- 剑指 Offer 27.二叉树的镜像">1、剑指 Offer 27.二叉树的镜像
- 剑指 Offer 55 - I.二叉树的深度">2、剑指 Offer 55 - I.二叉树的深度
- 剑指 Offer 54.二叉搜索树的第k大节点">3、剑指 Offer 54.二叉搜索树的第k大节点
- 剑指 Offer 68 - II.二叉树的最近公共祖先">4、剑指 Offer 68 - II.二叉树的最近公共祖先
- 剑指 Offer 07.重建二叉树">5、剑指 Offer 07.重建二叉树
- 剑指 Offer 68 - I.二叉搜索树的最近公共祖先">6、剑指 Offer 68 - I.二叉搜索树的最近公共祖先
- 剑指 Offer 32 - II. 从上到下打印二叉树 II">7、剑指 Offer 32 - II. 从上到下打印二叉树 II
- 剑指 Offer 36.二叉搜索树与双向链表">8、剑指 Offer 36.二叉搜索树与双向链表
- 剑指 Offer 32 - I.从上到下打印二叉树">9、剑指 Offer 32 - I.从上到下打印二叉树
- 剑指 Offer 32 - III.从上到下打印二叉树 II">11、剑指 Offer 32 - III.从上到下打印二叉树 II
- 剑指 Offer 34.二叉树中和为某一值">12、剑指 Offer 34.二叉树中和为某一值
- 剑指 Offer 28.对称的二叉树">13、剑指 Offer 28.对称的二叉树
- 剑指 Offer 37.序列化二叉树">14、剑指 Offer 37.序列化二叉树
- 剑指 Offer 33.二叉搜索树的后序遍历">15、剑指 Offer 33.二叉搜索树的后序遍历
- 剑指 Offer 26.树的子结构">16、剑指 Offer 26.树的子结构
- 226. 翻转二叉树">17、226. 翻转二叉树
- 617. 合并二叉树">18、617. 合并二叉树
- 94. 二叉树的中序遍历">19、94. 二叉树的中序遍历
- 538. 把二叉搜索树转换为累加树">20、538. 把二叉搜索树转换为累加树
- 114. 二叉树展开为链表">21、114. 二叉树展开为链表
- 208. 实现 Trie (前缀树)">22、208. 实现 Trie (前缀树)
- 96. 不同的二叉搜索树">23、96. 不同的二叉搜索树
- 337. 打家劫舍 III">24、337. 打家劫舍 III
- 437. 路径总和 III">25、437. 路径总和 III
- 543. 二叉树的直径">26、543. 二叉树的直径
- 面试题 04.06. 后继者">27、面试题 04.06. 后继者
- 104. 二叉树的最大深度">28、104. 二叉树的最大深度
1、剑指 Offer 27.二叉树的镜像
1.1 题目
请完成一个函数,输入一个二叉树,该函数输出它的镜像。
例如输入:
4
/ \
2 7
/ \ / \
1 3 6 9
镜像输出:
4
/ \
7 2
/ \ / \
9 6 3 1
1.2 思路
1.3 代码
class Solution {public TreeNode mirrorTree(TreeNode root) {if (root == null) {return null;}TreeNode tmp = mirrorTree(root.right);root.right = mirrorTree(root.left);root.left = tmp;return root;}}
2、剑指 Offer 55 - I.二叉树的深度
2.1 题目
输入一棵二叉树的根节点,求该树的深度。从根节点到叶节点依次经过的节点(含根、叶节点)形成树的一条路径,最长路径的长度为树的深度。
例如:
给定二叉树 [3,9,20,null,null,15,7],
3
/ \
9 20
/ \
15 7
返回它的最大深度 3 。
2.2 思路
有dfs和bfs两种思路,dfs就是常规的递归,bfs需要借助队列层序遍历二叉树。
2.3 代码
dfs:
class Solution {public int maxDepth(TreeNode root) {if (root == null) {return 0;}return Math.max(maxDepth(root.left), maxDepth(root.right)) + 1;}}
bfs:
import java.util.LinkedList;class Solution {public int maxDepth(TreeNode root) {int depth = 0;LinkedList<TreeNode> queue = new LinkedList<>();if (root == null) {return depth;}queue.addLast(root);while (!queue.isEmpty()) {int size = queue.size();++depth;for (int i = 0; i < size; ++i) {TreeNode node = queue.pollFirst();if (node.left != null) {queue.addLast(node.left);}if (node.right != null) {queue.addLast(node.right);}}}return depth;}}
3、剑指 Offer 54.二叉搜索树的第k大节点
3.1 题目

3.2 思路
- 前提是二叉搜索树,二叉搜索树的性质是左子树上的节点都小于根节点,右子树上的节点都大于根节点,利用这个性质,可以对二叉树进行“中序遍历”,顺序为“右根左”;
还有一个关键的问题是,何时对计数器k减一,答案是遍历某一个节点时,仅做一次减一操作。
3.3 代码
class Solution {private int res = 0;private int cnt = 0;public int kthLargest(TreeNode root, int k) {dfs(root, k);return this.res;}private void dfs(TreeNode root, int k) {if (root == null) {return;}dfs(root.right, k);if (++cnt == k) {this.res = root.val;return;}dfs(root.left, k);}}
4、剑指 Offer 68 - II.二叉树的最近公共祖先
4.1 题目
给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。
百度百科中最近公共祖先的定义为:“对于有根树 T 的两个结点 p、q,最近公共祖先表示为一个结点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”
例如,给定如下二叉树: root = [3,5,1,6,2,0,8,null,null,7,4]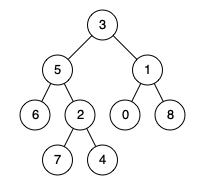
示例 1:
输入: root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 1 输出: 3 解释: 节点 5 和节点 1 的最近公共祖先是节点 3。
示例 2:
输入: root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 4 输出: 5 解释: 节点 5 和节点 4 的最近公共祖先是节点 5。因为根据定义最近公共祖先节点可以为节点本身。
4.2 思路
二叉树公共祖先的问题可以归纳成二叉树的一种题型。
root是p、q的最近公共祖先,则只可能为以下三种情况之一:
- p和q分布在root的左右子树中;
- p=root,q在root的左子树或者右子树中;
- q=root,p在root的左子树或者右子树中;
算法流程:
终止条件:
- 当root越过叶子节点(即叶子节点的左右空子树),返回null;
- 当root等于p或者q时,直接返回root。
a、b可以合并成一个判断条件。
递归工作:
二叉树的后序遍历。- 递归root.left,返回值为left;
- 递归root.right,返回值为right。
- 返回值:
- 当left == null && right == null,说明root的左右子树中均不含p、q,返回null;
- 当left != null && right != null,说明p、q分布在root的左右子树中,直接返回root;
- 当left == null && right != null,说明p、q均不在root的左子树中,直接返回right;
- 当left != null && right == null,说明p、q均不在root的右子树中,直接返回left。
情况 a 可以合并到c、d内,即只写c、d就相当于写了a。
可以先把所有情况的判断都写上,然后在考虑简化合并判断条件。
4.3 代码
class Solution {public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {if (root == p || root == q || root == null) {return root;}TreeNode left = lowestCommonAncestor(root.left, p, q);TreeNode right = lowestCommonAncestor(root.right, p, q);if (left == null) {return right;}if (right == null) {return left;}return root;}}
5、剑指 Offer 07.重建二叉树
5.1 题目
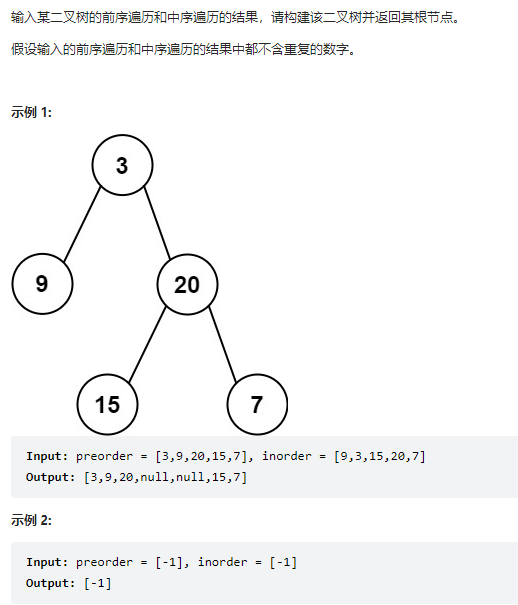
5.2 思路
这道题是已知二叉树的前序遍历和中序遍历,能唯一确定一棵二叉树。
前序遍历:根左右;
中序遍历:左根右。
可以推出以下结论:
1. 前序遍历的第一个元素即为根节点;
2. 找到根节点后,在中序遍历数组中,根节点左边的部分是左子树的组成元素,根节点右边的部分是右子树的组成元素。即将中序遍历的数组分成了左子树、根节点、右子树;
3. 根据2中序遍历划分好的左右子树,可以获取左右子树中的元素的个数,以此在前序遍历中根据个数划分左右子树。即前序遍历的数组也划分了左子树、根节点、右子树。
根据上面推论,可以通过前序遍历生成二叉树的方式复原二叉树,需要注意以下几点:
1. 在划分中序遍历数组时需要计算左右子树的元素个数,这里可以用一个map维护,key是中序遍历的元素,value是元素对应的下标。这样做的目的是,在dfs函数里划分前序遍历的左右子树时,更加方便的获取左右子树的元素数量及下标,直接从map里get即可,不需要再遍历数组了;
2. 注意递归终止条件,当树的元素只有1个时,此时直接返回这个元素对应的树节点即可;当前序和中序数组都只有两个元素,比如前序[3,9],中序[9,3],对应了start > end的条件,此时应返回null;
3. 前序遍历和中序遍历的数组均成功划分了左右子树后,对root.left和root.right分治,划分左右子树时下标的计算很容易出错。
递归返回条件中,start > end时返回null不要忘。
5.3 代码
class Solution {private int[] preorder;private int[] inorder;private Map<Integer, Integer> inorderMap = new HashMap<>();public TreeNode buildTree(int[] preorder, int[] inorder) {if (preorder == null || inorder == null) {return null;}this.preorder = preorder;this.inorder = inorder;for (int i = 0; i < inorder.length; ++i) {inorderMap.put(inorder[i], i);}return dfs(0, preorder.length - 1, 0, inorder.length - 1);}private TreeNode dfs(int preStart, int preEnd, int inStart, int inEnd) {// 这两个if判断去掉也可以,当数组中只有一个节点时直接返回叶子节点即可,不需要再做后续的逻辑了if (preStart == preEnd) {return new TreeNode(preorder[preStart]);}if (inStart == inEnd) {return new TreeNode(inorder[inStart]);}// 当前序为【1,2】,中序为【2,1】时,这种情况下应返回nullif (preStart > preEnd || inStart > inEnd) {return null;}int inMid = inorderMap.get(preorder[preStart]);int leftNum = inMid - inStart;int preMid = preStart + leftNum;TreeNode node = new TreeNode(preorder[preStart]);// 左子树node.left = dfs(preStart + 1, preMid, inStart, inMid - 1);// 右子树node.right = dfs(preMid + 1, preEnd, inMid + 1, inEnd);return node;}}
6、剑指 Offer 68 - I.二叉搜索树的最近公共祖先
6.1 题目
给定一个二叉搜索树, 找到该树中两个指定节点的最近公共祖先。
百度百科中最近公共祖先的定义为:“对于有根树 T 的两个结点 p、q,最近公共祖先表示为一个结点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”
例如,给定如下二叉搜索树: root = [6,2,8,0,4,7,9,null,null,3,5]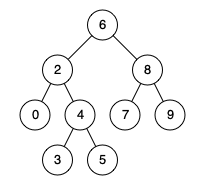
示例 1:
输入: root = [6,2,8,0,4,7,9,null,null,3,5], p = 2, q = 8 输出: 6 解释: 节点 2 和节点 8 的最近公共祖先是 6。
示例 2:
输入: root = [6,2,8,0,4,7,9,null,null,3,5], p = 2, q = 4 输出: 2 解释: 节点 2 和节点 4 的最近公共祖先是 2, 因为根据定义最近公共祖先节点可以为节点本身。
