 __
__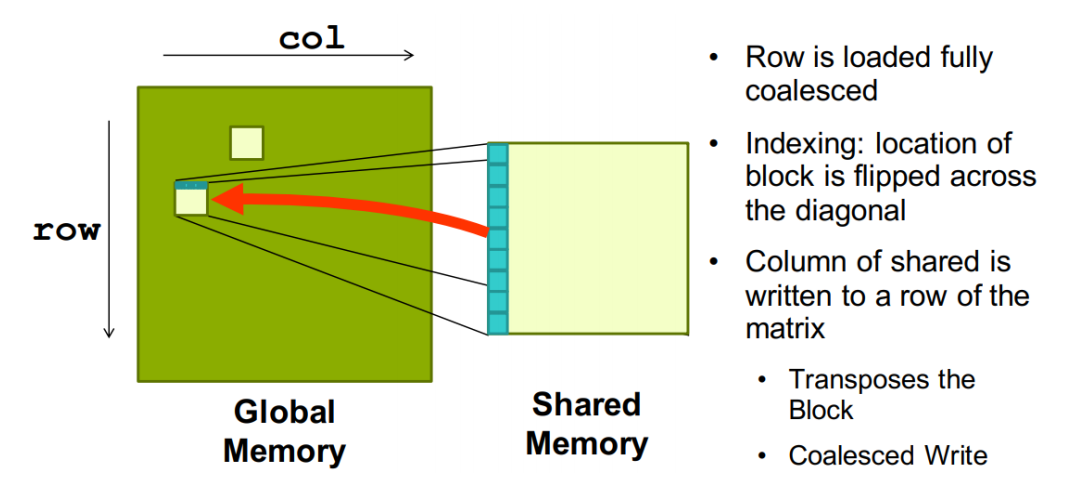
row is loaded coalesced
location of block is filpped
Conflicts in share memory
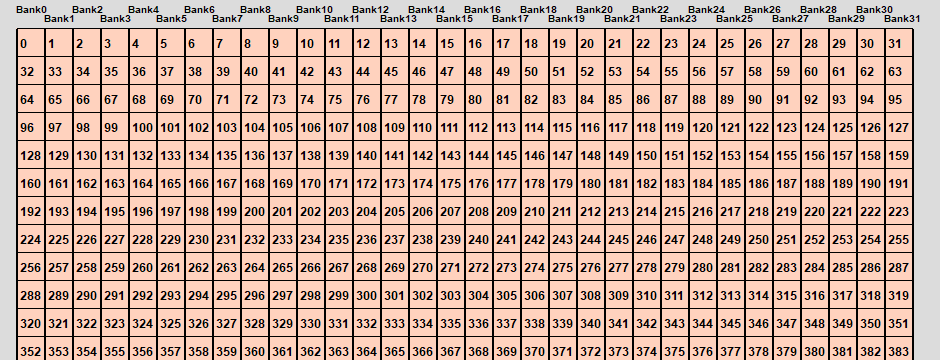
Shared memory is setup as 32 bank
- If we divide the shared memory into 4 byte-long elements,
element i lies in bank i % 32.
Mapping addresses in shared memory to banks
shared DTYPE tile[TILE_DIM][TILE_DIM];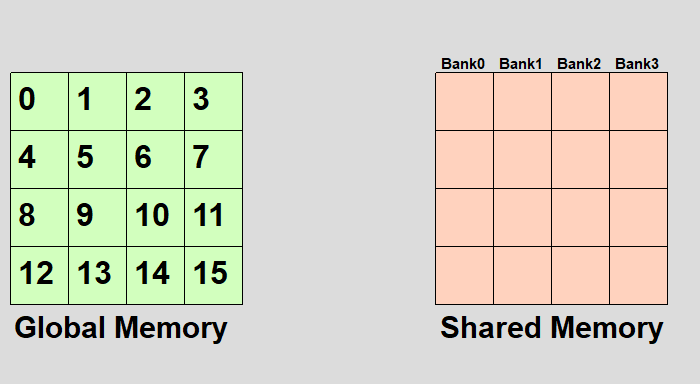
Shared memory is setup as 32 banks
- A bank conflict occurs when ≥2 threads in a warp access different elements in the same bank.
Bank conflicts cause serial memory accesses rather than parallel.
