学习目标
掌握ndarray多维数组的创建
掌握数组元素的索引、切片和选择
掌握数组的运算
掌握读写数据文件
NumPy简介
NumPy是在1995年诞生的Python库Numeric的基础上建立起来的,但真正促使NumPy的发行的是Python的SciPy库。SciPy中并没有合适的类似于Numeric中的对于基础数据对象处理的功能,于是,SciPy的开发者将SciPy中的一部分和Numeric的设计思想结合,在2005年发行了NumPy。
NumPy(Numerical Python的缩写)是一个开源的Python科学计算和数据分析的扩展库,包含很多实用的数学函数,涵盖线性代数运算、傅里叶变换和随机数生成等功能,是很多数据分析扩展库的基础库。
NumPy允许用户进行快速的交互式原型设计,可以很自然地使用数组和矩阵。
NumPy的部分功能如下:
- ndarrray:一个具有矢量算术运算且节省空间的多维数组。
- 用于对整组数据进行快速运算的标准数学函数(无需编写循环)。
- 用于读/写磁盘数据的工具以及用于操作内存映射文件的工具。
- 线性代数、随机数生成以及傅里叶变换功能。
-
NumPy多维数组
NumPy提供了两种基本的对象:
ndarray:英文全称为n-dimensional array object,称为多维数组,后统一称之为数组。
- ufunc:英文全称为universal function object,它是一种能够对数组进行处理的特殊函数。
NumPy库的核心对象是n维数组对象ndarray,Python中所有的ufunc函数都是围绕ndarray对象进行的。
- ndarray数组能够对整块数据进行数学运算
- 通常来说,ndarray是存储单一数据的容器,即其中的所有元素都需要是相同的类型
- 和list不同,它能直接保存数据,而list保存的是对象的引用。
Numpy常用的导入格式:import numpy as np。
NumPy库的基础是n维数组对象(即ndarray对象),该对象由两部分组成:
- 一部分是实际的数据(同种类型)
- 另一部分是描述这些数据的元数据
ndarray数组中的维度(dimensions)又称为轴(axis)。
数组的第0轴对应着第一维,第1轴对应着第二维,维度为(3, 4)的形状,元素总个数为12。
创建ndarray对象
1. 利用array函数创建数组对象
array函数的格式:np.array(object, dtype, ndmin)
array函数的主要参数及说明表:
| 参数名称 | 说明 |
|---|---|
| object | 接收array,表示想要创建的数组 |
| dtype | 接收data-type,表示数组需要的数据类型,未给定则选择保存对象所需最小类型,默认为None |
| ndmin | 接收int,指定生成数组应该具有的最小维度,默认为None |
import numpy as np# 列表data1 = [1, 3, 5, 7]w1 =np.array(data1)print('w1:', w1)# 元组data2 = (2, 4, 6, 8)w2 = np.array(data2)print('w2:', w2)# 多维数组data3 = [[1, 2, 3, 4], [5, 6, 7, 8]]w3 = np.array(data3)print('w3:', w3)'''w1: [1 3 5 7]w2: [2 4 6 8]w3: [[1 2 3 4][5 6 7 8]]'''
2. 专门创建数组的函数
arange函数创建等差一维函数。
格式:np.arange([start, ]stop, [step, ]dtype)
| 参数名称 | 说明 |
|---|---|
| start | 起始值,默认从0开始 |
| stop | 结束值,生成的元素不包括结束值 |
| step | 步长,可省略,默认步长为1 |
| dtype | 设置元素的数据类型,默认使用输入数据的类型 |
warray = np.arange(20)print(warray)warray = np.arange(0, 1, 0.2)print(warray)'''[ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19][0. 0.2 0.4 0.6 0.8]'''
linspace函数创建等差一维数组,接收元素数量作为参数。
格式:np.linspace(start, stop, num, endpoint, retstep = False, dtype = None)
| 参数名称 | 说明 |
|---|---|
| start | 起始值,默认从0开始 |
| stop | 结束值,生成的元素不包括结束值 |
| num | 要生成的等间隔样例数量 |
warray = np.linspace(0, 1, 5)print(warray)'''[0. 0.25 0.5 0.75 1. ]'''
logspace函数:创建等比一维数组
格式:np.logspace(start, stop, num, endpoint = True, base = 10.0, dtype = None)
| 参数名称 | 说明 |
|---|---|
| start,stop | 代表的是10的幂,默认基数base为10 |
| num | 要生成的元素个数 |
# 生成1-10之间的具有5个元素的等比数列warray = np.logspace(0, 1, 5)print(warray)'''[ 1. 1.77827941 3.16227766 5.62341325 10. ]'''
zeros函数:创建指定长度或形状的全0数组
格式:np.zeros(shape, dtype = float, order = 'C')ones函数:创建指定长度或形状的全1数组
格式:np.ones(shape, dtype = None, order = 'C')empty()函数:创建一个随机数组
格式:np.empty(shape, dtype = float, order = 'C')eye()函数创建一个对角线全1,其余位置全是0的二维数组
格式:eye(N, M = None, k = 0)
说明:
- N:行数
- M:可选参数,列数,默认值为N
- k:k = 0时,全1对角线为主对角线;k > 0时,全1对角线向右上方偏移;k < 0时,全1对角线向左下方偏移。 ```python import numpy as np arr1 = np.zeros(shape = (2, 2)) arr2 = np.ones(shape = (2, 2)) arr3 = np.empty(shape = (3, 3)) arr4 = np.eye(3) print(arr1) print(arr2) print(arr3) print(arr4)
‘’’ [[0. 0.] [0. 0.]] [[1. 1.] [1. 1.]] [[0.00000000e+000 0.00000000e+000 0.00000000e+000] [0.00000000e+000 0.00000000e+000 6.00783825e-321] [0.00000000e+000 0.00000000e+000 9.86546146e-312]] [[1. 0. 0.] [0. 1. 0.] [0. 0. 1.]] ‘’’
```pythonarr1 = np.eye(3, k = 0)arr2 = np.eye(3, k = 1)print(arr1)print(arr2)'''[[1. 0. 0.][0. 1. 0.][0. 0. 1.]][[0. 1. 0.][0. 0. 1.][0. 0. 0.]]'''
