1.分库分表的相关术语
读写分离:不同的数据库,同步相同的数据,分别只负责数据的读和写。
分区:指定分区列表表达式,把记录拆分到不同的区域中(必须是同一台服务器,可以是不同的硬盘),应用看来还是同一张表,没有变化;
分库:一个系统的多张数据表,存储到多个数据库实例中;
分表:对于一张多行(记录)多列(字段)的二维数据表,分两种:
- 垂直分表:竖向切分,不同分表存储不同的字段,可以吧不常用或大容量、或者不同业务的字段拆分出去;
- 水平分表(最复杂的):横向切分,按照特定分片算法,不同分表存储不同的记录;
垂直分表:将一个表按照字段分成多表,每个表存储其中一部分字段。(热数据和冷数据的区分,不会改变数据量)
垂直分库:指按照业务将表进行分类,分布到不同的数据库上面,每个库可以放在不同的服务器上,其核心理念是专库专用。
水平分库:是把同一个表的数据按一定会规则拆分到不同的数据库中,每个库可以放到不同的服务器上。
水平分表:在同一个数据库内,把同一个表的数据按一定规则拆分到多个表中。
逻辑表:进行水平拆分的时候同一类型的表的总称。如两张表tab_user_0和tab_user_1,他们的逻辑表名为tab_user。
真实表:在分片的数据库中真实存在的物理表。如:tab_user_0和tab_user_1。
数据节点:数据分片的最小单元,由数据源名称和数据表组成。如:db_0.tab_user_0或db_0.tab_user_1、db_1.tab_user_0或db_1.tab_user_1。
动态表:逻辑表和物理表不一定需要在配置规则中静态配置。如,按照日期分片的场景,物理表的名称随着时间会产生变化。
广播表(公共表):指所有的分片数据源中都存在的表,表结构和表中的数据在每个数据库中完全一致。适用于数据量大且需要与海量数据的表进行关联查询的场景,如:字典表。
绑定表:指分片规则一致的主表和子表。例如:t_order表和t_order_item表,均按照order_id分片,则此两张表互为绑定表关系。绑定表之间的多表关联查询不会出现笛卡尔积关联,关联查询效率将大大提升。
2.分库分表存在什么样的问题?在什么情况下才会采用它?
存在的问题:1)事务一致性的问题;2)跨节点关联查询;3)跨节点分页、排序函数;4)主键避重;5)公共表
分库分表会为数据库维护和业务逻辑带来一系列复杂性和性能损耗,除非预估的业务量大到万不得已,切莫过过度设计,过早优化。
当前数据量如果没有达到几百万,通常无需分库分表;
数据量的问题,可以通过增加磁盘或增加分库(不同的业务的功能表,整表拆分至不同的数据库);
性能的问题,升级CPU/内存、读写分离、优化数据库系统配置、优化数据表/索引、优化SQL、分区、数据表的垂直切分;
**
3.shardingJDBC的执行原理是什么?
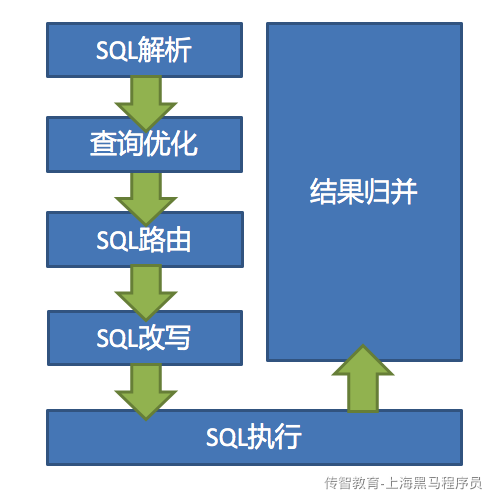
SQL解析
分为词法解析和语法解析。 先通过词法解析器将SQL拆分为一个个不可再分的单词。再使用语法解析器对SQL进行理解,并最终提炼出解析上下文。 解析上下文包括表、选择项、排序项、分组项、聚合函数、分页信息、查询条件以及可能需要修改的占位符的标记。
执行器优化
合并和优化分片条件,如OR等。
SQL路由
根据解析上下文匹配用户配置的分片策略,并生成路由路径。目前支持分片路由和广播路由。
SQL改写
将SQL改写为在真实数据库中可以正确执行的语句。SQL改写分为正确性改写和优化改写。
SQL执行
通过多线程执行器异步执行。
结果归并
将多个执行结果集归并以便于通过统一的JDBC接口输出。结果归并包括流式归并、内存归并和使用装饰者模式的追加归并这几种方式。
4.在你们的项目中shardingJDBC是如何使用的?
