概念
树
Tree,树,表示一种分层数据模型。
节点间的关系是分层、从属的关系。其顶点(分层关系中最上层)我们称之为根结点。其最下层(某些节点是没有子节点的)称之为叶子节点。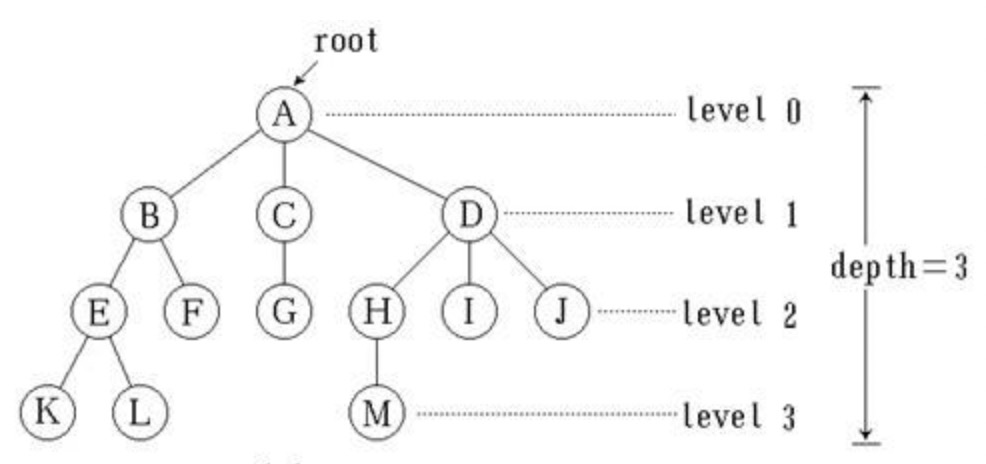
树在前端中比较常见,在编程中经常会遇到这种数据结构。
比如目录、比如级联选择器,或者我们常常讲,DOM或者virtualDOM,最终都是抽象成树这个数据结构。
二叉树
有一类比较常见的特殊的树,叫二叉树,Binary Tree。
二叉树的特点是,每一个节点最多可能有两个子节点,而且这两个子节点是有次位的,分别是左,右,子节点被称之为左子树、右子树。
更有一些特殊的二叉树:
- 满二叉树:除了叶子节点外,每个节点都有左右两个子节点,这种二叉树叫做满二叉树
- 完全二叉树:叶子节点都在最底下两层,最后一层叶子节都靠左排列,并且除了最后一层,其他层的节点个数都要达到最大(满二叉树),这种二叉树叫做完全二叉树。
有重要关系是:
满二叉树的节点和层级的关系,假设满二叉树有n个节点,一共有h层
换一种写法:
另外还有一个数据结构概念,堆:
堆是一种完全二叉树,它的特点是任何一个节点的子节点一定比其父节点大(或者小),如果整棵树都是比父节点大,它是一个最小堆,反之,则是最大堆。
JS常用的Tree数据结构
我们常见这样的表现形式
// 常见这样表示的interface TreeNode {value: any;children: Array<TreeNode>;}// 比如这样const tree: TreeNode = {value: 'a',children: [{value: 'x',children: [{ value: '1' }],},{value: 'y',children: [{ value: '2' }],},],};
二叉树常常被这样表示:
// 常见这样表示的interface BTreeNode {value: any;left: BTreeNode;right: BTreeNode;}// 比如这样const tree: BTreeNode = {value: 'a',left: {value: 'x',},right : {value: 'rightx',left: { value: 666 },right: { value: 888 },}};
遍历树
遍历树是最基本最常见的操作了。
普通的树分为:DFS(Depth First Spread,深度优先)、BFS(Breadth First Spread,广度优先)。
DFS
深度优先最常见的思路就是递归调用。
const dfs => root => {console.log('遍历', root.value);if(root.children){root.children.forEach(n => {dfs(n);})}}dfs(tree);
不过可以利用栈做迭代来进行DFS。
const stack = [tree];while(queue.length > 0) {const node = stack.pop();console.log('遍历', node.value);if(node.children) {node.children.forEach(n => {queue.push(n);})}}
BFS
广度优先遍历需要利用Queue。
const queue = [tree];while(queue.length > 0) {const node = queue.shift();console.log('遍历', node.value);if(node.children) {node.children.forEach(n => {queue.push(n);})}}
二叉树遍历(递归)
先序遍历
记住先序访问顺序:根-左-右
const preOrder = root => {if(!root) return;const { value, left, right } = root;console.log('遍历,', value);left && preOrder(left);right && preOrder(right);}
中序遍历
访问顺序:左-根-右
const inOrder = root => {if(!root) return;const { value, left, right } = root;left && inOrder(left);console.log('遍历,', value);right && inOrder(right);}