identity()函数创建n*n单位矩阵,主对角线上元素都为1,其他元素都为0
格式:identity(n, dtype = None)
说明:
- n:单位矩阵的行数(也是列数)
- dtype:指定矩阵元素的数据类型 ```python arr1 = np.identity(3, dtype = int) print(arr1)
‘’’ [[1 0 0] [0 1 0] [0 0 1]] ‘’’
`full()`函数创建由固定值填充的数组<br />格式:`full(shape, fill_vlaue, dtype = None, order = 'C')`<br />说明:- shape:int或int类型序列,表示矩阵形状- fill_value:填充值- dtype:可选参数,指定元素的数据类型- order:可选参数,取值‘C’或‘F’,表示数组在内存中的存放次序是以行(C)为主还是以列(F)为主,默认值为‘C’。```pythonarr2 = np.full((2, 3), 8)print(arr2)'''[[8 8 8][8 8 8]]'''
3. 使用ndarray()函数创建ndarray数组
常用参数如下表:
| 参数 | 类型 | 作用 |
|---|---|---|
| shape | int型tuple | 指定数组的维度和每维的大小 |
| dtype | int型、float型等 | 指定数组中元素的类型 |
| buffer | ndarray | 用于初始化数组的数组 |
| offset | int | buffer中用于初始化数组的首个数据的偏移,是数组元素在内存中所占字节数的整数倍 |
| strides | int型tuple | 每个轴的下标增加1时,数据指针在内存中增加的字节数 |
| order | ‘C’或者’F’ | ‘C’表示行优先,buffer中的数据按行的顺序存入将要创建的数组中;‘F’表示列优先 |
# buffer中的数据按行的顺序存入将要创建的数组e中e = np.ndarray(shape = (2, 3), dtype = int,buffer = np.array([0, 1, 2, 3, 4, 5, 6, 7, 8]),offset = 0, order = 'C')# buffer中的数据按列的顺序存入将要创建的数组f中f = np.ndarray(shape = (2, 3), dtype = int,buffer = np.array([0, 1, 2, 3, 4, 5, 6, 7, 8]),offset = 0, order = 'F')print(e)print(f)'''[[0 1 2][3 4 5]][[0 2 4][1 3 5]]'''
ndarray对象属性和数据转换
ndarray对象属性及说明表:
| ndarray数组对象的属性 | 属性说明 |
|---|---|
| T | ndarray.T返回数组的转置 |
| dtype | 描述数组元素的类型 |
| shape | 返回数组的形状,以元组表示的数组的各维的大小 |
| ndim | 返回数组的维度 |
| size | ndarray.size返回数组中元素的个数 |
| itemsize | 返回数组中的单个元素在内存中所占字节数 |
| flat | 返回一个数组的迭代器,对flat赋值将导致整个数组的元素被覆盖 |
| real/imag | 给出复数数组的实部/虚部 |
| nbytes | 返回数组的所有元素所占的存储空间 |
warray = np.array([[1, 2, 3], [4, 5, 6]])print('维度为:', warray.ndim)print('形状为:', warray.shape)print('元素个数为:', warray.size)'''维度为: 2形状为: (2, 3)元素个数为: 6'''
warray = np.array([[1, 2, 3], [4, 5, 6]])warray.shape = (3, 2)print(warray)'''[[1 2][3 4][5 6]]'''
arr1 = np.arange(6)print(arr1.dtype)arr2 = arr1.astype(np.float64)print(arr2.dtype)'''int32float64'''
numpy.random模块
numpy.random模块中常用的随机分布函数表
numpy.random模块中常用的随机分布函数表:
| 随机分布函数 | 函数功能 |
|---|---|
| binomial(n, p, size = None) | 产生size个二项分布的样本值 n表示n次试验,p表示每次试验发生(成功)的概率。 函数的返回值表示n次试验中发生(成功)的次数 |
| exponential(scale = 1.0, size = None) | 产生size个指数分布的样本值 这里的scale是β,为标准差,β = 1/λ, λ为单位时间内事件发生的次数 |
| normal(loc = 0.0, scale = 1.0, size = None) | 产生size个正态(高斯)分布的样本值 loc为正态分布的均值,scale为正态分布的标准差, size缺省,则采样一个 |
| poisson(lam = 1.0, size = None) | 从泊松分布找那个生成随机数 lam是单位时间内事件的平均发生次数 |
| uniform(low = 0.0, high = 1.0, size = None) | 产生size个均匀分布[low, high)的样本值 size为int或tuple类型, 如size = (m, n, k),则输出mnk个样本,缺省时输出1个值 |
简单随机数
在NumPy.random模块中,提供了多种随机数的生成函数。randint()函数:randint函数生成指定范围的随机整数来构成指定形状的数组。
格式:np.random.randint(low, high = None, size = None)
说明:
- 生成size个随机整数,若为元组则指定数组形状
- 取值区间为[low, high)
