- Spring Boot篇
- Spring Cloud篇
- 1.什么是Spring Cloud?(了解)
- 2..Spring Cloud的开发组件有哪些?(必会)
- 3.Spring Cloud 和 Spring Cloud Alibaba的关系是怎样的?(必会)
- 4.请讲一下Eureka的服务注册与发现的执行流程?(必会)
- 5.请简要描述一下eureka的心跳检测机制【服务续约】。(必会)
- 6.请简要描述一下eureka的服务剔除以及保护机制。(必会)
- 7.Ribbon的负载均衡策略有哪些?(高薪提问)*负载均衡策略: 至少要记住三个以上**
- 8.负载均衡的执行流程是怎样的?请描述一下。(必会)
- 9.负载均衡的源码,自己讲4遍,第5遍结合项目的短信服务讲解。*
- 10.Feign的工作流程是怎样的?(必会)
- 11.Feign调用服务失败,会重试吗?它的重试机制是啥?(必会)
- 12.Feig的超时时间是怎么设置的?Feign和Ribbon的区别是啥?
- 12.什么是微服务的级联失败(雪崩问题)?解决方案是什么?(必会)
- 13.Spring Cloud GateWay网关的作用是什么,有哪些功能?可以结合项目来讲(统一认证和权限模块)(必会)
- 14.Spring Cloud GateWay网关的执行流程是怎样的?(必会)
- 15.网关中断言匹配是什么? 你们项目中用的是什么? 还有哪些?(必会)
- RabbitMQ消息中间件篇**
Spring Boot篇
1.请讲一下Spring Boot自动配置(自动装配)的流程(高薪提问)*
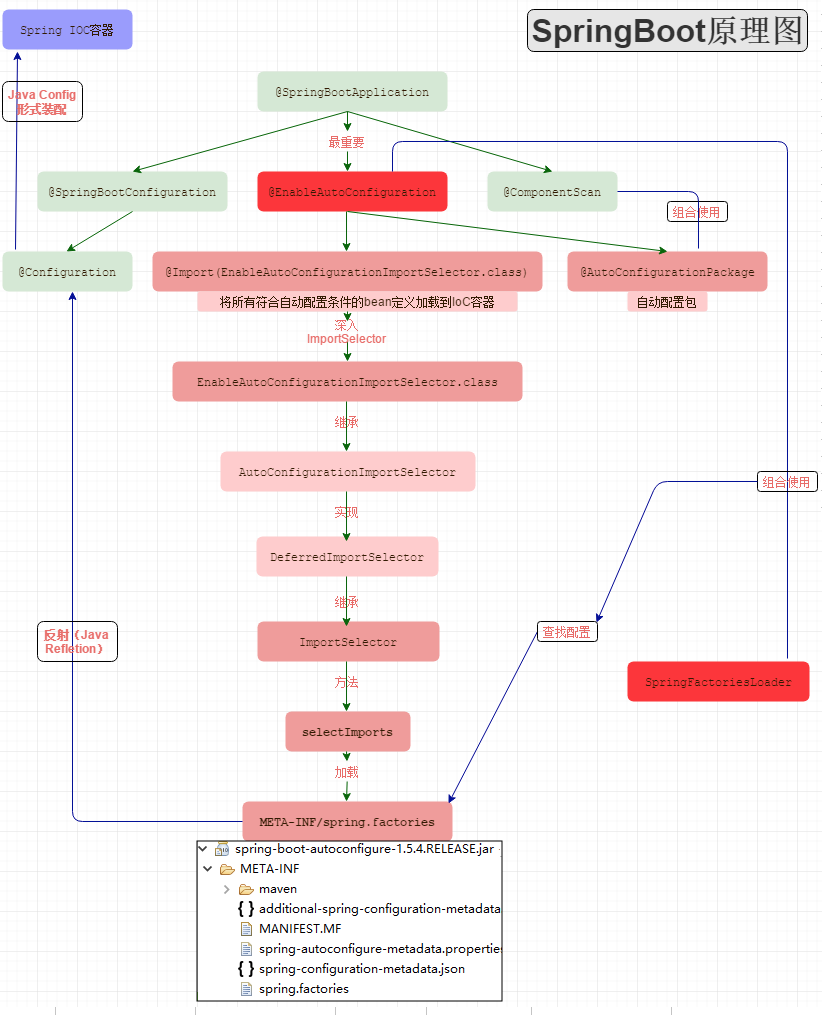
初始化:
1)@SpringbootApplication底层可拆分三个注解@SpringBootConfiguration、@EnableAutoConfiguration和@ComponentScan;
2)@SpringBootConfiguration是对Spring注解@Configuration的包装;
3)@ComponentScan定义了默认的扫包范围为当前启动类所在包下的所有类;
4)@EnableAutoConfiguration中主要引入了AutoConfigurationImportSelector这个类选择器;
5)AutoConfigurationImportSelector中将**org.springframework.boot.autoconfiguration**这个依赖jar中的Spring.factories文件中的类全部加载;
6)spring.factories中定义了很多配置类,其中包括DispatcherServletAutoConfiguration(springMVC核心类)和ServletWebServerFactoryAutoConfiguration(容器类);
7)ServletWebServerFactoryAutoConfiguration中通过@Import将三种web容器注入IOC:EmbeddedTomcat、EmbeddedJetty和EmbeddedUndertow;
8)以默认的tomcat为例:IOC:EmbeddedTomcat中通过@Bean的方式将TomcatServletWebServerFactory注入IOC;
9)TomcatServletWebServerFactory的getWebServer方法里会创建tomcat服务器,并将本地class文件交由其运行管理;
启动运行流程:
1)springboot启动时,会先创建springApplication对象,再执行其run方法;
2)创建springApplication对象时会先判断当前启动哪一类型的WebApplicationType;
3)通过setInitializers和setListeners会将所有jar中/resources/META-INF/下的spring.factories文件中的类注入IOC;
4)执行run方法时,会开启计时;
5)获取所有的启动listener;
6)将环境加载;
7)打印轮播图;
8)创建springboot的上下文对象;
9)装配上下文;
10)刷新上下文(和spring注解方式启动原理一致);
11)刷新之后的后续操作(扩展);
12)发布订阅的方式广播通知Listener,context要启动了;
13)发布订阅的方式广播通知listener,context已经启动。
具体流程分析● SpringBootConfiguration● Configuration● EnableAutoConfiguration○ 这个注解的作用是告诉SpringBoot开启自动配置功能,这样就减少了我们的配置■ AutoConfigurationPackage● 观察其内部实现,内部是采用了@Import,来给容器导入一个Registrar组件● 通过源码跟踪,我们知道,程序运行到这里,会去加载启动类所在包下面的所有类● 就是为什么,默认情况下,我们要求定义的类,比如controller,service必须在启动类的同级目录或子级目录的原因■ Import(AutoConfigurationImportSelector.class)● 发现默认加载了好多的自动配置类,这些自动配置类,会自动给我们加载每个场景所需的所有组件,并配置好这些组件,这样就省去了很多的配置● 深入理解SpringBoot启动机制(starter机制)○ @Configuration注解的类可以看作是能生产让Spring IoC容器管理的Bean实例的工厂。