学习目标
了解pandas库
掌握Series对象的建立、常见属性和方法
掌握DataFrame对象的建立、常见属性和方法
Pandas库
Pandas(Python Data Analysis Library)是基于NumPy的数据分析库,提供了高性能易用的数据类型,以及大量能使我们快速便捷地处理数据的函数和方法,可以说Pandas是使得Python能够成为高效且强大的数据分析环境的重要因素之一。
Pandas有三种数据结构:
- Series:类似于一维数组
- DataFrame是类似表格的二维数组
- Panel可以视为Excel的多表单
Series
Series对象是一维数组结构,与NumPy中的一维数组ndarray类似,二者与Python基本的数据结构list也很接近。
区别是list中的元素可以是不同的数据类型,而一维数组ndarray和Series中则只允许存储同一数据类型的数据。
Series包含了一个值序列,并且包含了数据标签,称为索引(index),可通过索引来访问数组中的数据。
| Series | |
|---|---|
| index | values |
| 0 | ‘a’ |
| 1 | ‘b’ |
| 2 | ‘c’ |
| 3 | ‘d’ |
Series对象创建
pandas.Series()方法创建
创建一个Series对象的最基本语法格式如下:pandas.Series(data = None, index = None, dtype = None, name = None)
说明:
- 返回值:返回一个Series对象
- data:可以是一个Python列表,index与列表元素个数一致;也可以是字典,将键值对中的“值”作为Series对象的数据,将“键”作为索引;也可以是一个标量值,这种情况下必须设置索引,标量值会重复来匹配索引的长度
- index:为Series对象的每个数据指定索引
- dtype:为Series对象的数据指定数据类型
- name:为Series对象起个名字 ```python import numpy as np import pandas as pd s = pd.Series(data = np.arange(0, 5, 2)) print(s)
‘’’ 0 0 1 2 2 4 dtype: int32 ‘’’
```pythonimport pandas as pds2 = pd.Series(25, index = ['a', 'b', 'c'])print(s2)'''a 25b 25c 25dtype: int64'''
import pandas as pdobj = pd.Series([1, -2, 3, -4])print(obj)'''0 11 -22 33 -4dtype: int64'''
import pandas as pdi = ['a', 'c', 'd', 'a']v = [2, 4, 5, 7]t = pd.Series(v, index = i, name = 'col')print(t)'''a 2c 4d 5a 7Name: col, dtype: int64'''
尽管创建Series指定了index参数,实际Pandas还是有隐藏的index位置信息的。
所以Series有两套描述某条数据的手段:
- 位置
- 标签 ```python val = [2, 4, 5, 6] idx1 = range(10, 14) idx2 = ‘hello the cruel world’.split() s0 = pd.Series(val) s1 = pd.Series(val, index = idx1) t = pd.Series(val, index = idx2) print(s0.index) print(s1.index) print(t.index) print(s0[0]) print(s1[10]) print(‘default:’,t[0], ‘label:’, t[‘hello’])
‘’’ RangeIndex(start=0, stop=4, step=1) RangeIndex(start=10, stop=14, step=1) Index([‘hello’, ‘the’, ‘cruel’, ‘world’], dtype=’object’) 2 2 default: 2 label: 2 ‘’’
<a name="YF0uJ"></a>### 通过字典创建如果数据被存放在一个Python字典中,也可以直接通过这个字典来创建Series。```pythonsdata = {'Ohio':35000, 'Texas':71000, 'Oregon':16000, 'Utah':5000}obj3 = pd.Series(sdata)print(obj3)'''Ohio 35000Texas 71000Oregon 16000Utah 5000dtype: int64'''
sdata = {'a':100, 'b':200, 'e':300}letter = ['a', 'b', 'c', 'e']obj = pd.Series(sdata, index = letter)print(obj)'''a 100.0b 200.0c NaNe 300.0dtype: float64'''
sdata = {'Ohio':35000, 'Texas':71000, 'Oregon':16000, 'Utah':5000}obj1 = pd.Series(sdata)states = ['California', 'Ohio', 'Oregon', 'Texas']obj2 = pd.Series(sdata, index = states)print(obj1 + obj2)'''California NaNOhio 70000.0Oregon 32000.0Texas 142000.0Utah NaNdtype: float64'''
obj = pd.Series([4, 7, -3, 2])obj.index = ['Bob', 'Steve', 'Jeff', 'Ryan']print(obj)'''Bob 4Steve 7Jeff -3Ryan 2dtype: int64'''
Series对象的属性
| 属性 | 描述 |
|---|---|
| shape | 获取Series对象的形状 |
| dtype | 获取Series对象的数据数组中的数据的数据类型 |
| values | 获取Series对象的数据数组 |
| index | 获取Series对象的数据数组的索引 |
| Series对象本身及索引的name属性 |
import pandas as pdobj = pd.Series([4, 7, -3, 2])obj.index = ['Bob', 'Steve', 'Jeff', 'Ryan']print(obj)print(obj.shape)print(obj.dtype)print(obj.values)print(obj.index)'''Bob 4Steve 7Jeff -3Ryan 2dtype: int64(4,)int64[ 4 7 -3 2]Index(['Bob', 'Steve', 'Jeff', 'Ryan'], dtype='object')'''
Series对象的数据的查看和修改
通过索引和切片查看Series对象的数据。
可以使用数据索引以“Series对象[id]”方式访问Series对象的数据数组中索引为id的数据。
s = pd.Series(data = [1, 2, 3], index = ['Java', 'C', 'Python'])print(s['C'])# 可通过默认索引来读取print(s[1])# 通过截取(切片)的方式读取多个元素print(s[0:2])'''22Java 1C 2dtype: int64'''
使用多个数据对应的索引来一次读取多个元素,注意索引要放在一个列表中。
根据筛选条件读取数据。
s = pd.Series(data = [1, 2, 3], index = ['Java', 'C', 'Python'])print(s[['Python', 'C', 'Java']])print(s[s > 1])'''Python 3C 2Java 1dtype: int64C 2Python 3dtype: int64'''
Series对象的基本运算
算术运算
适用于NumPy数组的运算符(+、-、、/)或其他数学函数,也适用于Series对象。
可以将Series对象的数据数组与标亮进行+、-、、/等算术运算。
函数运算
s = pd.Series([2, 4, 6], index = ['a', 'b', 'c'])# 计算各数据的平方根s1 = np.sqrt(s)# 计算各数据的平方s2 = np.square(s)print(s1)print(s2)'''a 1.414214b 2.000000c 2.449490dtype: float64a 4b 16c 36dtype: int64'''
Series对象之间的运算
Series对象之间也可进行+、-、*、/等运算,不同Series对象运算的时候,能够通过识别索引进行匹配计算,即只有索引相同的元素才会进行相应的运算操作。
s5 = pd.Series([10, 20], index = ['c', 'd'])s6 = pd.Series([2, 4, 6, 8], index = ['a', 'b', 'c', 'd'])# 相同索引值的元素相加,其他的补NaNprint(s5 + s6)'''a NaNb NaNc 16.0d 28.0dtype: float64'''
DataFrame对象
