一、数据仓库
1、概念
数据仓库(Data Warehouse)是一个面向主题的(Subject Oriented)、集成的(Integrated)、相对稳定的(Non-Volatile)、反映历史变化的(Time Variant)数据集 合,用于支持管理决策(Decision Making Support)和信息的全局共享(Global Sharing of Information)。
2、作用
通过对数据的分析,得出各种指标,为决策做服务参考。也可以做为公司的数据集中的一个地方。
日志数据、数据库数据、外来买的其他数据— 将这些数据统一纳入我们的数据仓库,进行一个汇总。
3、特点
- 数据仓库的数据是面向主题的
2. 数据仓库的数据是集成的
3. 数据仓库的数据是非易失的
4. 数据仓库的数据是随时间不断变化的4、数据集市
统计出来的指标5、数据仓库的架构
1) inmon架构
2) kimball架构
两个架构,Kimball 我们使用的最多,因为它的层级少,比inmon少了一个数据集市的一层。因为比较的方便。
kimball架构,需要的指标,当前需要,就立马统计,比较的方便。Inmon在项目一开始,就有明确的目标,专业性强,人员需要的也多,不太适合小公司使用。6、数据仓库的分层(重点)
Java的开发:遵循三层架构 控制层、服务层、数据操作层
数据仓库的开发,为了效率以及维护成本,我们也需要将数据进行分层。
为什么要分层? 数据的来源很多,很杂,而我们展示给用的数据,需要很精简,很少。
从原始数据到我们的展示的指标数据,中间需要大量的工作,我们将这些工作通过分层,进行规划。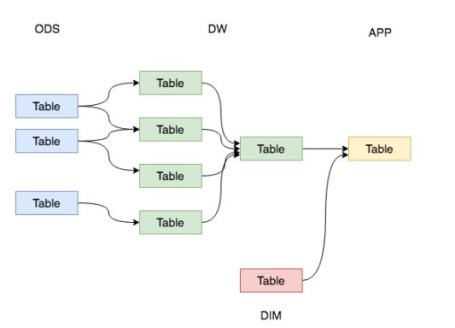
数仓的常见分层一般为3层,分别为:数据操作层、数据仓库层和数据集市层 。
ODS层:一般存储原始数据。
DW层:进行数据的清洗以及汇总。
DIM中存放的是公共的维度信息(客户类型、城市的类型)
APP层:统计出来的指标数据。
ODS层概念: Operate data store,操作数据存储,是最接近数据源中数据的一层,数据源中的数据,经过抽取、 洗净、传输,也就说传说中的ETL之后,装入本层。本层的数据,总体上大多是按照源头业务系统的分 类方式而分类的。 也可以在这一层不清洗,在dw层清洗也可以的。
DW层: Data warehouse,数据仓库层。在这里,从ODS层中获得的数据按照主题建立各种数据模型。
DW层可以分为三层,不是说必须使用,可以选择性的使用一层到三层,每一层都是对上一层的数据的聚合,所谓的聚合可以认为是将多个表合并为一个表。
1. 数据明细层:DWD(Data Warehouse Detail)
该层一般保持和ODS层一样的数据粒度,并且提供一定的数据质量保证。同时,为了提高数据明细层的易用性,该层会采用一些维度退化手法,将维度退化至事实表中,减少事实表和维表的关联。
另外,在该层也会做一部分的数据聚合,将相同主题的数据汇集到一张表中,提高数据的可用性,后文会举例说明。
2. 数据中间层:DWM(Data WareHouse Middle)
该层会在DWD层的数据基础上,对数据做轻度的聚合操作,生成一系列的中间表,提升公共指标的复用性,减少重复加工。
直观来讲,就是对通用的核心维度进行聚合操作,算出相应的统计指标。
3. 数据服务层:DWS(Data WareHouse Servce)—最重要
宽表—就是将之前多个表的字段汇总起来的表,表字段非常的多,称之为宽表。
又称数据集市或宽表。按照业务划分,如流量、订单、用户等,生成字段比较多的宽表,用于提供后续的业务查询,OLAP分析,数据分发等。
一般来讲,该层的数据表会相对比较少,一张表会涵盖比较多的业务内容,由于其字段较多,因此一般也会称该层的表为宽表。
在实际计算中,如果直接从DWD或者ODS计算出宽表的统计指标,会存在计算量太大并且维度太少的问题,因此一般的做法是,在DWM层先计算出多个小的中间表,然后再拼接成一张DWS的宽表。由于宽和窄的界限不易界定,也可以去掉DWM这一层,只留DWS层,将所有的数据在放在DWS亦可。DM层:
存放报表数据的,也就是我们常说的统计出来的结果。DIM层:维度层 —看待事务的角度
同样的一批人: 性别的角度(性别表)
国家的角度(国家表)
学历的角度(学历表)
为什么要分这么多层?