○ @Bean注解告诉Spring,一个带有@Bean的注解方法将返回一个对象,该对象应该被注册到spring容器中。● DataSourceAutoConfiguration○ EnableConfigurationProperties■ @EnableConfigurationProperties注解的作用是使@ConfigurationProperties注解生效。如果只配置@ConfigurationProperties注解,在spring容器中是获取不到yml或者properties配置文件转化的bean的.○ ConfigurationProperties■ @ConfigurationProperties注解的作用是把yml或者properties配置文件转化为bean。● Bean的发现○ 实际上重要的只有三个Annotation:■ @Configuration(@SpringBootConfiguration里面还是应用了@Configuration)● @Configuration的作用上面我们已经知道了,被注解的类将成为一个bean配置类■ @ComponentScan● @ComponentScan的作用就是自动扫描并加载符合条件的组件,比如@Component和@Repository等,最终将这些bean定义加载到spring容器中■ @EnableAutoConfiguration● @AutoConfigurationPackage○ @AutoConfigurationPackage的作用就是自动配置的包● @Import○ @Import导入需要自动配置的组件。○ 每个xxxAutoConfiguration都是一个基于java的bean配置类。实际上,这些xxxAutoConfiguration不是所有都会被加载,会根据xxxAutoConfiguration上的@ConditionalOnClass等条件判断是否加载;通过反射机制将spring.factories中@Configuration类实例化为对应的java实例● Bean 加载○ 如果要让一个普通类交给Spring容器管理,通常有以下方法:■ 使用 @Configuration与@Bean 注解■ 使用@Controller @Service @Repository @Component 注解标注该类,然后启用@ComponentScan自动扫描■ 使用@Import 方法○ springboot中使用了@Import 方法○ @EnableAutoConfiguration注解中使用了@Import({AutoConfigurationImportSelector.class})注解,AutoConfigurationImportSelector实现了DeferredImportSelector接口,○ DeferredImportSelector接口继承了ImportSelector接口,ImportSelector接口只有一个selectImports方法。○ selectImports方法返回一组bean,@EnableAutoConfiguration注解借助@Import注解将这组bean注入到spring容器中,springboot正是通过这种机制来完成bean的注入的。
2.什么是Spring Boot?(了解)
Spring Boot 是 Spring 开源组织下的子项目,是 Spring 组件一站式解决方案,主要是简化了使用 Spring 的难度,节省了繁重的配置,提供了各种启动器,开发者能快速上手。
3.Spring Boot 的核心注解是哪个?它主要由哪几个注解组成的?(必会)
| @SpringBootApplication | 在启动类上的注解,核心注解 | |
|---|---|---|
| @SpringBootConfiguration | 组合了@Configuration注解,实现配置文件的功能 | |
@EnableAutoConfiguration | 打开自动配置的功能,也可以关闭某个自动配置的选项,如关闭数据源自动配置功能。@SpringBootApplication(exclude={DataSourceAutoConfiguration.class}) | | | @ComponentScan | Spring组件扫描 | |
4.你如何理解 Spring Boot 配置加载顺序?(必会)
1)properties文件;2)YAML文件;3)系统环境变量;4)命令行参数……
5.YAML 配置的优势在哪里 ?Spring Boot 是否可以使用 XML 配置 ?(了解)
YAML优势:a.配置有序,在一些特殊场景下配置有序很关键;b.支持数组,数组中的元素可以是基本数据类型也可以是对象。
YAML缺点:就是不支持@PropertySource注解导入自定义的YAML配置。
Spring Boot 推荐使用 YML 配置而非 XML 配置,但是 Spring Boot 中也可以使用 XML 配置,通过 @ImportResource 注解可以引入一个 XML 配置。
6.spring boot 核心配置文件是什么?bootstrap.properties 和 application.properties 有何区别 ?(必会)
| bootstrap.yml/properties | application.yml/properties | ||
|---|---|---|---|
| 由ApplicationContext加载的,比application优先加载,配置在应用程序上下文的引导阶段生效。一般来说我们在Spring Cloud或者Nacos中会用到它。且bootstrap里面的属性不能被覆盖 |
