1、算法基础
1、定义
简单的说,回溯算法就是一种结合递归的暴力搜索方法
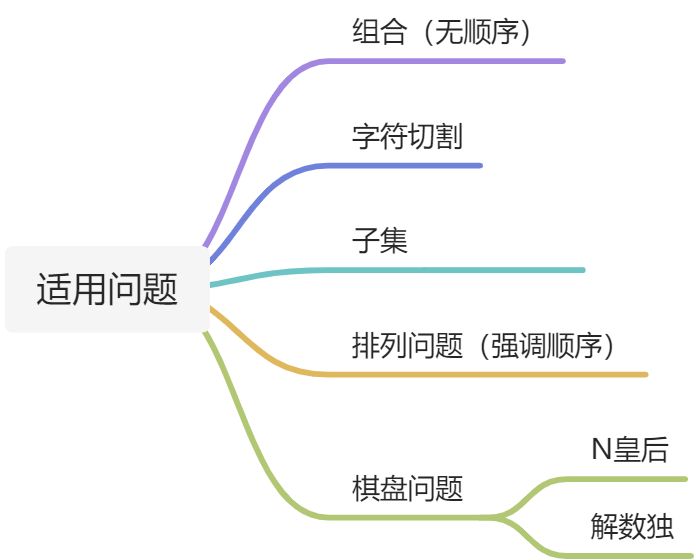
2、适用问题
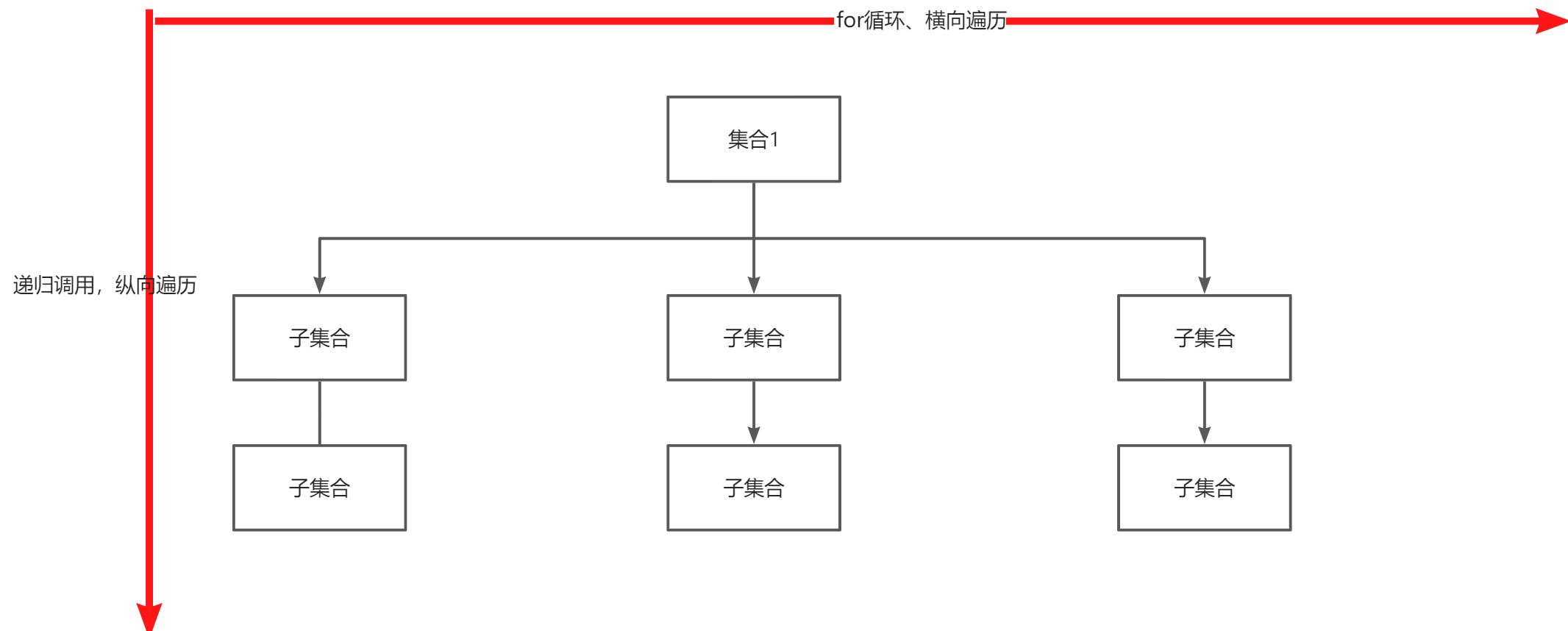
3、算法思想
伪代码:
回溯函数遍历过程
for(选择:本层集合中元素(苏中节点的数量就是集合的大小)){处理几点;backtracking(路径,选择列表); //递归回溯,撤销处理结果}
回溯算法模板框架 ```java void backtracking(参数){ if(终止条件){ 存放条件; return; }
for(选择:本层集合中元素(苏中节点的数量就是集合的大小)){ 处理几点; backtracking(路径,选择列表); //递归 回溯,撤销处理结果 } }
<a name="lzasm"></a># 2、组合问题> 首先画一个树形来模拟组合问题> 确定需要有一个递增的起始参数> 三部曲```javaArrayList<List<Integer>> res = new ArrayList<>();LinkedList<Integer> path = new LinkedList<>();public List<List<Integer>> combine(int n, int k) {//从 start=1 开始trackCombine(n,k,1);return res;}//确定参数:前两个和原函数一致,start表示for循环中递归调用的起始位置void trackCombine(int n, int k,int start) {//终止条件if (path.size() == k) {res.add(new ArrayList<>(path)); //此处path是全局变量,所以需要重新创建return;}//for循环for (int i = start; i <= n; i++){path.add(i); //数字加入数组trackCombine(n, k, ++start);path.removeLast(); //回溯,返回上一级}}
3、组和总和
套用模板
原始
class Solution {ArrayList<List<Integer>> resSum3 = new ArrayList<>();LinkedList<Integer> paths = new LinkedList();public List<List<Integer>> combinationSum3(int k, int n) {trackSum3(k, n, 1);return resSum3;}void trackSum3(int k, int n, int start) {int sum = 0;if (paths.size() == k) {for (int i = 0; i < paths.size(); i++) {sum += paths.get(i);}if (sum==n) resSum3.add(new ArrayList<>(paths));}for (int i = start; i < 10; i++) {paths.add(i);trackSum3(k, n, ++start);paths.removeLast();}}}
将求和带入到参数中