DataFrame是一个表格型的数据结构,既有行索引(保存在index)又有列索引(保存在columns),是Series对象从一维到多维的扩展。
DataFrame对象每列相同位置处的元素共用一个行索引,每行相同位置处的元素共用一个列索引。
DataFrame对象各列的数据类型可以不相同。
DataFrame对象的内部组成入土所示: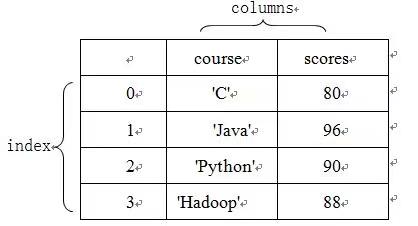
创建DataFrame对象
创建DataFrame对象最常用的方法是使用panda的DataFrame()构造函数。
格式:Pd.DataFrame(data = None, index = None, columns = None, dtype = None)
说法:
- 返回值:DataFrame对象
- data:创建DataFrame对象的数据,其类型可以是字典、嵌套列表、元组列表、numpy的ndarray对象、其他DataFrame对象
- index:行索引,创建DataFrame对象的数据时,如果没有提供索引,默认赋值为arange(n)
- columns:列索引,没有提供索引时,默认赋值为arange(n)
- dtype:用来指定元素的数据类型,如果为空,自动推断类型
- 可将一个字典对象传递给DataFrame()函数来生成一个DataFrame对象,字典的键作为DataFrame对象的列索引,字典的值作为列索引对应的列值,pandas也会自动为其添加一列从0开始的数值作为行索引。
```python
data = {‘course’:[‘C’, ‘Java’, ‘Python’, ‘Hadoop’],
df = pd.DataFrame(data) print(df)'scores':[82, 96, 92, 88],'grade':['B', 'A', 'A', 'B']}
‘’’ course scores grade 0 C 82 B 1 Java 96 A 2 Python 92 A 3 Hadoop 88 B ‘’’
可以只选择字典对象的一部分数据来创建DataFrame对象,只需在DataFrame构造函数中,用columns选项指定需要的列即可,新建的DataFrame对象各列顺序与指定的列顺序一致。```pythondata = {'course':['C', 'Java', 'Python', 'Hadoop'],'scores':[82, 96, 92, 88],'grade':['B', 'A', 'A', 'B']}df1 = pd.DataFrame(data, columns = ['course', 'grade'])print(df1)'''course grade0 C B1 Java A2 Python A3 Hadoop B'''
创建DataFrame对象时,如果没有用index数组明确指定行索引,pandas也会自动为其添加一列从0开始的数值作为行索引。如果想用自己定义的行索引,则要把定义的索引放到一个数组中,赋值给index选项。
data = {'course':['C', 'Java', 'Python', 'Hadoop'],'scores':[82, 96, 92, 88],'grade':['B', 'A', 'A', 'B']}df2 = pd.DataFrame(data, index = ['一', '二', '三', '四'])print(df2)'''course scores grade一 C 82 B二 Java 96 A三 Python 92 A四 Hadoop 88 B'''
创建DataFrame时,可以同时指定行索引和列索引,这时候就需要传递三个参数给DataFrame()构造函数,三个参数的顺序是:数据、index选项和columns选项。将存放行索引的数组赋值给index选项,将存放列索引的数组赋值给columns选项。
df3 = pd.DataFrame([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12], [13, 14, 15, 16]],index = ['一', '二', '三', '四'],columns = ['A', 'B', 'C', 'D'])print(df3)'''A B C D一 1 2 3 4二 5 6 7 8三 9 10 11 12四 13 14 15 16'''
以字典的字典或Series的字典的结构创建DataFrame对象,pandas会将外边的键解释成列名称,将里面的键解释成行索引。
data = {'name':{'one':'Jack', 'two':'Mary', 'three':'John', 'four':'Alice'},'age':{'one':10, 'two':20, 'three':30, 'four':40},'weight':{'one':30, 'two':40, 'three':50, 'four':65}}df = pd.DataFrame(data)print(df)'''name age weightone Jack 10 30two Mary 20 40three John 30 50four Alice 40 65'''
用键值为列表的字典构建DataFrame,其中每个列表(list)代表的是一个列,字典的键则是列索引。
这里要注意的是每个列表中的元素数量应该相同,否则会报错。
data1 = {'name':['Jack', 'Mary', 'John'],'age':[10, 20, 30],'weight':[30, 40, 50]}df = pd.DataFrame(data1)print(df)'''name age weight0 Jack 10 301 Mary 20 402 John 30 50'''
以字典的列表构建DataFrame,其中每个字典代表的是每条记录(DataFrame中的一行),字典中各个键的键值对应的是这条记录的相关属性。
d = [{'one':1, 'two':1}, {'one':2, 'two':2}, {'one':3, 'two':3}, { 'two':4} ]df = pd.DataFrame(d, index = ['a', 'b', 'c', 'd'], columns = ['one', 'two'])print(df)'''one twoa 1.0 1b 2.0 2c 3.0 3d NaN 4'''
以numpy对象构建DataFrame。
df4 = pd.DataFrame(np.arange(9).reshape(3, 3),index = ['a', 'c', 'd'],columns = ['one', 'two', 'four'])print(df4)'''one two foura 0 1 2c 3 4 5d 6 7 8'''
DataFrame对象的属性
| 属性名 | 功能描述 |
|---|---|
| T | 行列转置 |
| columns | 查看列索引名,可得到各列的名称 |
| dtypes | 查看各列的数据类型 |
| index | 查看行索引名 |
| shape | 查看DataFrame对象的形状 |
| size | 返回DataFrame对象包含的元素个数,为行数、列数大小的乘积 |
| values | 获取存储在DataFrame对象中的数据,返回一个NumPy数组 |
| index.name | 行索引的名称 |
| columns.name | 列索引的名称 |
| loc | 通过行索引获取行数据 |
| iloc | 通过行号获取行数据 |
DataFrame对象的常用属性
| 属性 | 返回值 |
|---|---|
| values | 元素 |
| index | 索引 |
| columns | 列名 |
| dtypes | 类型 |
| size | 元素个数 |
| ndim | 维度数 |
| shape | 数据形状(行列数目) |
data3 = {'':['one', 'two', 'three', 'four', 'five'],'status':['good', 'good', 'well', 'well', 'wonderful'],'year':['2012', '2013', '2014', '2015', '2016'],'index':[1, 2, 3, 4, 5]}df = pd.DataFrame(data3)print(df)print('信息表的所有值为:\n', df.values)print('信息表的所有列为:\n', df.columns)print('信息表的元素个数为:\n', df.size)print('信息表的维度为:\n', df.ndim)print('信息表的形状为:\n', df.shape)'''status year index0 one good 2012 11 two good 2013 22 three well 2014 33 four well 2015 44 five wonderful 2016 5信息表的所有值为:[['one' 'good' '2012' 1]['two' 'good' '2013' 2]['three' 'well' '2014' 3]['four' 'well' '2015' 4]['five' 'wonderful' '2016' 5]]信息表的所有列为:Index(['', 'status', 'year', 'index'], dtype='object')信息表的元素个数为:20信息表的维度为:2信息表的形状为:(5, 4)'''
索引对象
Pandas的索引对象负责管理轴标签和其他元数据(比如轴名称等)。