由ApplicationContext加载,用于Spring Boot项目的自动化配置。 | | |
7.Spring Boot 中如何解决跨域问题 ?(了解)
跨域可以在前端通过 JSONP 来解决,但是 JSONP 只可以发送 GET 请求,无法发送其他类型的请求,在 RESTful 风格的应用中,就显得非常鸡肋,因此我们推荐在后端通过 (CORS,Cross-origin resource sharing) 来解决跨域问题。这种解决方案并非 Spring Boot 特有的,在传统的 SSM 框架中,就可以通过 CORS 来解决跨域问题,只不过之前我们是在 XML 文件中配置 CORS ,现在可以通过实现WebMvcConfigurer接口然后重写addCorsMappings方法解决跨域问题。
项目中前后端分离部署,所以需要解决跨域的问题。
我们使用cookie存放用户登录的信息,在spring拦截器进行权限控制,当权限不符合时,直接返回给用户固定的json结果。
当用户登录以后,正常使用;当用户退出登录状态时或者token过期时,由于拦截器和跨域的顺序有问题,出现了跨域的现象。
我们知道一个http请求,先走filter,到达servlet后才进行拦截器的处理,如果我们把cors放在filter里,就可以优先于权限拦截器执行。
Spring Cloud篇
1.什么是Spring Cloud?(了解)
Spring Cloud是一系列框架的有序集合。它利用Spring Boot的开发便利性巧妙地简化了分布式系统基础设施的开发,如服务发现注册、配置中心、智能路由、消息总线、负载均衡、断路器、数据监控等,都可以用Spring Boot的开发风格做到一键启动和部署。Spring Cloud并没有重复制造轮子,它只是将各家公司开发的比较成熟、经得起实际考验的服务框架组合起来,通过Spring Boot风格进行再封装屏蔽掉了复杂的配置和实现原理,最终给开发者留出了一套简单易懂、易部署和易维护的分布式系统开发工具包。
2..Spring Cloud的开发组件有哪些?(必会)
| 网关 | zuul(淘汰)、Spring Cloud Gateway(推荐) | |
|---|---|---|
| 注册中心 | Zookeeper、consul、euraka、nacos(推荐) | |
| 配置中心 | Spring Cloud config + bus(淘汰)、apollo(携程)、nacos(推荐) | |
| 远程调用 | Ribbon、Feign(推荐),Feign是基于Ribbon实现的 | |
| 熔断器 | Hystrix(淘汰)、Alibaba Sentinel(推荐)熔断降级 | |
| 分布式事务 | Alibaba Seata-AT模式 | |
| 消息驱动 | Spring Cloud Stream(推荐) | |
| 链路追踪 | Spring Cloud Sleath + zipkin,Skywalking(推荐) |
3.Spring Cloud 和 Spring Cloud Alibaba的关系是怎样的?(必会)
Spring Cloud Alibaba 出现是为了解决 SpringCloud中相关组件不维护的问题,不是替代SpringCloud的,而是对SpringCloud的增强,所以Alibaba和SPringCloud可以配合使用。
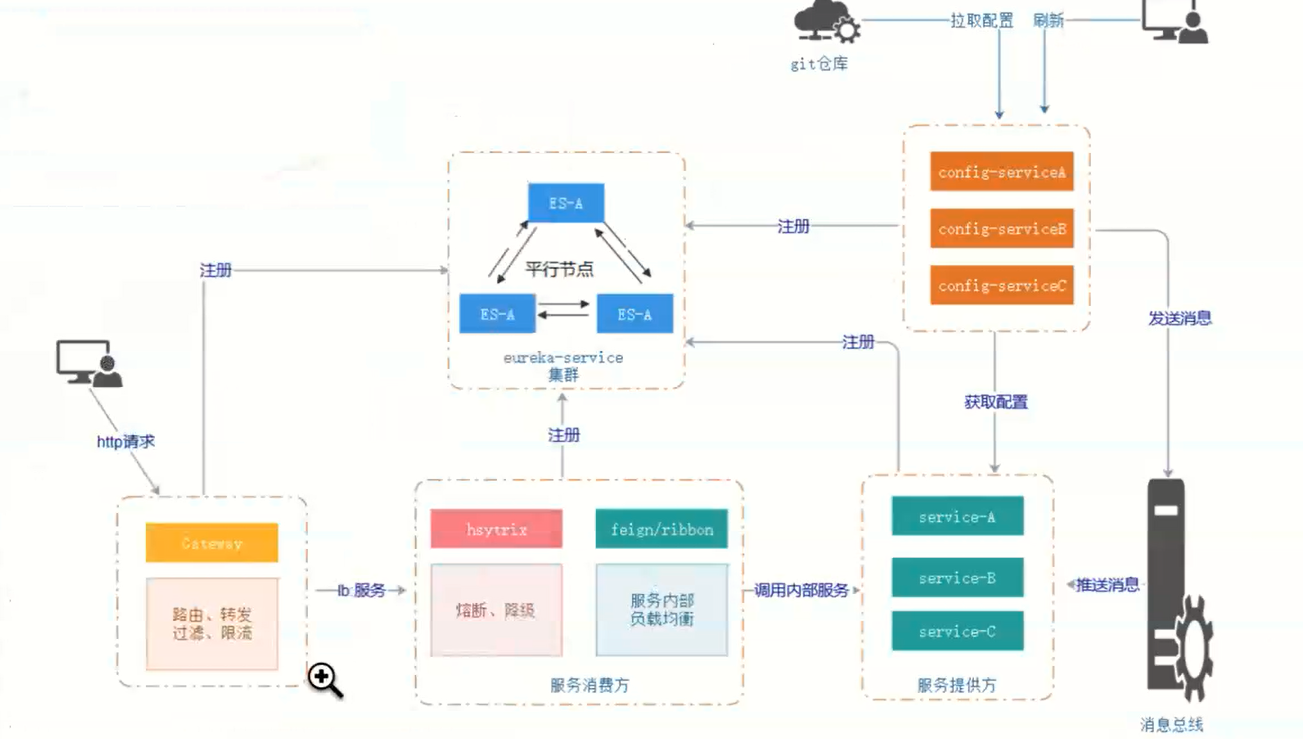
4.请讲一下Eureka的服务注册与发现的执行流程?(必会)
服务提供者:
a.启动后,向注册中心发起register请求,注册服务;
b.在运行过程中,定时向注册中心发送renew心跳,证明我还活着;【心跳检测机制】
c.如果停止服务,服务提供者向注册中心发起cancel请求,清空当前服务注册信息。
服务消费者:
启动后,根据服务名称从注册中心拉取服务注册信息;在运行过程中,定时更新服务注册信息。
注册中心:
a.启动后,在其他节点同步服务注册信息;
b.运行过程中,定时运行evct任务,剔除没有按时renew的服务(包括非正常停止和网络故障的服务)。
c.运行过程中,接收到register、renew、cancel,getRegister请求后,清空二级缓存,即readWriteCacheMap,主要作用是保证数据的一致性,都会同步至其他注册中心节点
5.请简要描述一下eureka的心跳检测机制【服务续约】。(必会)
服务注册后,要定时(默认30s,可自己配置)向注册中心发送请求,告诉注册中心“我还活着”。
注册中心收到续约请求后:
a.更新服务对象的最近续约时间,即Lease对象的lastUpdateTimestamp【0>45】;
b.同步服务消息,将此事件同步至其他的Eureka Server节点;
c.剔除服务之前会先判断服务是否已经过期(心跳超时时间),判断服务是否过期的条件之一是续约时间和当前时间的差值是不是大于阈值。
背诵并记忆
心跳续约时间: 30s
定时扫描间隔: 30s
心跳的超时时间:90s
6.请简要描述一下eureka的服务剔除以及保护机制。(必会)
服务剔除:
a.服务正常停止之前都会向注册中心发送注册请求,告诉注册中心“我要下线了”;
b.注册中心接收到cancel请求后:
1. **剔除服务信息,将服务信息从registry注册表中剔除;**1. **更新队列,将此事件添加到更新队列中,供Eureka Client增量同步服务信息使用;**1. **清空二级缓存,即readWriteCacheMap,用于保护数据的一致性;**1. **更新阈值,供剔除服务使用;**1. **同步服务信息,将此事件同步至其他的Eureka Server节点;**1. **服务正常停止才会发送Cancel请求,如果是非正常停止,则不会发送,此服务由Eureka Server主动剔除。**
保护机制:
a.未开启自我保护机制,则直接进入服务剔除流程;
b.开启自我保护机制,进一步判断是Server出问题还是Client出问题:
1. **判断依据实际续约数是否大于自我保护阈值;**1. **只有大于阈值(客户端出问题),才会进入剔除流程;**
自我保护阈值是区分Client还是Server出问题的临界值;如果超出阈值就表示大量服务可用,认为Eureka Client出了问题。如果未超出阈值就表示大量服务不可用,认为Server出问题了。
计算剔除数:
如:服务数100个,续约百分比阈值是85%,最大剔除数:100*(1-85%)=15个。
7.Ribbon的负载均衡策略有哪些?(高薪提问)*负载均衡策略: 至少要记住三个以上**
| 策略名 | 规则描述 | ||
|---|---|---|---|
| RoundRobinRule | 简单轮询服务列表来选择服务器 | ||
| AvailablityFilteringRule | a.过滤掉那些因为一直连接失败的被标记为circuit tripped的后端server; b.过滤掉那些高并发的的后端server(active connections 超过配置的阈值),并发连接数的上限。 |
||
| WeightedResponseTimeRule | 为每一个服务器赋予一个权重值,服务器响应时间越长,这个服务器的权重就会越小。权重值会影响服务器的选择。 | ||
| ZoneAvoldanceRule | 以区域可用的服务器为基础进行服务器的选择,使用Zone对服务器进行分类,而后再对Zone内的多个服务做轮询。(系统默认的方案) | ||
| BestAvailableRule | 忽略那些短路的服务器,并选择并发数较低的服务器。 | ||
| RandomRule | 随机选择一个可用的服务器 | ||
| RetryRule | 重试机制的选择逻辑 |
冷知识:
SpringCloud Alibaba dubbo 远程调用服务框架 RPC实现
SpringCloud Ribbon 组件服务调用框架 HTTP 协议
8.负载均衡的执行流程是怎样的?请描述一下。(必会)
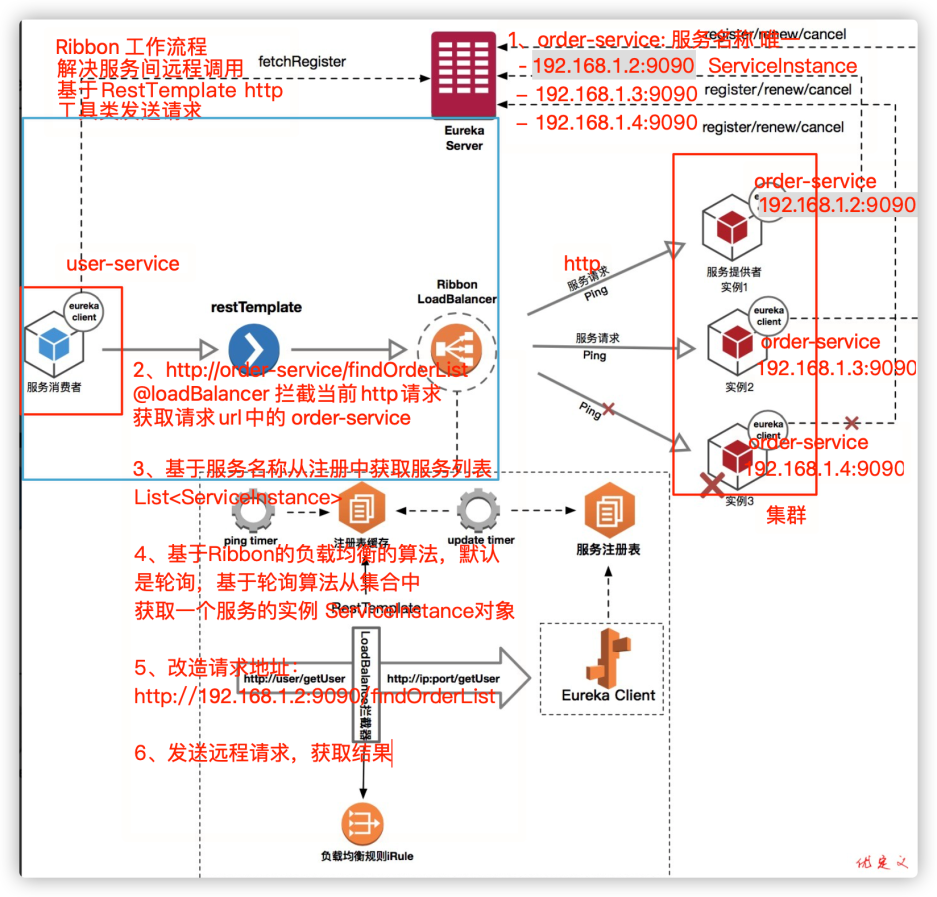
9.负载均衡的源码,自己讲4遍,第5遍结合项目的短信服务讲解。*
10.Feign的工作流程是怎样的?(必会)
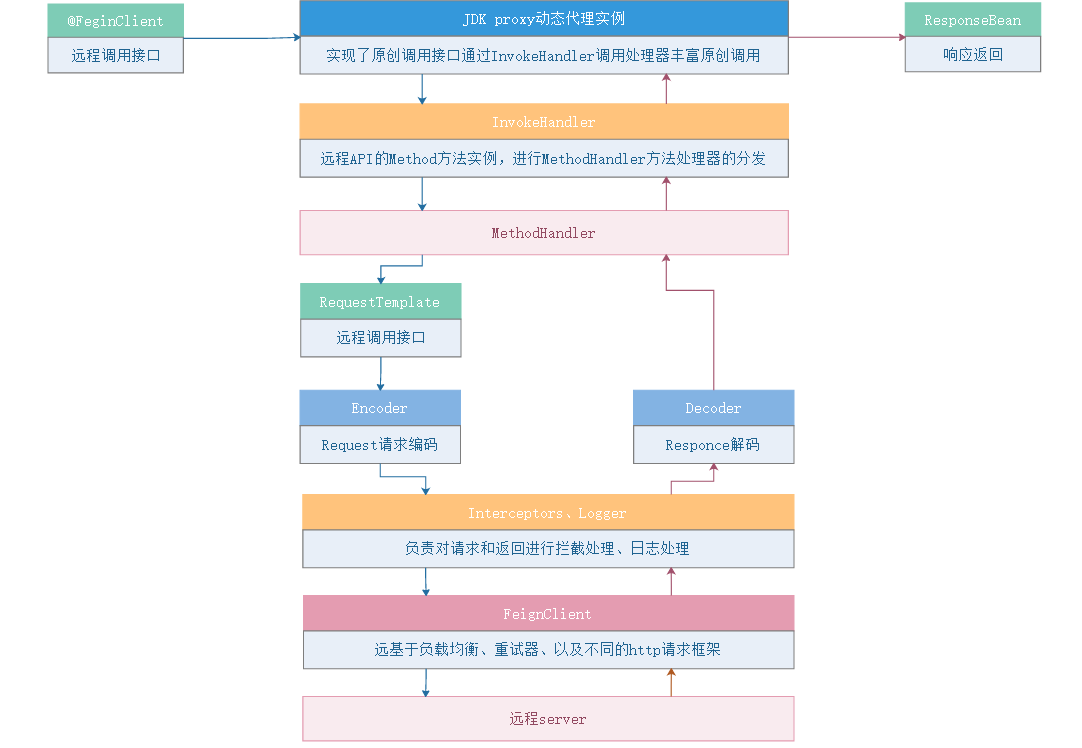
冷知识:
Feign 就是现在 SpringCloud OpenFeign ;
Feign底层就是基于Ribbon实现 ;
面向接口的远程调用,对SpringMVC增强 ;
Feign 底层是 JDK动态代理实现。
11.Feign调用服务失败,会重试吗?它的重试机制是啥?(必会)
配置:
module-user-service:ribbon:# NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule #配置规则 随机# NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RoundRobinRule #配置规则 轮询# NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RetryRule #配置规则 重试# NFLoadBalancerRuleClassName: com.netflix.loadbalancer.WeightedResponseTimeRule #配置规则 响应时间权重NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RoundRobinRuleConnectTimeout: 500 #请求连接超时时间ReadTimeout: 500 #请求处理的超时时间OkToRetryOnAllOperations: false #对所有请求都进行重试MaxAutoRetriesNextServer: 2 #切换实例的重试次数MaxAutoRetries: 1 #对当前实例的重试次数
重点关注:**MaxAutoRetriesNextServer: 2 #切换实例的重试次数**
** MaxAutoRetries: 1 #对当前实例的重试次数**
Feign的调用次数=MaxAutoRetries+MaxAutoRetriesNextServer+(MaxAutoRetries *MaxAutoRetriesNextServer)+1,即1+2+(2X1)+1=6次
当ribbon超时后且hystrix没有超时,便会采取重试机制。当OkToRetryOnAllOperations设置为false时,只会对get请求进行重试。如果设置为true,便会对所有的请求进行重试,如果是put或post等写操作,如果服务器接口没做==幂等性==,会产生不好的结果,所以OkToRetryOnAllOperations慎用。
如果不配置ribbon的重试次数,默认会重试一次 。默认情况下,GET方式请求无论是连接异常还是读取异常,都会进行重试,非GET方式请求,只有连接异常时,才会进行重试。
12.Feig的超时时间是怎么设置的?Feign和Ribbon的区别是啥?
