常见面试题
- List是否可以存null,Set是否可以存null,List和Map的区别?
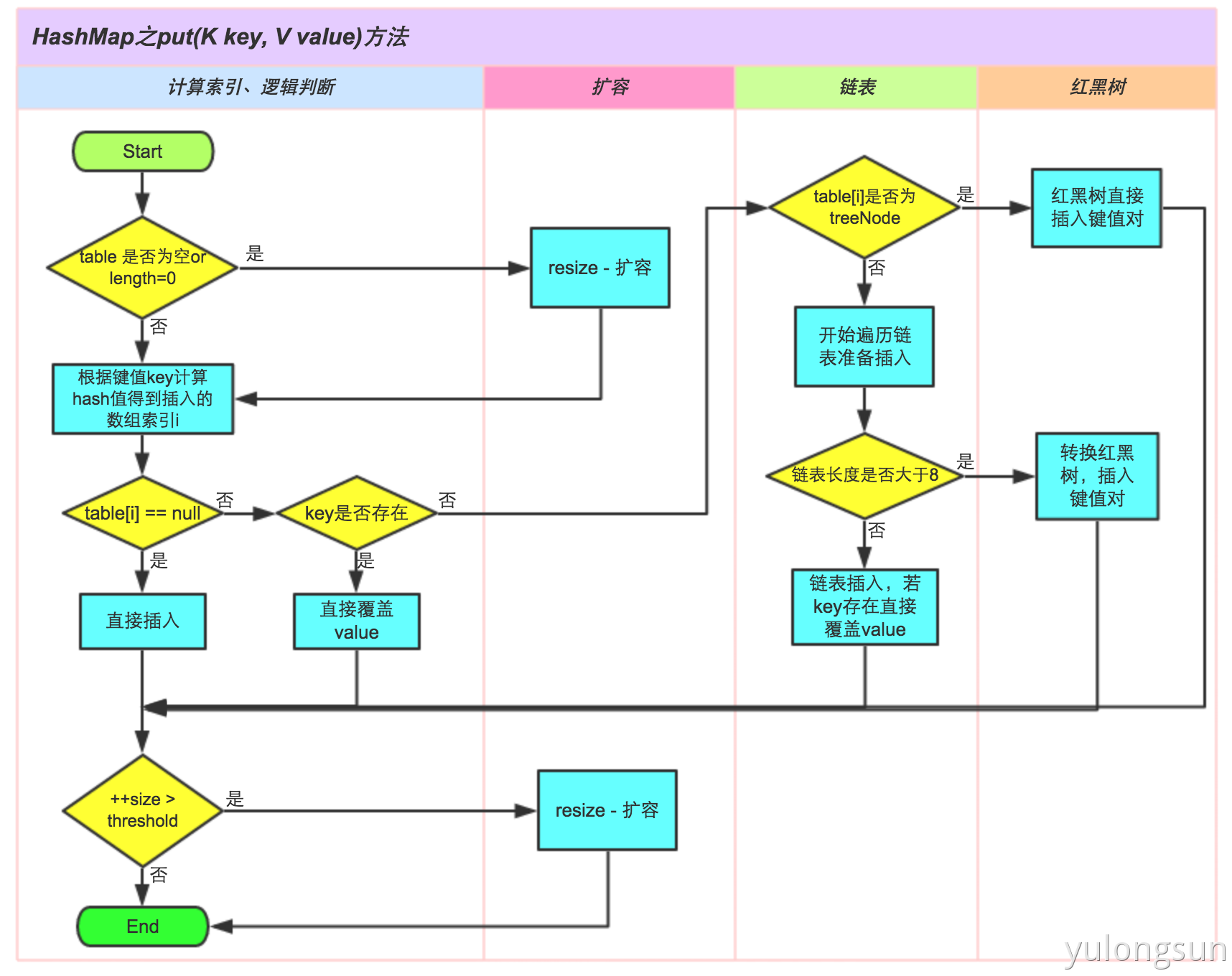
- 说一说 HashMap原理、put()原理、get()原理、扩容原理?