- 若没有输入参数high,则取值区间为[0, low) ```python arr = np.random.randint(100, 200, size = (2, 4)) print(arr)
‘’’ [[187 187 100 146] [172 114 142 170]] ‘’’
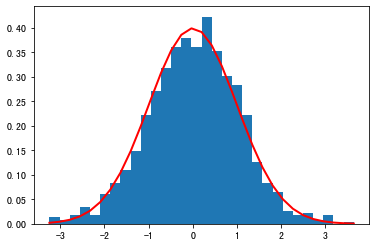
<a name="XatXg"></a>### 随机分布`normal()`函数:产生size个正态(高斯)分布的样本值<br />格式:`normal(loc = 0.0, scale = 1.0, size = None)````pythonfrom numpy import randomimport numpy as npimport matplotlib.pyplot as pltmu, sigma = 0, 1# 获取1000个样本值s = random.normal(loc = mu, scale = sigma, size = 1000)# 绘制样本的直方图,以及概率密度函数count, bins, patches = plt.hist(s, 30, density = True)plt.plot(bins,1 / (sigma * np.sqrt(2 * np.pi)) * np.exp(- (bins - mu)**2 / (2 * sigma**2)),linewidth = 2,color = 'r')plt.show()
随机排序
numpy.random模块中用于对数组对象随机排序的函数
| 函数名称 | 函数功能 |
|---|---|
| shuffle(x) | 打乱对象x(多维数组按照第一维打乱) 直接在原来的数组上进行操作,改变原来数组元素的顺序 无返回值 x可以是数组或者列表 |
| permutation(x) | 打乱并返回新对象(多维数组按照第一维打乱) 不直接在原数组上进行操作,而是返回一个新的打乱元素顺序的数组,并不改变原来的数组 x可以是整数或者列表,如果是整数k,那就随机打乱numpy.arange(k) |
import numpy as nparr1 = np.arange(9).reshape((3, 3))print('原数组:\n', arr1)np.random.shuffle(arr1)print('随机排序后的数组:\n', arr1)'''原数组:[[0 1 2][3 4 5][6 7 8]]随机排序后的数组:[[3 4 5][0 1 2][6 7 8]]'''
数组变换
ndarray数组对象提供了一些方法用来改变数组的形状。
| 改变数组形状的方法 | 功能 |
|---|---|
| ndarray.reshape(shape, order) | 返回一个具有相同数据域,但shape不一样的视图 |
| ndarray.resize(new_shape, orefcheck) | 原地修改数组的形状,需要保持元素个数前后相同 |
| ndarray.transpose(*axes) | 返回数组针对某一轴进行转置后的数组,对于二维ndarray,transpose在不指定参数时默认是矩阵转置 |
| ndarray.swapaxes(axis1, axis2) | 返回数组axis1轴与axis2轴互换的视图 |
| ndarray.flatten(order) | 返回将原数组展平后的一维数组的拷贝(全新的数组) |
| ndarray.ravel(order = ‘C’) | 返回将原数组展平后的一维数组的视图 |
1. 数组重塑(reshape函数)
对于定义好的数组,可以通过reshape方法改变其数组维度。
格式:np.reshape(a, newshape, order = 'C')
说明:
- a:需要处理的数据
- newshape:新维度——整数或整数元组 ```python arr1 = np.arange(8) print(‘原数组:\n’, arr1) arr2 = arr1.reshape(4, 2) print(‘重塑后的数组:\n’, arr2)
‘’’ 原数组: [0 1 2 3 4 5 6 7] 重塑后的数组: [[0 1] [2 3] [4 5] [6 7]] ‘’’
reshape的参数中的其中一个可以设置为-1,表示数组的维度可以通过数据本身来推断。```pythonarr1 = np.arange(12)print('arr1:', arr1)arr2 = arr1.reshape(2, -1)print('arr2:\n', arr2)'''arr1: [ 0 1 2 3 4 5 6 7 8 9 10 11]arr2:[[ 0 1 2 3 4 5][ 6 7 8 9 10 11]]'''
2. 数组重塑(ravel函数和flatten函数)
与reshape相反的方法是数据散开(ravel)或数据扁平化(flatten)。数据重塑不会改变原来的数组。
arr1 = np.arange(12).reshape(3, 4)arr2 = arr1.ravel()arr3 = arr1.flatten()print('arr1:\n', arr1)print('arr2:', arr2)print('arr3:', arr3)'''arr1:[[ 0 1 2 3][ 4 5 6 7][ 8 9 10 11]]arr2: [ 0 1 2 3 4 5 6 7 8 9 10 11]arr3: [ 0 1 2 3 4 5 6 7 8 9 10 11]'''
3. 数组合并(hstack函数、vstack函数和concatenate函数)
- hstack函数:实现横向合并
- vstack函数:实现纵向合并
- concatenate函数:可以实现数组的横向或纵向合并,参数axis = 1时进行横向合并,axis = 0时进行纵向合并。 ```python arr1 = np.arange(6).reshape(3,2) arr2 = arr1 * 2 arr3 = np.hstack((arr1, arr2)) arr4 = np.vstack((arr1, arr2)) print(‘arr1:\n’, arr1) print(‘arr2:\n’, arr2) print(‘横向合并hstack为:\n’, arr3) print(‘纵向合并vstack为:\n’, arr4)