Feign的超时时间 = Ribbon的超时时间 + Hystrix的超时时间
module-user-service:ribbon:ConnectTimeout: 500 #请求连接超时时间ReadTimeout: 500 #请求处理的超时时间MaxAutoRetriesNextServer: 2 #切换实例的重试次数MaxAutoRetries: 1 #对当前实例的重试次数hystrix:command:default:execution.isolation.thread.timeoutInMilliseconds: 5000 # 熔断超时时间
一般情况下,ribbon 的总超时时间(<)hystrix的超时时间
Hystrix的超时时间 = ReadTimeout(MaxAutoRetries+MaxAutoRetriesNextServer+(MaxAutoRetries MaxAutoRetriesNextServer)+1),即(1+2+(2X1)+1)X500=3000。
区别:
| Feign | Ribbon | |
|---|---|---|
| **Feign 采使用接口的方式,将需要调使用的方法声明即可,不需要自己构建 Http 请求。不过要注意的是声明方法的注解、方法签名要和提供服务的方法完全一致。** | Ribbon 需要自己构建 Http 请求,模拟 Http 请求而后用 RestTemplate 发送给其余服务,步骤相当繁琐。 | |
12.什么是微服务的级联失败(雪崩问题)?解决方案是什么?(必会)
微服务架构中服务间调用关系错综复杂,一个服务的业务,有可能需要调用多个其它微服务,才能完成,当一个服务发生故障,调用这个服务也会发生故障造成阻塞。请求阻塞后,用户得不到响应,则tomcat(默认支持150个并发)的这个线程不会释放,于是越来越多的用户请求到来,越来越多的线程会阻塞。由于服务器支持的线程和并发数有限,请求一直阻塞,会导致服务器资源耗尽,从而导致所有其他服务都不可用,形成雪崩效应。
解决方案一:线程隔离(了解)仓壁模式(大船)
Hystrix为每个服务调用的功能分配一个小的线程池,如果线程池已满调用将被立即拒绝,默认不采用排队.加速失败判定时间,用户的请求将不再直接访问服务,而是通过线程池中的空闲线程来访问服务,如果线程池已满,或者请求超时,则会进行降级处理:返回给用户一个错误提示或备选结果。
解决方案二:服务熔断和服务降级*(服务熔断是手段,服务降级是结果。基于保险丝的思想。)
服务降级:
Fallback相当于是降级操作. 对于查询操作, 我们可以重写一个fallback方法, 当请求后端服务出现异常的时候, 可以使用fallback方法返回的值. fallback方法的返回值一般是设置的默认值或者来自缓存,当然,降级方法需要配置和编码,服务降级的目标是为了更友好的提示,如果你有备选服务组的话,可以走备选服务组,以最大限度的保存程序的高可用
服务熔断:
断路器很好理解, 当Hystrix Command请求后端服务失败数量超过一定比例(默认50%), 断路器会切换到开路状态(Open). 这时所有请求会直接失败而不会发送到后端服务. 断路器保持在开路状态一段时间后(默认5秒), 自动切换到半开路状态(HALF-OPEN). 这时会判断下一次请求的返回情况, 如果请求成功, 断路器切回闭路状态(CLOSED), 否则重新切换到开路状态(OPEN). Hystrix的断路器就像我们家庭电路中的保险丝, 一旦后端服务不可用, 断路器会直接切断请求链, 避免发送大量无效请求影响系统吞吐量, 并且断路器有自我检测并恢复的能力。
断路器的三种状态:CLOSED(所有服务都可用)、OPEN(所有服务都不可用)、HALF-OPEN(允许部分服务可用):这是一种中间状态。
三种状态之间是怎么转换的?
