的盒子表示广播的值。同样需要注意的是,这个额外的内存并没有在实际操作中进行分配,但是这样的想象方式更方便我们从概念上理解。<br /><a name="b3172896"></a>### 2.5.2 广播的规则NumPy 的广播遵循一组严格的规则,设定这组规则是为了决定两个数组间的操作。- 规则 1:如果两个数组的维度数不相同,那么小维度数组的形状将会在最左边补 1。- 规则 2:如果两个数组的形状在任何一个维度上都不匹配,那么数组的形状会沿着维度为 1 的维度扩展以匹配另外一个数组的形状。- 规则 3:如果两个数组的形状在任何一个维度上都不匹配并且没有任何一个维度等于 1,那么会引发异常。为了更清楚地理解这些规则,来看几个具体示例。1. **广播示例1**<br />将一个二维数组与一个一维数组相加:
In[8]: M = np.ones((2, 3)) a = np.arange(3)
来看这两个数组的加法操作。两个数组的形状如下:
M.shape = (2, 3) a.shape = (3,)
可以看到,根据规则 1,数组 `a` 的维度数更小,所以在其左边补 1:
M.shape -> (2, 3) a.shape -> (1, 3)
根据规则 2,第一个维度不匹配,因此扩展这个维度以匹配数组:
M.shape -> (2, 3) a.shape -> (2, 3)
现在两个数组的形状匹配了,可以看到它们的最终形状都为 `(2, 3)`:
In[9]: M + a
Out[9]: array([[ 1., 2., 3.], [ 1., 2., 3.]])
2. **广播示例2**<br />来看两个数组均需要广播的示例:
In[10]: a = np.arange(3).reshape((3, 1)) b = np.arange(3)
同样,首先写出两个数组的形状:
a.shape = (3, 1) b.shape = (3,)
规则 1 告诉我们,需要用 `1` 将 `b` 的形状补全:
a.shape -> (3, 1) b.shape -> (1, 3)
规则 2 告诉我们,需要更新这两个数组的维度来相互匹配:
a.shape -> (3, 3) b.shape -> (3, 3)
因为结果匹配,所以这两个形状是兼容的,可以看到以下结果:
In[11]: a + b
Out[11]: array([[0, 1, 2], [1, 2, 3], [2, 3, 4]])
3. **广播示例3**<br />现在来看一个两个数组不兼容的示例:
In[12]: M = np.ones((3, 2)) a = np.arange(3)
和第一个示例相比,这里有个微小的不同之处:矩阵 `M` 是转置的。那么这将如何影响计算呢?两个数组的形状如下:
M.shape = (3, 2) a.shape = (3,)
同样,规则 1 告诉我们,`a` 数组的形状必须用 1 进行补全:
M.shape -> (3, 2) a.shape -> (1, 3)
根据规则 2,`a` 数组的第一个维度进行扩展以匹配 `M` 的维度:
M.shape -> (3, 2) a.shape -> (3, 3)
现在需要用到规则 3——最终的形状还是不匹配,因此这两个数组是不兼容的。当我们执行运算时会看到以下结果:
In[13]: M + a
ValueError Traceback (most recent call last)
请注意,这里可能发生的混淆在于:你可能想通过在 `a` 数组的右边补 1,而不是左边补 1,让 `a` 和 `M` 的维度变得兼容。但是这不被广播的规则所允许。这种灵活性在有些情景中可能会有用,但是它可能会导致结果模糊。如果你希望实现右边补全,可以通过变形数组来实现(将会用到 `np.newaxis` 关键字,详情请参见 2.2 节):
In[14]: a[:, np.newaxis].shape
Out[14]: (3, 1)
In[15]: M + a[:, np.newaxis]
Out[15]: array([[ 1., 1.], [ 2., 2.], [ 3., 3.]])
