概率基础
数据的集中趋势
我们经常会使用以下几个指标来描述一组数据的集中趋势:
均值 - 均值代表某个数据集的整体水平,我们经常提到的客单价、平均访问时长、平均配送时长等指标都是均值。均值的缺点是容易受极值的影响,虽然可以使用加权平均值来消除极值的影响,但是可能事先并不清楚数据的权重;对于正数可以用几何平均值来替代算术平均值。
- 算术平均值:$$\bar{x}=\frac{\sum{i=1}^{n}x{i}}{n}=\frac{x{1}+x{2}+\cdots +x_{n}}{n}$$,例如计算最近30天日均DAU、日均新增访客等,都可以使用算术平均值。
- 几何平均值:$$\left(\prod{i=1}{\frac{1}{n}}={\sqrt[{n}]{x{1}x{2} \cdots x{n}}}$$,例如计算不同渠道的平均转化率、不同客群的平均留存率、不同品类的平均付费率等,就可以使用几何平均值。
- 中位数 - 将数据按照升序或降序排列后位于中间的数,它描述了数据的中等水平。
- 众数 - 数据集合中出现频次最多的数据,它代表了数据的一般水平。数据的趋势越集中,众数的代表性就越好。众数不受极值的影响,但是无法保证唯一性和存在性。
例子:有A和B两组数据。
A组:5, 6, 6, 6, 6, 8, 10B组:3, 5, 5, 6, 6, 9, 12
A组的均值:6.74,中位数:6,众数:6。
B组的均值:6.57,中位数:6,众数:5, 6。
说明:在Excel中,可以使用AVERAGE、MEDIAN、MODE函数分别计算均值、中位数和众数。求中位数也可以使用QUARTILE.EXC或QUARTILE.INC函数,将第二个参数设置为2即可。
对A组的数据进行一些调整。
A组:5, 6, 6, 6, 6, 8, 10, 200B组:3, 5, 5, 6, 6, 9, 12
A组的均值会大幅度提升,但中位数和众数却没有变化。
思考:怎样判断上面的200到底是不是一个异常值?
| 优点 | 缺点 | |
|---|---|---|
| 均值 | 充分利用了所有数据,适应性强 | 容易收到极端值(异常值)的影响 |
| 中位数 | 能够避免被极端值(异常值)的影响 | 不敏感 |
| 众数 | 能够很好的反映数据的集中趋势 | 有可能不存在(数据没有明显集中趋势) |
练习1:在“概率基础练习.xlsx”文件的表单“练习1”中,有一组用户订单支付金额的数据,计算订单的均值、中位数、众数。
练习2:在“概率基础练习.xlsx”文件的表单“练习2”中,有一组商品销售量的数据,现计划设定一个阈值,对阈值以下的商品对应的分销商进行优化,应该选择什么作为阈值比较合适?
数据的离散趋势
如果说数据的集中趋势,说明了数据最主要的特征是什么;那么数据的离散趋势,则体现了这个特征的稳定性。例如 A 地区冬季平均气温0摄氏度,最低气温-10摄氏度;B 地区冬季平均气温-2摄氏度,最低气温-4摄氏度;如果你是一个特别怕冷的人,在选择 A 和 B 两个区域作为工作和生活的城市时,你会做出怎样的选择?
