学习目标
掌握文件的基本操作
掌握二进制文件的处理
了解文件的系统操作
了解常见文件格式的读写
文件分类
按文件中数据的组织形式分类:
- 文本文件
- 存储的是常规字符串,由若干文本行组成,每行以换行符“\n”结尾。
- 可以使用文本编辑器进行显示、编辑并且能够直接阅读。
- 如网页文件、记事本文件、程序源代码文件等。
- 二进制文件
- 存储的是字节串bytes。
- 需要使用专门的软件进行解码后才能读取、显示、修改或执行。
- 如图形图像文件、音视频文件、可执行文件、数据库文件等。
打开文件
向(从)一个文件写(读)数据之前,需要先创建一个和物理文件相关的文件对象,然后通过该文件对象对文件内容进行读取、写入、删除、修改等操作,最后关闭并保存文件内容。
Python内置的open()函数可以按指定的模式打开指定的文件并创建文件对象。 ``` ‘’’ open函数打开文件file,返回一个指向文件file的文件对象file_object ‘’’
file_object = open(file, mode = ‘r’, buffering = -1, encoding)
open函数参数说明:- filename:要访问的文件名称。file是一个包含文件所在路径及文件名称的字符串值,如'C:\\User\\test.txt'。(这里要注意是两个右斜杠)- mode:指定打开文件后的处理方式:只读,写入,追加等。这个参数是非强制的,默认文件访问模式为只读(r)。- buffering:0表示不缓存,1表示缓存。大于1表示缓冲区的大小。-1表示缓冲区的大小为系统默认值。- encoding:指定对文本进行编码和解码的方式,只适用于文本模式,可以使用Python支持的任何格式,如gbk、utf8、cp936等。Python使用open()方法打开一个文件,并返回一个可迭代的文本对象,通过该文本对象可以对文件进行读写操作。如果文本不存在、访问权限不够、磁盘空间不足或其他原因导致创建文件对象失败,open()函数就会抛出一个IOError的错误,并且给出错误码和详细的信息。<br />磁盘满、无法写入,打开文件要读取但文件不存在,或文件路径错误。这些是文件读写过程中随时可能遇到的问题。<br />凡是涉及文件输入输出的操作,这类问题在程序设计时是必然要考虑的因素,否则程序的设计并不完整和严谨。<a name="e9KdA"></a>## 文件打开模式打开模式定义了打开文件后的处理方式。| 模式 | 功能描述 || --- | --- || r | 只读模式 || w | 写模式,若存在则覆盖原有内容 || a | 追加模式 || r+ | 读写,不创建 || w+ | 读写,若不存在则创建 || a+ | 追加模式但可读 || rt, wt | 默认为文本方式,相当于r, w || rb, wb | 读写二进制文件 |文件打开的不同模式的详细描述:| 模式 | 描述 || --- | --- || r | 以只读方式打开文件,文件的指针放在文件的开头。这是默认模式,可省略。 || r+ | 以读写格式打开一个文件,文件指针放在文件的开头。 || w | 以写入格式打开一个文件,如果该文件已存在,则将其覆盖。如果该文件不存在,则创建新文件。 || w+ | 以读写格式打开一个文件,如果该文件已存在则将其覆盖。如果该文件不存在,则创建新文件。 || a | 以追加格式打开一个文件,如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 || a+ | 以读写格式打开一个文件,如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |<a name="SEv0d"></a>## 文件对象属性一个文件被打开后,返回一个文件对象,通过文件对象可以得到有关该文件的各种信息。<br />文件对象的属性如表所示:| 属性 | 描述 || --- | --- || closed | 判断文件是否关闭,如果文件已被关闭,返回True;否则返回False || mode | 返回被打开文件的访问模式 || name | 返回文件的名称 |```pythonfile_object = open('C:\\test\\scores.txt', 'r')print('文件名:', file_object.name)print('是否已关闭:', file_object.closed)print('访问模式:', file_object.mode)
文件对象
文件对象常用方法
| 方法 | 功能描述 |
|---|---|
| close() | 刷新缓冲区里还没写入的信息,并关闭该文件 |
| flush() | 刷新文件内部缓冲,把内部缓冲区的数据立刻写入文件,但不关闭文件 |
| next() | 返回文件下一行 |
| read([size]) | 从文件的开始位置读取指定的size个字符数,如果未给定则读取所有 |
| readline() | 读取整行,包括“\n”字符 |
| readlines() | 把文本文件中的每行文本作为一个字符串存入列表中并返回该列表 |