‘’’ arr1: [[0 1] [2 3] [4 5]] arr2: [[ 0 2] [ 4 6] [ 8 10]] 横向合并hstack为: [[ 0 1 0 2] [ 2 3 4 6] [ 4 5 8 10]] 纵向合并vstack为: [[ 0 1] [ 2 3] [ 4 5] [ 0 2] [ 4 6] [ 8 10]] ‘’’
<a name="jTHgV"></a>#### 4. 数组分割(hsplit函数、vsplit函数和split函数)- hsplit函数:实现数组横向分割- vsplit函数:实现数组纵向分割- split函数:实现数组指定方向的分割```pythonarr = np.arange(16).reshape(4, 4)arr1 = np.hsplit(arr, 2)arr2 = np.vsplit(arr, 2)print(arr)print('横向分割为:\n', arr1)print('纵向分割为:\n', arr2)'''[[ 0 1 2 3][ 4 5 6 7][ 8 9 10 11][12 13 14 15]]横向分割为:[array([[ 0, 1],[ 4, 5],[ 8, 9],[12, 13]]), array([[ 2, 3],[ 6, 7],[10, 11],[14, 15]])]纵向分割为:[array([[0, 1, 2, 3],[4, 5, 6, 7]]), array([[ 8, 9, 10, 11],[12, 13, 14, 15]])]'''
5. 数组转置和轴对称
- transpose方法进行转置
- 直接利用数组的T属性进行数组转置 ```python arr = np.arange(6).reshape(3, 2) arr1 = arr.transpose((1, 0)) arr2 = arr.T print(‘原矩阵:\n’, arr) print(‘函数转置矩阵:\n’, arr1) print(‘属性转置矩阵:\n’,arr2)
‘’’ 原矩阵: [[0 1] [2 3] [4 5]] 函数转置矩阵: [[0 2 4] [1 3 5]] 属性转置矩阵: [[0 2 4] [1 3 5]] ‘’’
<a name="y2SzM"></a>### 索引和切片数组索引机制指的是用方括号[]加序号的形式抽取元素、选取数组的某些元素以及为索引处的元素重新赋值。<br />数组的切片操作是用来抽取数组的一部分元素生成新数组。切片是把用冒号“:”隔开的数字置于方括号“[]”里。> 注意:对Python列表进行切片操作得到的列表是原列表的拷贝,而NumPy对ndarray数组进行切片操作得到的数组是指向相同缓冲区的视图,对所得切片数组元素的改变就是对原数组元素的改变。<a name="sXYOh"></a>#### 一维数组的索引和切片一维数组的索引类似Python中的列表。```pythonarr = np.arange(10)print(arr)print(arr[2])print(arr[-1])print(arr[1:4])'''[0 1 2 3 4 5 6 7 8 9]29[1 2 3]'''
数组的切片返回的是原始数组的视图,不会产生新的数据,如果需要的并非视图而是要复制数据,则可以通过copy方法实现。
arr = np.arange(10)arr1 = arr[-4:-1].copy()print(arr)print(arr1)'''[0 1 2 3 4 5 6 7 8 9][6 7 8]'''
使用列表索引数组
x = np.arange(10, 1, -1)print(x)x[[2, 2, 1, 6]]'''[10 9 8 7 6 5 4 3 2]array([8, 8, 9, 4])'''
布尔值索引数组
y = np.arange(30)b = y > 20y[b]'''array([21, 22, 23, 24, 25, 26, 27, 28, 29])'''
多维数组的索引和切片
对于多维数组,它的每一个维度都有一个索引,各个维度的索引之间用逗号分隔。
也可以使用整数函数和布尔值索引访问多维数组。
arr = np.arange(12).reshape(3, 4)print(arr)print('第0行中第1列到第2列的元素:\n', arr[0, 1:3])print('第2列元素:\n', arr[:, 2])print('第0行第0列元素:\n', arr[:1, :1])'''[[ 0 1 2 3][ 4 5 6 7][ 8 9 10 11]]第0行中第1列到第2列的元素:[1 2]第2列元素:[ 2 6 10]第0行第0列元素:[[0]]'''
arr = np.arange(12).reshape(3, 4)# 从两个序列的对应位置取出两个整数来组成下标:arr[0, 1], arr[1, 3]print(arr)print('索引结果1:', arr[(0, 1), (1, 3)])# 索引第1、2行中第0、2、3列的元素print('索引结果2:',arr[1:2, (0, 2, 3)])mask = np.array([1, 0, 1], dtype = np.bool)# mask是一个布尔数组,它索引第0,2行中第1列元素print('索引结果3:', arr[mask, 1])'''[[ 0 1 2 3][ 4 5 6 7][ 8 9 10 11]]索引结果1: [1 7]索引结果2: [[4 6 7]]索引结果3: [1 9]'''
选择数组元素的方法
ndarray.take()
ndarray.take()函数:根据指定的索引indices从数组对象ndarray中获取对应元素,并构成一个新的数组返回。
格式:ndarray.take(indices[, axis = None, out = None, mode = 'raise'])
说明:
- axis:用来指定选择元素的轴,默认情况下,使用扁平化的输入数组,即把数组当成一个一维数组
- out:是ndarray对象,用来存放函数返回值,要求其shape必须与函数返回值的shape一致