6.2 思路
跟前面普通二叉树的最近公共祖先是一类题目。要利用二叉搜索树的性质,即根节点的值均大于左子树的所有节点值,均小于右子树的所有节点值。
算法流程:
- 当p、q值均小于root值时,说明p、q在root的左子树上,递归入参的root缩小范围为root.left;
- 当p、q值均大于root值时,说明p、q在root的右子树上,递归入参的root缩小范围为root.right;
- 当p或者q中有一个值等于root值时,直接返回root(对应root值为p或者q中的一个,剩下的一个p或者q在root的子树中这种情况);
- 当p、q值一个大于root,一个小于root,表明p、q是分别分布在root的左右子树上的,则直接返回root。
第3、4步可以写到一个判断逻辑中,即不满足1、2时,就直接返回root。
6.3 代码
class Solution {public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {if (p.val < root.val && q.val < root.val) {return lowestCommonAncestor(root.left, p, q);}if (p.val > root.val && q.val > root.val) {return lowestCommonAncestor(root.right, p, q);}return root;}}
7、剑指 Offer 32 - II. 从上到下打印二叉树 II
7.1 题目
从上到下按层打印二叉树,同一层的节点按从左到右的顺序打印,每一层打印到一行。
7.2 思路
7.3 代码
class Solution {private List<List<Integer>> res = new LinkedList<>();public List<List<Integer>> levelOrder(TreeNode root) {if (root == null) {return res;}LinkedList<TreeNode> queue = new LinkedList<>();queue.addLast(root);while (!queue.isEmpty()) {List<Integer> list = new LinkedList<>();int size = queue.size();for (int i = 0; i < size; ++i) {TreeNode node = queue.pollFirst();list.add(node.val);if (node.left != null) {queue.addLast(node.left);}if (node.right != null) {queue.addLast(node.right);}}res.add(new LinkedList<>(list));}return res;}}
8、剑指 Offer 36.二叉搜索树与双向链表
8.1 题目
输入一棵二叉搜索树,将该二叉搜索树转换成一个排序的循环双向链表。要求不能创建任何新的节点,只能调整树中节点指针的指向。为了让您更好地理解问题,以下面的二叉搜索树为例: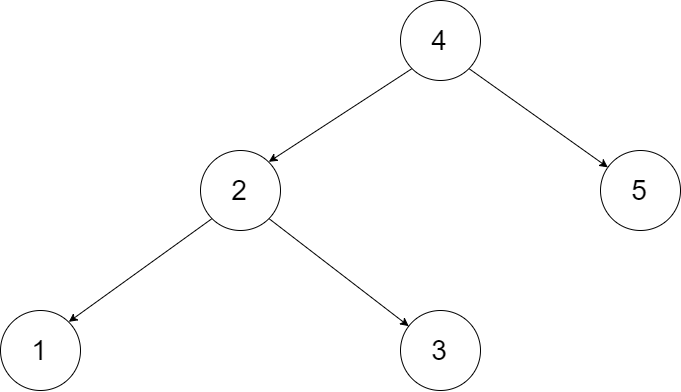
我们希望将这个二叉搜索树转化为双向循环链表。链表中的每个节点都有一个前驱和后继指针。对于双向循环链表,第一个节点的前驱是最后一个节点,最后一个节点的后继是第一个节点。下图展示了上面的二叉搜索树转化成的链表。“head” 表示指向链表中有最小元素的节点。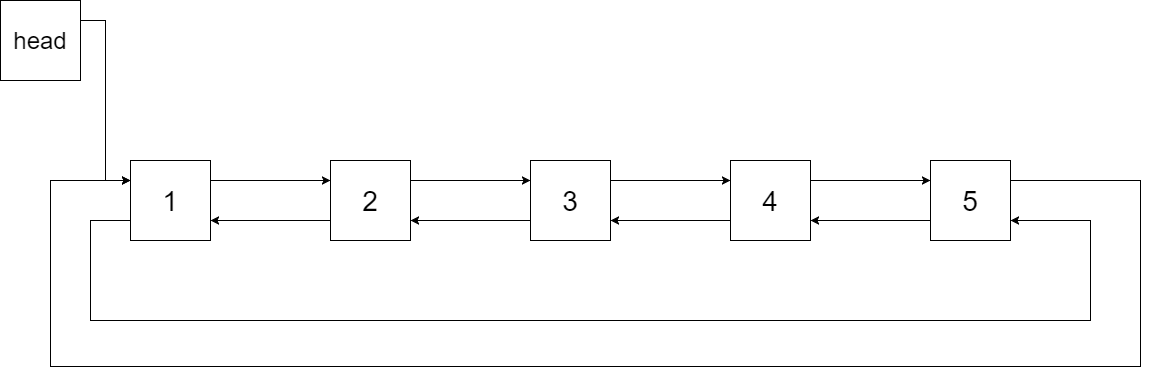
特别地,我们希望可以就地完成转换操作。当转化完成以后,树中节点的左指针需要指向前驱,树中节点的右指针需要指向后继。还需要返回链表中的第一个节点的指针。
8.2 思路
二叉搜索树中序遍历,得到的val会按升序排序,因此本题的dfs为中序遍历。
- 需要维护两个private成员变量head、pre,head为生成的双向循环链表的头结点,pre为双向循环链表的前一个节点,最终pre为最后一个节点;
- 当pre为null时,说明此时的cur正是头结点,令head指向cur;
- 二叉搜索树每轮dfs,令
pre.right = cur,cur.left = pre; -
8.3 代码
class Solution {private Node head;private Node pre;public Node treeToDoublyList(Node root) {if (root == null) {return null;}dfs(root);pre.right = head;head.left = pre;return head;}private void dfs(Node cur) {if (cur == null) {return;}dfs(cur.left);if (pre == null) {head = cur;} else {pre.right = cur;}cur.left = pre;pre = cur;dfs(cur.right);}}
9、剑指 Offer 32 - I.从上到下打印二叉树
9.1 题目
从上到下打印出二叉树的每个节点,同一层的节点按照从左到右的顺序打印。

9.2 思路
二叉树的层序遍历。这里需要注意一个List
转换为 int[]的方法: list.stream().mapToInt(Integer::valueOf).toArray();9.3 代码
```java import java.util.ArrayList; import java.util.LinkedList; import java.util.List;
class Solution {
private List
public int[] levelOrder(TreeNode root) {if (root == null) {return new int[0];}LinkedList<TreeNode> queue = new LinkedList<>();queue.addLast(root);while (!queue.isEmpty()) {int size = queue.size();for (int i = 0; i < size; ++i) {TreeNode node = queue.pollFirst();res.add(node.val);if (node.left != null) {queue.addLast(node.left);}if (node.right != null) {queue.addLast(node.right);}}}return res.stream().mapToInt(Integer::valueOf).toArray();}
}