<a name="aaf1b7f8"></a>### 2.5.3 广播的实际应用**数组的归一化**<br />在前面的一节中,我们看到通用函数让 NumPy 用户免于写很慢的 Python 循环。广播进一步扩展了这个功能,一个常见的例子就是数组数据的归一化。假设你有一个有 10 个观察值的数组,每个观察值包含 3 个数值。我们将用一个 10×3 的数组存放该数据:
In[17]: X = np.random.random((10, 3))
我们可以计算每个特征的均值,计算方法是利用 `mean` 函数沿着第一个维度聚合:
In[18]: Xmean = X.mean(0) Xmean
Out[18]: array([ 0.53514715, 0.66567217, 0.44385899])
现在通过从 `X` 数组的元素中减去这个均值实现归一化(该操作是一个广播操作):
In[19]: X_centered = X - Xmean
为了进一步核对我们的处理是否正确,可以查看归一化的数组的均值是否接近 0:
In[20]: X_centered.mean(0)
Out[20]: array([ 2.22044605e-17, -7.77156117e-17, -1.66533454e-17])
在机器精度范围内,该均值为 0。<a name="e8d35c0d"></a>## 2.6 比较、掩码和布尔逻辑这一节将会介绍如何用布尔掩码来查看和操作 NumPy 数组中的值。当你想基于某些准则来抽取、修改、计数或对一个数组中的值进行其他操作时,掩码就可以派上用场了。例如你可能希望统计数组中有多少值大于某一个给定值,或者删除所有超出某些门限值的异常点。在 NumPy 中,布尔掩码通常是完成这类任务的最高效方式。<a name="9061f5d2"></a>### 2.6.1 和通用函数类似的比较操作2.3 节介绍了通用函数,并且特别关注了算术运算符。我们看到用 `+`、`-`、`*`、`/` 和其他一些运算符实现了数组的逐元素操作。NumPy 还实现了如 `<`(小于)和 `>`(大于)的逐元素比较的通用函数。这些比较运算的结果是一个布尔数据类型的数组。一共有 6 种标准的比较操作:
In[4]: x = np.array([1, 2, 3, 4, 5])
In[5]: x < 3 # 小于
Out[5]: array([ True, True, False, False, False], dtype=bool)
In[6]: x > 3 # 大于
Out[6]: array([False, False, False, True, True], dtype=bool)
In[7]: x <= 3 # 小于等于
Out[7]: array([ True, True, True, False, False], dtype=bool)
In[8]: x >= 3 # 大于等于
Out[8]: array([False, False, True, True, True], dtype=bool)
In[9]: x != 3 # 不等于
Out[9]: array([ True, True, False, True, True], dtype=bool)
In[10]: x == 3 # 等于
Out[10]: array([False, False, True, False, False], dtype=bool)
另外,利用复合表达式实现对两个数组的逐元素比较也是可行的:
In[11]: (2 x) == (x * 2)
Out[11]: array([False, True, False, False, False], dtype=bool)
和算术运算符一样,比较运算操作在 NumPy 中也是借助通用函数来实现的。例如当你写 `x < 3` 时,NumPy 内部会使用 `np.less(x, 3)`。这些比较运算符和其对应的通用函数如下表所示。| 运算符 | 对应的通用函数 || --- | --- || `==` | `np.equal` || `!=` | `np.not_equal` || `<` | `np.less` || `<=` | `np.less_equal` || `>` | `np.greater` || `>=` | `np.greater_equal` |和算术运算通用函数一样,这些比较运算通用函数也可以用于任意形状、大小的数组。下面是一个二维数组的示例:
In[12]: rng = np.random.RandomState(0) x = rng.randint(10, size=(3, 4)) x
Out[12]: array([[5, 0, 3, 3], [7, 9, 3, 5], [2, 4, 7, 6]])
In[13]: x < 6
Out[13]: array([[ True, True, True, True], [False, False, True, True], [ True, True, False, False]], dtype=bool)
这样每次计算的结果都是布尔数组了。NumPy 提供了一些简明的模式来操作这些布尔结果。<a name="1e4dab54"></a>### 2.6.2 操作布尔数组给定一个布尔数组,你可以实现很多有用的操作。首先打印出此前生成的二维数组 `x`:
In[14]: print(x)
[[5 0 3 3] [7 9 3 5] [2 4 7 6]]
