1、掌握Dubbo运行流程(※)
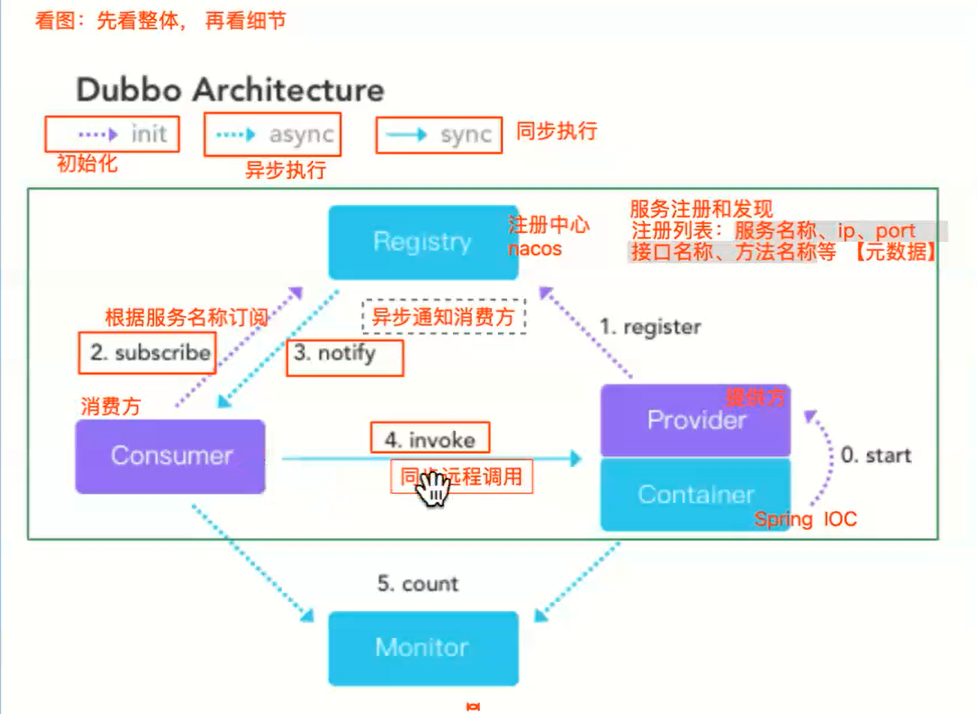
1.springboot项目启动,dubbo开始初始化,将对象交由spring管理
2.服务提供方得到dubbo的对象后,将自己的服务注册列表(服务名称、ip、port、接口名称、方法名称等)注册到nacos注册中心
3.服务消费方通过服务名称在nacos注册中心订阅服务
4.nacos注册中心得到服务提供方的信息后,将信息异步通知给订阅过该服务的服务消费方
5.服务消费方得到消息后同步远程调用服务提供方
2、掌握Dubbo配置-超时、重试、灰度发布、启动检查等
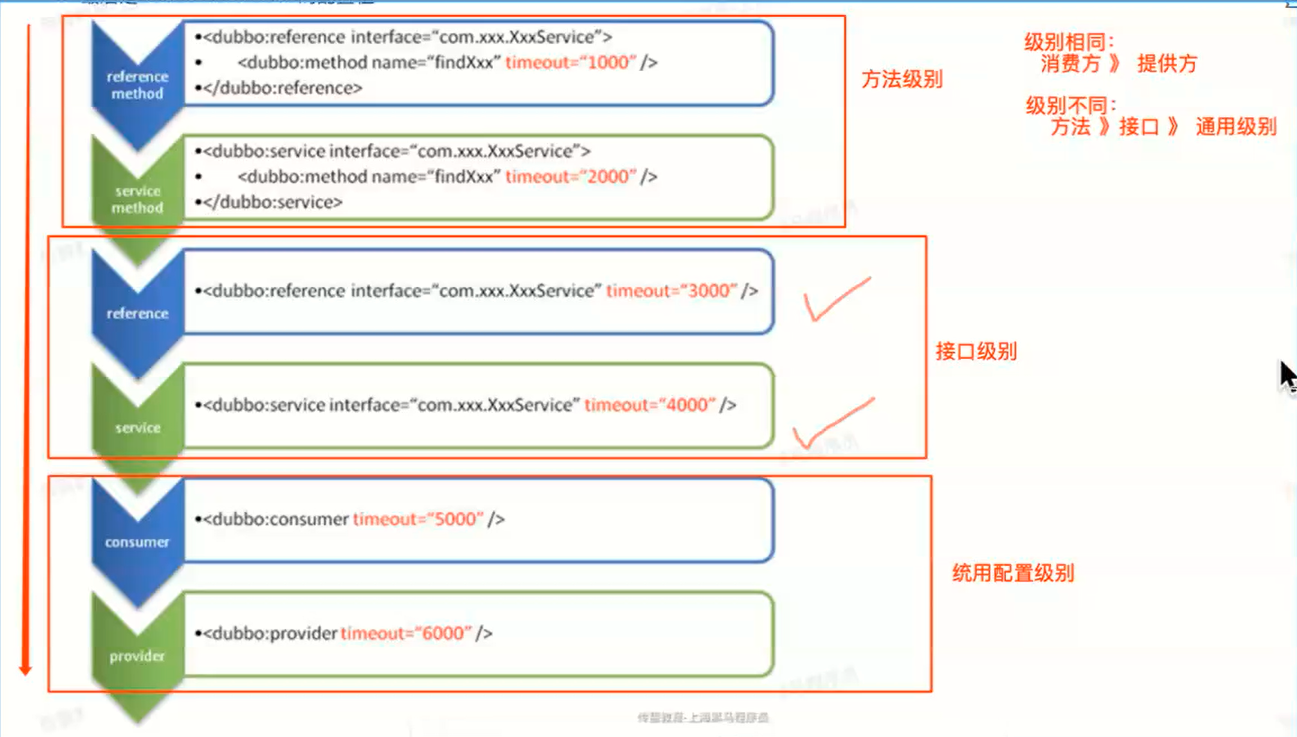
1.dubbo配置的优先级别:
1)当级别相同时,消费方的配置是 > 提供方的配置
2)当级别不同时,在方法上的配置>在接口的配置>全局配置
2.配置原则设计的目的
1)先配置服务提供方相关配置;
2)如果提供方的配置在消费不满足使用,则可以在消费方优化
3.重试次数
当dubbo远程调用失败后,会重试其他服务器,但会带来更长的延迟,远程调用成功则不重试。dubbo默认设置的重试次数是2,不包含第一次的正常调用,属性是“retries”。
注意:重试次数不建议设置的过多,建议的重试次数不大于2.
重试次数的配置:
重试次数配置如下:<dubbo:service retries="2" />或<dubbo:reference retries="2" />或<dubbo:reference><dubbo:method name="findAll" retries="2" /></dubbo:reference>
4.超时时间
为了避免超时导致客户端资源(线程)挂起耗尽,必须设置超时时间。dubbo默认设置的是1s,属性“timeout”
超时时间配置:
# dubbo服务提供方全局超时配置<dubbo:provider timeout="5000" />指定接口以及特定方法超时配置<dubbo:provider interface="com.foo.BarService" timeout="2000"><dubbo:method name="sayHello" timeout="3000" /></dubbo:provider>
# dubbo服务消费方全局超时配置<dubbo:consumer timeout="5000" />指定接口以及特定方法超时配置<dubbo:reference interface="com.foo.BarService" timeout="2000"><dubbo:method name="sayHello" timeout="3000" /></dubbo:reference>
5.灰度发布-版本号
一个接口实现出现不兼容升级时,可以用版本号过渡,版本号不同的服务相互间不引用可以进行版本迁移,属性“version”