class Solution {ArrayList<List<Integer>> resSum3 = new ArrayList<>();LinkedList<Integer> paths = new LinkedList();public List<List<Integer>> combinationSum3(int k, int n) {trackSum3(k, n, 1,0);return resSum3;}void trackSum3(int k, int n, int start,int sum) {//将sum带入 时间复杂度会增高if (paths.size() == k) {if (sum==n) resSum3.add(new ArrayList<>(paths));}for (int i = start; i < 10; i++) {sum += i;paths.add(i);trackSum3(k, n, ++start, sum);sum -= i;paths.removeLast();}}}
剪枝
class Solution {ArrayList<List<Integer>> resSum3 = new ArrayList<>();LinkedList<Integer> paths = new LinkedList();public List<List<Integer>> combinationSum3(int k, int n) {trackSum3(k, n, 1,0);return resSum3;}void trackSum3(int k, int n, int start,int sum) {//初步剪枝,如果求和过程中大于目标则返回if (sum > n) {return;}if (paths.size() == k) {if (sum==n) resSum3.add(new ArrayList<>(paths));return;}//二次剪枝,如果构不成k个数,则返回for (int i = start; i <= 9 - (k - paths.size()) + 1; i++) {sum += i;paths.add(i);trackSum3(k, n, i+1, sum);sum -= i;paths.removeLast();}}}
4、电话号码的字母组和
class Solution {ArrayList<String> res = new ArrayList<>();public List<String> letterCombinations(String digits) {if (digits.isEmpty()) return res;String[] strMap = new String[]{ "","","abc","def","ghi","jkl","mno","pqrs","tuv", "wxyz"};trackLetter(digits, strMap, 0);return res;}StringBuffer sb = new StringBuffer();//此处的num不是记录开始位置,而是为了记录结果集中当前处理的下标void trackLetter(String digits, String[] strMap, int num) {if (num== digits.length()) {res.add(sb.toString());return;}String str = strMap[digits.charAt(num)-'0'];//遍历strfor (int i = 0; i < str.length(); i++) {sb.append(str.charAt(i));trackLetter(digits, strMap, num+1);sb.deleteCharAt(sb.length() - 1);}}}
5、组和总和||
此题的难点,主要是数字可以重复使用 对于此,有以下方式应对:
- 将数组排序,从小到大,保证数字递加时不会提前跳出循环