1、数据更加清晰明了
2、将一个杂乱的数据,一层层整理出来,便于我们后面的统计,由于我们不知道以后的一个统计的方向,所以我们将数据根据粗细力度,变为一个个的表。
猪 —> 分层处理(清洗一部分,腌制一部分,放冰箱一部分,搞成半成品备用一部分) —> 红烧肉
数据分层的实质性的好处就是可以重复利用。
二、外卖项目
1、项目的了解
本平台是外卖行业类的自营业务的运营分析平台的一部分,通过对业务数据的分析,获得用户主题和订单的相关分析情况,生成用户的访问模型和用户的订单行为模型,对访问时段和下单区域分布进行分析和报表展示。<br />明确我们分析的主题是:用户和订单<br />干的事情:先创建用户的表以及订单相关的表,然后统计订单的下单时间以及分散的区域。<br />具体的目标就是:
l 学校下单总数,
l 公司下单总数,
l 家里下单总数,
l 凌晨下单总数,
l 上午下单总数,
l 中午下单总数,
l 下午下单总数,
l 晚上下单总数
时间口径:
凌晨:0-05 上午:06-12 中午:13-15 下午16-20 晚上:21-24
2、数据来源
来自于mysql数据库。
执行sql语句: data_init_mt.sql
数据的导入:
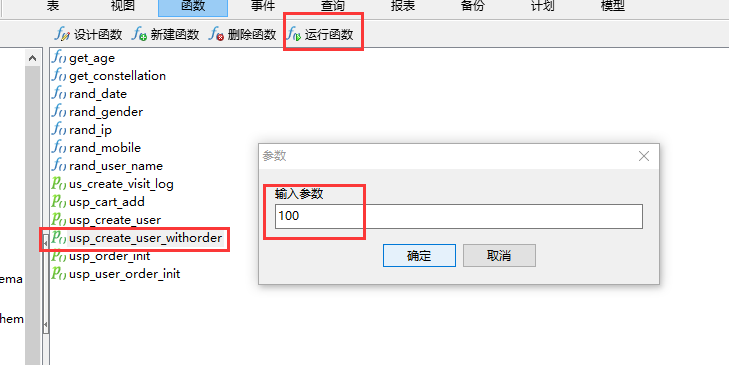
开始产生数据。不要动。
us_order 表中,看到有数据产生,就可以停止了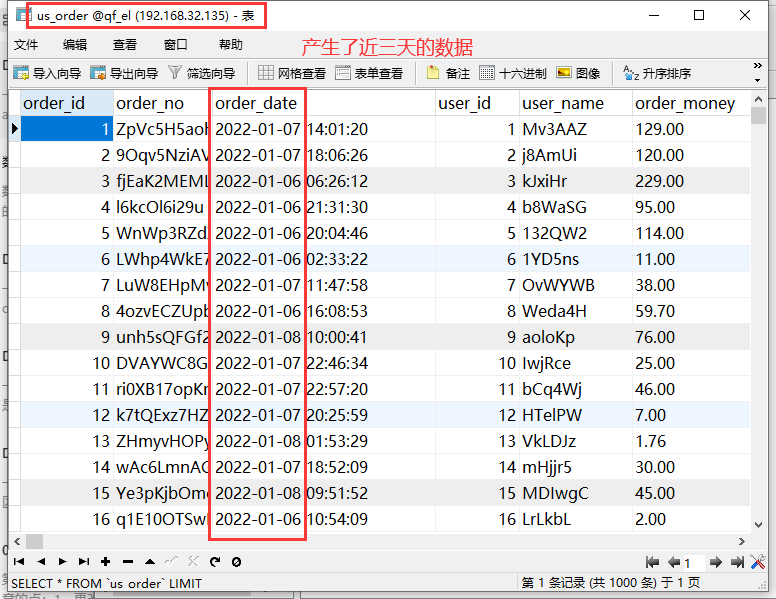
3、分析一下表结构
分析的指标是:
2022-01-06单天,整个外卖平台,在家里,在学校,在公司的一个下单数量分别是多少,看看哪个更多?
