一、复习
1、大数据学习路线
2、Hadoop (HDFS、MapReduce、Yarn)
3、Hive的安装
三种运行模式:嵌入式模式(Derby)、本地模式(Mysql)、远程模式
3、学习了一些关于hive的基本用法
总结:Hive 只需要认识到两点: 1)Hive是对结构化的数据的一种映射,映射成表
2) 通过操作hive中的表,来运行mapreduce.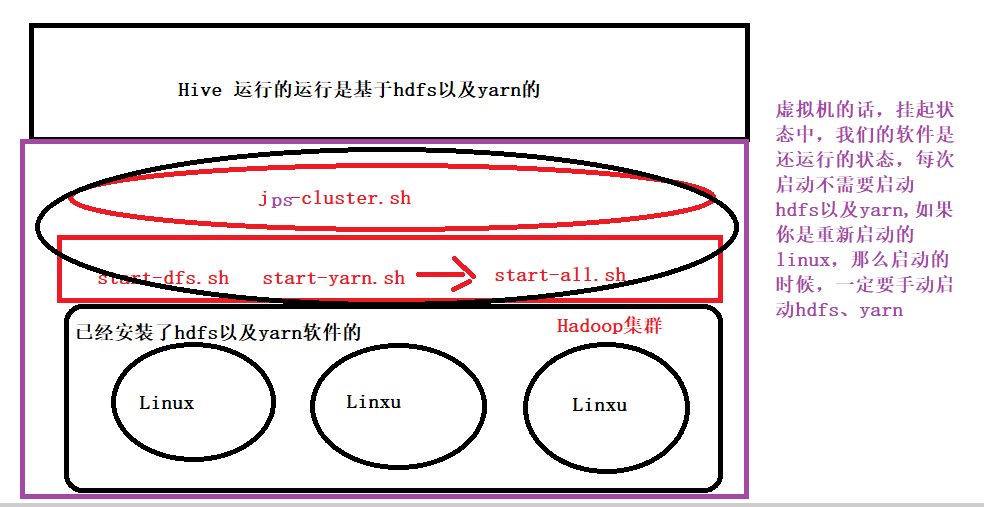
二、Hive的基本操作
1、Hive 和Hadoop的关系
Hive是基于Hadoop的。<br /> Hive本身其实没有多少功能,hive就相当于在Hadoop上面加了一个外壳,就是对hadoop进行了一次封装。<br /> Hive的存储是基于HDFS的,hive的计算是基于MapReduce。
2、Hive 和数据库比较
没有什么比较的,因为hive就不是数据库。只是操作手法参照了数据库的操作。
3、搞一个案例分析
1)先找到需要分析的日志文件,搞明白每一行的含义
1 15649428888 00-0C-29-CD-75-8C:CMCC-EASY 192.169.17.8 www.bjfkfu.com 88 25 751 2694 200 1446307200
2 13243983434 06-0C-29-CD-79-8C:CMCC-EASY 192.169.0.46 www.fgd.com 99 88 1913 3440 200 1446307200
3 15642428887 00-7C-29-CD-79-8C:CMCC-EASY 192.169.139.91 www.blfy.com 16 75 938 1720 200 1446307200
4 15649428888 00-0C-29-CD-79-86:CMCC-EASY 192.169.211.90 www.bjfkfu.com 54 72 3914 2628 200 1446307200
5 18323234884 01-0C-29-CD-79-8C:CMCC-EASY 192.169.10.52 www.fgd.com 21 55 9852 8116 200 1446307200
6 15652106623 30-0C-29-4D-79-8C:CMCC-EASY 192.169.189.6 www.bjhfu.com 77 0 9085 7793 200 1446307200
7 15649428881 00-0C-29-CD-75-8C:CMCC-EASY 192.169.17.8 www.bjfkfu.com 88 25 751 2694 200 1446307200
8 13243983436 06-0C-29-CD-79-8C:CMCC-EASY 192.169.0.46 www.fgd.com 99 88 1913 3440 200 1446307200
9 15642428889 00-7C-29-CD-79-8C:CMCC-EASY 192.169.139.91 www.blfy.com 16 75 938 1720 200 1446307200
10 15649428885 00-0C-29-CD-79-86:CMCC-EASY 192.169.211.90 www.bjfkfu.com 54 72 3914 2628 200 1446307200
11 18323234881 01-0C-29-CD-79-8C:CMCC-EASY 192.169.10.52 www.fgd.com 21 55 9852 8116 200 1446307200
12 15652106622 30-0C-29-4D-79-8C:CMCC-EASY 192.169.189.6 www.bjhfu.com 77 0 9085 7793 200 1446307200
13 15649428888 00-0C-29-CD-75-8C:CMCC-EASY 192.169.17.8 www.bjfkfu.com 88 25 751 2694 200 1446307200
14 13243983434 06-0C-29-CD-79-8C:CMCC-EASY 192.169.0.46 www.fgd.com 99 88 1913 3440 200 1446307200
15 15642428887 00-7C-29-CD-79-8C:CMCC-EASY 192.169.139.91 www.blfy.com 16 75 938 1720 200 1446307200
16 15649428888 00-0C-29-CD-79-86:CMCC-EASY 192.169.211.90 www.bjfkfu.com 54 72 3914 2628 200 1446307200
17 18323234884 01-0C-29-CD-79-8C:CMCC-EASY 192.169.10.52 www.fgd.com 21 55 9852 8116 200 1446307200
18 15652106622 30-0C-29-4D-79-8C:CMCC-EASY 192.169.189.6 www.bjhfu.com 77 0 9085 7793 200 1446307200
含义:id 手机号 mac地址 IP url网址 上行流量包的数量 下行包数量 本次的上行总流量 本次的下次流量 响应状态 时间毫秒值
2)建表—根据日志的格式建表
create table if not exists flow_new(
id int,
phoneNum string,
mac string,
ip string,
url string,
up_num int,
down_num int,
upflow int,
downflow int,
status int,
dt string
)
row format delimited
fields terminated by ' '
lines terminated by '\n';