- 极值:就是最大值(maximum)、最小值(minimum),代表着数据集的上限和下限。
说明:在Excel中,计算极值的函数是MAX和MIN。
极差:又称“全距”,是一组数据中的最大观测值和最小观测值之差,记作
。一般情况下,极差越大,离散程度越大,数据受极值的影响越严重。
四分位距离:$ IQR = Q_3 - Q_1 $。
方差:将每个值与均值的偏差进行平方,然后除以总数据量得到的值。简单来说就是表示数据与期望值的偏离程度。方差越大,就意味着数据越不稳定、波动越剧烈,因此代表着数据整体比较分散,呈现出离散的趋势;而方差越小,意味着数据越稳定、波动越平滑,因此代表着数据整体比较集中。
- 总体方差:$$ \sigma^2 = \frac {\sum_{i=1}^{N}(X_i - \mu)^2} {N} $$。
- 样本方差:$$ S^2 = \frac {\sum_{i=1}^{N}(X_i - \bar{X})^2} {N-1} $$。
说明:在Excel中,计算总体方差和样本方差的函数分别是VAR.P和VAR.S。
标准差:将方差进行平方根运算后的结果,与方差一样都是表示数据与期望值的偏离程度。
- 总体标准差:$$ \sigma = \sqrt{\frac{\sum_{i=1}^{N}(X_i - \mu)^2}{N}} $$。
- 样本标准差:$$ S = \sqrt{\frac{\sum_{i=1}^{N}(X_i - \bar{X})^2}{N-1}} $$。
说明:在Excel中,计算标准差的函数分别是STDEV.P和STDEV.S。
练习3:复制“概率基础练习.xlsx”文件的表单“练习1”,将复制的表单命名为“练习3”,计算订单支付金额的最大值、最小值、极差、方差和标准差。
数据的频数分析
频数分析是指用一定的方式将数据分组,然后统计每个分组中样本的数量,再辅以图表(如直方图)就可以更直观的展示数据分布趋势的一种方法。
频数分析的意义:
- 大问题变小问题,迅速聚焦到需要关注的群体。
- 找到合理的分类机制,有利于长期的数据分析(维度拆解)。
例如:一个班有40个学生,考试成绩如下所示:
73, 87, 88, 65, 73, 76, 80, 95, 83, 69, 55, 67, 70, 94, 86, 81, 87, 95, 84, 92, 92, 76, 69, 97, 72, 90, 72, 85, 80, 83, 97, 95, 62, 92, 67, 73, 91, 95, 86, 77
用上面学过的知识,先解读学生考试成绩的数据。
均值:81.275,中位数:83,众数:95。
最高分:97,最低分:55,极差:42,方差:118.15,标准差:10.87。
但是,仅仅依靠上面的数据是很难对一个数据集做出全面的解读,我们可以把学生按照考试成绩进行分组,如下所示,大家可以自行尝试在Excel或用Python来完成这个操作。
| 分数段 | 学生人数 |
|---|---|
| <60 | 1 |
| [60, 65) | 1 |
| [65, 69) | 5 |
| [70, 75) | 6 |
| [75, 80) | 3 |
| [80, 85) | 6 |
| [85, 90) | 6 |
| [90, 95) | 6 |
| >=95 | 6 |