- mode:指定越界索引将如何处理 ```python x = np.array([0, 2, 4, 6, 8, 10, 12, 14, 16, 18]) print(‘第1次取出的元素:\n’, x.take([0, 2, 4])) print(‘第2次取出的元素:\n’, x.take([[2, 5], [3, 6]]))
‘’’ 第1次取出的元素: [0 4 8] 第2次取出的元素: [[ 4 10] [ 6 12]] ‘’’
<a name="TRdXM"></a>#### ndarray.put()`ndarray.put()`函数:将数组中索引indices指定的位置处的元素值设置为values中对应的元素值。<br />格式:`ndarray.put(indices, values[, mode])````pythonx = np.arange(0, 20, 2)print(x)# 将x中索引[0, 1]处的值设置为列表[1, 3]中对应的值x.put([0, 1], [1, 3])print(x)'''[ 0 2 4 6 8 10 12 14 16 18][ 1 3 4 6 8 10 12 14 16 18]'''
ndarray.sezrchsorted()
ndarray.searchsorted()函数:将v插入到当前有序的数组中,返回插入的位置索引。
格式:ndarray.searchsorted(v, side = 'left', sorter = None)
w = np.array([1, 2, 3, 3, 3, 3, 6, 7, 9, 10, 12])w.searchsorted(3)print(w.searchsorted(3))print(w.searchsorted(3, side = 'right'))'''26'''
ndarray.itemset()
ndarray.itemset()函数:修改数组中某个元素的值
歌手ndarray.itemset(*args)
a = np.array([[0, 1, 2], [33, 4, 5], [6, 7, 8]])print('修改前:\n', a)a.itemset((1, 2), 12)print('修改后:\n', a)'''修改前:[[ 0 1 2][33 4 5][ 6 7 8]]修改后:[[ 0 1 2][33 4 12][ 6 7 8]]'''
NumPy多维数组的运算
ufunc函数
ufunc函数全称为通用函数,是一种能够对数组中的所有元素进行操作的函数。
对一个数组进行重复运算时,使用ufunc函数比使用math库中的函数效率要高很多。
常用的ufunc函数运算
四则运算
加(+)、减(-)、乘()、除(/)、幂(*)。
数组减的四则运算表示对每个数组中的元素分别进行四则运算,所以形状必须相同。
比较运算
、<、==、>=、<=、!=。
比较运算返回的结果是一个布尔数组,每个元素为每个数组对应元素的比较结果。算术运算的二元函数
numpy模块中对两个数组的元素进行算术运算的二元函数。
| 函数 | 说明 |
|---|---|
| add(a, b) | 将两个数组中对应的元素相加,a、b为两个ndarray数组 |
| subtract(a, b) | 将两个数组中对应的元素相减 |
| multiply(a, b) | 将两个数组中对应的元素相乘 |
| power(a, b) | 对第一个数组中的元素x,第二个数组中的对应位置的元素y,计算x的y次方 |
| greate、greate_equal、 less、less_equal、 equal、not_equal |
将两个数组中对应的元素进行比较运算,最终产生布尔型的数组。 相当于运算符>、>=、<、<=、==、!= |
数组最常用的运算是算术运算,可以为数组的每个元素加上或乘以某个数值,可以让两个数组对应元素之间做加、减、乘、除运算等。
import numpy as npa = np.array([[1, 2, 3], [4, 5, 6]])print('a = \n', a)print('a + 6 = \n', a + 6)'''a =[[1 2 3][4 5 6]]a + 6 =[[ 7 8 9][10 11 12]]'''
通过在数组和数字之间使用条件运算符,比如大于号,将会得到由布尔值组成的数组,对于原数组中满足条件的元素,布尔数组中处于同等位置的元素为True。
import numpy as npa = np.array([[0.51691317, 0.20933602, 0.22460165],[0.91598144, 0.43223077, 0.59339314]])b = a[a > 0.5]print('a > 0.5?\n', a > 0.5)print('a > 0.5:\n', b)'''a > 0.5?[[ True False False][ True False True]]a > 0.5:[0.51691317 0.91598144 0.59339314]'''
逻辑运算
np.any函数表示逻辑“or”np.all函数表示逻辑“and”- 运算结果返回布尔值 ```python a = np.array([1, -1, 5]) b = np.array([4, 0, 3]) c = np.any([a, b]) print(‘a = ‘, a) print(‘b = ‘, b) print(‘any(a, b) = ‘, c)
‘’’ a = [ 1 -1 5] b = [4 0 3] any(a, b) = True ‘’’
<a name="s8aVq"></a>### 条件逻辑运算在NumPy中可以利用基本的逻辑运算就可以实现数组的条件运算。```pythonarr1 = np.array([1, 3, 5, 7])arr2 = np.array([2, 4, 6, 8])cond = np.array([True, False, True, False])result = [(x if c else y) for x, y, c in zip(arr1, arr2, cond)]result'''[1, 4, 5, 8]'''
这种方法对大规模数组处理效率不高,也无法用于多维数组。
