1、排序
1.1 快速排序
1.1.1 思想分析
快速排序(QuickSort)是对冒泡排序的一种改进。快速排序由C. A. R. Hoare在1962年提出。它的基本思想是:
- 从待排序数组中选取一个数为基准数,基准数一般为数组的首元素或者尾元素;
- 通过一趟快排将带排序数组分成两个子数组,其中左子数组的数据都比基准数小,右子数组的数据都比基准数大;
- 将左右子数组的分界线的index对应的元素用基准数填充;
-
1.1.2 过程演示
给定一个原始数组为:

开始时,我们首先选择第一个数作为基准pivot,并且设置两个指针left和right,指向数组的最左位置和最右位置:
从right位置开始和基准pivot比较,直到right对应的那个数比基准pivot小的时候停下;然后从left位置开始和基准pivot比较,直到left对应的那个数比基准pivot大的时候停下。因为right对应的1比4小,所以停下不动;left对应的是4没有大于4,所以向右移动,然后left对应的是7比4大,所以停下不动: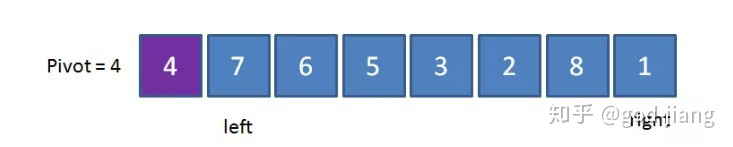
这时交换left和right的位置:
接下来继续重复刚才的过程,right向左移动到8比4大,继续移动到2,比4小,所以停下;然后left向右移动到6比4大,所以停下:
这时交换left和right的位置: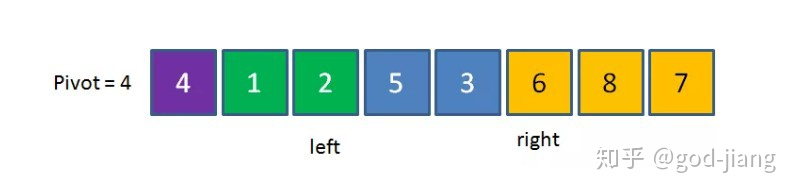
继续重复上面的过程,right向左移动到3比4小,所以停下;left向右移动到5比4大,所以停下: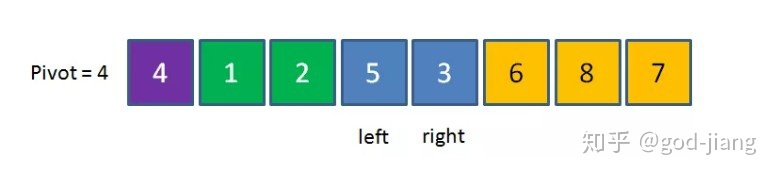
这时交换left和right的位置:
right向左移动和left指针重合,这个时候停下: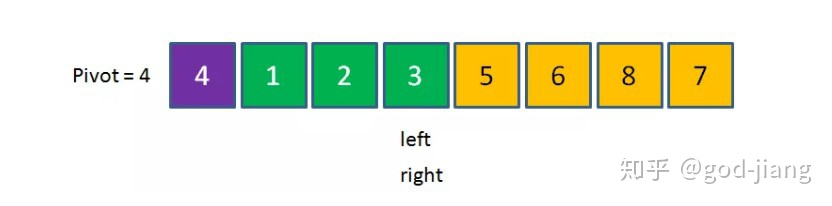
当left和right重合的时候,我们把pivot位置和left位置进行交换,这个时候就是一趟快排的结果,基准pivot的值是4,它的左边都比4小,它的右边都比4大: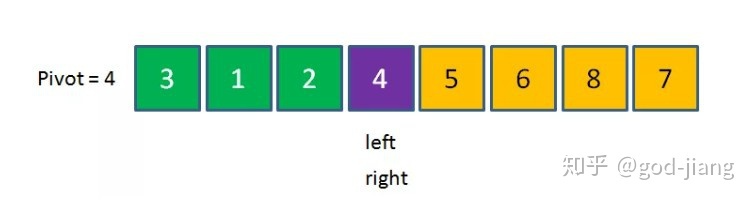
然后就通过分治递归的方法,分别对左边和右边继续刚才的过程,直到数组不能再分为止。1.1.3 代码实现
```java public class Sorter { public void quickSort(int[] nums) {
quickHelper(nums, 0, nums.length - 1);
}
private void quickHelper(int[] nums, int start, int end) {
// start == end对应待排序数组中仅有一个元素,start > end对应待排序数组中没有元素了if (start >= end) {return;}int pivot = partition(nums, start, end);quickHelper(nums, start, pivot - 1);quickHelper(nums, pivot + 1, end);
