一、学习Hive中的分区
1、为什么分区
数据量越来越大之后,为了提高查询的效率,从而引进分区技术,使用分区技术,能避免hive做全表扫描,从而提交查询效率。可以将用户的整个表在存储上分成多个子目录(子目录以分区变量的值来命名)。
2、一般分区按照时间或者地区划分
比如14亿人口,我可以按照省\市\县区
比如我们有很多的订单数据:可以按照年\月\日
比如想查询 2021年12月份的某些数据,我只需要去到2021年2月份的一个数据集中查询即可,没必须全部查询。
3、基本用法
1)创建一级分区
create table if not exists part1(id int,name string)partitioned by(dt string)row format delimitedfields terminated by ',';
将数据load进去。
load data local inpath '/root/hivedata/seq.csv' into table part1 partition(dt='2022-01-07');
查看数据: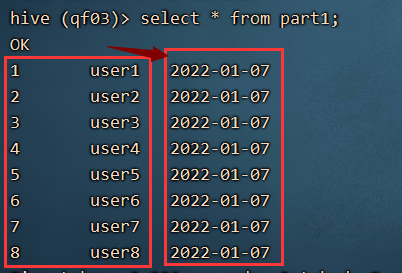

他在我们的hdfs上的表现就是在表文件夹下多了分区文件夹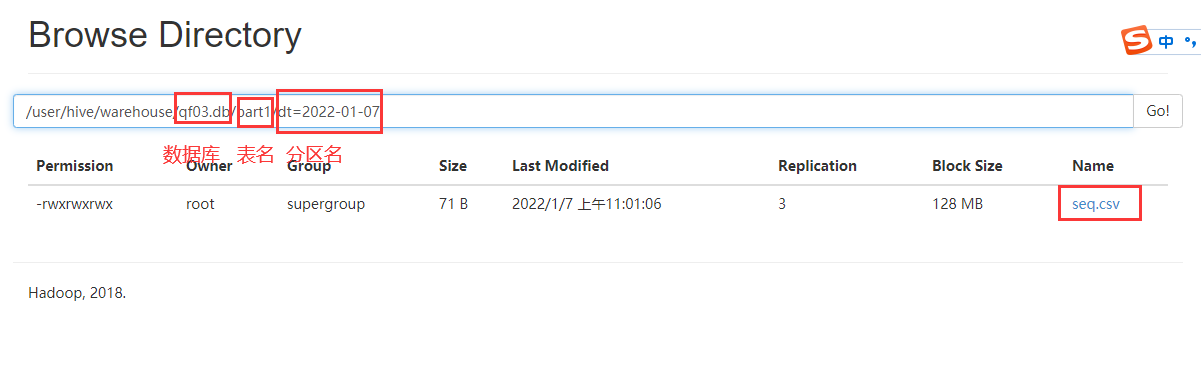

查询语句:
select * from part1 where dt='2022-01-07';
2) 二级分区
create table if not exists part2(
id int,
name string
)
partitioned by(year string,month string)
row format delimited
fields terminated by ',';
相较于一级分区,在建表的时候使用了两个虚拟字段,分别是年和月。
load data local inpath '/root/hivedata/seq.csv' into table part2 partition(year='2022',month='01');
load data local inpath '/root/hivedata/seq.csv' into table part2 partition(year='2022',MONTH='02');
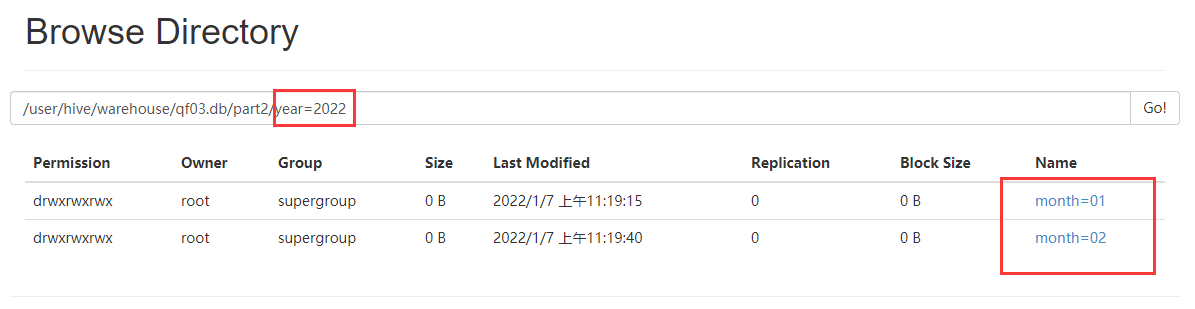
这里有一个小问题,如果分区字段是一个string类型的,导入数据的时候,编写了一个数字类型,可以自动转换为string类型
load data local inpath '/root/hivedata/seq.csv' into table part2 partition(year='2022',MONTH=12);
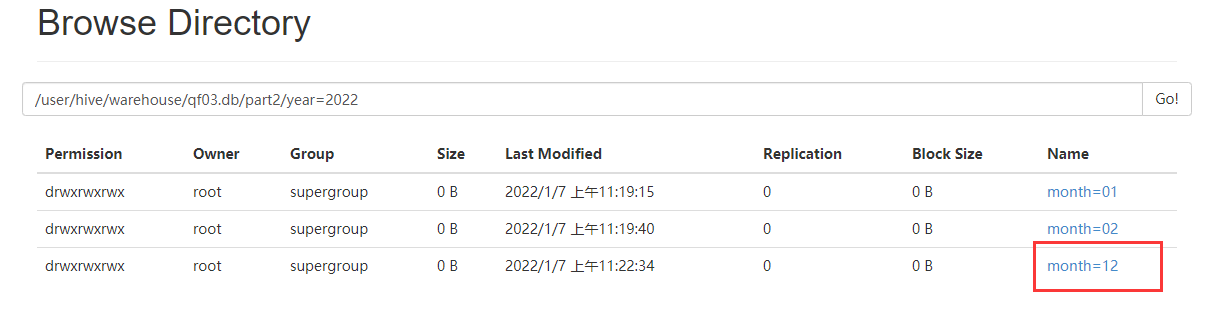
load data local inpath '/root/hivedata/seq.csv' into table part2 partition(year='2022',MONTH=06);
会将06 变为 6 创建文件夹,所以写SQL,要规范,不要随心所欲。
3)分区的一些增删改查
查看分区:show partitions 表名;
增加分区:alter table 表名 add partition(分区字段)
删除分区:alter table 表名 drop partiton(分区字段);

4、分区的分类
静态分区(同上)、动态分区、混合分区
说一说动态分区:
导入数据的时候,不知道有多少个分区,根据字段的不同,字段的创建分区。
建表,跟之前一模一样:
create table dy_part1(
id int,
name string
)
partitioned by (dt string)
row format delimited fields terminated by ',';
不能使用load data 命令,将我们的数据,直接加载到我们的分区表中。
