方差分析和参数估计
方差分析
基本概念
在产品运营中,我们会遇到各种需要评估运营效果的场景,包括促活的活动是否起到作用、A/B 测试的策略有无成效等等。具体例如,产品升级前的平均 DAU 是 155 万,产品升级后的平均 DAU 是 157 万,那么如何判断 DAU 提升的 2 万是正常的波动,还是升级带来的效果呢?对比同一组数据在实施某些策略前后的数据变化,判断数据波动是不是某一因素导致的,这种方法我们称之为方差分析。方差分析通常缩写为 ANOVA(Analysis of Variance),也叫“F 检验”,用于两个及两个以上分组样本的差异性检验。简单的说,分析差异的显著性是否明显的方法就是方差分析。
举一个例子,如果我们需要分析优惠券的金额对用户的购买转化率是否能起到有效作用,我们可以将数据分成以下三个组:
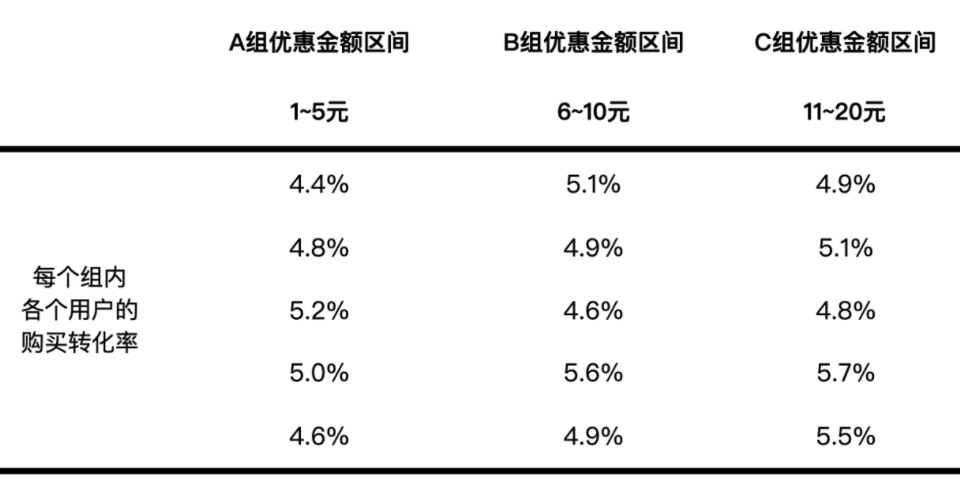
用户购买行为是随机的,购买率很高的不会很多,购买率极低的也不会很多,绝大部分用户的购买率都集中在某个值附近,这个值我们叫作整体购买率的平均值。如果每个客群分组自身的购买率均值与这个整体购买率平均值不一致,就会出现以下两种情况。
第一种情况
蓝色分组的购买率平均值(蓝色线)比整体平均值(黑色线)要高,有可能是最右边那个很高的购买率把分组的均值抬升的,同时蓝色分组的数据分布很散(方差大),此时不能有十足把握说明该组用户的购买转化率很高。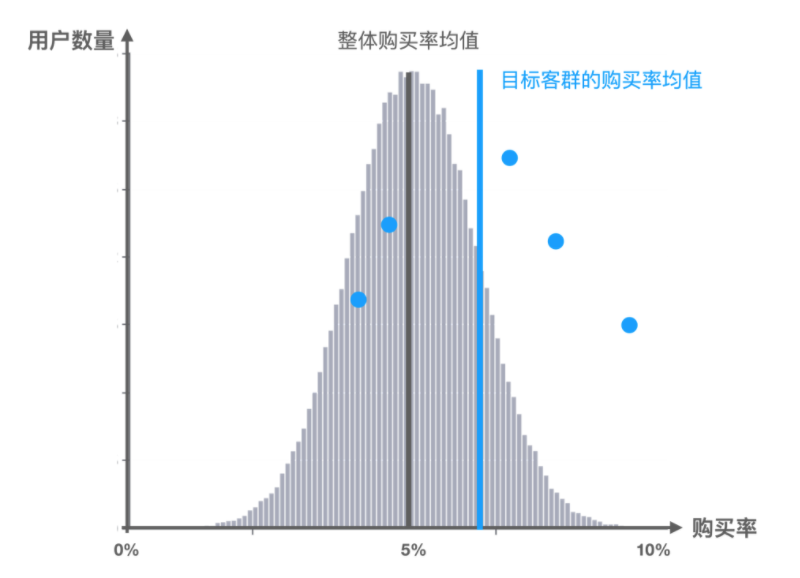
第二种情况
绿色分组的购买率平均值(绿色线)比整体平均值(黑色线)要高,但是绿色分组的数据非常集中,都集中在分组的平均值(绿色线)附近,此时我们可以认为该组的转化率平均值与整体有明显区别。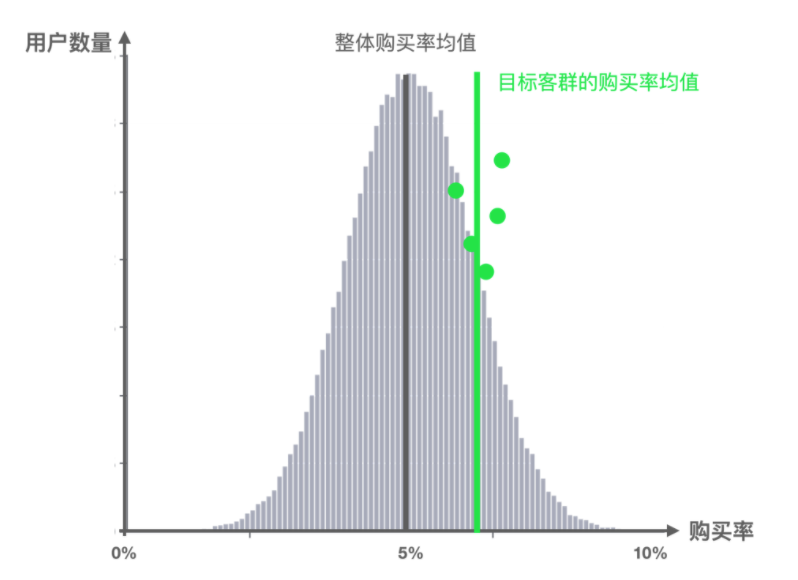