}
// 返回基准数在最终排序好的数组中的下标 private int partition(int[] nums, int start, int end) {
int left = start, right = end;// 基准数选取当前子数组的首元素int pivot = nums[start];while (left < right) {// 注意这里内层while循环也要加上left < right的判断,且nums[right]和nums[left]与pivot比较是>=和<=while (left < right && nums[right] >= pivot) {--right;}while (left < right && nums[left] <= pivot) {++left;}swap(nums, left, right);}// 第一轮完成,让left和right重合的位置(left)和基准(start)交换,返回基准的位置swap(nums, start, left);return left;
}
private void swap(int[] nums, int i, int j) {
int tmp = nums[i];nums[i] = nums[j];nums[j] = tmp;
} }
<a name="iPGgd"></a>### 1.1.4 复杂度分析<a name="GOto0"></a>#### 1.1.4.1 时间复杂度经过上述一趟快速排序,我们只确定了一个元素的最终位置,我们最终需要经过n趟快速排序才能将一个含有  个数据元素的序列排好序,下面我们来分析其时间复杂度.<br />设  为待排序数组中的元素个数,  为算法需要的时间复杂度,则<br /> <br />其中  ,是一趟快排需要的比较次数,一趟快排结束后将数组分成两部分  和 。<br />**(1)最好时间复杂度**:<br />核心点:最好情况下,每一次划分都正好将数组分成长度相等的两半:<br /><br /><br />**(2)最坏时间复杂度**<br />核心点:最坏情况下,每一次划分都将数组分成了0和n-1两部分,在这种情况下,每次都只能得到比上一次少1个数的子序列(即要么全比基准数大,要么全比基准小):<br /><br /><br />**(3)平均时间复杂度**<br />证明过程太过复杂,结论是:<br /><a name="eBkrx"></a>#### 1.1.4.2 空间复杂度空间的消耗主要是递归造成的栈空间使用。<br />**(1)最好空间复杂度**:<br />最好情况下,需要进行log2n次递归调用,因此最好空间复杂度为log2n。<br />**(2)最坏空间复杂度**<br />最坏情况下,每次都只能得到比上一次少1个数的子序列,需要进行n - 1次递归调用,因此最坏空间复杂度为O(n)。