一维列表展开为二维列表
A = [1, 3, 4, 4, 5, 5]list(zip(*[iter(A)] * 2))"""[(1, 2), (3, 4), (5, 6)]"""
二维列表展开为一维列表
B = [(1, 2), (3, 4), (5, 6)]import itertoolsprint(list(itertools.chain.from_iterable(B)))"""[1, 2, 3, 4, 5, 6]"""
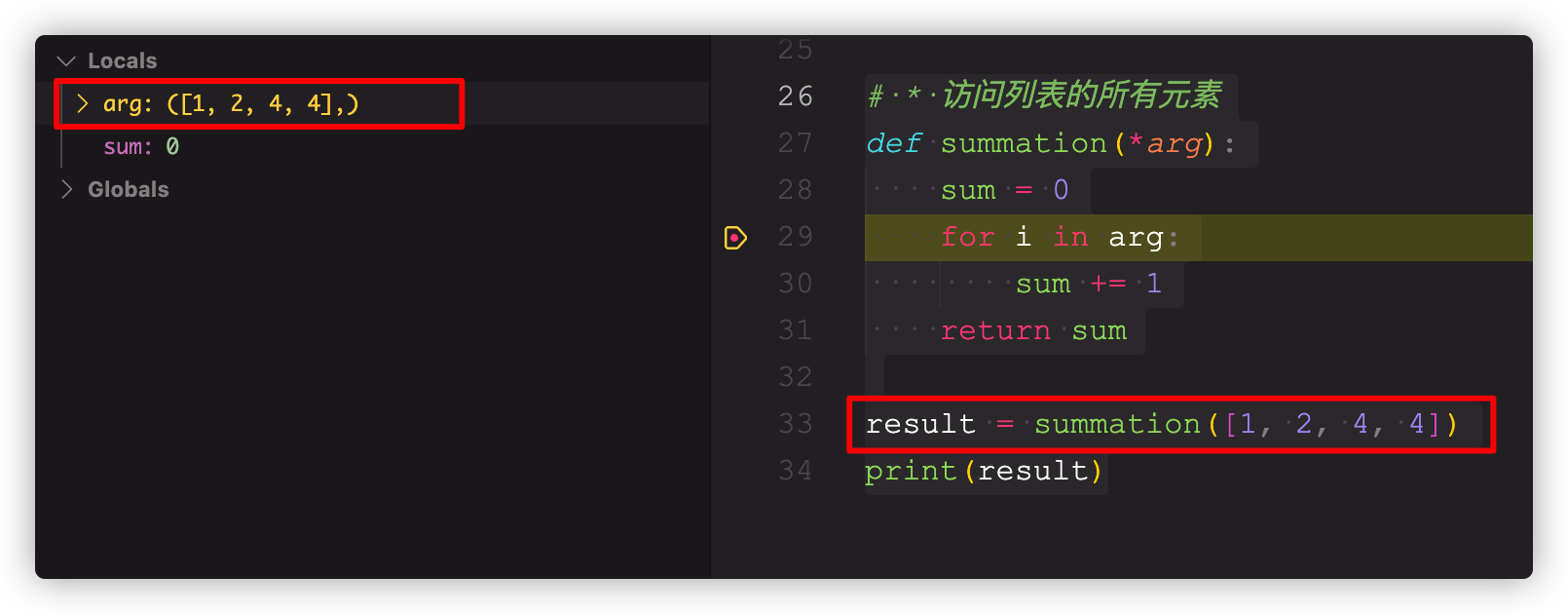
使用*访问列表中的每个元素
# * 访问列表的所有元素def summation(*arg):sum = 0for i in arg:sum += 1return sumresult = summation([1, 2, 4, 4]) # 这种传参方式会把列表当作可变位置参数的一项,见下文截图print(result)

在同一行中打印多个元素
print("111", '2222', end=' ')print('3333', end='\n')"""111 2222 3333"""
在一行代码中合并 2 个字典
first_dct = {"a": 1, "b": 2}second_dct = {"c": 3, "d": 4}print({**first_dct, **second_dct})"""{'a': 1, 'b': 2, 'c': 3, 'd': 4}"""
for实现死循环
# iter除了可以将列表转化为迭代器,还能接受一个callable对象,和一个sentinel参数,当第一个对象返回sentinel值才结束for i in iter(int, 1):pass
关闭异常自动关联上下文
try:print(1 / 0)except Exception as exc:raise RuntimeError("something bad happened")"""Traceback (most recent call last):File "/home/worktests/base/descriptor_test.py", line 344, in <module>print(1 / 0)ZeroDivisionError: division by zeroDuring handling of the above exception, another exception occurred:Traceback (most recent call last):File "/home/work/base/descriptor_test.py", line 346, in <module>raise RuntimeError("something bad happened")RuntimeError: something bad happened"""# 通过from 限制新异常是由哪个异常引起的try:print(1 / 0)except Exception as exc:raise RuntimeError("something bad happened") from exc"""Traceback (most recent call last):File "/home/work/tests/base/descriptor_test.py", line 364, in <module>print(1 / 0)ZeroDivisionError: division by zeroThe above exception was the direct cause of the following exception:Traceback (most recent call last):File "/home/workts/base/descriptor_test.py", line 366, in <module>raise RuntimeError("something bad happened") from excRuntimeError: something bad happened"""# 使用raise ... from None 彻底关闭自动关联异常上下文try:print(1 / 0)except Exception as exc:raise RuntimeError("something bad happened") from None"""Traceback (most recent call last):File "/home/work/tests/base/descriptor_test.py", line 387, in <module>raise RuntimeError("something bad happened") from NoneRuntimeError: something bad happened"""
使用自带缓存机制
from functools import lru_cache"""maxsize: 最多可以缓存多少个此函数的调用结果,为None时无限制typed:为true,则不同参数类型的调用分别缓存"""# @lru_cache(maxsize=1, typed=True)@lru_cache(None)def add(x, y):print("计算结果:%s + %s" % (x, y))return x + yprint(add(2, 8))print(add(22, 8))print(add(222, 8))print(add(2, 8))# 计算结果:2 + 8# 10# 10# 10
流式读取超大文件