| seek(offset[, from]) | 用于移动文件读取指针到指定位置,offset为需要移动的字节数;from指定从哪个位置开始移动,默认值为0,0代表从文件开头开始,1代表从当前位置开始,2代表从文件末尾开始。 |
| tell() | 方法返回文件的当前位置,即文件指针当前位置 |
| truncate([size]) | 删除从当前指针位置到文件末尾的内容。如果指定了size,则不论指针在什么位置 |
| write(str) | 把字符串str的内容写入文件中,没有返回值。由于缓冲,字符串内容可能没有加入到实际的文件中,直到调用flush()或close()方法被调用。 |
| writelines([str]) | 用于向文件中写入字符串序列 |
| writabe() | 测试当前文件是否可写 |
| readable() | 测试当前文件是否可读 |
文件关闭
当对文件内容操作完成以后,必须关闭文件,这样能够保证所做的修改得到保存。
close()方法用于关闭一个已打开的文件,可以将缓冲的数据写入文件,然后关闭文件。
关闭后的文件不能再进行读写操作,否则会触发ValueError错误。
close()方法允许调用多次。
flush()方法将缓冲的数据写入文件,但是不关闭文件。
使用上下文管理语句with可以自动管理资源,在代码块执行完毕后自动还原进入该代码块之前的现场或上下文。
with context_expr[as var]:with语句块
with open('myfile.txt') as f:for line in f:print(line, end = '')
使用with语句的好处:
- 使用with自动关闭资源,可以在代码块执行完毕后还原进入该代码块时的现场。
- 不论何种原因跳出with块,不论是否发生异常,总能保证文件被正确关闭,资源被正确释放。
文件读写
写文件
当一个文件以“写”的方式打开后,可以使用write()方法和writelines()方法,将字符串写入文本文件。
- write()方法:
write(s)方法用于向一个打开的文件中写入指定的字符串。在文件关闭前或缓冲区刷新前,字符串内容存储在缓冲区中,这时在文件中是看不到写入的内容的。
write()方法不会在字符串的结尾添加换行符“\n”。
'''参数str:要写入文件的字符串返回值:返回的是写入的字符长度'''fileObject.write(str)
在操作文件时,每调用一次write()方法, 写入的数据就会追加到文件末尾。
'''程序运行时是,会在程序的当前路径下,生成一个名为test.txt文件,打开该文件,可以看到数据成功被写入'''fp = open('test.txt', 'w')fp.write('My name is Guido van Rossum!\n')fp.close()
注意:当向文件写入数据时,如果文件不存在,那么系统会自动创建一个文件并写入数据。如果文件存在,那么会清空原来文件的数据,重新写入新数据。
- writelines()方法
writelines()方法把字符串列表写入文本文件,不添加换行符“\n”。
data = ['My', 'name', 'is', 'John!\n', 'How', 'are', 'you!']with open('data_desc.txt', 'w') as fp:fp.writelines(data)with open('data_desc.txt', 'r') as fp:for line in fp:print(line)
读文件
文件打开后从文件中读取数据的三种方式:
| 方法 | 功能描述 |
|---|---|
| read([size]) | 从文件读取指定的size个字符数,如果未给定则读取所有。 |
| readline() | 读取整行 |
| readlines() | 把文本文件中的每行文本作为一个字符串存入列表中并返回该列表。 |
注意:打开一个已经存在的文件,读取正常,当试图打开一个不存在的文件,系统会给出错误信息。
每种方法可以接受一个变量以限制每次读取的数据数量。
- read()方法
read()方法从文件当前位置起读取size个字符串,若无参数size,则表示读取至文件结束为止。如果使用多次,那么后面读取的数据是从上次读完后的位置开始。
'''参数size:从文件中读取的字符数。如果没有指定字符数,那么就表示读取文件的全部内容。返回值:返回从字符串读取的字符内容。'''fileObject.read(size)
fp = open('test.txt', 'r')# 读取10个字节数据content = fp.read(10)print(content)
- readline()方法
该方法每次读出一行内容,该方法读取时占用内存小,比较适合大文件,该方法返回一个字符串对象。
'''返回值:返回读取的字符串'''fileObject.readline()
fp = open('test.txt', 'r')line = fp.readline()print('读取第一行:%s' %(line))print('--------------华丽的分割线------------------')while line:print(line)line = fp.readline()fp.close()print('文件', f.name, '已经成功分行读出!')