- 进阶:默认初始长度是16,并且每次自动扩展或者手动初始化,必须是2的幂次,为什么?
- 针对 HashMap 中某个 Entry 链太长,查找的时间复杂度可能达到 O(n),怎么优化?
- 高并发下的HashMap:你了解重新调整HashMap大小存在什么问题吗?
- HashMap遇到Hash碰撞的时候,除了拉链法解决,还是什么其他的方法吗?
- JDK1.7和JDK1.8的HashMap有什么区别?
- 重写HashCode()一定要重写Equals()吗?
- 为什么String, Interger这样的类适合作为键?
- 为什么HashMap选择红黑树而不选择AVL树?MySQL选择B+树而不选择红黑树?
- ConcurrentHashMap(CHM)
- CHM如何求size? 如何保证求size过程中插入了数据,最终结果的正确性?
- CHM的数据结构? — JDK1.7 Segment数组+HashEntry数组
- CHM是先插入再扩容还是先扩容再插入?HashMap呢?
详解
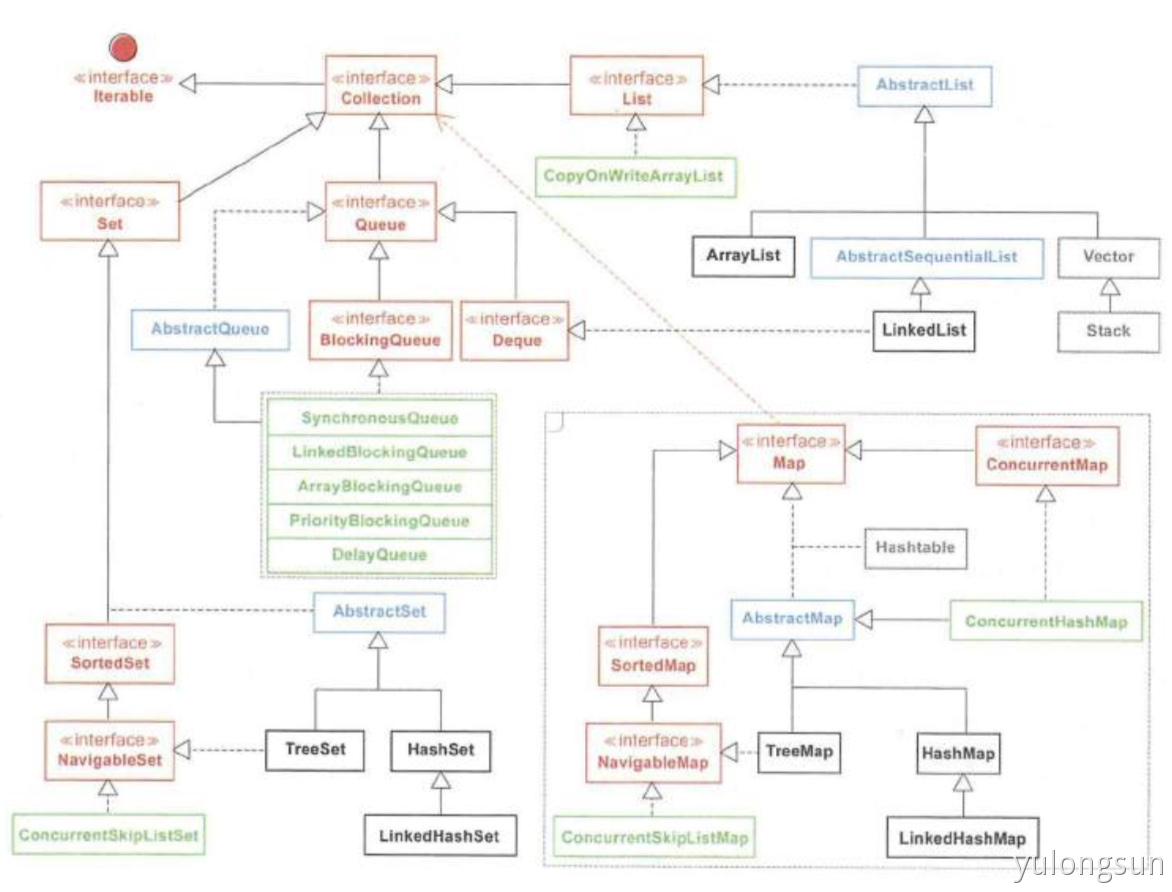
1. List
ArrayList 内部实现用数组,快速随机访问,但是插入删除慢,因为要移动其他元素;
LinkedList 内部实现用双向链表,插入删除快,但是随机访问慢。优点在于:将零散的内存关联起来,利用率高。
1.1 面试题:List是否可以存null,Set是否可以存null,List和Map的区别?