XA事务使用shardingJDBC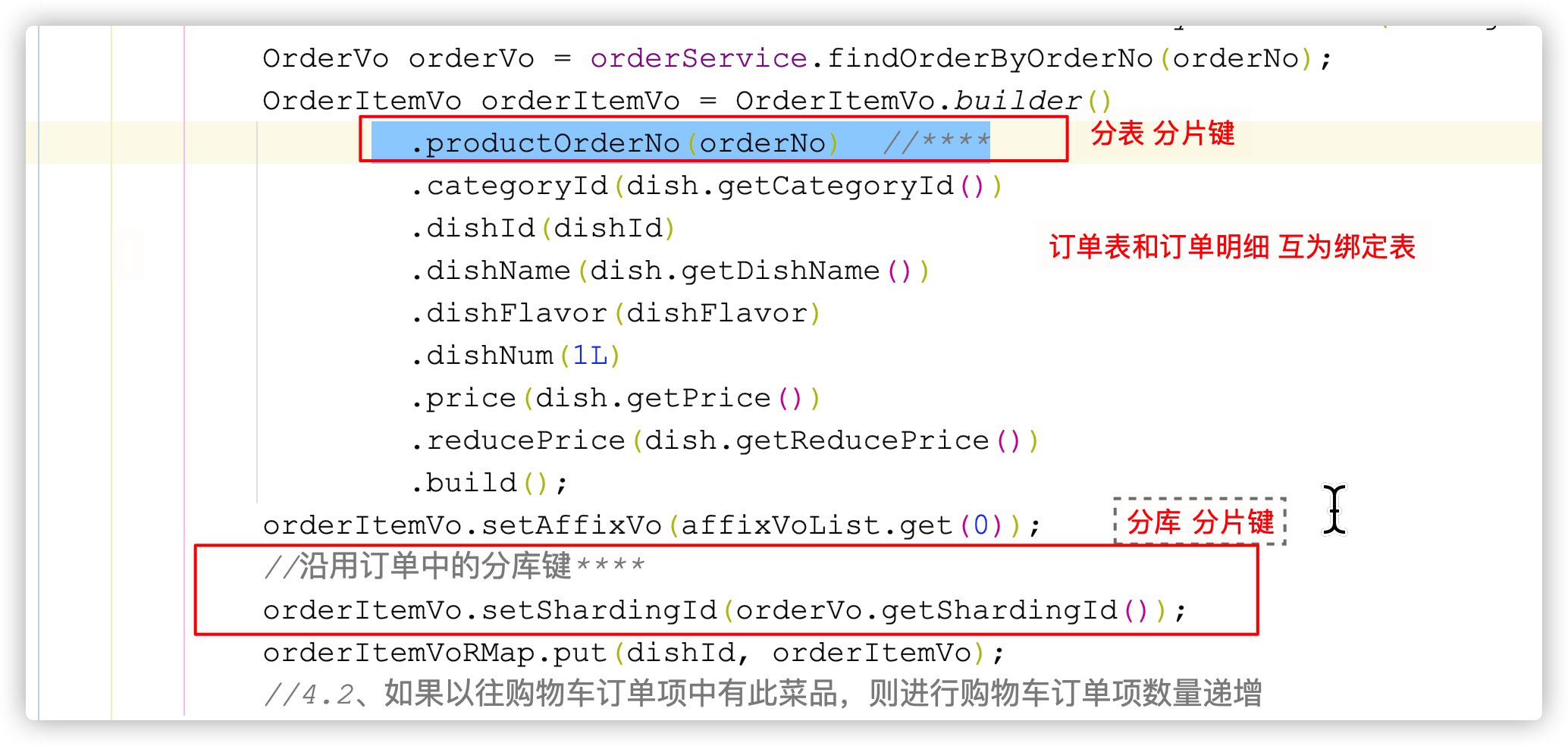
1.分库字段和分表字段如何确定?