- 在回溯模板中,for循环增加 如果sum大于target时,跳出循环
- for 中的下标 i ,作为下次循环的起始值
ArrayList<List<Integer>> ressum = new ArrayList<>();LinkedList<Integer> path = new LinkedList<>();public List<List<Integer>> combinationSum(int[] candidates, int target) {if (candidates.length == 0) {return ressum;}//数组先行排序Arrays.sort(candidates);trackSum(candidates, target, 0,0);return ressum;}void trackSum(int[] cand, int target,int sum, int start) {System.out.println("sum:"+sum);if (sum == target){ressum.add(new ArrayList<>(path));return;}for (int i = start; i < cand.length; i++) {//由于这种相加的方式,是可以重复的添加,因此需要添加此条件跳出循环if (sum + cand[i] > target) break;System.out.println(i);path.add(cand[i]);//将i 作为下次开始,保证数字的重复使用trackSum(cand, target, sum + cand[i], i);path.removeLast();}}
6、分割回文串
- 回溯函数的参数:
- 字符串,索引值
- 回溯函数的逻辑:
- 如果子字符串为回文字符串,则将结果加到path中
- 如果不是回文,则跳过本次for循环
- 递归调用下一个索引起点(索引++)
- path移除末尾元素进行回溯
- 终止条件
- 如果索引值大于等于s 的长度,则返回
class Solution {ArrayList<List<String >> resP = new ArrayList<>();LinkedList<String> pathp = new LinkedList<>();public List<List<String>> partition(String s) {if (s.length()==0) return resP;tracePart(s, 0);return resP;}void tracePart(String s, int index) {// System.out.println("index: "+index);if (index >= s.length()) {resP.add(new ArrayList<>(pathp));return;}for (int i = index; i < s.length(); i++) {if (partFlag(s, index, i)) {//此处的i+1|只是为了截取字符串pathp.add(s.substring(index, i+1));} else {//当不是回文时,跳过本次循环continue;}//当遍历字符是回文时,在本次的基础上索引直接加1(不需要再减回来),遍历下一个字符tracePart(s,i+1);//路径变量进行回溯pathp.removeLast();}}boolean partFlag(String s, int start, int end) {for (int i = start, j = end; i < j; i++, j--) {if (s.charAt(i) != s.charAt(j)) {return false;}}return true;}}