a. List中的元素:有序、可重复、可为NULL;
b. Set中的元素:无序、不可重复、只有一个NULL;
c. Map中的元素:无序、Key不重,Value可重、可一个NULL Key,多个NULL值;
2. Queue
3. Set
不允许出现重复元素。常用的是HashSet、TreeSet、LinkedHashSet。
4. Map
常用的是HashMap、ConcurrentHashMap、TreeMap。
4.1 HashMap原理
- 底层实现使用的是:数组+链表的数据结构。
- 面试题:默认初始长度是16,并且每次自动扩展或者手动初始化,必须是2的幂次,为什么?
- 为了服务key到index的Hash算法。
- Hash算法最终得到的index结果,完全取决于Key的Hashcode值的最后几位。
- 面试题:默认初始长度是16,并且每次自动扩展或者手动初始化,必须是2的幂次,为什么?
- put原理:(扩容机制)
- 根据key获取相应的Hash值:int hash = hash(key.hash.hashcode())
- 根据Hash值和数组长度确定引用位置:int index = hashCode(Key)&(length-1)。
- 经典面试题1:Put()当两个对象的HashCode相同会发生什么?,就放入链表。新来的Entry插入链表时,使用的是”头插法”。—为什么呢?因为HashMap的开发者认为,后插入的Entry被查找的概率比较大。
- 经典面试题2:针对 HashMap 中某个 Entry 链太长,查找的时间复杂度可能达到 O(n),怎么优化?
- 经典面试题3:高并发下的HashMap:你了解重新调整HashMap大小存在什么问题吗?
- Hashmap的Resize包含扩容和ReHash两个步骤,ReHash在多线程并发的情况下可能会形成链表环。
- 原因是什么?— 因为扩容前后链表中元素的顺序反了。
- 老生常谈,HashMap的死循环 占小狼
- 经典面试题4:HashMap遇到Hash碰撞的时候,除了拉链法解决,还是什么其他的方法吗?
- 开放定址法
- 线性探测再散列
- 再Hash
- get原理:
- 根据HashCode获取对应Index;
- 遍历该数组所在链表:key.equals();
- 如果2个Key的HashCode相同,如何获取Value?
- 找到bucket位置之后,会调用keys.equals()方法去找到链表中正确的节点,最终找到要找的值对象。
- 经典面试题:
- JDK1.7和JDK1.8的HashMap有什么区别?
- 为了加快查询效率,JDK1.8的HashMap引入了红黑树结构,当链表长度>8并且数组长度>=64时,该链表就会改成红黑树结构,从而加快查询效率。当Node节点数<=6时,红黑树又退化为链表。
- 重写HashCode()一定要重写Equals()吗?— 要
- 为什么String, Interger这样的类适合作为键?
- String, Interger这样的类作为HashMap的键是再适合不过了,而且String最为常用。因为String对象是不可变的,而且已经重写了equals()和hashCode()方法了。
- 不可变性是必要的,因为为了要计算hashCode(),就要防止键值改变,如果键值在放入时和获取时返回不同的hashcode的话,那么就不能从HashMap中找到你想要的对象。不可变性还有其他的优点如线程安全。
- 因为获取对象的时候要用到equals()和hashCode()方法,那么键对象正确的重写这两个方法是非常重要的。如果两个不相等的对象返回不同的hashcode的话,那么碰撞的几率就会小些,这样就能提高HashMap的性能。
- 为什么HashMap选择红黑树而不选择AVL树?MySQL选择B+树而不选择红黑树?