NumPy提供的where方法可以克服这些问题。np.where()函数:满足条件(condition)输出x,不满足输出y
格式:np.where(condition, x, y)
np.where([[True, False], [True, True]], [[1, 2], [3, 4]], [[9, 8], [7, 6]])'''array([[1, 8],[3, 4]])'''
np.where()中若只有条件(condition),没有x和y,则输出满足条件元素的坐标。
这里的坐标以tuple的形式给出,通常原数组有多少维,输出的tuple中就包含几个数组,分别对应符合条件元素的各维坐标。
w = np.array([2, 5, 6, 3, 10])np.where(w > 4)'''(array([1, 2, 4], dtype=int64),)'''
ufunc函数的广播机制
广播(broadcasting)是指不同形状的数组之间执行算术运算的方式。
需要遵循4个原则:
- 让所有输入数组都向其中shape最长的数组看齐,shape中不足的部分都通过在左边加1补齐。
- 如果两个数组的形状在任何一个维度上都不匹配,那么数组的形状会沿着维度为1的维度进行扩展,以匹配另一个数组的形状。
- 输出数组的shape是输入数组shape的各个轴上最大值
- 如果两个数组的形状在任何一个维度上都不匹配,并且没有任何一个维度等于1,则引发异常。 ```python arr1 = np.array([[0, 0, 0], [1, 1, 1], [2, 2, 2]]) arr2 = np.array([1, 2, 3]) print(‘arr1:\n’, arr1) print(‘arr2:\n’, arr2) print(‘arr1 + arr2:\n’, arr1 + arr2)
‘’’ arr1: [[0 0 0] [1 1 1] [2 2 2]] arr2: [1 2 3] arr1 + arr2: [[1 2 3] [2 3 4] [3 4 5]] ‘’’
<a name="dQMrN"></a>### 常用统计函数Numpy中提供了很多用于统计分析的函数,常见的有sum、mean、std、var、min和max等。<br />ndarray数组对象的很多统计计算方法都有一个axis参数,它有如下作用:- 当axis = None(默认)时,数组被当成一个一维数组,对数组的计算操作是对整个数组进行的,比如sum方法,就是求数组中所有元素的和- 当axis被指定一个int整数时,对数组的计算操作是以提供的axis轴进行的,axis = 0表示对column(列)进行操作,axis = 1表示对row(行)进行操作| ndarray数组对象的常用统计计算方法 | 功能 || --- | --- || ndarray.max(axis = None, out = None) | 返回根据指定的axis计算最大值,axis = 0表示求各column的最大值,axis = 1表示求各row的最大值 || ndarray.argmax(axis = None, out) | 返回根据指定axis计算最大值索引,out是ndarray对象,用来存放函数返回值,要求其shape必须与函数返回值的shape一致 || ndarray.min(axis = None, out None) | 返回根据指定的axis计算最小值 || ndarray.argmin(axis = None, out = None) | 返回指定axis最小元素的索引 || ndarray.ptp(axis, out) | 返回根据指定axis计算最大值与最小值的差 || ndarray.clip(min, max, out) | 返回数组元素限制在[min, max]之间的新数组,小于min的转为min,大于max的转为max || ndarray.trace(offset = 0,axis1 = 0, aixs2 = 1, dtype = None, out = None) | 返回数组的迹(对角线元素的和),offset表示离开主对角线的偏移量 || ndarray.sum(axis = None, dtype = None, out = None) | 返回指定axis的所有元素的和,默认求所有元素的和 || ndarray.cumsum(axis = None, dtype = None, out = None) | 按照所给定的轴参数返回元素的累计和 || ndarray.mean(axis = None, dtype = None, out = None) | 返回指定axis的数组元素均值 || ndarray.var(axis = None, dtype = None, out = None, ddof = 0) | 根据指定的axis计算数组的方差 || ndarray.std(axis = None, dtype = None, out = None, ddof = 0) | 根据指定axis计算数组的标准差 || ndarray.prod(axis = None, dtype = None, out = None) | 返回指定轴的所有元素乘积 || ndarray.cumprod(axis = None, dtype = None, out = None) | 返回指定轴的累积 |<a name="axpe6"></a>### 统计计算`ndarray.max()`函数:返回根据指定的axis计算最大值<br />格式:`ndarray.max(axis=None, out=None)`<br />说明:- axis=0表示求各column的最大值,axis=1表示求各row的最大值- out是ndarray对象,用来存放函数返回值,要求其shape必须与函数返回值的shape一致```pythonimport numpy as npa = np.array([[2, 3, 4, 9], [8, 7, 6, 5], [4, 3, 5, 8]])o = np.ndarray(shape = 3)# axis = 1表示求各row的最大值a.max(axis = 1, out = o)print(o)'''[9. 8. 8.]'''