构建Series或DataFrame时,所用到的任何数组或其他序列的标签都会被转换成一个index。
df = pd.DataFrame(np.arange(9).reshape(3,3),index = ['a', 'c', 'd'],columns = ['one', 'two', 'four'])print(df)print(df.index)print(df.columns)print('name' in df.columns)print('a' in df.index)'''one two foura 0 1 2c 3 4 5d 6 7 8Index(['a', 'c', 'd'], dtype='object')Index(['one', 'two', 'four'], dtype='object')FalseTrue'''
每个索引都有一些方法和属性,他们可用于设置逻辑并回答有关该索引所包含的数据的常见问题。
index的常用方法和属性
| 方法 | 说明 |
|---|---|
| append | 连接另一个index对象,产生一个新的index |
| diff | 计算差集,并得到一个index |
| intersection | 计算交集 |
| union | 计算并集 |
| isin | 计算一个指示各值是否都包含在参数集合中的布尔型数组 |
| delete | 删除索引i处的元素,并得到新的index |
| drop | 删除传入的值,并得到新的index |
| insert | 将元素插入到索引i处,并得到新的index |
| is_monotonic | 当各元素均大于等于前一个元素时,返回True |
| is.unique | 当index没有重复值时,返回True |
| unique | 计算index中唯一值的数组 |
重新索引
obj.reindex()函数:返回索引重新排序后的数据对象
格式:obj.reindex(index, method, fill_value, limit, level, copy)
说明:
- index:用于索引的新序列
- method:插值(填充)方式
- fill_value:缺失值替换值
- limit:最大填充量
- level:在multiindex的指定级别上匹配简单索引,否则选取其子集
- 默认为True,无论如何都复制;如果为False,则新旧相等时就不复制
索引对象是无法修改的,因此,重新索引是指对索引重新排序而不是重新命名,如果某个索引值不存在的话,会引入缺失值。
对于重建索引引入的缺失值,可以利用fill_value参数填充。
obj = pd.Series([7.2, -4.3, 4.5, 3.6],index = ['b', 'a', 'd', 'c'])print(obj)obj.reindex(['a', 'b', 'c', 'd', 'e'])'''b 7.2a -4.3d 4.5c 3.6dtype: float64a -4.3b 7.2c 3.6d 4.5e NaNdtype: float64'''
obj = pd.Series([7.2, -4.3, 4.5, 3.6],index = ['b', 'a', 'd', 'c'])print(obj)obj.reindex(['a', 'b', 'c', 'd', 'e'], fill_value = 0)'''b 7.2a -4.3d 4.5c 3.6dtype: float64a -4.3b 7.2c 3.6d 4.5e 0.0dtype: float64'''
对于顺序数据,比如时间序列,重新索引时可能需要进行插值或填值处理,利用参数method选项可以设置:
- method = ‘ffill’或’pad’,表示前向值填充
- method = ‘bfill’或’backfill’,表示后向值填充 ```python import numpy as np obj1 = pd.Series([‘blue’, ‘red’, ‘black’], index = [0, 2, 4]) obj1.reindex(np.arange(6), method = ‘ffill’)
‘’’ 0 blue 1 blue 2 red 3 red 4 black 5 black dtype: object ‘’’
```pythonimport numpy as npobj1 = pd.Series(['blue', 'red', 'black'], index = [0, 2, 4])obj1.reindex(np.arange(6), method = 'backfill')'''0 blue1 red2 red3 black4 black5 NaNdtype: object'''
更换索引
如果不希望使用默认的行索引,则可以在创建的时候通过index参数来设置。
在DataFrame数据中,如果希望将列数据作为索引,则可以通过set_index方法来实现。
import pandas as pddata2 = {'name':['Alice', 'Jack', 'John', 'Mary'],'age':[40, 10, 30, 20],'weight':[65, 30, 50, 40]}df = pd.DataFrame(data2, index = ['four', 'one', 'three', 'two'])df1 = df.set_index('name')print(df)print(df1)'''name age weightfour Alice 40 65one Jack 10 30three John 30 50two Mary 20 40age weightnameAlice 40 65Jack 10 30John 30 50Mary 20 40'''
DataFrame数据的编辑
增加数据
增加一行:直接通过append方法传入字典结构数据即可。
import numpy as npimport pandas as pddata2 = {'name':['Alice', 'Jack', 'John', 'Mary'],'age':[40, 10, 30, 20],'weight':[65, 30, 50, 40]}df = pd.DataFrame(data2, index = ['four', 'one', 'three', 'two'])print('原数据:\n', df)data1 = {'name':'Harli', 'age':33, 'weight':55}df.append(data1, ignore_index = True)
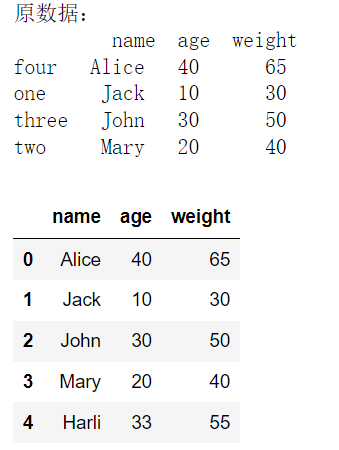
增加一列:只需为要增加的列赋值即可创建一个新的列。
import numpy as npimport pandas as pddata2 = {'name':['Alice', 'Jack', 'John', 'Mary'],'age':[40, 10, 30, 20],'weight':[65, 30, 50, 40]}df = pd.DataFrame(data2, index = ['four', 'one', 'three', 'two'])print('原数据:\n', df)df['math'] = 85df['paper'] = [82, 90, 86, 88]print(df)'''原数据:name age weightfour Alice 40 65one Jack 10 30three John 30 50two Mary 20 40name age weight math paperfour Alice 40 65 85 82one Jack 10 30 85 90three John 30 50 85 86two Mary 20 40 85 88'''
删除数据
drop()方法:删除数据
格式:df.drop('要删除的行列名称', axis = , inplace = )
说明:
- 通过axis参数确定删除的是行还是列
- 默认数据删除不修改原数据,需要在原数据删除行和列需要设置参数inplace = True
```python
import numpy as np
import pandas as pd
data2 = {‘name’:[‘Alice’, ‘Jack’, ‘John’, ‘Mary’],
df = pd.DataFrame(data2, index = [‘four’, ‘one’, ‘three’, ‘two’]) print(‘原数据:\n’, df) print(df.drop(‘two’))'age':[40, 10, 30, 20],'weight':[65, 30, 50, 40]}
‘’’ 原数据: name age weight four Alice 40 65 one Jack 10 30 three John 30 50 two Mary 20 40 name age weight four Alice 40 65 one Jack 10 30 three John 30 50 ‘’’
```pythonimport numpy as npimport pandas as pddata2 = {'name':['Alice', 'Jack', 'John', 'Mary'],'age':[40, 10, 30, 20],'weight':[65, 30, 50, 40]}df = pd.DataFrame(data2, index = ['four', 'one', 'three', 'two'])print('原数据:\n', df)df.drop('age', axis = 1, inplace = True)print(df)'''原数据:name age weightfour Alice 40 65one Jack 10 30three John 30 50two Mary 20 40name weightfour Alice 65one Jack 30three John 50two Mary 40'''