7、复原IP地址
复原IP地址本质上还是数字组和问题,只不过不能改变数字的顺序,变的只是切割的位置,而且每一个 被分割的子字符串都要符合IP地址的条件。 按照以上思路,我们可以预先定义一个路径集和结果集。 在回溯模板中,参数设置为字符串和开始索引 终止条件就是路径集的大小为 4 ,并且如果开始索引的大小和s的长度一致时,将路径集通过join的方法加入到结果集中。 for循环中i = start,由于字串大小限制最大为3,所以可以增加条件 i<start+3 与 i<s.length() 如果子字符串不符合ip条件。直接跳出循环否则进行回溯 在isValid函数中,s.length()!=1 对单“0”的优化
class Solution {ArrayList<String> resIP = new ArrayList<>();LinkedList<String> pathIP = new LinkedList<>();public List<String> restoreIpAddresses(String s) {if (s.length() == 0) {return resIP;}trackIP(s, 0);return resIP;}void trackIP(String s, int start) {//如果存入的数字总共有四个if (pathIP.size() == 4) {//且构成的数字和原字符串一致if (start == s.length()) {//数组用join方法加标点resIP.add(String.join(".", pathIP));}return;}//因为IP是由三个数字组成,且不能超过字符串长度限制for (int i = start; i < start + 3 && i < s.length(); i++) {//System.out.println("start:" + start);// System.out.println("i:" + i);String sub = s.substring(start, i+1);//如果不符合要求,可以直接跳出递归if (!isValid(sub)) break;//将字串加入路径中pathIP.add(sub);trackIP(s, i + 1);//回溯pathIP.removeLast();}}boolean isValid(String s) {//s.length()!=1 对单“0”的优化if (s.length()!=1&&s.charAt(0)=='0' || Integer.valueOf(s)>255) {return false;}return true;}}
8、子集问题
与组和、排列不同,如果将这些都抽象成一棵树的话,组和和分割是收集树的叶子节点,而子集是收集树的所有节点。 又因为子集都是无序的,所以回溯时,for循环要从start开始,并且每一层递归的结果都需要收集。 终止条件是当前长度等于s.length
class Solution {ArrayList<List<Integer>> resSub = new ArrayList<>();LinkedList<Integer> pathSub = new LinkedList<>();public List<List<Integer>> subsets(int[] nums) {if (nums.length==0) return resSub;trackSub(nums, 0);return resSub;}void trackSub(int[] nums,int start) {resSub.add(new ArrayList<>(pathSub));if (start==nums.length) return;for (int i = start; i < nums.length; i++) {pathSub.add(nums[i]);trackSub(nums, i + 1);pathSub.removeLast();}}}
