1997年5月3日-1997年5月11日一场别开生面的比赛在纽约的公平大厦举行,吸引了全世界的关注。对垒的双方分别是世界国际象棋冠军卡斯帕罗夫和IBM的超级计算机“深蓝”。经过六场激烈的比赛,“深蓝”最终战胜了卡斯帕罗夫,赢得了具有特殊意义的胜利。而这一次比赛也载入了人类的史册。<br /> 而另一场可以载入人类史册的人机大战发生在2016年3月9日-2016年3月15日。这一次比赛双方是世界顶级围棋棋手李世石和Google的人工智能AlphaGo。赛前有很多人并不看好AlphaGo,认为AlphaGo会惨败。没想到AlphaGo最终以4:1大胜李世石,从而一战成名。由于AlphaGo的胜利,AlphaGo用到的深度学习(Deep Learning)技术以及人工智能(Artificial Intelligence)也成为了当下最热门的技术话题。
1 什么是人工智能
我们可以把人工智能理解为“人为地使设备或软件模仿人类的行为”。在此基础上发展而来的设备能够根据程序独立进行判断。另外,人工智能还包括设备按照自己的意志采取某种行动的情况(图 1-1)。
图 1-1 人工智能
过去,在表现某种智能行动方面,人工智能的实现方法和生物智能完全不同。人工智能实际输出的,也就是最终呈现在我们面前的,是自动控制的结果(图 1-2)。
图 1-2 自动控制的典型示例
人工智能随着时代的变化而发展。例如,在计算机出现的早期,简单的条件分支就是自动控制的主要功能,而现在,即便应用了复杂的理论,有些程序也无法称为人工智能(图 1-3)。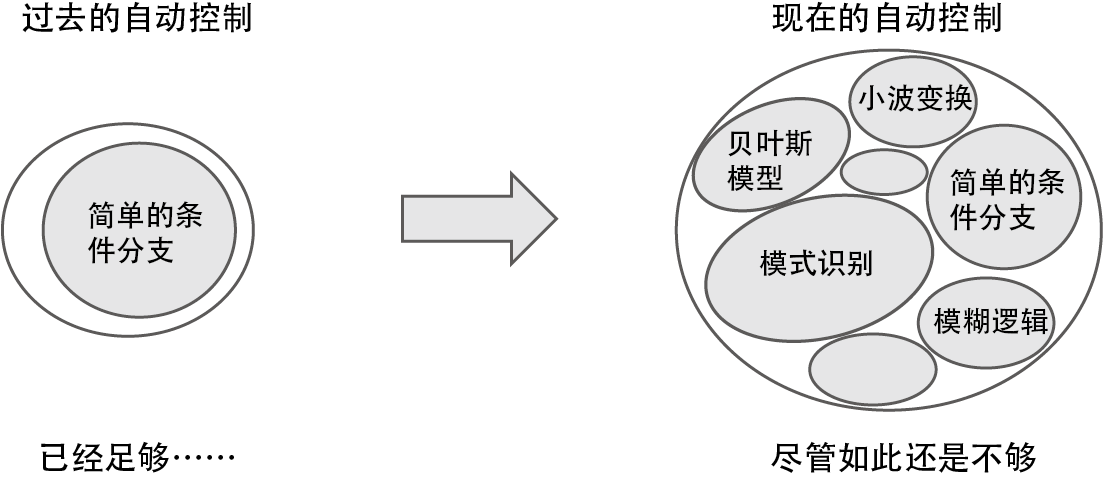
图 1-3 人工智能和自动控制的关系
人工智能只是一个抽象概念,它不是任何具体的机器或算法。任何类似于人的智能或高于人的智能的机器或算法都可以称为人工智能。比如几年前我们去洗车的时候会看到洗车店写着自动化洗车,看起来很高级。今天我们再去看,可能它改成了人工智能洗车,看起来更高级。实际上它的技术并没有改变,只是改了一个名字。随着人工智能技术的大热,很多商品都挂上了人工智能的标签,实际上任何看起来有一点智能的算法和机器都可以称为人工智能,所以人工智能这个标签并不能代表某个商品的技术水平。
2 人工智能的黎明时期
人工智能的诞生
1956 年的达特茅斯会议上首次出现了人工智能一词。再往前追溯 10 年,英国的艾伦·麦席森·图灵(Alan Mathison Turing)对人工智能的发展做出了诸多贡献。他的名字也通过图灵测试(the turing test)和图灵机(turing machine)流传至今。
