学习目标
掌握pandas读写数据
掌握基本的数据清洗方法
掌握基本的数据整理方法
pandas读写数据
pandas常用的读写不同格式文件的函数表
| 读取函数 | 写入函数 | 描述 |
|---|---|---|
| read_csv() | to_csv() | 读写csv格式的数据 |
| read_table() | 读取普通分隔符分隔的数据 | |
| read_excel() | to_excel() | 读写excel格式的数据 |
| read_json() | to_json() | 读写json格式的数据 |
| read_html() | to_html() | 读写html格式的数据 |
| read_sql() | to_sql() | 读写数据库中的数据 |
读写csv文件
读取csv文件中的数据
student.csv文件内容如下:
Name,Math,Physics,Chemistry
WangLi,93,88,90
ZhangHua,97,86,92
LiMing,84,72,77
ZhouBin,97,94,80
这个文件以逗号作为分隔符,可使用pandas的read_csv()函数读取它的内容,返回DataFrame格式的文件。
import pandas as pd# 从csv中读取数据csvframe = pd.read_csv('student.csv')print(csvframe)'''Name Math Physics Chemistry0 WangLi 93 88 901 ZhangHua 97 86 922 LiMing 84 72 773 ZhouBin 97 94 80'''
csv文件中的数据为列表数据,位于不同列的元素用逗号隔开,csv文件被视为文本文件,也可以使用pandas的read_table()函数读取,但需要指定分隔符。
pd.read_table('student.csv', sep = ',')print(csvframe)'''Name Math Physics Chemistry0 WangLi 93 88 901 ZhangHua 97 86 922 LiMing 84 72 773 ZhouBin 97 94 80'''
pd.read_csv(filepath_or_buffer, sep = ',', header = 'infer', names = None, index_col = Noone, usecols = None)
作用:读取csv(逗号分隔)文件到DataFrame对象
说明:
- filepath_or_buffer:拟要读取的文件的路径
- sep:其类型是str,默认’,’,用来指定分隔符,csv文件中的分隔符一般为逗号分隔符
- header:指定第几行作为列名,默认为0(第一行)。如果第一行不是列名,是内容,可以设置header = None,以便不把第一行当做列名。
- names:用于结果的列名列表,对各列重命名,即添加表头
- index_col:用作行索引的列编号或列名,可使用index_col = [0, 1]来指定文件中的第1和2列为行索引。
- usecols:选取某几列,不读取整个文件的内容,如usecols = [1, 2]
header参数可以是一个列表,例如[0, 2],这个列表表示将文件中的这些行作为列标题,介于中间的行将被忽略掉(例如本例中的行号为0、2的行将被作为多级标题出现,行号为1的行将被丢弃,dataframe的数据从行号为3的行开始)。
import pandas as pd# 从csv中读取数据csvframe = pd.read_csv('student.csv')print(csvframe)# 指定csv文件中的行号为0/2的行为列标题csvframe = pd.read_csv('student.csv', header = [0, 2])print(csvframe)'''Name Math Physics Chemistry0 WangLi 93 88 901 ZhangHua 97 86 922 LiMing 84 72 773 ZhouBin 97 94 80Name Math Physics ChemistryZhangHua 97 86 920 LiMing 84 72 771 ZhouBin 97 94 80'''
往csv文件写入数据
DataFrame.to_csv(path_or_buf = None, sep = ',', na_rep = '', columns = None, header = True, index = True)
作用:以逗号为分隔将DataFrame对象中的数据写入csv文件中
说明:
- filepath_or_buffer:拟要写入的文件的路径或对象
- sep:默认字符’,’,用来指定输出文件的字段分隔符
- na_rep:字符串,默认’’,缺失数据表示
- columns:指定要写入文件的列
- header:是否保存列名,默认为True,保存。如果给定字符串列表,则将其作为列名的别名
- index:是否保存行索引,默认为True,保存
```python
import pandas as pd
import csv
df10 = pd.DataFrame([[12, 3, 5], [13, 8, 7], [15, 13, 12], [22, 18, 15]],
print(df10) df10.to_csv(‘bbp1.csv’, index = False, header = False) with open(‘bbp1.csv’, newline = ‘’) as csvfile: linereader = csv.reader(csvfile) for row in linereader:index = ['2018-08-01', '2018-08-02', '2018-08-03', '2018-08-04'],columns = ['book', 'box', 'pen'])