练习4:在“概率基础练习.xlsx”文件的表单“练习4”中,有某App首页版本迭代上线后的A/B测试数据,数据代表了参与测试的用户7日的活跃天数,请分析A组和B组的数据并判定哪组表现更优。
练习5:在“概率基础练习.xlsx”文件的表单“练习5”中,有某App某个功能迭代上线后的A/B测试数据,数据代表了参与测试的用户30日的产品使用时长,请分析A组和B组的数据并判定哪组表现更优。
数据的概率分布
基本概念
随机试验:在相同条件下对某种随机现象进行观测的试验。随机试验满足三个特点:
- 可以在相同条件下重复的进行。
- 每次试验的结果不止一个,事先可以明确指出全部可能的结果。
- 重复试验的结果以随机的方式出现(事先不确定会出现哪个结果)。
随机变量:如果
指定给概率空间
中每一个事件
有一个实数
#card=math&code=X%28e%29),同时针对每一个实数
都有一个事件集合
与其相对应,其中
%20%5Cle%20r%5C%7D#card=math&code=A_r%3D%5C%7Be%3A%20X%28e%29%20%5Cle%20r%5C%7D),那么
- 离散型随机变量:数据可以一一列出。
- 连续型随机变量:数据不可以一一列出。
概率质量函数/概率密度函数:概率质量函数是描述离散型随机变量为特定取值的概率的函数,通常缩写为PMF。概率密度函数是描述连续型随机变量在某个确定的取值点可能性的函数,通常缩写为PDF。二者的区别在于,概率密度函数本身不是概率,只有对概率密度函数在某区间内进行积分后才是概率。
离散型分布
- 伯努利分布(Bernoulli distribution):又名两点分布或者0-1分布,是一个离散型概率分布。若伯努利试验成功,则随机变量取值为1。若伯努利试验失败,则随机变量取值为0。记其成功概率为
#card=math&code=p%20%280%20%5Cle%20p%20%5Cle%201%29),失败概率为
,则概率质量函数为:
%3Dp%5E%7Bx%7D(1-p)%5E%7B1-x%7D%3D%5Cleft%5C%7B%7B%5Cbegin%7Bmatrix%7Dp%26%7B%5Cmbox%7Bif%20%7D%7Dx%3D1%2C%5C%5Cq%5C%20%26%7B%5Cmbox%7Bif%20%7D%7Dx%3D0.%5C%5C%5Cend%7Bmatrix%7D%7D%5Cright.%7D%20%0A#card=math&code=%7B%5Cdisplaystyle%20f_%7BX%7D%28x%29%3Dp%5E%7Bx%7D%281-p%29%5E%7B1-x%7D%3D%5Cleft%5C%7B%7B%5Cbegin%7Bmatrix%7Dp%26%7B%5Cmbox%7Bif%20%7D%7Dx%3D1%2C%5C%5Cq%5C%20%26%7B%5Cmbox%7Bif%20%7D%7Dx%3D0.%5C%5C%5Cend%7Bmatrix%7D%7D%5Cright.%7D%20%0A)
二项分布(Binomial distribution):
个独立的是/非试验中成功的次数的离散概率分布,其中每次试验的成功概率为
。一般地,如果随机变量
#card=math&code=X%5Csim%20B%28n%2Cp%29)。
次成功的概率由概率质量函数给出,