迁移步骤:
1)在低压力时间段,先升级一半提供者为新版本;
2)再将所有消费者升级为新版本;
3)最后将剩下的一半提供者升级为新版本。
# 版本迁移配置<!-- 老版本服务提供者配置:--><dubbo:service interface="com.foo.BarService" version="1.0.0" /><!-- 新版本服务提供者配置:--><dubbo:service interface="com.foo.BarService" version="2.0.0" /><!-- 老版本服务消费者配置:--><dubbo:reference id="barService" interface="com.foo.BarService" version="1.0.0" /><!-- 新版本服务消费者配置:--><dubbo:reference id="barService" interface="com.foo.BarService" version="2.0.0" /><!-- 如果不需要区分版本,可以按照以下的方式配置:--><dubbo:reference id="barService" interface="com.foo.BarService" version="*" />
6.上下文信息
RpcContext是一个ThreadLoacl的临时状态记录器,当接收或发起到RPC请求时,RpcContext的状态都会发生变化。比如,A调B,B调C。在B机器上,B调C之前,RpcContext记录的是A调B的信息,但是在B调C之后,RpcContext记录的是B调C的信息。
服务消费方// 远程调用xxxService.xxx();// 本端是否为消费端,这里会返回trueboolean isConsumerSide = RpcContext.getContext().isConsumerSide();// 获取最后一次调用的提供方IP地址String serverIP = RpcContext.getContext().getRemoteHost();// 获取当前服务配置信息,所有配置信息都将转换为URL的参数String application = RpcContext.getContext().getUrl().getParameter("application");// 注意:每发起RPC调用,上下文状态会变化yyyService.yyy();