修改数据
修改一个数据时直接对选择数据赋值即可。
注意:数据修改是直接对DataFrame数据修改,操作无法撤销,因此更改数据时要做好数据备份。
import numpy as npimport pandas as pddata2 = {'name':['Alice', 'Jack', 'John', 'Mary'],'age':[40, 10, 30, 20],'weight':[65, 30, 50, 40]}df = pd.DataFrame(data2)print(df)df['name'][0] = 'Grace'print(df)'''name age weight0 Alice 40 651 Jack 10 302 John 30 503 Mary 20 40name age weight0 Grace 40 651 Jack 10 302 John 30 503 Mary 20 40C:\Users\ADMINI~1.NZ3\AppData\Local\Temp/ipykernel_10160/4289633496.py:8: SettingWithCopyWarning:A value is trying to be set on a copy of a slice from a DataFrameSee the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copydf['name'][0] = 'Grace''''
可以用DataFrame对象的name属性为DataFrame对象的列索引columns和行索引index指定别名称,以便于识别。
import numpy as npimport pandas as pddata1 = {'name':['Alice', 'Jack', 'John', 'Mary'],'age':[40, 10, 30, 20],'weight':[65, 30, 50, 40]}df = pd.DataFrame(data1)df.index.name = 'id'df.columns.name = 'item'print(df)'''item name age weightid0 Alice 40 651 Jack 10 302 John 30 503 Mary 20 40'''
可以为DataFrame对象添加新的列,指定新列的名称,以及为新列赋值。
import numpy as npimport pandas as pddata1 = {'name':['Alice', 'Jack', 'John', 'Mary'],'age':[40, 10, 30, 20],'weight':[65, 30, 50, 40]}df = pd.DataFrame(data1)# 添加新列,并都赋值为10df['new'] = 10print(df)'''name age weight new0 Alice 40 65 101 Jack 10 30 102 John 30 50 103 Mary 20 40 10'''
DataFrame数据的查询与编辑
在数据分析中,选取需要的数据进行分析处理是最基本的操作。
在Pandas中需要通过索引完成数据的选取。
选取列
通过列索引或以属性的方式可以单独获取DataFrame的列数据,返回的数据类型为Series。
import numpy as npimport pandas as pddata2 = {'name':['Alice', 'Jack', 'John', 'Mary'],'age':[40, 10, 30, 20],'weight':[65, 30, 50, 40]}df = pd.DataFrame(data2, index = ['four', 'one', 'three', 'two'])print('原数据:\n', df)w1 = df['name']print('选取1列数据:\n', w1)w2 = df[['name', 'age']]print('选取2列数据:\n', w2)'''原数据:name age weightfour Alice 40 65one Jack 10 30three John 30 50two Mary 20 40选取1列数据:four Aliceone Jackthree Johntwo MaryName: name, dtype: object选取2列数据:name agefour Alice 40one Jack 10three John 30two Mary 20'''
选取行
通过切片形式可以选取一行或多行数据。
import numpy as npimport pandas as pddata2 = {'name':['Alice', 'Jack', 'John', 'Mary'],'age':[40, 10, 30, 20],'weight':[65, 30, 50, 40]}df = pd.DataFrame(data2, index = ['four', 'one', 'three', 'two'])print('原数据:\n', df)print('显示前2行:\n', df[:2])print('显示2-3行:\n', df[1:3])'''原数据:name age weightfour Alice 40 65one Jack 10 30three John 30 50two Mary 20 40显示前2行:name age weightfour Alice 40 65one Jack 10 30显示2-3行:name age weightone Jack 10 30three John 30 50'''
查看DataFrame对象中的一个元素
要想获取存储在DataFrame对象中的一个元素,需要依次指定元素所在的列名称、行名称(索引)。
import numpy as npimport pandas as pddata2 = {'name':['Alice', 'Jack', 'John', 'Mary'],'age':[40, 10, 30, 20],'weight':[65, 30, 50, 40]}df = pd.DataFrame(data2)print(df)print(df['age'][1])'''name age weight0 Alice 40 651 Jack 10 302 John 30 503 Mary 20 4010'''
布尔选择
可以对DataFrame中的数据进行布尔方式选择。
import numpy as npimport pandas as pddata2 = {'name':['Alice', 'Jack', 'John', 'Mary'],'age':[40, 10, 30, 20],'weight':[65, 30, 50, 40]}df = pd.DataFrame(data2, index = ['four', 'one', 'three', 'two'])df[df['weight'] == 50]

判断元素是否属于DataFrame对象
可通过DataFrame对象的方法isin()判断一组元素是否属于DataFrame对象。
import numpy as npimport pandas as pddata2 = {'name':['Alice', 'Jack', 'John', 'Mary'],'age':[40, 10, 30, 20],'weight':[65, 30, 50, 40]}df = pd.DataFrame(data2, index = ['four', 'one', 'three', 'two'])print(df)print(df.isin(['Jack', 30]))'''name age weightfour Alice 40 65one Jack 10 30three John 30 50two Mary 20 40name age weightfour False False Falseone True False Truethree False True Falsetwo False False False'''
数据运算与排序
DataFrame对象的数据运算与排序方法如表所示,表中的df表示一个DataFrame对象。
| 数据运算与排序方法 | 描述 |
|---|---|
| df.T | df的行列转置 |
| df * N | df的所有元素乘以N |
| df1 + df2 | 将df1和df2的行名和列名都相同的元素相加 其他位置的元素用NaN填充 |
| df1.add(other, axis = ‘columns’, level = None, fill_value = None) | 将df1中的元素与other中的元素相加 other的类型可以是scalar(标量)、sequence(序列)、Series、DataFrame等形式 |
| df1.sub(other, axis = ‘columns’, level = None, fill_value = None) | 将df1中的元素与other中的元素相减 |
| df1.div(other, axis = ‘columns’, level = None, fill_value = None) | 将df1中的元素与other中的元素相除 |
| df1.(other, axis = ‘columns’, level = None, fill_value = None) | 将df1中的元素与other中的元素相乘 |