a.失败比例超过50%,触发断路器从CLOSED状态->OPEN状态;
b.保持在OPEN状态一段休眠时间后(默认5s),自动切换到HALF-OPEN状态,允许部分服务可以访问;
c.判断部分服务请求的成功率,如果超过50%就从HALF-OPEN状态切换到CLOSED状态;否则就从HALF-OPEN状态切换到OPEN状态,再次进入休眠时间。**
hystrix:command:default:execution.isolation.thread.timeoutInMilliseconds: 2000 # 超时时间circuitBreaker:requestVolumeThreshold: 10 #触发熔断的最小请求次数,默认20errorThresholdPercentage: 50 #触发熔断错误比例阈值,默认值50%sleepWindowInMilliseconds: 10000 #熔断后休眠时长,默认值5000毫秒
13.Spring Cloud GateWay网关的作用是什么,有哪些功能?可以结合项目来讲(统一认证和权限模块)(必会)
作用:
| 协议转换,路由转发 | ||
|---|---|---|
| 流量聚合,对流量进行监控,日志输出 | ||
| 作为整个系统的,对流量进行控制,有限流的作用 | ||
| 作为系统的前端边界,外部流量只能通过网关才能访问系统 | ||
| 可以在网关层做权限的判断 | ||
| 可以在网关层做缓存==》全局过滤器 |
功能:路由转发、流量监控、限流(令牌桶算法Redis)、日志、认证鉴权、跨域处理
14.Spring Cloud GateWay网关的执行流程是怎样的?(必会)
1)客户端向Spring Cloud GateWay发出请求;
2)由GateWay Handler Mapping确定请求与路由匹配,则将其发送到GateWay Web Handler;
3)Handler通过指定的过滤器链将请求发送到我们实际的服务执行逻辑,然后返回;
4)过滤器由虚线分隔的原因是,过滤器可以在发送代理请求之前或之后执行逻辑;
GateWayFilter和GlobalFilter的区别:
GateWayFilter:需要通过**spring.cloud.routes.filters**配置在具体路由下,只作用在当前路由上或通过**spring.cloud.default.filter**配置在全局,作用在所有路由上。
GlobalFilter:全局过滤器,不需要配置即可作用在所有路由上,其核心是**GateWayFilterChain**作用为请求业务以及路由的URL转换为真实业务服务的请求地址。
15.网关中断言匹配是什么? 你们项目中用的是什么? 还有哪些?(必会)
spring:cloud:gateway:routes:- id: module-user-feign #从eureka中找到服务uri: lb://module-user-feignpredicates:- Path=/user/** #路径断言- Method=POST #如果添加这个断言,则表示、/user/**中所有的POST请求走此路由- id: module-user-service #从eureka中找到服务uri: lb://module-user-servicepredicates:- Path=/user/** #路径断言- Method=GET #如果添加这个断言,则表示、/user/**中所有的GET请求走此路由
重点:路径断言**Path=/user/** #路径断言**,请求方式断言**Method=POST #如果添加这个断言,则表示、/user/**中所有的POST请求走此路由**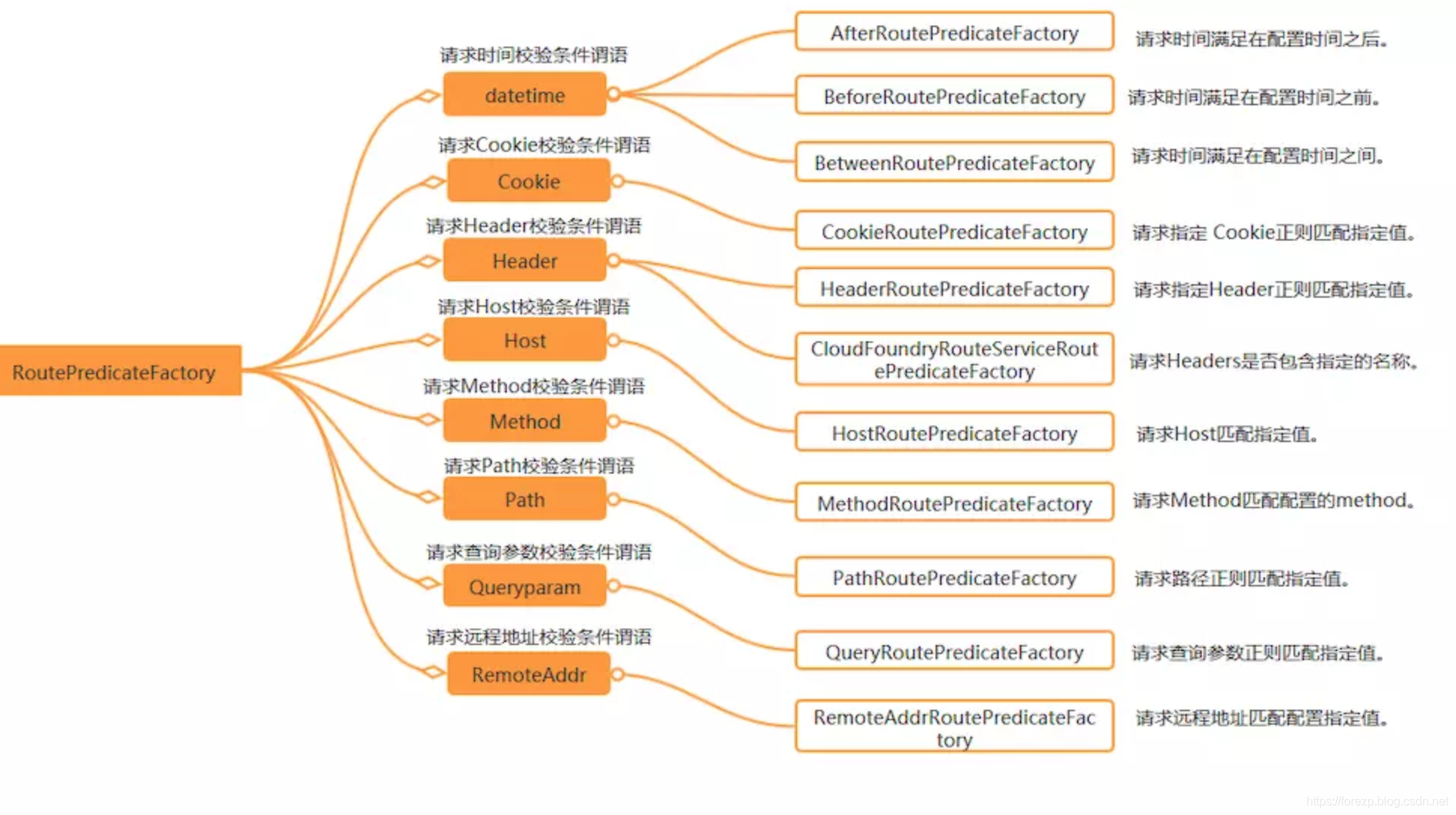
datetime(请求时间校验)、cookie(请求Cookie校验)、header(请求Header校验)、Host(请求Host校验)、Method(请求Method校验)、path(请求Path校验)、queryParam(请求查询参数校验)、RempteAddr(强求远程地址校验)一共有八种。
冷知识:
网关使用需要基于 注册中心(nacos、eureka);
网关也具备负载均衡功能,功能实现基于Ribbon,默认负载均衡的算法是 轮询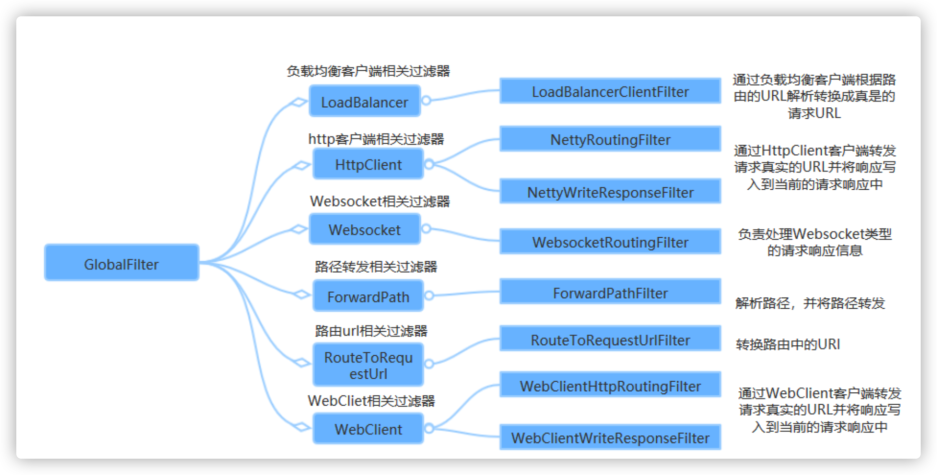
RabbitMQ消息中间件篇**
1、RabbitMQ 工作模式
| Basic Queue(简单队列) | 是MQ最简单的工作模式 | |
|---|---|---|
| Work Queue(工作队列) | 让多个消费者绑定到一个队列,共同消费队列的消息,默认平均分配,可以通过配置改为能者多劳**prefetch**的分配 |
|
| Fanout(广播模式) | 交换机的作用:接收生产者发送的消息;将消息按照规则路由到与之绑定的队列;不能缓存消息,存在路由失败,消息丢失的问题; | |
Direct(订阅模式) | 队列与交换机的绑定,要指定一个RoutingKey(路由key);
消息的发送方在向Exchange发送消息时,也必须指定消息RoutingKey;