为了更好表述上面的问题,我们可以引入“组内方差”的概念,即描述每个分组内部数据分布的离散情况。如下图所示,对于上面蓝色和绿色分组的“组内方差”,显然蓝色的组内方差更大,绿色的组内方差更小。
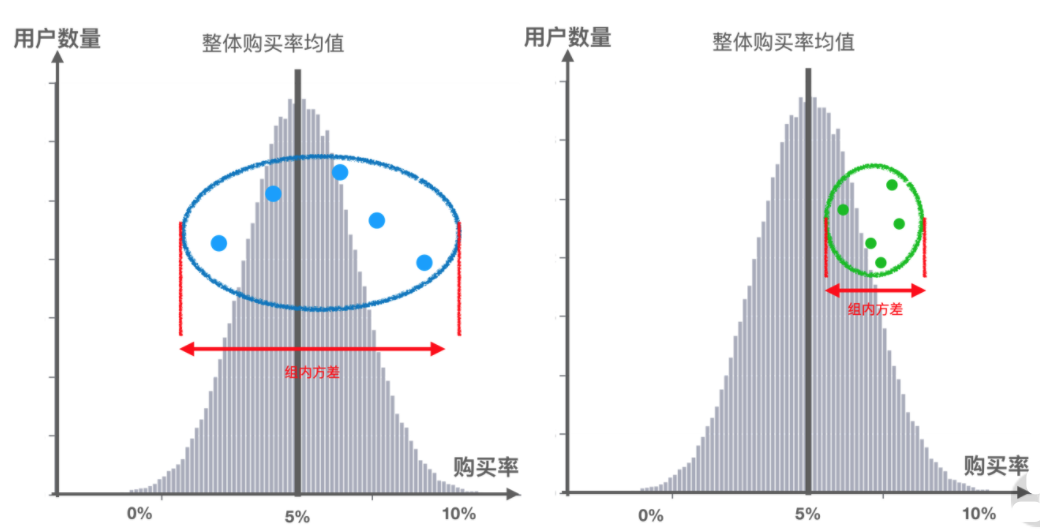
综上所述,如果上面三个分组的用户购买率平均值不在中线(整体购买率)左右,而是有明显的偏高或偏低,并且该组内的每个转化率都紧紧围绕在该组购买率平均值的附近(即组内方差很小)。那么我们就可以断定:该组的购买率与整体不一致,是该组对应优惠金额的影响造成的。
定量分析
如果要进行定量分析,可以使用 F 检验值和 F crit 临界值这两个指标。F 检验值用来精确表达这几组差异大小的,F crit临界值是一个判断基线:
- 当 F > F crit,这几组之间的差异超过判断基准了,认为不同优惠金额的分组间的购买率是不一样的,优惠金额这个因素会对购买率产生影响,也就是说通过运营优惠金额这个抓手,是可以提升用户购买转化率的;
- 当 F < F crit,则认为不同优惠金额的分组间的购买率是一样的,优惠金额这个因素不会对购买率产生影响,也就是说需要继续寻找其他与购买转化率有关的抓手。
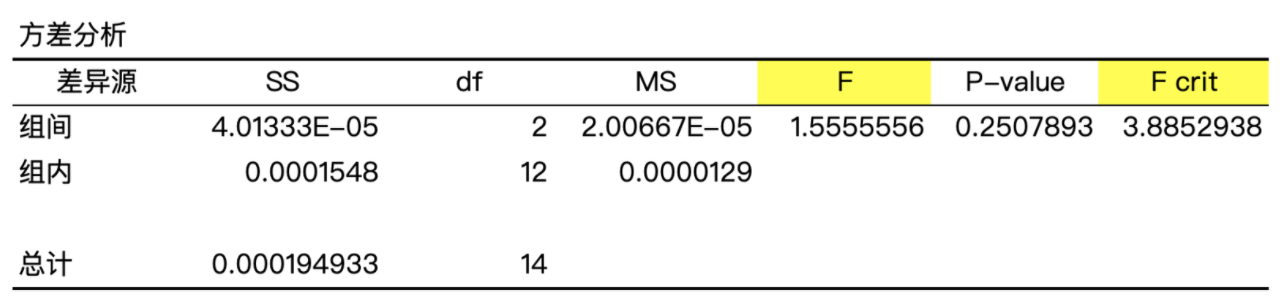
说明:图中 SS 代表方差、df 代表指标自由度、MS 是均方差、P-value 是差异的显著性水平。
上图是用 Excel 得出的 A、B、C 三组的方差分析结果,如图所示 F < F crit,所以从定量分析角度,可以判定优惠金额不会对购买率产生影响。
实施方法
实施方差分析可以分为以下三步走:
判断样本是否满足“方差分析”的前提条件
- 每个分组中的每个值都必须来自同一个总体样本;
方差分析只能分析满足正态分布的指标,事实上,在产品运营中大部分指标都是正态分布,例如:
- 几乎所有的转化率都满足正态分布:购买率、点击率、转化率、活跃率、留存率、复购率等。
- 几乎所有的业务量都满足正态分布:客单价、每日新增用户数、渠道引流的流量等。
- 几乎所有的用户画像指标都满足正态分布:年龄、城市、登录次数、使用时长等。
- 分析的样本必须是随机抽样
计算 F 检验值和 F crit 临界值
如果有差异,需要评估差异大小
我们用一个新的指标来表示:$ R^2=SSA / SST $,其中 $ R^2 $ 表示差异大小,$ SSA $ 是组间误差平方和,$ SST $ 是总误差平方和。- 当 $ R^2 \gt 0.5 $,认为各个分组间的差异非常显著;
- 当 $ R^2 $ 在 $ [0.1, 0.5] $ 之间时,认为各个分组间的差异一般显著;
- 当 $ R^2 \lt 0.1 $ 时,认为各个分组间的差异微弱显著。
练习:打开“方差分析练习.xlsx”文件,完成练习1。
多因素方差分析
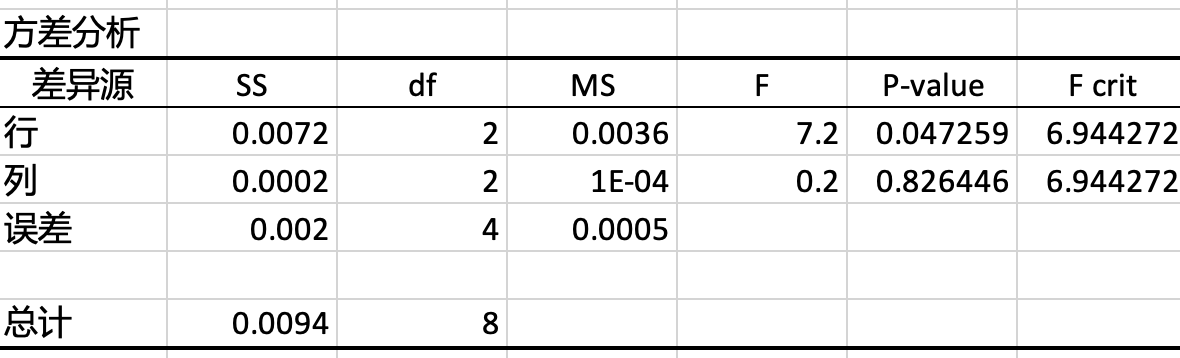
上面的案例是针对一种策略来分析效果。我们把这种形式的方差分析叫作单因素方差分析,实际工作中,我们可能需要研究多种策略(例如运营中的渠道、活动、客群等)对结果的影响,我们称之为多因素方差分析。例如我们会在多个运营渠道上安排多种运营活动,评价各个渠道的转化率。此时,影响转化率的因素有渠道和活动两个因素,我们可以使用“无重复双因素方差分析”来检查数据。
应用场景
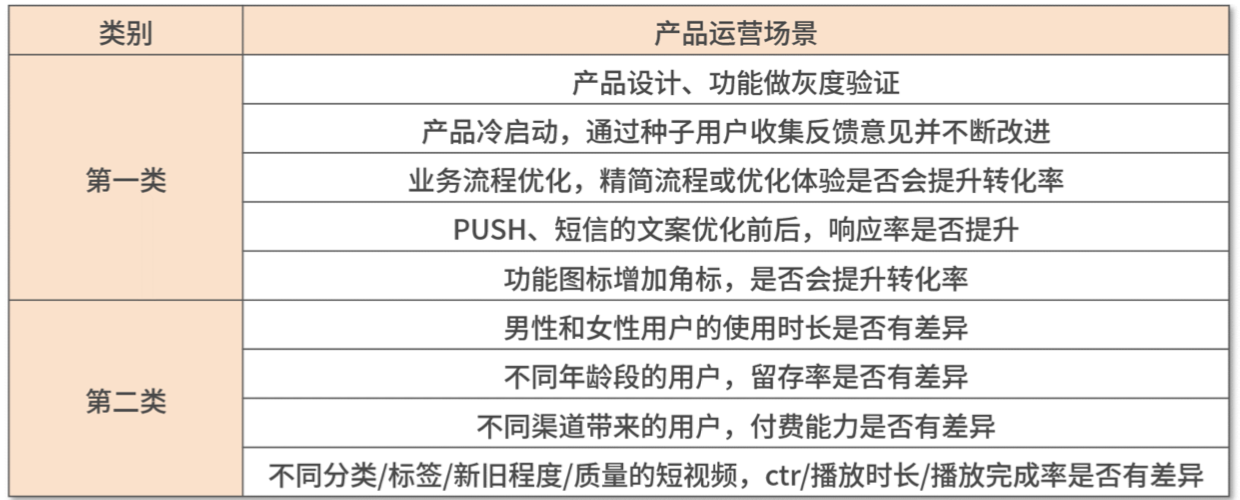