3) 分析的指标
1— 统计每一个手机号的总流量
2—查询访问次数最多的网站前三名
4)、导入数据到hive中
1)创建文件夹 在 /root 下 , mkdir hivedata
2) 将log1.txt 上传至该文件夹下
3)在hive中执行 load data local inpath ‘/root/hivedata/log1.txt’ into table flow;
4)查看数据表是否有数据 select * from flow;
5)、根据指标编写sql语句
select phonenum,(sum(upflow+downflow)) from flow group by phonenum;
通过以上的SQL,一般的统计类型的sql语句都会自动的转换为MapReduce任务。
由于每次执行都是分布式运行的,所以统计的结果非常的慢,不利于开发环境,所以我们需要配置本地运行。
6) 做一个HIve的本地优化
大多数的Hadoop Job是需要Hadoop提供的完整的可扩展性来处理大数据集的。不过,有时Hive的输入数据量是非常小的。在这种情况下,为查询触发执行任务的时间消耗可能会比实际job的执行时间要多得多。对于大多数这种情况,Hive 可以通过本地模式在单台机器上(或某些时候在单个进程中)处理所有的任务。对于小数据集,执行时间可以明显被缩短。用户可以按照如下这个例子中所演示的方式,在执行过程中临时启用本地模式。
在 .hiverc 中配置即可
set hive.exec.mode.local.auto=true;
set hive.exec.mode.local.auto.inputbytes.max=134217728;
set hive.exec.mode.local.auto.input.files.max=4;
由于我们的.hiverc 是在hive启动时加载的,所以需要退出hive,重新进入。
7) 继续数据统计
1— 每一个手机号的总流量,单位是M,精确到小数点后两位
select phonenum,round(sum(upflow+downflow)/1024.0,2) from flow group by phonenum;

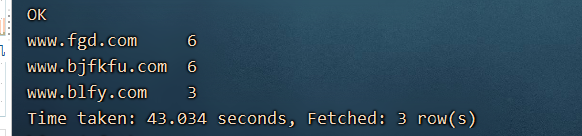
2、统计网站前三名
select url,count(url) urlcount from flow group by url order by urlcount desc limit 3;
在看Hive的理解: 是对结构化的数据的一种映射,将数据映射成表,然后通过表执行HQL语句,从而转换为MapReduce任务,将结果统计出来。
4、关于数据的加载与克隆
1)数据的加载
在企业中,数据一般以日志的形式存在。数据要么在本地存放,要么在hdfs平台上存放。
如果数据在本地(Linux本地):需要添加local ,并且路径指的是本地的路径
load data local inpath ‘/root/hivedata/log1.txt’ into table flow;
如果数据在hdfs平台上:不要加local,数据在hdfs的路径下
将本地的log1.txt 上传到hdfs 的根路径下 /
hdfs dfs -put /root/hivedata/log1.txt /
load data inpath ‘/log1.txt’ into table flow;
上传之后发生了什么?
1) hdfs上的文件消失了 hdfs的根路劲下的数据不见了。所以hdfs上的数据不是复制而是剪切。
2) hive数据库中的数据变多了一倍,说明数据默认不是覆盖,而是追加。
3)如果每次导入的时候想覆盖的话,不管是本地还是hdfs,都可以添加override 关键字
load data local inpath ‘/root/hivedata/log1.txt’ overwrite into table flow;
2、克隆数据
1)创建一个新表,将老表中的数据导入到新表中
insert into flow_new select from flow;
2)克隆表并且带数据
create table flow2 as select from flow;
5、复杂数据类型
基本数据类型中:int string <br /> 如果导入的数据,到hive表中,如果数据类型不匹配,不会报错,而是导入了null.<br /> 1) array 数组<br /> 创建一个array.txt 文件 touch array.txt
zhangsan 78,89,92,96
lisi 67,75,83,94
wangwu 89,96
复制数据。<br /> 建表:
create table if not exists array1(
name string,
scores array<int>
)
row format delimited
fields terminated by '\t'
collection items terminated by ','
lines terminated by '\n';
加载数据到表中:
load data local inpath ‘/root/hivedata/array.txt’ into table array1;
可以统计一些指标:
--- 查询每一个人的第一个成绩
select name,scores[0] from array1;
-- 查询每一个人成绩的数量
select name,size(scores) from array1;
--查询每一个人的总成绩
不太正确的做法:
select name,scores[0]+scores[1]+scores[2]+scores[3] from array1; // wangwu的成绩为null
# 由于任何数字和null相加都为null,所有我们是用了nvl函数
select name,nvl(scores[0],0)+nvl(scores[1],0)+nvl(scores[2],0)+nvl(scores[3],0) from array1;