- readlines()方法
readlines()方法读取文件的所有行,保存在一个列表中,每行作为一个元素,但读取大文件会比较占内存。该列表可以由Python的for … in … 结构进行处理。
'''返回值:此方法返回包含所有行的列表'''fileObject.readlines()
fp = open('test.txt', 'r')lines = fp.readlines()print('行的数据类型:', type(lines))print('列表形式存放每一行:%s' %(lines))print('-----------------华丽的分割线------------------')for line in lines:line = line.strip()print('读取的数据为:%s' %(line))fp.closeprint('文件', f.name, '已经成功把所有行读出!')
Windows平台下open()函数在打开文件的时候缺省的编码(encoding)为gbk(cp936),并不是UTF-8,因此在打开文件的时候应指定编码为UTF-8,否则读取文件会出现错误。
fname = r'C:\test\shi.txt'with open(fname, 'r', encoding = 'utf-8') as f:lines = f.readlines()for line in lines:print(line.rstrip())
- 从文件逐行读取数据
with open('test.txt') as f:for line in f:print(line, end = '')
文件指针的定位
文件对象的tell()方法返回文件的当前位置,即文件指针当前位置。
使用文件对象的read()方法读取文件之后,文件指针到达文件的末尾,如果再来一次read()将会发现读取的是空内容,如果想在此读取全部内容,或读取文件中的某行字符,必须将文件指针移动到文件开始或某行开始,这可通过文件对象的seek()方法来实现。 ```python ‘’’ 函数作用:用于移动文件读取指针到指定位置 offset:需要移动的字节数 whence:指定从哪个位置开始移,默认值为0。
‘’’0代表从文件开头开始,1代表从当前位置开始,2代表从文件末尾开始。
seek(offset[, whence])
> 注意:Python3不允许非二进制打开的文件相对于文件末尾的定位```python'''运行结果显示s为空串,通过tell()方法查看文件指针,可以看出文件的指针在该文件的末尾。'''with open('test.txt','a+') as f:s = f.read(5)print('in file ->', s)point = f.tell()print(point)
with open('test.txt', 'a+') as f:f.write('\n Python is a programming language. \n')# 清空缓冲区,确保数据保存到文件f.flush()# 将文件指针转移到文件首部f.seek(0)s = f.readlines()# 逐行读取文件数据for line in s:print(line)
二进制文件
二进制文件包括图像文件、可执行文件、音视频文件、字处理文档等。
二进制文件不能使用记事本或其他文本编辑软件直接读写。
二进制文件的读写
二进制文件读写的是bytes字节串。
'''由于写入的是一个字符串,非字节串,系统会抛出异常。'''with open('test.bt', 'wb') as fp:fp.write('abcd')
二进制文件模式表:
| 文件使用方式 | 意义 |
|---|---|
| rb | 只读打开一个二进制文件,只允许读数据。如文件存在,则打开后可以顺序读;如文件不存在,则打开失败。 |
| wb | 只写打开或建立一个二进制文件,只允许写数据。如文件不存在,则建立一个空文件;如文件已经存在,则把原文件内容清空。 |
| ab | 追加打开一个文本文件,并在文件末尾写数据。如文件不存在,则建立一个空文件;如文件已经存在,则把原文件打开,并保持原内容不变,文件位置指针指向末尾,新写入的数据追加在文件末尾。 |
因为二进制文件是字节流,因此二进制文件在打开读写时不用指定编码,也不存在readline,readlines读一行或多行的操作函数。
一般二进制文件使用read函数读取,使用write函数写入。
- 写二进制文件 ```python ‘’’ 把二进制数据data写入文件 ‘’’
文件对象.write(data)
2. 读二进制文件```python'''如果不指定要读取的字符数n,使用read()读,则读到整个文件的内容。如果使用read(n)指定要读取的字符数,要么就按要求读取n个字符;如果要读n个字符,而文件没有那么多字符,那么就读取所有文件内容。'''文件对象.read(n)