ndarray.clip()函数:返回数组元素限制在[min, max]之间的新数组(小于min的转为min,大于max的转为max)。
格式:ndarray.clip(min, max, out)
import numpy as npa = np.array([[2, 3, 4, 9], [8, 7, 6, 5], [4, 3, 5, 8]])print(a.clip(5, 8))'''[[5 5 5 8][8 7 6 5][5 5 5 8]]'''
ndarray.cumsum()函数:按照给定轴参数返回元素的累计和。
格式:ndarry.cumsum(axis = None, dtype = None, out = None)
import numpy as npa = np.array([[2, 3, 4, 9], [8, 7, 6, 5], [4, 3, 5, 8]])print('a = \n', a)# 按行求累计和print('按行求累计和=\n', a.cumsum(axis = 1))'''a =[[2 3 4 9][8 7 6 5][4 3 5 8]]按行求累计和=[[ 2 5 9 18][ 8 15 21 26][ 4 7 12 20]]'''
重复数据与去重
统计分析中有时也需要把一个数据重复若干次,使用tile和repeat函数即可实现此功能。tile()函数:把一个数组数据重复
格式:np.tile(A, reps)
说明:
- A:要重复的数组
- reps:重复次数
repeat()函数:把一个数组数据重复
格式:np.repeat(A, reps, axis = None)
说明:
- A:需要重复的数组元素
- reps:重复次数
- axis:指定沿哪个轴进行重复,axis = 0表示按行进行元素重复;axis = 1表示按列进行元素重复 ```python import numpy as np arr = np.arange(5) print(‘原数组:’, arr) wy = np.tile(arr,3) print(‘重复数据1:’, wy) arr2 = np.array([[1, 2, 3], [4, 5, 6]]) print(‘重复数据2:\n’, arr2.repeat(2, axis = 0))
‘’’ 原数组: [0 1 2 3 4] 重复数据1: [0 1 2 3 4 0 1 2 3 4 0 1 2 3 4] 重复数据2: [[1 2 3] [1 2 3] [4 5 6] [4 5 6]] ‘’’
`unique()`函数:去除一维数组或列表中重复的元素,并按元素大小由小到大返回一个新的元组或者列表。<br />格式:`np.unique(A)````pythonimport numpy as npnames = np.array(['红色', '蓝色', '黄色', '白色', '红色'])print('原数组:', names)print('去重后的数据:', np.unique(names))'''原数组: ['红色' '蓝色' '黄色' '白色' '红色']去重后的数据: ['白色' '红色' '蓝色' '黄色']'''
排序
ndarray数组对象的排序元素常用方法如表所示。
| 排序元素的方法 | 方法功能 |
|---|---|
| ndarray.sort(axis = -1, kind = ‘quicksort’, order = None) |
- 原地对数组元素进行排序,即排序后改变了原数组,无返回值 - axis指定排序沿着数组的轴方向,0表示按行,1表示按列,axis默认值为-1,表示沿最后的轴排序 - kind指定排序的算法,其取值集合为{‘quicksort’, ‘mergesort’, ‘heapsort’} - order指定元素的排列顺序,默认升序 |
| ndarray.argsort(axis = -1, kind = ‘quicksort’, order = None) |
返回对数组进行升序排序之后的数组元素在原数组中的索引 |
import numpy as npy1 = np.array([[0, 15, 10, 5], [25, 22, 3, 2], [55, 45, 59, 50]])print('原y1=\n', y1)y1.sort()print('排序后的y1=\n', y1)'''原y1=[[ 0 15 10 5][25 22 3 2][55 45 59 50]]排序后的y1=[[ 0 5 10 15][ 2 3 22 25][45 50 55 59]]'''
np.argsort函数和np.lexsort函数根据一个或多个键值对数据集进行排序。np.argsort():返回数组值从大到小的索引值np.lexsort():返回按照最后一个传入数据排序的结果
使用argsort和lexsort函数,可以在给定一个或多个键时,得到一个由整数构成的索引数组,索引值表示数据在新的序列中的位置。
import numpy as nparr = np.array([7, 9, 5, 2, 9, 4, 3, 1, 4, 3])print('原数组:', arr)print('排序后:', arr.argsort())'''原数组: [7 9 5 2 9 4 3 1 4 3]排序后: [7 3 6 9 5 8 2 0 1 4]'''
import numpy as npa = np.array([7, 2, 1, 4])b = np.array([5, 2, 6, 7])c = np.array([5, 2, 4, 6])d = np.lexsort((a, b, c))print('排序后:', list(zip(a[d], b[d], c[d])))'''排序后: [(2, 2, 2), (1, 6, 4), (7, 5, 5), (4, 7, 6)]'''
数组拼接与切分
垂直拼接
vstack()函数:用来将列数相同的数组序列tup中的数组进行竖直方向的拼接,即把数组序列tup中后一个数组作为行追加到前一个数组的下边,数组向竖直方向上生长。
格式:np.vstack(tup)
说明:
- 参数tup的类型可以是元组、列表或numpy数组
- 返回结果为numpy数组 ```python import numpy as np a = np.array([1, 2, 3]) b = np.array([2, 3, 4]) print(np.vstack((a, b)))
‘’’ [[1 2 3] [2 3 4]] ‘’’
<a name="MzVtg"></a>#### 水平拼接`hstack()`函数:用来将行数相同的数组序列tup中的数组进行水平方向的拼接,即把数组序列tup中后一个数组作为列追加到前一个数组的右边,数组向水平方向上生长。<br />格式:`np.hstack(tup)`<br />说明:- 参数tup的类型可以是元组、列表或numpy数组- 返回结果为numpy数组```pythona = np.array([1, 2, 3]).reshape(3, 1)b = np.array([4, 5, 6]).reshape(3, 1)c = np.hstack((a, b))print('a=\n', a)print('b=\n', b)print('c=\n', c)'''a=[[1][2][3]]b=[[4][5][6]]c=[[1 4][2 5][3 6]]'''
水平切分
hsplit()函数:用来水平方向上切分数组
格式:np.hsplit(ary, indices_or_sections)