后续遍历
访问顺序:左-右-根
const postOrder = root => {if(!root) return;const { value, left, right } = root;left && postOrder(left);right && postOrder(right);console.log('遍历,', value);}
这里我们发现,用递归遍历的写法倒是很好理解,按照访问顺序调用递归函数就行。
二叉树遍历(迭代)
先序遍历
先序遍历其实就是二叉树版本的深度优先遍历,所以可以借助深度优先遍历的方法:
const stack = [tree];while(stack.lenght > 0) {const { value, left, right } = stack.pop();console.log('遍历,', value);// 因为是栈所以顺序是先右right && stack.push(right);left && stack.push(left);}
中序遍历
中序遍历是左-根-右,其思路是,每当遇到一个节点,就把一路碰到的所以节点的left都放到栈中。然后出栈,出栈的过程中,对right也进行这样的操作,就是把right也当作一个节点。
const stack = [];let p = root;while(stack.lenght > 0 || p){while(p) {stack.push(p);p = p.left;}const n = stack.pop();console.log('遍历,', n.value);p = n.right;}
后续遍历
非递归版后序遍历不太好理解。
简单的来说就是,左-右-根,就是根-右-左在栈中,然后出栈。
因为根-左-右是先序遍历,那么把先序遍历的左右顺序调整下,入栈,最终输出之前全部出栈就好.
const stack = [tree];while(stack.lenght > 0) {const n = stack.pop();const { value, left, right } = n;stack.push(n);// 因为是栈所以顺序是先右// right && stack.push(right);// left && stack.push(left);// 调整下顺序left && stack.push(left);right && stack.push(right);}while(stack.length > 0){console.log('遍历,', stakc.pop().value);}
笔试题
几种遍历
上文涉及的遍历都是重点
LeetCode 102: 二叉树的层序遍历
102. 二叉树的层序遍历
给你一个二叉树,请你返回其按 层序遍历 得到的节点值。 (即逐层地,从左到右访问所有节点)。
示例:
二叉树:[3,9,20,null,null,15,7],
3
/ \
9 20
/ \
15 7
返回其层次遍历结果:
[
[3],
[9,20],
[15,7]
]
这个思路就是,最外层的循环每次都将现有的元素出栈。
而现有的元素是当前遍历到元素的下一层级
所以内层循环出栈的次数是当前元素数量,尽管后续会增加元素,但是记住这个数量,在本次外层循环中只出栈这么多次就能保证。
_
LeetCode 102: 二叉树的最大深度
104. 二叉树的最大深度
给定一个二叉树,找出其最大深度。
二叉树的深度为根节点到最远叶子节点的最长路径上的节点数。
说明: 叶子节点是指没有子节点的节点。
示例:
给定二叉树 [3,9,20,null,null,15,7],
3
/ \
9 20
/ \
15 7
返回它的最大深度 3 。
LeetCode 111: 二叉树的最小深度
111. 二叉树的最小深度
给定一个二叉树,找出其最小深度。
最小深度是从根节点到最近叶子节点的最短路径上的节点数量。
说明: 叶子节点是指没有子节点的节点。
示例:
给定二叉树 [3,9,20,null,null,15,7],
3
/ \
9 20
/ \
15 7
返回它的最小深度 2.
二叉树深度问题其实很简单,就是遍历的过程中,可以讲当前深度带上,如果是叶子节点,和当前深度最值比较,然后更新最值,如果不是叶子节点,那么遍历后续节点记得深度加一。
最小深度的话,如果用广度优先遍历,第一次遇到叶子节点的深度就可以认为是最小深度,就没有必要继续下去了。
LeeCode 144、94、145: 前中后序遍历二叉树
144. 二叉树的前序遍历
94. 二叉树的中序遍历
145. 二叉树的后序遍历

若有收获,就点个赞吧
0 人点赞