def writeFile():fobj = open('abc.txt', 'wb')fobj.write('Python文件'. encode())fobj.close()def readFile():fobj = open('aabc.txt', 'rb')data = fobj.read()print(data.decode())fobj.close()writeFile()readFile()
with open('test.bt', 'wb+') as fp:# 转换成使用utf-8编码fp.write(bypes('我爱中国'.encode('utf-8')))# 文件指定定位到开头fp.seek(0)# 解码方式和编码方式要一致b = fp.read().decode('utf-8')print(b)
可以看出如果直接用文本文件或二进制文件格式存储Python中的各种对象,通常需要进行繁琐的转换。
Python程序在内存中的数据一般是放置在列表、元组、字典等各类对象之中。当进行文件保存或网络处理时,不能直接送入这些对象本身,必须将这些对象进行序列化,以转化为字节码才能进行处理。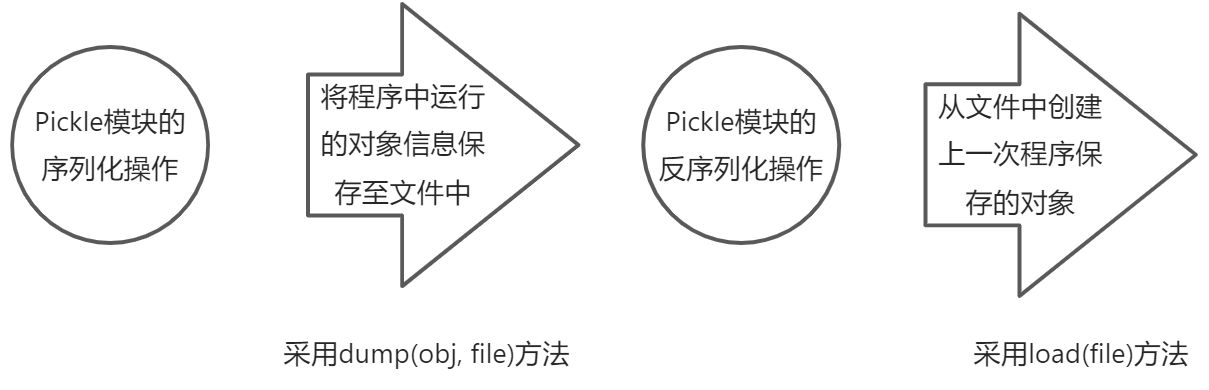
import picklename = '张三'age = 20scores = [65, 70, 76, 80]with open('test.bt', 'wb+') as fp:# 写入文件pickle.dump(name, fp)pickle.dump(age, fp)pickle.dump(scores, fp)# 将文件指针移动到文件开头fp.seek(0)# 读出文件的全部内容,返回一个字节串print(fp.read())fp.seek(0)# 读取文件name = pickle.load(fp)age = pickle.load(fp)scores = pickle.load(fp)print(name, ';', age, ';', scores)''' b'\x80\x04\x95\n\x00\x00\x00\x00\x00\x00\x00\x8c\x06\xe5\xbc\xa0\xe4\xb8\x89\x94.\x80\x04K\x14.\x80\x04\x95\r\x00\x00\x00\x00\x00\x00\x00]\x94(KAKFKLKPe.'张三 ; 20 ; [65, 70, 76, 80]'''
文件系统操作
os模块
os模块除了提供使用操作系统功能和访问文件系统的简便方法外,还提供了大量文件和目录操作的方法。
1. 文件的重命名
os.rename()方法用于重命名文件或目录,如果dst是一个存在的目录,将抛出OSError。
'''src:要修改的目录名dst:修改后的目录名返回值:该方法没有返回值'''os.rename(src, dst)
2. 文件的删除
os.remove()方法用于删除指定路径的文件。如果指定的路径是一个目录,将抛出OSError。
'''path:要移除的文件路径返回值:该方法没有返回值'''os.remove(path)
import os# 列出当前目录下的文件和子目录print('目录为:%s' %os.listdir(os.getcwd()))# 重命名文件os.rename('test.txt', 'test1.txt')print('重命名成功!')print('重命名后目录为:%s' %os.listdir(os.getcwd()))# 删除文件os.remove('test1.txt')print('删除成功!')print('删除后目录为:%s' %os.listdir(os.getcwd()))
3. 判断是否是文件
'''作用:判断path是否是一个文件返回值:True或False'''os.path.isfile(path)
4. 文件的复制
'''作用:将文件src复制到文件或目录dst中返回值:返回目标文件名'''shutil.copy(src, dst)
5. 检查文件是否存在
'''作用:检查文件的存在性返回值:返回一个布尔值'''os.path.exists(path)
6. 获取绝对路径名
'''作用:获取绝对路径名返回值:返回path的绝对路径名'''os.path.abspath(path)
import os.shutil# 当前目录下1.py文件不存在if not os.path.exists(r'.\1.py'):# 创建1.py文件with open(r'.\1.py', 'w') as fp:fp.write("print('hello world!')\n")# 复制1.py到C:\test目录下filename = shutil.copy(r'.\1.py', 'C:\\test')# 打印1.py文件所在的绝对路径print(os.path.abspath('1.py'))
7. os模块的常用文件操作方法
| 方法 | 功能说明 |
|---|---|
| access(path, mode) | 按照mode指定的权限访问文件 |
| open(path, flags, mode = 511) | 按mode指定的权限打开文件,默认权限为可读、可写、可执行 |
| chmod(path, mode, * ,dir_fd = None) | 改变文件的访问权限 |