当时刚出现的电子计算机以“辅助和代替人类”为目的,除了进行科学计算,还会对内容进行判断。
最初的人工智能程序通过二分类的堆叠来输出自动判断结果(图 1-4)。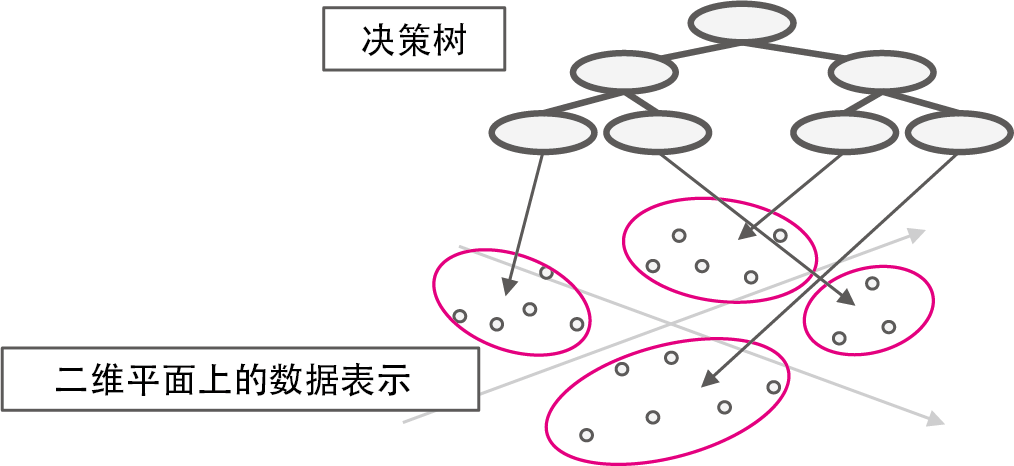
图 1-4 决策树
人工智能和图灵测试
既然机器根据计算结果给出答案的目的是代替人类,那么我们必然会质疑这个答案到底是由人还是由机器给出的。
每个人都会犯错误,而机器按照人类制定的条件判断标准来运行,所以机器也会犯错误。有观点认为“机器的判断是正确的”,但我们必须明确这种观点成立的前提是“对程序的性能进行测试后,结果在合理的范围内”。
例如,飞机的飞行自动控制系统现在基本按照传感器的指示进行操作,由人类进行判断有时反而会发生事故(图 1-5)。
图 1-5 人为错误和自动驾驶
在人工智能研究的初期阶段,机器只能在有限的范围内进行判断和回答,但图灵认为终有一天,机器代替人类给出的回答将无法与人类自身的回答区分开来。简单来说,就是机器具备了思考的能力。这些都反映到了图灵测试中。
图灵测试
图灵测试的过程如下所示。
测试者分别与一个人和一台机器进行对话,经过多次测试之后,如果有30%的测试者不能确定被测试者是人还是机器,那么说明这台机器通过了测试 (图 1-6)。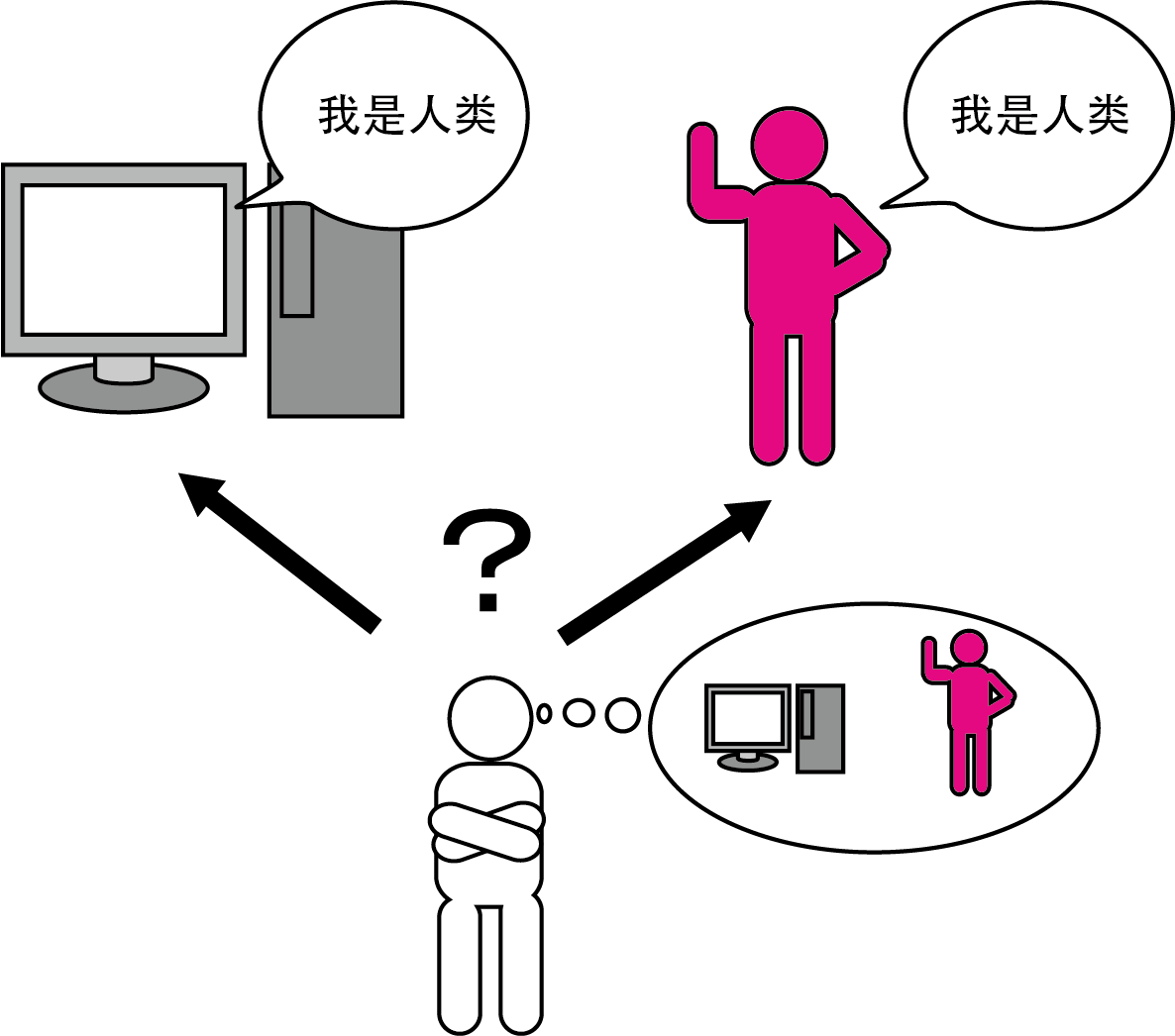
图 1-6 图灵测试
将测试者与被测试者隔离,为了避免机器的声音影响测试结果,测试者只通过键盘和显示器等设备以文字形式向被测试者提问,然后判断对方是人还是机器。
在 2014 年的图灵测试大会上,一台俄罗斯的超级计算机伪装成 13 岁的男孩,回答了测试者输入的所有问题。其中有 33% 的测试者认为与自己对话的是人而非机器,这台计算机也成为有史以来首台通过图灵测试的计算机。在此之前人类已经开发了各种各样的人工智能程序,其中最接近图灵测试合格标准的是 ELIZA(1966 年)和 PARRY(1972 年)。两个程序都模仿了特定的人群。ELIZA 模仿的是心理治疗师,PARRY 模仿的是妄想型精神分裂症患者。
关于上述内容,我们需要注意的是,图灵测试用于测试机器模仿人类行为的能力,它不一定能测试出机器是否具有掌控思维的能力。例如,对于在解决需要具备创新能力的课题时所采取的智能行为,图灵测试就无法奏效了。
3 人工智能的发展
