一、大数据的学习路线
大数据学科是Java学科的一个延伸。
1、基础
Java(JUC、虚拟机内存模型,GC性能调优、双亲委派机制)、MySQL(SQL编写、索引数据结构、优化)、Linux(常用命令\Shell编程)、Maven(重要)
2、Hadoop(生态圈)
基础部分:注重理论 — HDFS、MapReduce、Yarn 、ZooKeeper
Hive (数据仓库的核心部件) + HBase (认为:大数据库)
3、其他的辅助性工具
Flume: 采集工具
Sqoop: 数据同步工具 Hive—>MySQL MySQL—>Hive HDFS等平台
DataX、Kylin、Azkaban、Redis、ES(重要)
可以胜任:数据仓库开发工程师、ETL数据清洗工程师 —偏离线的数据分析
4、Spark(重要的)
Scala语言—> Spark Core —>SparkSQL —>SparkStreaming + Kafka
可以进行离线以及在线的数据分析—替换MapReduce
5、Flink (重要的东西)
6、Canal 阿里的技术 Apache Druid (单独的流式工具)
比如:秒杀系统—> 高并发
商品有好几百个,有些商品没人买,有些商品买的人很多,并发量很大。
如何动态的识别哪些商品是热门商品,识别出来之后做一个应对策略。
需要大数据技术—>记录日志,看哪些商品的访问量大—>信息采集工具—>Kafka消息中间件—>Apache Druid (通过SQL动态查询访问频率)
—> 计算出来的热门商品放入Redis缓存中备用。
7、Web层— Java工程师 — 不要花费太多时间
只需要学习一个SpringBoot 就可以了。
SSM — > SpringBoot —> 分布式架构(SpringCloud\Dubbo)+ Echarts做一个图形化的东西
岗位—> 大数据工程师、大数据运维工程师、数仓工程师、ETL工程师、大数据架构工程师、架构师(java+大数据)、技术总监。
二、大数据中Hadoop
Hadoop 讲解的是一个狭义的Hadoop
1、HDFS
分布式的文件存储系统(类似于FastDFS、币圈的IPFS、起亚)
举个例子—> 阿里的商品图片上传,上传到哪里去了?
上传到阿里的图片服务器了(集群),这样的集群必须满足如下条件:
1) 必须易于拓展(10EP),只需要增加一些服务器,整个的集群磁盘空间就还会自动扩容。
2) 数据会自动的流向新的服务器
3) 容灾性能好 —> 必须保证一张图片,在集群中是有多个备份的,不同机房的不同机器上。
HDFS—>
将庞大的数据切割成一个个块儿,每个块2.x的hadoop默认的是128M. 不同的块分散的整个hdfs的集群电脑上,组合成一个庞大的磁盘。
每一个块,默认的话,有三个备份。
启动命令: start-dfs.sh 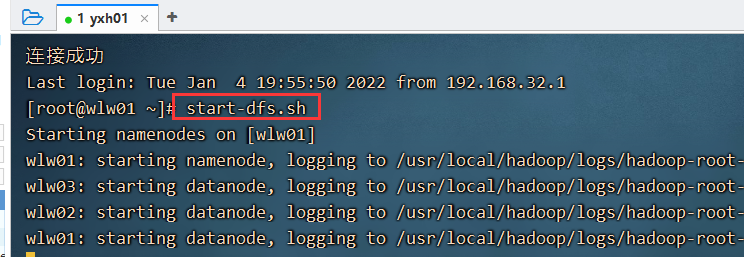
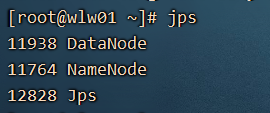
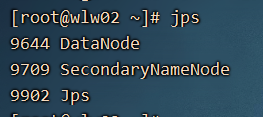
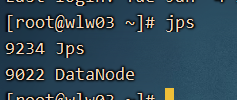
如何查看我们的这个hdfs大磁盘的数据呢?