| remove(path) | 删除指定的文件 |
| rename(src, dst) | 重命名文件或目录 |
| stat(path) | 返回文件的所有属性 |
| fstat(path) | 返回打开的文件的所有属性 |
| startfile(filepath[, operation]) | 使用关联的应用程序打开指定文件 |
| mkdir(path, mode = 511) | 创建目录 |
| makedirs(path1 / path2 …, mode = 511) | 创建多级目录 |
| rmdir(path) | 删除目录 |
| removedirs(path1 / path2 …) | 删除多级目录 |
| listdir(path) | 返回指定目录下的文件和目录信息 |
| getcwd() | 返回当前工作目录 |
| get_exec_path() | 返回可执行文件的搜索路径 |
| chdir(path) | 把path设为当前工作目录 |
| walk(top, topdown = True) | 遍历目录树,该方法返回一个元组,包括3个元素:所有路径名、所有目录列表与文件列表 |
| sep | 当前操作系统所使用的路径分隔符 |
| estsep | 当前操作系统所使用的文件扩展名分隔符 |
8. os.path模块的常用文件操作方法
| 方法 | 功能描述 |
|---|---|
| abspath(path) | 返回绝对路径 |
| dirname(p) | 返回目录的路径 |
| exists(path) | 判断文件是否存在 |
| getatime(filename) | 返回文件的最后访问时间 |
| getctime(filename) | 返回文件的创建时间 |
| getmtime(filename) | 返回文件的最后修改时间 |
| getsize(filename) | 返回文件的大小 |
| isabs(path) | 判断path是否为绝对路径 |
| isdir(path) | 判断path是否为目录 |
| idfile(path) | 判断path是否为文件 |
| join(path, *paths) | 连接两个或多个path |
| split(path) | 对路径进行分割,以列表形式返回 |
| splitext(path) | 从路径中分割文件的扩展名 |
| splitdrive(path) | 从路径中分割驱动器的名称 |
在实际开发中,有时需要用程序的方式对文件夹进行一定的操作。比如创建、删除、显示目录内容等,可以通过os和os.path模块提供的方法来完成。
'''作用:批量修改文件和目录名的小程序,实现文件和目录名前加上Python-前缀'''import osfolderName = './test/'# 获取指定路径下所有文件和子目录的名字dirList = os.listdir(folderName)# 遍历输出所有文件和子目录的名字for name in dirList:print('修改前文件名:', name)newName = 'Python-' + nameprint('修改后文件名:', newName)os.rename(os.path.join(folderName, name), os.path.join(folderName, newName))
shutil模块
shutil模块也属于Python标准库,是对os模块的补充。
shutil模块可以与os模块配合使用,基本可以完成一般的文件系统功能。
使用shutil操作文件与文件夹
shutil模块拥有许多文件(夹)操作的功能,包括复制、移动、重命名、删除、压缩包处理等。
shutil.copyfileobj(fsrc, fdst)
将文件内容从源fsrc文件复制到fdst文件中去,前提是目标文件fdst具备可写权限。
fsrc、fdst参数是打开的文件对象。
shutil.copy(fsrc, destination)
将fsrc文件复制到destination文件夹中,两个参数都是字符串格式。如果destination是一个文件名称,那么它会被用来当作复制后的文件名称,即等于“复制 + 重命名”。
shutil.copytree(source, destination)
复制整个文件夹,将source文件夹中的所有内容复制到destination中,包括source里面的文件、子文件夹都会被复制过去。两个参数都是字符串格式。
shutil.move(source, destination)
将source文件或文件夹移动到destination中。返回值是移动后文件的绝对路径字符串。如果destination指向一个文件夹,那么source文件将被移动到destination中,并且保持其原有名字。如果source指向一个文件,destination指向一个文件,那么source文件将被移动并重命名。
import shutil, os# 进入文件所在目录os.chdir('C:\\test')shutil.copy('scores.txt', 'sample1.txt')