开始步骤:
第一步:先建一个表,这个表是临时表,分区字段是一个普通字段。
create table temp_part(
id int,
name string,
dt string
)
row format delimited fields terminated by ',';
临时表和动态的hive表,一个是伪字段,一个是实实在在的字段。
第二步:将数据先加载到临时表中。
1,laoyan,2022-01-07
2,dalaowang,2022-01-07
3,laoxing,2022-01-06
4,laoliu,2022-01-06
创建了一些临时测试数据,part.txt
load data local inpath '/root/hivedata/part.txt' into table temp_part;
将临时表中的数据通过insert into 导入到动态分区表中。
insert into dy_part1 partition(dt) select id,name,dt from temp_part;
报错:没有开启非严格模式
在hive中,直接设置
set hive.exec.dynamic.partition.mode=nonstrict;
此种设置只能使用这一次,下次再进入,需要重新设置,如果想一直有效,此句话放入 .hiverc 中。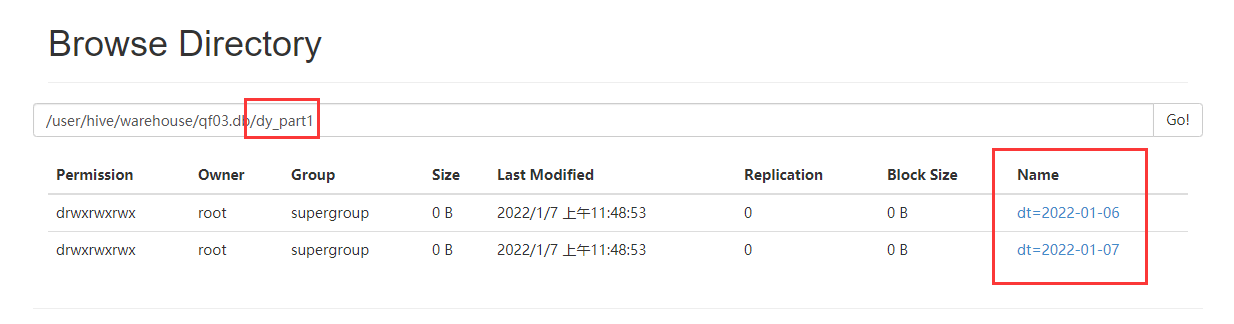
所谓的动态分区:其实就是根据我们的查询结果,自动导入到一个分区表中,这个过程会根据数据的不同,自动的创建分区,并且把响应的数据放在分区中。
二、sqoop介绍及安装
1、介绍
Sqoop是一个数据的导入和导出的一个工具。HDFS-->MySQL,MySQL-->HDFS,MySQL-->Hive、Hbase,Hive-->MySQL。<br />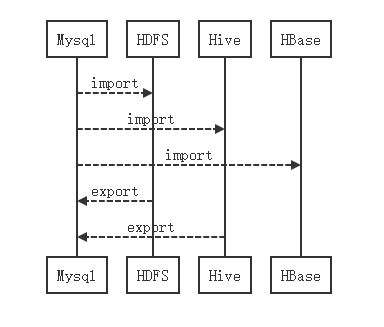<br />大数据--> 数据的采集、数据的流动、数据存储、数据的分析与计算<br />人工智能 --> 讲究的是算法。学习开源的算法。算法工程师。<br />外卖平台数据 MySQL产生的数据--> Hive -->层层过滤-->结论 -->MySQL --> 图形化的界面展示出来。<br /> Sqoop的**核心设计思想是利用MapReduce加快数据传输速度**。也就是说Sqoop的导入和导出功能是通过基于Map Task(只有map)的MapReduce作业实现的。所以它是一种批处理方式进行数据传输,难以实现实时的数据进行导入和导出。
2、sqoop的安装
1)上传软件,并解压
tar -zxvf sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz -C /usr/local
2)重命名
mv sqoop-1.4.7.bin__hadoop-2.6.0 sqoop-1.4.7
3)配置环境变量
修改 /etc/profile
export SQOOP_HOME=/usr/local/sqoop-1.4.7
export PATH=$PATH:$SQOOP_HOME/bin
source /etc/profile<br />4) 修改sqoop的核心配置文件<br />在sqoop 解压文件下,找到conf
cp sqoop-env-template.sh sqoop-env.sh
接着修改里面的内容:
文件的位置: /usr/local/sqoop-1.4.7/conf
export HADOOP_COMMON_HOME=/usr/local/hadoop
export HADOOP_MAPRED_HOME=/usr/local/hadoop
export HIVE_HOME=/usr/local/hive
找到我们上传的mysql 的驱动包,复制到sqoop的lib下
cp mysql-connector-java-5.1.28-bin.jar /usr/local/sqoop-1.4.7/lib/

