TTS-文字转语音
可以通过提示词模拟语气停顿、笑声、叹息、背景音乐等
GitHub - suno-ai/bark: 🔊 Text-Prompted Generative Audio Model
声音克隆
GPT-SoVITS/docs/cn/README.md at main · RVC-Boss/GPT-SoVITS
集样本预处理、训练与预测于一体,只需要1分钟的语音样本即可克隆声音。
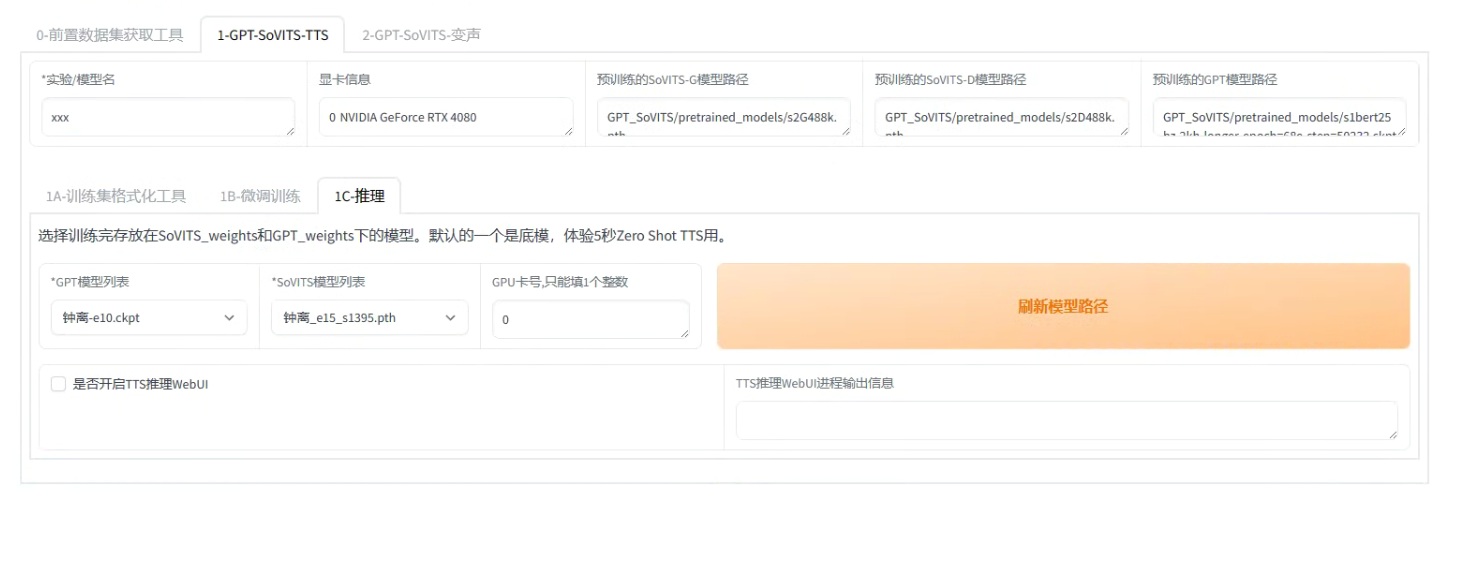
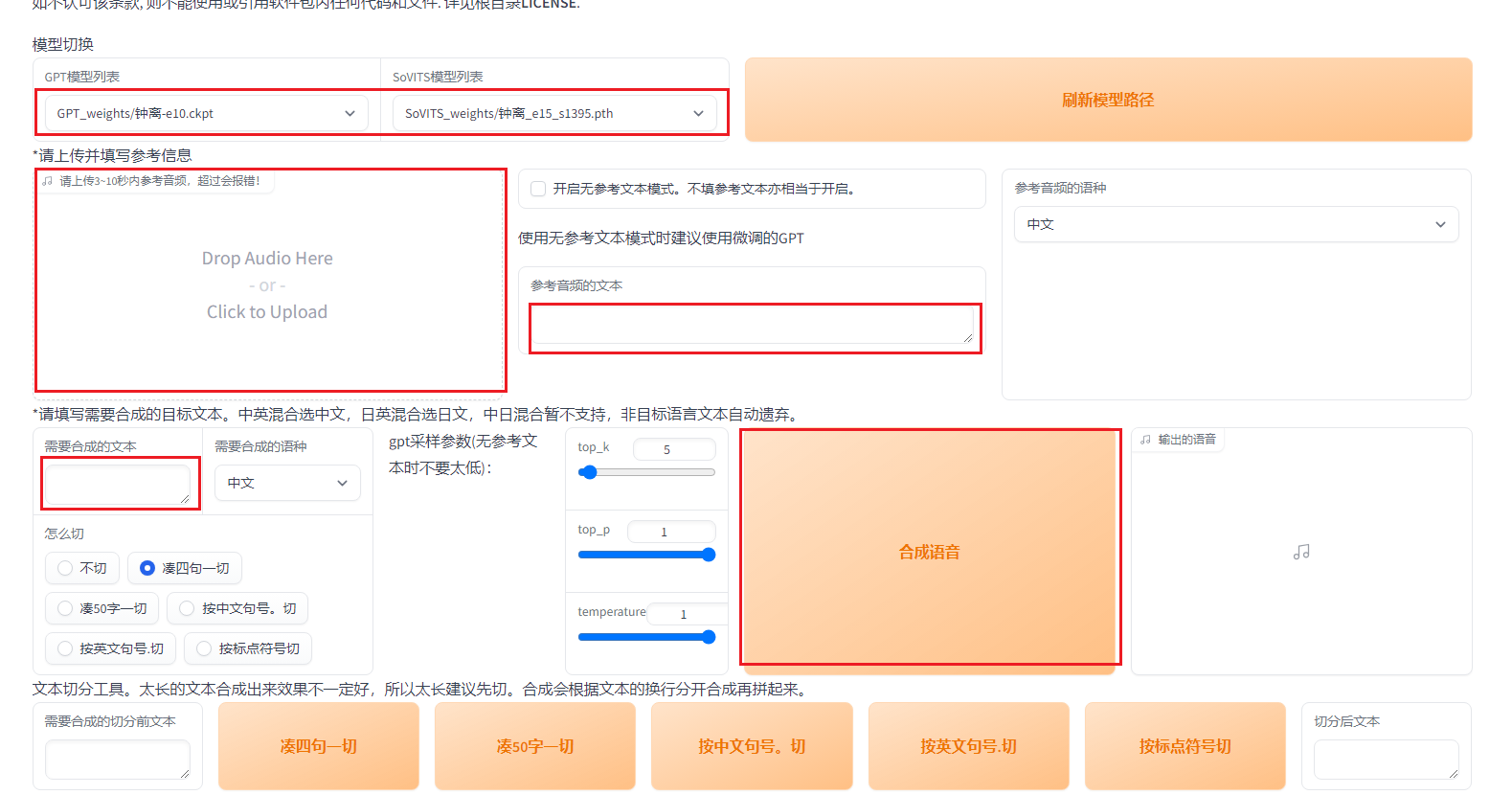
钟离先生不在这里,多少有些可惜,他是位相当懂行的观众,又欣赏得来辛焱的演出….wav
语音转文字
openAI开源,必属精品,业内最强开源模型
GitHub - openai/whisper: Robust Speech Recognition via Large-Scale Weak Supervision