%3D%5CPr(X%3Dk)%3D%7Bn%20%5Cchoose%20k%7Dp%5E%7Bk%7D(1-p)%5E%7Bn-k%7D#card=math&code=%5Cdisplaystyle%20f%28k%2Cn%2Cp%29%3D%5CPr%28X%3Dk%29%3D%7Bn%20%5Cchoose%20k%7Dp%5E%7Bk%7D%281-p%29%5E%7Bn-k%7D),对于
,其中
!%7D%7D#card=math&code=%7Bn%20%5Cchoose%20k%7D%3D%7B%5Cfrac%20%7Bn%21%7D%7Bk%21%28n-k%29%21%7D%7D)。
泊松分布(Poisson distribution):适合于描述单位时间内随机事件发生的次数的概率分布。如某一服务设施在一定时间内受到的服务请求的次数、汽车站台的候客人数、机器出现的故障数、自然灾害发生的次数、DNA序列的变异数、放射性原子核的衰变数等等。泊松分布的概率质量函数为:
%3D%5Cfrac%7Be%5E%7B-%5Clambda%7D%5Clambda%5Ek%7D%7Bk!%7D#card=math&code=P%28X%3Dk%29%3D%5Cfrac%7Be%5E%7B-%5Clambda%7D%5Clambda%5Ek%7D%7Bk%21%7D),泊松分布的参数
是单位时间(或单位面积)内随机事件的平均发生率。
说明:泊松分布是在没有计算机的年代,由于二项分布的运算量太大运算比较困难,为了减少运算量,数学家为二项分布提供的一种近似。
分布函数和密度函数
对于连续型随机变量,我们不可能去罗列每一个值出现的概率,因此要引入分布函数的概念。
%20%3D%20P%5C%7BX%20%5Cle%20x%5C%7D%0A#card=math&code=F%28x%29%20%3D%20P%5C%7BX%20%5Cle%20x%5C%7D%0A)
如果将$ X x
(-\infty, x) $中的概率。分布函数有以下性质:
- $ F(x) $是一个单调不减的函数;
- $ 0 \le F(x) \le 1
F(-\infty) = \lim{x \to -\infty} F(x) = 0 $,
%20%3D%20%5Clim%7Bx%20%5Cto%20%5Cinfty%7D%20F(x)%20%3D%201#card=math&code=F%28%5Cinfty%29%20%3D%20%5Clim_%7Bx%20%5Cto%20%5Cinfty%7D%20F%28x%29%20%3D%201);
- $ F(x) $是右连续的。
概率密度函数就是给分布函数求导的结果,简单的说就是:
%20%3D%20%5Cint%7B-%20%5Cinfty%7D%5E%7Bx%7D%20f(t)dt%0A#card=math&code=F%28x%29%20%3D%20%5Cint%7B-%20%5Cinfty%7D%5E%7Bx%7D%20f%28t%29dt%0A)
连续型分布
均匀分布(Uniform distribution):如果连续型随机变量