人工智能领域发生了很多里程碑事件。下面,我们来看看人工智能的历史发展过程(图 1-7)。
图 1-7 1960 ~ 2010 年的人工智能历史
1960 ~ 1980 年:专家系统和第一次人工智能热潮
20 世纪 50 年代以来,基于使用了多个条件分支的自动判断程序,搭载了推理机的问题处理系统相继问世。专家系统就是其中之一,程序内部包含专家(expert)提供的知识与经验。
早期开发的专家系统 DENDRAL 能够利用物质的质谱分析结果,来识别有机化合物的分子结构(参照小贴士)。由此掀起了第一次人工智能热潮。
在 20 世纪 70 年代,专家系统被引入制造系统。由此问世的医疗专家系统 MYCIN(参照小贴士)等开始试运行。
1980 ~ 2000 年:第二次人工智能热潮和神经网络的寒冬期
进入 20 世纪 80 年代后,随着计算机硬件成本的不断下降,复杂的大规模集成电路得以实现,计算机的计算能力由此实现指数级增长。这就是摩尔定律(参照小贴士)。
小贴士 摩尔定律 1965年,美国英特尔公司的戈登·摩尔(Gordon Moore)在他的论文中指出,大规模集成电路上可容纳的元器件数量每隔 18~24 个月便会增加一倍。
随着集成电路上可容纳的元器件数量的增加,计算机的存储区域持续呈爆炸式增长,主存储器中可存储的数据类型越来越多样化。人工智能领域的研究也因此受益,并发展到以国家为主导的持续提升计算机计算能力的阶段。人工智能迎来第二次热潮。
在此期间,神经网络也得到了快速发展。20 世纪 60 年代提出的单层感知器因为无法处理非线性分类问题而陷入低谷,由多个感知器堆叠组成的多层感知器则解决了非线性分类问题。
但随后,因计算机性能方面的限制,第二次人工智能热潮遇到了瓶颈。自 20 世纪 90 年代开始,人工智能的研究陷入低谷。这一时期又称为人工智能的寒冬期。
2000 ~ 2010 年:统计机器学习方法和分布式处理技术的发展
以 20 世纪 80 年代发展起来的神经网络为基础的人工智能研究,虽然在后期陷入了低谷,但是基于统计模型的机器学习算法等取得了稳步发展。
20 世纪 90 年代,基于贝叶斯定理的贝叶斯统计学被重新定义。21 世纪以后,开始出现了使用贝叶斯过滤器的机器学习系统,并逐渐普及(图 1-8)。贝叶斯过滤器的典型应用示例就是垃圾邮件过滤系统。除此之外,它还可用于语音输入系统中的降噪和语音识别处理。
图 1-8 贝叶斯定理和贝叶斯过滤器