- HashMap和AVL树的区别?
- JDK1.7和JDK1.8的HashMap有什么区别?
- Java7/8 中的 HashMap 和 ConcurrentHashMap 全解析
- Java进阶(六)从ConcurrentHashMap的演进看Java多线程核心技术
4.2 HashMap-1.8分析
https://blog.csdn.net/wushiwude/article/details/75331926
1. HashMap中关于红黑树的三个重要参数
常见面试题1. List是否可以存null,Set是否可以存null,List和Map的区别?2. 说一说 HashMap原理、put()原理、get()原理、扩容原理?a. 进阶:默认初始长度是16,并且每次自动扩展或者手动初始化,必须是2的幂次,为什么?b. 针对 HashMap 中某个 Entry 链太长,查找的时间复杂度可能达到 O(n),怎么优化?c. 高并发下的HashMap:你了解重新调整HashMap大小存在什么问题吗?d. HashMap遇到Hash碰撞的时候,除了拉链法解决,还是什么其他的方法吗?e. JDK1.7和JDK1.8的HashMap有什么区别?f. 重写HashCode()一定要重写Equals()吗?g. 为什么String, Interger这样的类适合作为键?h. 为什么HashMap选择红黑树而不选择AVL树?MySQL选择B+树而不选择红黑树?3. ConcurrentHashMap(CHM)a. CHM如何求size? 如何保证求size过程中插入了数据,最终结果的正确性?b. CHM的数据结构? -- JDK1.7 Segment数组+HashEntry数组c. CHM是先插入再扩容还是先扩容再插入?HashMap呢?详解1. ListArrayList 内部实现用数组,快速随机访问,但是插入删除慢,因为要移动其他元素;LinkedList 内部实现用双向链表,插入删除快,但是随机访问慢。优点在于:将零散的内存关联起来,利用率高。1.1 面试题:List是否可以存null,Set是否可以存null,List和Map的区别?a. List中的元素:有序、可重复、可为NULL;b. Set中的元素:无序、不可重复、只有一个NULL;c. Map中的元素:无序、Key不重,Value可重、可一个NULL Key,多个NULL值;2. Queue队列是一种特殊的线性表,常被用于缓存、线程池场景。3. Set不允许出现重复元素。常用的是HashSet、TreeSet、LinkedHashSet。4. Map常用的是HashMap、ConcurrentHashMap、TreeMap。4.1 HashMap原理1. 底层实现使用的是:数组+链表的数据结构。a. 面试题:默认初始长度是16,并且每次自动扩展或者手动初始化,必须是2的幂次,为什么?ⅰ. 为了服务key到index的Hash算法。ⅱ. Hash算法最终得到的index结果,完全取决于Key的Hashcode值的最后几位。2. put原理:(扩容机制)a. 根据key获取相应的Hash值:int hash = hash(key.hash.hashcode())b. 根据Hash值和数组长度确定引用位置:int index = hashCode(Key)&(length-1)。c. 经典面试题1:Put()当两个对象的HashCode相同会发生什么?,就放入链表。新来的Entry插入链表时,使用的是"头插法"。--为什么呢?因为HashMap的开发者认为,后插入的Entry被查找的概率比较大。d. 经典面试题2:针对 HashMap 中某个 Entry 链太长,查找的时间复杂度可能达到 O(n),怎么优化?e. 经典面试题3:高并发下的HashMap:你了解重新调整HashMap大小存在什么问题吗?ⅰ. Hashmap的Resize包含扩容和ReHash两个步骤,ReHash在多线程并发的情况下可能会形成链表环。ⅱ. 原因是什么?-- 因为扩容前后链表中元素的顺序反了。ⅲ. 老生常谈,HashMap的死循环 占小狼f. 经典面试题4:HashMap遇到Hash碰撞的时候,除了拉链法解决,还是什么其他的方法吗?ⅰ. 开放定址法ⅱ. 线性探测再散列ⅲ. 再Hash3. get原理:a. 根据HashCode获取对应Index;b. 遍历该数组所在链表:key.equals();c. 如果2个Key的HashCode相同,如何获取Value?