<a name="sNJQH"></a># 10、[剑指 Offer 55 - II.平衡二叉树](https://leetcode-cn.com/problems/ping-heng-er-cha-shu-lcof/)<a name="QcAIH"></a>## 10.1 题目输入一棵二叉树的根节点,判断该树是不是平衡二叉树。如果某二叉树中任意节点的左右子树的深度相差不超过1,那么它就是一棵平衡二叉树。<br /><a name="mbwIM"></a>## 10.2 思路这道题看似是求一棵树是否为平衡二叉树,其实是求二叉树深度的题的变种。底层的dfs函数还是在求树的深度,具体地:1. 当以root为根节点的树是平衡二叉树时,dfs函数返回树的高度;否则,返回固定值-1,表明当前树不是平衡二叉树;1. dfs函数内部采用后序遍历,当左子树或者右子树的高度是-1时,说明左子树或者右子树不是平衡二叉树,直接返回-1,不用再进行后续的dfs了。<a name="nk8mM"></a>## 10.3 代码```javaclass Solution {public boolean isBalanced(TreeNode root) {if (root == null) {return true;}return helper(root) != -1;}private int helper(TreeNode root) {if (root == null) {return 0;}int leftDepth = helper(root.left);if (leftDepth == -1) {return -1;}int rightDepth = helper(root.right);if (rightDepth == -1) {return -1;}return Math.abs(leftDepth - rightDepth) <= 1? Math.max(leftDepth, rightDepth) + 1: -1;}}
11、剑指 Offer 32 - III.从上到下打印二叉树 II
11.1 题目
请实现一个函数按照之字形顺序打印二叉树,即第一行按照从左到右的顺序打印,第二层按照从右到左的顺序打印,第三行再按照从左到右的顺序打印,其他行以此类推。
11.2 思路
二叉树的层序遍历。只不过要判断一下层号,偶数的正常,奇数的反转。
11.3 代码
import java.util.Collections;import java.util.LinkedList;import java.util.List;class Solution {private List<List<Integer>> res = new LinkedList<>();public List<List<Integer>> levelOrder(TreeNode root) {if (root == null) {return res;}LinkedList<TreeNode> queue = new LinkedList<>();queue.addLast(root);int level = 0;while (!queue.isEmpty()) {List<Integer> list = new LinkedList<>();int size = queue.size();for (int i = 0; i < size; ++i) {TreeNode node = queue.pollFirst();list.add(node.val);if (node.left != null) {queue.addLast(node.left);}if (node.right != null) {queue.addLast(node.right);}}if (level % 2 == 0) {res.add(new LinkedList<>(list));} else {Collections.reverse(list);res.add(new LinkedList<>(list));}++level;}return res;}}
12、剑指 Offer 34.二叉树中和为某一值
12.1 题目
给你二叉树的根节点 root 和一个整数目标和 targetSum ,找出所有 从根节点到叶子节点 路径总和等于给定目标和的路径。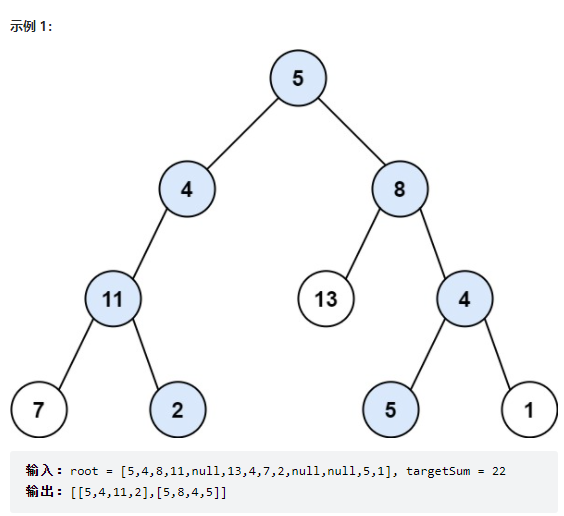
12.2 思路
整体还是一个二叉树的先序遍历,需要注意以下两点:
- 判断trace是否添加到res的条件,不需要到root==null,只要root的左右子树都为null,且target已经减到零时就可以将trace添加到res了;
- 一定要注意:由于trace是一个引用,指向堆中唯一一块内存,递归中trace指向的也是同一个对象,因此当前节点add到trace,并递归了节点的左右子树之后,需要把节点从trace里remove掉,否则递归向上走到11时时,trace里还有之前的7。
12.3 代码
class Solution {private List<List<Integer>> res = new ArrayList<>();private LinkedList<Integer> trace = new LinkedList<>();public List<List<Integer>> pathSum(TreeNode root, int target) {if (root == null) {return res;}dfs(root, target);return res;}private void dfs(TreeNode root, int target) {if (root == null) {return;}trace.addLast(root.val);target -= root.val;if (root.left == null && root.right == null && target == 0) {res.add(new ArrayList<>(trace));}dfs(root.left, target);dfs(root.right, target);trace.removeLast();}}
13、剑指 Offer 28.对称的二叉树
13.1 题目
请实现一个函数,用来判断一棵二叉树是不是对称的。如果一棵二叉树和它的镜像一样,那么它是对称的。
例如,二叉树 [1,2,2,3,4,4,3] 是对称的。
1
/ \
2 2
/ \ / \
3 4 4 3
但是下面这个 [1,2,2,null,3,null,3] 则不是镜像对称的:
1
/ \
2 2
\ \
3 3
示例 1:
输入:root = [1,2,2,3,4,4,3] 输出:true
示例 2:
输入:root = [1,2,2,null,3,null,3] 输出:false
13.2 思路
需要借助一个辅助的dfs函数来处理,这个dfs函数来判断两个根节点对应的树是否是镜像对称。注意root为null这个边界情况,root为null的树也是对称二叉树。
13.3 代码
class Solution {public boolean isSymmetric(TreeNode root) {if (root == null) {return true;}return isMirror(root.left, root.right);}private boolean isMirror(TreeNode root1, TreeNode root2) {if (root1 == null && root2 == null) {return true;}if (root1 == null || root2 == null) {return false;}if (root1.val != root2.val) {return false;}return isMirror(root1.left, root2.right) && isMirror(root1.right, root2.left);}}