读写常见文件格式
CSV文件
CSV格式属于电子表格文件,其中数据存储在单元格内。每个单元格按照行和列结构进行组织。
CSV中的每一行代表一个观察,通常称为一条记录。每个记录可以包含一个或多个由逗号分隔的字段。如果文件中不使用逗号分隔,而是使用制表符进行分隔,这样的文件格式称为TSV(制表符分隔符)文件格式。
csv文件的读取和写入
csv(comma separated values,逗号分隔值)文件是一种用来存储表格数据(数字和文本)的纯文本格式文件,文档的内容是由“,”分隔的一列列的数据构成,它可以被导入各种电子表格和数据库中。纯文本意味着该文件是一个字符序列。
在csv文件中,数据“栏”(数据所在列,相当于数据库的字段)以逗号分隔,可允许程序通过读取文件为数据重新创建正确的栏结构(如把两个数据栏的数据组合在一起),并在每次遇到逗号时开始新的一栏。
csv文件由任意数目的记录组成,记录间以某种换行符间隔,一行即为数据表的一行;每条记录由字段组成,字段间的分隔符最常见的是逗号或制表符。
可使用Word、记事本、Excel等方式打开csv文件。
创建csv文件的方法有很多,最常用的方法是用电子表格创建,如Microsoft Excel。在Microsoft Excel中,选择“文件”>“另存为”,然后在“文件类型”下拉选择框中选择“CSV(逗号分隔)(*.csv)”,然后点击保存即创建了一个csv格式的文件。
Python的csv模块提供了多种读取和写入csv格式文件的方法。
本节基于consumer.csv文件,其内容为:
| 客户年龄 | 平均每次消费金额 | 平均消费周期 |
|---|---|---|
| 23 | 318 | 10 |
| 22 | 147 | 13 |
| 24 | 172 | 17 |
| 27 | 194 | 57 |
- csv文件的读取
csv.reader(csvfile, dialect = 'excel')
参数说明:
- csvfile:可以使文件(file)对象或者列表(list)对象,如果csvfile是文件对象,要求该文件要以
newline = ''的方式打开,否则两行之间会空一行。 - dialect:编码风格,默认为excel的风格,也就是用逗号(,)分隔,dialect方式也支持自定义,通过调用register_dialect方法来注册。

import csv, shutil, os# 进入文件所在目录os.chdir('C:/bigdata/juputer code')with open('consumer.csv', newline = '') as csvfile:# 返回的是迭代类型spamreader = csv.reader(csvfile)for row in spamreader:# 以逗号连接各字段print(','.join(row))# 文件指针移动到文件开始csvfile.seek(0)for row in spamreader:print(row)
- csv文件的写入
csv.writer(csvfile, dialect = 'excel', **fmtpatams)
参数说明:
- csvfile:可以使文件(file)对象或列表(list)对象。
- dialect:编码风格,默认为excel的风格,也就是用逗号(,)分隔,dialect方式也支持自定义,通过调用register_dialect方法来注册。
csv。writer()所生成csv.writer文件对象支持一下写入csv文件的方法:
- writerow(row):写入一行数据
- writerows(rows):写入多行数据
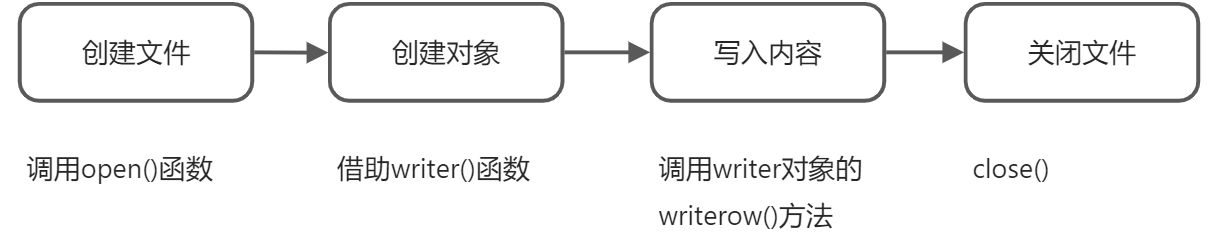
import csv, shutil, os# 进入文件所在目录os.chdir('C:/bigdata/jupyter code')with open('consumer.csv', 'w', newline = '') as csvfile:# 写入的数据将覆盖consumer.csv文件# 生成csv.writer文件对象spamwriter = csv.writer(csvfile)# 写入一行数据spamwriter.writerow(['55', '555', '55'])spamwriter.writerows([('35', '355', '35'), ('18', '188', '18')])#重新打开文件with open('consumer.csv', newline = '') as csvfile:sapmreader = csv.reader(csvfile)# 输出数据文件for row in spamreader:print(row)