print(','.join(row))
‘’’ book box pen 2018-08-01 12 3 5 2018-08-02 13 8 7 2018-08-03 15 13 12 2018-08-04 22 18 15 12,3,5 13,8,7 15,13,12 22,18,15 ‘’’
<a name="hsfgi"></a>## 读取text文件pandas的函数`read_table()`可读取txt文本文件。<br />格式:`pandas.read_table(filepath_or_buffer, sep = '\t', header = 'infer', names = None, index_col = None, skiprows = None, nrows = None, delim_whitespace = False)`<br />作用:读取以'\t'分隔的文件,返回DataFrame对象<br />说明:- sep:其类型是str, 用来指定分隔符,默认为制表符,可以是正则表达式- index_col:指定行索引- skiprows:用来指定读取时要排除的行- nrows:从文件中要读取的行数- dclim_whitespace:dclim_whitespace = True表示用空行来分隔每行首先在工作目录下创建名为11.txt的文本文件,其内容如下:<br />C Python Java<br />1 4 5<br />3 3 4<br />4 2 3<br />2 1 1```pythonimport pandas as pdprint(pd.read_table('11.txt'))'''C Python Java0 1 4 51 3 3 42 4 2 33 2 1 1'''
读写Excel文件
pandas提供了read_excel()函数来读取Excel文件,用to_excel()函数往Excel文件写入数据。
格式:pandas.read_excel(io, sheet_name = 0, header = 0, names = None, index_col = None, usecols = None, skiprows = None, skip_footer = 0)
作用:读取Excel文件中的数据,返回一个DataFrame对象
说明:
- io:Excel文件路径,是一个字符串
- sheet_name:返回指定的sheet(表),如果将sheet_name指定为None,则返回全表;如果需要返回多个表,可以将sheet_name指定为一个列表,例如[‘sheet1’, ‘sheet2’];可以根据sheet的名字字符串或索引来指定所要选取的sheet,例如[0, 1, ‘SEET5’]将返回第一、第二和第五个表,默认返回第一个表。
- header:指定作为列名的行,默认为0,即取第一行,数据为列名行以下的数据;若数据不含列名,则设定header = None
- names:指定所生成的DataFrame对象的列的名字,传入一个list数据
- index_col:指定某列为行索引
- usecols:通过名字或索引值读取指定的列
- skiprows:省略指定行数的数据
- skip_footer:int,默认值为0,读取数据时省略最后int行
首先在工作目录下创建名为chengji.xlsx的Excel文件,Sheet1的内容表所示。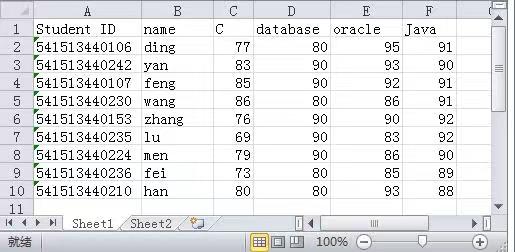
# 将chengji.xlsx的列名作为所生成的DataFrame对象的第一行数据,并重新生成索引print(pd.read_excel('chengji.xlsx', header = None))
把DataFrame对象df中的数据写入Excel文件的函数为df.to_excel()。
格式:df.to_excel(excel_writer, sheet_name = 'Sheet1', na_rep = '', columns = None, header = True, index = True, index_label = None, startrow = 0, startcol = 0, engine = None)
说明:
- excel_writer:输出路径
- sheet_name:将数据存储在Excel的哪个sheet页面,如sheet1页面
- na_rep:缺失值填充
- colums:选择输出的列
- header:指定列名,布尔或字符串列表,默认为True,如果给定字符串列表,则鉴定它是列名称的别名。header = False则不输出题头
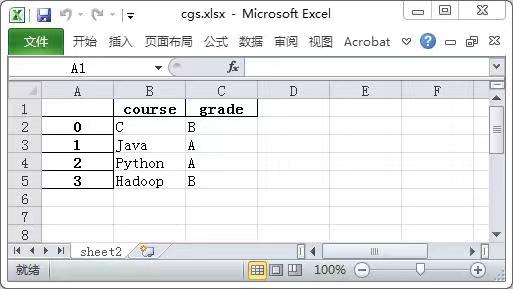
- index:布尔型,默认True,显示行索引(名字),当index = False,则不显示行索引(名字) ```python ‘’’ sheet_name = ‘sheet2’表示将df存储在Wxcel的sheet2页面 columns = [‘course’, ‘grade’]表示选择’course’, ‘grade’两列进行输出 ‘’’
df11 = pd.DataFrame([[‘C’, ‘B’, 32], [‘Java’, ‘A’, 90], [‘Python’, ‘A’, 92], [‘Hadoop’, ‘B’, 88]], columns = [‘course’, ‘grade’, ‘scores’]) df11.to_excel(excel_writer = ‘cgs.xlsx’, sheet_name = ‘sheet2’, columns = [‘course’, ‘grade’])
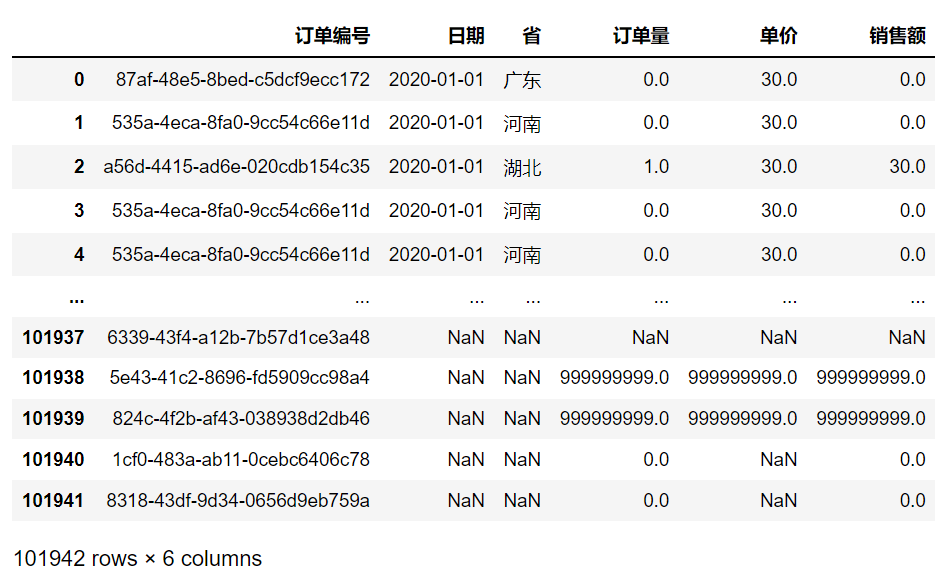