%3D%5Cbegin%7Bcases%7D%7B%5Cfrac%7B1%7D%7Bb-a%7D%7D%20%5Cquad%20%26%7Ba%20%5Cleq%20x%20%5Cleq%20b%7D%20%5C%5C%20%7B0%7D%20%5Cquad%20%26%7B%5Cmbox%7Bother%7D%7D%5Cend%7Bcases%7D#card=math&code=f%28x%29%3D%5Cbegin%7Bcases%7D%7B%5Cfrac%7B1%7D%7Bb-a%7D%7D%20%5Cquad%20%26%7Ba%20%5Cleq%20x%20%5Cleq%20b%7D%20%5C%5C%20%7B0%7D%20%5Cquad%20%26%7B%5Cmbox%7Bother%7D%7D%5Cend%7Bcases%7D),则称
上的均匀分布,记作
。
指数分布(Exponential distribution):如果连续型随机变量
#card=math&code=X%20%5Csim%20Exp%28%5Clambda%29)。指数分布可以用来表示独立随机事件发生的时间间隔,比如旅客进入机场的时间间隔、客服中心接入电话的时间间隔、知乎上出现新问题的时间间隔等等。指数分布的一个重要特征是无记忆性(无后效性),这表示如果一个随机变量呈指数分布,它的条件概率遵循:
%3DP(T%20%5Cgt%20s)%2C%20%5Cforall%20s%2Ct%20%5Cge%200#card=math&code=P%28T%20%5Cgt%20s%2Bt%5C%20%7C%5C%20T%20%5Cgt%20t%29%3DP%28T%20%5Cgt%20s%29%2C%20%5Cforall%20s%2Ct%20%5Cge%200)。
正态分布(Normal distribution):又名高斯分布(Gaussian distribution),是一个非常常见的连续概率分布,经常用自然科学和社会科学中来代表一个不明的随机变量。若随机变量
、尺度参数为
的正态分布,记为
#card=math&code=X%20%5Csim%20N%28%5Cmu%2C%5Csigma%5E2%29),其概率密度函数为:
%3D%7B%5Cfrac%20%7B1%7D%7B%5Csigma%20%7B%5Csqrt%20%7B2%5Cpi%20%7D%7D%7D%7De%5E%7B-%7B%5Cfrac%20%7B%5Cleft(x-%5Cmu%20%5Cright)%5E%7B2%7D%7D%7B2%5Csigma%20%5E%7B2%7D%7D%7D%7D#card=math&code=%5Cdisplaystyle%20f%28x%29%3D%7B%5Cfrac%20%7B1%7D%7B%5Csigma%20%7B%5Csqrt%20%7B2%5Cpi%20%7D%7D%7D%7De%5E%7B-%7B%5Cfrac%20%7B%5Cleft%28x-%5Cmu%20%5Cright%29%5E%7B2%7D%7D%7B2%5Csigma%20%5E%7B2%7D%7D%7D%7D)。
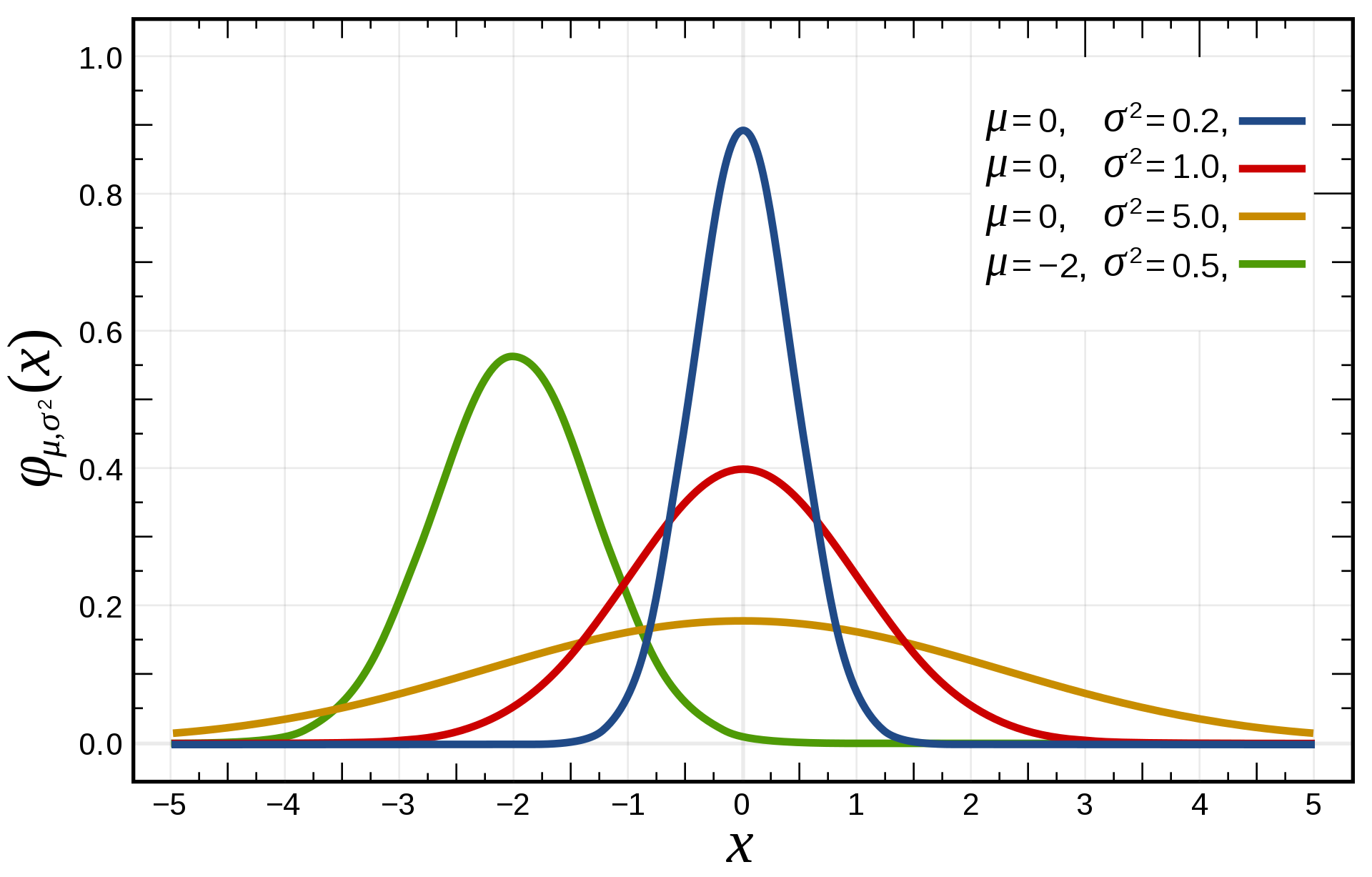
“3
正态分布有一个非常重要的性质,大量统计独立的随机变量的平均值的分布趋于正态分布,这就是中心极限定理。中心极限定理的重要意义在于,我们可以用正态分布作为其他概率分布的近似。
一个例子:假设某校入学新生的智力测验平均分数与标准差分别为 100 与 12。那么随机抽取 50 个学生,他们智力测验平均分数大于 105 的概率是多少?小于 90 的概率是多少?