交换机根据消息的Routing Key进行判断,只有队列的Routing Key与消息的Routing Key完全一致,才会接收到消息。 | |
| Topic(主题模式) | 和Direct相比Exchange多了一个通配符。#代表匹配一个或多个词;*代表匹配不多不少恰好一个词 | |
2、MQ如何保证顺序消费
通过一个queue对应一个consumer,然后这个consumer内部使用List集合做排队,然后分发给底层不同的thread来处理,而且还支持高并发。
3、MQ如何消息不丢失,持久化
Exchange交换机的持久化
在RabbitMQ中交换机默认是非持久化的,mq重启之后就丢失,但是在SpringAMQP中可以通过代码指定交换机持久化:**new DirectExchange("simple.direct",true,false)**,三个参数分别代表:交换机名称,是否开启持久化,当没有queue与其绑定时是否自动删除。在默认情况下,由SpringAMQP声明的交换机都是持久化的
queue队列的持久化
在RabbitMQ中队列默认是非持久化的,mq重启之后就丢失,但是在SpringAMQP中可以通过代码指定代码持久化:**new Queue("simple.queue",true)**,三个参数分别代表:交换机名称,是否开启持久化。在默认情况下,由SpringAMQP声明的队列都是持久化的。
消息的持久化
利用SpringAMQP发送消息时,可以设置消息的属性,指定delivery-mode。在默认情况下,SpringAMQP发出的任何消息都是持久化的,不用特意去指定。
4、MQ的消息确认机制
生产者确认机制
RabbitMQ提供了生产者确认机制来避免消息发送到MQ过程中丢失的问题,给每一个消息指定唯一ID。消息发送到MQ以后,会返回一个结果给发送者,表示消息是否处理成功。
返回结果有两种:
a.发送者确认:消息成功投递到交换机,返回ACK,如果消息未投递到交换机,返回NACK;
b.发送者回执:消息投递到交换机,但是没有路由到队列,返回ACK及路由失败的原因。
tip:确认机制发送消息时,需要给每个消息设置一个全局唯一id,以区分不同消息,避免ack冲突。
消费者确认机制
RabbitMQ确认消息被消费者消费后会立刻删除机制。通过消费者回执来确认消费者是否成功处理消息的:消费者获取消息后,应该向RabbitMQ发送ACK回执,表明自己已经处理消息。
SpringAMQP允许配置三种确认模式:
a.manual:手动ACK,需要在业务代码结束后,调用api发送ACK;可以根据业务情况来判断什么时候该ACK
b.auto:自动ACK,由spring检测Listener代码是否出现异常,没有异常则返回ACK;抛出异常则返回NACK;类似事务机制,出现异常消息回滚到MQ;没有异常正常消费。默认使用的模式
c.none:关闭ACK,MQ假定消息者获取消息后会成功处理,因此消息投递后立即被删除。存在消息丢失的可能。
设想这样的场景:
- 1)RabbitMQ投递消息给消费者
- 2)消费者获取消息后,返回ACK给RabbitMQ
- 3)RabbitMQ删除消息
- 4)消费者宕机,消息尚未处理
5.MQ的失败重试机制
问题:当消费者出现异常后,消息会不断requeue到队列,再重新发送给消费者,然后再次异常,再次requeue无限循环,导致MQ的消息处理飙升,带来不必要的压力;
解决方案:
在配置文件中设置**rabbitmq.listener.retry.enable:true # 开启消费者失败重试**,**rabbitmq.listener.retry.max-attempts:3 #最大重试次数**。
开启本地重试时,消息处理过程中抛出异常,不会requeu到队列,而是在消费者本地重试。
重试达到最大次数后,Spring会返回ACK,消息会被丢弃。
失败策略(重试机制的优化):
问题:当消息达到最大重试次数后,消息会被丢弃,这是由Spring内部机制决定的,这样是不可取的。
解决方案:
在开启重试模式后重试次数耗尽,如果消息依然失败则需要将消息投递到一个指定的专门存放异常消息的队列,后续由人工集中处理。具体实现:**MessageRecovery**接口来处理,它包含三个实现类:
a.**RejectAndDontRequeueRecoverer**:重试耗尽后,直接拒绝,丢弃消息。默认采取的方式;
b.**ImmediateRequeueMessageRecoverer**:重试耗尽后,返回NACK,消息重新进入队列;
c.**RepublishMessageRecoverer**:重试耗尽后,将失败消息投递到指定的交换机(推荐)。
死信交换机:
什么是死信消息:a.消息被消费者reject或者返回NACK;b.消息超时未消费;c.队列满了。
使用场景:
a.如果队列绑定了死信交换机,死信消息会被投递到死信交换机;
b.可以利用死信交换机收集所有消费者处理失败的消息(死信),交由人工统一处理,进一步提高消息队列的可靠性。
TTL(消息超时):
消息超时的两种方式:a.给队列设置超时时间,进入队列后超过超时时间的消息变为死信消息;b.给消息设置超时时间,队列接收到消息超过超时时间后变为死信消息。
如何实现发送一个消息20秒后消费者才收到消息?