ⅰ. 找到bucket位置之后,会调用keys.equals()方法去找到链表中正确的节点,最终找到要找的值对象。4. 经典面试题:a. JDK1.7和JDK1.8的HashMap有什么区别?ⅰ. 为了加快查询效率,JDK1.8的HashMap引入了红黑树结构,当链表长度>8并且数组长度>=64时,该链表就会改成红黑树结构,从而加快查询效率。当Node节点数<=6时,红黑树又退化为链表。b. 重写HashCode()一定要重写Equals()吗?-- 要c. 为什么String, Interger这样的类适合作为键?ⅰ. String, Interger这样的类作为HashMap的键是再适合不过了,而且String最为常用。因为String对象是不可变的,而且已经重写了equals()和hashCode()方法了。ⅱ. 不可变性是必要的,因为为了要计算hashCode(),就要防止键值改变,如果键值在放入时和获取时返回不同的hashcode的话,那么就不能从HashMap中找到你想要的对象。不可变性还有其他的优点如线程安全。ⅲ. 因为获取对象的时候要用到equals()和hashCode()方法,那么键对象正确的重写这两个方法是非常重要的。如果两个不相等的对象返回不同的hashcode的话,那么碰撞的几率就会小些,这样就能提高HashMap的性能。d. 为什么HashMap选择红黑树而不选择AVL树?MySQL选择B+树而不选择红黑树?ⅰ. HashMap和AVL树的区别?5. Java7/8 中的 HashMap 和 ConcurrentHashMap 全解析6. Java进阶(六)从ConcurrentHashMap的演进看Java多线程核心技术4.2 HashMap-1.8分析https://blog.csdn.net/wushiwude/article/details/753319261. HashMap中关于红黑树的三个重要参数//一个桶的树化阈值//当桶中元素个数>=这个值时,需要使用红黑树节点替换链表节点//这个值必须为 8,要不然频繁转换效率也不高static final int TREEIFY_THRESHOLD = 8;//一个树的链表还原阈值//当扩容时,桶中元素个数小于这个值,就会把树形的桶元素 还原(切分)为链表结构//这个值应该比上面那个小,至少为 6,避免频繁转换static final int UNTREEIFY_THRESHOLD = 6;//哈希表的最小树形化容量//当哈希表中的容量大于这个值时,表中的桶才能进行树形化//否则桶内元素太多时会扩容,而不是树形化//为了避免进行扩容、树形化选择的冲突,这个值不能小于 4 * TREEIFY_THRESHOLDstatic final int MIN_TREEIFY_CAPACITY = 64;2. 求SizeJDK1.7 和 JDK1.8 对 size 的计算是不一样的。 1.7 中是先不加锁计算三次,如果三次结果不一样在加锁。JDK1.8 size 是通过对 baseCount 和 counterCell 进行 CAS 计算,最终通过 baseCount 和遍CounterCell 数组得出 size。4.3 ConcurrentHashMap聊聊并发(四)——深入分析 ConcurrentHashMap1. CHM如何求size? 如何保证求size过程中插入了数据,最终结果的正确性?--modCount2. CHM的数据结构? -- JDK1.7 Segment数组+HashEntry数组3. CHM是先插入再扩容还是先扩容再插入?HashMap呢? -- HashMap是先插入再扩容,会有浪费。
求Size
JDK1.7 和 JDK1.8 对 size 的计算是不一样的。 1.7 中是先不加锁计算三次,如果三次结果不一样在加锁。
JDK1.8 size 是通过对 baseCount 和 counterCell 进行 CAS 计算,最终通过 baseCount 和遍CounterCell 数组得出 size。4.3 ConcurrentHashMap
CHM如何求size? 如何保证求size过程中插入了数据,最终结果的正确性?—modCount
- CHM的数据结构? — JDK1.7 Segment数组+HashEntry数组
- CHM是先插入再扩容还是先扩容再插入?HashMap呢? — HashMap是先插入再扩容,会有浪费。

若有收获,就点个赞吧
0 人点赞