filename = "test.py"def read_file(filename, block_size = 1024 * 8):with open(filename, "r") as fp:while True:chunk = fp.read(block_size) # 设置读取多少个字符if not chunk:print("已读取完毕")breakyield chunkres = read_file(filename=filename)print(res) # 生成器对象for i in res:print(i)
逗号的独特用法
# 元组的转化def func():return "test",print(func()) # ('test',)
运行代码时查看源代码
# 运行代码查看源代码import inspectdef add(x, y):return x + yprint("#"* 90)print(inspect.getsource(add))
字典访问不存在的key不报错
# 方式一import collectionsprofile = collections.defaultdict(int)# 使用匿名函数# profile = collections.defaultdict(lambda : "this is default value")print(profile["a"]) # 0profile["a"] = 1print(profile["a"]) # 1# 方式二profile1 = {}print(profile1["a"]) # KeyError: 'a'print(profile1.get("a", 100)) # 100
利用any替换for循环
# 利用any 替代for循环things = [2, 4, 1, 3]found = Falsefor thing in things:if thing == 1:found = Truebreakprint("found: {}".format(found))# found: True# 等同上for循环效果found_2 = any(thing == 1 for thing in things)print("found_2: {}".format(found_2)) # found_2: True
parse库-优雅解析规范的字符串
from parse import parsebefore_data = ('cookie=0x9816da8e872d717d, duration=298506.364s, table=0, n_packets=480')print(f"before_data: {before_data}")# before_data: cookie=0x9816da8e872d717d, duration=298506.364s, table=0, n_packets=480parse_result = parse('cookie={cookie}, duration={duration}, table={table}, n_packets={n_packets}', before_data)print(f"parse_result: {parse_result}")# parse_result: <Result () {'cookie': '0x9816da8e872d717d', 'duration': '298506.364s', 'table': '0', 'n_packets': '480'}>print(f'cookie: {parse_result["cookie"]}') # cookie: 0x9816da8e872d717d# 解析没有定义字段名字的情况before_data_2 = 'I am zaygee, 26 years old'parse_2_result = parse("i am {}, {} years old", before_data_2)print(f"parse_2_result: {parse_2_result}") # parse_2_result: <Result ('zaygee', '26') {}># 解析类似字典的实例的情况parse_3_result = parse("i am {name}, {age} years old", before_data_2)print(f"parse_3_result: {parse_3_result}") # parse_3_result: <Result () {'name': 'zaygee', 'age': '26'}>print(parse_3_result["name"]) # zaygee
根据进程名称模糊匹配获取pid
import subprocessfrom typing import Listdef get_pid_by_process_name(name: str)->List[int]:"""根据进程名称grep 匹配获取pid"""results = subprocess.Popen(['pgrep', '-f', name], stdout=subprocess.PIPE, shell=False)response = results.communicate()[0]return [int(pid) for pid in response.decode('utf-8').split() if response]if __name__ == '__main__':get_pid_by_process_name(name='tongxue')

若有收获,就点个赞吧
0 人点赞