服务提供方// 本端是否为提供端,这里会返回trueboolean isProviderSide = RpcContext.getContext().isProviderSide();// 获取调用方IP地址String clientIP = RpcContext.getContext().getRemoteHost();// 获取当前服务配置信息,所有配置信息都将转换为URL的参数String application = RpcContext.getContext().getUrl().getParameter("application");// 注意:每发起RPC调用,上下文状态会变化yyyService.yyy();// 此时本端变成消费端,这里会返回falseboolean isProviderSide = RpcContext.getContext().isProviderSide();
注意:dubbo上下文对象用于存储调用链路中的数据环境信息。
7.隐式参数
可以通过RpcContext上的setAttachment()方法和getAttchment()方法在服务消费方和提供方之间进行参数的隐式传递。
注意:path、group、version、dubbo、token、timeout几个key是保留字段,不可使用。
# 服务消费方设置隐式参数:RpcContext.getContext().setAttachment("index", "1"); // 隐式传参,后面的远程调用都会隐式将这些参数发送到服务器端,类似cookie,用于框架集成,不建议常规业务使用xxxService.xxx(); // 远程调用
# 服务提供方获取隐式参数// 获取客户端隐式传入的参数,用于框架集成,不建议常规业务使用String index = RpcContext.getContext().getAttachment("index");
3、Dubbo负载均衡有几种,默认是什么
1)Random LoadBalance(加权随机负载均衡),dubbo默认的负载均衡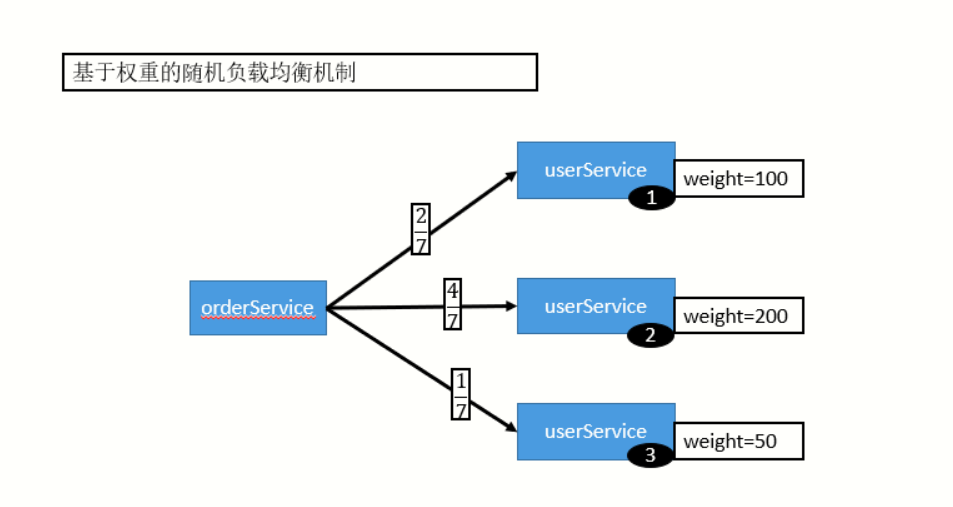
按权重设置随机概率在一个截面上碰撞的概率高,但调用量越大分布越均匀,而且按概率使用权重后也比较均匀。
2)RoundRobin LoadBalance(加权轮询负载均衡)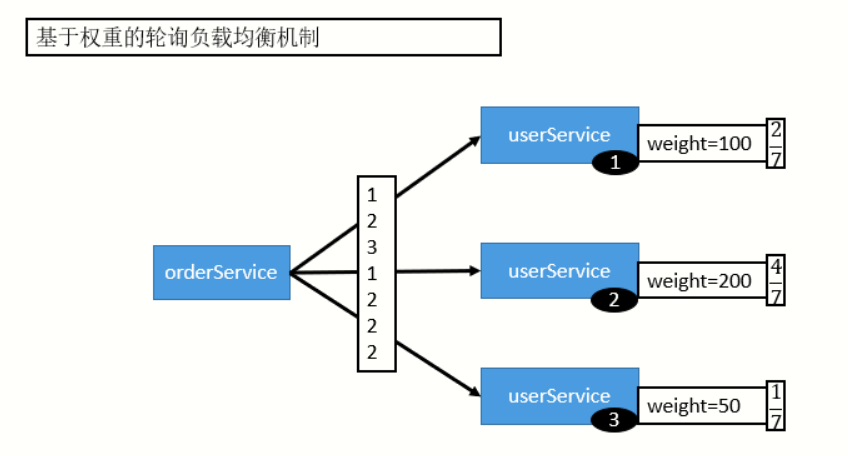
按公约后的权重设置轮询比率。存在慢的提供者累积请求的问题,比如:第二台机器很慢,但是没挂,当请求调到第二台时就卡在这里了,随着时间发展所有的请求都卡在第二台机器了。
3)LeastActive LoadBalance(最少活跃数负载均衡)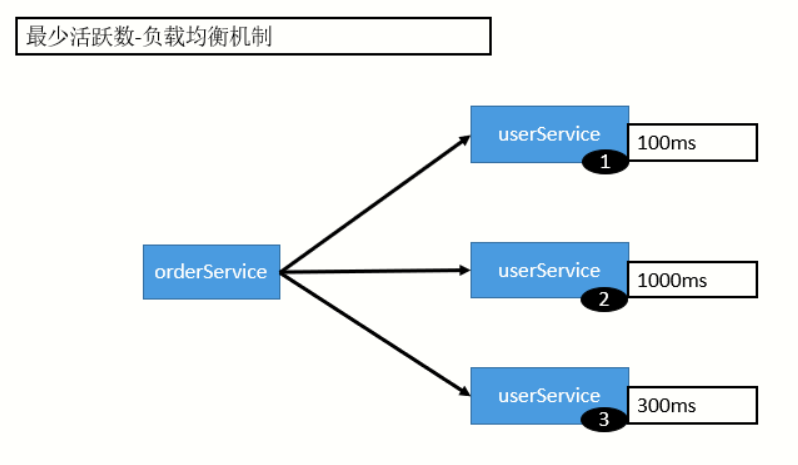
最少活跃调用数,相同活跃数的随机,活跃数指的是调用前后的计数差。使慢的提供者收到更少请求,因为越慢的提供者调用前后计数差会越大。
4)ConsistentHash LoadBalance(一致性Hash负载均衡)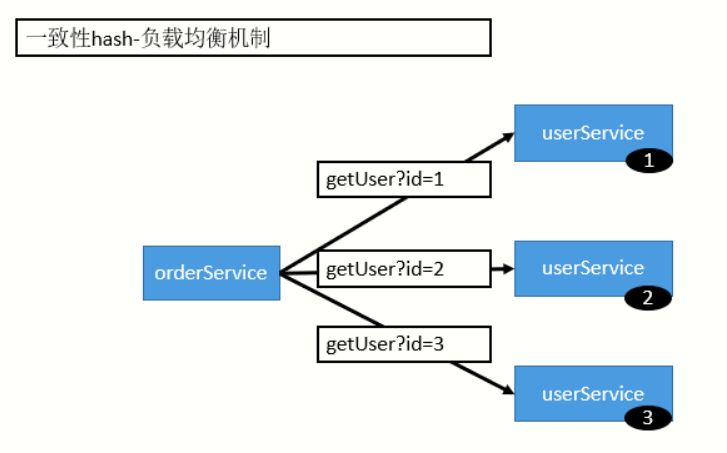
一致性Hash,相同参数的请求总是发到同一提供者。当某一台提供者挂掉后,原本发往该提供者的请求,基于虚拟节点,平摊到其他提供者,不会引起剧烈变动。