工作中遇到以下两类场景就可以使用方差分析:
- 同一个客群在实施某个策略前后的指标对比。
- 两个或多个客群对比同一指标,评估同一指标在不同客群上的差异。
参数估计
在产品运营的工作中,数据分析常会遭遇诸多非常让人困扰的情况,例如:产品运营面对的数据量动辄百万级、千万级,带来的就是分析速度急剧下降,跑个数等一两天时间已经是很理想情况;另外,在很多场景下,我们都只能拿到部分数据(样本),而无法获取全量数据(总体)。在这种情况下我们就必须通过分析非常小量样本的特征,再用这些特征去评估海量总体数据的特征,可以称之为样本检验。
推断型统计的核心就是用样本推测总体。在实际生产环境中,可能无法获得所有的数据,或者即便获取了所有的数据,但是没有足够的资源来分析所有的数据,在这种情况下,我们都需要用非常小量的样本特征去评估总体数据的特征,这其中的一项工作就是参数估计。
参数估计应用的场景非常的多,例如:
- 在产品侧,我们可以用参数估计的方式评估A/B测试的效果。
- 在运营侧,我们可以用参数估计的方式优化活动配置和推荐策略。
- 在市场侧,我们可以用参数估计的方式制定广告投放策略。
实施步骤
确定分析的置信水平
确定估计的参数类型
计算参数估计的区间
- 数值型指标:$ A = z \times 样本标准差 / \sqrt{样本数量} $,其中 $ z $ 的值可以通过查表得到,如果置信水平选择95%,那么 $ z $ 的值就是1.96。大部分运营指标都是数值型指标,例如DAU、ARPU、转化率等。
- 占比型指标:$ A = z \times \sqrt{占比 \times (1 - 占比) / 样本数量}
z $ 值同上。占比型指标如性别占比、渠道占比、品类占比等。

若有收获,就点个赞吧
0 人点赞