14、剑指 Offer 37.序列化二叉树
14.1 题目
请实现两个函数,分别用来序列化和反序列化二叉树。
你需要设计一个算法来实现二叉树的序列化与反序列化。这里不限定你的序列 / 反序列化算法执行逻辑,你只需要保证一个二叉树可以被序列化为一个字符串并且将这个字符串反序列化为原始的树结构。
示例: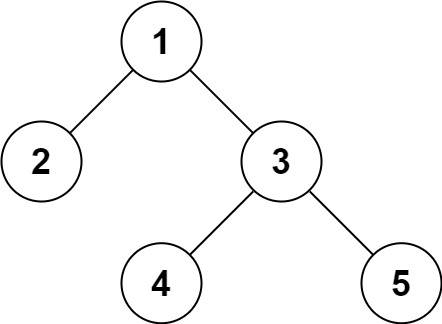
输入:root = [1,2,3,null,null,4,5] 输出:[1,2,3,null,null,4,5]
14.2 思路
采用深度优先搜索的思想。
- 序列化
前序遍历二叉树,将值用逗号分割开,叶子节点将null值也用null字符串返回,比如:”1,2,null,null,3,4,null,null,5,null.null”。注意在序列化的dfs函数里,只append root节点的值,左右子树仅递归,无需append。
- 反序列化
由于序列化生成的字符串是由先序遍历生成,因此反序列化里也采用先序遍历的dfs函数。每次dfs仅处理list链表的首元素,具体地:
- 当首元素为null字符串时,返回null的TreeNode,并且把这个首元素从list中移除;
以当前list链表的首元素来new一个TreeNode,先dfs左子树,后dfs右子树。
14.3 代码
public class Codec {public String serialize(TreeNode root) {StringBuilder sb = new StringBuilder();return serializeDfs(root, sb).toString();}private StringBuilder serializeDfs(TreeNode root, StringBuilder sb) {if (root == null) {sb.append("null").append(',');} else {sb.append(root.val).append(',');serializeDfs(root.left, sb);serializeDfs(root.right, sb);}return sb;}public TreeNode deserialize(String data) {String[] array = data.split(",");List<String> list = new LinkedList<>(Arrays.asList(array));return deserializeDfs(list);}private TreeNode deserializeDfs(List<String> list) {if ("null".equals(list.get(0))) {list.remove(0);return null;}TreeNode root = new TreeNode(Integer.parseInt(list.get(0)));list.remove(0);root.left = deserializeDfs(list);root.right = deserializeDfs(list);return root;}}
15、剑指 Offer 33.二叉搜索树的后序遍历
15.1 题目
输入一个整数数组,判断该数组是不是某二叉搜索树的后序遍历结果。如果是则返回 true,否则返回 false。假设输入的数组的任意两个数字都互不相同。
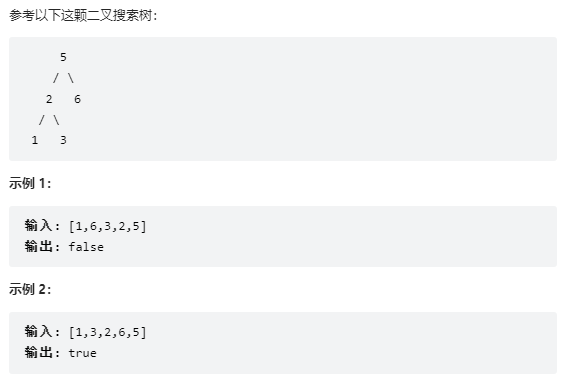
15.2 思路
整体是递归的实现,一个数组是某一个二叉搜索树的后续遍历序列,则找到数组中左右子树的分界点,基于分界点找到对应左右子树对应的数组,如果左右子树对应的数组也是二叉搜索树的后续遍历结果,则整个数组就是二叉搜索树的后续遍历结果。
- 正确的二叉搜索树的后续遍历,对应的数组的最后一位是根节点;
- 获取二叉树的左右子树的分界线:遍历数组,遇到的第一个比最后一位根节点大的值,对应的数组下标就是分界线;
- 以分界线获取左右子树对应的数组,再进行递归,只有左右子树对应的数组都是二叉搜索树的后续遍历结果,才返回true;
- 最后是确定递归函数的返回值(boolean):
- 3中找到分界点后,还需要继续向后遍历,此时遍历的是右子树。如果右子树中的某一个元素值小于根节点值,则整个数组不是二叉搜索树的后续遍历结果,返回false;
- 如果left和right值相等,说明当前数组仅有一个元素,仅有一个根节点的树是二叉搜索树,返回true;
- 如果left > right,则对应数组中仅有两个元素且是升序,比如[0, 1],此时也是二叉搜索树,返回true。
left >= right,return true,不要忘了>的场景。
15.3 代码
class Solution {public boolean verifyPostorder(int[] postorder) {if (postorder == null || postorder.length == 0) {return true;}return dfs(0, postorder.length - 1, postorder);}private boolean dfs(int left, int right, int[] postorder) {if (left >= right) {return true;}int rootVal = postorder[right];int index = left;while (index < right && postorder[index] < rootVal) {++index;}int mid = index;while (index < right) {if (postorder[index] < rootVal) {return false;}++index;}return dfs(left, mid - 1, postorder) && dfs(mid, right - 1, postorder);}}
16、剑指 Offer 26.树的子结构
16.1 题目
输入两棵二叉树A和B,判断B是不是A的子结构。(约定空树不是任意一个树的子结构)。B是A的子结构, 即 A中有出现和B相同的结构和节点值。
例如:
给定的树 A:
3
/ \
4 5
/ \
1 2
给定的树 B:
4
/
1
返回 true,因为 B 与 A 的一个子树拥有相同的结构和节点值。
示例 1:
输入:A = [1,2,3], B = [3,1] 输出:false
示例 2:
输入:A = [3,4,5,1,2], B = [4,1] 输出:true
16.2 思路
这道题跟之前树的题目不同的是,这道题目是双重递归:判断B树是不是A树的子树整体用了递归;判断以A、B为根节点的A、B两棵树,B树上对应节点能否对应上A树上节点时又用了递归。
- isContain 递归
该方法判断以A、B为根节点的两棵二叉树,B树的节点能否在A树的相应位置找到对应的节点,即根节点要相同,然后向下递归,B树上的任意位置节点在A树的相同位置都能找到相同节点与之对应。整体是前序遍历。
- isSubStructure 递归
该方法判断B树是否是A树的子结构。如果树B是树A的子树,则必满足以下三种条件之一:
- A树和B树的根节点相同,且B树的节点在A树相同位置都能找到相同的节点,即满足isContain(A, B);
- B树是A树的左子树的子树;