4、Dubbo服务熔断降级有如何实现,容错机制有几种
向注册中心写入动态配置覆盖规则:
egistryFactory registryFactory = ExtensionLoader.getExtensionLoader(RegistryFactory.class).getAdaptiveExtension();Registry registry = registryFactory.getRegistry(URL.valueOf("nacos://10.20.153.10:2181"));registry.register(URL.valueOf("override://0.0.0.0/com.foo.BarService?category=configurators&dynamic=false&application=foo&mock=force:return+null"));
mock=force:return+null表示消费方对该服务的方法调用都直接返回null值,不发起远程调用。(应用场景:用来屏蔽不重要的服务在不可用时对调用方的影响)
可以修改为mock=fail:return+null表示消费方对该服务的方法调用都直接返回null值,不抛异常。(应用场景:容忍不重要的服务在不稳定时对调用方的影响)
集群容错机制,dubbo默认是failover重试
1)Failover Cluster
失败自动切换,当出现失败,重试其他服务器。通常用于读操作,但重试会带来更长的延迟,可通过retries = “2”来设置重试次数(不包含第一次)
2)FailFast Cluster
快速失败,只发起一次调用,失败立即报错,通常用于非幂等性的写操作,比如新增记录。
3)Failsafe Cluster
失败安全,出现异常时,直接忽略。通常用于写入审计日志等操作。
4)Failback Cluster
失败自动恢复,后台记录失败请求,定时重发。通常用于消息通知操作。
5)Forking Cluster
并行调用多个服务器,只要一个成功即返回。通常用于实时性要求较高的读操作,但需要浪费更多的服务资源。“forcks=2”可设置最大并行数
6)BroadCast Clustrer
广播调用所有提供者,逐个调用,任意一台报错则报错。通常用于通知所有提供者更新缓存或日志等本地资源信息。
5、SpringCloud 和 Dubbo 区别(面试题)
核心要素比较:
| 核心要素 | dubbo | springcloud |
|---|---|---|
| 服务注册中心 | zookeeper、redis | springcloud netfix eureka、consul |
| 服务调用方式 | RPC | REST API |
| 服务网关 | 无 | springcloud Netfix Zuul |
| 断路器 | 不完善 | springcloud Netfix Hystrix |