1. **统计记录的个数**<br />如果需要统计布尔数组中 `True` 记录的个数,可以使用 `np.count_nonzero` 函数: <br />我们看到有 8 个数组记录是小于 6 的。另外一种实现方式是利用 `np.sum`。在这个例子中,`False` 会被解释成 `0`,`True` 会被解释成 `1`: <br />`sum()` 的好处是,和其他 NumPy 聚合函数一样,这个求和也可以沿着行或列进行: <br />这是矩阵中每一行小于 6 的个数。<br />如要快速检查任意或者所有这些值是否为 `True`,可以用(你一定猜到了)`np.any()` 或 `np.all()`: <br />`np.all()` 和`n p.any()` 也可以用于沿着特定的坐标轴,例如: <br />这里第 1 行和第 3 行的所有元素都小于 8,而第 2 行不是所有元素都小于 8。<br />最后需要提醒的是,正如在 2.4 节中提到的,Python 有内置的 `sum()`、`any()` 和 `all()` 函数,这些函数在 NumPy 中有不同的语法版本。如果在多维数组上混用这两个版本,会导致失败或产生不可预知的错误结果。因此,确保在以上的示例中用的都是 `np.sum()`、`np.any()` 和 `np.all()` 函数。
In[15]: # 有多少值小于6? np.count_nonzero(x < 6)
Out[15]: 8
```In[16]: np.sum(x < 6)Out[16]: 8
In[17]: # 每行有多少值小于6?np.sum(x < 6, axis=1)Out[17]: array([4, 2, 2])
In[18]: # 有没有值大于8?np.any(x > 8)Out[18]: TrueIn[19]: # 有没有值小于0?np.any(x < 0)Out[19]: FalseIn[20]: # 是否所有值都小于10?np.all(x < 10)Out[20]: TrueIn[21]: # 是否所有值都等于6?np.all(x == 6)Out[21]: False
In[22]: # 是否每行的所有值都小于8?np.all(x < 8, axis=1)Out[22]: array([ True, False, True], dtype=bool)
- 布尔运算符
我们已经看到该如何统计所有降水量小于 4 英寸或者大于 2 英寸的天数,但是如果我们想统计降水量小于 4 英寸且大于 2 英寸的天数该如何操作呢?这可以通过 Python 的逐位逻辑运算符(bitwise logic operator)&、|、^和~来实现。同标准的算术运算符一样,NumPy 用通用函数重载了这些逻辑运算符,这样可以实现数组的逐位运算(通常是布尔运算)。
例如,可以写如下的复合表达式:
可以看到,降水量在 0.5 英寸~1 英寸间的天数是 29 天。
请注意,这些括号是非常重要的,因为有运算优先级规则。如果去掉这些括号,该表达式会变成以下形式,这会导致运行错误:
利用 A AND B 和 NOT (NOT A OR B) 的等价原理(你应该在基础逻辑课程中学习过),可以用另外一种形式实现同样的结果:
将比较运算符和布尔运算符合并起来用在数组上,可以实现更多有效的逻辑运算操作。
以下表格总结了逐位的布尔运算符和其对应的通用函数。
利用这些工具,就可以回答那些关于天气数据的问题了。以下的示例是结合使用掩码和聚合实现的结果计算:
``` In[23]: np.sum((inches > 0.5) & (inches < 1))
Out[23]: 29
```inches > (0.5 & inches) < 1
In[24]: np.sum(~( (inches <= 0.5) | (inches >= 1) ))Out[24]: 29
| 运算符 | 对应通用函数 |
|---|---|
& |
np.bitwise_and |
| |
np.bitwise_or |
^ |
np.bitwise_xor |
~ |
np.bitwise_not |
In[25]: print("Number days without rain: ", np.sum(inches == 0))print("Number days with rain: ", np.sum(inches != 0))print("Days with more than 0.5 inches:", np.sum(inches > 0.5))print("Rainy days with < 0.2 inches :", np.sum((inches > 0) &(inches < 0.2)))Number days without rain: 215Number days with rain: 150Days with more than 0.5 inches: 37Rainy days with < 0.1 inches : 75
2.6.3 将布尔数组作为掩码
在前面的小节中,我们看到了如何直接对布尔数组进行聚合计算。一种更强大的模式是使用布尔数组作为掩码,通过该掩码选择数据的子数据集。以前面小节用过的 x 数组为例,假设我们希望抽取出数组中所有小于 5 的元素:
In[26]: xOut[26]: array([[5, 0, 3, 3],[7, 9, 3, 5],[2, 4, 7, 6]])
如前面介绍过的方法,利用比较运算符可以得到一个布尔数组:
In[27]: x < 5Out[27]: array([[False, True, True, True],[False, False, True, False],[ True, True, False, False]], dtype=bool)
现在为了将这些值从数组中选出,可以进行简单的索引,即掩码操作:
In[28]: x[x < 5]Out[28]: array([0, 3, 3, 3, 2, 4])
现在返回的是一个一维数组,它包含了所有满足条件的值。换句话说,所有的这些值是掩码数组对应位置为 True 的值。
使用关键字 **and**/**or** 与使用逻辑操作运算符 **&**/**|**
人们经常困惑于关键字 and 和 or,以及逻辑操作运算符 & 和 | 的区别是什么,什么时候该选择哪一种?