1)在设计表结构的时候,会增加一个sharding_id的字段,这是一个分库键,这个字段保证订单表和订单明细表使用的是同一个值:保证分库算法一致
2)在tab_order和tab_order_item两张表中,因为它两是绑定表关系,并且都有order_no以这个字段作为分表字段,有分表字段可以有效消除笛卡尔积问题。保证分表算法一致。
sharding_id和order_no在分库分表时值是对应的,保证两个表的数据是落在同一个库的同一个表中。
2.创建模块framework-sharding-jdbc
3.framework-sharding-jdbc模块引依赖:
<dependencies><!-- 使用XA事务时,需要引入此模块,sharding的本地刚性事务 --><dependency><groupId>org.apache.shardingsphere</groupId><artifactId>sharding-transaction-xa-core</artifactId></dependency><!-- 使用BASE事务时,需要引入此模块分布式事务的柔性事务 --><dependency><groupId>org.apache.shardingsphere</groupId><artifactId>sharding-transaction-base-seata-at</artifactId></dependency><!-- sharding-jdbc --><dependency><groupId>org.apache.shardingsphere</groupId><artifactId>sharding-jdbc-spring-boot-starter</artifactId></dependency></dependencies>
注意:XA事务和BASE事务,两者根据实际情况选择,没有远程调用选XA事务,有远程调用选BASE事务。当引入shardingJDBC后,事务就由seata交给shardingJDBC管理了,所以需要移除seata的依赖。
在model-shop-applet模块引入依赖:
<dependency><groupId>com.itheima.restkeeper</groupId><artifactId>model-security-service</artifactId><exclusions><exclusion><artifactId>druid-spring-boot-starter</artifactId><groupId>com.alibaba</groupId></exclusion></exclusions></dependency><!--sharding-JDBC 必须使用原生的druid,排除druid-spring-boot-starter--><dependency><groupId>com.itheima.restkeeper</groupId><artifactId>model-shop-service</artifactId><exclusions><exclusion><groupId>com.alibaba</groupId><artifactId>druid-spring-boot-starter</artifactId></exclusion></exclusions></dependency><!--使用XA事务,则必须移除seata-at依赖--><dependency><groupId>com.itheima.restkeeper</groupId><artifactId>framework-sharding-jdbc</artifactId><exclusions><exclusion><groupId>org.apache.shardingsphere</groupId><artifactId>sharding-transaction-base-seata-at</artifactId></exclusion></exclusions></dependency>
4.在model-shop-applet模块的resources文件夹下添加配置application.yml
#服务配置server:#端口port: 7079#服务编码tomcat:uri-encoding: UTF-8#spring相关配置spring:main:allow-bean-definition-overriding: trueredis:redisson:config: classpath:singleServerConfig.yaml#redis配置信息host: 192.168.200.129port: 6379password: passjta:atomikos:properties:log-base-dir: logs/model-shop-applet-atomikoslog-base-name: model-shop-applet#数据源配置shardingsphere:datasource:names: ds0,ds1ds0:type: com.alibaba.druid.pool.DruidDataSourcedriverClassName: com.mysql.jdbc.Driverurl: jdbc:mysql://192.168.200.129:3306/restkeeper-shop-0?serverTimezone=UTC&useUnicode=true&characterEncoding=utf8username: rootpassword: passds1:type: com.alibaba.druid.pool.DruidDataSourcedriverClassName: com.mysql.jdbc.Driverurl: jdbc:mysql://192.168.200.151:3306/restkeeper-shop-1?serverTimezone=UTC&useUnicode=true&characterEncoding=utf8username: rootpassword: root#分库分表sharding:tables:tab_order: #数据库中要分表的逻辑名actualDataNodes: ds${0..1}.tab_order_${0..1}databaseStrategy:inline:shardingColumn: sharding_idalgorithmExpression: ds${sharding_id % 2}tableStrategy:inline:shardingColumn: order_noalgorithmExpression: tab_order_${order_no % 2}keyGenerator:type: SNOWFLAKEcolumn: idtab_order_item: #数据库中要分表的逻辑名actualDataNodes: ds${0..1}.tab_order_item_${0..1}databaseStrategy:inline:shardingColumn: sharding_idalgorithmExpression: ds${sharding_id % 2}tableStrategy:inline:shardingColumn: product_order_noalgorithmExpression: tab_order_item_${product_order_no % 2}keyGenerator:type: SNOWFLAKEcolumn: idbinding-tables:- tab_order- tab_order_itembroadcast-tables:- tab_brand- tab_category- tab_dish- tab_dish_flavor- tab_printer- tab_printer_dish- tab_store- tab_table- tab_table_area- undo_logdefault-key-generator:type: SNOWFLAKEcolumn: idprops:sql.show: true#mybatis配置mybatis-plus:# MyBaits 别名包扫描路径,通过该属性可以给包中的类注册别名type-aliases-package: com.itheima.springcloud.pojo# 该配置请和 typeAliasesPackage 一起使用,如果配置了该属性,则仅仅会扫描路径下以该类作为父类的域对象 。