| df.apply(func, axis = 0) | 将func函数应用到df的行或列所构成的一维数组上 |
| df.applymap(func) | 将func函数应用到各个元素上 |
| df.sort_index(axis = 0, ascending = True) | 按行索引进行升序排序 |
| df.sort_values(by, axis = 0, ascending = True) | 按指定的列或行进行值排序 |
| df.rank(axis = 0, method = ‘aveage’, ascending = True) |
沿着行计算元素值的排名 对于相同的两个元素值,沿着行顺序排在前面的数据排名高 返回各个位置上元素值从小到大排序对应的序号 |
DataFrame数据的筛选
可以通过指定条件筛选DataFrame对象的元素。
import numpy as npimport pandas as pddata2 = {'name':['Alice', 'Jack', 'John', 'Mary'],'age':[40, 10, 30, 20],'weight':[65, 30, 50, 40]}df = pd.DataFrame(data2)print(df[df.weight > 35])print(df[df.age > 35])'''name age weight0 Alice 40 652 John 30 503 Mary 20 40name age weight0 Alice 40 65'''
DataFrame对象的常用数据筛选方法如表所示:
| DataFrame对象的数据筛选方法 | 描述 |
|---|---|
| df.head(N) | 返回前N行 |
| df.tail(M) | 返回后M行 |
| df[m:n] | 切片, 选取m~n-1行 |
| df[df[‘列名’] > value] | 选取满足条件的行 |
| df.query(‘列名 > value’) | 选取满足条件的行 |
| df.query(‘列名 == [v1, v2, …]’) | 选取列名的值等于v1, v2, …的行 |
| df.iloc[:, col] | 选取colname列的所有行 |
| df.iloc[row, col] | 选取某一元素 |
| df[‘col’] | 获取col列,返回Series |
选取通过DataFrame提供的head和tail方法可以得到多行数据,但是用这两种得到的数据都是从开始或末尾获取连续的数据,而利用sample可以随机抽取数据并显示。
- head():默认获取前5行
- head(n):获取前n行
- tail();默认获取后5行
- tail(n):获取后n行
- sample():随机抽取n行显示
选取行和列:
- DataFrame.loc(行索引名称或条件,列索引名称)
- DataFrame.iloc(行索引位置,列索引位置)
```python
import numpy as np
import pandas as pd
data2 = {‘name’:[‘Alice’, ‘Jack’, ‘John’, ‘Mary’],
df = pd.DataFrame(data2, index = [‘four’, ‘one’, ‘three’, ‘two’]) print(df.loc[:, [‘name’, ‘age’]]) print(df.loc[[‘three’, ‘two’], [‘name’, ‘age’]])'age':[40, 10, 30, 20],'weight':[65, 30, 50, 40]}
‘’’ name age four Alice 40 one Jack 10 three John 30 two Mary 20 name age three John 30 two Mary 20 ‘’’
```pythonimport numpy as npimport pandas as pddata2 = {'name':['Alice', 'Jack', 'John', 'Mary'],'age':[40, 10, 30, 20],'weight':[65, 30, 50, 40]}df = pd.DataFrame(data2, index = ['four', 'one', 'three', 'two'])print(df.iloc[:, 2])print(df.iloc[[1, 3], [1, 2]])'''four 65one 30three 50two 40Name: weight, dtype: int64age weightone 10 30two 20 40'''
算术运算
Pandas的数据对象在进行算术运算时,如果有相同索引则进行算术运算,如果没有,则会自动进行数据对齐,但会引入缺失值。
import pandas as pdobj1 = pd.Series([5.1, -2.6, 7.8, 10], index = ['a', 'c', 'g', 'f'])print('obj1:\n', obj1)obj2 = pd.Series([2.6, -2.8, 3.7, -1.9], index = ['a', 'b', 'g', 'h'])print('obj2:\n', obj2)print(obj1 + obj2)'''obj1:a 5.1c -2.6g 7.8f 10.0dtype: float64obj2:a 2.6b -2.8g 3.7h -1.9dtype: float64a 7.7b NaNc NaNf NaNg 11.5h NaNdtype: float64'''
a = np.arange(6).reshape(2, 3)b = np.arange(4).reshape(2, 2)df1 = pd.DataFrame(a, columns = ['a', 'b', 'e'], index = ['A', 'C'])print('df1:\n', df1)df2 = pd.DataFrame(b, columns = ['a', 'b'], index = ['A', 'D'])print('df2:\n', df2)print('df1 + df2:\n', df1 + df2)'''df1:a b eA 0 1 2C 3 4 5df2:a bA 0 1D 2 3df1 + df2:a b eA 0.0 2.0 NaNC NaN NaN NaND NaN NaN NaN'''
函数应用和映射
已定义好的函数可以通过以下三种方法应用到数据:
- map函数:将函数套用到Series的每个元素中
- apply函数:将函数套用到DataFrame的行或列上,行与列通过axis参数设置
- applymap函数:将函数套用到DataFrame的每个元素上 ```python data = {‘fruit’:[‘apple’, ‘grape’, ‘banana’], ‘price’:[‘30元’, ‘43元’, ‘28元’]} df1 = pd.DataFrame(data) print(df1) def f(x): return x.split(‘元’)[0] df1[‘price’] = df1[‘price’].map(f) print(‘修改后的数据表:\n’, df1)
‘’’ fruit price 0 apple 30元 1 grape 43元 2 banana 28元 修改后的数据表: fruit price 0 apple 30 1 grape 43 2 banana 28 ‘’’
`apply()`函数:将func函数应用到DataFrame对象df的行或列所构成一维数组上<br />格式:`df.apply(func, axis = 0)`<br />说明:- 应用到行或列上的函数- axis;axis = 0,对每一列应用func函数;axis = 1,对每一行应用函数```pythonimport pandas as pddf4 = pd.DataFrame([[0, 1, 2, 3], [4, 5, 6, 7], [8, 9, 10, 11], [12, 13, 14, 15]],index = ['A', 'B', 'C', 'D'], columns = ['a', 'b', 'c', 'd'])# 计算数组元素的取值间隔def f(x):return x.max() - x.min()print(df4)print(df4.apply(f, axis = 0))'''a b c dA 0 1 2 3B 4 5 6 7C 8 9 10 11D 12 13 14 15a 12b 12c 12d 12dtype: int64'''
import numpy as npumport pandas as pddf2 = pd. DataFrame(np.random.randn(3, 3),columns = ['a', 'b', 'c'],index = ['app', 'win', 'mac'])print(df2)df2.apply(np.mean)'''a b capp -0.770779 1.087394 0.968645win 0.378884 -1.568485 1.135082mac 0.657291 -1.121842 0.345367a 0.088465b -0.534311c 0.816365dtype: float64'''
df2 = pd.DataFrame(np.random.rand(3, 3),columns = ['a', 'b', 'c'],index = ['app', 'win', 'mac'])print(df2)df2.applymap(lambda x : '%.3f' %x)