图形化的web: http://192.168.32.135:50070/
可以查看里面的数据:
查看整个集群的数据:
NameNode 、SecondaryNameNode、DataNode
NameNode 节点在集群中只有一个(HA除外),DataNode 每一个电脑有一个。
NameNode:好比是图书馆里的一个查询目录,里面记录这每一个块数据分别放置的位置。
DataNode: 好比是书架(每一本书就是一个数据)
SecondaryNameNode:它是协助我们NameNode 进行数据备份的。因为NameNode中的数据是基于内存的,一旦电脑关停了,内存中的数据是会丢失的,SecondaryNameNode 每隔一个小时或者hdfs操作超过100万次,就会触发备份。下一次namenode 启动就会加载本地的备份数据到内存。
一个小技巧:
目前有三台电脑,每一次查看进行 需要在三台电脑上分别 jps 查看,非常不方便。可以通过shell编程,编写一个脚本:
将这个脚本上传到 /usr/local/bin 目录下。通过拖拽就可以。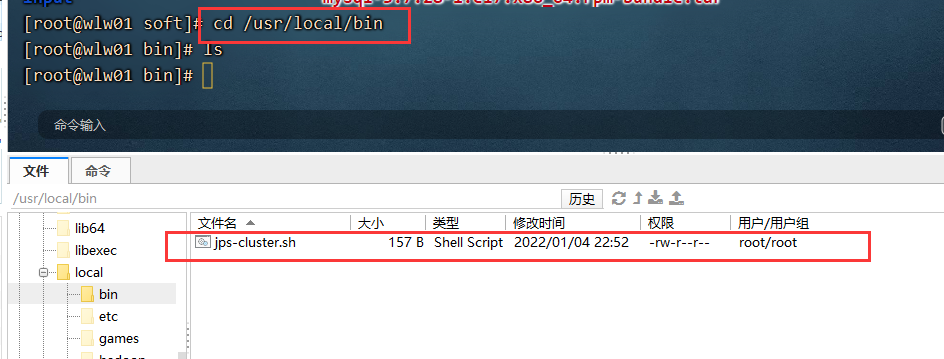
该脚本并没有执行的权限:
进入到该bin目录下,执行 chmod u+x jps-cluster.sh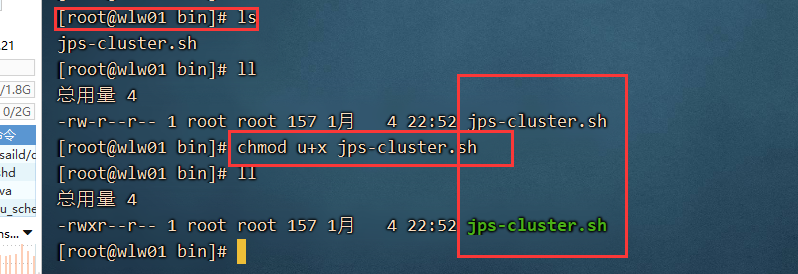
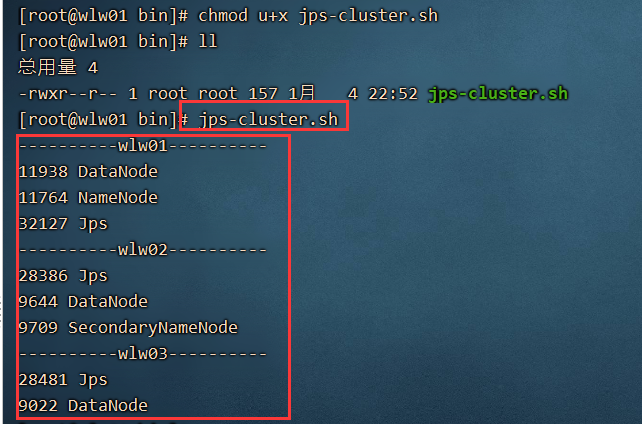
通过以上的脚本可以在wlw01上的任何地方输入 jps-cluster.sh 查看三台电脑的jps.