type-aliases-super-type: com.itheima.restkeeper.basic.BasicPojoconfiguration:# 这个配置会将执行的sql打印出来,在开发或测试的时候可以用log-impl: org.apache.ibatis.logging.stdout.StdOutImpl# 驼峰下划线转换map-underscore-to-camel-case: trueuse-generated-keys: truedefault-statement-timeout: 60default-fetch-size: 100#忽略商户号表ignore-enterprise-tables:- tab_brand- tab_category- tab_dish- tab_dish_flavor- tab_order- tab_order_item- tab_printer- tab_printer_dish- tab_store- tab_table- tab_table_area- tab_role- tab_order_role- undo_log#忽略门店号表ignore-store-tables:- tab_brand- tab_category- tab_dish- tab_dish_flavor- tab_order- tab_order_item- tab_printer- tab_printer_dish- tab_store- tab_table- tab_table_area- tab_role- tab_order_role- undo_loglogging:config: classpath:logback.xmldubbo:application:version: 1.0.0logger: slf4jscan:base-packages: com.itheima.restkeeperregistry:address: spring-cloud://192.168.200.129protocol:#指定二进制协议name: dubboport: 27079threads: 200accesslog: logs/model-shop-applet-01.log
5.在resources文件夹下添加jta.properties 这个文件的作用是什么?待问
com.atomikos.icatch.output_dir=D:/atomikos/model-shop-appletcom.atomikos.icatch.log_base_dir=D:/atomikos/model-shop-applet
6.在AppletFaceImpl类中需要事务的方法上添加@ShardingTransactionType(TransactionType.XA)注解。注意:如果是分布式事务TransactionType.XA改为TransactionType.BASE
seata-at使用shardingJDBC
1.创建模块framework-sharding-jdbc
2.引入依赖
<dependency><groupId>com.itheima.restkeeper</groupId><artifactId>model-shop-service</artifactId><exclusions><exclusion><groupId>com.alibaba</groupId><artifactId>druid-spring-boot-starter</artifactId></exclusion></exclusions></dependency><dependency><groupId>com.itheima.restkeeper</groupId><artifactId>framework-sharding-jdbc</artifactId><exclusions><exclusion><groupId>org.apache.shardingsphere</groupId><artifactId>sharding-transaction-xa-core</artifactId></exclusion></exclusions></dependency>
3.在model-shop-producer模块中的resource文件夹下添加application.yml
#服务配置server:#端口port: 7077#服务编码tomcat:uri-encoding: UTF-8#spring相关配置spring:#应用配置application:#应用名称name: model-shop-producermain:allow-bean-definition-overriding: trueredis:redisson:config: classpath:singleServerConfig.yaml#redis配置信息host: 192.168.200.129port: 6379password: passcloud:alibaba:seata:tx-service-group: project_tx_groupjta:atomikos:properties:log-base-dir: logs/model-shop-producer-atomikoslog-base-name: model-shop-producer#数据源配置shardingsphere:datasource:names: ds0,ds1ds0:type: com.alibaba.druid.pool.DruidDataSourcedriverClassName: com.mysql.jdbc.Driverurl: jdbc:mysql://192.168.200.129:3306/restkeeper-shop-0?serverTimezone=UTC&useUnicode=true&characterEncoding=utf8username: rootpassword: passds1:type: com.alibaba.druid.pool.DruidDataSourcedriverClassName: com.mysql.jdbc.Driverurl: jdbc:mysql://192.168.200.151:3306/restkeeper-shop-1?serverTimezone=UTC&useUnicode=true&characterEncoding=utf8username: rootpassword: root#分库分表sharding:tables:tab_order: #数据库中要分表的逻辑名actualDataNodes: ds${0..1}.tab_order_${0..1}databaseStrategy:inline:shardingColumn: sharding_idalgorithmExpression: ds${sharding_id % 2}tableStrategy:inline:shardingColumn: order_noalgorithmExpression: tab_order_${order_no % 2}keyGenerator:type: SNOWFLAKEcolumn: idtab_order_item: #数据库中要分表的逻辑名actualDataNodes: ds${0..1}.tab_order_item_${0..1}databaseStrategy:inline:shardingColumn: sharding_idalgorithmExpression: ds${sharding_id % 2}tableStrategy:inline:shardingColumn: product_order_noalgorithmExpression: tab_order_item_${product_order_no % 2}keyGenerator:type: SNOWFLAKEcolumn: idbinding-tables:- tab_order- tab_order_itembroadcast-tables:- tab_brand- tab_category- tab_dish- tab_dish_flavor- tab_printer- tab_printer_dish- tab_store- tab_table- tab_table_area- undo_logdefault-key-generator:type: SNOWFLAKEcolumn: idprops:sql.show: true#mybatis配置mybatis-plus:# MyBaits 别名包扫描路径,通过该属性可以给包中的类注册别名type-aliases-package: com.itheima.springcloud.pojo# 该配置请和 typeAliasesPackage 一起使用,如果配置了该属性,则仅仅会扫描路径下以该类作为父类的域对象 。type-aliases-super-type: com.itheima.restkeeper.basic.BasicPojoconfiguration:# 这个配置会将执行的sql打印出来,在开发或测试的时候可以用log-impl: org.apache.ibatis.logging.stdout.StdOutImpl# 驼峰下划线转换map-underscore-to-camel-case: trueuse-generated-keys: truedefault-statement-timeout: 60default-fetch-size: 100#忽略商户号表ignore-enterprise-tables:- tab_dish_flavor- tab_order_item- undo_log#忽略门店号表ignore-store-tables:- tab_dish_flavor- tab_brand- tab_order_item- tab_store- undo_logseata:tx-service-group: project_tx_groupenabled: trueapplication-id: ${spring.application.name}# **注意:此处必须设置为 false,将数据源的代理权限交给sharding-jdbc管理enable-auto-data-source-proxy: falseservice:#这里的名字与file.conf中vgroup_project_tx_group = "default"相同vgroup-mapping:project_tx_group: default#这里的名字与file.conf中default.grouplist = "192.168.200.129:8091"相同grouplist:default: 192.168.200.129:9200config:type: nacosnacos:group: SEATA_GROUPserver-addr: 192.168.200.129:8848username: nacospassword: nacosregistry:type: nacosnacos:group: SEATA_GROUPserver-addr: 192.168.200.129:8848username: nacospassword: nacosdubbo:#dubbo应用服务定义application:#版本version: 1.0.0#日志logger: slf4jscan:#扫描路径base-packages: com.itheima.restkeeperregistry:#注册中心address: spring-cloud://192.168.200.129#服务协议定义protocol:#服务协议名称name: dubbo#协议端口port: 27077#线程数threads: 200#dubbo调用日志accesslog: logs/model-shop-producer-01.log
注意: enable-auto-data-source-proxy: false在seata中一定要写false,因为引入sharding-jdbc后事务就是由sharding-jdbc管理了,而不是seata。
4.添加jta.properties 这个文件的作用是什么?待问
com.atomikos.icatch.output_dir=D:/atomikos/model-shop-producercom.atomikos.icatch.log_base_dir=D:/atomikos/model-shop-producer
5.在resource路径下添加seata.conf 这个文件的作用是什么?待问
client {application.id = model-shop-producertransaction.service.group = project_tx_group}
6.在需要事务的方法上添加注解@ShardingTransactionType(TransactionType.BASE)
5.在项目中分片键的值是怎么设置的?
采用了分片键回填机制,mybatis-plus提供了一个MetaObjectHandler接口(作用是在插入或更新数据的时候为一些字段指定默认值),有两个方法void insertFill(MetaObject metaObject)插入时自动填充和void updateFill(MetaObject metaObject)更新时自动填充。
在项目中自定义了一个类来实现这个接口,并且引入了mybatisplus的雪花算法IdentifierGenerator解决了分片键值设置的问题。不能采用自动回填机制,这样会导致每个表的sharding_id都是1.2.3.4…,在分片策略(对数取余)下,最终会导致数据分布不均匀,影响性能。

若有收获,就点个赞吧
0 人点赞