9、子集问题2
思想和 8 类似,还是收集回溯树的路径信息,主要有以下两点变动
- 有序数组无序且重复,因此需要先对数组进行排序
- 为了防止子集重复问题,在for中如果相邻两个数重复则直接跳过
ArrayList<List<Integer>> resSub = new ArrayList<>();LinkedList<Integer> pathSub = new LinkedList<>();void trackSub(int[] nums,int start) {resSub.add(new ArrayList<>(pathSub));if (start==nums.length) {System.out.println("changdu ");return;}for (int i = start; i < nums.length; i++) {//相邻两个数字重复则跳过if (i>start && nums[i]==nums[i-1]) continue;pathSub.add(nums[i]);trackSub(nums, i + 1);pathSub.removeLast();}}public List<List<Integer>> subsetsWithDup(int[] nums) {if (nums.length==0) return resSub;//将数组排序Arrays.sort(nums);trackSub(nums, 0);return resSub;}
10、递增子序列
与子集问题类似,都是收集抽象树上的路径,但是这个数组不是组和问题,所以不能直接排序,因此需要利用一个hash,将数字的使用情况收集起来
利用hashmap ```java class Solution { ArrayList
pathSeq = new LinkedList<>(); public List if (nums.length==0) return resSeq;trackSeq(nums,0);return resSeq;
}
void trackSeq(int[] nums, int start) {
if (pathSeq.size()>1) resSeq.add(new ArrayList<>(pathSeq));if (start== nums.length) return;//录本层元素是否重复使⽤,新的⼀层uset都会重新定义(清空)HashMap<Integer, Integer> map = new HashMap<>();for (int i = start; i < nums.length; i++) {if (!pathSeq.isEmpty()&&nums[i] < pathSeq.getLast()){ continue;}if (map.getOrDefault(nums[i],0)>0) continue;map.put(nums[i], map.getOrDefault(nums[i], 0) + 1);pathSeq.add(nums[i]);trackSeq(nums, i + 1);pathSeq.removeLast();}
}
}