2、Yarn
Yarn是hadoop系统中一个非常重要的功能。好比是大数据中的操作系统(Linux、Windows)。
为我们运行大数据的MapReduce 以及Spark中的任务,提供了一个环境。是大数据整个运行环境的一个统称。
运行:start-yarn.sh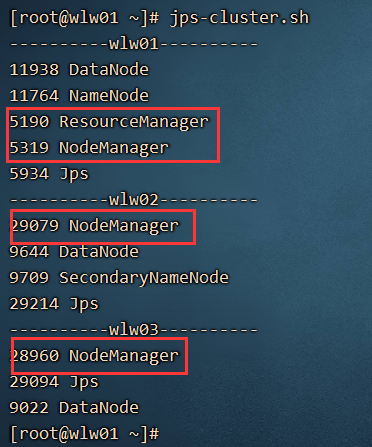
Yarn也有web界面:
http://192.168.32.135:8088/cluster
Yarn中的一些部件:
ResourceManager: 整个yarn平台只有一个,它相当于是技术总监,大Boss
NodeManager:相当于各个部分的经理。
AppMaster: 相当于项目经理
Container: 每一个Container 就相当于是一个个的虚拟机。相当于干活的员工。
3、MapReduce — 可以分为map阶段和reduce阶段
是用来编写代码的技术。编写代码时有一定的格式:
public class WordCountMapper extends Mapper
重写里面的map方法
public class WordCountReducer extends Reducer
重写里面的reduce方法
接着就开始编写一个入口main方法:
里面的代码无非就是mapper类和reduce类是哪一个,数据的来源在哪里,数据统计好的结果放哪里。
通过以上要说明的是:我们为了统计某个指标,需要编写大量代码,并且这么代码格式非常的固定。
造成效率非常慢,所以Hive诞生了。
三、Hive
<br />一)概念<br />Hive是一个基于Hadoop的数据仓库工具,可以将结构化的数据文件映射成一张数据表,并可以使用类似SQL的方式来对数据文件进行读写以及管理。HQL 语句。<br />1、将结构化的数据映射成表<br />2、通过HQL语句底层自动转换为MapReduce任务,跑出结构。<br />二)安装<br />1、上传安装包<br />
2、解压安装包