使用统计学方法解决的课题可以分为两大类:分类和预测。机器学习利用程序自动计算输入数据,以此来推导特征值,实现分类和预测的功能(图 1-9)。在多数情况下,这些特征值还需要数据科学家检测它们的构成要素和贡献率并进行深入分析,不过我们也可以通过构建模型使处理自动化。
图 1-9 机器学习的典型功能:分类和预测
机器学习的应用示例包括推荐引擎,以及使用了日志数据及在线数据的异常检测系统。
20 世纪 90 年代后期,随着互联网的普及,多媒体数据等大容量数据的应用变得越来越广泛(图 1-10)。因此,提高图像数据和音频数据处理效率的需求应运而生。
图 1-10 黑白二色→ 16 色→ 256 色→ 1677 万色的图画和动画
为了灵活处理数据,过去人们使用的,是用于科学计算等领域的大型计算机(超级计算机)所提供的分布式计算环境。但 2000 年以后出现了 OpenMP(共享存储并行编程)和与 GPGPU(General-Purpose computing on Graphics Processing Units,通用图形处理器)相关的技术 CUDA(Compute Unified Device Architecture,统一计算设备架构),它们提供的是多核计算环境和异构计算环境,像计算机一样可以由个人来操作(当时还比较昂贵)。
与按照指令执行的分布式处理机制一样,一些软件中也添加了分布式处理的管理机制。例如 Google 以 Google 文件系统(Google File System)为开端开发的 MapReduce 架构(图 1-11),还有 Yahoo! 在 MapReduce 的基础上开发的 Hadoop。分布式系统不仅可以为每个任务预定义计算资源,还能通过网络线路进行任务管理,所以能够随意地增减资源。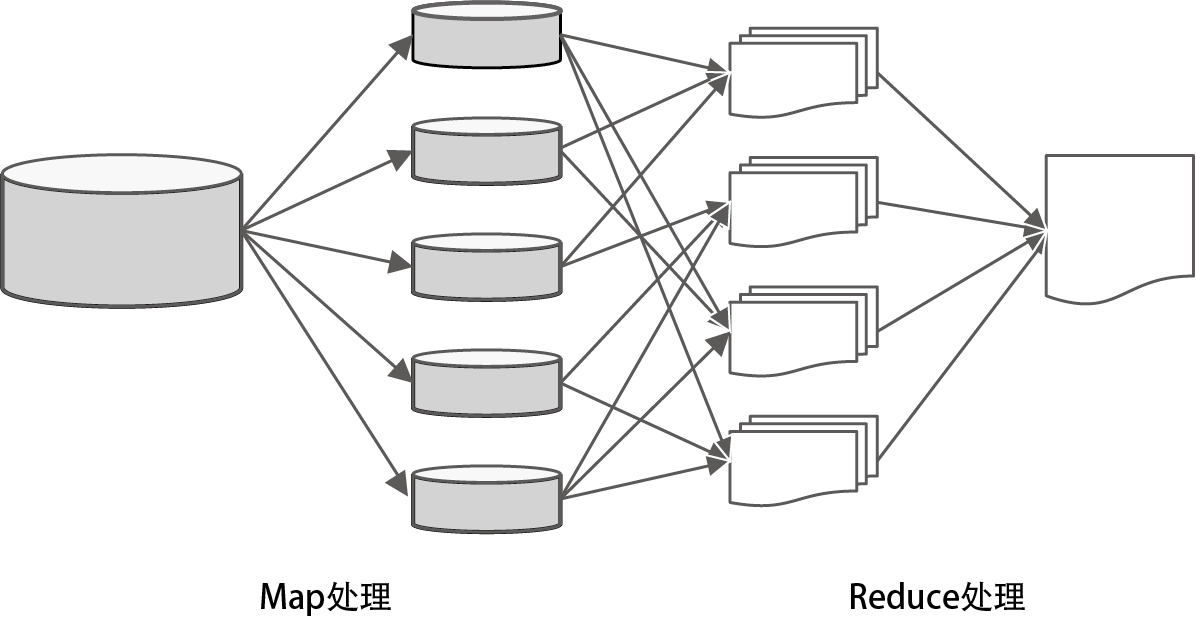
图 1-11 MapReduce 架构
从 2005 年左右开始,高效的分布式处理和摩尔定律所带来的计算机硬件的性能提升推动了神经网络研究的再次兴起。
2006 年,随着自编码器(一种使用神经网络进行数据维度压缩的算法)的出现,人工智能的发展进入了深度学习时代。
深度神经网络(Deep Neural Network,DNN)是一种支持深度学习的多层神经网络。当时,超过 5 层的神经网络就称为深度神经网络,因为受到计算机性能的限制,很难构建更多的层。到了 2010 年以后,就已经能构建出 100 多层的深度神经网络了。
2010年以后:深度神经网络带来图像识别性能的飞跃性提高,第三次人工智能热潮
