一、程序本质
高级语言编译为机器指令才能被CPU识别执行,根据编译的过程可以将高级语法分为三类
二、基础语法
1、变量
在其作用域(一对花括号)内可以发生改变的量称为变量。
内存地址和变量的关系,跟IP地址和域名的关系类似。在机器码中,我们通过内存地址来实现对内存中数据的读写。在代码中,我们通过变量来实现对内存中数据的读写。
2、类型
2.1 基本类型
1)分类
基本类型包括:整型(byte,short,int,long)、浮点型(float,double)、字符型(char)、布尔型(boolean)。
| 基本类型 | 字节大小 |
|---|---|
| byte | 1 |
| short | 2 |
| int | 4 |
| long | 8 |
| float | 4 |
| double | 8 |
| char | 2 |
| boolean | 1 |
2)转换自动类型转换:小的类型向大的类型提升,byte、short、char 运算时直接提升为 int 。强制类型转换:大的类型向小的类型提升,如 int a =(int)100L
byte b1 = 10;byte b2 = 11;byte b3 = b1 + b2 //错误,byte运算自动转换成int,int赋给一个byte要强制转换byte b3 = (byte)(b1 + b2); //正确,short s1 = 1;s1 = s1 + 1; //错误,short运算自动转换成int,short赋给一个short要强制转换short s2 = 1;s2 += 1; // 等同于short s2 = (short)(s2 + (short)1); //正确
3)装箱拆箱
//显式装箱拆箱int i = 100;Integer integer = new Integer(i);Integer integer = Integer.valueOf(i);int i = integer.intValue();//隐式装箱拆箱Integer total = 99;int totalprim = total;
- 将基本类型数据赋值给包装类变量(包括参数传递)时,触发自动装箱。
- 将包装类对象赋值给基本类型变量(包括参数传递)时,触发自动拆箱。
- 当包装类对象参与算术运算时,触发自动拆箱操作。
- 当包装类对象参与关系运算(<、>)时,触发自动拆箱操作。
- 当包装类对象参与关系运算(==),并且另一方是基本类型数据时,触发拆箱操作。
4)常量池
Interger 类型引用[-128,127]区间中是指向常量池中的,超过该范围才会创建对象。
2.2 引用类型
引用类型包括类、接口、数组。
3、运算
- 算术运算,比如加、减、乘、除
- a++是使用的a后,再对a进行加1。++a是先把a加1,然后再使用a
- 关系运算,比如大于、小于、等于;
- 赋值运算,比如a=5;
- a+ = 1 相当于 a=a+1,但是留意a的类型,+=不改变运算类型
- 逻辑运算,比如&&,丨丨;
-
4、流程
1)选择
if(搭配else,或者elseif)
- switch(匹配到相应case的case就会往下执行直到break结束)
2)循环
- for(已知次数使用)
- while(未知次数使用)
- do..while(至少会一次,注意最后不能遗漏分号)
3) 控制关键字
break执行直接跳出循环;-
5、函数
5.1 参数
参数传递是值传递。基本类型时,传递的是数据值;为引用类型时,传递的是地址值;
参数可以有多个,但只能有一个可变参数,可变参数必须写在参数列表的最后。5.2 重载与重载
重载:函数名称一样,参数不一样(只于参数的个数、类型有关,与方法的返回类型无关);
重写:只在继承关系中存在,方法名称一样,参数也一样(子类的返回值必须小于等于父类的返回值);三、类和对象
1、面向对象
1.1 介绍
面向对象编程是一种编程范式或编程风格
以类或对象作为组织代码的基本单元,并将封装、抽象、继承、多态四个特性作为代码设计和实现的基石