三、Sqoop 的使用
1、help

2、查看所有的数据库
一定要注意斜杠,有空格,每一行除了最后一行都有
sqoop list-databases \
--connect jdbc:mysql://192.168.32.135:3306 \
--username root \
--password root;
3、展示某个数据库中的表
sqoop list-tables \
--connect jdbc:mysql://192.168.32.135:3306/hive \
--username root \
--password root;
4、import 数据导入【重点】
实际操作:
在mysql中创建数据:
通过Navicat 创建数据库:
执行以下代码:
CREATE TABLE emp(
empno INT primary key,
ename VARCHAR(50),
job VARCHAR(50),
mgr INT,
hiredate DATE,
sal DECIMAL(7,2),
comm decimal(7,2),
deptno INT
) ;
INSERT INTO emp values(7369,'SMITH','CLERK',7902,'1980-12-17',800,NULL,20);
INSERT INTO emp values(7499,'ALLEN','SALESMAN',7698,'1981-02-20',1600,300,30);
INSERT INTO emp values(7521,'WARD','SALESMAN',7698,'1981-02-22',1250,500,30);
INSERT INTO emp values(7566,'JONES','MANAGER',7839,'1981-04-02',2975,NULL,20);
INSERT INTO emp values(7654,'MARTIN','SALESMAN',7698,'1981-09-28',1250,1400,30);
INSERT INTO emp values(7698,'BLAKE','MANAGER',7839,'1981-05-01',2850,NULL,30);
INSERT INTO emp values(7782,'CLARK','MANAGER',7839,'1981-06-09',2450,NULL,10);
INSERT INTO emp values(7788,'SCOTT','ANALYST',7566,'1987-04-19',3000,NULL,20);
INSERT INTO emp values(7839,'KING','PRESIDENT',NULL,'1981-11-17',5000,NULL,10);
INSERT INTO emp values(7844,'TURNER','SALESMAN',7698,'1981-09-08',1500,0,30);
INSERT INTO emp values(7876,'ADAMS','CLERK',7788,'1987-05-23',1100,NULL,20);
INSERT INTO emp values(7900,'JAMES','CLERK',7698,'1981-12-03',950,NULL,30);
INSERT INTO emp values(7902,'FORD','ANALYST',7566,'1981-12-03',3000,NULL,20);
INSERT INTO emp values(7934,'MILLER','CLERK',7782,'1982-01-23',1300,NULL,10);
MySQL数据导入Hdfs
命令:
sqoop import \
--connect jdbc:mysql://192.168.32.135:3306/yxhdb \
--username root \
--password root \
--table emp \
--target-dir hdfs://192.168.32.135:8020/sqoopdata/emp \
--delete-target-dir