tar -xvf apache-hive-2.1.1-bin.tar.gz -C /usr/local/
3、重命名
cd /usr/local/
mv apache-hive-2.1.1-bin hive
4、配置环境变量
穿插:nodePad++用法,解压就可以使用了


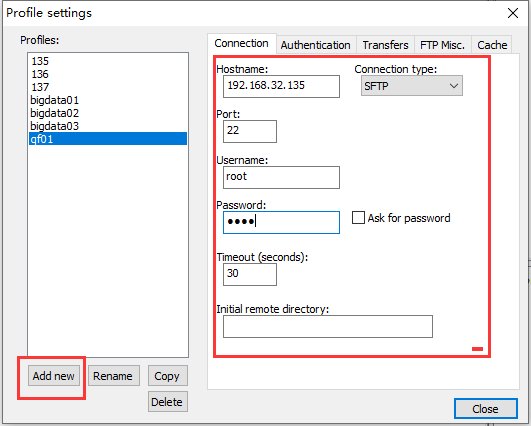

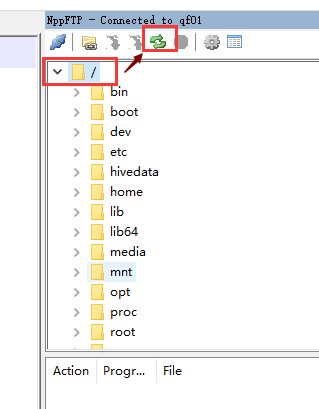
除了编辑本地的文本文件之外还可以远程编辑我们虚拟机中的文本文件,可以替代我们的vi 、vim 编辑器
开始修改环境变量: /etc/profile
export HIVE_HOME=/usr/local/hiveexport PATH=$PATH:$HIVE_HOME/bin
然后,刷新一下我们的配置文件 source /etc/profile
5、修改hive-env.sh
进入到 /usr/local/hive/conf 下,cp hive-env.sh.template hive-env.sh
export HIVE_CONF_DIR=/usr/local/hive/conf
export JAVA_HOME=/usr/local/jdk
export HADOOP_HOME=/usr/local/hadoop
export HIVE_AUX_JARS_PATH=/usr/local/hive/lib
6、创建hive-site.xml
在conf 文件夹下,cp hive-default.xml.template hive-site.xml
7、修改dir
通过命令的方式,操作我们的hdfs,创建文件夹
hdfs dfs -mkdir -p /user/hive/warehouse
hdfs dfs -mkdir -p /tmp/hive
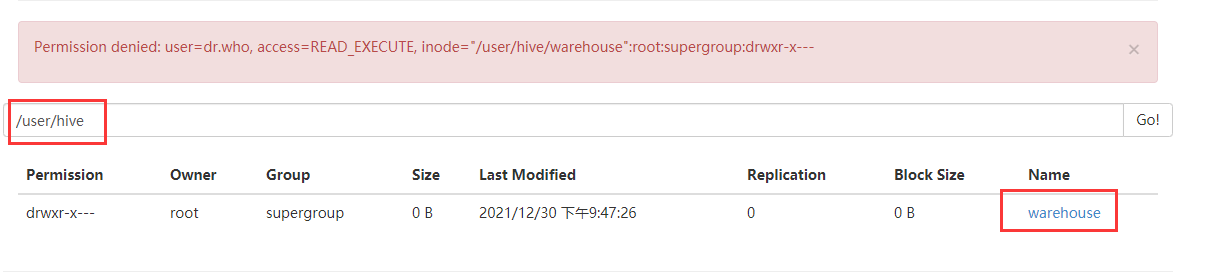
此处就在我们的hdfs上创建了多级文件夹,但是权限不够:
hdfs dfs -chmod 777 /user/hive/warehouse
hdfs dfs -chmod 777 /tmp/hive
8、修改io.temdir 路径
一定要在hive文件夹下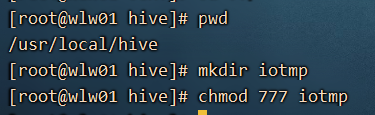
把hive-site.xml 中所有包含 ${system:Java.io.tmpdir}替换成/usr/local/hive/iotmp.
如果系统默认没有指定系统用户名,那么要把配置${system:user.name}替换成当前用户名root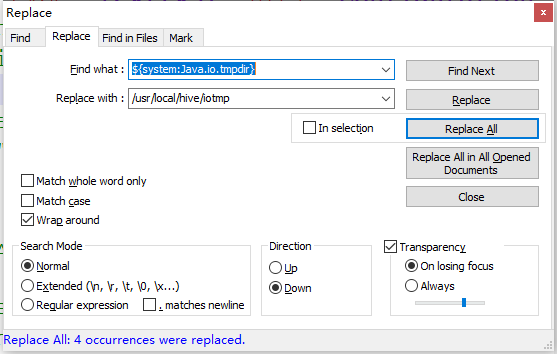
9、在保证hdfs以及yarn都启动的情况下,进行hive的初始化
schematool -initSchema -dbType derby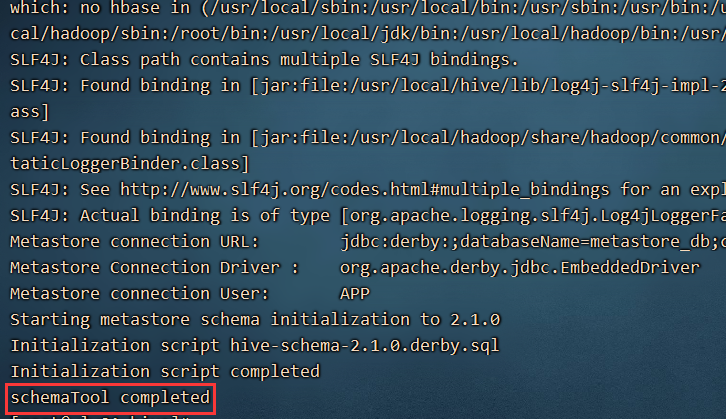
9)启动hive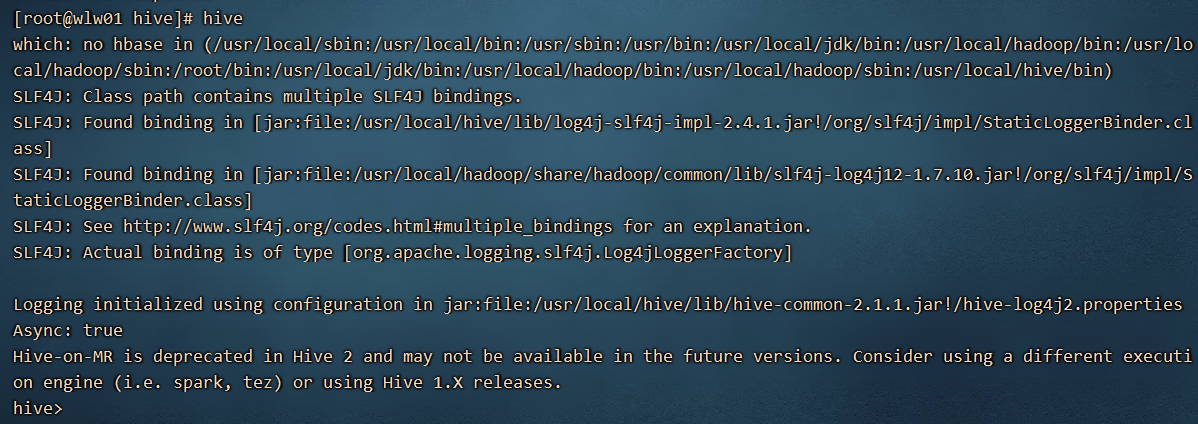
show databases;
查看所有的数据库。
以上模式是使用的嵌入式模式,有点是安装比较简单,缺点是两个窗口就报错: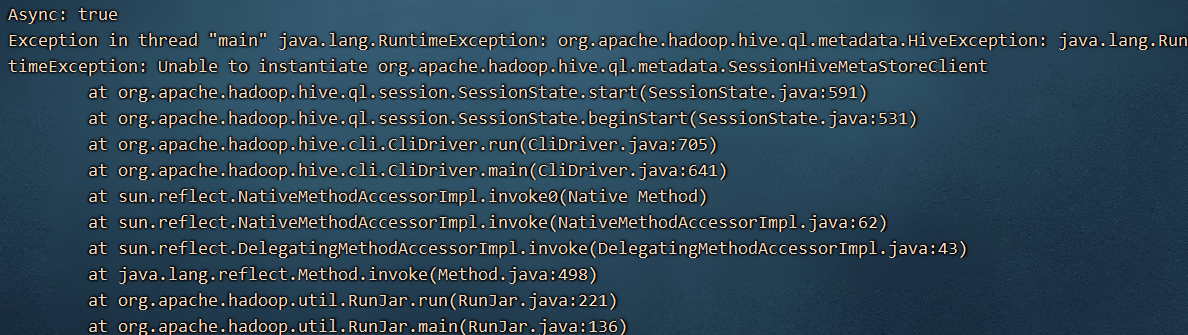
本地模式:将hive的元数据从Derby数据库中移动到了mysql 数据库中。
好处就是:可以开启多个窗口,执行hive操作。一般在企业中使用比较多的是本地模式。
三) 本地模式安装
1、安装MySQL数据库
1)启动mysql
systemctl restart mysqld
2) 查看mysql 的运行状态
systemctl status mysqld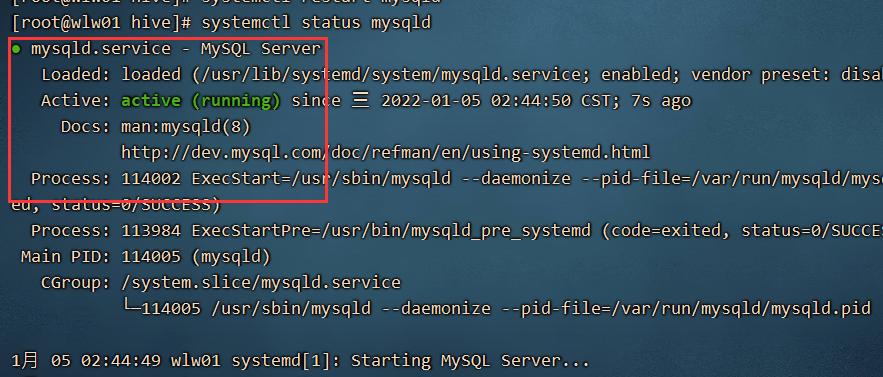
3) 连接mysql
mysql -uroot -proot 连接成功表示可以使用了。
2、修改hive-site.xml 配置文件