-
16.3 代码
class Solution {public boolean isSubStructure(TreeNode A, TreeNode B) {if (A == null || B == null) {return false;}return isContain(A, B) || isSubStructure(A.left, B) || isSubStructure(A.right, B);}private boolean isContain(TreeNode A, TreeNode B) {if (B == null) {return true;}if (A == null || A.val != B.val) {return false;}return isContain(A.left, B.left) && isContain(A.right, B.right);}}
17、226. 翻转二叉树
17.1 题目
17.2 思路
递归思想:
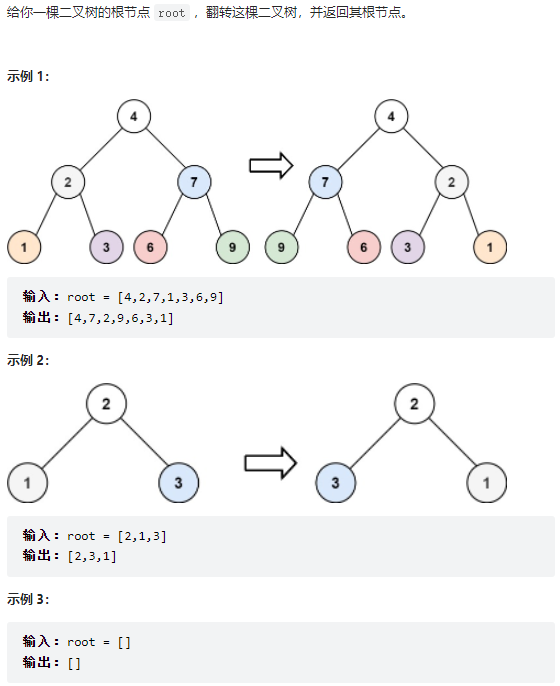
- 先对root.left翻转,再对root.right翻转;
root的左子树用root.right翻转得到的树代替,root的右子树用root.left翻转得到的树代替。
17.3 代码
class Solution {public TreeNode invertTree(TreeNode root) {if (root == null) {return null;}TreeNode left = invertTree(root.left);TreeNode right = invertTree(root.right);root.left = right;root.right = left;return root;}}
18、617. 合并二叉树
18.1 题目
给你两棵二叉树: root1 和 root2 。想象一下,当你将其中一棵覆盖到另一棵之上时,两棵树上的一些节点将会重叠(而另一些不会)。你需要将这两棵树合并成一棵新二叉树。合并的规则是:如果两个节点重叠,那么将这两个节点的值相加作为合并后节点的新值;否则,不为 null 的节点将直接作为新二叉树的节点。返回合并后的二叉树。注意: 合并过程必须从两个树的根节点开始。
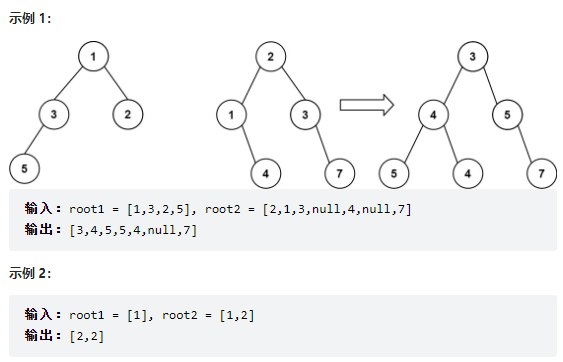
18.2 思路
18.3 代码
class Solution {public TreeNode mergeTrees(TreeNode root1, TreeNode root2) {if (root1 == null && root2 == null) {return null;}if (root1 == null) {return root2;}if (root2 == null) {return root1;}TreeNode root = new TreeNode(root1.val + root2.val);root.left = mergeTrees(root1.left, root2.left);root.right = mergeTrees(root1.right, root2.right);return root;}}
19、94. 二叉树的中序遍历
19.1 题目
给定一个二叉树的根节点 root ,返回 它的 中序 遍历 。
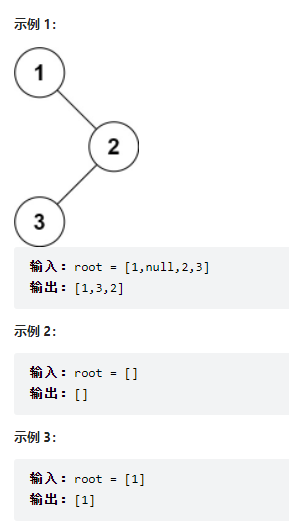
19.2 思路
这道题递归的思路很简单,这里写一下迭代的思路。
迭代需要借助一个栈的数据结构;
- 如果root.left != null,一直dfs,并且把root入栈;
- 当root.left == null时,此时将栈顶元素出栈,将元素的值插入到res里,再将root = root.right,再去对root的右子树去搜索;
- 注意外层while条件是 || 不是 &&;
-
19.3 代码
class Solution {public List<Integer> inorderTraversal(TreeNode root) {List<Integer> res = new ArrayList<>();LinkedList<TreeNode> stack = new LinkedList<>();while (root != null || !stack.isEmpty()) {while (root != null) {stack.addFirst(root);root = root.left;}root = stack.pollFirst();res.add(root.val);root = root.right;}return res;}}
20、538. 把二叉搜索树转换为累加树
20.1 题目
给出二叉 搜索 树的根节点,该树的节点值各不相同,请你将其转换为累加树(Greater Sum Tree),使每个节点 node 的新值等于原树中大于或等于 node.val 的值之和。
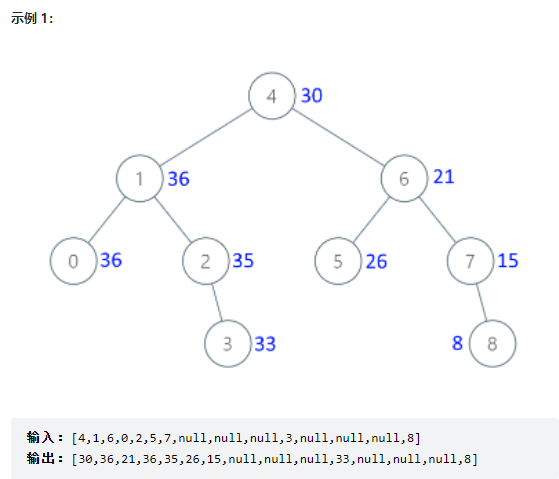
20.2 思路
本题是二叉搜索树,dfs的话肯定是往中序遍历想,因为题目要求root.val+=root右子树上所有节点和,因此是先搜索右子树的中序遍历。
设sum是当前中序遍历所经过的节点的val的累加值;
二叉树节点的值等于该节点的值 + 当前中序遍历所经过的节点的val的累加值sum,root.val的更新都是依靠sum的值去维护的。
20.3 代码
class Solution {private int sum = 0;public TreeNode convertBST(TreeNode root) {if (root != null) {convertBST(root.right);sum += root.val;root.val = sum;convertBST(root.left);}return root;}}
21、114. 二叉树展开为链表
跟本文的第八题很相似。第八题是双向链表,本题是单向链表。但本题的方法跟第八题的又不相关。
21.1 题目
给你二叉树的根结点 root ,请你将它展开为一个单链表:展开后的单链表应该同样使用 TreeNode ,其中 right 子指针指向链表中下一个结点,而左子指针始终为 null 。展开后的单链表应该与二叉树先序遍历顺序相同。
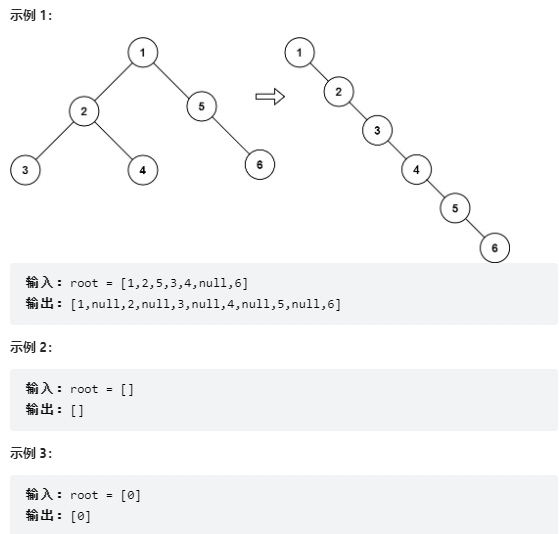
21.2 思路
这思路应该只能用到这一个题上……
题解参考:https://leetcode-cn.com/problems/flatten-binary-tree-to-linked-list/solution/xiang-xi-tong-su-de-si-lu-fen-xi-duo-jie-fa-by—26/如果当前节点的左子树为null,不需要处理,直接root往下搜索;
- 将当前节点的右子树插入到左子树的最右侧节点
- 将插入后的左子树放置到当前节点的右子树上;
- 将当前节点的左子树置为null。
图解过程:
1/ \2 5/ \ \3 4 6// 将 1 的左子树插入到右子树的地方1\2 5/ \ \3 4 6// 将原来的右子树接到左子树的最右边节点1\2/ \3 4\5\6// 将 2 的左子树插入到右子树的地方1\2\3 4\5\6// 将原来的右子树接到左子树的最右边节点1\2\3\4\5\6......