以前,在图像识别精度方面,基于统计模型的机器学习要优于基于神经网络的机器学习,但在某个阶段之后,这种优势出现了颠覆性的逆转。最典型的示例就是 2012 年 ImageNet 大规模视觉识别挑战赛 ILSVRC 2012(IMAGENET Large Scale Visual Recognition Challenge)的图像分类任务。加拿大多伦多大学团队开发的基于深度学习的图像识别算法摘得桂冠(图 1-12)。
图 1-12 ILSVRC 2012 的图像分类任务结果
和第三名东京大学团队使用的统计机器学习算法相比,多伦多大学团队使用的深度学习算法将错误识别率降低了 10%,在业界引起轰动。人类的错误识别率约为 5%,而在 2015 年出现了错误识别率低于 5% 的算法。
基于深度学习的图像识别算法的有效性迅速得到认可。人们建立大型数据库来存储图像和元数据之间的关联,并提供给用户使用,因此在汽车上装载图像识别引擎的研究也逐渐活跃起来(图 1-13)。除了图像识别领域,深度学习在语音识别领域和自然语言处理领域也取得了一定成效,逐渐被应用到聊天机器人程序中。
图 1-13 图像识别引擎的应用领域
从专家系统到机器学习
人工智能早期阶段,迅速解决了一些对于人类来说比较困难,但是对于计算机来说相对容易的问题,比如下棋,推理,路径规划等等。我们下象棋的时候,通常需要思考很久才能推算出几步棋之后棋盘战局的变化,并且经常还会有看错看漏的情况。而计算机能在一瞬间计算出七八步棋甚至十几步棋之后棋盘的情况,并从中选出对自己最有利的下法来与对手对弈。面对如此强大的对手,人类早在20年前就已经输了。可能有人会想到人工智能在象棋领域早就战胜了人类最顶尖的选手,为什么在围棋领域一直到2016年才出了个AlphaGo把人类顶级棋手击败。比起象棋,围棋的局面发展的可能性要复杂得多。或许我们在设计象棋AI的时候可以使用暴力计算的方法,把几步之内所有可能的走法都遍历一次,然后选一个最优下法。同样的方法放到围棋上就行不通了,围棋每一步的可能性都太多了,用暴力计算法设计出来的围棋AI,它的棋力是很差的。虽然AlphaGo的计算非常快,可以在短时间完成大量运算,但是AlphaGo比其他棋类AI强的地方并不是计算能力,而是它的算法,也可以理解为它拥有更强大的“智慧”。就像是进行小学速算比赛,题目是100以内的加减法,10个小学生为一队,1个数学系的博士为另一队。如果比赛内容是1分钟哪个队做的正确题目多,小学生队肯定是能够战胜数学博士的。如果是进行大学生数学建模比赛,那10000个小学生也赢不了1个数学博士。对于解决复杂的问题,需要的往往不只是计算速度,更多的应该是智慧。
