先出面试题
Q1:下列程序的输出结果:
String s1 = “abc”;
String s2 = “abc”;
System.out.println(s1 == s2);
Q2:下列程序的输出结果:
String s1 = new String(“abc”);
String s2 = new String(“abc”);
System.out.println(s1 == s2);
Q3:下列程序的输出结果:
String s1 = “abc”;
String s2 = “a”;
String s3 = “bc”;
String s4 = s2 + s3;
System.out.println(s1 == s4);
Q3:下列程序的输出结果:
String s1 = “abc”;
final String s2 = “a”;
final String s3 = “bc”;
String s4 = s2 + s3;
System.out.println(s1 == s4);
Q4:下列程序的输出结果:
String s = new String(“abc”);
String s1 = “abc”;
String s2 = new String(“abc”);
System.out.println(s == s1.intern());
System.out.println(s == s2.intern());
System.out.println(s1 == s2.intern());
考察点
- String intern在JDK1.6和JDk1.7中的区别,以及常量池在2个版本中的位置;
- String intern返回的是什么?
- String 为什么用final 修饰?
讲解
- new String都是在堆上创建字符串对象。当调用 intern() 方法时,编译器会将字符串添加到常量池中(stringTable维护),并返回指向该常量的引用。
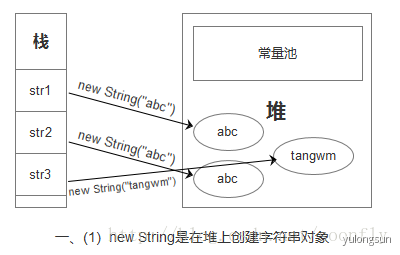
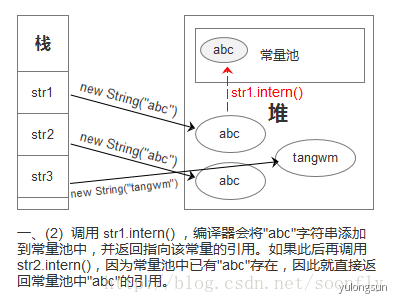
str1.intern()返回的是常量池中的引用。
@Testpublic void test1() {String abc = new String("abc");System.out.println(abc.intern() == abc); //false}
- 通过字面量赋值创建字符串(如:String str=”twm”)时,会先在常量池中查找是否存在相同的字符串,若存在,则将栈中的引用直接指向该字符串;若不存在,则在常量池中生成一个字符串,再将栈中的引用指向该字符串。
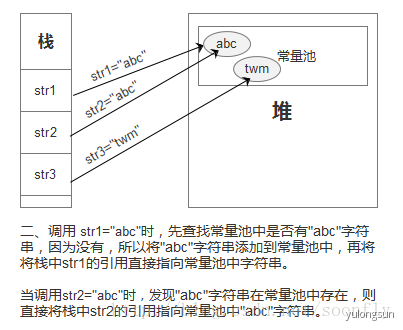
@Testpublic void test2() {String abc = "abc";System.out.println(abc.intern() == abc); //true}
常量字符串的“+”操作,编译阶段直接会合成为一个字符串。如string str=”JA”+”VA”,在编译阶段会直接合并成语句String str=”JAVA”,于是会去常量池中查找是否存在”JAVA”,从而进行创建或引用。
@Testpublic void test3() {String java = "JA"+"VA";System.out.println(java.intern() == "JAVA"); //true}
对于final字段,编译期直接进行了常量替换(而对于非final字段则是在运行期进行赋值处理的)。
final String str1=”ja”;
final String str2=”va”;
String str3=str1+str2;
在编译时,直接替换成了String str3=”ja”+”va”,根据第三条规则,再次替换成String str3=”JAVA”
- 常量字符串和变量拼接时(如:String str3=baseStr + “01”;)会调用stringBuilder.append()在堆上创建新的对象。
- JDK 1.7后,intern方法还是会先去查询常量池中是否有已经存在,如果存在,则返回常量池中的引用,这一点与之前没有区别,区别在于,如果在常量池找不到对应的字符串,则不会再将字符串拷贝到常量池,而只是在常量池中生成一个对原字符串的引用。简单的说,就是往常量池放的东西变了:原来在常量池中找不到时,复制一个副本放到常量池,1.7后则是将在堆上的地址引用复制到常量池。
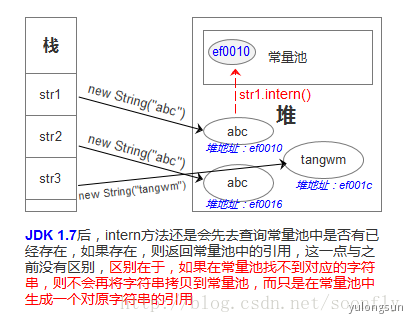
举例说明:
@Testpublic void test4() {String str2 = new String("str") + new String("01"); //堆str2.intern(); //在常量池中生成堆的引用String str1 = "str01"; //常量池中的引用,其实就是堆的引用System.out.println(str2 == str1);//true}
在JDK 1.7后,常量池从Perm迁移到堆。当执行str2.intern();时,因为常量池中没有“str01”这个字符串,所以会在常量池中生成一个对堆中的“str01”的引用(注意这里是引用 ,就是这个区别于JDK 1.6的地方。在JDK1.6下是生成原字符串的拷贝),而在进行String str1 = “str01”;字面量赋值的时候,常量池中已经存在一个引用,所以直接返回了该引用,因此str1和str2都指向堆中的同一个字符串,返回true。
@Testpublic void test5() {String str1 = "str01"; //常量池对象String str2 = new String("str") + new String("01"); //堆str2.intern(); //在常量池生成引用,但是引用是指向堆System.out.println(str2 == str1); //false}
将中间两行调换位置以后,因为在进行字面量赋值(String str1 = “str01″)的时候,常量池中不存在,所以str1指向的常量池中的位置,而str2指向的是堆中的对象,再进行intern方法时,对str1和str2已经没有影响了,所以返回false。
解答
有了对以上的知识的了解,我们现在再来看常见的面试或笔试题就很简单了:
Q:下列程序的输出结果:
String s1 = “abc”;
String s2 = “abc”;
System.out.println(s1 == s2);
A:true,均指向常量池中对象。
Q:下列程序的输出结果:
String s1 = new String(“abc”);
String s2 = new String(“abc”);
System.out.println(s1 == s2);
A:false,两个引用指向堆中的不同对象。
Q:下列程序的输出结果:
String s1 = “abc”;
String s2 = “a”;
String s3 = “bc”;
String s4 = s2 + s3;
System.out.println(s1 == s4);
A:false,因为s2+s3实际上是使用StringBuilder.append来完成,会生成不同的对象。
Q:下列程序的输出结果:
String s1 = “abc”;
final String s2 = “a”;
final String s3 = “bc”;
String s4 = s2 + s3;
System.out.println(s1 == s4);
A:true,因为final变量在编译后会直接替换成对应的值,所以实际上等于s4=”a”+”bc”,而这种情况下,编译器会直接合并为s4=”abc”,所以最终s1==s4。
Q:下列程序的输出结果:
String s = new String(“abc”);
String s1 = “abc”;
String s2 = new String(“abc”);
System.out.println(s == s1.intern());
System.out.println(s == s2.intern());
System.out.println(s1 == s2.intern());
A:false,false,true。

若有收获,就点个赞吧
0 人点赞