21.3 代码
class Solution {private TreeNode pre = null;public void flatten(TreeNode root) {while (root != null) {TreeNode left = root.left;// 如果root.left为null,直接向下继续遍历if (left == null) {root = root.right;} else {// 遍历后tmp指向root.left的最右侧节点TreeNode tmp = left;while (tmp.right != null) {tmp = tmp.right;}// 将root的右子树插入到root的左子树的最右侧节点的righttmp.right = root.right;// root的右子树用root的左子树替换root.right = root.left;// 将root的左子树置为nullroot.left = null;// 继续搜索下一个节点root = root.right;}}}}
22、208. 实现 Trie (前缀树)
本题是一颗26叉树,且跟传统的二叉树的dfs和bfs的解法不同。打死我都想不出来。
22.1 题目
Trie(发音类似 “try”)或者说 前缀树 是一种树形数据结构,用于高效地存储和检索字符串数据集中的键。这一数据结构有相当多的应用情景,例如自动补完和拼写检查。
请你实现 Trie 类:
- Trie() 初始化前缀树对象。
- void insert(String word) 向前缀树中插入字符串 word 。
- boolean search(String word) 如果字符串 word 在前缀树中,返回 true(即,在检索之前已经插入);否则,返回 false 。
- boolean startsWith(String prefix) 如果之前已经插入的字符串 word 的前缀之一为 prefix ,返回 true ;否则,返回 false 。
示例:
输入 [“Trie”, “insert”, “search”, “search”, “startsWith”, “insert”, “search”] [[], [“apple”], [“apple”], [“app”], [“app”], [“app”], [“app”]] 输出 [null, null, true, false, true, null, true] 解释 Trie trie = new Trie(); trie.insert(“apple”); trie.search(“apple”); // 返回 True trie.search(“app”); // 返回 False trie.startsWith(“app”); // 返回 True trie.insert(“app”); trie.search(“app”); // 返回 True
22.2 思路

22.3 代码
class Trie {private Trie[] children;private boolean isEnd;public Trie() {children = new Trie[26];isEnd = false;}public void insert(String word) {Trie node = this;for (int i = 0; i < word.length(); ++i) {char ch = word.charAt(i);if (node.children[ch - 'a'] == null) {node.children[ch - 'a'] = new Trie();}node = node.children[ch - 'a'];}node.isEnd = true;}public boolean search(String word) {Trie node = searchPrefix(word);return node != null && node.isEnd;}public boolean startsWith(String prefix) {return searchPrefix(prefix) != null;}private Trie searchPrefix(String prefix) {Trie node = this;for (int i = 0; i < prefix.length(); ++i) {char ch = prefix.charAt(i);if (node.children[ch - 'a'] == null) {return null;}node = node.children[ch - 'a'];}return node;}}
23、96. 不同的二叉搜索树
一点思路都没有,甚至不知道这是个dp的题目。打死都想不出来的状态转移方程,只能死记硬背,没有其他法子。
23.1 题目
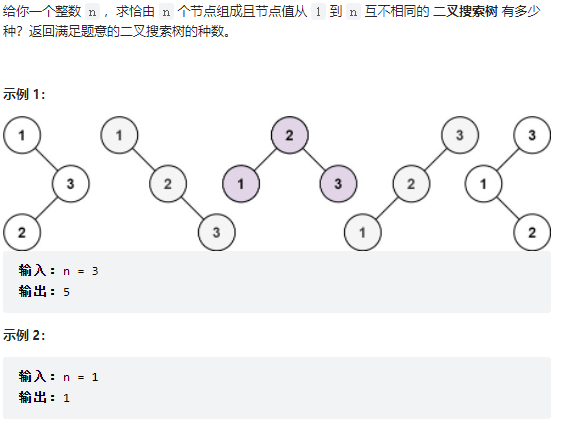
23.2 思路


23.3 代码
class Solution {public int numTrees(int n) {int[] dp = new int[n + 1];dp[0] = 1;dp[1] = 1;for (int i = 2; i <= n; ++i) {for (int j = 1; j <=i; ++j) {dp[i] += dp[j - 1] * dp[i - j];}}return dp[n];}}
24、337. 打家劫舍 III
24.1 题目
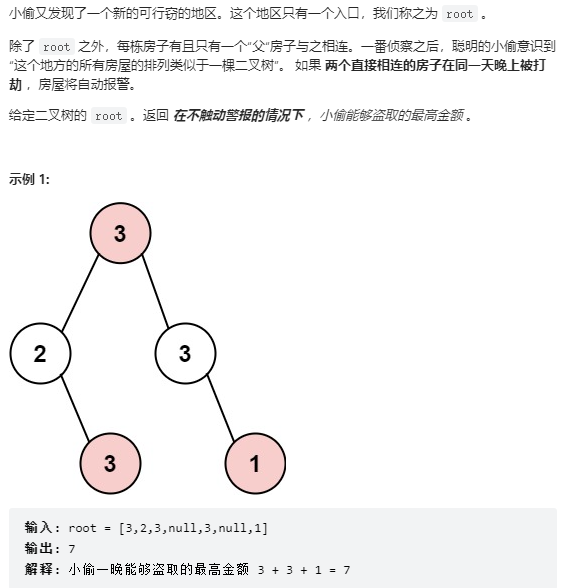
24.2 思路

24.3 代码
class Solution {private Map<TreeNode, Integer> f = new HashMap<>();private Map<TreeNode, Integer> g = new HashMap<>();public int rob(TreeNode root) {if (root == null) {return 0;}dfs(root);return Math.max(f.get(root), g.get(root));}private void dfs(TreeNode root) {if (root == null) {return;}dfs(root.left);dfs(root.right);f.put(root, root.val + g.getOrDefault(root.left, 0) + g.getOrDefault(root.right, 0));g.put(root,Math.max(f.getOrDefault(root.left, 0), g.getOrDefault(root.left, 0)) +Math.max(f.getOrDefault(root.right, 0), g.getOrDefault(root.right, 0)));}}