<br />**(3)平均空间复杂度**<br />平均情况,空间复杂度也为O(logn)。<a name="rDTIv"></a>## 1.2 归并排序> 参考题解:[剑指 Offer 51. 数组中的逆序对](https://leetcode-cn.com/problems/shu-zu-zhong-de-ni-xu-dui-lcof/)<a name="Fur9u"></a>### 1.2.1 思想分析归并排序体现了 “分而治之” 的算法思想,具体为:1. **分**: 不断将数组从中点位置划分开(即二分法),将整个数组的排序问题转化为子数组的排序问题;1. **治**: 划分到子数组长度为 1 时,开始向上合并,不断将 较短排序数组 合并为 较长排序数组,直至合并至原数组时完成排序。如下图所示,为数组 [7, 3, 2, 6, 0, 1, 5, 4][7,3,2,6,0,1,5,4] 的归并排序过程:<br />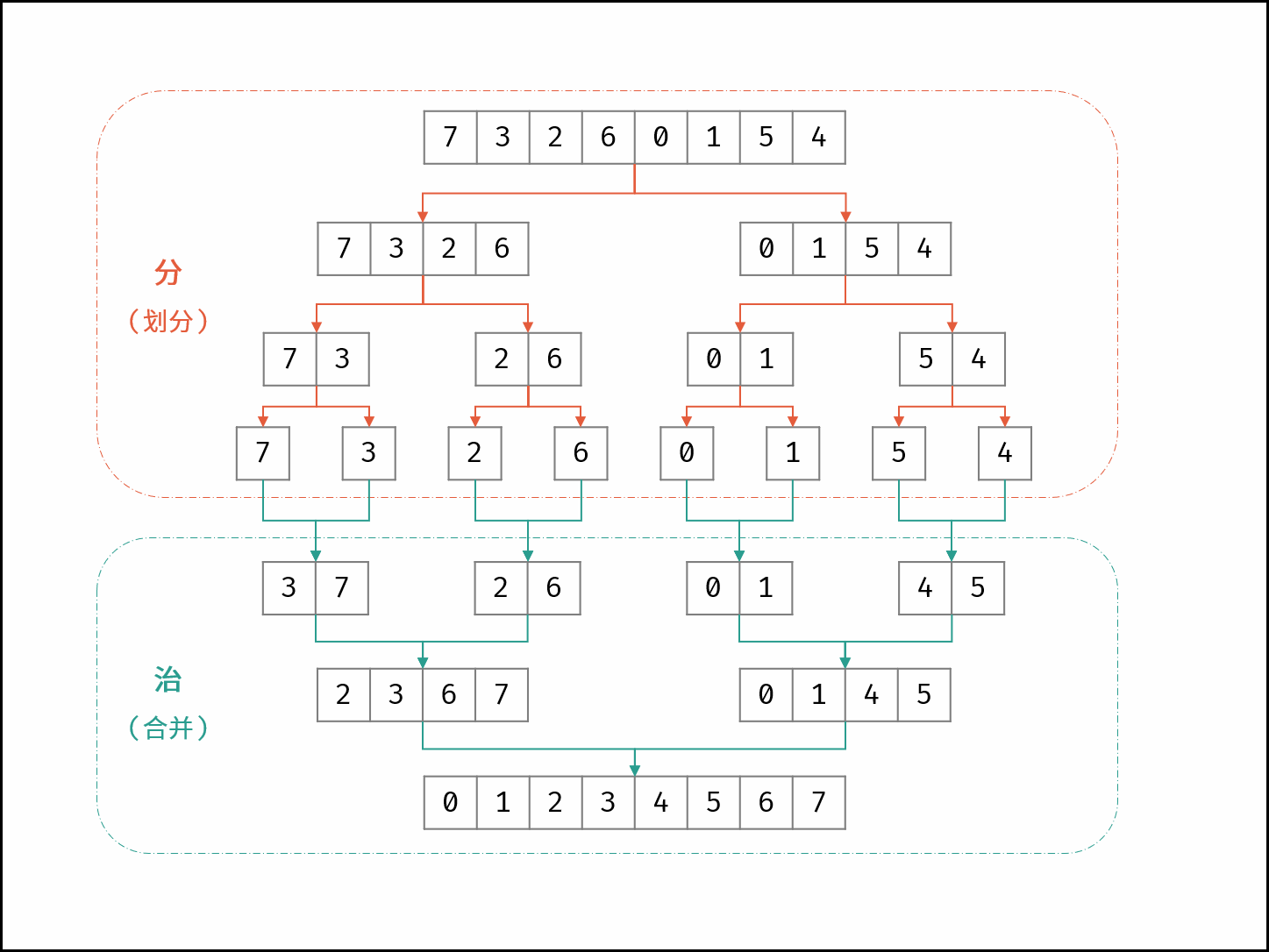<a name="QpKhQ"></a>### 1.2.2 过程演示上面的图就很清晰了。先从上到下分,再从下到上治(排序)。<a name="W9sAX"></a>### 1.2.3 代码实现```java/*** @Description:* @Author: Jerry* @Date: 2022-04-05 17:35*/public class Sort {public void mergeSort(int[] nums) {merge(nums, 0, nums.length - 1);}private void merge(int[] nums, int left, int right) {if (left == right) {return;}if (left < right) {int mid = (left + right) >> 1;merge(nums, left, mid);merge(nums, mid + 1, right);mergeSortTwoArrays(nums, left, right, mid);}}private void mergeSortTwoArrays(int[] nums, int left, int right, int mid) {int[] tmpArray = new int[right - left + 1];int leftIdx = left, rightIdx = mid + 1, tmpIdx = 0;while (leftIdx <= mid && rightIdx <= right) {if (nums[leftIdx] <= nums[rightIdx]) {tmpArray[tmpIdx++] = nums[leftIdx++];} else {tmpArray[tmpIdx++] = nums[rightIdx++];}}while (leftIdx <= mid) {tmpArray[tmpIdx++] = nums[leftIdx++];}while (rightIdx <= right) {tmpArray[tmpIdx++] = nums[rightIdx++];}if (tmpArray.length >= 0) {System.arraycopy(tmpArray, 0, nums, left, tmpArray.length);}}}
1.2.4 复杂度分析
1.2.4.1 时间复杂度
设  为待排序数组中的元素个数,
为待排序数组中的元素个数,  为算法需要的时间复杂度,则
为算法需要的时间复杂度,则

其中  是将两个含有
是将两个含有  个数据元素的序列合并为一个含有
个数据元素的序列合并为一个含有  个数据元素的序列所需要的比较操作次数
个数据元素的序列所需要的比较操作次数
(1)最优时间复杂度
由对合并操作的最优时间复杂度分析我们知道,当刚好一个序列的最后一个值是另一个序列的最小值时, 

(2)最坏时间复杂度
由对合并操作的最坏时间复杂度分析我们知道,当两个序列各个元素的大小交叉排列时,

1.2.4.2 空间复杂度
 ,需要一个额外的n维数组
,需要一个额外的n维数组 
2、二分查找
2.1 二分查找基础版
2.1.1 题目
给定一个 n 个元素有序的(升序)整型数组 nums 和一个目标值 target ,写一个函数搜索 nums 中的 target,如果目标值存在返回下标,否则返回 -1。
示例 1:
输入: nums = [-1,0,3,5,9,12], target = 9 输出: 4 解释: 9 出现在 nums 中并且下标为 4
示例 2:
输入: nums = [-1,0,3,5,9,12], target = 2 输出: -1 解释: 2 不存在 nums 中因此返回 -1
LC链接:704. 二分查找
2.1.2 思路
2.1.3 代码
public class BinarySearcher {public int binarySearch(int[] nums, int target) {int left = 0, right = nums.length - 1;while (left <= right) {int mid = (left + right) >> 1;if (nums[mid] > target) {right = mid - 1;} else if (nums[mid] < target) {left = mid + 1;} else {return mid;}}return -1;}}
- 时间复杂度:O(lgn);
- 空间复杂度:O(lgn)。
2.2 有重复元素的二分查找
3、位运算
计算机中的数在内存中都是以二进制形式进行存储的,用位运算就是直接对整数在内存中的二进制位进行操作,因此其执行效率非常高,在程序中尽量使用位运算进行操作,这会大大提高程序的性能。3.1 按位与或