a.给消息的目标队列指定死信交换机;b.将消费者监听的队列绑定到死信交换机;c.发送消息时给消息设置超时时间为20s。
死信交换机 + TTL = 延迟队列:*
使用场景:a.延迟发送短信;b.用户下单,如果用户在15分钟内未支付,则自动取消;c.预约工作会议,20分钟后自动通知所有参会人员。
使用:a.声明一个交换机,添加delayed属性为true;b.发送消息时,添加X-delay头,值为超时时间。
tip:RabbitMQ本身是不支持延迟队列的,但是可以通过官方推出DelayExchange插件来实现
6、MQ高可用
MQ的集群分类
| 普通集群 | 是一种分布式集群,将队列分散到集群的各个节点,从而提高整个集群的并发能力。但是当队列所在节点宕机,队列中的消息就会丢失(不推荐) | |
|---|---|---|
| 镜像集群 | 是一种主从集群,在普通集群的基础上,添加了主从备份功能,提高集群的数据可用性。不是强一致性的,也存在数据丢失的风险(不推荐) |
仲裁队列(RabbitMQ3.8以后推出的)
仲裁队列是替代镜像集群的,底层采用了Raft协议(一致性算法)来确保主从的数据一致性。
特征:a.与镜像队列一样,都是主从模式,支持主从数据同步;b.使用非常简单,没有复杂的配置;c.主从同步是基于Raft协议,强一致性。
JAVA代码创建仲裁队列@Beanpublic Queue quorumQueue() {return QueueBuilder.durable("quorum.queue") // 持久化.quorum() // 仲裁队列.build();}
7、消息生产方将消息成功投递到消息消费方,消息消费成功了, 业务逻辑执行失败了, 问怎么办?(结合项目回答)
自动确认机制 改成 手动确认,在业务逻辑 try…catch{} 拒绝接收,消息重放到MQ队列
项目中的应用: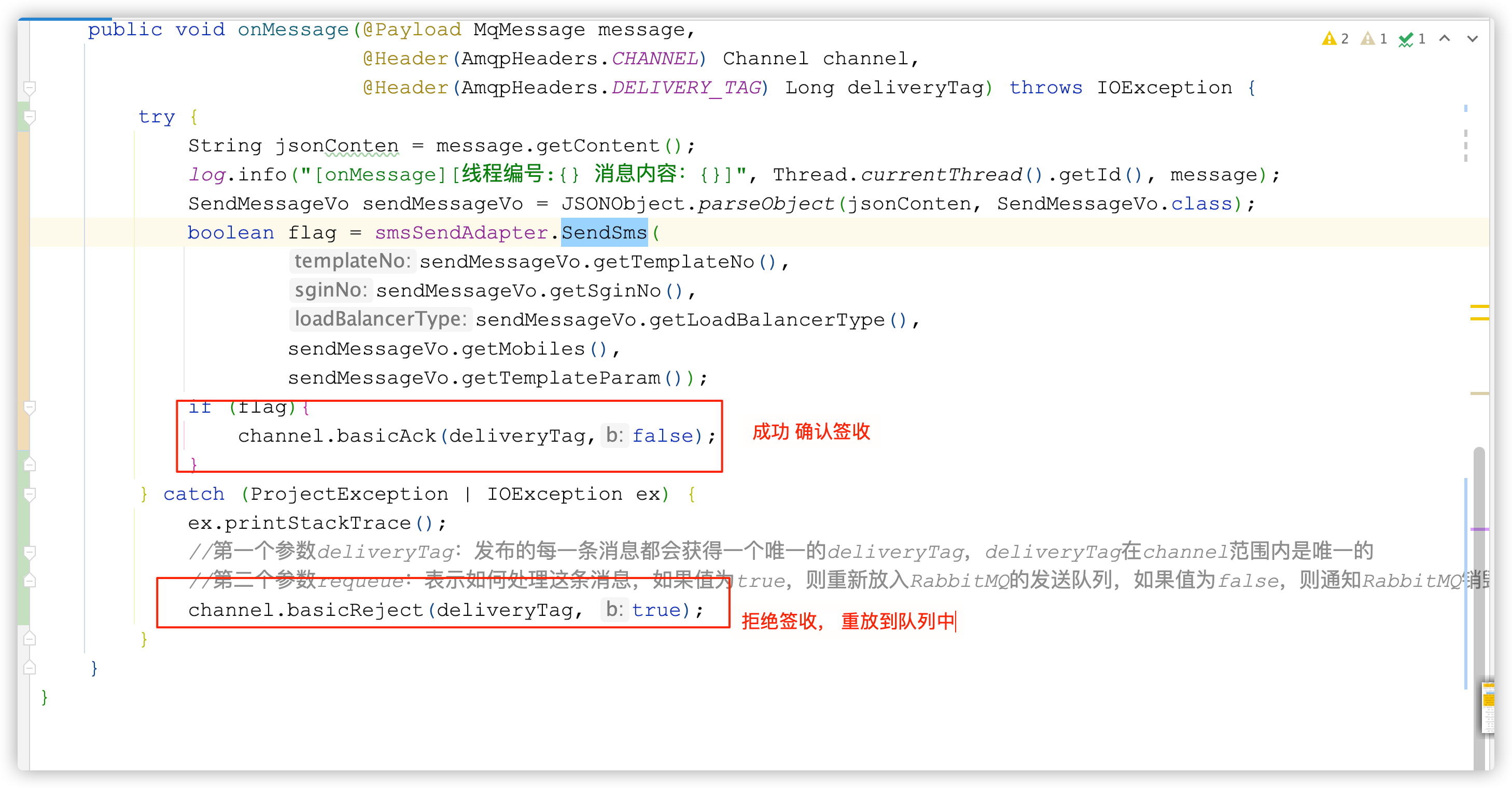
8、MQ消息堆积问题(结合项目回答)
消息堆积问题:当生产者发送消息的速度超过了消费者处理消息的速度,就会导致队列中的消息堆积,直到队列存储消息达到上限,之后发送的消息就会成为死信,可能会被丢弃。
解决方案:
a.队列上绑定多个消费者,提高消费速度(项目采取的方案)
b.使用惰性队列,可以在mq中保存更多消息。
惰性队列的优点:
基于磁盘存储,消息上限高;没有间歇性的page-out,性能比较稳定;
惰性队列缺点:
基于磁盘存储,消息时效性会降低;性能受限于磁盘的IO。
多线程消息 + 一个线程一次去多少条消息
短信服务的解决方案: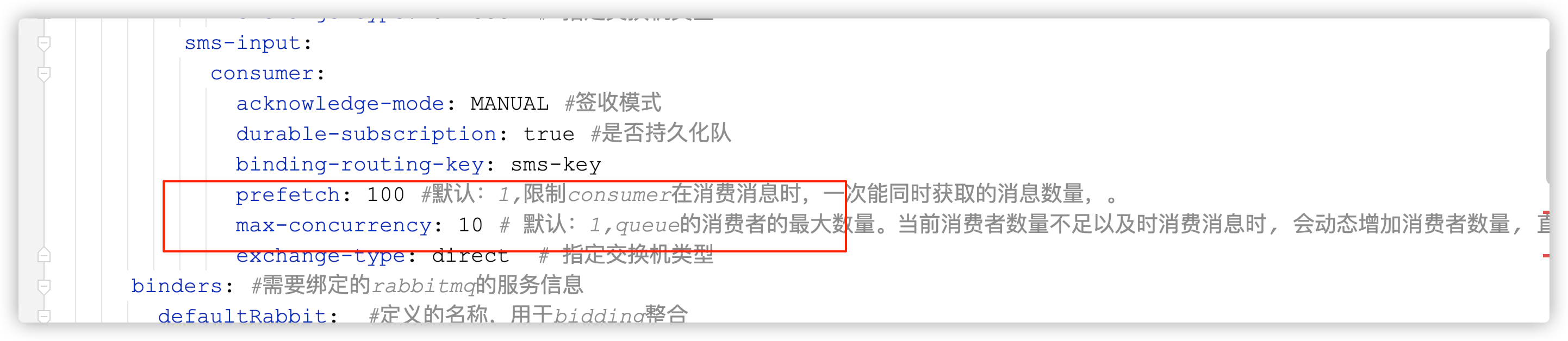

若有收获,就点个赞吧
0 人点赞