说明:
- ary:表示待切分的数组
- indices_or_sections:可以是一个整数,表示平均切分的个数,必须要均等分,否则会报错,也可以是一个数组元素递增的整数一维数组,如:[2, 3]表示要将ary分成ary[:2]、ary[2:3]、ary[3:]三个子数组。 ```python a = np.arange(16).reshape(4, 4) x, y, z = np.hsplit(a, [2, 3]) print(‘a:\n’, a) print(‘x:\n’, x) print(‘y:\n’, y) print(‘z:\n’, z)
‘’’ a: [[ 0 1 2 3] [ 4 5 6 7] [ 8 9 10 11] [12 13 14 15]] x: [[ 0 1] [ 4 5] [ 8 9] [12 13]] y: [[ 2] [ 6] [10] [14]] z: [[ 3] [ 7] [11] [15]] ‘’’
<a name="Ewhgl"></a>#### 竖直切分`vsplit()`函数:用来竖直方向上切分数组<br />格式:np.vsplit(ary, indices_or_sections)```pythona = np.arange(16).reshape(4, 4)x, y = np.vsplit(a, 2)print('a:\n', a)print('x:\n', x)print('y:\n', y)'''a:[[ 0 1 2 3][ 4 5 6 7][ 8 9 10 11][12 13 14 15]]x:[[0 1 2 3][4 5 6 7]]y:[[ 8 9 10 11][12 13 14 15]]'''
线性代数运算
在NumPy中,用“*”进行两个数组相乘是两个数组对应位置上的元素相乘。
NumPy用dot()函数执行一般意义上的矩阵(用ndarray数组表示)乘积。
A = np.arange(1, 10).reshape((3, 3))B = np.ones(shape = (3, 3), dtype = int)print('A=', A)print('B=', B)C = np.dot(A, B)D = A.dot(B)E = A * Bprint('dot(A, B)=', C)print('A.dot(B)=', D)print('A*B=', E)'''A= [[1 2 3][4 5 6][7 8 9]]B= [[1 1 1][1 1 1][1 1 1]]dot(A, B)= [[ 6 6 6][15 15 15][24 24 24]]A.dot(B)= [[ 6 6 6][15 15 15][24 24 24]]A*B= [[1 2 3][4 5 6][7 8 9]]'''
线性代数运算常用函数
numpy的linalg模块提供了一些进行线性代数运算的函数。
| 函数 | 描述 |
|---|---|
| det | 计算矩阵行列式 |
| eig(A) | 计算方阵A的特征值和特征向量 |
| inv(A) | 计算方阵A的逆 |
| svd(A, full_matrices = 1, compute_uv = 1) |
对矩阵进行奇异值分解 该函数返回3个矩阵-U、Sigma和V 其中U和V是正交矩阵,Sigma是输入矩阵的奇异值 |
| solve(a, b) | 求解形如AX=B的线性方程组 其中A是一个N*N的二维数组,而B是一个长度为N的一维数组,数组X是待求解的线性方程组的解 |
创建numpy矩阵
创建矩阵有两种方法:
- mat()函数
- matrix()函数 ```python matr1 = np.mat(‘1, 2, 3, 4, 5, 6, 7, 8, 9’, dtype = np.float64) matr2 = np.matrix([[1, 2, 3], [4, 5, 6], [7, 8, 9]]) print(matr1) print(matr2)
‘’’ [[1. 2. 3. 4. 5. 6. 7. 8. 9.]] [[1 2 3] [4 5 6] [7 8 9]] ‘’’
<a name="MNlJF"></a>### 矩阵运算矩阵运算是针对整个矩阵中的每个元素进行的,和使用循环比,在运算速度上更快。<br />矩阵和矩阵之间可以进行+、-、*、/,其中*为点乘,需要特别注意。如果要对应元素相乘使用multipy()函数。<a name="OkDAT"></a>### 矩阵特有的属性| 属性 | 含义 || --- | --- || T | 返回矩阵的转置 || H | 返回矩阵的共轭转置 || I | 返回逆矩阵 || A | 返回矩阵的视图 |<a name="tcKtR"></a># 读写数据文件<a name="U85B5"></a>## 读写二进制文件numpy中的`save()`函数以二进制格式保存数组到一个文件中,文件的扩展名为“.npy”,该扩展名是由系统自动添加的。<br />numpy中的`load()`函数从二进制文件中读取数据。<br />格式:`numpy.save(file, arr)`<br />说明:- file:用来保存数组的文件名或文件路径,是字符串类型- arr:要保存的数组```pythonimport numpy as npA = np.arange(16).reshape(2, 8)print(A)np.save('C:/test/A.npy', A)np.load('C:/test/A.npy')
读写文本文件
np.savetxt()函数:用于将数组中的数据存放到文本文件中
格式:np.savetxt(filename, arr, fmt = '%.18e', delimiter = '', newline = '\n')
说明:
- filename:存放数据的文件名
- arr:要保存的数组
- fmt:指定数据存入格式
- delimiter:数据列之间的分隔符,数据类型为字符串,默认值为’ ‘
- newline:数据行之间的分隔符
np.loadtxt()函数:读取文本文件
格式:np.loadtxt(fname, dtype = , comments = '#', delimiter = None, converters = None, skiprows = 0,usecol = None, unpack = False, ndmin = 0, encoding = 'bytes')
说明:
- fname:str,读取的CSV文件名
- delimiter:str,数据的分隔符
- usecols:tuple,执行加载数据文件中的哪些列
- unpack:bool,是否将加载的数据拆分为多个组,True表示拆,False表示不拆
- skipprows:int,跳过多少行,一般用于跳过前几行的描述性文字
- encoding:bytes,编码格式
import numpy as npb = np.arange(10).reshape(2, 5)print(b)np.savetxt('C:/test/b.txt', b)print(np.loadtxt('C:/b.txt'))# 将数组元素保存为浮点数,以逗号分隔np.savetxt('C:/test/c.txt', b, fmt = '%f', delimiter = ',')# load时叶鏊指定以逗号分隔,指定要读取的数据类型为浮点型np.loadtxt('C:/test/c.txt', dtype = 'f', delimiter = ',')

若有收获,就点个赞吧
0 人点赞