需要用到列转行:
select explode(scores) from array1;
select name,cj from array1 lateral view explode(scores) score as cj;
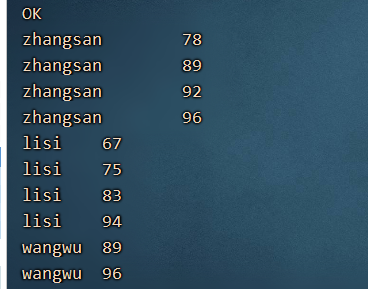
select name,sum(cj) from array1 lateral view explode(scores) score as cj group by name;
提升一下难度:
如果成绩是如图所示:
zhangsan 78
zhangsan 89
zhangsan 92
zhangsan 96
lisi 67
lisi 75
lisi 83
lisi 94
wangwu 89
wangwu 96
如何变成数组:
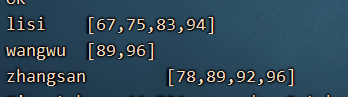
zhangsan [78,89,92,96]
lisi [67,75,83,94]
wangwu [89,96]
这样的需求就叫做行转列:
先创建一个表,表中的数据就是一行行的数据:
create table array_temp
as
select name,cj from array1 lateral view explode(scores) score as cj;
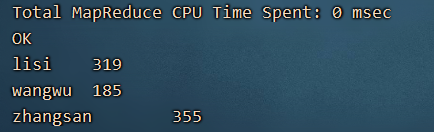
select name,collect_list(cj) from array_temp group by name;
行转列,需要借助于 collect_list() / collect_set()
2)map
首先创建一个数据 touch map.txt
搞点数据:
zhangsan chinese:90,math:87,english:63,nature:76
lisi chinese:60,math:30,english:78,nature:0
wangwu chinese:89,math:25,english:81,nature:9
根据日志的格式,创建表
create table if not exists map1(
name string,
scores map<string,int>
)
row format delimited
fields terminated by ' '
collection items terminated by ','
map keys terminated by ':'
lines terminated by '\n';
导入数据到表中:
load data local inpath ‘/root/hivedata/map.txt’ into table map1;
查看数据:
zhangsan {"chinese":90,"math":87,"english":63,"nature":76}
lisi {"chinese":60,"math":30,"english":78,"nature":0}
wangwu {"chinese":89,"math":25,"english":81,"nature":9}
统计指标:
——-数学成绩大于35分的同学的姓名以及英语和自然的成绩
select name,scores['english'],scores['nature'] from map1 where scores['math']>35;
——-计算每一个人的总成绩
将map中的scores 成绩展开 select explode(scores) from map1;
数据展开成一行行的数据:
select name,subject,cj from map1 lateral view explode(scores) sc_table as subject,cj;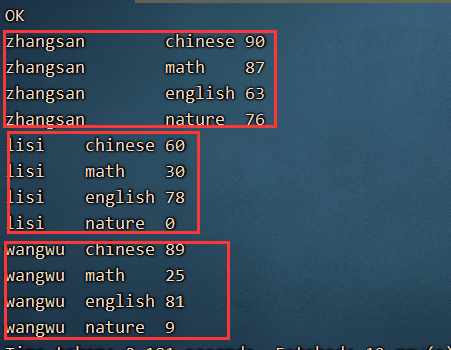
每一个学生的总成绩:
select name,sum(cj) from map1 lateral view explode(scores) sc_table as subject,cj group by name;

——计算每一个学科的总成绩
select subject,sum(cj) from map1 lateral view explode(scores) sc_table as subject,cj group by subject;
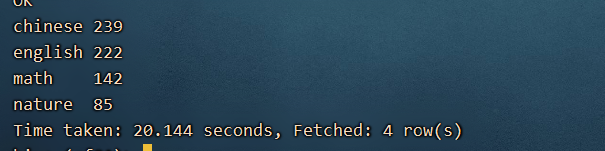
高级玩法:将展开的数据合并成map
3) struct —类似于我们java中的类
创建数据 touch struct.txt
河南省 郑州市 管城区
洛阳市 偃师区 市区
河北省 石家庄 xx区
创建表:
create table if not exists strut1(
address struct<province:string,city:string,street:string>
)
row format delimited
collection items terminated by '\t'
lines terminated by '\n';
load data local inpath '/root/hivedata/struct.txt' overwrite into table strut1;
查看所有的省份:
select address.province from strut1;

若有收获,就点个赞吧
0 人点赞