<a name="SK0zu"></a># 数据预处理现实中采集到的原始数据往往不够规范,会存在一定程度的缺失值、重复值以及噪声数据等。直接采用这些的数据进行分析有很大的可能得到错误的结论。因此,在开始数据处理之前,需要对数据进行预处理。<br />垃圾数据会得出垃圾结论<a name="rJpJN"></a>## DataFrame对象的数据预处理方法| DataFrame对象的数据预处理方法 | 描述 || --- | --- || df.duplicated(subset = None, keep = 'first') | 针对某些列,返回用布尔序列表示的重复行 || df.drop_duplicates(subset = None, keep = 'first', inplace = False) | 用于删除df中重复行,并返回删除重复后的结果 || df.fillna(value = None, method = None, axis = None, inplace = False, limit = None) | 使用指定的方法填充NA/NaN缺失值 || df.drop(labels = None, axis = 0, index = None, columns = None, inplace = False) | 删除指定轴上的行或列,它不改变原有的DataFrame对象中的数据,而是返回另一个DataFrame对象来存放删除后的数据 || df.dropna(axis = 0, how = 'any', thresh = None, subset = None, inpace = False) | 删除指定轴上的缺失值 || del df['col'] | 直接在df对象上删除col列 || df.columns = col_lst | 重新命名列名,col_lst为自定义列名列表 || df.rename(index = {'row1':'A'}, columns = {'col1':'A1'}) | 重命名行索引名和列索引名 || df.reindex(index = None, columns = None, fill_value = 'NaN') | 改变索引,返回一个重新索引的新对象,index用作新行索引,columns用作新列索引,将缺失值填充为fill_value || df.replace(to_replace = None, value = None, inplace = False, limit = None, regex = False, method = 'pad') | 用来把to_replace所列出的且在df对象中出现的元素值替换为value所表示的值 || df.merge(right, how = 'inner', on = None, left_on = None, right_on = None) | 通过行索引或列索引进行两个DataFrame对象的连接 || pandas.concat(objs, axis = 0, join = 'outer', join_axes = None, ignore_index = False, keys = None) | 以指定的轴将多个对象堆叠到一起,concat()不会去重对象中重复的记录 || df.stack(level = -1, dropna = True) | 将df的列旋转成行 || df.unstack(level = -1, fill_value = None) | 将df的行旋转为列 |<a name="Y5h07"></a>## 数据预处理的流程数据预处理一般分为三个步骤:数据清洗、数据整理以及数据写入。<br />在数据分析中,数据清洗是数据价值链中最关键的步骤。<br />数据清洗就是处理缺失数据以及清除无意义的信息。对于垃圾数据,即使是通过最好的分析,也将产生错误的结果,并误导业务本身。<a name="Ka3cK"></a>### 数据清洗原始数据中因为各种原因,可能存在缺失和错误。一般表现为数据的某些特征缺失,有噪声和不一致。数据清洗过程首先识别出缺失的值,噪声数据和异常数据点等,并纠正数据中的缺失和错误。<br />数据清洗通常包括三个步骤:- 处理重复值- 处理缺失值- 处理异常值<a name="HVgrE"></a>#### 查看数据(部分数据)查看头部数据,使用`df.head()`会默认打印出前5行。<br />`df.head() # 查看前5行数据,df为DataFrame对象`<br />`df.head(2) # 查看数据前2行数据,括号里指定行数,就会打印指定的前几行数据`<br />查看尾部数据,使用`df.tail()`会默认打印出后5行。<br />`df.tail() # 查看后5行数据,df为DataFrame对象`<br />`df.tail(n) # n为数字几,就是查看尾部几行的数据````python'''数据文件在下方附件中'''import pandas as pd# 读取口罩厂数据,文件路径为根目录mask_data = pd.read_csv('mask_data.csv')print(mask_data.head())print(mask_data.tail())'''订单编号 日期 省 订单量 单价 销售额0 87af-48e5-8bed-c5dcf9ecc172 2020-01-01 广东 0.0 30.0 0.01 535a-4eca-8fa0-9cc54c66e11d 2020-01-01 河南 0.0 30.0 0.02 a56d-4415-ad6e-020cdb154c35 2020-01-01 湖北 1.0 30.0 30.03 535a-4eca-8fa0-9cc54c66e11d 2020-01-01 河南 0.0 30.0 0.04 535a-4eca-8fa0-9cc54c66e11d 2020-01-01 河南 0.0 30.0 0.0订单编号 日期 省 订单量 单价 \101937 6339-43f4-a12b-7b57d1ce3a48 NaN NaN NaN NaN101938 5e43-41c2-8696-fd5909cc98a4 NaN NaN 999999999.0 999999999.0101939 824c-4f2b-af43-038938d2db46 NaN NaN 999999999.0 999999999.0101940 1cf0-483a-ab11-0cebc6406c78 NaN NaN 0.0 NaN101941 8318-43df-9d34-0656d9eb759a NaN NaN 0.0 NaN销售额101937 NaN101938 999999999.0101939 999999999.0101940 0.0101941 0.0'''