对于一些人类比较擅长的任务,比如图像识别,语音识别,自然语言处理等,计算机却完成得很差。人类的视觉从眼睛采集信息开始,但起到主要作用的是大脑。人类的每个脑半球中都有着非常复杂的视觉皮层,包含着上亿个神经元以及几百亿条神经元之间的连接。人类的大脑就像是一台超级计算机,可以轻松处理非常复杂的图像问题。神经元之间的电信号可以快速传递,但是就像前面说到的,对于复杂的问题,计算速度只是一方面。人类的视觉能力是通过几亿年地不断进化,不断演变最终才得到的,更强的视觉和听觉能力使得人类可以拥有更强的生存能力。
在人工智能的早期阶段,计算机的智能通常是基于人工制定的“规则”,我们可以通过详细的 规则去定义下棋的套路,推理的方法,以及路径规划的方案。但是我们却很难用规则去详细描述图片中的物体,比如我们要判断一张图片中是否存在猫。那我们首先要通过规则去定义一只猫,如图1-14所示。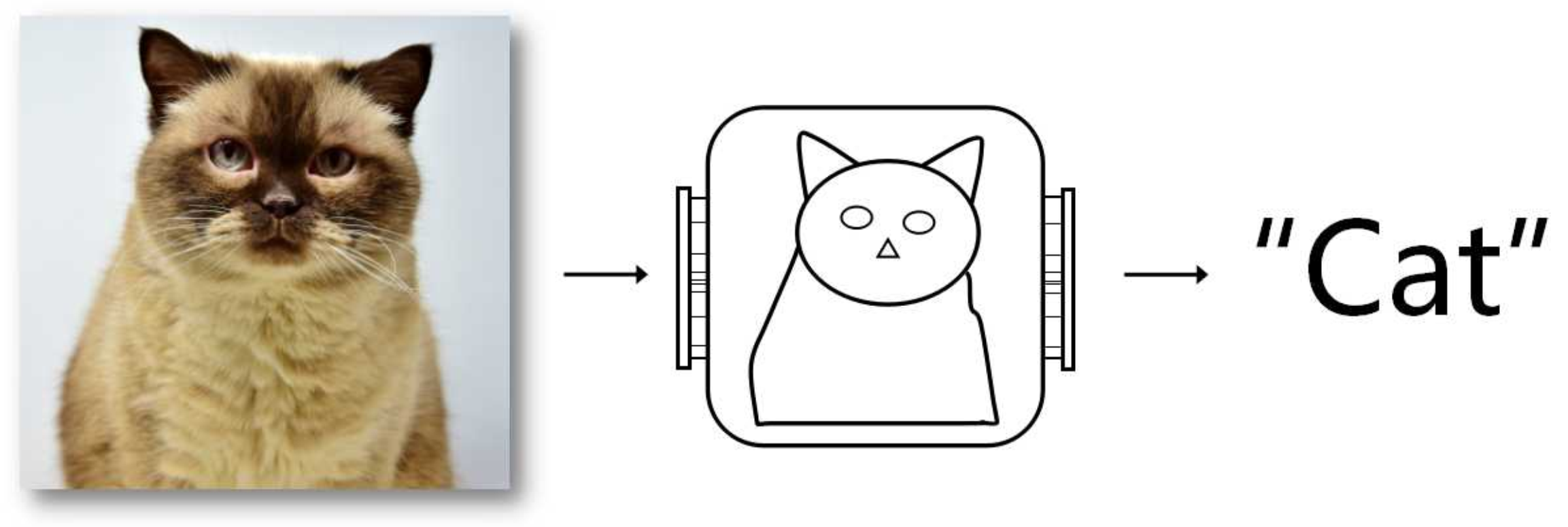
图1-14 猫
观察图1-14中的猫,我们可以知道猫有一个圆脑袋,两个三角形的耳朵,又胖又长的身体,和一条长尾巴,然后可以定义一套规则在图片中寻找猫。这看起来好像是可行的,但是如果我们遇到的是图1-15,图1-16中的猫该怎么办?
图1-15 团起来的猫

图1-16 带着兔耳朵的猫
猫可能只露出身体的一部分,可能会摆出奇怪的造型,那么我们又要针对这些情况定义新的规则。从这个例子中大家应该能看得出来,即使是一只很普通的家养宠物,都可能会出现无数种不同的外形。如果我们使用人工定义的规则去定义这个物体,那么可能需要设置非常大量的规则,并且效果也不一定会很好。仅仅一个物体就这么复杂,而现实中常见的各种物体成千上万,所以在图像识别领域,使用使用人为定义的规则去做识别肯定是行不通的。很多其他的领域也同样存在这种问题。
对于人类的很多智能行为( 比如语言理解、 图像理解等),我们很难知道其中的原理,也无法描述这些智能行为背后的“知识”。因此,我们也很难通过知识和推理的方式来实现这些行为的智能系统。为了解决这类问题,研究者开始将研究重点转向让计算机从数据中自己学习。事实上,“学习”本身也是一种智能行为。从人工智能的萌芽时期开始, 就有一些研究者尝试让机器来自动学习, 即机器学习( Machine Learning, ML)。