| 分布式配置 | 无 | springcloud Config |
| 分布式追踪系统 | 无 | springcloud Sleuth |
| 消息总线 | 无 | springcloud Bus |
| 数据流 | 无 | springcloud Stream 基于Redis、Rabbit,Kafka实现的消息做服务 |
| 批量任务 | 无 | springcloud Task |
整体比较:
| dubbo是基于RPC二进制的传输占用的带宽会更少 | springcloud是http协议传输,带宽会比较多,同时使用http协议一般会使用JSON报文,消耗会更大 |
|---|---|
| dubbo的开发难度较大,原因是dubbo的jar包依赖问题很多大型工程无法解决 | springcloud的接口协议约定比较自由且松散,需要有强有力的行政措施来限制接口无序升级 |
| dubbo的注册中心可以选择nacos、zookeeper、redis等 | springcloud的注册中心用eureka或者consul |
6、Eureka和Nacos区别
| 区别 | nacos | eureka |
|---|---|---|
| 相同点 | 都支持服务注册和服务拉取;都支持服务提供者心跳方式做健康检测 | |
不同点 |
nacos支持服务端主动检测提供者状态:临时实例采用心跳模式;非临时实例采用主动检测模式 | 不区分临时实例和非临时实例,只对服务端做心跳检测 |
| 临时实例心跳不正常会被剔除,非临时实例则不会被剔除 | 只要实例不正常都会被剔除 | |
| nacos支持服务列表变更的消息推送模式,服务列表更新更及时 | 不支持 | |
| nacos集群默认采用AP方式,当集群中存在非临时实例时,采用CP模式 | eureka采用AP方式 |
7、注册中心是否可以替换?如果可以替换用什么来替换?为什么?
nacos注册中心宕机,可以继续消费dubbo暴露的服务,所以nacos注册中心是可以替换的。
dubbo的高可用设计:
通过dubbo直连方式调用,绕开nacos注册中心实现。实现:在注解或配置文件中添加url地址。如:<dubbo:reference url="47.96.248.4:20880">
注册中心可替换的原因:
1)数据库宕机后,nacos注册中心仍然可以通过缓存(在本地)提供服务列表查询,但是不能注册新服务。
2)注册中心对等集群,任意一台宕机后,会自动切换到另外一台。
3)注册中心全部宕机后,服务提供者和服务消费者仍然可以通过本地缓存进行通讯
4)服务提供者全部宕机后,服务消费者将无法使用,并无限次重连并等待服务提供者恢复
5)服务提供者处于无状态时,任意一台宕机后,不影响使用。
可以用nacos/zookepper/redis等,来替换
8、redis是否可以作为注册中心,为什么?数据结构是什么?怎么实现?