代码中所用到的文件:
mask_data.csv
test_data.csv
import pandas as pdmask_data = pd.read_csv('mask_data.csv')mask_data
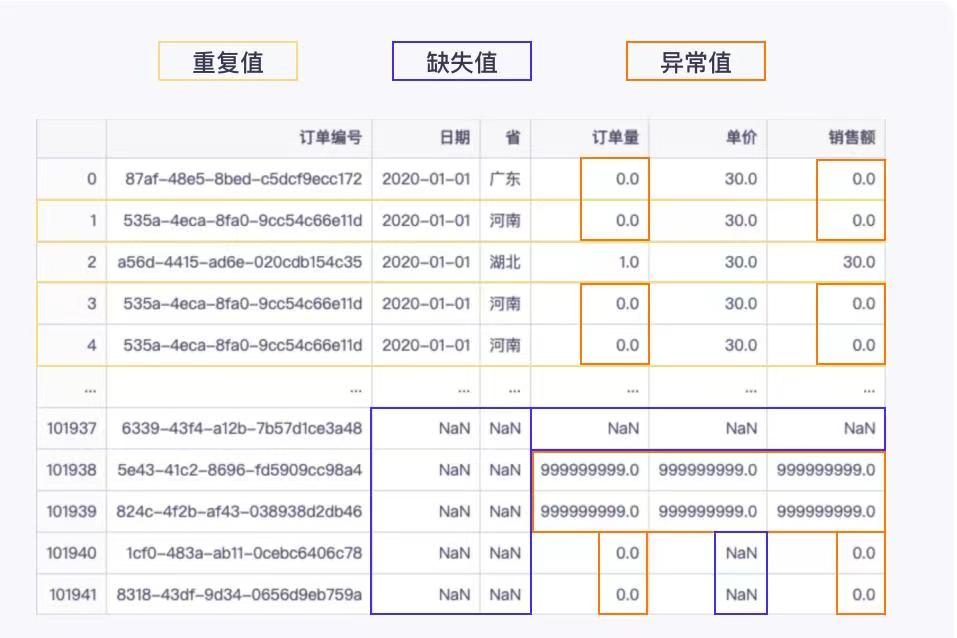
重复值处理
重复值很好理解,就跟字面意思一样,指的是表格中重复出现的数据。
处理重复值的方法非常简单,发现重复值,删除即可,这样可以避免重复处理一些不完整的数据。
查看重复值:data.duplicated(subset, keep)
作用:返回的是一个存有布尔值的Series对象,如果想查看具体的值,可以直接布尔索引data[data.duplicated(subset, keep)]
说明:
- subset:可以传入具体的列名或列名序列,来精准定位查看某列的重复值,默认为None
- keep:可以传入{‘first’, ‘last’, False},默认为’first’,只显示后面出现的重复值。如果要一起显示重复与被重复的数据,可以将keep参数的值设置为False
```python
data = {‘name’:[‘Alice’, ‘Jack’, ‘John’, ‘Mary’, ‘Alice’, ‘Jack’, ‘John’, ‘Mary’],
df = pd.DataFrame(data)'age':[40, 10, 30, 20, 40, 10, 30, 20],'weight':[65, 30, 50, 40, 65, 30, 50, 40]}
显示布尔值
print(df.duplicated())当keep为False时,显示所有重复值
print(df[df.duplicated(keep = False)])keep值默认为first,保留第一次出现的值,只显示后面出现的重复值
print(df[df.duplicated()])
‘’’ 0 False 1 False 2 False 3 False 4 True 5 True 6 True 7 True dtype: bool name age weight 0 Alice 40 65 1 Jack 10 30 2 John 30 50 3 Mary 20 40 4 Alice 40 65 5 Jack 10 30 6 John 30 50 7 Mary 20 40 name age weight 4 Alice 40 65 5 Jack 10 30 6 John 30 50 7 Mary 20 40 ‘’’
删除重复值:`data.drop_duplicates(subset, keep, inplace)`<br />说明:- subset:可以传⼊具体的列名或列名序列,来精准定位删除某列的重复值,默认为None- keep :可以传⼊ {'first', 'last', False},默认为'first' ,保留第⼀次出现的重复值,删除后⾯的重复值- inplace :可以传⼊ True 或 False,默认为 False,True 表示直接在原来的DataFrame上删除重复项,⽽默认值False表示⽣成⼀个副本```pythondata = {'name':['Alice', 'Jack', 'John', 'Mary', 'Alice', 'Jack', 'John', 'Mary'],'age':[40, 10, 30, 20, 40, 10, 30, 20],'weight':[65, 30, 50, 40, 65, 30, 50, 40]}df = pd.DataFrame(data)print(df)# 查看重复数据print(df[df.duplicated()])# 去除数据重复值df.drop_duplicates(inplace = True)# 验证,重新查看是否有重复值print(df[df.duplicated(keep = False)])print(df)'''name age weight0 Alice 40 651 Jack 10 302 John 30 503 Mary 20 404 Alice 40 655 Jack 10 306 John 30 507 Mary 20 40name age weight4 Alice 40 655 Jack 10 306 John 30 507 Mary 20 40Empty DataFrameColumns: [name, age, weight]Index: []name age weight0 Alice 40 651 Jack 10 302 John 30 503 Mary 20 40'''
缺失值处理
数据缺失是经常遇到的情况,有一部分是源于现实数据不好获得,一部分则是源于人为因素。
遇到数据缺失的情况,一般有两种方法进行处理:
- 直接删除
- 数据填补
直接删除数据是最简便的方法。但这建立在数据量足够多的情况下。此时,删除几个空缺值,对整个数据不会构成较大影响。
查看数据信息:info()
在实际的数据分析项目中,一般使用info()方法查看数据的缺失情况。当非空数据与数据总量不一致时,就说明这份数据有可能存在缺失值。