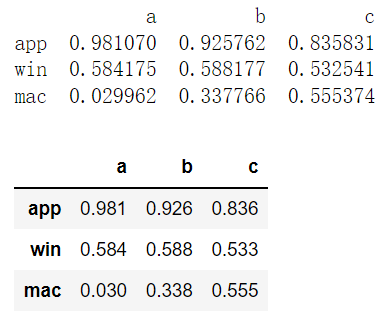
数据排序
df.sort_values(by, axis = 0, ascending = True)
作用:按指定的列或行进行值排序
说明:
- by:指定某些行或列作为排序的依据
- axis:axis = 0,对列进行排序;axis = 1,对行进行排序
```python
data5 = {‘col1’:[‘A’, ‘A’, ‘B’, ‘D’, ‘C’],
df = pd.DataFrame(data5, index = [0, 1, 2, 3, 4]) print(df) print(df.sort_values(by = [‘col1’, ‘col2’]))'col2':[2, 9, 8, 7, 4],'col3':[1, 9, 4, 2, 3]}
‘’’ col1 col2 col3 0 A 2 1 1 A 9 9 2 B 8 4 3 D 7 2 4 C 4 3 col1 col2 col3 0 A 2 1 1 A 9 9 2 B 8 4 4 C 4 3 3 D 7 2 ‘’’
`df.sort_index()`<br />作用:对索引进行排序<br />说明:- 默认为升序,降序排序时加参数`ascending = False````pythonwy = pd.Series([1, -2, 4, -4], index = ['c', 'b', 'a', 'd'])print(wy)print('排序后的Series:\n',wy.sort_index())'''c 1b -2a 4d -4dtype: int64排序后的Series:a 4b -2c 1d -4dtype: int64'''
对于DataFrame数据排序,通过指定轴方向,使用sort_index函数对行或列索引进行排序。
如果要进行列排序,则通过sort_values函数把列名传给by参数即可。
df2 = pd.DataFrame(np.random.rand(3, 3),columns = ['a', 'b', 'c'],index = ['app', 'win', 'mac'])print(df2)print('排序后的DataFrame:\n',df2.sort_values('c'))'''a b capp 0.284547 0.487116 0.475905win 0.853080 0.653251 0.837440mac 0.587622 0.592593 0.953217排序后的DataFrame:a b capp 0.284547 0.487116 0.475905win 0.853080 0.653251 0.837440mac 0.587622 0.592593 0.953217'''
数学统计
DataFrame对象的常用数学统计方法如表所示:
| 数学统计方法 | 描述 |
|---|---|
| df.count(axis = 0, level = None) | 统计每列或每行非NaN的元素个数 |
| df.describe(percentiles = None, include = None, exclude = None) | 生成描述性统计,总结数据集分布的中心趋势,分散和形状,不包括NaN值 |
| df.max(axis = 0) | axis = 0表示返回每列的最大值 axis = 1表示返回每行的最大值 |
| df.min(axis = 0) | axis = 0表示返回每列的最小值 axis = 1表示返回每行的最小值 |
| df.sum(axis = None, skipna = None, level = None) | 返回指定轴上元素值和 |
| df.mean(axis = None, skipna = None, level = None) | 返回指定轴上元素值的平均值 |
| df.median(axis = None, skipna = None, level = None) | 返回指定轴上元素值的中位数 |
| df.var(axis = None, skipna = None, level = None) | 返回指定轴上元素值的均方差 |
| df.std(axis = None, skipna = None, level = None) | 返回指定轴上元素值的标准差 |
| df.cov() | 计算df的列列之间的协方差,不包括NaN空值 |
| df.corr(method = ‘pearson’) | 计算df的列列之间的相关性,不包括NaN空值 |
| df1.corrwith(df2) | 计算df1与df2的行或列之间的相关性 |
| df.cumsum(axis = 0, skipna = True) | 对df求累加和,计算结果是与df形状相同的DataFrame对象 |
| df.cumprod(axis = None, skipna = True) | 返回df指定轴的元素的累计积 |
Pandas中常用的描述性统计量表
| 方法名称 | 说明 | 方法名称 | 说明 |
|---|---|---|---|
| min | 最小值 | max | 最大值 |
| mean | 均值 | ptp | 极差 |
| median | 中位数 | std | 标准差 |
| var | 方差 | cov | 协方差 |
| sem | 标准误差 | mode | 众数 |
| skew | 样本偏度 | kurt | 样本峰度 |
| quantile | 四分位数 | count | 非空值数目 |
| describe | 描述统计 | mad | 平均绝对离差 |
唯一值和值计数
通过Series对象的unique()方法可以获取不重复的数据。
通过Series对象的value_counts()方法可以统计每个值出现的次数。
import pandas as pddf = pd.DataFrame({'Va1':[1, 3, 4, 3, 4], 'Va2':[2, 3, 1, 2, 3], 'Va3':[1, 5, 2, 4, 4]})print('原DataFrame:\n', df)print('Va1频数统计:\n', df['Va1'].value_counts())print('Va3去重:\n', df['Va3'].unique())'''原DataFrame:Va1 Va2 Va30 1 2 11 3 3 52 4 1 23 3 2 44 4 3 4Va1频数统计:3 24 21 1Name: Va1, dtype: int64Va3去重:[1 5 2 4]'''
数据分组与聚合
对数据集进行分组并对各分组应用函数是数据分析中的重要环节。
在pandas中,分组运算主要通过groupby函数来完成,聚合操作主要通过agg函数来完成。
分组的基本过程是:
- 首先数据集按照分组键(key)的方式分成小的数据片(split)
- 然后对每一个数据片进行操作
- 最后将结果再组合起来形成新的数据集(combine)
groupby对数据进行数据分组运算的过程分为三个阶段:分组、用函数处理分组和分组结果合并。
- 分组。
按照键(key)或者分组变量将数据分组。
分组键可以有多种形式,且类型不必相同:
- 列表或数组,其长度与待分组的轴一样
- DataFrame对象的 某个列名
- 字典或Series,给出待分组轴上的值域分组名之间的对应关系
- 函数,用于处理轴索引或索引中的各个标签
- 用函数处理。
对于每个分组应用指定的函数,这些函数可以是Python自带函数,可以是自定义的函数。
- 合并分组处理结果。
数据分组
df.groupby(by = None, axis = 0, level = None, as_index = True, sort = True, group_keys = True, squeeze = False)
作用:通过指定列索引或行索引,对df的数据元素进行分组
说明:
- by:可以传入函数、字典、Series等,用于确定分组的依据
- axis:接收int,表示操作的轴方向,默认为0
- level:接收int或索引名,代表标签所在级别,默认为None
- as_index:接收boolean,表示聚合后的标签是否以DataFrame索引输出
- sort:接收boolean,表示对分组依据和分组标签排序,默认为True
- group_keys:接收boolean,表示是否显示分组标签的名称,默认为True
- squeeze:接收boolean,表示是否在允许情况下对返回数据降维,默认为False
```python
import pandas as pd
import numpy as np
df = pd.DataFrame({‘key1’:[‘a’, ‘a’, ‘b’, ‘b’, ‘a’],
grouped = df[‘data1’].groupby(df[‘key1’]) print(grouped.size()) print(grouped.mean())'key2':['yes', 'no','yes', 'yes', 'no'],'data1':np.random.randn(5),'data2':np.random.randn(5)})
‘’’ key1 a 3 b 2 Name: data1, dtype: int64 key1 a -1.339624 b 0.988889 Name: data1, dtype: float64 ‘’’
