- 1.二分查找的基本实现:
- Upper_ceil:若target 有多个,则返回索引值最大的那个;若不存在,则返回大于target 的第一个元素,即 upper()的结果
- Upper_floor: 若target 有多个,返回索引值最大的那个;若不存在,则返回小于target的最后一个元素,即lower()的结果
- lower:查找小于 target 的最后一个元素
- lower_floor:若target 有多个,则返回索引值最小的那个;若不存在,则返回小于target的最后一个元素,即lower()
- lower_ceil: 若target 有多个,则返回索引值最小的那个;若不存在,则返回upper(),即大于target的第一个元素
- 3.总结:
- 4.时间复杂度:
二分查找法也是使用分治的思想,来查找元素,并没有对数组进行排序。且二分查找需要已排序的数组。
https://www.cnblogs.com/taoyuann/p/15463145.html
1.二分查找的基本实现:
- 若不存在元素,返回 - 1 , 否则返回元素的位置(最先出现的位置)
```java
// 递归实现,每次都将查找范围缩小 1/2
public int search(E[] arr, E target, int l, int r){
int mid = l + (r - l) / 2;
if(l > r) return -1;
if(arr[mid].compareTo(target) == 0){
}else if(arr[mid].compareTo(target) > 0){return mid;
}else{search(arr, target, l, mid - 1);
} }search(arr, target, mid + 1, r);
// 非递归实现,每次都将查找范围缩小 1/2 public int searchR(E[] arr, E target){ int l = 0, r = arr.length - 1; while(l > r){ int mid = l + (r - l) / 2; if(arr[mid].compareTo(target) == 0){ return mid; }else if(arr[mid].compareTo(target) > 0){ r = mid - 1; }else{ l = mid + 1; } } return -1; }
<a name="h4Z0d"></a>## 2.二分查找的变种- **ceil : 向上取整**- **floor : 向下取整**<a name="WTJac"></a>### Upper: 查找大于 target 的第一个元素```java// 如果没有大于 target 的元素, 则此时会返回 arr.length ,即没有大于target 的值public int upper(E[] arr, E target){int l = 0, r = arr.length;while(l > r){int mid = l + (r - l) / 2;if(arr[mid].compaerTo(target) <= 0){l = mid + 1 ;}else{r = mid;}}return l;}
Upper_ceil:若target 有多个,则返回索引值最大的那个;若不存在,则返回大于target 的第一个元素,即 upper()的结果
public int upper_ceil(E[] arr, E target){
int res = upper(arr, target);
if(arr[res - 1].compareTo(target) == 0){
return res - 1;
}
return res;
}
Upper_floor: 若target 有多个,返回索引值最大的那个;若不存在,则返回小于target的最后一个元素,即lower()的结果
public int upper_floor(E[] arr, E target){
int res = lower(arr, target);
if(arr[res + 1].compareTo(target) == 0){
return res + 1;
}
return res;
}
lower:查找小于 target 的最后一个元素
// 注意一个问题,要防止死循环
// 所所有元素均大于 target, 返回 -1;
public int lower(E[] arr, E target){
int l = - 1, r = arr.length - 1;
while(l < r){
int mid = l + (r - l + 1) / 2;
if(arr[mid].compareTo(target) >= 0){
r = mid - 1;
}else{
l = mid;
}
}
return l;
}
lower_floor:若target 有多个,则返回索引值最小的那个;若不存在,则返回小于target的最后一个元素,即lower()
public int lower_floor(E[] arr, E target){
int res = lower(arr, target);
if(arr[res + 1].compareTo(target) == 0){
return res + 1;
}
return res;
}
lower_ceil: 若target 有多个,则返回索引值最小的那个;若不存在,则返回upper(),即大于target的第一个元素
public int lower_ceil(E[] arr, E target){
int res = lower(arr, target);
if(arr[res - 1].compareTo(target) == 0){
return res - 1;
}
return res;
}
3.总结:
1.upper:获取大于target的第一个元素
2.lower:获取小于target的第一个元素
3.ceil:当存在target 取 索引的最大值
4.floor:当存在 target 时取最小值
4.时间复杂度:
对于二分搜索树:每次都将整个数组分为两部分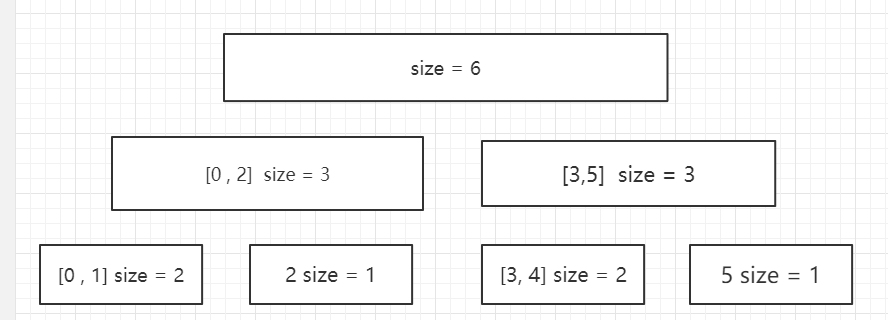
最坏情况下:需要遍历 h 层, 一层需要一次操作,时间复杂度为:
o( h ) = O(log n); 即时间复杂度为O(log n

若有收获,就点个赞吧
0 人点赞