import pandas as pdmask_data = pd.read_csv('mask_data.csv')# 查看mask_data数据的基本信息mask_data.info()'''<class 'pandas.core.frame.DataFrame'>RangeIndex: 101942 entries, 0 to 101941Data columns (total 6 columns):# Column Non-Null Count Dtype--- ------ -------------- -----0 订单编号 101942 non-null object1 日期 100956 non-null object2 省 100956 non-null object3 订单量 100960 non-null float644 单价 100958 non-null float645 销售额 100960 non-null float64dtypes: float64(3), object(3)memory usage: 4.7+ MB'''

查看缺失值:data.isnull()
作用:返回DataFrame类型的布尔值数据,检测结果为布尔值,缺失数据会用True来表示,False则代表这里的数据正常。True的位置标示该位置的数据为缺失值。
可以通过data[data.isnull().values]查看具体的值。
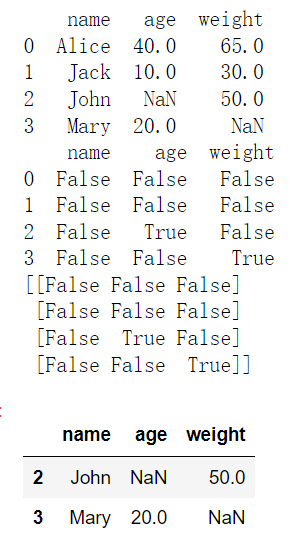
data = {'name':['Alice', 'Jack', 'John', 'Mary'],'age':[40, 10, None, 20],'weight':[65, 30, 50, None]}df = pd.DataFrame(data)print(df)# 返回一个DataFrame类型数据,无法通过data[]索引取值print(df.isnull())# 返回一个array数组,可以通过data[]索引取值print(df.isnull().values)# 重新查看有空值的数据df[df.isnull().values]
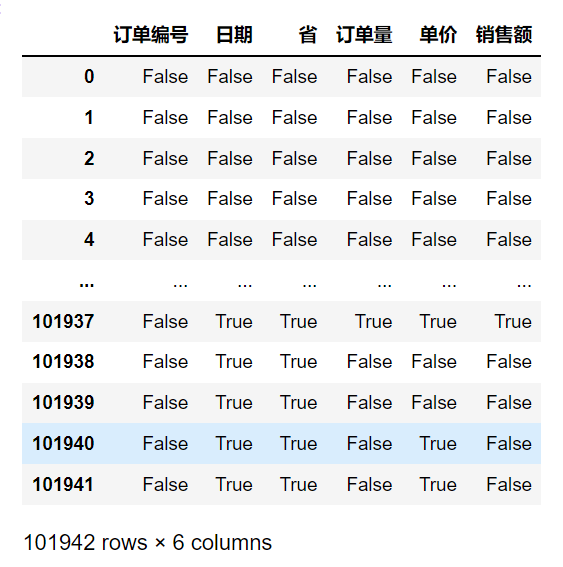
import pandas as pdmask_data = pd.read_csv('mask_data.csv')# 查看mask_data的缺失值mask_data.isnull()
直接删除
删除缺失值:data.dropna(axis, how)
说明:
- axis:可以传入0或1,0为行,1为列,默认值为0。用于确定是否删除包含缺失值的行或列。
- how:可以传入’any’或’all’,默认为’any’。’any’表示如果存在任何空值,则删除该行或列;’all’表示如果所有值均为空值,则删除该行或列。
df.dropna()代码返回的是一个删掉所有缺失数据的DataFrame对象,不会修改原DataFrame对象的数据,因此需要重新赋值给变量来保存结果。 删除所有缺失值后重新赋值给变量mask_data:mask_data = mask_data.dropna()
import pandas as pdmask_data = pd.read_csv('mask_data.csv')# 将DataFrame对象中包含缺失值的每一行全部删掉mask_data = mask_data.dropna()# 查看mask_data的缺失值mask_data.isnull()
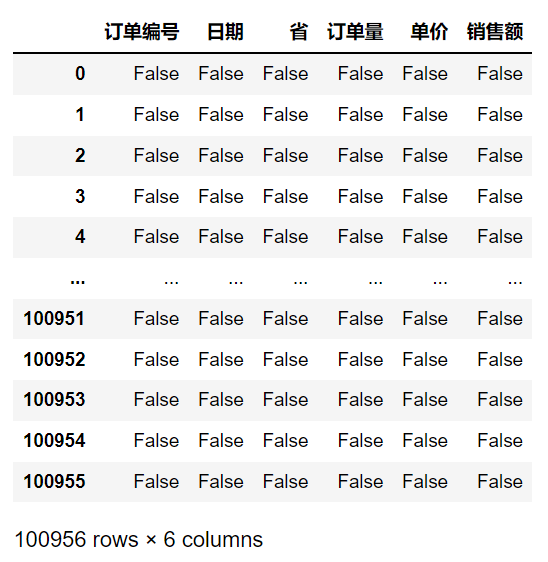
df.dropna()将DataFrame对象中包含缺失值的每一行全部删掉。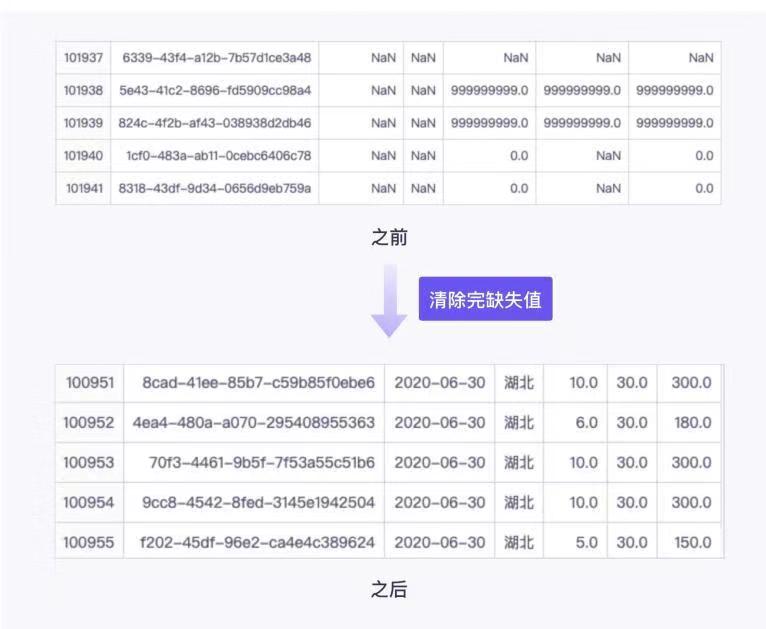
subset参数,它可以在dropna()方法中指定删除一列或多列数据中含有缺失值的行。
将指定的列名写进中括号[]中,再赋值给subset参数,即可限定dropna()方法的删除范围。
# 删除'ID'一列数据缺失的行test_data = test_data.dropna(subset = ['ID'])
数据填补
缺失值所在的特征为数值型时,通常利用其均值、中位数和众数等描述其集中趋势的统计量来填充;缺失值所在特征为类别型数据时,则选择众数来填充。
填补缺失值:DataFrame.fillna(value = None, method = None, axis = None, inplace = False, limit = None)
说明:
- value:可以传入变量、字典、Series、DataFrame,用于修改填补缺失值。可以通过字典的形式,针对每一列缺失值进行填补。
- inplace:可以传入True或False,确认是否在原数据操作。
```python
df = pd.DataFrame([[None, 3, None, None], [2, 4, None, 3],
print(df)[None, None, None, None], [0, 1, 5, 4]],columns = ['A', 'B', 'C', 'D'])
空值用0填充
print(df.fillna(0, inplace = False))空值用字典填充
print(df.fillna({‘A’:0, ‘B’:1, ‘C’:2, ‘D’:3}, inplace = False))
‘’’ A B C D 0 NaN 3.0 NaN NaN 1 2.0 4.0 NaN 3.0 2 NaN NaN NaN NaN 3 0.0 1.0 5.0 4.0 A B C D 0 0.0 3.0 0.0 0.0 1 2.0 4.0 0.0 3.0 2 0.0 0.0 0.0 0.0 3 0.0 1.0 5.0 4.0 A B C D 0 0.0 3.0 2.0 3.0 1 2.0 4.0 2.0 3.0 2 0.0 1.0 2.0 3.0 3 0.0 1.0 5.0 4.0 ‘’’
```pythonimport numpy as npimport pandas as pd# 通过字典形式填充缺失值df = pd.DataFrame(np.random.randn(5, 3))df.loc[:3, 1] = Nonedf.loc[:2, 2] = Noneprint(df)df.fillna({1:0.88, 2:0.66})