当我们执行一些命令的时候,必须保障mysql 是可以连接的,我们的hdfs也是没有问题的,yarn也是启动。
查看hadoop集群是否启动了。
如果没有启动,start-all.sh 启动即可。
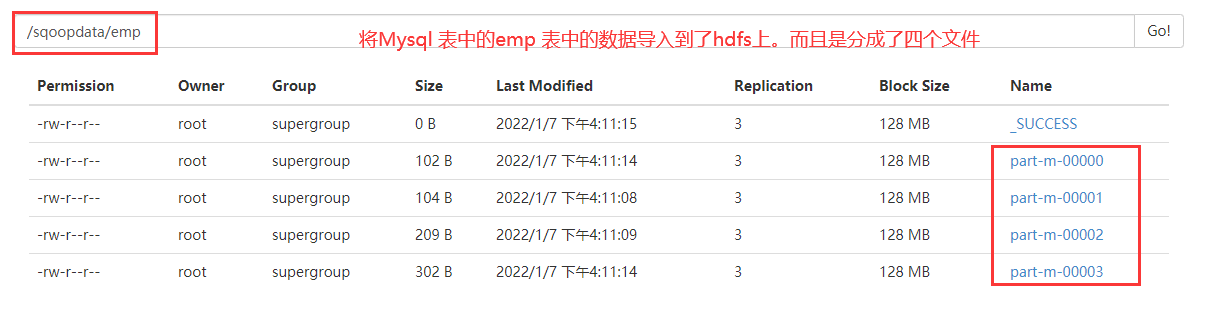
如果运行的结果part-r-0000xx 说明这个文件是reduce任务执行的输出。
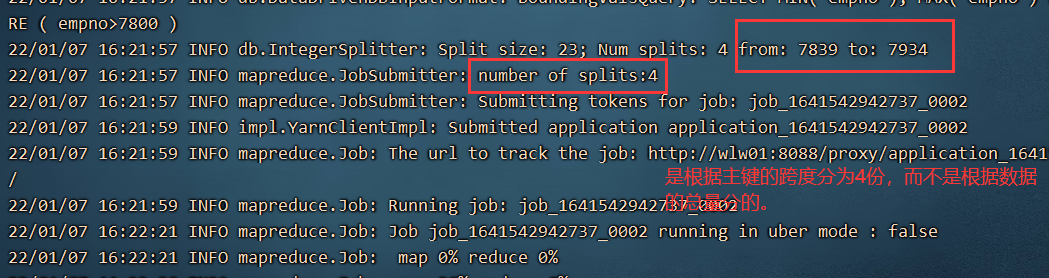
如果是part-m-00000xxx说明是map任务执行的输出,Sqoop的导入和导出都会将命令变为Map Task任务,执行。为什么是四个文件,而不是一个或者其他个,因为默认的。不过文件内容有多大或多小,都会根据emp等表的主键,切分为四份。
根据条件导入某些列:
sqoop import \
--connect jdbc:mysql://192.168.32.135:3306/yxhdb \
--username root \
--password root \
--table emp \
--columns 'empno,mgr' \
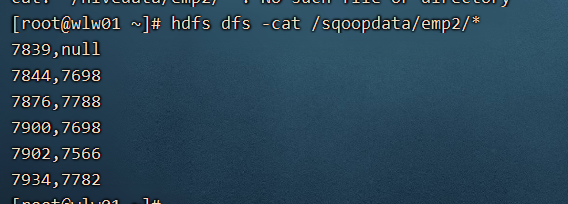
--where 'empno>7800' \
--target-dir hdfs://192.168.32.135:8020/sqoopdata/emp2 \
--delete-target-dir
还可以根据查询条件,执行导入:
sqoop import \
--connect jdbc:mysql://192.168.32.135:3306/yxhdb \
--username root \
--password root \
--query 'select empno,mgr,job from emp WHERE empno>7800 and $CONDITIONS' \
--target-dir hdfs://192.168.32.135:8020/sqoopdata/emp2 \
--delete-target-dir \
-m 1
这个脚本文件需要注意的点:
1、 指定map任务的数量 是 -m 不是 —m
2、query的查询语句,是单引号,不是双引号,双引号要做特殊处理
3、条件中必须添加 $CONDITIONS
4、如果指定了map,我们需要添加 —split by empno
执行脚本有问题,少 —split by
sqoop import \
--connect jdbc:mysql://192.168.32.135:3306/yxhdb \
--username root \
--password root \
--query 'select empno,mgr,job from emp WHERE empno>7800 and $CONDITIONS' \
--target-dir hdfs://192.168.32.135:8020/sqoopdata/emp2 \
--delete-target-dir \
--split-by empno \
-m 1