> DataFrame数据的列索引名可以作为分组键,但注意的是用于分组的对象必须是DataFrame数据本身,否则搜索不到索引名称会报错。```pythonimport pandas as pdimport numpy as npdf = pd.DataFrame({'key1':['a', 'a', 'b', 'b', 'a'],'key2':['yes', 'no','yes', 'yes', 'no'],'data1':np.random.randn(5),'data2':np.random.randn(5)})groupk1 = df.groupby('key2').mean()groupk1
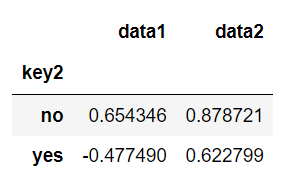
import pandas as pdimport numpy as npdf7 = pd.DataFrame([[5, 2, 'a', 'one'], [5, 4, 'a', 'two'], [3, 5, 'b', 'one'],[4, 3, 'b', 'two'], [1, 2, 'a', 'one']],columns = ['data1', 'data2', 'key1', 'key2'],index = [0, 1, 2, 3, 4])print(df7)# 按key1进行分组group = df7.groupby('key1')# 通过groups属性来查看分组情况print(group.groups)'''data1 data2 key1 key20 5 2 a one1 5 4 a two2 3 5 b one3 4 3 b two4 1 2 a one{'a': [0, 1, 4], 'b': [2, 3]}'''
分组键还可以是长度和DataFrame行数相同的列表或元组,相当于将列表或元组看作DataFrame的一列,然后将其分组。
import pandas as pdimport numpy as npdf = pd.DataFrame({'key1':['a', 'a', 'b', 'b', 'a'],'key2':['yes', 'no','yes', 'yes', 'no'],'data1':np.random.randn(5),'data2':np.random.randn(5)})wlist = ['w', 'w', 'y', 'w', 'y']print(df)df.groupby(wlist).sum()

如果原始的DataFrame中分组信息很难确定或不存在,可以通过字典结构,定义分组信息。
import pandas as pdimport numpy as npdf = pd.DataFrame(np.random.normal(size = (6, 5)),index = ['a', 'b', 'c', 'A', 'B', 'c'])print('数据为:\n', df)wdict = {'a':'one', 'A':'one', 'b':'two', 'B':'two', 'c':'three'}print('分组汇总后的结果为:\n', df.groupby(wdict).sum())'''数据为:0 1 2 3 4a 0.330358 -1.928660 -0.341849 -1.425793 -0.523291b 0.247215 0.520215 -3.251158 -1.232760 0.211477c -0.621474 -0.470327 1.002234 -0.206586 1.151982A 0.767502 1.943025 1.170166 1.048459 0.053068B 0.157708 0.470093 -0.274381 -0.691474 0.541805c 0.036297 1.357280 -0.204612 -1.700342 -0.221059分组汇总后的结果为:0 1 2 3 4one 1.097860 0.014365 0.828317 -0.377335 -0.470223three -0.585177 0.886952 0.797622 -1.906929 0.930923two 0.404923 0.990308 -3.525539 -1.924234 0.753281'''
函数作为分组键的原理类似于字典,通过映射关系进行分组,但是函数更加灵活。
import pandas as pdimport numpy as npdef judge(x):if x >= 0:return 'a'else:return 'b'df = pd.DataFrame(np.random.randn(4, 4))print('数据为:\n', df)print('函数作用后的结果为:\n', df[3].groupby(df[3].map(judge)).sum())'''数据为:0 1 2 30 0.234852 -0.524527 2.453916 0.9065441 -1.055680 0.860786 0.538826 0.5447592 1.041588 2.456769 -0.027524 0.1675363 -0.470495 -0.847614 -0.313982 1.253514函数作用后的结果为:3a 2.872353Name: 3, dtype: float64'''
按分组统计
在df.groupby()所生成的分组上应用size()、sum()、count()、mean()等统计函数,能分别统计分组数量、不同列的分组和、不同列的分组数量、分组不同列的平均值。
import pandas as pdimport numpy as npdf7 = pd.DataFrame([[5, 2, 'a', 'one'], [5, 4, 'a', 'two'], [3, 5, 'b', 'one'],[4, 3, 'b', 'two'], [1, 2, 'a', 'one']],columns = ['data1', 'data2', 'key1', 'key2'],index = [0, 1, 2, 3, 4])print(df7)group = df7.groupby('key1')print(group.size())print(group.sum())'''data1 data2 key1 key20 5 2 a one1 5 4 a two2 3 5 b one3 4 3 b two4 1 2 a onekey1a 3b 2dtype: int64data1 data2key1a 11 8b 7 8'''
数据聚合
常用聚合运算统计函数
| 函数 | 使用说明 |
|---|---|
| count | 计数 |
| sum | 求和 |
| mean | 求平均值 |
| median | 求中位数 |
| std、var | 无偏标准差和方差 |
| min、max | 求最小值最大值 |
| prod | 求积 |
| first、last | 第一个和最后一个值 |
使用agg方法聚合数据
agg、aggregate方法都支持对每个分组应用某个函数,包括Python内置函数或自定义函数。同时,这两个方法也能够直接对DataFrame进行函数应用操作。
在正常使用过程中,agg和aggregate函数对DataFrame对象操作的功能基本相同,因此只需掌握一个即可。
对于聚合,一般指的是从数组产生标量值的数据转换过程,常见的聚合运算都有相关的统计函数快速实现,当然也可以自定义聚合运算。
聚合操作主要通过agg函数来完成。
格式:DataFrame.agg(func, axis = 0)
作用:通过func在指定轴上进行聚合操作
说明:
- 用来指定聚合操作的方式,其数据形式有函数、字符串、字典以及字符串或函数所构成的列表
- axis:axis = 0表示在列上操作,axis = 1表示在行上操作
```python
data = {‘A’:[1, 2, 7], ‘B’:[2, 5, 8], ‘C’:[3, 6, 9]}
df8 = pd.DataFrame(data)
print(df8)
在df的各列上执行‘sum’和‘min’聚合操作
print(df8.agg([‘sum’, ‘min’]))
‘’’ A B C 0 1 2 3 1 2 5 6 2 7 8 9 A B C sum 10 15 18 min 1 2 3 ‘’’
在`df.groupby()`所生成的分组上应用`agg()`,对于分组的某一列或者多个列,应用agg(func)可以对分组后的数据应用func函数。<br />例如:用group['data1'].agg('kye1')对分组后的'data1'列求均值。<br />也可以推广到同时作用于多个列和使用多个函数。```pythondata = {'data1':[1, 6, 8, 7, 7, 2, 8, 7],'data2':[7, 2, 3, 3, 4, 4, 5, 4],'key1':['a', 'b', 'c', 'd', 'a', 'b', 'c','d'],'key2':['one', 'two', 'three', 'one', 'two', 'three', 'one', 'two']}df9 = pd.DataFrame(data)group9 = df9.groupby('key1')print(df9)# 在df的各列上执行’mean‘聚合操作print(group9.agg('mean'))'''data1 data2 key1 key20 1 7 a one1 6 2 b two2 8 3 c three3 7 3 d one4 7 4 a two5 2 4 b three6 8 5 c one7 7 4 d twodata1 data2key1a 4.0 5.5b 4.0 3.0c 8.0 4.0d 7.0 3.5'''