它们的区别是:and 和 or 判断整个对象是真或假,而 & 和 | 是指每个对象中的比特位。
当你使用 and 或 or 时,就等于让 Python 将这个对象当作整个布尔实体。在 Python 中,所有非零的整数都会被当作是 True:
In[30]: bool(42), bool(0)Out[30]: (True, False)In[31]: bool(42 and 0)Out[31]: FalseIn[32]: bool(42 or 0)Out[32]: True
当你对整数使用 & 和 | 时,表达式操作的是元素的比特,将 and 或 or 应用于组成该数字的每个比特:
In[33]: bin(42)Out[33]: '0b101010'In[34]: bin(59)Out[34]: '0b111011'In[35]: bin(42 & 59)Out[35]: '0b101010'In[36]: bin(42 | 59)Out[36]: '0b111011'
请注意,& 和 | 运算时,对应的二进制比特位进行比较以得到最终结果。
当你在 NumPy 中有一个布尔数组时,该数组可以被当作是由比特字符组成的,其中 1 = True、0 = False。这样的数组可以用上面介绍的方式进行 & 和 | 的操作:
In[37]: A = np.array([1, 0, 1, 0, 1, 0], dtype=bool)B = np.array([1, 1, 1, 0, 1, 1], dtype=bool)A | BOut[37]: array([ True, True, True, False, True, True], dtype=bool)
而用 or 来计算这两个数组时,Python 会计算整个数组对象的真或假,这会导致程序出错:
In[38]: A or B---------------------------------------------------------------------------ValueError Traceback (most recent call last)<ipython-input-38-5d8e4f2e21c0> in <module>()----> 1 A or BValueError: The truth value of an array with more than one element is...
同样,对给定数组进行逻辑运算时,你也应该使用 | 或 &,而不是 or 或 and:
In[39]: x = np.arange(10)(x > 4) & (x < 8)Out[39]: array([False, False, ..., True, True, False, False], dtype=bool)
如果试图计算整个数组的真或假,程序也同样会给出 ValueError 的错误:
In[40]: (x > 4) and (x < 8)---------------------------------------------------------------------------ValueError Traceback (most recent call last)<ipython-input-40-3d24f1ffd63d> in <module>()----> 1 (x > 4) and (x < 8)ValueError: The truth value of an array with more than one element is...