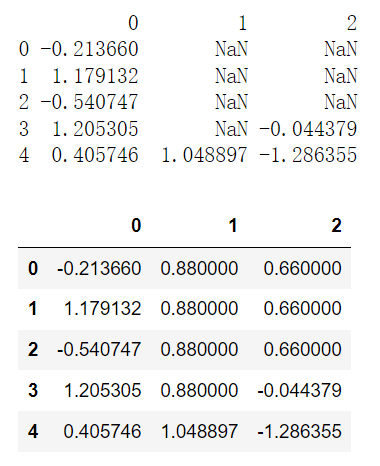
data = pd.Series([1, None, 3.5, None, 7])data1 = data.fillna(data.mean())print(data)print(data1)'''0 1.01 NaN2 3.53 NaN4 7.0dtype: float640 1.0000001 3.8333332 3.5000003 3.8333334 7.000000dtype: float64'''
df = pd.DataFrame(np.random.randn(4, 3))df.iloc[2:, 1] = Nonedf.iloc[3:, 2] = Noneprint(df)df[1] = df[1].fillna(df[1].mean())print(df)'''0 1 20 0.216087 0.500261 -0.0749251 -0.472647 -0.915703 1.3330182 -0.958768 NaN -2.3539043 -0.577112 NaN NaN0 1 20 0.216087 0.500261 -0.0749251 -0.472647 -0.915703 1.3330182 -0.958768 -0.207721 -2.3539043 -0.577112 -0.207721 NaN'''
df.fillna(method = 'ffill')
作用:用前一个数据值替代NaN填补缺失值
import pandas as pdimport numpy as npdf = pd.DataFrame(np.random.randn(6, 3))df.iloc[2:, 1] = Nonedf.iloc[4:, 2] = Noneprint(df)df.fillna(method = 'ffill')
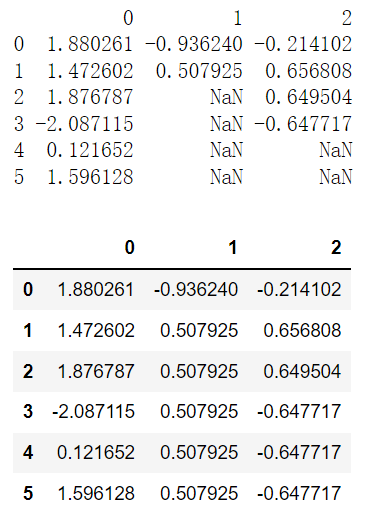
df.fillna(method = 'bfill')
作用:用后一个数据值替代NaN,与pad相反,bfill表示用后一个数据代替NaN,可以用limit限制每列可以替代NaN的数目。
import pandas as pdimport numpy as npdf = pd.DataFrame(np.random.randn(6, 3))df.iloc[2:, 1] = Nonedf.iloc[4:, 2] = Noneprint(df)df.fillna(method = 'bfill')
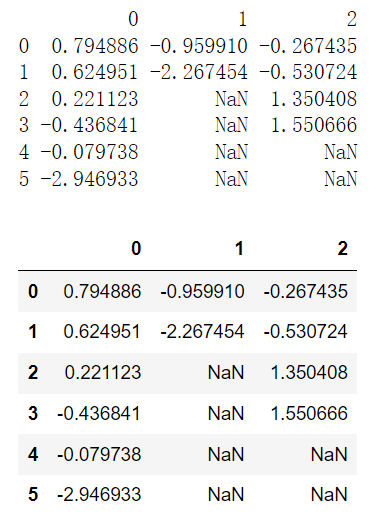
df.fillna(df.mean())
作用:用平均数或其他描述性统计量来替代NaN
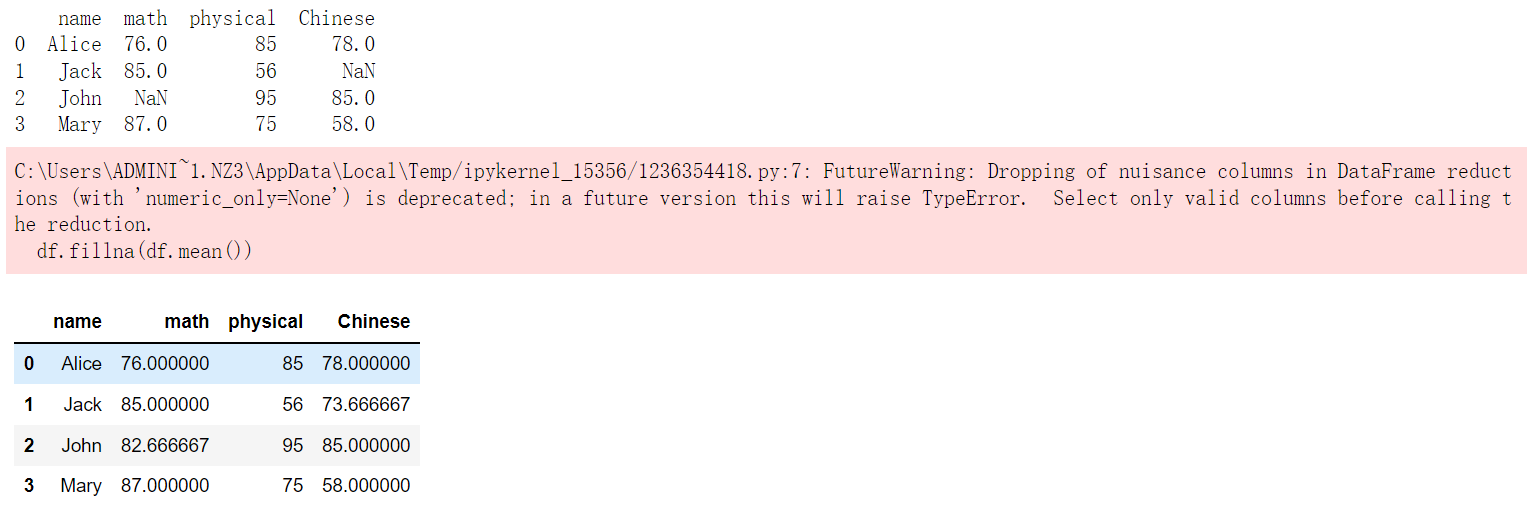
data = {'name':['Alice', 'Jack', 'John', 'Mary'],'math':[76, 85, None, 87],'physical':[85, 56, 95, 75],'Chinese':[78, None, 85, 58]}df = pd.DataFrame(data)print(df)df.fillna(df.mean())
常用的缺失值填补:
| 方法 | 描述 |
|---|---|
| data.mean() | 求平均数 |
| data.median() | 求中位数 |
| data.mode() | 求众数 |
| data.max() | 求最大值 |
| data.min() | 最最小值 |
| data.sum() | 求和 |
| data.std() | 求标准差 |
strip():清除字符型数据左右(首尾)指定的字符,默认为空格,中间的不清除。
data = {'name':['Alice', 'Jack', 'John', 'Mary'],'IP':['221.205.98.55', '183.184.226.205', '221.205.98.55', '222.31.51.200'],'年龄':[25, 44, 46, 34],'性别':['女', '男', '男', '女']}df = pd.DataFrame(data)print(df)# 因为IP是一个对象,所以先转为strnewDF = df['IP'].str.strip()newDF
异常值处理
有时数据中有一个或多个异常大或异常小的数值,超出了这份数据实际的限定范围,这样的数值被称为异常值。
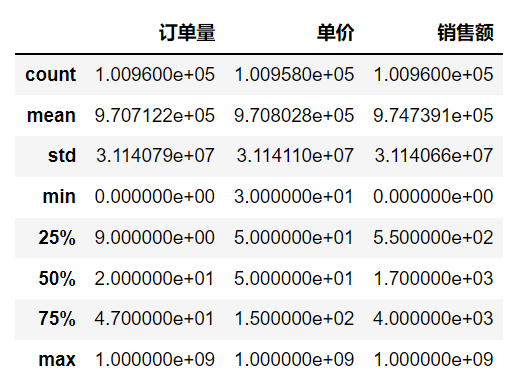
df.describe():查看Series对象或者DataFrame对象描述性统计信息
mask_data = pd.read_csv('mask_data.csv')mask_data.describe()

在pandas库中,有一种筛选数据的方法叫做布尔索引,使用df[]通过表达式的形式来提取一定范围的数据。
使用df['列索引']来提取某一列的信息。
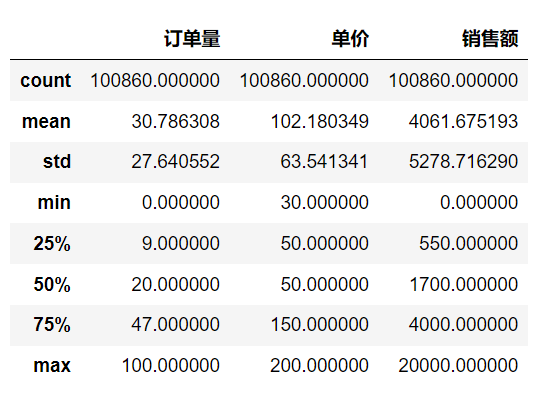
比如想选择mask_data数据中,单价一列小于等于200的数据,就可以设置条件表达式mask_data['单价'] <= 200。把它加入括号中索引:mask_data[mask_data['单价'] <= 200],就可以选取mask_data数据中单价这一列小于等于200的数据。
# 筛选单价小于等于200的数据mask_data = mask_data[mask_data['单价'] <= 200]# 查看mask_data的描述性统计信息mask_data.describe()
数据整理
数据清洗完毕后并不意味着这份数据可以直接拿去分析。
不光要把数据清洗干净,还需要整理数据将数据变得规整,这样才有利于后续的数据分析。
数据整理指的是在数据分析前对所需字段进行数据排序、数据转换、数据抽取、数据合并、数据计算等准备操作。