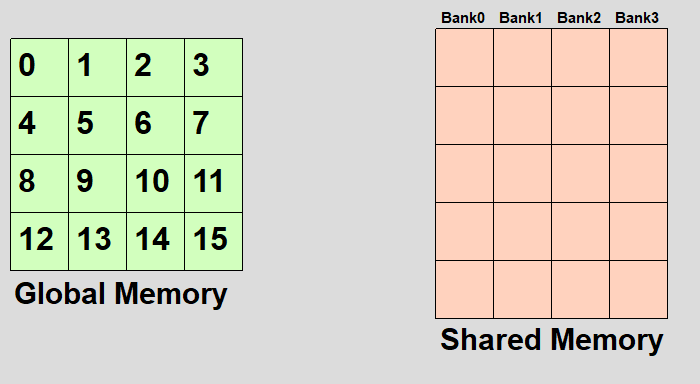
AVOIDING BANK CONFLICTS
CODE
__global__ void kernel_transpose_per_element_tiled_no_bank_conflicts(DTYPE *input, DTYPE *output, int num_rows, int num_cols){__shared__ float data[BLOCK_SIZE][BLOCK_SIZE+1];int input_col_id = blockIdx.x*blockDim.x+threadIdx.x;int input_row_id = blockIdx.y*blockDim.y+threadIdx.y;int block_x = blockIdx.x*blockDim.x;int block_y = blockIdx.y*blockDim.y;if(input_col_id<num_cols&&input_row_id<num_rows&&threadIdx.x<BLOCK_SIZE)data[threadIdx.y][threadIdx.x]=input[input_row_id*num_cols+input_col_id];__syncthreads();int output_col_id = block_y+threadIdx.x;int output_row_id =block_x+threadIdx.y;if(output_col_id<num_rows&&output_row_id<num_cols)output[output_row_id*num_rows+output_col_id]=data[threadIdx.x][threadIdx.y];}
main 函数调用
```cpp
include
include”error_check.h”
include”gpu_timer.h”
define DTYPE float
define DTYPE_OUTPUT_FORMAT “%f “
define H 1024
define W 977
define BLOCK_SIZE 32
int main() { int numBytes = HWsizeof(DTYPE); DTYPE data_input = (DTYPE )malloc(numBytes); DTYPE data_output = (DTYPE )malloc(numBytes); DTYPE data_result = (DTYPE )malloc(numBytes);
init_data(data_input, H*W);transpose_CPU(data_input, data_result, H, W);DTYPE *d_in, *d_out;cudaMalloc((void **)&d_in, numBytes);cudaMalloc((void **)&d_out, numBytes);cudaMemcpy(d_in, data_input, numBytes, cudaMemcpyHostToDevice);GpuTimer timer;/** 1. matrix transpose serial **/timer.Start();kernel_transpose_serial<<<1, 1>>>(d_in, d_out, H, W);timer.Stop();cudaMemcpy(data_output, d_out, numBytes, cudaMemcpyDeviceToHost);printf("\nTime cost (serial):%g ms. Veryifying results...%s\n",timer.Elapsed(), compare_matrices(data_output, data_result, H, W)?"Passed":"Failed");memset(data_output, 0, numBytes);cudaMemset(d_out, 0, numBytes);/** 2. matrix transpose per row **/timer.Start();kernel_transpose_per_row<<<1, W>>>(d_in, d_out, H, W);timer.Stop();cudaMemcpy(data_output, d_out, numBytes, cudaMemcpyDeviceToHost);printf("\nTime cost (per row):%g ms. Veryifying results...%s\n",timer.Elapsed(), compare_matrices(data_output, data_result, H, W)?"Passed":"Failed");memset(data_output, 0, numBytes);cudaMemset(d_out, 0, numBytes);/** 3. matrix transpose per element **/timer.Start();dim3 blocks((W-1)/BLOCK_SIZE+1, (H-1)/BLOCK_SIZE+1);dim3 threads(BLOCK_SIZE, BLOCK_SIZE);kernel_transpose_per_element<<<blocks, threads>>>(d_in, d_out, H, W);timer.Stop();cudaMemcpy(data_output, d_out, numBytes, cudaMemcpyDeviceToHost);printf("\nTime cost (per element):%g ms. Veryifying results...%s\n",timer.Elapsed(), compare_matrices(data_output, data_result, H, W)?"Passed":"Failed");memset(data_output, 0, numBytes);cudaMemset(d_out, 0, numBytes);/** 4. matrix transpose tiled with shared memory **/timer.Start();kernel_transpose_per_element_tiled<<<blocks, threads>>>(d_in, d_out, H, W);timer.Stop();cudaMemcpy(data_output, d_out, numBytes, cudaMemcpyDeviceToHost);printf("\nTime cost (tiled with shared memory):%g ms. Veryifying results...%s\n",timer.Elapsed(), compare_matrices(data_output, data_result, H, W)?"Passed":"Failed");memset(data_output, 0, numBytes);cudaMemset(d_out, 0, numBytes);/** 5. matrix transpose tiled without bank conflicts **/timer.Start();kernel_transpose_per_element_tiled_no_bank_conflicts<<<blocks, threads>>>(d_in, d_out, H, W);timer.Stop();cudaMemcpy(data_output, d_out, numBytes, cudaMemcpyDeviceToHost);printf("\nTime cost (tiled without bank conflicts):%g ms. Veryifying results...%s\n",timer.Elapsed(), compare_matrices(data_output, data_result, H, W)?"Passed":"Failed");free(data_input);free(data_output);free(data_result);cudaFree(d_in);cudaFree(d_out);return 0;
}
<a name="k6X9R"></a>
### matrix helper
```cpp
void init_data(DTYPE *arr, int n)
{
for(int i=0; i<n; i++){
arr[i] = (DTYPE)(i+1);
}
}
int compare_matrices(DTYPE *input, DTYPE *ref, int num_rows, int num_cols)
{
for(int row_idx=0; row_idx<num_rows; row_idx++)
{
for(int col_idx=0; col_idx<num_cols; col_idx++)
{
if(abs(ref[row_idx*num_cols+col_idx]-input[row_idx*num_cols+col_idx])>1e-3)
{
printf("Error:%f at (%d, %d)\n", abs(ref[row_idx*num_cols+col_idx]-input[row_idx*num_cols+col_idx]), row_idx, col_idx);
return 0;
}
}
}
return 1;
}

若有收获,就点个赞吧
0 人点赞