<!--配置mysql的连接字符串-->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<!--配置mysql的连接驱动-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<!--配置登录mysql的用户-->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use against metastore database</description>
</property>
<!--配置登录mysql的密码-->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
<description>password to use against metastore database</description>
</property>
3、添加驱动jar包
hive要连接mysql ,就需要添加mysql的驱动包。
hive 的退出使用 quit;<br /> mysql 的退出 exit<br /> <br /> <br /> cp mysql-connector-java-5.1.28-bin.jar /usr/local/hive/lib/<br />4、初始化hive --- 将数据初始化到我们的mysql 中<br /> schematool -initSchema -dbType mysql<br />5、在我们的mysql 中就多了一个数据库叫hive<br />我们可以使用navcat 去连接mysql<br /><br />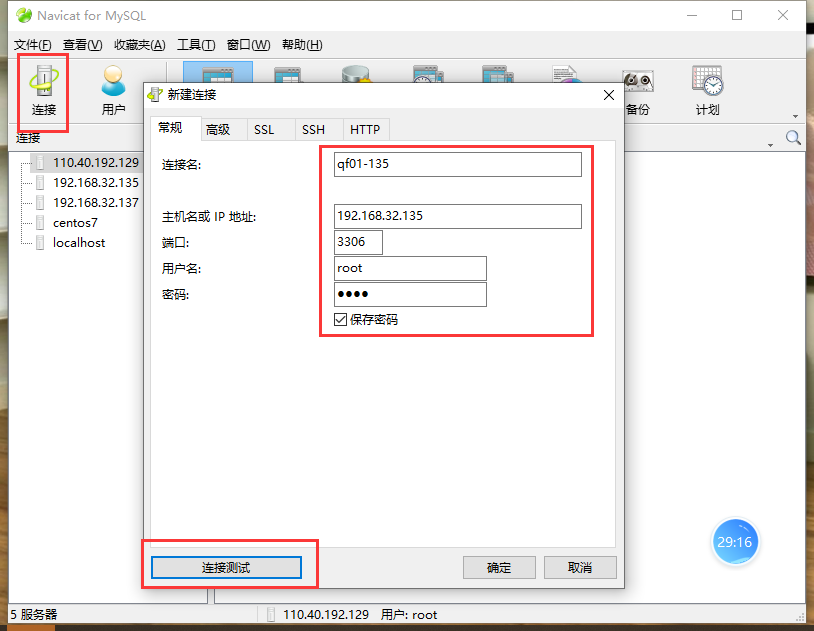<br />可以查看到有一个数据库叫hive:<br />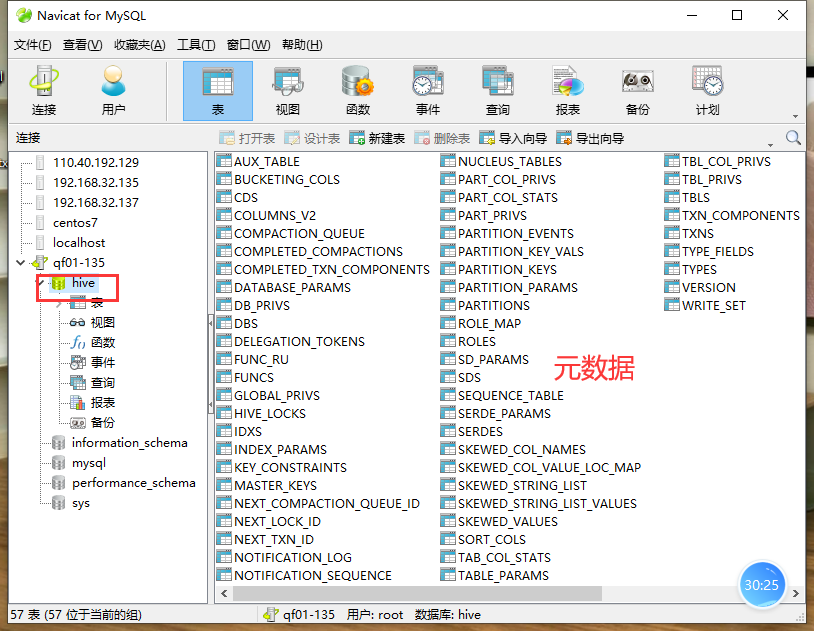<br />测试是否可以打开多个窗口操作hive.
