作者:张裕鹏
日期:2021-3-16
如何查看目标文件的文件信息
命令:file 目标文件
zhangyp@ubuntu:~/code/test_code/gcc demo$ file mainmain: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2, for GNU/Linux 2.6.32, BuildID[sha1]=6a566d5f12c39250d4654e3389a9bc075e9c8495, not stripped
目标文件组成
程序源代码编译后的机器指令经常被放在代码段(Code Section)里,代码段常见的名字有“.code”或“.text”;全局变量和局部静态变量数据经常放在数据段(Data Section),数据段的一般名字都叫“.data”。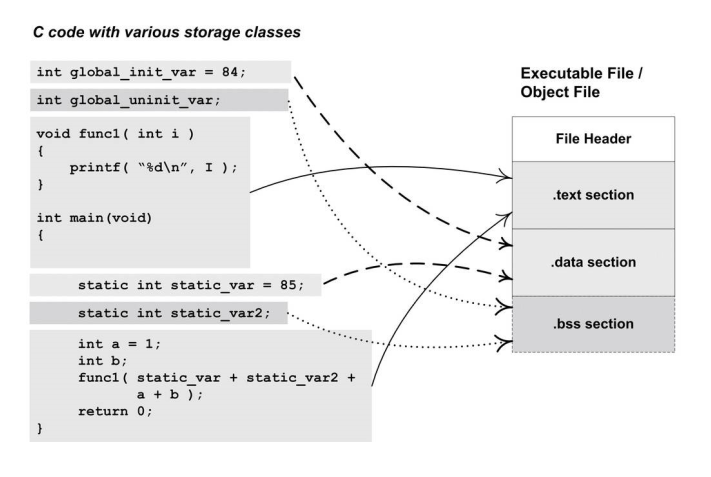
从图中可以看到,ELF文件的开头是一个“文件头”,它描述了整个文件的文件属性,包括文件是否可执行、是静态链接还是动态链接及入口地址(如果是可执行文件)、目标硬件、目标操作系统等信息,文件头还包括一个段表(Section Table),段表其实是一个描述文件中各个段的数组。段表描述了文件中各个段在文件中的偏移位置及段的属性等,从段表里面可以得到每个段的所有信息。文件头后面就是各个段的内容,比如代码段保存的就是程序的指令,数据段保存的就是程序的静态变量等。
一般C语言的编译后执行语句都编译成机器代码,保存在.text段;已初始化的全局变量和局部静态变量都保存在. data段;未初始化的全局变量和局部静态变量一般放在一个叫.“bss”的段里。我们知道未初始化的全局变量和局部静态变量默认值都为0,本来它们也可以被放在.data段的,但是因为它们都是0,所以为它们在.data段分配空间并且存放数据0是没有必要的。程序运行的时候它们的确是要占内存空间的,并且可执行文件必须记录所有未初始化的全局变量和局部静态变量的大小总和,记为.bss段。所以.bss段只是为未初始化的全局变量和局部静态变量预留位置而已,它并没有内容,所以它在文件中也不占据空间。
程序指令和数据为什么要分开?
一方面是当程序被装载后,数据和指令分别被映射到两个虚存区域。由于数据区域对于进程来说是可读写的,而指令区域对于进程来说是只读的,所以这两个虚存区域的权限可以被分别设置成可读写和只读。这样可以防止程序的指令被有意或无意地改写。
另外一方面是对于现代的CPU来说,它们有着极为强大的缓存(Cache)体系。由于缓存在现代的计算机中地位非常重要,所以程序必须尽量提高缓存的命中率。指令区和数据区的分离有利于提高程序的局部性。现代CPU的缓存一般都被设计成数据缓存和指令缓存分离,所以程序的指令和数据被分开存放对CPU的缓存命中率提高有好处。
当系统中运行着多个该程序的副本时,它们的指令都是一样的,所以内存中只须要保存一份该程序的指令部分。对于指令这种只读的区域来说是这样,对于其他的只读数据也一样。当然每个副本进程的数据区域是不一样的,它们是进程私有的。不要小看这个共享指令的概念,它在现代的操作系统里面占据了极为重要的地位,特别是在有动态链接的系统中,可以节省大量的内存。
目标文件内容
/** SimpleSection.c** Linux:* gcc -c SimpleSection.c** Windows:* cl SimpleSection.c /c /Za*/int printf( const char* format, ... );int global_init_var = 84;int global_uninit_var;void func1( int i ){printf( "%d\n", i );}int main(void){static int static_var = 85;static int static_var2;int a = 1;int b;func1( static_var + static_var2 + a + b );return a;}
命令:gcc -c SimpleSection.c 生成目标文件
objdump -h 目标文件:查看目标文件各段信息
size 目标文件:查看 ELF 文件的代码段、数据段和 BSS 段的长度