机器学习的主要目的是设计和分析一些学习算法,让计算机可以从数据( 经验)中自动分析并获得规律,之后利用学习到的规律对未知数据进行预测,从而帮助人们完成一些特定任务,提高开发效率。机器学习的研究内容也十分广泛,涉及线性代数、概率论、统计学、数学优化、计算复杂性等多门学科。在人工智能领域,机器学习从一开始就是一个重要的研究方向。但直到1980年后,机器学习因其在很多领域的出色表现,才逐渐成为热门学科。
机器学习其实与人类学习的过程类似。打个比方:假如我们现在都是原始人,并不知道太阳和月亮是什么东西。但是我们可以观察天上的太阳和月亮,并且把太阳出来时候的光线和温度记录下来,把月亮出来时候的光线和温度记录下来(这就相当于是收集数据)。观察了100天之后,我们进行思考,总结这100天的规律我们可以发现,太阳和月亮是交替出现的(偶尔同时出现可以忽略)。出太阳的时候光线比较亮,温度比较高。月亮出来的时候光线比较暗,温度比较低(这相当于是分析数据,建立模型)。之后我们看到太阳准备落山,月亮准备出来的时候我们就知道温度要降低可能要多穿树叶或毛皮(原始人没有衣服),光线也准备要变暗了(预测未来的情况)。机器学习也可以利用已有的数据进行学习,获得一个训练好的模型,然后可以利用此模型预测未来的情况。
图1-17中表现了机器学习与人类思维的对比。我们可以使用历史数据来训练一个机器学习的模型,模型训练好之后,再放入新的数据,模型就可以对新的数据进行预测分析。人类也善于从以往的经验中总结规律,当遇到新的问题时,我们可以根据之前的经验来预测未来的结果。 
图1-17 机器学习与人类思维的对比
人工智能从诞生至今,经历了一次又一次的繁荣与低谷,其发展历程大体上可以分为“推理期”“知识期”和“学习期”,如图1-18所示。
图1-18 人工智能发展史
4 人工智能、机器学习、神经网络、深度学习之间的关系
新闻媒体在报道AlphaGo的时候,可能人工智能,机器学习,神经网络和深度学习这几个词都有用到过。对于初学者来说,难免容易混淆。
人工智能 —— 我们先说说人工智能,人工智能是这几个词中最早出现的。人工智能其实是一种抽象的概念,并不是指任何实际的算法。人工智能可以对人的意识、思维进行模拟,但又不是人的智能。有时候我们还会把人工智能分为弱人工智能(Weak AI)和强人工智能(Strong AI)。<br /> 弱人工智能是擅长于单个方面技能的人工智能。比如AlphaGo能战胜了众多世界围棋冠军的,在围棋领域所向披靡,但它只会下围棋,做不了其他事情。