data = {'data1':[1, 6, 8, 7, 7, 2, 8, 7],'data2':[7, 2, 3, 3, 4, 4, 5, 4],'key1':['a', 'b', 'c', 'd', 'a', 'b', 'c','d'],'key2':['one', 'two', 'three', 'one', 'two', 'three', 'one', 'two']}df9 = pd.DataFrame(data)print(df9)# 在df的各列上使用两个函数print(df9.groupby('key2').agg(['mean', 'sum']))'''data1 data2 key1 key20 1 7 a one1 6 2 b two2 8 3 c three3 7 3 d one4 7 4 a two5 2 4 b three6 8 5 c one7 7 4 d twodata1 data2mean sum mean sumkey2one 5.333333 16 5.000000 15three 5.000000 10 3.500000 7two 6.666667 20 3.333333 10'''
使用apply()函数执行聚合操作
data = {'data1':[1, 6, 8, 7, 7, 2, 8, 7],'data2':[7, 2, 3, 3, 4, 4, 5, 4],'key1':['a', 'b', 'c', 'd', 'a', 'b', 'c','d'],'key2':['one', 'two', 'three', 'one', 'two', 'three', 'one', 'two']}df9 = pd.DataFrame(data)print(df9)print(df9.groupby('key2').apply(sum))'''data1 data2 key1 key20 1 7 a one1 6 2 b two2 8 3 c three3 7 3 d one4 7 4 a two5 2 4 b three6 8 5 c one7 7 4 d twodata1 data2 key1 key2key2one 16 15 adc oneoneonethree 10 7 cb threethreetwo 20 10 bad twotwotwo'''
分组运算
- transform方法:可以将运算分布到每一行
- apply方法:类似于agg方法, 可以将函数应用于每一列
数据分组与聚合实例分析
项目背景:王老师是某教育培训机构的数学老师。现在他想研究一下他的学生数学期末考试成绩和什么因素有关。于是王老师先提取了一小部分学生的数据,保存在 DataFrame 对象中,王老师想要查看一下不同班级的学生数学平均分情况。就需要用到分组聚合操作。
分组聚合操作的定义:分组聚合操作指的是按照某项规则对数据进行分组,接着对分完组的数据执行总结性统计的操作(比如求和、求均值)。它可以帮助我们从庞杂的数据中提炼出我们想要的数据样式。
下图展现的就是利用分组聚合操作计算不同班级学生的均分的过程。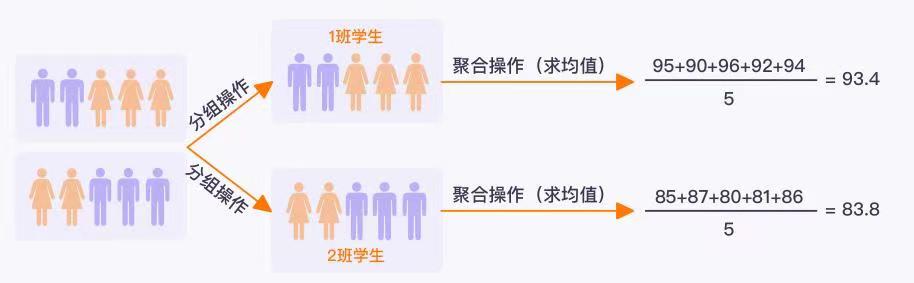
分组聚合操作根据其分组方式的不同可以分为单层分组聚合操作以及多层分组聚合操作。单层分组聚合操作
单层分组聚合操作指的是针对某一个组进行聚合操作。
王老师的案例就是单层分组聚合操作,因为他只需要针对班级这一列进行分组。 ```python import pandas as pd grade_df = pd.DataFrame({‘班级’:[1, 1, 1, 1, 1, 2, 2, 2, 2, 2],
grade_df1 = grade_df.groupby(‘班级’)[‘成绩’].mean() print(grade_df) print(grade_df1)'性别':['男', '男', '女', '女', '女','男', '男', '男', '女', '女'],'眼睛':['是', '否', '是', '否', '是', '是', '是', '否', '否', '否'],'成绩':[95, 90, 96, 92, 94, 85, 87, 80, 81, 86]})
‘’’ 班级 性别 眼睛 成绩 0 1 男 是 95 1 1 男 否 90 2 1 女 是 96 3 1 女 否 92 4 1 女 是 94 5 2 男 是 85 6 2 男 是 87 7 2 男 否 80 8 2 女 否 81 9 2 女 否 86 班级 1 93.4 2 83.8 Name: 成绩, dtype: float64 ‘’’
单层分组聚合操作的代码:`df.groupby(by)['列索引'].mean()`<br />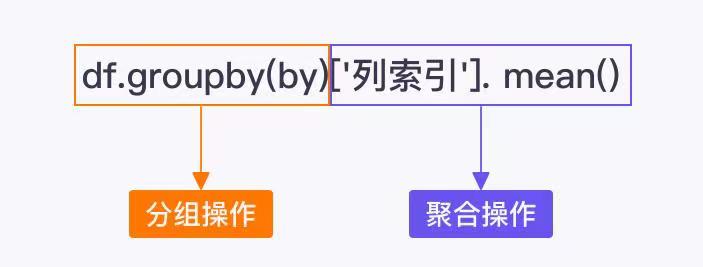> 注意:单层分组操作只能根据一列数据进行分组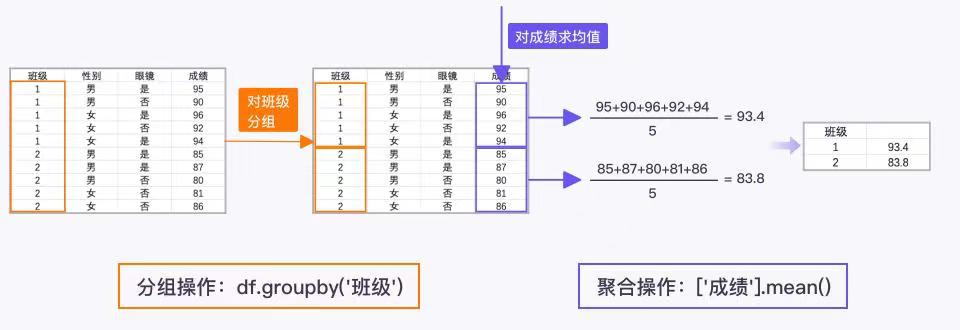<br />常用的聚合操作方法表:| 流程 | 方法 | 示例 || --- | --- | --- || 求最小值 | min() | 一组数据的最小值 || 求最大值 | max() | 一组数据的最大值 || 求标准差 | std() | 一组数据的标准差 || 求平均值 | mean() | 一组数据的总和除以一组数据的个数 || 求中位数 | median() | 一组数据处于中间位置的数 || 求总和 | sum() | 一组数据的总和 || 求数量 | count() | 一组数据的非空数据的个数 || 求频数分布 | value_counts() | 一组数据各个类别出现的次数 |```pythonimport pandas as pdgrade_df = pd.DataFrame({'班级':[1, 1, 1, 1, 1, 2, 2, 2, 2, 2],'性别':['男', '男', '女', '女', '女','男', '男', '男', '女', '女'],'眼睛':['是', '否', '是', '否', '是', '是', '是', '否', '否', '否'],'成绩':[95, 90, 96, 92, 94, 85, 87, 80, 81, 86]})grade_df2 = grade_df.groupby('性别')['成绩'].median()print(grade_df2)'''性别女 92.0男 87.0Name: 成绩, dtype: float64'''
从运行结果中可以发现,分组聚合操作返回的是一个Series对象。只不过这个Series对象和之前讲过的有些不一样,它的索引会多一个名字。这个名字对应的是分组操作中的列索引。由于刚才是对性别这一列进行分组,所以名字就是性别。
多层分组聚合操作
王老师还想对这组数据有进一步的研究,他想知道如何获取不同班级下不同性别的学生的平均分,这个时候就需要用到多层分组聚合操作的知识了。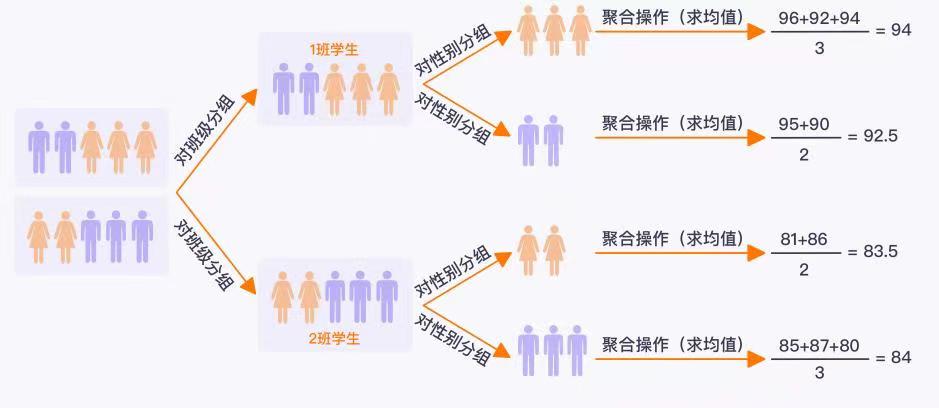
import pandas as pdgrade_df = pd.DataFrame({'班级':[1, 1, 1, 1, 1, 2, 2, 2, 2, 2],'性别':['男', '男', '女', '女', '女','男', '男', '男', '女', '女'],'眼睛':['是', '否', '是', '否', '是', '是', '是', '否', '否', '否'],'成绩':[95, 90, 96, 92, 94, 85, 87, 80, 81, 86]})grade_df3 = grade_df.groupby(['班级', '性别'])['成绩'].mean()print(grade_df3)'''班级 性别1 女 94.0男 92.52 女 83.5男 84.0Name: 成绩, dtype: float64'''
多层分组聚合和单层分组聚合相比,代码是相同的,都是df.groupby(by)['列索引'].mean()。
多层分组聚合操作返回的也是一个Series对象。
唯一的不同点在于索引的层数上。单层分组聚合操作的索引只有一层,而多层分组聚合操作的索引至少有两层。
多层分组聚合操作需要将多个列索引放在容器列表中给参数by。
分组的顺序和列表中的参数是对应的(从左往右依次拆分)。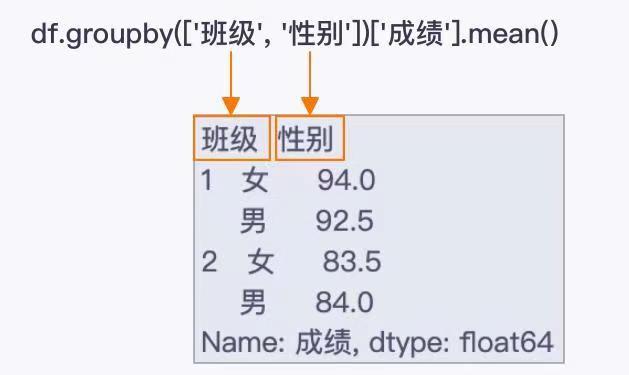
虽然通过多层分组聚合的方法,可以求出不同组别下的学生考试成绩的情况,但是返回的结果看起来却有些冗杂。所有的组别信息都扎堆出现在一个Series对象的索引中,有没有办法能够让这些信息看起来更直观一些呢?s.unstack()函数就是解决这问题的常见方法。
作用:可以将一个多层分组聚合后的Series对象转变为DataFrame对象。s.unstack()这个方法是针对多层分组聚合后的Series对象来使用的。作用就是将其索引的最后一列转变成DataFrame对象的列索引,而剩下的索引则转变成DataFrame对象的行索引。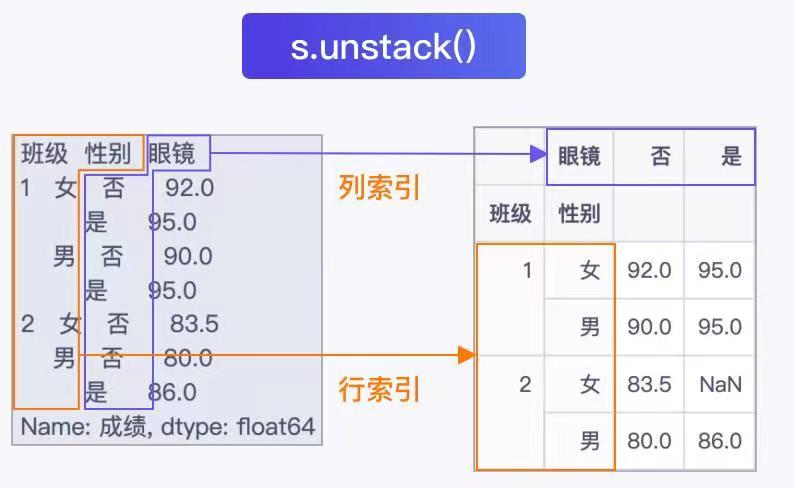
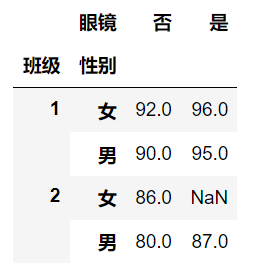
import pandas as pdgrade_df = pd.DataFrame({'班级':[1, 1, 1, 1, 1, 2, 2, 2, 2, 2],'性别':['男', '男', '女', '女', '女','男', '男', '男', '女', '女'],'眼镜':['是', '否', '是', '否', '是', '是', '是', '否', '否', '否'],'成绩':[95, 90, 96, 92, 94, 85, 87, 80, 81, 86]})grade_df5 = grade_df.groupby(['班级', '性别', '眼镜'])['成绩'].max()df6 = grade_df5.unstack()df6

若有收获,就点个赞吧
0 人点赞