- 利用hashset```javaclass Solution {//存放结果List<List<Integer>> result = new ArrayList<>();//暂存结果List<Integer> path = new ArrayList<>();public List<List<Integer>> findSubsequences(int[] nums) {backTrack(nums, 0);return result;}private void backTrack(int[] nums, int startIndex) {if(path.size() > 1){result.add(new ArrayList<>(path));//注意这⾥不要加return,因为要取树上的所有节点}HashSet<Integer> uset = new HashSet<>();//录本层元素是否重复使⽤,新的⼀层uset都会重新定义(清空)for (int i = startIndex; i < nums.length; i++) {//!path.isEmpty()&&nums[i]<path.get(path.size()-1)) : 保证子序列是递增的//!uset.add(nums[i]) :保证在同一层不会重复使用相同数字if ((!path.isEmpty()&&nums[i]<path.get(path.size()-1))||!uset.add(nums[i])) {continue;}path.add(nums[i]);backTrack(nums, i + 1);path.remove(path.size() - 1);}}}
11、全排列
全排可以想象成一种暴力排列的方式,因此不需要有前后顺序,所以for循环中的索引每次都从0 开始,参数也无需有索引开始的取值,但由于每次都从0 开始,所以需要判断每层的递归树中使用次数
辅助数组
class Solution {ArrayList<List<Integer>> resPer = new ArrayList<>();LinkedList<Integer> pathPer = new LinkedList<>();boolean[] visited;public List<List<Integer>> permute(int[] nums) {visited = new boolean[nums.length];tackPermute(nums);return resPer;}void tackPermute(int[] nums) {if (pathPer.size() == nums.length) {resPer.add(new ArrayList<>(pathPer));return;}for (int j = 0; j < nums.length; j++) {if (visited[j]) {continue;}visited[j] = true;pathPer.add(nums[j]);tackPermute(nums);pathPer.removeLast();visited[j] = false;}}}
直接判断path中是否含有这个数字
class Solution {ArrayList<List<Integer>> resPer = new ArrayList<>();LinkedList<Integer> pathPer = new LinkedList<>();public List<List<Integer>> permute(int[] nums) {tackPermute(nums);return resPer;}void tackPermute(int[] nums) {if (pathPer.size() == nums.length) {resPer.add(new ArrayList<>(pathPer));return;}for (int j = 0; j < nums.length; j++) {if (pathPer.contains(nums[j])) {continue;}pathPer.add(nums[j]);tackPermute(nums);pathPer.removeLast();}}}