在开始整理数据之前,我们先观察一下清洗好的数据,看看有哪些字段可以被整理。
# 查看之前清洗好的数据mask_data
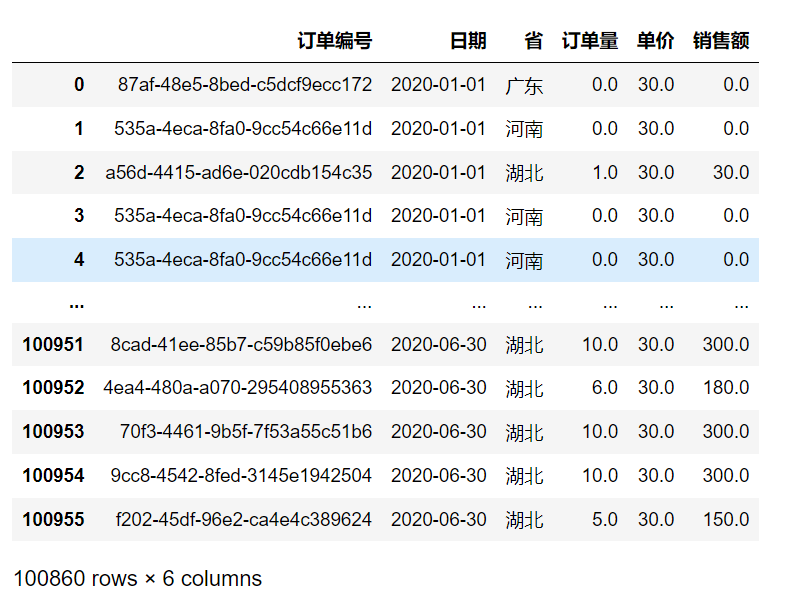
从结果中可以发现,日期这一列数据的格式是年-月-日,也就是说,我们的统计数据是精确到日的。
假设要先分析研究各个月的利润变化情况,所以需要将日期的统计数据由年-月-日调整为月,然后作为新的月份字段保存到数据中。
但是mask_data中的日期列数据并不是datatime类型。
mask_data.info()'''<class 'pandas.core.frame.DataFrame'>Int64Index: 100860 entries, 0 to 100955Data columns (total 6 columns):# Column Non-Null Count Dtype--- ------ -------------- -----0 订单编号 100860 non-null object1 日期 100860 non-null object2 省 100860 non-null object3 订单量 100860 non-null float644 单价 100860 non-null float645 销售额 100860 non-null float64dtypes: float64(3), object(3)memory usage: 5.4+ MB'''
Python中有一种专门储存时间日期的数据类型——datetime,可以直接从中提取想要的时间单位。
需要将日期这一列的数据类型转换为datetime类型,才能从中提取月份信息。
因此可以将这次的数据整理分成三个步骤,他们分别是:
- 转换日期数据
- 提取月份信息
-
转换日期数据
pd.to_datetime(arg, format)
作用:将DataFrame对象或Series对象的数据类型转换成datetime类型。
说明: arg:为要转换的数据,它可以是DataFrame对象或Series对象
- format:为datetime类型的日期格式,比如说这份数据,它是以年-月-日的形式出现的,那么它对应的format就是’%Y-%m-%d’(year-month-day的缩写)
注意:是datetime而不是datatime,可别写错了哦
import pandas as pd# 转换日期数据,并设置对应的日期格式date_data = pd.to_datetime(mask_data['日期'], format = '%Y-%m-%d')# 查看date_datadate_data'''0 2020-01-011 2020-01-012 2020-01-013 2020-01-014 2020-01-01...100951 2020-06-30100952 2020-06-30100953 2020-06-30100954 2020-06-30100955 2020-06-30Name: 日期, Length: 100860, dtype: datetime64[ns]'''
提取月份信息
Series.dt.month:提取月份信息Series.dt
作用:可以把datetime类型的数据转成便于我们提取对应的日期和时间数据的对象
| 日期数据属性 | |
|---|---|
| s.dt.year | 返回年份信息 |
| s.dt.month | 返回月份信息 |
| s.dt.day | 返回某日信息 |
# 转换日期数据,并设置对应的日期格式date_data = pd.to_datetime(mask_data['日期'], format = '%Y-%m-%d')# 提取日期数据中的月份信息month_data = date_data.dt.month# 查看month_datamonth_data'''0 11 12 13 14 1..100951 6100952 6100953 6100954 6100955 6Name: 日期, Length: 100860, dtype: int64'''
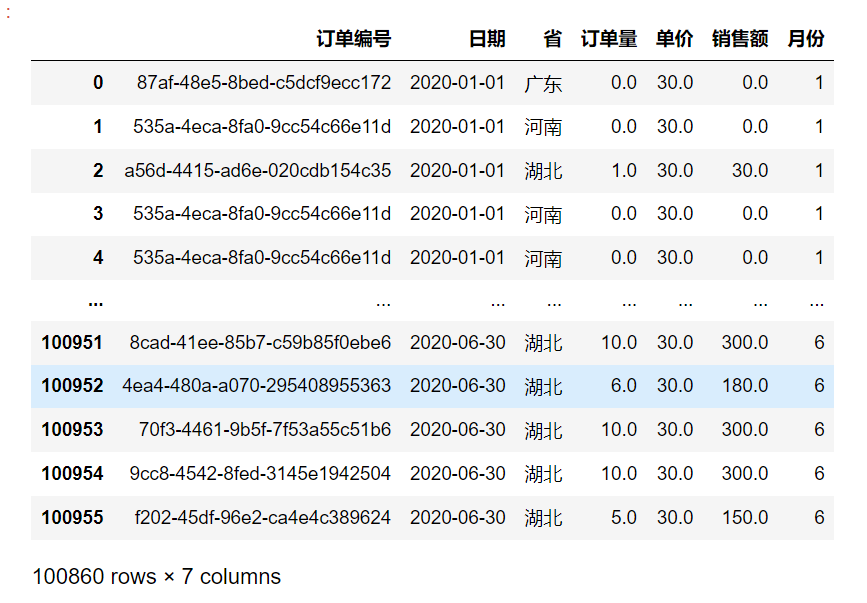
添加新列
df['colname'] = Series
作用:为原数据添加新的一列
说明:
- df:是DataFrae对象的简称
- colname:是要添加的新列的列名,在此案例中,colname就是月份
- Series:是要传入的Series对象
在此案例中,s就是上一页得到的month_data。
mask_data['月份'] = month_datamask_data
数据写入
df.to_csv()
作用:将清洗好的数据写入csv文件中
说明:
使用index参数来限制DataFrame对象的行索引是否写入到csv文件。它的默认值为True,会让写入的csv文件包含一列行索引。如果把这个参数设置为index = False就可以取消写入行索引,不用将行索引那一列写入cav文件
# 保存清洗干净的数据,并取消写入行索引mask_data.to_csv('mask_data_clean.csv', index = False)
格式问题处理
格式问题分为格式错误和具体格式处理两种情况:
格式错误:时间、日期、数值等显示格式不一致,比如同一列数值,有的是数字格式、有的是文本格式,这种情况统一成一种格式即可。
具体格式处理:内容中有不该存在的字符,比如某个人的身份证是360199102030022李,此时’李’就是不该存在的字符,这种情况下需要定位修改成正确的身份证号码。
格式错误
常见的是时间格式的处理。
pd.to_datetime(arg, format, errors)
作用:进行时间格式化
说明:arg:可以传入需要处理的内容,可以是int、float、str、datetime、list、tuple等。
- format:传入的值需要对应待处理数据的格式,如’20201201’对应’%Y%m%d’、’11042021’对应’%d%m%Y’.