四、hive的一些基本操作
hive的使用类似于mysql ,但是原理大不一样。
1)操作数据库
create database qf01;
create database if not exists qf02;
show databases;
create database if not exists qf03 comment ‘this is a 老闫’;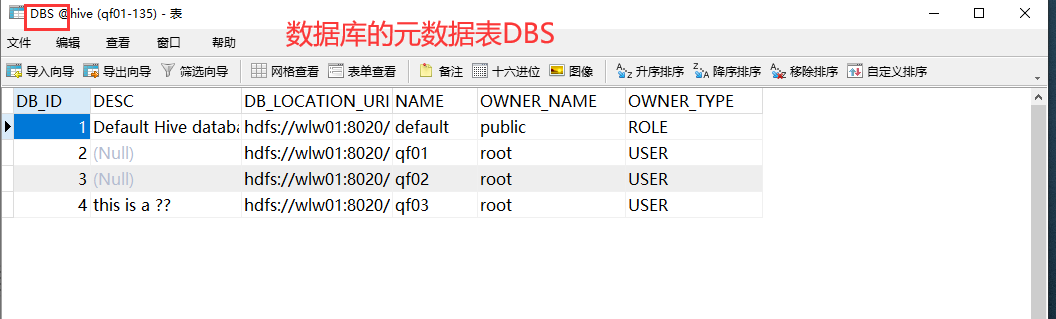
在创建表和数据库的时候,中间的中文会出现乱码,所以一般都写中文的。因为hive的元数据中的编码是拉丁编码。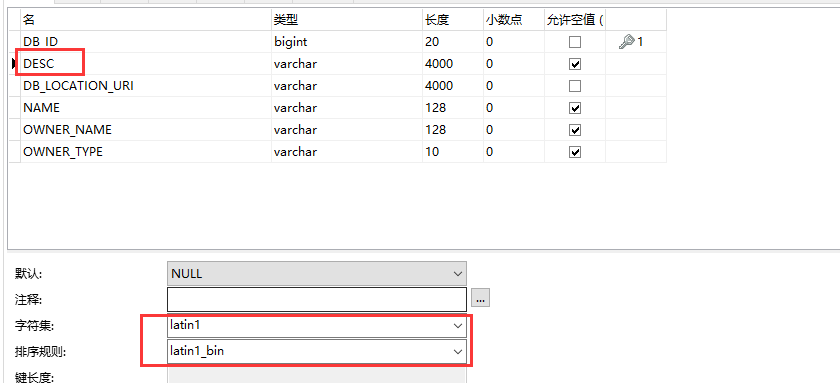
hive中的数据库元数据在mysql ,真正的数据在hdfs上。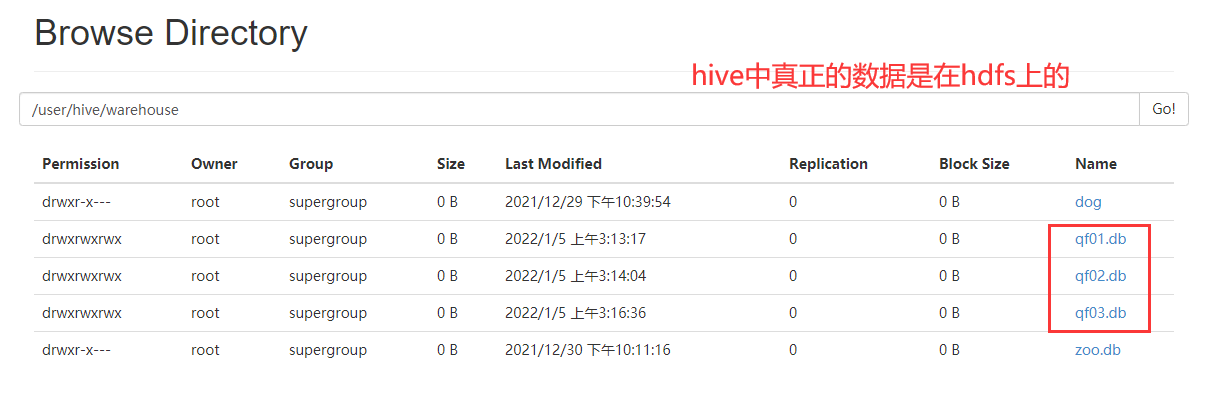
2、创建表
use qf01; 切换数据库
创建表:create table t_user(id int,name string);
创建表比较常见的HQL语句:
create table t_user
(
id int,
name string
)
row format delimited
fields terminated by '\t'