我们目前的人工智能相关的技术,比如图像识别,语言识别,自然语言处理等等,基本都是处于弱人工智能阶段。<br /> 强人工智能指的是在各方面都能和人类智能差不多的人工智能,人类能干的脑力劳动它都能干。创造强人工智能比创造弱人工智能难度要大很多,我们现阶段还做不到,只有在一些科幻电影中才能看到。著名的教育心理学教授Linda Gottfredson 把智能定义为“一种宽泛的心理能力,能够进行思考、计划、解决问题、抽象思维、理解复杂理念、快速学习和从经验中学习等操作。”强人工智能在进行这些操作时应该跟人类一样得心应手。机器学习 —— 是指从有限的观测数据中学习( 或“猜测”)出具有一般性的规律,并利用这些规律对未知数据进行预测的方法。人工智能是抽象的概念,而机器学习是具体的可以落地的算法。机器学习不是一个算法,而是一大类具体智能算法的统称。神经网络 —— 神经网络是众多机器学习算法中的其中一个,是模仿人类大脑神经结构构建出来的一种算法,构建出来的网络称为人工神经网络(Artificial Neural Networks,ANN)。神经网络算法在机器学习中并不算特别出色,所以一开始的时候并没有引起人们的特别关注。虽然神经网络可以很容易地增加层数、神经元数量, 从而构建复杂的网络,但其计算复杂性也会随之增长。 当时的计算机性能和数据规模不足以支持训练大规模神经网络。 在 20 世纪 90 年代中期,统计学习理论和以支持向量机为代表的机器学习模型开始兴起。相比之下,神经网络的理论基础不清晰、优化困难、可解释性差等缺点更加凸显。直到2006年神经网络重新命名为深度学习,再次兴起。深度学习 —— 深度学习的基础其实就是神经网络,之所以后来换了一种叫法,主要是由于之前的神经网络算法中网络的层数不能太深,也就是不能有太多层网络,网络层数过多会使得网络无法训练。随着神经网络理论的发展,科学家研究出了多种方式使得训练深层的网络也成为可能,深度学习由此诞生。如卷积神经网络(Convolutional Neural Network, CNN),长短时记忆网络(Long Short Term Memory Network, LSTM),深度残差网络(Deep Residual Network)等都属于深度学习,其中深度残差网络的深度可以到达1000层,甚至更多。深层的网络有助于挖掘数据中深层的特征,可以使得网络拥有更强大的性能。
图1-19 人工智能、机器学习、神经网络、深度学习之间的关系

若有收获,就点个赞吧
0 人点赞