import csvdef csv_write(path, data):with open(path, 'w', encoding = 'utf-8', newline = '') as f:writer = csv.writer(f, dialect = 'excel')for row in data:writer.writerow(row)return Truedata = [['姓名','年龄', '身高(cm)', '体重(kg)'],['张三', 38, '176cm', '75'],['李四', 25, '160cm', '46'],['王五', 28, '170cm', '62']]csv_write('persons.csv', data)
很多情况下,读取csv数据时,往往先把csv文件中的数据读成字典的形式,即为读出的每条记录中的数据添加一条说明性的关键词,这样便于理解。
- 将csv文件读取为字典
csv.DictReader(csvfile, fieldnames = None, dialect = 'excel')
作用:
- 返回一个csv.DictReader对象,可以将读取的信息映射为字典,其关键字由可选参数fieldnames来指定。
参数说明:
- csvfile:可以是文件(file)对象或列表(list)对象。
- fieldnames:是一个序列,用于为输出的数据指定字典关键字,如果没有指定,则以第一行的各字段名作为字典关键字。
- dialect:编码风格,默认为excel的风格。
import csvwith open('consumer.csv', 'r') as csvfile:dict_reader = csv.DictReader(csvfile)for row in dict_reader:print(row)
- 将字典形式的记录数据写入csv文件
csv.DictWriter(csvfile, fieldnames, dialect = 'excel')
说明:操作方法与参数含义与dictReader()类似
import csvdict_record = [{'客户年龄':23, '平均每次消费金额':318, '平均消费周期':10},{'客户年龄':22, '平均每次消费金额':147, '平均消费周期':13}]keys = ['客户年龄', '平均每次消费金额', '平均消费周期']with open('consumer1.csv', 'w+', newline = '') as csvfile:dictwriter = csv.DictWriter(csvfile, fieldnames = keys)# 若直接写入会导致没有数据名,先执行writeheader()将头文件写入# writeheader()没有参数,建立对象dictwriter时已指定fieldnamesdictwriter.writeheader()for item in dict_record:dictwriter.writerow(item)
import csvprint('以csv.DictReader()读取consumer1.csv:')with open('consumer1.csv', 'r') as csvfile:reader = csv.DictReader(csvfile)for row in reader:print(row)
csv文件的格式化参数
创建csv.reader或csv.writer对象时,可以指定csv文件格式化参数。
csv文件格式化参数表:
| 参数 | 描述 |
|---|---|
| delimiter | 单字词,默认值为“,”,用来分割字段。 |
| doublequote | 如果为True(默认值),字符串中的双引号用””表示,若为False,使用转义字符escapechar指定的字符。 |
| escapechar | 转义字符,一个单词串,当quoting被设置成QUOTE_NONE、doublequote被设置为False,被writer用来转义delimiter。 |
| lineterminator | 被writer用来换行,默认为’\r\n’。 |
| quotechar | 单字串,用于包含特殊符号的引用字段,默认值为’”‘。 |
自定义dialect
dialect用来指定csv文件的编码风格,默认为excel的风格,也就是用逗号“,”分隔,dialect支持自定义,即通过调用register_dialect方法来注册csv文件的编码风格。csv.register_dialect(name[, dialect], **fmtparams)
作用:
- 这个函数是用来自定义dialect的。
参数说明:
- name:所自定义的dialect的名字,比如默认的是’excel’,你可以定义成’mydialect’。
- delimiter:分隔符,默认的是逗号。
- fmtparams:用于指定特定格式,以覆盖dialect中的格式。
import csv# 自定义了一个命名为mydialect的dialect# 参数只设置了delimiter和quoting这两个,其他的仍然采用默认值# 其中以':'为分隔符# quoting用于指定使用双引号的规则,QUOTE_ALL(全部)csv.register_dialect('mydialect', delimiter = ':',quoting = csv.QUOTE_ALL)with open('consumer.csv', newline = '') as f:spamreader = csv.reader(f, dialect = 'mydialect')for row in spamreader:print(row)