12、全排列2
大致思路:由于题目中的数组可以重复,但是结果不能有重复的排列,主要思路和组合问题2 类似,都是先将数组排序,然后在for 循环中控制数字添加到路径中。 具体:经分析,此题应是树的层级去重,因此在前后判断的同时还需加一个控制位,来对递归层数相同的排列去重,否则直接横向、纵向都会被去重。具体参考下图:
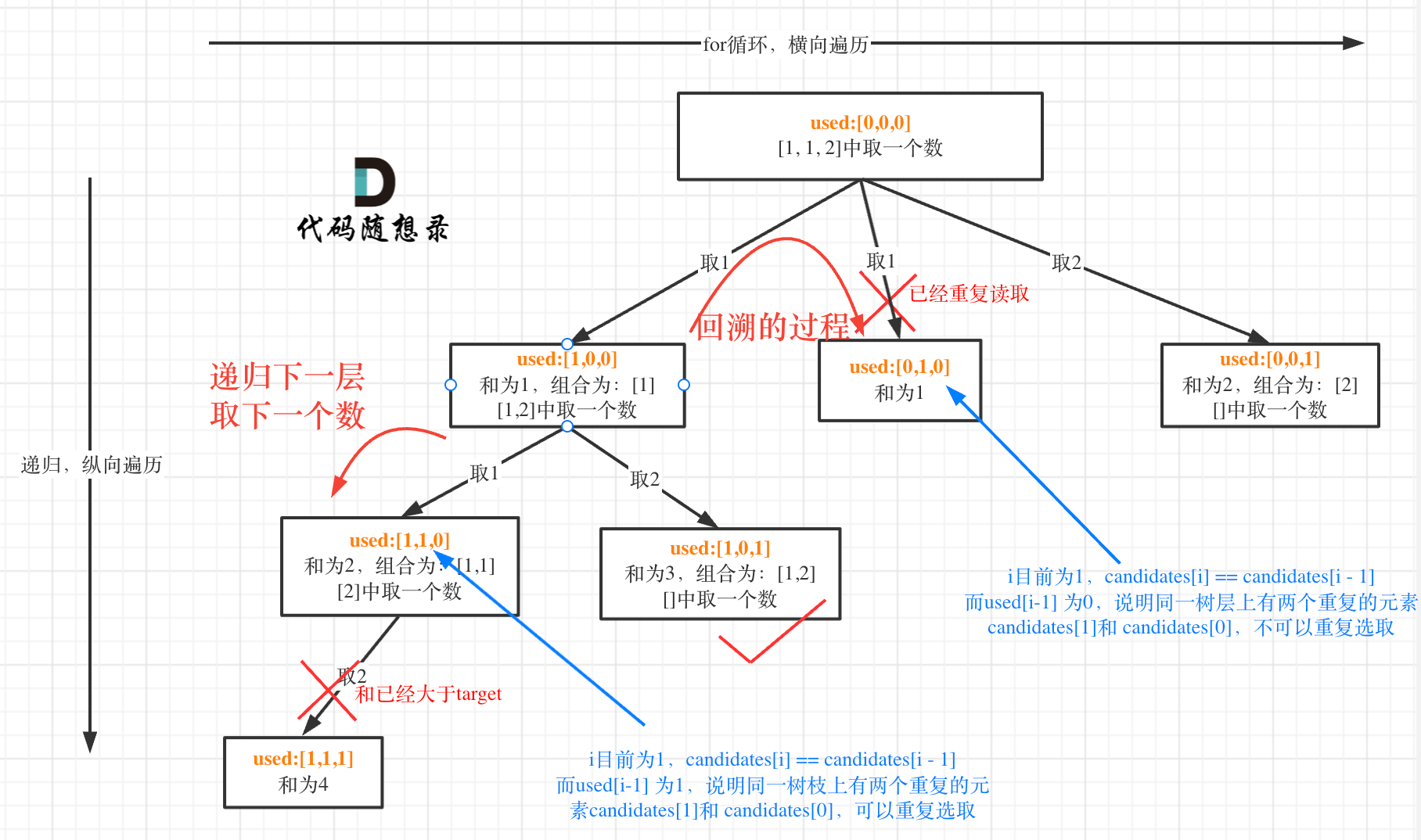
public class Day_02 {ArrayList<List<Integer>> resPer = new ArrayList<>();LinkedList<Integer> pathPer = new LinkedList<>();boolean[] uset;public List<List<Integer>> permuteUnique(int[] nums) {uset = new boolean[nums.length];Arrays.sort(nums);trackPer(nums);return resPer;}void trackPer(int[] nums) {if (nums.length == pathPer.size()) {resPer.add(new ArrayList<>(pathPer));}for (int i = 0; i < nums.length; i++) {if (uset[i]) continue;//通过uset[i - 1] 进行横向去重//当条件为true ,也能AC,但是由于这样是纵向去重的,所以复杂度会更高if (i != 0 && nums[i] == nums[i - 1] && uset[i - 1]==false) {continue;}//去重后对标记位赋值,可以视为加锁uset[i] = true;pathPer.add(nums[i]);trackPer(nums);pathPer.removeLast();uset[i] = false;}}}
【同层剪枝 VS 非同层剪枝】 相信你现在已经知道如下条件的作用了,很多人对最后一个子条件比较疑惑。即采用!visited[i - 1] 或 visited[i - 1],结果竟然是一样的,不光都是对的,而且输出也是一摸一样。
if(visited[i] || (i > 0 && nums[i - 1] == nums[i] && !visited[i - 1])) continue;
实际上如果你愿意付出点时间用纸笔跟踪一下递归过程,你会发现 !visited[i - 1] 实现了 「同层剪枝」,而 visited[i - 1] 实现「非同层剪枝」。 【同层剪枝】 当选取到nums[i],并满足 i > 0 && nums[i - 1] == nums[i] 时,若 !visited[i - 1] = true,说明以nums[i - 1]为某一层元素的选择已穷尽,以至于在回溯的时候置 visited[i - 1] = false)。于是后续会根据这个条件跳过同层相等元素。 