redis可以作为注册中心,redis存在发布订阅特性来实现注册中心的功能。
数据结构:Hash结构,大key储存当前服务的全限定类名+类型,Map Key存储服务的ID,Map Value存储服务的过期时间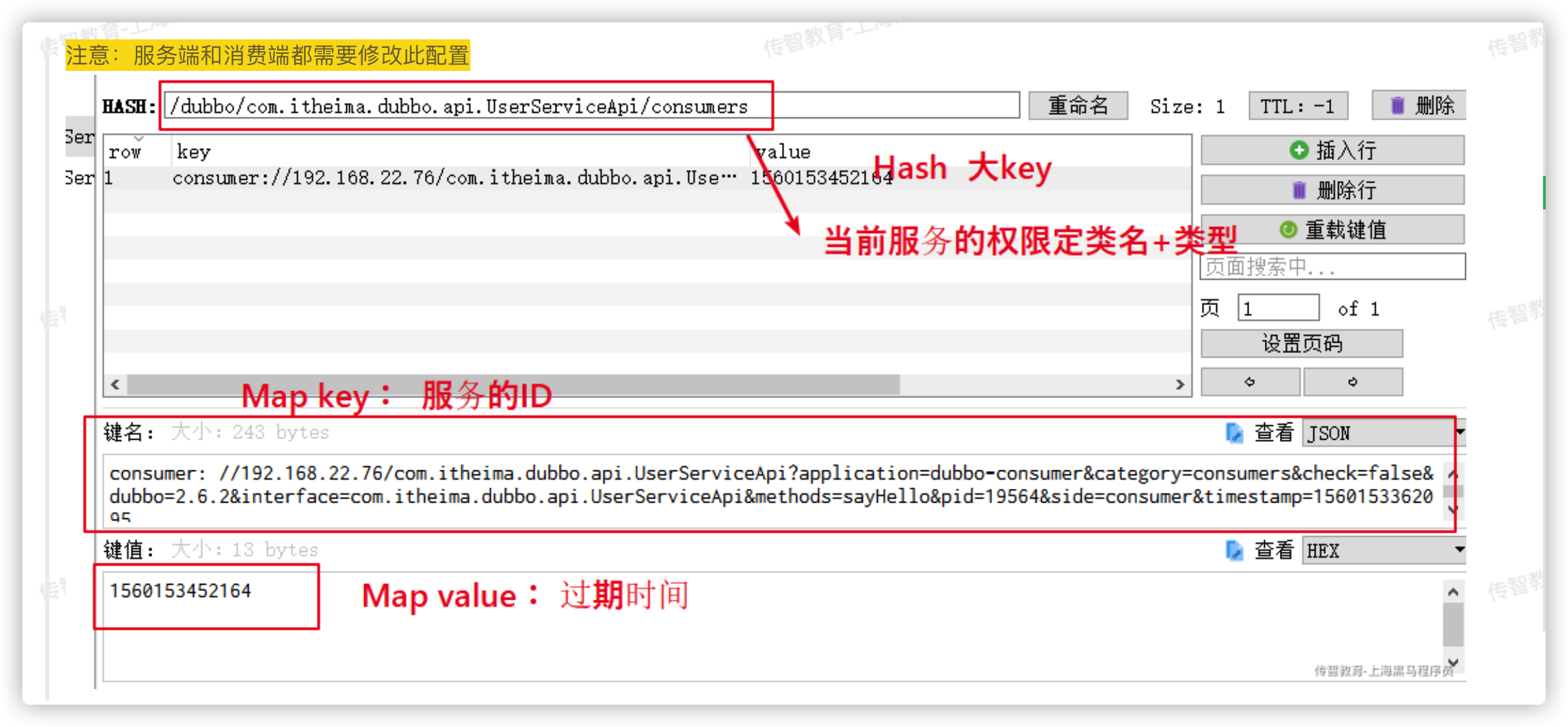
9、分布式系统演变的原因?