Excel文件
Excel是常见的电子表格文件,常用openpyxl模块读写Excel表格中的数据。
在安装jupyter notebook时已经安装好了openpyxl模块。
可在编辑器中输入并运行conda list查看这个模块。
一个Excel文档也称为一个工作簿(workbook),每个工作簿里可以有多个工作表(worksheet),当前打开的工作表又叫活动表。
每个工作表里有行和列,特定的行与列相交的放个称为单元格(cell)。
在进行Excel文件读写时,应首先进行工作簿(’workbook’)的获取,然后从工作簿中处理表单(’sheet’)。进入表单处理环节后,即可按行或列进行数据的读取,或是按单元格的方式处理数据。
Excel文件写入的步骤: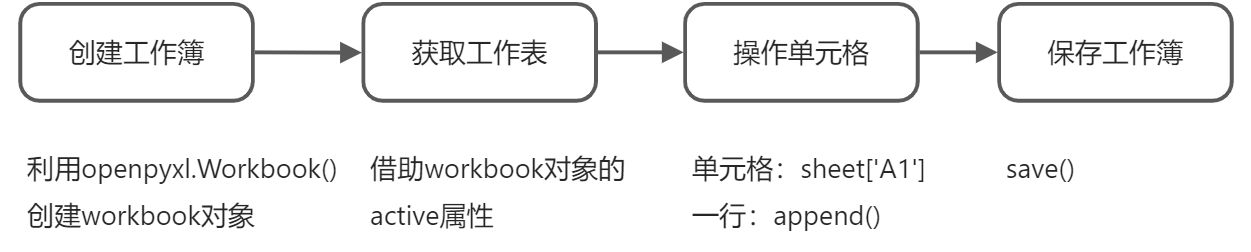 ```python
import openpyxl
wb = openpyxl.Workbook()
sheet = wb.active
sheet.title = ‘student’
rows = [[‘学号’, ‘姓名’, ‘班级’], [‘201401’, ‘张三’, ‘14班’], [‘201302’, ‘李四’, ‘14班’]]
for i in rows:
sheet.append(i)
print(rows)
wb.save(‘student.xlsx’)
```python
import openpyxl
wb = openpyxl.Workbook()
sheet = wb.active
sheet.title = ‘student’
rows = [[‘学号’, ‘姓名’, ‘班级’], [‘201401’, ‘张三’, ‘14班’], [‘201302’, ‘李四’, ‘14班’]]
for i in rows:
sheet.append(i)
print(rows)
wb.save(‘student.xlsx’)
‘’’ [[‘学号’, ‘姓名’, ‘班级’], [‘201401’, ‘张三’, ‘14班’], [‘201302’, ‘李四’, ‘14班’]] ‘’’
Excel文件读取的步骤:<br />```pythonimport openpyxlwb = openpyxl.load_workbook('student1.xlsx')sheet = wb['student']columns = sheet.max_columnrows = sheet.max_rowrow_data = []for i in range(1, rows + 1):for j in range(1, columns + 1):cell_value = sheet.cell(i, j).valuerow_data.append(cell_value)print(row_data)
Json文件
Json是一种使用广泛的轻量级数据格式,它可以将JavaScript对象中表示的一组数据转换为字符串,常用于数据的存储和交换。
从数据格式来看,Python中的字典类型与Json数据格式很接近。
d = {'a':123,'b':{'x':['A', 'B', 'C']},'c':True,'d':Nune}
d = {"a":123,"b":{"x":["A", "B", "C"]},"c":true,"d":null}
Python字典类型数据与Json类型数据的区别:
- Python中的字符串允许单引号和双引号,而Json数据中要求必须是双引号
- 二者在布尔类型、空值的处理方面也有区别
Python标准库中的json模块可以直接将Python数据类型转化为Json。
import jsond = {}d['a'] = 123d['b'] = {'x':['A', 'B', 'C']}d['c'] = Trued['d'] = Noneprint(d)# 转换成Json字符串json_str = json.dumps(d)print(json_str)# 将Json转换成Python字典类型e = json.loads(json_str)print(e)'''{'a': 123, 'b': {'x': ['A', 'B', 'C']}, 'c': True, 'd': None}{"a": 123, "b": {"x": ["A", "B", "C"]}, "c": true, "d": null}{'a': 123, 'b': {'x': ['A', 'B', 'C']}, 'c': True, 'd': None}'''
总结
pickle模块可用于对二进制数据进行序列化和反序列化
os、os.path、shutil的文件操作系统方法
CSV文件、Excel文件和Json文件的读写方法

若有收获,就点个赞吧
0 人点赞