zhangyp@ubuntu:~/code/test_code/ld demo$ objdump -h SimpleSection.oSimpleSection.o: 文件格式 elf64-x86-64节:Idx Name Size VMA LMA File off Algn0 .text 00000055 0000000000000000 0000000000000000 00000040 2**0CONTENTS, ALLOC, LOAD, RELOC, READONLY, CODE1 .data 00000008 0000000000000000 0000000000000000 00000098 2**2CONTENTS, ALLOC, LOAD, DATA2 .bss 00000004 0000000000000000 0000000000000000 000000a0 2**2ALLOC3 .rodata 00000004 0000000000000000 0000000000000000 000000a0 2**0CONTENTS, ALLOC, LOAD, READONLY, DATA4 .comment 00000036 0000000000000000 0000000000000000 000000a4 2**0CONTENTS, READONLY5 .note.GNU-stack 00000000 0000000000000000 0000000000000000 000000da 2**0CONTENTS, READONLY6 .eh_frame 00000058 0000000000000000 0000000000000000 000000e0 2**3CONTENTS, ALLOC, LOAD, RELOC, READONLY, DATAzhangyp@ubuntu:~/code/test_code/ld demo$ size SimpleSection.otext data bss dec hex filename177 8 4 189 bd SimpleSection.o
.data段保存的是那些已经初始化了的全局静态变量和局部静态变量。前面的SimpleSection.c代码里面一共有两个这样的变量,分别是global_init_varabal与static_var。这两个变量每个4个字节,一共刚好8个字节,所以“.data”这个段的大小为8个字节。
“.rodata”段存放的是只读数据,一般是程序里面的只读变量(如const修饰的变量)和字符常量。单独设立“.rodata”段有很多好处,不光是在语义上支持了C++的const关键字,而且操作系统在加载的时候可以将“.rodata”段的属性映射成只读,这样对于这个段的任何修改操作都会作为非法操作处理,保证了程序的安全性。另外在某些嵌入式平台下,有些存储区域是采用只读存储器的,如ROM,这样将“.rodata”段放在该存储区域中就可以保证程序访问存储器的正确性。
.bss段存放的是未初始化的全局变量和局部静态变量,如上述代码中global_uninit_var和static_var2就是被存放在.bss段,其实更准确的说法是.bss段为它们预留了空间。但是我们可以看到该段的大小只有4个字节,这与global_uninit_var和static_var2的大小的8个字节不符。
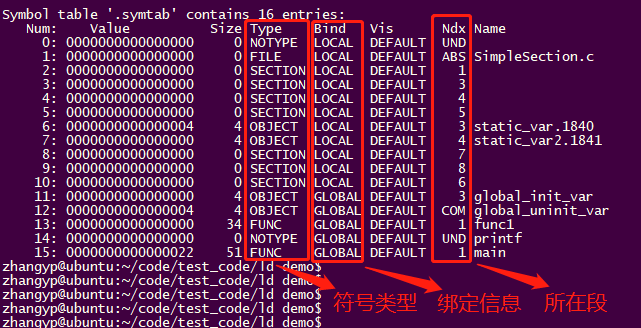
其实我们可以通过符号表(Symbol Table)看到,只有static_var2被存放在了.bss段,而global_uninit_var却没有被存放在任何段,只是一个未定义的“COMMON符号”。这其实是跟不同的语言与不同的编译器实现有关,有些编译器会将全局的未初始化变量存放在目标文件.bss段,有些则不存放,只是预留一个未定义的全局变量符号,等到最终链接成可执行文件的时候再在.bss段分配空间。
zhangyp@ubuntu:~/code/test_code/ld demo$ objdump -t SimpleSection.oSimpleSection.o: 文件格式 elf64-x86-64SYMBOL TABLE:0000000000000000 l df *ABS* 0000000000000000 SimpleSection.c0000000000000000 l d .text 0000000000000000 .text0000000000000000 l d .data 0000000000000000 .data0000000000000000 l d .bss 0000000000000000 .bss0000000000000000 l d .rodata 0000000000000000 .rodata0000000000000004 l O .data 0000000000000004 