10、http和RPC区别?RPC的传输流程?
http工作在网络7层模型的应用层,rpc工作在网络层。
rpc的传输流程: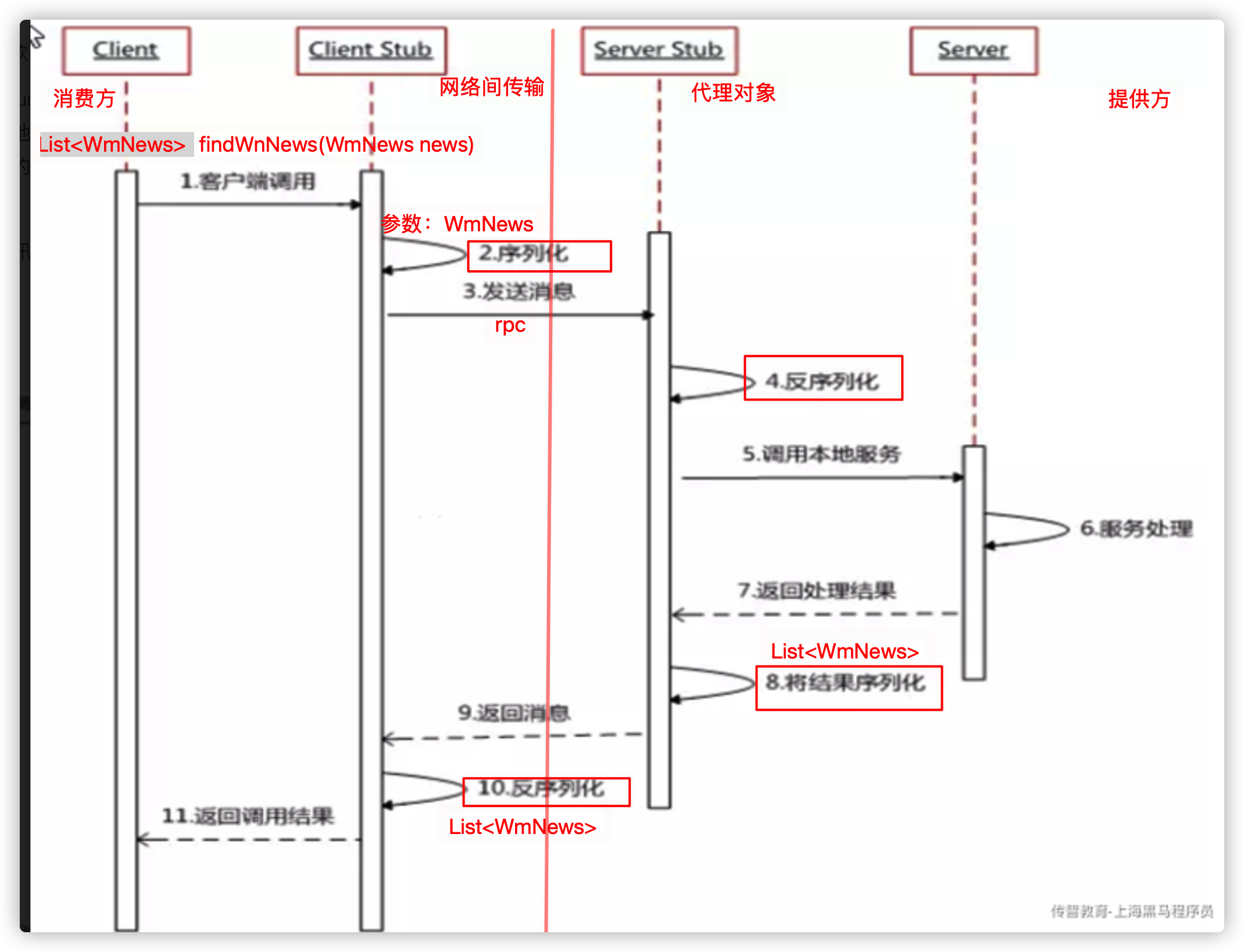
1)客户端开始调用消费方发送List
2)将集合的WmNews参数序列化;
3)序列化后的消息发送给代理对象;
4)代理对象将序列化的消息反序列化;
5)代理对象反序列化后调用本地服务;
6)提供方进行服务处理;
7)服务处理完毕后返回处理结果;
8)代理对象将结果序列化(List
9)在网络传输过程中反序列化;
10)把反序列化的结果给消费方

若有收获,就点个赞吧
0 人点赞
