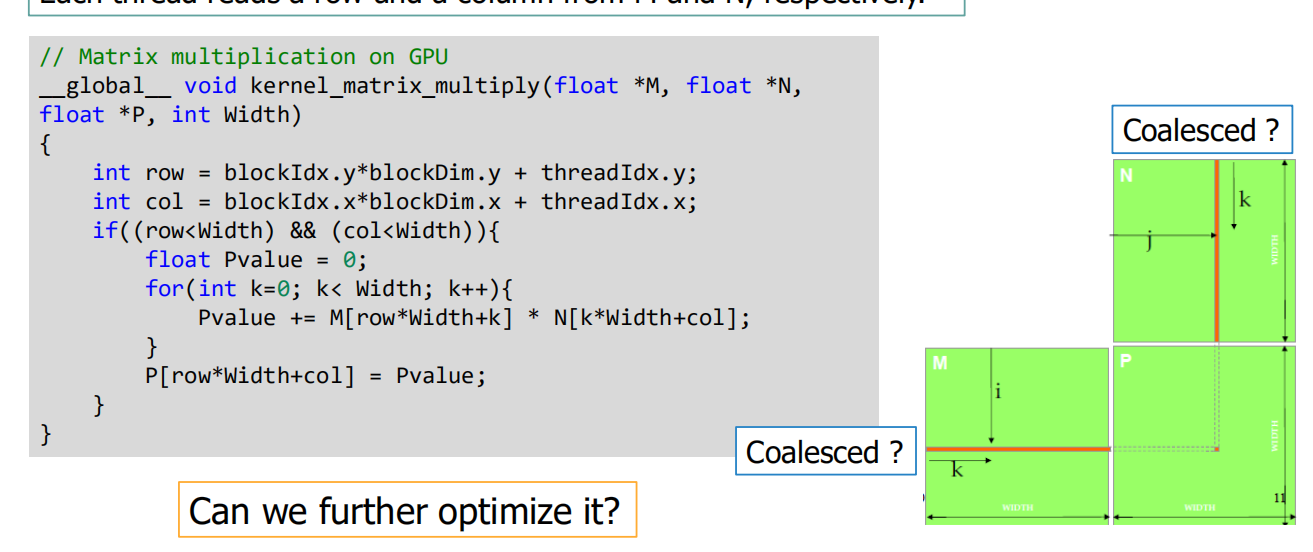
Simple Matrix Multiplication
Tiled matrix Multiplication
__global__ void kernel_matrix_multiply(float *M, float *N, float *P, int M_rows, int M_cols, int N_rows, int N_cols){__shared__ float Mds[BLOCK_SIZE][BLOCK_SIZE];__shared__ float Nds[BLOCK_SIZE][BLOCK_SIZE];int bx= blockIdx.x,by=blockIdx.y;int tx =threadIdx.x,ty=threadIdx.y;int row =by*BLOCK_SIZE+ty;int col=bx*BLOCK_SIZE+tx;float Pvalue=0;for(int ph=0;ph<(M_cols-1)/BLOCK_SIZE+1;ph++){if(row<M_rows &&ph*BLOCK_SIZE+tx<M_cols)Mds[ty][tx]=M[row*M_cols+ph*BLOCK_SIZE+tx];if((ph*BLOCK_SIZE+ty)<N_rows &&col<N_cols)Nds[ty][tx]=N[(ph*BLOCK_SIZE+ty)*N_cols+col];__syncthreads();for(int k=0;k<BLOCK_SIZE;k++){Pvalue+=Mds[ty][k]*Nds[k][tx];}__syncthreads();}if(row<M_rows&&col<N_cols){P[row*N_cols+col]=Pvalue;}}
这里Mds,Nds都是coalsec 访问的
linr 15 为什么需要syncthreads():
保证一个block中的所有thread把M,N中的分块全部放进了share memory 中,每个thread才能开始计算
line 20 为什么需要syncthreads():
保证所有thread 使用完成了share memory 所有值,才能开始下一次搬运。如果没有,会出现一个thread计算完成后,迭代下一次for循环搬运一个分块,而block中其他thread还在用前一个分块的值,导致结果出错。

若有收获,就点个赞吧
0 人点赞