- 面向对象分析就是要搞清楚做什么,面向对象设计就是要搞清楚怎么做,两个阶段最终的产出是类的设计,包括程序被拆解为哪些类,每个类有哪些属性方法、类与类之间如何交互等
- 类是属性和行为的集合,对一类事物的描述,是抽象的。如猫是一个种类。对象是类的实例,是具体的。如一只猫。
1.2 四大特性
1)封装
定义:类通过暴露有限的访问接口,授权外部仅能通过类提供的方式来访问内部信息或者数据。需要编程语言提供权限访问控制语法来支持,例如 Java 中的 private、protected、public 关键字。
意义:一方面是保护数据 不被随意修改,提高代码的可维护性;另一方面是仅暴露有限的必要接口,提高类的易用性。
2)抽象
定义:抽象就是讲如何隐藏方法的具体实现,让使用者只 需要关心方法提供了哪些功能,不需要知道这些功能是如何实现的。抽象可以通过接口类或者抽象类来实现,但也并不需要特殊的语法机制来支持。
意义:一方面是提高代码的可扩展性、维护性,修改实现不需要改变定义,减少代码的改动范围;另一方面,它也是处理复杂系统的有效手段,能有效地过滤掉不必要关注的信息。
3)继承
定义:继承是用来表示类之间的 is-a 关系,比如猫是一种哺乳动物。需要编程语言提供特殊的语法机制来支持,比如 Java 使用 extends 关键字来实现继承。
意义:继承主要是用来解决代码复用的问题。
继承容易出现层次过深、过的继承关系影响会代码可维护性。可以利用组合处理。 ```java public interface Flyable { void fly(); }
// 省略 Tweetable/TweetAbility/EggLayable/EggLayAbility public class FlyAbility implements Flyable { @Override public void fly() { //… } }
public class Ostrich implements Tweetable, EggLayable {// 鸵鸟 private TweetAbility tweetAbility = new TweetAbility(); // 组合 private EggLayAbility eggLayAbility = new EggLayAbility(); // 组合 //… 省略其他属性和方法… @Override public void tweet() { tweetAbility.tweet(); // 委托 } @Override public void layEgg() { eggLayAbility.layEgg(); // 委托 } }
在实际的项目开发中,我们还是要根据具体的情况,来选择该用继承还是组合。如果类之间的继承结构稳定,层次比较浅,关系不复杂,我们就可以大胆地使用继承。反之,我们就尽量使用组合来替代继承。除此之外,还有一些设计模式、特殊的应用场景,会固定使用继承或者组合。<br />**4)多态**<br />定义:多态是指子类可以替换父类,在实际的代码运行过程中,调用子类的方法实现。多态这种特性也需要编程语言提供特殊的语法机制来实现,比如**继承**、**接口类**等。<br />意义:多态可以提高代码的扩展性和复用性,是很多设计模式、设计原则、编程技巧实现基础。**成员变量和静态方法:编译看左边,运行还看左边;成员方法:编译看左边,运行看右边**;```javapublic class Animal{static String name = "animal";int num = 1;public static void sleep() {System.out.println("animal sleep");}public void run() {System.out.println("animal run");}}public class Cat extends Animal{static String name = "cat";int