本例没有正态分布的假设,还好中心极限定理提供一个可行解,那就是当随机样本数量超过30,样本平均数 近似于一个正态变量,标准正态变量$ Z = \frac {\bar{X} - \mu} {\sigma / \sqrt{n}} $。
平均分数大于 105 的概率为:$ P(Z \gt \frac{105 - 100}{12 / \sqrt{50}}) = P(Z \gt 5/1.7) = P(Z \gt 2.94) = 0.0016$。
平均分数小于 90 的概率为:$ P(Z \lt \frac{90-100}{12/\sqrt{50}}) = P(Z < -5.88) = 0.0000 $。说明:上面标准正态分布的概率值可以查表得到。
伽马分布(Gamma distribution):假设
为连续发生事件的等候时间,且这
(
)服从伽玛分布,即
#card=math&code=Y%20%5Csim%20%5CGamma%28%5Calpha%2C%5Cbeta%29),其中
,这里的
卡方分布(Chi-square distribution):若
是相互独立且符合标准正态分布(数学期望为0,方差为1)的随机变量,则随机变量
的平方和
被称为服从自由度为
#card=math&code=X%20%5Csim%20%5Cchi%5E2%28k%29)。
其他内容
条件概率和贝叶斯定理
条件概率是指事件A在事件B发生的条件下发生的概率,通常记为#card=math&code=P%28A%7CB%29)。设A与B为样本空间
中的两个事件,其中
%20%5Cgt%200#card=math&code=P%28B%29%20%5Cgt%200)。那么在事件B发生的条件下,事件A发生的条件概率为:
%3D%5Cfrac%7BP(A%20%5Ccap%20B)%7D%7BP(B)%7D#card=math&code=P%28A%7CB%29%3D%5Cfrac%7BP%28A%20%5Ccap%20B%29%7D%7BP%28B%29%7D),其中
#card=math&code=P%28A%20%5Ccap%20B%29)是联合概率,即A和B两个事件共同发生的概率。
事件A在事件B已发生的条件下发生的概率,与事件B在事件A已发生的条件下发生的概率是不一样的。然而,这两者是有确定的关系的,贝叶斯定理就是对这种关系的陈述,即:%3D%5Cfrac%7BP(A)P(B%7CA)%7D%7BP(B)%7D#card=math&code=P%28A%7CB%29%3D%5Cfrac%7BP%28A%29P%28B%7CA%29%7D%7BP%28B%29%7D),其中:
#card=math&code=P%28A%7CB%29)是已知B发生后,A的条件概率,也称为A的后验概率。
#card=math&code=P%28A%29)是A的先验概率(也称为边缘概率),是不考虑B时A发生的概率。
#card=math&code=P%28B%7CA%29)是已知A发生后,B的条件概率,称为B的似然性。
#card=math&code=P%28B%29)是B的先验概率。
按照上面的描述,贝叶斯定理可以表述为:后验概率 = (似然性 * 先验概率) / 标准化常量,简单的说就是后验概率与先验概率和相似度的乘积成正比。
大数定理
样本数量越多,则其算术平均值就有越高的概率接近期望值。
- 弱大数定律(辛钦定理):样本均值依概率收敛于期望值,即对于任意正数
,有:
%3D0#card=math&code=%5Clim_%7Bn%20%5Cto%20%5Cinfty%7DP%28%7C%5Cbar%7BX_n%7D-%5Cmu%7C%3E%5Cepsilon%29%3D0)。
- 强大数定律:样本均值以概率1收敛于期望值,即:
%3D1#card=math&code=P%28%5Clim_%7Bn%20%5Cto%20%5Cinfty%7D%5Cbar%7BX_n%7D%3D%5Cmu%29%3D1)。
假设检验
假设检验就是通过抽取样本数据,并且通过小概率反证法去验证整体情况的方法。假设检验的核心思想是小概率反证法(首先假设想推翻的命题是成立的,然后试图找出矛盾,找出不合理的地方来证明命题为假命题),即在零假设(null hypothesis)的前提下,估算某事件发生的可能性,如果该事件是小概率事件,在一次研究中本来是不可能发生的,但现在却发生了,这时候就可以推翻零假设,接受备择假设(alternative hypothesis)。如果该事件不是小概率事件,我们就找不到理由来拒绝之前的假设,实际中可引申为接受所做的无效假设。
假设检验会存在两种错误情况,一种称为“拒真”,一种称为“取伪”。如果原假设是对的,但你拒绝了原假设,这种错误就叫作“拒真”,这个错误的概率也叫作显著性水平,或称为容忍度;如果原假设是错的,但你承认了原假设,这种错误就叫作“取伪”,这个错误的概率我们记为
。
总结
描述性统计通常用于研究表象,将现象用数据的方式描述出来(用整体的数据来描述整体的特征);推理性统计通常用于推测本质(通过样本数据特征去推理总体数据特征),也就是你看到的表象的东西有多大概率符合你对隐藏在表象后的本质的猜测。

若有收获,就点个赞吧
0 人点赞