static_var.18400000000000000000 l O .bss 0000000000000004 static_var2.18410000000000000000 l d .note.GNU-stack 0000000000000000 .note.GNU-stack0000000000000000 l d .eh_frame 0000000000000000 .eh_frame0000000000000000 l d .comment 0000000000000000 .comment0000000000000000 g O .data 0000000000000004 global_init_var0000000000000004 O *COM* 0000000000000004 global_uninit_var0000000000000000 g F .text 0000000000000022 func10000000000000000 *UND* 0000000000000000 printf0000000000000022 g F .text 0000000000000033 main
其他端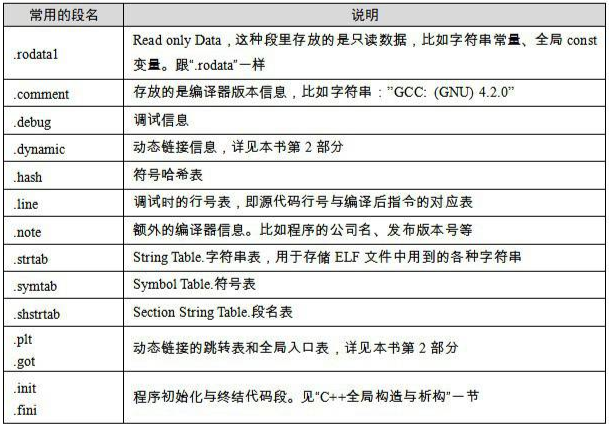
内存结构图
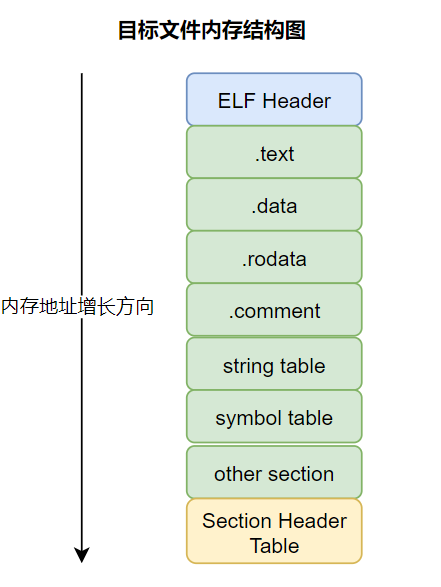
常见命令
objdump 命令
| 命令 | 解释 |
|---|---|
| objdump -h 目标文件 | 打印 ELF 文件各个段的基本信息 |
| objdump -x 目标文件 | 打印 ELF 文件各个段的大部分信息 |
| objdump -s 目标文件 | 以 16 进制打印各个段的信息 |
| objdump -d 目标文件 | 打印指令的反汇编 |
| objdump -r 目标文件 | 查看目标文件的重定位表 |
readelf 命令
| 命令 | 解释 |
|---|---|
| readelf -h 目标文件 | 查看 “文件头”内容 |
| readelf -S 目标文件 | 查看“段表”内容 |
| readelf -s 目标文件 | 查看“符号表”内容 |
符号
在链接中,我们将函数和变量统称为符号(Symbol),函数名或变量名就是符号名(Symbol Name)。
链接过程中很关键的一部分就是符号的管理,每一个目标文件都会有一个相应的符号表(Symbol Table),这个表里面记录了目标文件中所用到的所有符号。每个定义的符号有一个对应的值,叫做符号值(Symbol Value)对于变量和函数来说,符号值就是它们的地址。
ELF 文件中的符号表往往是文件中的一个段,段名一般叫“.symtab”。
符号的常见分类
- 定义在本目标文件的全局符号,可以被其他目标文件引用。
- 在本目标文件中引用的全局符号,却没有定义在本目标文件,这一般叫做外部符号(External Symbol)。
- 局部符号,这类符号只在编译单元内部可见。
- 行号信息,即目标文件指令与源代码中代码行的对应关系,它也是可选的。
特殊符号
当我们使用ld作为链接器来链接生产可执行文件时,它会为我们定义很多特殊的符号,这些符号并没有在你的程序中定义,但是你可以直接声明并且引用它,我们称之为特殊符号。其实这些符号是被定义在ld链接器的链接脚本中的,目前你只须认为这些符号是特殊的,你无须定义它们,但可以声明它们并且使用。链接器会在将程序最终链接成可执行文件的时候将其解析成正确的值,注意,只有使用ld链接生产最终可执行文件的时候这些符号才会存在。
几个很具有代表性的特殊符号如下。
- __executable_start,该符号为程序起始地址,注意,不是入口地址,是程序的最开始的地址。
- __etext或_etext或etext,该符号为代码段结束地址,即代码段最末尾的地址。
- _edata或edata,该符号为数据段结束地址,即数据段最末尾的地址。
- _end或end,该符号为程序结束地址。
符号修饰与函数签名
符号修饰:为了解决多个模块中函数或者变量同名的问题,所以在编译的时候会根据函数或者变量所在的命名空间、类(如果有的话)来修改编译后的符号名称,而不是和原符号相同。
函数签名:包含了一个函数的信息,包括函数名、它的参数类型、它所在的类和名称空间及其他信息。函数签名用于识别不同的函数,就像签名用于识别不同的人一样,函数的名字只是函数签名的一部分。
强符号与弱符号
强符号:我们经常在编程中碰到一种情况叫符号重复定义。多个目标文件中含有相同名字全局符号的定义,那么这些目标文件链接的时候将会出现符号重复定义的错误,这种符号的定义可以被称为强符号。