需要us_order 表,但是us_order 表看不出是哪里下的单,只能看到下单用户,user、user_addr表中,有一个字段
user_order_flag,可以根据这个字段,来统计是在哪里下的单。
综上所述需要的表有:
us_order 、user 、user_addr 表三个表进行关联。
2022-01-06单天,整个外卖平台,凌晨、早上、中午、下午、晚上各个时间段的一个下单数量哪个更多。
可以根据us_order 表中的下单时间,推测是凌晨、早上、中午、下午、晚上。
4、思路梳理
将数仓项目分为:Hive
1、不断的将mysql 中的数据,拉取到 ods层的表中。
ODS层:存储订单数据以及订单的配送数据(跟数据库中的数据保持一致) us_order order_delivery
2、dim 维度表
这个里面存储用户信息(user) 以及 用户的配送地址 (user_address)
3、dw层—数据仓库层
制作一个关于订单的宽表(字段非常的多) 将以上四个表中的重要的字段全部合并为dw层中的一个表,数据就是以上四个表的
关联之后的数据。
4、dm层 —- 分析出来的指标
就根据之前描述的业务,编写SQL语句,查询第三步的宽表数据,将查询的结果保存在 dm层中的表里面。
5、将dm层的统计的结果数据导出到mysql数据库中即可。
总体来讲:先将mysql中的四个表的数据导入到hive表中,四个表数据合并为一个表A,查询表A的数据做出统计,将统计的结果放入到B中,然后将B中结果导出到mysql对应的表里面即可。
5、开始进行编程
第一步:先创建数据库以及建表(4个)
先创建各个层级的数据库:
create database if not exists ods_el; #ods层数据库:存放订单数据
create database if not exists dw_el; #数据仓库数据库,存放宽表
create database if not exists dm_el; #存放统计的结果
create database if not exists dim_el; #存放维度信息(user,user_addr)
先根据数据库表的字段,创建一个一模一样的hive表 us_order
create table if not exists ods_el.us_order(
`order_id` bigint,
`order_no` string,
`order_date` string,
`user_id` bigint,
`user_name` string,
`order_money` double,
`order_type` int,
`order_status` int,
`pay_status` int,
`pay_type` int,
`order_source` string,
`update_time` string
)
partitioned by(dt string)
row format delimited
fields terminated by ','
lines terminated by '\n'
stored as textfile;
创建order_delivery 表
CREATE TABLE if not exists ods_el.order_delivery (
`order_id` bigint,
`order_no` string,
`consignee` string,
`area_id` bigint,
`area_name` string,
`address` string,
`mobile` bigint,
`phone` string,
`coupon_id` bigint,
`coupon_money` double,
`carriage_money` double,
`create_time` string,
`update_time` string,
`addr_id` bigint
)
partitioned by(dt string)
row format delimited
fields terminated by ','
lines terminated by '\n'
stored as textfile;
在维度层(dim_el)创建 user 以及user_addr
CREATE TABLE if not exists dim_el.`user` (
`user_id` bigint,
`user_name` string,
`user_gender` tinyint,
`user_birthday` string,
`user_age` int,
`constellation` string,
`province` string,
`city` string,
`city_level` tinyint,
`e_mail` string,
`op_mail` string,
`mobile` bigint,
`num_seg_mobile` int,
`op_Mobile` string,
`register_time` string,
`login_ip` string,
`login_source` string,
`request_user` string,
`total_score` double,
`used_score` double,
`is_blacklist` tinyint,
`is_married` tinyint,
`education` string,
`monthly_income` double,
`profession` string,
`create_date` string
)row format delimited
fields terminated by ','
lines terminated by '\n'
stored as textfile;
一定要注意,user表这个名字非常的特殊,需要使用 包括起来,否则报错。
CREATE TABLE if not exists dim_el.user_addr (
`user_id` bigint,
`order_addr` string,
`user_order_flag` tinyint,
`addr_id` bigint,
`arear_id` int
)
row format delimited
fields terminated by ','