num = 2;public static void sleep() {System.out.println("cat sleep");}public void run() {System.out.println("cat run");}}public static void main(String args[]) {Cat cat = new Cat();Animal animal = new Cat();System.out.println(cat.num);//2System.out.println(animal.num);//1System.out.println(cat.name);//catSystem.out.println(animal.name);//animalcat.sleep();//cat sleepanimal.sleep();//animal sleepcat.run();//cat runanimal.run();//cat run}
2、抽象类与接口
2.1 抽象类(abstract)
- 不能实例化
- 不能被 final 修饰;
- 如果一个类中含有抽象方法,那么这个类必须定义成抽象类
如果这个类是抽象的,那么这个类被子类继承,抽象方法必须被重写
2.2 接口(interface)
不能实例化
- 一般方法使用 public abstract修饰,但可以省略不写,没有方法体
- 默认方法(为了解决接口升级,因为实现类必须实现接口里的所有抽象方法,如果接口添加了一个新的方法就会影响到所有的实现类)abstract关键改成default,并且有方法体默认方法可以被接口的实现类的对象直接调用,也可以在接口的实现类重写。
- 静态方法abstract关键改成static ,并且有方法体;直接通过接口名调用
- 私有方法(java9以后才能写在接口里,用于解决默认方法和静态方法代码重复的问题)格式是把默认方法和静态方法的public 改成private,只能接口自己调用,不能给实现类或者其他人使用
2.3 如何决定该用抽象类还是接口
可以使用接口来实现面向对象的抽象特性、多态特性和基于接口而非实现的设计原则,使用抽象类来实现面向对象的继承特性和模板设计模式等等。
如果要表示一种 is-a 的关系,并且是为了解决代码复用 的问题,就用抽象类;
如果要表示一种 has-a 关系,并且是为了解决抽象而非代 码复用的问题,那我们就可以使用接口。
抽象类是一种自下而上的设计思路,先有子类的代码重复,然后再 抽象成上层的父类(也就是抽象类)。
接口是一种自上而下的设计思路。一般都是先设计接口,再去考虑具体的实现。
3、类与类的关系

4、关键字
4.1 权限
| 权限 | 作用域 |
|---|---|
| private | 本类 |
| default | 本类、子类 |
| protected | protected |
| public | 全局 |
4.2 final
- 修饰类上表示该类不可被继承;
- 修饰方法上表示该方法为最终方法不能被重写;
- 修饰类的成员变量必须手动赋值;
修饰函数的局部变量表示该局部变量不能进行更改,
静态跟对象没关系,直接跟类挂钩,在类中定义了带static关键字的属性,凡是本类创建的对象都会使用,所有对象共享同一份数据。
- 直接通过类名.的形式直接调用。
- 静态不能访问非静态,因为内存中先有静态内容
-
5、内部类
5.1 内部类的访问规则
可以直接访问外部类的成员,包括私有
-
5.2 成员内部类
Inner当成Outer的成员存在,即一个事物包含另一个小的事物,如身体和心脏