因此可以记住:and 和 or 对整个对象执行单个布尔运算,而 & 和 | 对一个对象的内容(单个比特或字节)执行多个布尔运算。对于 NumPy 布尔数组,后者是常用的操作。
2.7 花哨的索引
在前面的小节中,我们看到了如何利用简单的索引值(如 arr[0])、切片(如 arr[:5])和布尔掩码(如 arr[arr > 0])获得并修改部分数组。在这一节中,我们将介绍另外一种数组索引,也称作花哨的索引(fancy indexing)。花哨的索引和前面那些简单的索引非常类似,但是传递的是索引数组,而不是单个标量。花哨的索引让我们能够快速获得并修改复杂的数组值的子数据集。
2.7.1 探索花哨的索引
花哨的索引在概念上非常简单,它意味着传递一个索引数组来一次性获得多个数组元素。例如以下数组:
In[1]: import numpy as nprand = np.random.RandomState(42)x = rand.randint(100, size=10)print(x)[51 92 14 71 60 20 82 86 74 74]
假设我们希望获得三个不同的元素,可以用以下方式实现:
In[2]: [x[3], x[7], x[2]]Out[2]: [71, 86, 14]
另外一种方法是通过传递索引的单个列表或数组来获得同样的结果:
In[3]: ind = [3, 7, 4]x[ind]Out[3]: array([71, 86, 60])
利用花哨的索引,结果的形状与索引数组的形状一致,而不是与被索引数组的形状一致:
In[4]: ind = np.array([[3, 7],[4, 5]])x[ind]Out[4]: array([[71, 86],[60, 20]])
花哨的索引也对多个维度适用。假设我们有以下数组:
In[5]: X = np.arange(12).reshape((3, 4))XOut[5]: array([[ 0, 1, 2, 3],[ 4, 5, 6, 7],[ 8, 9, 10, 11]])
和标准的索引方式一样,第一个索引指的是行,第二个索引指的是列:
In[6]: row = np.array([0, 1, 2])col = np.array([2, 1, 3])X[row, col]Out[6]: array([ 2, 5, 11])
这里需要注意,结果的第一个值是 X[0, 2],第二个值是 X[1, 1],第三个值是 X[2, 3]。在花哨的索引中,索引值的配对遵循 2.5 节介绍过的广播的规则。因此当我们将一个列向量和一个行向量组合在一个索引中时,会得到一个二维的结果:
In[7]: X[row[:, np.newaxis], col]Out[7]: array([[ 2, 1, 3],[ 6, 5, 7],[10, 9, 11]])
这里,每一行的值都与每一列的向量配对,正如我们看到的广播的算术运算:
In[8]: row[:, np.newaxis] * colOut[8]: array([[0, 0, 0],[2, 1, 3],[4, 2, 6]])
这里特别需要记住的是,花哨的索引返回的值反映的是广播后的索引数组的形状,而不是被索引的数组的形状。
2.7.2 组合索引
花哨的索引可以和其他索引方案结合起来形成更强大的索引操作:
In[9]: print(X)[[ 0 1 2 3][ 4 5 6 7][ 8 9 10 11]]
可以将花哨的索引和简单的索引组合使用:
In[10]: X[2, [2, 0, 1]]Out[10]: array([10, 8, 9])
也可以将花哨的索引和切片组合使用:
In[11]: X[1:, [2, 0, 1]]Out[11]: array([[ 6, 4, 5],[10, 8, 9]])
更可以将花哨的索引和掩码组合使用:
In[12]: mask = np.array([1, 0, 1, 0], dtype=bool)X[row[:, np.newaxis], mask]Out[12]: array([[ 0, 2],[ 4, 6],[ 8, 10]])
索引选项的组合可以实现非常灵活的获取和修改数组元素的操作。
2.7.3 用花哨的索引修改值
正如花哨的索引可以被用于获取部分数组,它也可以被用于修改部分数组。例如,假设我们有一个索引数组,并且希望设置数组中对应的值:
In[18]: x = np.arange(10)i = np.array([2, 1, 8, 4])x[i] = 99print(x)[ 0 99 99 3 99 5 6 7 99 9]
可以用任何的赋值操作来实现,例如:
In[19]: x[i] -= 10print(x)[ 0 89 89 3 89 5 6 7 89 9]
不过需要注意,操作中重复的索引会导致一些出乎意料的结果产生,如以下例子所示:
In[20]: x = np.zeros(10)x[[0, 0]] = [4, 6]print(x)[ 6. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
4 去哪里了呢?这个操作首先赋值 x[0] = 4,然后赋值 x[0] = 6,因此当然 x[0] 的值为 6。
以上还算合理,但是设想以下操作:
In[21]: i = [2, 3, 3, 4, 4, 4]x[i] += 1xOut[21]: array([ 6., 0., 1., 1., 1., 0., 0., 0., 0., 0.])