弱符号:对于C/C++语言来说,编译器默认函数和初始化了的全局变量为强符号,未初始化的全局变量为弱符号。我们也可以通过GCC的“attribute((weak))”来定义任何一个强符号为弱符号。注意,强符号和弱符号都是针对定义来说的,不是针对符号的引用。
针对强弱符号的概念,链接器就会按如下规则处理与选择被多次定义的全局符号:
- 规则1:不允许强符号被多次定义(即不同的目标文件中不能有同名的强符号);如果有多个强符号定义,则链接器报符号重复定义错误。
- 规则2:如果一个符号在某个目标文件中是强符号,在其他文件中都是弱符号,那么选择强符号。
- 规则3:如果一个符号在所有目标文件中都是弱符号,那么选择其中占用空间最大的一个。比如目标文件A定义全局变量global为int型,占4个字节;目标文件B定义global为double型,占8个字节,那么目标文件A和B链接后,符号global占8个字节(尽量不要使用多个不同类型的弱符号,否则容易导致很难发现的程序错误)。
强引用与弱引用
目前我们所看到的对外部目标文件的符号引用在目标文件被最终链接成可执行文件时,它们须要被正确决议,如果没有找到该符号的定义,链接器就会报符号未定义错误,这种被称为强引用(Strong Reference)。与之相对应还有一种弱引用(Weak Reference),在处理弱引用时,如果该符号有定义,则链接器将该符号的引用决议;如果该符号未被定义,则链接器对于该引用不报错。链接器处理强引用和弱引用的过程几乎一样,只是对于未定义的弱引用,链接器不认为它是一个错误。一般对于未定义的弱引用,链接器默认其为0,或者是一个特殊的值,以便于程序代码能够识别。
在GCC中,我们可以通过使用“attribute((weakref))”这个扩展关键字来声明对一个外部函数的引用为弱引用,比如下面这段代码:
__attribute__ ((weakref)) void foo();int main(){foo();}
我们可以将它编译成一个可执行文件,GCC并不会报链接错误。但是当我们运行这个可执行文件时,会发生运行错误。因为当main函数试图调用foo函数时,foo函数的地址为0,于是发生了非法地址访问的错误。
调试信息
标文件里面还有可能保存的是调试信息。几乎所有现代的编译器都支持源代码级别的调试,比如我们可以在函数里面设置断点,可以监视变量变化,可以单步行进等,前提是编译器必须提前将源代码与目标代码之间的关系等,比如目标代码中的地址对应源代码中的哪一行、函数和变量的类型、结构体的定义、字符串保存到目标文件里面。如果我们在GCC编译时加上“-g”参数,编译器就会在产生的目标文件里面加上调试信息,我们通过readelf等工具可以看到,目标文件里多了很多“debug”相关的段:
zhangyp@ubuntu:~/code/test_code/ld demo$ readelf -S SimpleSection.o|grep debug[ 6] .debug_info PROGBITS 0000000000000000 000000a4[ 7] .rela.debug_info RELA 0000000000000000 000006d0[ 8] .debug_abbrev PROGBITS 0000000000000000 00000191[ 9] .debug_aranges PROGBITS 0000000000000000 00000224[10] .rela.debug_arang RELA 0000000000000000 00000880[11] .debug_line PROGBITS 0000000000000000 00000254[12] .rela.debug_line RELA 0000000000000000 000008b0[13] .debug_str PROGBITS 0000000000000000 000002a0
试信息在目标文件和可执行文件中占用很大的空间,往往比程序的代码和数据本身大好几倍,所以当我们开发完程序并要将它发布的时候,须要把这些对于用户没有用的调试信息去掉,以节省大量的空间。在Linux下,我们可以使用“strip”命令来去掉ELF文件中的调试信息:
$strip 目标文件
总结
无论是可执行文件、目标文件或库,它们实际上都是一样基于段的文件或是这种文件的集合。程序的源代码经过编译以后,按照代码和数据分别存放到相应的段中,编译器(汇编器)还会将一些辅助性的信息,诸如符号、重定位信息等也按照表的方式存放到目标文件中,而通常情况下,一个表往往就是一个段。

若有收获,就点个赞吧
0 人点赞