class Outer { private int age = 20; //成员位置 class Inner { public void show() { System.out.println(age); } } } class Test { public static void main(String[] ages) { //成员内部类是非静态的演示 Outer.Inner oi = new Outer().new Inner(); oi.show(); } } //成员内部类不是静态的: 外部类名.内部类名 对象名 = new 外部类名.new 内部类名(); //成员内部类是静态的: 外部类名.内部类名 对象名 = new 外部类名.内部类名();5.3 静态内部类
5.4 局部内部类
就是定义在一个方法或者一个作用域里面的类,主要是作用域发生了变化,只能在自身所在方法和属性中被使用。
5.5 匿名内部类
接口的实现类或者父类的子类,只使用唯一的一次,为了简化代码。
四、常用库类
1、Object
1)equals()
只能比较引用数据类型,equals方法和==号比较引用数据类型无区别,重写后的equals方法比较的是对象中的属性。
“==” 是一个比较运算符号,既可以比较基本数据类型,也可以比较引用数据类型,基本数据类型比较的是值,引用数据类型比较的是地址值.
2)hashCode()
返回对象的哈希代码值,如果两个对象的哈希码值不同,那这两个对象一定不等;哈希码值相同,不能确保一定相等。
2、String
1)常量池技术
String s1 ="abc";//直接在字符串常量池
String s2 =new String("abc");//堆上的对象
String s3 = s2.intern();//可以把堆上的对象复制到常量池
2)不可变性
String类是不可变类。1.String类运用了常量池,修改会影响其他引用;2.在HashMap中经常使用String作为key值,修改会影响其hashcode的计算;3.String要和其他基本类型保持一致
3)StringBuffer
字符串常量相加的技术底层就是StringBuilder
StringBuffer线程安全、StringBuilder 线程不安全。
五、容器框架
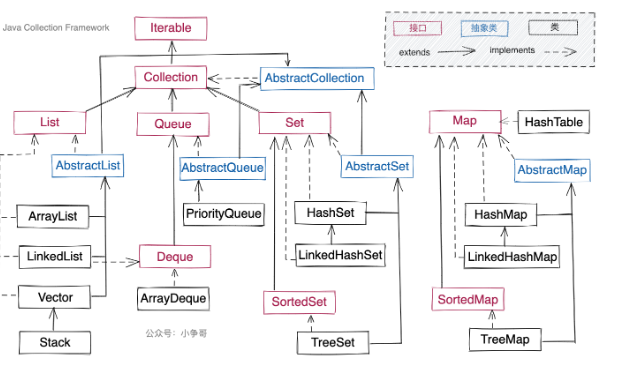
- List(列表):ArrayList、LinkedList、Vector(废弃)
- Stack():Stack(废弃)
- Queue(队列):ArrayDeque、LinkedList、PriorityQueue
- Set(集合):HashSet、.LinkedHashSet、.TreeSet
- Map(映射):HashMap、LinkedHashMap、TreeMap、HashTable(废弃)
1、List

动态扩容:
2、Stack
已废弃,使用队列中的双端队列替代
Deque<Integer> deque = new LinkedList<>();
deque.push(1);
deque.push(2);
deque.push(3);
while (!deque.isEmpty()) {
deque.pop();
}
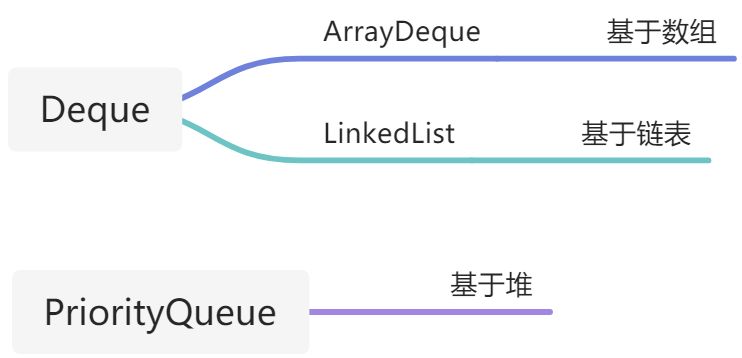
3、Deque
4、Set

5、Map
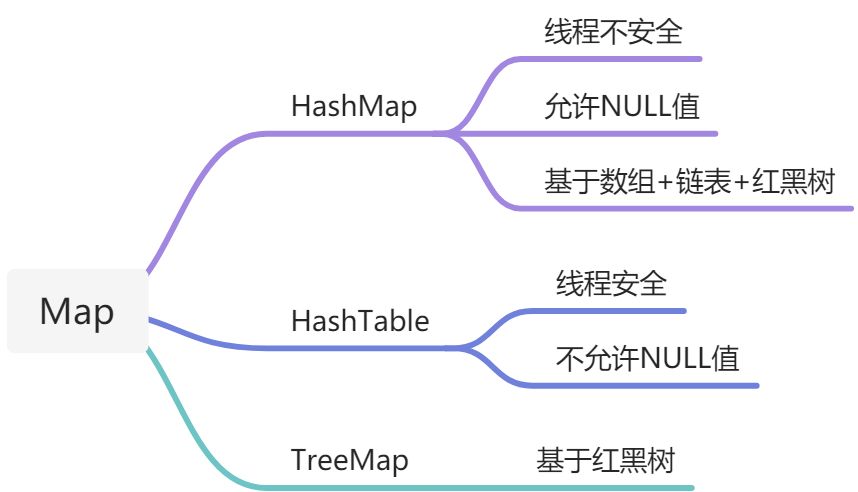
5.1 HashMap详解
1)结构及扩容示意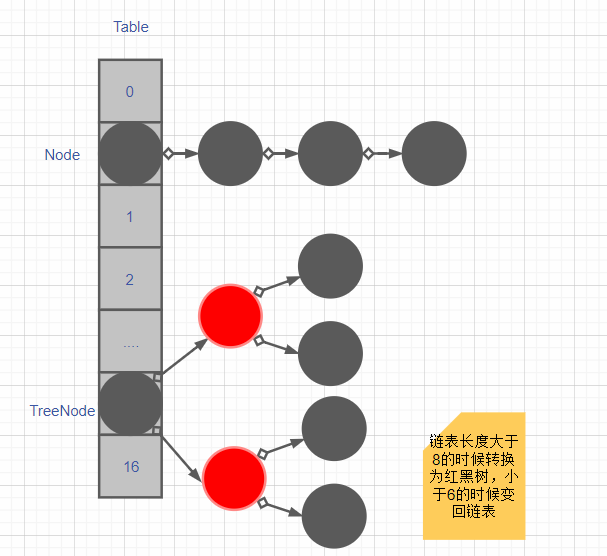
- HashMap默认初始容量为16(太小容易频繁扩容影响性能,太大浪费资源),负载因子为0.75。HashMap的容量必须为2的幂,因为底层进行按位与运算,根据hash值计算存放于哪个桶,假如不是2的幂运算的结果,就是有几个桶永远没数据。
- 当存放的元素大于16*0.75的时候自动扩容,减少hash冲突提高查询效率
2)存储原理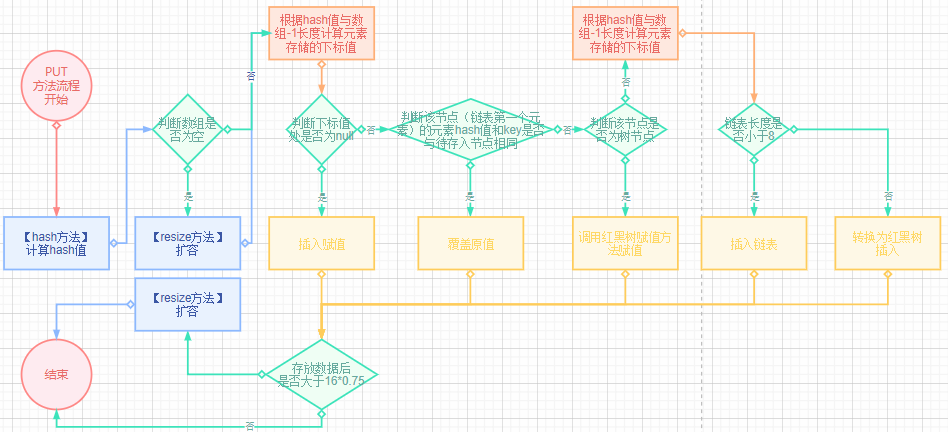
- 将k,v封装到Node对象中。
- 根据key计算hash值,得到存放的数组下标。
- 判断下标节点值,为空直接插入,hash冲突则对整个链表(红黑树)进行equal比较。如果为true则进行覆盖,如果都为false则进行尾插。