你可能期望 x[3] 的值为 2,x[4] 的值为 3,因为这是这些索引值重复的次数。但是为什么结果不同于我们的预想呢?从概念的角度理解,这是因为 x[i] += 1 是 x[i] = x[i] + 1 的简写。x[i] + 1 计算后,这个结果被赋值给了 x 相应的索引值。记住这个原理后,我们却发现数组并没有发生多次累加,而是发生了赋值,显然这不是我们希望的结果。
因此,如果你希望累加,该怎么做呢?你可以借助通用函数中的 at() 方法(在 NumPy 1.8 以后的版本中可以使用)来实现。进行如下操作:
In[22]: x = np.zeros(10)np.add.at(x, i, 1)print(x)[ 0. 0. 1. 2. 3. 0. 0. 0. 0. 0.]
at() 函数在这里对给定的操作、给定的索引(这里是 i)以及给定的值(这里是 1)执行的是就地操作。另一个可以实现该功能的类似方法是通用函数中的 reduceat() 函数,你可以在 NumPy 文档中找到关于该函数的更多信息。
2.8 数组的排序
尽管 Python 有内置的 sort 和 sorted 函数可以对列表进行排序,但是这里不会介绍这两个函数,因为 NumPy 的 np.sort 函数实际上效率更高。
如果想在不修改原始输入数组的基础上返回一个排好序的数组,可以使用 np.sort:
In[5]: x = np.array([2, 1, 4, 3, 5])np.sort(x)Out[5]: array([1, 2, 3, 4, 5])
如果希望用排好序的数组替代原始数组,可以使用数组的 sort 方法:
In[6]: x.sort()print(x)[1 2 3 4 5]
另外一个相关的函数是 argsort,该函数返回的是原始数组排好序的索引值:
In[7]: x = np.array([2, 1, 4, 3, 5])i = np.argsort(x)print(i)[1 0 3 2 4]
以上结果的第一个元素是数组中最小元素的索引值,第二个值给出的是次小元素的索引值,以此类推。这些索引值可以被用于(通过花哨的索引)创建有序的数组:
In[8]: x[i]Out[8]: array([1, 2, 3, 4, 5])
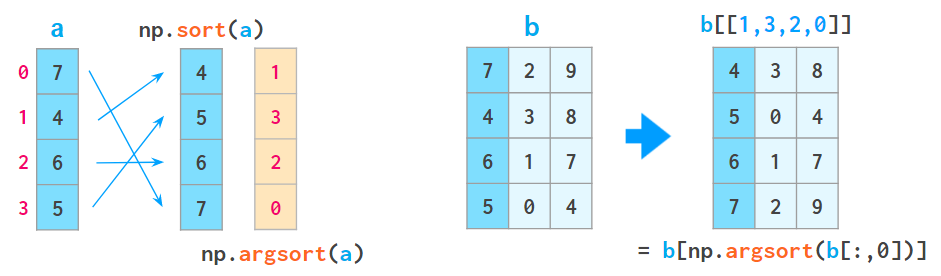
沿着行或列排序
NumPy 排序算法的一个有用的功能是通过 axis 参数,沿着多维数组的行或列进行排序,例如:
In[9]: rand = np.random.RandomState(42)X = rand.randint(0, 10, (4, 6))print(X)[[6 3 7 4 6 9][2 6 7 4 3 7][7 2 5 4 1 7][5 1 4 0 9 5]]In[10]: # 对X的每一列排序np.sort(X, axis=0)Out[10]: array([[2, 1, 4, 0, 1, 5],[5, 2, 5, 4, 3, 7],[6, 3, 7, 4, 6, 7],[7, 6, 7, 4, 9, 9]])In[11]: # 对X每一行排序np.sort(X, axis=1)Out[11]: array([[3, 4, 6, 6, 7, 9],[2, 3, 4, 6, 7, 7],[1, 2, 4, 5, 7, 7],[0, 1, 4, 5, 5, 9]])
需要记住的是,这种处理方式是将行或列当作独立的数组,任何行或列的值之间的关系将会丢失!

若有收获,就点个赞吧
0 人点赞