lines terminated by '\n';
show tables; //查看某个数据库下的所有表名
desc t_user ; 查看表中的字段
desc formatted t_user; //查看表中的详细的信息不仅仅表字段。
3、搞一个小技巧
select current_database();
每次我们在操作数据库的时候,经常不知道目前正在操作哪个数据库,我们必须使用select current_database(); 语句查询,非常的麻烦。
可以在/usr/local/hive/conf 下创建一个 .hiverc 文件,里面添加一句话:
set hive.cli.print.current.db=true;
进入到 目标文件夹 cd /usr/local/hive/conf
touch .hiverc 创建一个文件
然后通过nodepad++ 修改里面内容。重新进入hive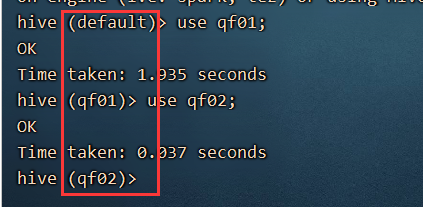
4、基本数据类型: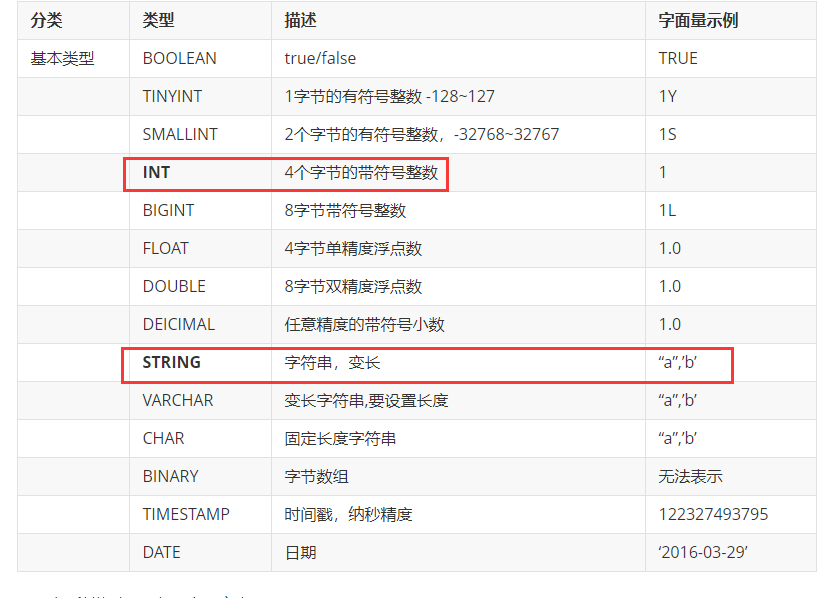
String 和Varchar 相比,选择String.
String 该字段可以存储2G的数据,varchar 最多存储65535个字符长度。

若有收获,就点个赞吧
0 人点赞