- & 与运算 两个位都是 1 时,结果才为 1,否则为 0,如
1 0 0 1 1
& 1 1 0 0 1
———————————————
1 0 0 0 1 - | 或运算 两个位都是 0 时,结果才为 0,否则为 1,如
1 0 0 1 1
| 1 1 0 0 1
———————————————
1 1 0 1 1
(1)按位与判断奇偶
if(0 == (a & 1)) {// 偶数} else {// 奇数}
(2)按位与求余数
前提:取余运算符右边的数是2的n次方。
x % 2 ^ n = x & (2 ^ n - 1)
(3)按位与判断二进制中的1
有时需要判断一个数的二进制哪一位是1,有多少个1,此时可以用按位与和无符号右移运算符(n是无符号数)。
int cnt = 0;while (n != 0) {cnt += (n & 1);n = n >>> 1;}return cnt;
3.2 按位异或
^ 异或运算,两个位相同则为 0,不同则为 1,如
1 0 0 1 1
^ 1 1 0 0 1
——————————————-
0 1 0 1 0
按位异或有3条重要性质:
- 对于任意整数 a,有 a ⊕ a = 0;
- 对于任意整数 a,有 a ⊕ 0 = 0 ⊕ a = a;
- 异或运算满足交换律,即 a ⊕ b = b ⊕ a。
拓展:设整型数组 nums 中出现一次的数字为 x ,出现两次的数字为 a, a, b, b, …,即:nums = [a, a, b, b, …, x],
若将 nums 中所有数字执行异或运算,留下的结果则为出现一次的数字 x,即:a ⊕ a ⊕ b ⊕ b ⊕…⊕ x = x。
3.3 移位运算符
移位运算符分类如下:
- 左移运算符;
- 右移运算符;
- 无符号左移运算符;
- 无符号右移运算符。
其中左移运算符和右移运算符都可以理解成有符号移位运算符,左移运算符和无符号左移运算符效果是一样的,但右移运算符和无符号右移运算符效果是不一样的。
// 有符号左移1位a << 1;// 有符号右移1位a >> 1;// 无符号左移1位a <<< 1;// 无符号右移1位a >>> 1;
学习本节前,需要学习一下二进制相关知识,比如有符号无符号,补码反码等。
3.3.1 有符号移位运算符
3.3.1.1 左移运算符
左移运算符的效果:低位补0,高位可能由于符号位数字改变,会由原来的正数左移成负数。
举一个int类型的数字733183670为例,说明一下左移运算符的效果。
Java中int类型中数据占32bit位。
十进制的733183670数字,转换成二进制如下:
左移1位,相当于733183670 2 = 1466367340,如下:
左移8位,变成-1283541504,首位符号位由0变为1,因此在使用左移运算符时要注意变成负数的情况,如下:
根据这个规则,左移32位后,右边补上32个0值是不是就变成了十进制的0了?答案是NO,当int类型进行左移操作时,*左移位数大于等于32位操作时,会先求余(%)后再进行左移操作。也就是说左移32位相当于不进行移位操作,左移40位相当于左移8位(40%32=8)。当long类型进行左移操作时,long类型在二进制中的体现是64位的,因此求余操作的基数也变成了64,也就是说左移64位相当于没有移位,左移72位相当于左移8位(72%64=8)。
以上都是介绍的int类型数据的左移操作,对于其他数据类型,左移操作如下:
- 由于double,float在二进制中的表现比较特殊,因此不能来进行移位操作,编译报错;
其它几种整形byte,short移位前会先转换为int类型(32位)再进行移位。
3.3.1.2 右移运算符
右移运算符的效果:高位补符号位数字,即正数补0,负数补1,低位丢弃,每一位依次右移。
还是int型数字:733183670,二进制如下:

右移1位,变为366591835,即733183670 / 2 = 366591835,如下: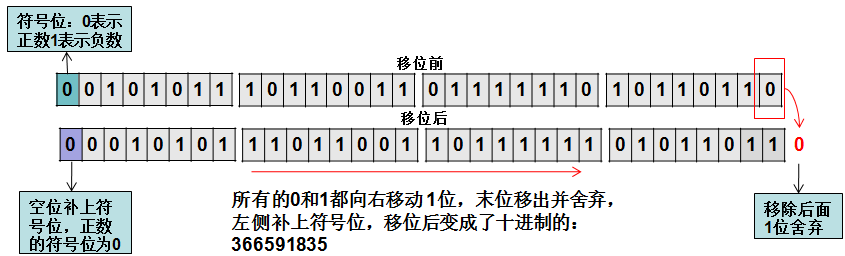
右移8位,变为2863998,如下:
上面介绍的是正数的有符号右移,负数的有符号右移如下:
-733183670的二进制如下:
-733183670有符号右移,高位补1,如下: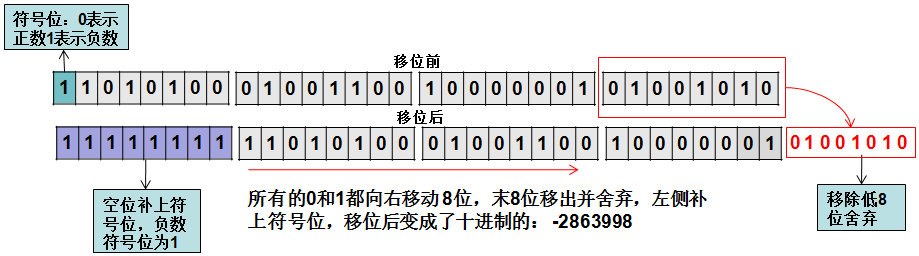
3.3.2 无符号移位运算符
3.3.2.1 无符号左移运算符
无符号左移跟有符号左移的效果完全一样。
3.3.2.2 无符号右移运算符
无符号右移效果:不论正数负数,高位通通补0,低位依次右移丢弃。
无符号右移和有符号右移的最大区别是:有符号右移,高位补符号位数字,即正数补0,负数补1;而无符号右移,不论正数负数,高位通通补0。
以-733183670 >>> 8 = 13913217为例,如下图: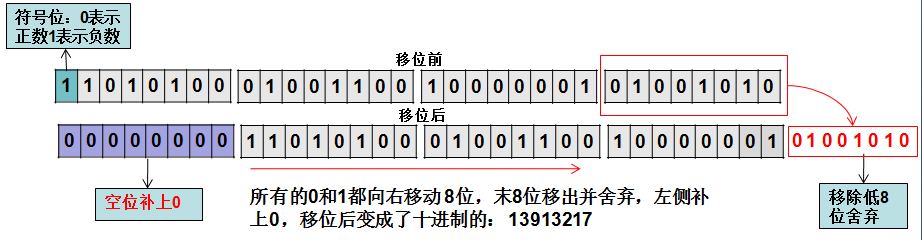
无符号右移,负数会变成正数。4、树
树这种数据结构刷算法题的时候经常遇到二叉树的题目,当然树这种数据结构也有实际应用,比如InnoDB存储引擎的索引的数据结构就是B+树、JDK 1.8中的HashMap底层数据结构引入了红黑树。
4.1 树的基本结构
树是一种非线性的具有层次关系的数据结构。把它叫做“树”是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶子朝下的。下图是树的示意图:

根据上图介绍一下树的基本术语:子树:上图中以B为根节点的子树称为A节点的左子树,以C为根节点的子树称为A节点的右子树;
- 父节点:B节点是以D为根节点的树的父节点;
- 根节点:在一棵树中没有父节点的节点称为根节点,根节点可以代表一棵树,上图中的A即为树的根节点;
- 叶子节点:左右子树均为null的节点称为叶子节点;
- 节点的度:节点拥有的子树的数目称为节点的度,上图中A的度为2,B的度为1,D的度为0;
- 层次:从一个树的根节点到叶子节点,从上至下的层数依次加一,根节点对应的层数为1,以此类推;