25、437. 路径总和 III
25.1 题目
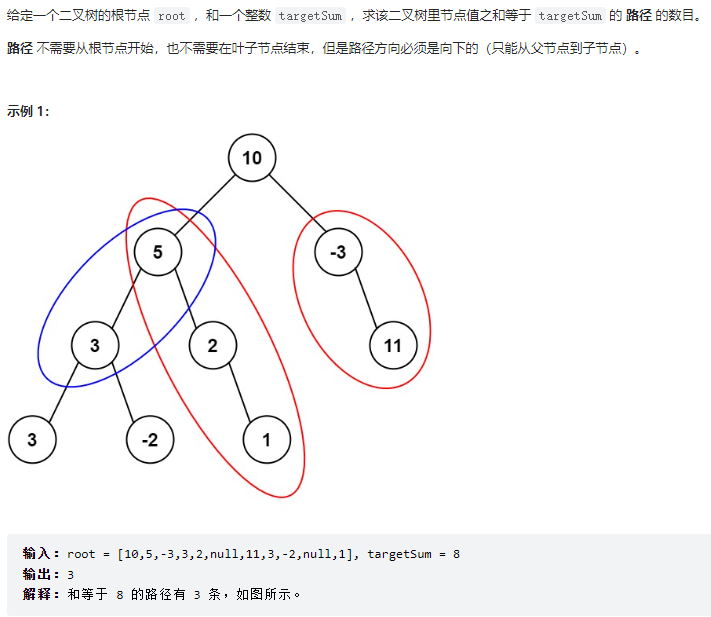
25.2 思路
本题是双重dfs,需要区分pathSum这个dfs和rootSum这个dfs的区别。
- 先说rootSum这个dfs,rootSum表示以root节点为起点,路径上节点之和为targetSum的所有路径的个数,rootSum要求路径一定要以root为起点,具体地:
- 当root==null时,以null为起点肯定一个不满足,所以return 0;
- 注意这种边界条件:当root.val == target时,即几点本身的值就是目标值,直接 + 1;
- 然后向左子树和右子树分别dfs,由于要以左子树节点和右子树节点为起点了,因此target值要减去root.val;
再说pathSum这个dfs:
- 先判断就以当前root为起点的路径,统计有多少条符合要求的路径;
然后在dfs左子树和右子树,主要pathSum不要求一定要以当前root为起点,当前root树中任意节点为起点都可以,这点是pathSum和rootSum的区别。
25.3 代码
class Solution {public int pathSum(TreeNode root, int targetSum) {if (root == null) {return 0;}int res = 0;res += rootSum(root, targetSum);res += pathSum(root.left, targetSum);res += pathSum(root.right, targetSum);return res;}// rootSum表示以root节点为起点,路径上节点之和为targetSum的所有路径的个数public int rootSum(TreeNode root, int targetSum) {if (root == null) {return 0;}int res = 0;if (root.val == targetSum) {++res;}res += rootSum(root.left, targetSum - root.val);res += rootSum(root.right, targetSum - root.val);return res;}}
26、543. 二叉树的直径
26.1 题目
给定一棵二叉树,你需要计算它的直径长度。一棵二叉树的直径长度是任意两个结点路径长度中的最大值。这条路径可能穿过也可能不穿过根结点。
示例 :
给定二叉树:1/ \2 3/ \4 5
返回 3, 它的长度是路径 [4,2,1,3] 或者 [5,2,1,3]。
26.2 思路
这道题其实是求二叉树深度的变种。
乍一看思路应该是:遍历二叉树中的每个节点,求以这个节点为根节点,value = 左子树高度 + 右子树高度 + 1,求遍历的每个节点对应的value的最大值;
- 因此题解主要还是求二叉树的深度,只不过需要维护一个成员变量res,求遍历每个节点时的value的最大值,res里时刻更新的是value的最大值;
需要边界条件的注意:
- 最后的解可能并不是过根节点的左右两个子树;
两结点之间的路径长度是以它们之间边的数目表示,即节点个数总和 - 1。
26.3 代码
class Solution {private int res;public int diameterOfBinaryTree(TreeNode root) {if (root == null) {return 0;}depth(root);return res - 1;}private int depth(TreeNode root) {if (root == null) {return 0;}int left = depth(root.left);int right = depth(root.right);if (left + right + 1 > res) {res = left + right + 1;}return Math.max(left, right) + 1;}}
27、面试题 04.06. 后继者
27.1 题目
设计一个算法,找出二叉搜索树中指定节点的“下一个”节点(也即中序后继)。如果指定节点没有对应的“下一个”节点,则返回null。
27.2 思路
本题还是用递归的思路。
如果root.val <= p.val,则p的后继节点一定在root的右子树中,因此对root的右子树递归查找p;
- 如果root.val > p.val,则p的后继节点可能在root的左子树中,也可能就是root节点本身,需要对左子树递归,得到递归后的结果,根据此结果进行判断:
- 如果递归结果不为null,则直接返回该结果,说明p的后继节点就在root左子树上的某一个节点;
- 如果递归结果为null,则没有在左子树中找到p的后继节点,则root本身就是p的后继节点。
27.3 代码
class Solution {public TreeNode inorderSuccessor(TreeNode root, TreeNode p) {if (root == null) {return null;}if (root.val <= p.val) {return inorderSuccessor(root.right, p);} else {TreeNode leftNode = inorderSuccessor(root.left, p);return leftNode == null? root: leftNode;}}}
28、104. 二叉树的最大深度
28.1 题目
给定一个二叉树,找出其最大深度。二叉树的深度为根节点到最远叶子节点的最长路径上的节点数。说明: 叶子节点是指没有子节点的节点。
示例:
给定二叉树 [3,9,20,null,null,15,7],
28.2 思路
跟求二叉树高度的代码很像,其实就是求左子树的最大深度和右子树最大深度的最大值再加一。28.3 代码
class Solution {public int maxDepth(TreeNode root) {if (root == null) {return 0;}return Math.max(maxDepth(root.left), maxDepth(root.right)) + 1;}}

若有收获,就点个赞吧
0 人点赞