lines terminated by '\n'
stored as textfile;
第二步:从MySQL 中导入数据到Hive 的表中。(Sqoop脚本)
1)导入user数据
sqoop import \
--connect jdbc:mysql://wlw01:3306/qf_el \
--username root \
--password root \
--query "SELECT * FROM qf_el.user where 1=1 and \$CONDITIONS" \
--fields-terminated-by ',' \
--target-dir /user/hive/warehouse/dim_el.db/user \
--delete-target-dir \
--m 1
查询数据: select * from user; 只有user表需要加两个点括起来。
2、导入user_addr数据
sqoop import \
--connect jdbc:mysql://wlw01:3306/qf_el \
--username root \
--password root \
--query "SELECT * FROM qf_el.user_addr where 1=1 and \$CONDITIONS" \
--fields-terminated-by ',' \
--target-dir /user/hive/warehouse/dim_el.db/user_addr \
--delete-target-dir \
--m 1
查询数据是否导入成功。 select * from user_addr;
3、导入us_order 表
sqoop import \
--connect jdbc:mysql://wlw01:3306/qf_el \
--username root \
--password root \
--query "SELECT * FROM qf_el.us_order uo WHERE DATE(uo.order_date) = '2022-01-06' and \$CONDITIONS" \
--fields-terminated-by ',' \
--target-dir /user/hive/warehouse/ods_el.db/us_order/dt=2022-01-06 \
--delete-target-dir \
--m 1
导入成功后,发现没有数据。 select * from us_order
需要手动的添加一个分区:
alter table ods_el.us_order add partition(dt='2022-01-06');
再次查询,发现有数据了。
4、导入order_deliver表
发现没有1月6日的数据,修改我们的源数据
update order_delivery set create_time='2022-01-06 11:38:28';
sqoop import \
--connect jdbc:mysql://wlw01:3306/qf_el \
--username root \
--password root \
--query "SELECT * FROM qf_el.order_delivery od WHERE DATE(od.create_time) = '2022-01-06' and \$CONDITIONS" \
--fields-terminated-by ',' \
--target-dir /user/hive/warehouse/ods_el.db/order_delivery/dt=2022-01-06 \
--delete-target-dir \
--m 1 \
--hive-import \
--hive-database ods_el \
--hive-table order_delivery \
--hive-partition-key dt \
--hive-partition-value 2022-01-06
查看数据,是否导入成功。
select * from order_delivery;
至此:我们将mysql中的需要的数据,全部导入到我们的hive的ods层,ods层是原生数据层,一般不做任何的处理,将数据全部搬过来。
第三步:数据仓库dw层
根据以上四个表,创建一个dw层的一个关于order主题的宽表。(order_wide_detail)
1、创建表
create external table if not exists dw_el.order_wide_detail(
`order_id` bigint,
`order_no` string,
`order_date` string,
`user_id` bigint,
`user_name` string,
`order_money` double,
`order_type` int,
`order_status` int,
`pay_status` int,
`pay_type` int,
`order_source` string,
`update_time` string,
user_order_flag string,
order_hour string,
`user_gender` tinyint,
`user_birthday` string,
`user_age` int,
`constellation` string,
`province` string,
`city` string,
`city_level` tinyint
)
partitioned by(dt string)
row format delimited
fields terminated by ','
lines terminated by '\n'
stored as textfile;
2、表中插入数据
insert into dw_el.order_wide_detail partition(dt='2022-01-06')
select
uo.order_id,
uo.order_no,
uo.order_date,
uo.user_id,
uo.user_name,
uo.order_money,
uo.order_type,
uo.order_status,
uo.pay_status,
uo.pay_type,