MySQL数据导入Hive
sqoop import \
--connect jdbc:mysql://192.168.32.135:3306/yxhdb \
--username root \
--password root \
--table emp \
--hive-import \
--hive-overwrite \
-m 1

sqoop中缺少两个包:
cp /usr/local/hive/lib/hive-exec-2.1.1.jar /usr/local/sqoop-1.4.7/lib/
cp /usr/local/hive/lib/hive-common-2.1.1.jar /usr/local/sqoop-1.4.7/lib/
说明我们的hdfs上有数据,需要先删除,再执行
hdfs dfs -rm -r /user/root/emp
再次执行没有问题,查看hive中的表数据emp,没问题
5、数据的导出export
1) 演示的是将hdfs上文件导出到mysql 的表中
sqoop export \
--connect jdbc:mysql://192.168.32.135:3306/yxhdb \
--username root \
--password root \
--table emp_2 \
--driver com.mysql.jdbc.Driver \
--export-dir '/sqoopdata/emp/*' \
-m 1
从数据库中导入到hdfs的时候的几个参数:
--fields-terminated-by '\t' \ --导入的时候,文件中每个数据之间的分隔符
--null-string '\\N' \ --如果mysql中的null ,导入是变为\N
--null-non-string '0' --mysql中的数值如果是null,导入的时候变为0
从hdfs导出到mysql 的时候有几个参数:
--input-fields-terminated-by '\t' \ --导出的时候,hdfs上的数据通过什么切割
--input-null-string '\\N' \ --如果hdfs的数据有null,mysql 中显示\N
--input-null-non-string '\\N' \ --数值类型也实现\N
6、增量导入
mysql 中的数据每次导入到hdfs上的时候,每次都是覆盖,刚开始没啥问题,随着数据量越来越大之后,mysql 中的数据导入hdfs就会越来越慢,怎么办呢?能不能每次导入的时候去追加没有导入过的数据,不要覆盖— 增量导入。
手动的进行增量导入,第一次导入的时候是从0开始的
sqoop import \
--connect jdbc:mysql://192.168.32.135:3306/yxhdb \
--username root \
--password root \
--table emp \
--driver com.mysql.jdbc.Driver \
--target-dir /sqoopdata/emp3 \
--split-by empno \
-m 1 \
--check-column empno \
--incremental append \
--last-value 0 \
--fields-terminated-by '\t' \
--null-string '\\N' \
--null-non-string '0'
导入成功后,隔了一段时间,数据又增加了,这个时候再次执行脚本
sqoop import \
--connect jdbc:mysql://192.168.32.135:3306/yxhdb \
--username root \
--password root \
--table emp \
--driver com.mysql.jdbc.Driver \
--target-dir /sqoopdata/emp3 \
--split-by empno \
-m 1 \
--check-column empno \
--incremental append \
--last-value 7934 \
--fields-terminated-by '\t' \
--null-string '\\N' \
--null-non-string '0'
我们查看到hdfs上新增了一个文件,这个文件中就只有后面产生的数据,而不是覆盖
7、通过job任务,制作自动化的增量导入

创建一个job
sqoop job --create sql -- import \
--connect jdbc:mysql://192.168.32.135:3306/yxhdb \
--username root \
--password root \
--table emp \
--driver com.mysql.jdbc.Driver \
--target-dir /sqoopdata/emp3 \
--split-by empno \
-m 1 \
--check-column empno \
--incremental append \
--last-value 0 \
--fields-terminated-by '\t' \
--null-string '\\N' \
--null-non-string '0'
查看job sqoop job —list
执行job 任务: sqoop job —exec sql
需要输入密码。
将增量导入的脚本写成job之后,每次执行完,job会自动帮我们保存last-value 不需要自己记忆。

若有收获,就点个赞吧
0 人点赞