【非同层剪枝】 最后一个子条件若采用 visited[i - 1],当选取到nums[i],并满足 i > 0 && nums[i - 1] == nums[i] 时,若 visited[i - 1] = true,表明当前是在nums[i - 1]的子树中选择nums[i],根据这个条件,在子树中遇到nums[i],总是不选取(continue),那么该子树总是无法提供有效排列(因为缺少nums[i]),于是对该子树的搜索都是无效的。之后回溯到nums[i - 1]所在层后,由于撤销为 visited[i - 1] = false,不再满足visited[i - 1] = true,于是不会跳过,可以正常选取到包含nums[i - 1]和nums[i]的排列。 通过上述说明,采用!visited[i - 1]的「同层剪枝」效率更高,因为「非同层剪枝」对nums[i - 1]的子树(存在nums[i] == nums[i - 1])的搜索是无效的。 另外我们也可以看到,无论哪一种,输出有效排列的顺序是一致的。二者的差别可理解为,非同层剪枝比同层剪枝多做了无效子树搜索动作。
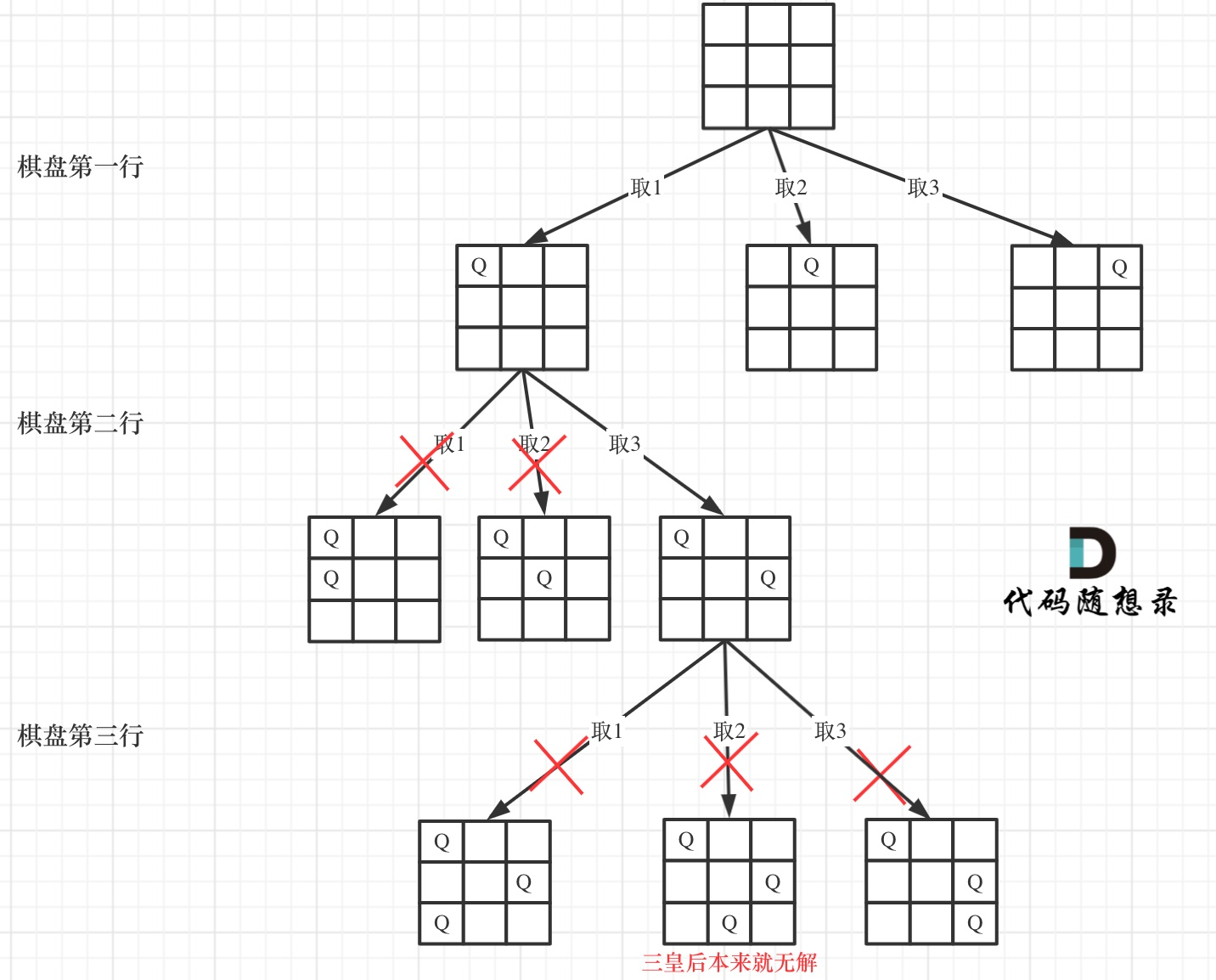
13、N皇后问题
N皇后主要难点在于这个是二维的问题,打破这个障碍,思路就变得通顺了,无非就是一行代表递归的层数,n+1代表递归层数+1,然后在访问到点时,校验这个点是否符合N皇后的规则
class Solution {List<List<String>> res = new ArrayList<>();public List<List<String>> solveNQueens(int n) {char[][] chessboard = new char[n][n];for (char[] c : chessboard) {Arrays.fill(c, '.');}backTrack(n, 0, chessboard);return res;}public void backTrack(int n, int row, char[][] chessboard) {if (row == n) {res.add(Array2List(chessboard));return;}for (int col = 0;col < n; ++col) {if (isValid (row, col, n, chessboard)) {chessboard[row][col] = 'Q';backTrack(n, row+1, chessboard);chessboard[row][col] = '.';}}}public List Array2List(char[][] chessboard) {List<String> list = new ArrayList<>();for (char[] c : chessboard) {list.add(String.copyValueOf(c));}return list;}public boolean isValid(int row, int col, int n, char[][] chessboard) {// 检查列for (int i=0; i<row; ++i) { // 相当于剪枝if (chessboard[i][col] == 'Q') {return false;}}// 检查45度对角线for (int i=row-1, j=col-1; i>=0 && j>=0; i--, j--) {if (chessboard[i][j] == 'Q') {return false;}}// 检查135度对角线for (int i=row-1, j=col+1; i>=0 && j<=n-1; i--, j++) {if (chessboard[i][j] == 'Q') {return false;}}return true;}}

若有收获,就点个赞吧
0 人点赞