- 树的高度:树的最大层次称为树的高度,上图中A为根节点的数的高度为3。
4.2 二叉树
二叉树是最常见的树的种类之一,树可以是多叉树,只是二叉树被人谈起的最多。二叉树是树中节点的度最大为2的树,如下图所示:
二叉树的性质:

4.2.1 满二叉树
对于一棵二叉树,非叶子节点的度均为2的二叉树叫做满二叉树,满二叉树的结构如下图所示: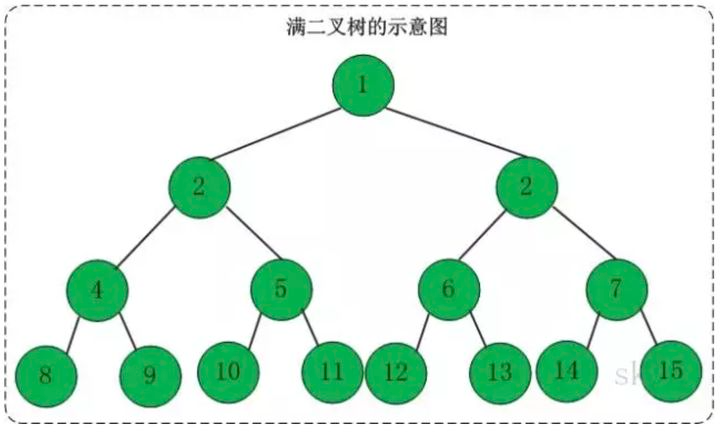
满二叉树除了满足普通二叉树的性质,还具有以下性质:
- 满二叉树中第 i 层的节点数为 2n-1 个。
- 深度为 k 的满二叉树必有 2k-1 个节点 ,叶子数为 2k-1。
- 满二叉树中不存在度为 1 的节点,每一个分支点中都两棵深度相同的子树,且叶子节点都在最底层。
-
4.2.2 完全二叉树
对于一棵二叉树,只有最下层和次下层的节点的度可以小于2,且最下层的叶子节点集中在树的左部的二叉树叫完全二叉树,完全二叉树如下图所示:
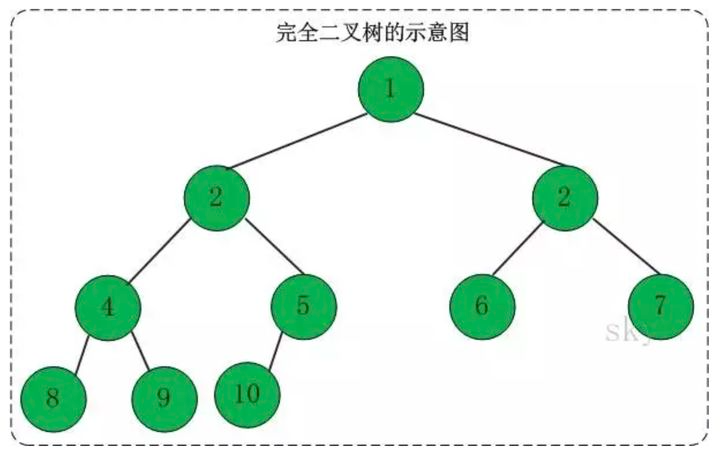
一棵满二叉树必定是一棵完全二叉树,而完全二叉树未必是满二叉树。堆这种数据结构就是一棵特殊的完全二叉树,因此完全二叉树在堆排序方面有应用。4.3 二叉搜索树
4.3.1 二叉搜索树的定义
二叉搜索树英文是Binary Search Tree,简称BST。二叉搜索树是一棵特别的二叉树,二叉搜索树的特点是:左子树上的所有节点都比父节点小,右子树上的所有节点都比父节点大,且左右子树也是二叉搜索树。二叉搜索树如下图所示:
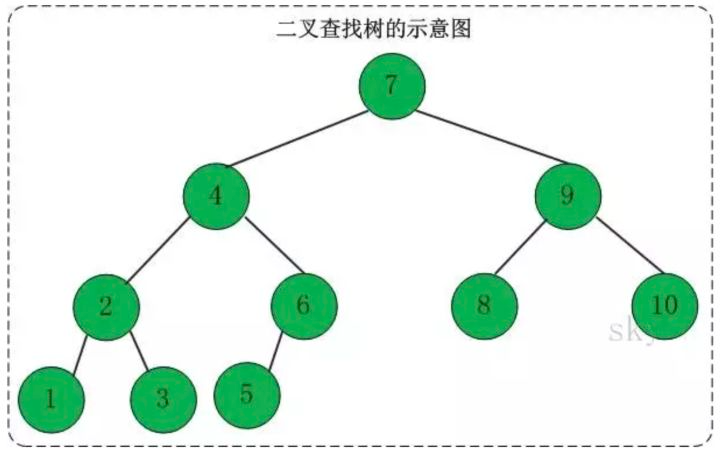
在上图中以根节点7为例,左子树(以4为根节点)上的所有节点都小于7,右子树(以9为根节点)上的所有节点都大于7,且左子树和右子树本身也是一棵二叉搜树。4.3.2 二叉搜索树的应用
二叉搜索树在排序、查找中应用广泛。以在一个升序数组中查找某一个元素为例介绍,如果是链表的结构,则如下图:

假如要查找值为8的元素,则需要依次遍历链表中的1、2、3、4、5、6、7、8这8个节点才能找到8,时间复杂度是O(n)。
如果把上面的链表转换为二叉搜索树,如下图所示: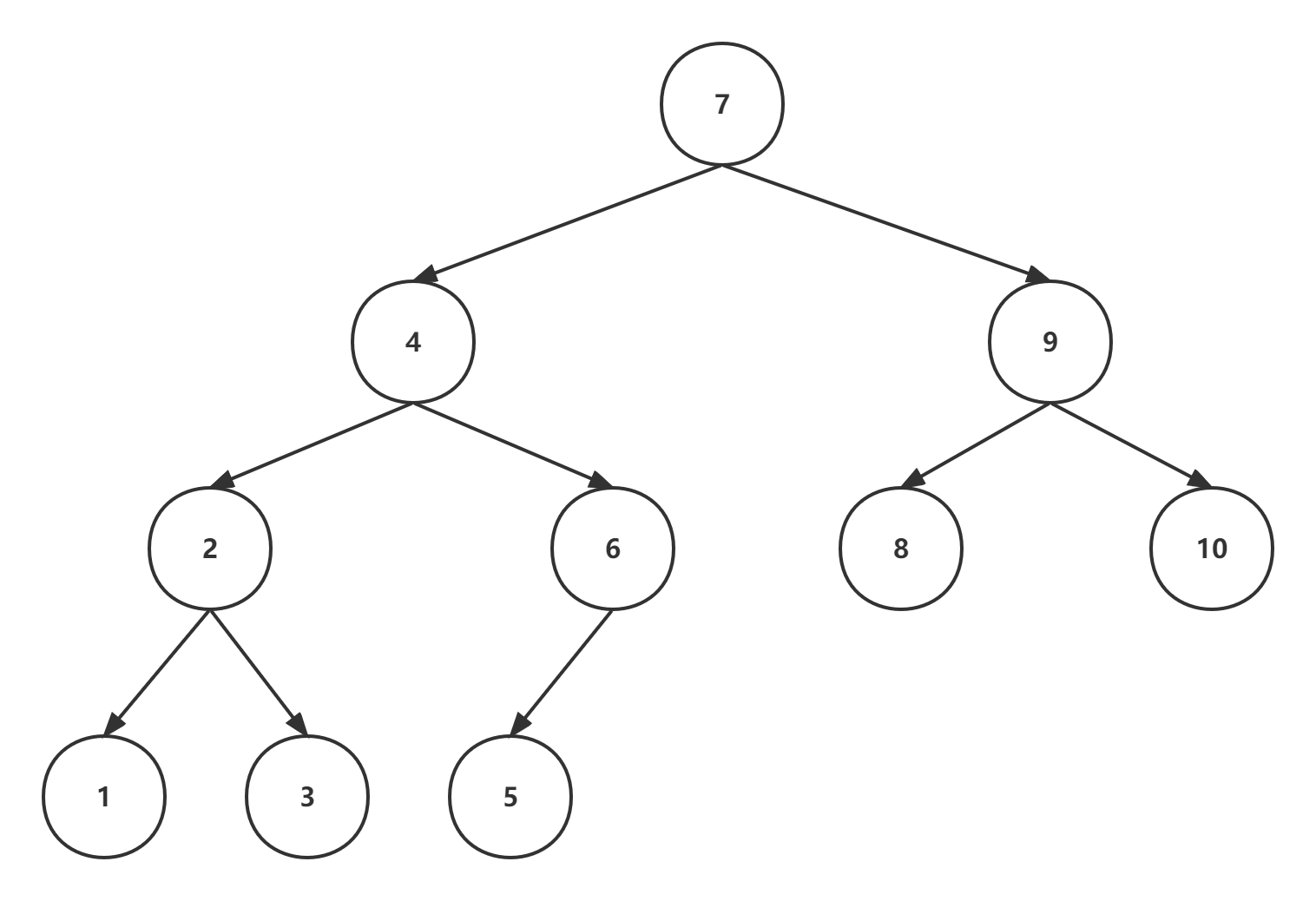
则查找8只需遍历7、9、8三个节点,在查找过程中我们会比较8这个节点与当前节点的值,如果8大于当前节点值,则从节点的右子树继续dfs,如果8小于当前节点值,则从节点的左子树继续dfs,如果8等于当前节点值,直接返回,由于是二叉树,因此基于二叉搜索树的查找实质上是二分查找的实现,查找的时间复杂度是O(lgn)。4.3.3 二叉搜索树的极端情况
根据一个排序序列并不能确认唯一一个二叉搜索树,在某些极端情况下,二叉搜索树会退化成一个单链表,如下图所示,与4.3.2中的二叉搜索树一样均满足排序序列1-10:

上述也是一棵二叉搜索树,且满足升序序列1-10,然后此时二叉搜索树已经退化成一个单链表,比如查找元素1,要一次遍历9-1这9个节点,查询的时间复杂度又变成了O(n)。