uo.order_source,
uo.update_time,
ua.user_order_flag user_order_flag,
hour(uo.order_date) order_hour,
uu.user_gender,
uu.user_birthday,
uu.user_age,
uu.constellation,
uu.province,
uu.city,
uu.city_level
from
ods_el.us_order uo
left join ods_el.order_delivery od
on uo.order_id = od.order_id
left join dim_el.user_addr ua
on od.addr_id = ua.addr_id
left join dim_el.`user` uu
on uo.user_id=uu.user_id
where uo.dt='2022-01-06';
至此我们的宽表已经创建,并且数据已经添加,这个表就是我们很多指标统计的依据。
第四步:DM层—关注指标统计
1、统计在2022-01-06当天,在学校,在公司,在家里的下单量,以及在凌晨,上午,中午,下午,晚上的一个下单量。
创建表
create external table if not exists dm_el.order_hour_locat_dist(
`date` string,
school_orders int,
company_orders int,
home_orders int,
orders_0_5 int,
orders_6_12 int,
orders_13_15 int,
orders_16_20 int,
orders_21_24 int
)
partitioned by(dt string)
row format delimited fields terminated by ','
lines terminated by '\n'
stored as textfile
;
开始统计,并且把统计结果存放到我们的order_hour_locat_dist。
通过查询我上面dw层宽表信息,拿到我想要的指标信息。
查询并且插入结果dm层:
insert into dm_el.order_hour_locat_dist partition(dt='2022-01-06')
select
to_date(od.order_date) dt,
sum(case when od.user_order_flag=1 then 1 else 0 end) school_orders,
sum(case when od.user_order_flag=2 then 1 else 0 end) company_orders,
sum(case when od.user_order_flag=3 then 1 else 0 end) home_orders,
sum(case when od.order_hour between 0 and 5 then 1 else 0 end) order_0_5,
sum(case when od.order_hour between 6 and 12 then 1 else 0 end) order_6_12,
sum(case when od.order_hour between 13 and 15 then 1 else 0 end) order_13_15,
sum(case when od.order_hour between 16 and 20 then 1 else 0 end) order_16_20,
sum(case when od.order_hour between 21 and 23 then 1 else 0 end) order_21_24
from
dw_el.order_wide_detail od
where to_date(od.order_date) = '2022-01-06'
group by to_date(od.order_date);
select * from dm_el.order_hour_locat_dist;
第五步:将dm层统计的结果导出到mysql中
在mysql中创建一个存储结果的表。
通过sqoop,将结果导出到mysql的表中。
sqoop export \
--connect jdbc:mysql://wlw01:3306/el_report \
--username root \
--password root \
--table order_locat_hour_dist \
--fields-terminated-by ',' \
--export-dir /user/hive/warehouse/dm_el.db/order_hour_locat_dist/dt=2022-01-06/ \
--m 1
查看el_report数据库中的order_locat_hour_dist是否有数据。
—————————————以上就是一个指标的整体流程,下面是两个新的指标————————————
下一个指标:每个年龄段,它的一个整体消费情况
年段口径:0-16,17-25,26-35,36-60,61-80,80++
创建一个表,用于接收统计的结果:
create external table if not exists dm_el.order_paytype_age_dist(
`date` string,
pay_type string,
orders_price_0_16 double,
orders_price_17_25 double,
orders_price_26_35 double,
orders_price_36_60 double,
orders_price_61_80 double,
orders_price_81_pluss double
)
partitioned by(dt string)
row format delimited fields terminated by ','
lines terminated by '\n'
stored as textfile
;
开始编写统计的sql语句,插入到上面的表中:
insert into dm_el.order_paytype_age_dist partition(dt="2022-01-06")