桌面版Whisper:
很好用,之前老婆要学习一个很长的课程,要交作业。直接将视频转为音频,再将音频通过这个工具转成了文字,然后再使用大模型对文字进行思维导图总结,一份完美的作业就好了。
GPU 版
https://github.com/Const-me/Whisper)
通过[此处]下载模型
实测即使是我的 4080,在使用 [ggml-large-v3.bin]模型跑任务也超级慢。用次一级的 [ggml-medium.bin] 速度和效果都还不错
CPU 版
https://github.com/chidiwilliams/buzz)
使用时会下载对应的模型,有时候网络问题导致下载失败,可以通过【help->Preferences->models】进行单独下载
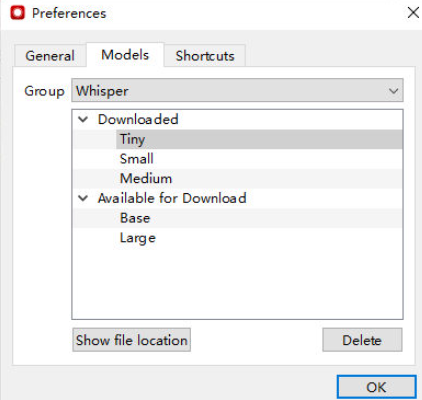
由于是 cpu 版,medium 模型就已经很慢了

若有收获,就点个赞吧
0 人点赞