可想而知,我们还是想让二叉搜索树称为4.3.2中的那样,查询时间复杂度能满足O(lgn),为了解决这个问题,我们提出了平衡二叉树的概念。4.4 平衡二叉树
平衡二叉树英文是Self-Balancing Binary Search Tree,又叫AVL树。平衡二叉树就是为了解决二叉搜索树退化成单链表而产生的,平衡二叉树的特点:
首先是一棵二叉搜索树;
- 每个节点的左子树和右子树的高度差不超过1。
4.3中的二叉搜索树对应的平衡二叉树如下图所示: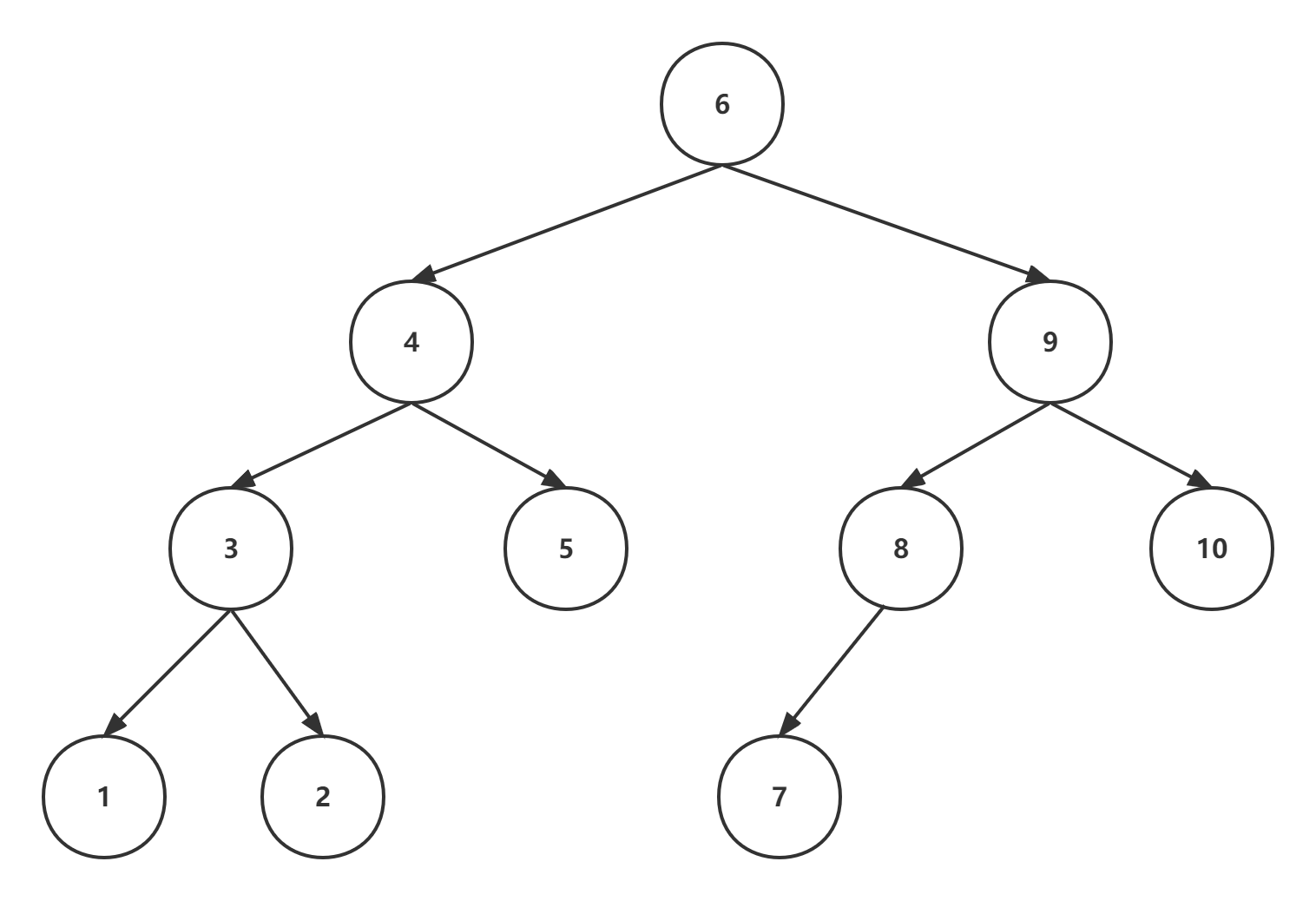
平衡二叉树基于“每个节点的左子树和右子树的高度差不超过1”这个特点就可以保证不会出现大量节点偏向于一边的情况了,避免二叉搜索树退化成单链表。对于有 n 个节点的平衡树,查找时间复杂度也为 O(logn)。
平衡二叉树在插入、删除元素时,为了维持平衡二叉树的特点(尤其是“每个节点的左子树和右子树的高度差不超过1”这个特点),会不断地通过左旋、右旋操作维持这种状态,也是需要付出维护代价的。关于平衡二叉树如何构建、插入、删除、左旋、右旋等操作,放在后续研究,请参考:【漫画】以后在有面试官问你AVL树,你就把这篇文章扔给他。
4.5 红黑树
红黑树英文名称是Red Black Tree,简称RBT。虽然平衡二叉树解决了二叉搜索树退化成单链表的缺点,能够把查询的时间复杂度控制在 O(logn),不过却不是最佳的,因为二叉平衡树要求左右子树的高度之差不超过1,每次进行插入删除操作的时候,几乎都会破坏平衡二叉树的这一结构,因此需要频繁地进行左旋和右旋,使之保持平衡二叉树这一结构。
为了解决平衡二叉树频繁左旋右旋降低性能这一问题,提出了红黑树,红黑树有以下特点:
- 具有二叉搜索树的所有特点;
- 根节点是黑色的;
- 每个叶子节点都是黑色的,且叶子节点不存放数据(null);
- 任何相邻的节点都不能同时为红色;
- 对于每个节点,从该节点到达其可以到达的所有叶子节点上的路径,黑色节点的数目相同。
红黑树如下图所示,图中黑色的、空的叶子节点没有画出: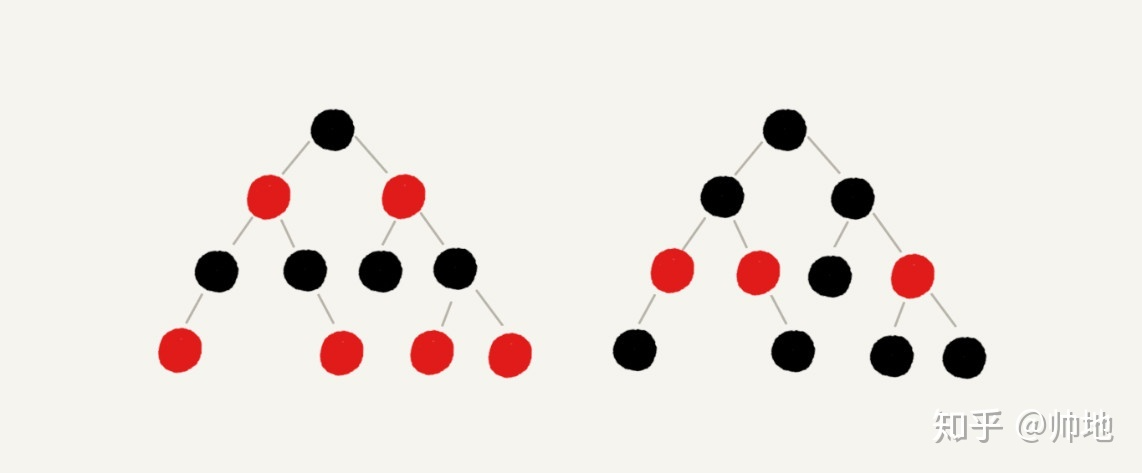
红黑树的增、删、改、查的时间复杂度均为 O(logn),与平衡二叉树相比,红黑树不会频繁地破坏红黑树的规则,也就是说不需要频繁地调整结构维持红黑树。平衡二叉树是为了解决二叉搜索树退化为链表的情况,而红黑树是为了解决平衡二叉树在插入、删除等操作需要频繁调整的情况。
红黑树的详细的增、删、改、插操作见这篇文章:一文带你彻底读懂红黑树(附详细图解)
参考
神级基础排序——快速排序
快速排序时间复杂度分析
归并排序时间复杂度分析
为什么二分查找的时间复杂度是 logN
二分查找细节详解
Java中的>>,>>>
Java中的移位运算符
通俗易懂讲解 二叉搜索树
记一次腾讯面试:有了二叉查找树、平衡树(AVL)为啥还需要红黑树?

若有收获,就点个赞吧
0 人点赞