select
to_date(od.order_date) dt,
od.pay_type pay_type,
round(sum(case when od.user_age between 0 and 16 then od.order_money else 0 end),3) orders_price_0_16,
round(sum(case when od.user_age between 17 and 25 then od.order_money else 0 end),3) orders_price_17_25,
round(sum(case when od.user_age between 26 and 35 then od.order_money else 0 end),3) orders_price_26_35,
round(sum(case when od.user_age between 36 and 60 then od.order_money else 0 end),3) orders_price_36_60,
round(sum(case when od.user_age between 61 and 80 then od.order_money else 0 end),3) orders_price_61_80,
round(sum(case when od.user_age >= 81 then od.order_money else 0 end),3) orders_price_81_pluss
from dw_el.order_wide_detail od
where to_date(od.order_date) = '2022-01-06'
group by to_date(od.order_date),od.pay_type
;
统计完,将hive表中的结果导出到mysql
mysql先建一个表:
CREATE TABLE `el_report`.`order_paytype_age_dist` (
`dt` varchar(10) DEFAULT NULL,
`pay_type` varchar(10) DEFAULT NULL,
`orders_price_0_16` double(10,3) DEFAULT '0.000',
`orders_price_17_25` double(10,3) DEFAULT '0.000',
`orders_price_26_35` double(10,3) DEFAULT '0.000',
`orders_price_36_60` double(10,3) DEFAULT '0.000',
`orders_price_61_80` double(10,3) DEFAULT '0.000',
`orders_price_81_pluss` double(10,3) DEFAULT '0.000'
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
导出数据到mysql:
sqoop export \
--connect jdbc:mysql://wlw01:3306/el_report \
--username root \
--password root \
--table order_paytype_age_dist \
--fields-terminated-by ',' \
--export-dir /user/hive/warehouse/dm_el.db/order_paytype_age_dist/dt=2022-01-06/ \
--m 1
最后一个指标:在2022-01-06那天,全国各个省份的一个下单情况。
创建一个hive表,用于接收统计的结果
create external table if not exists dm_el.order_map_dist(
`date` string,
province string,
orders_cnt int,
order_prices double
)
partitioned by(dt string)
row format delimited fields terminated by ','
lines terminated by '\n'
stored as textfile
;
统计并将结果存放到hive表中
insert into dm_el.order_map_dist partition(dt="2022-01-06")
select
to_date(od.order_date) dt,
od.province province,
count(od.order_id) order_cnt,
round(sum(od.order_money),3) order_prices
from dw_el.order_wide_detail od
where to_date(od.order_date) = '2022-01-06'
group by to_date(od.order_date),od.province
;
然后创建mysql
CREATE TABLE `el_report`.`order_map_dist` (
`dt` varchar(10) DEFAULT NULL,
`province` varchar(255) DEFAULT NULL,
`order_cnt` int DEFAULT '0',
`order_prices` double(10,3) DEFAULT '0.000'
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
导出数据到mysql,注意字符编码
sqoop export \
--connect "jdbc:mysql://wlw01:3306/el_report?useUnicode=true&characterEncoding=UTF-8" \
--table order_map_dist \
--username root \
--password root \
--fields-terminated-by ',' \
--export-dir /user/hive/warehouse/dm_el.db/order_map_dist/dt=2022-01-06/ \
--m 1

若有收获,就点个赞吧
0 人点赞