- errors:可以传入{‘ignore’, ‘raise’, ‘coerce’},默认为’raise’。如果为’raise’,当无法解析时程序会报错,如20200231,2月没有31号,程序会报错;如果为’coerce’,当无法解析时,将内容设置为空值;如果为’ignore’,当无法解析时,忽视该数据。 ```python result = pd.to_datetime(‘03042021’, format = ‘%d%m%Y’) result
‘’’ Timestamp(‘2021-04-03 00:00:00’) ‘’’
<a name="nLvnY"></a>#### 具体格式处理当数据量过多时,可以通过`data.info()`或`data.dtypes`来查看整体数据的类型,如果某一列的数据都为int类型时,显示的就是int64,如果其中有一个数据是其他类型的话,就会显示object。```pythondata.info()
当某列数据的类型不符合要求时,可以通过data.astype()进行强制转换。
data['顾客编号'] = data['顾客编号'].astype('object')data.dtypes
当使用data.astype()遇到报错时,证明该列的数据类型不统一,可以根据报错提示进行定位修正。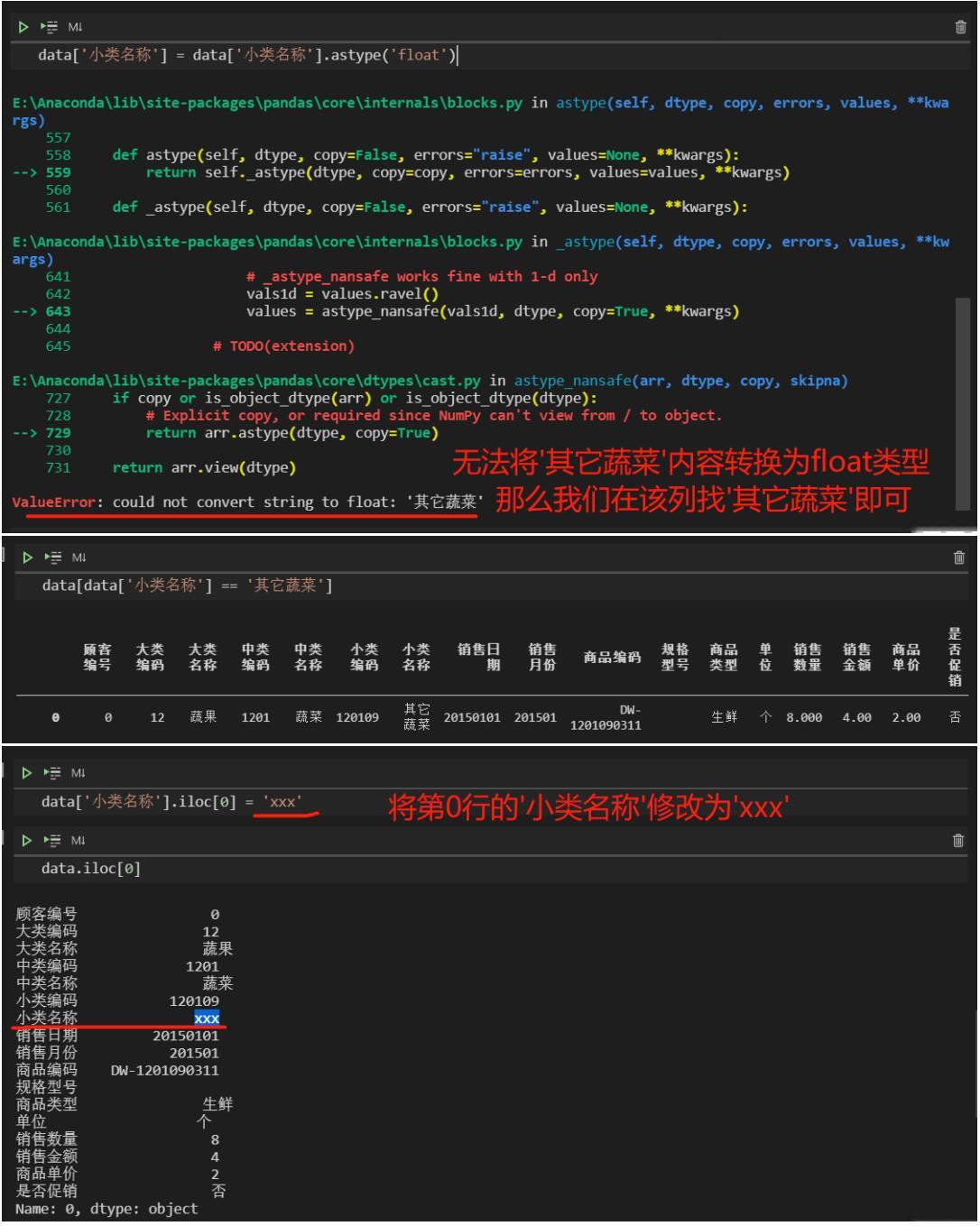
常用的数据处理函数
merge数据合并
merge(left, right, how = 'inner', on = None, left_on = None, right_on = None, left_index = False, right_index = False, sort = False, suffixes = ('_x', '_y'), copy = True, indicator = False, validate = None)
作用:通过一个或多个键将两个DataFrame按行合并起来,与SQL中的join用法类似。
说明:
- left:参与合并的左侧DataFrame
- right:参与合并的右侧DataFrame
- how:连接方法有inner、left、right、outer
- on:用于连接的列名
- left_on:左侧DataFrame中用于连接键的列
- right_on:右侧DataFrame中用于连接键的列
- left_index:左侧DataFrame中行索引作为连接键
- right_index:右侧DataFrame中行索引作为连接键
- sort:合并后会对数据排序,默认为True
- suffixes:修改重复名
price = pd.DataFrame({'fruit':['apple', 'grape', 'orange', 'orange'],'price':[8, 7, 9, 11]})amount = pd.DataFrame({'fruit':['apple', 'grape', 'orange'],'amount':[5, 11, 8]})display(price, amount, pd.merge(price, amount))

concat数据连接
如果要合并的DataFrame之间没有连接键,就无法使用merge方法。
pandas中的concat方法可以实现,默认情况下会按行的方向堆叠数据。如果在列向上连接设置axis = 1即可。 ```python s1 = pd.Series([0, 1], index = [‘a’, ‘b’]) s2 = pd.Series([2, 3, 4], index = [‘a’, ‘d’, ‘e’]) s3 = pd.Series([5, 6], index = [‘f’, ‘g’]) print(pd.concat([s1, s2, s3]))
‘’’ a 0 b 1 a 2 d 3 e 4 f 5 g 6 dtype: int64 ‘’’ ```

若有收获,就点个赞吧
0 人点赞