6、泛型
6.1 作用
泛型本质上就是对类型的参数化,在类的定义中,我们可以把类型当做参数。
- 代码复用
- 泛型中的类型在使用时指定,不需要强制类型转换(编译器会检查类型)
6.2 使用
//泛型类(接口) public class Generic<T> implements GenericInterface<T>{ private T key;//key这个成员变量的类型为T,T的类型由外部指定 public Generic(T key) { //泛型构造方法形参key的类型也为T,T的类型由外部指定 this.key = key; } public T getKey(){ //泛型方法getKey的返回值类型为T,T的类型由外部指定 return key; } }
尖括号内的E、T等表示类型参数,实际上,它们也可以替换为任意大写字母;
可以支持多个类型参数;
可以使用extends上界限定符,限定类型参数的具体取值范围。例如,
6.3 通配符
//通配符的使用方式
public void printList(List<?> list ){ 方法体;}
//通配符的上限,泛型的类是上限,只能接受该类及其子类
public void printList2(List<? extend 类> list ){ 方法体;}
//通配符的下限,泛型的类是下限,只能接受该类及其父类
public void printList3(List<? super 类> list ){ 方法体;}
参数类型(T)与通配符(?)的区别在于,T在声明了类型参数之后只能存储该类型数据,?则可以存放不同类型的数据。
6.4 原理
泛型是一个语法糖。在编译时,编译器会使用泛型做类型检查,但是,当代码编译为字节码之后,泛型中的类型
参数和通配符统统替换成上界,这种实现方式叫做类型擦除。因为Java泛型的类型擦除,我们不能使用newT()来创建类型参数对象。
六、异常处理
1、异常体系
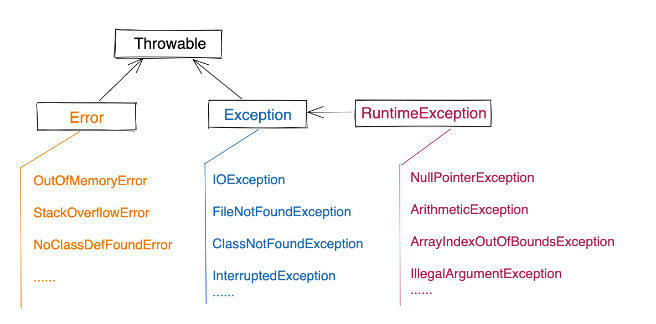
2、异常使用
- throw:抛出具体异常
- throws:在方法定义中声明方法可抛出的异常
- try:用来标记需要监控异常的代码
- jdk7后对于实现了java.lang.AutoClosable接口的资源类可以无需finally关闭
- catch:用来捕获代码抛出的异常并进行处理
- 先捕获子类异常,再捕获父类异常
- jdk7后可以同时捕获多个异常
finally:不管是否出现异常代码都会被执行
捕获后记录日志:上层代码并不关心被调用函数内部的这个异常
- 原封不动抛出:异常跟函数的业务相关,上层代码在调用此函数时,知道如何处理此异常
- 包装成新异常再抛出:异常跟函数的业务相无关,上层代码在调用此函数时,不知道如何处理此异常
异常的最佳实践:异常的创建、抛出、打印异常调用链这些操作都是非常耗时的,对于业务异常,我们没必要记录stackTrace栈追踪信息,可以使用Throwable有一个特殊的构造函数禁止打印。
七、文件/IO
1、io
1.1 抽象父类
| 字节流 | 字符流 | |
|---|---|---|
| 输入流 | InputStream | Reader |
| 输出流 | OutputStream | Writer |
字符流比起字节流来说,只是多了一个字符编码转换的环节。
字符流带有缓冲器,一般用来操作文本文件。
1.2 原始类
| 文件流 | FileInputStream等 | 文件读写 |
|---|---|---|
| 内存流 | ByteArrayInputStream等 | 内存读写,多用于兼容与测试 |
| 管道流 | PipedInputStream等 | 对于两个线程之间非对象的原始数据的传输 |
| 网络流 | 无 | 复用InputStream类 |
| 标准流 | System.in等 |
1.3 装饰器类
装饰器类是对原始类的功能增强,不能独立使用,必须嵌套原始类或其他装饰器类。
| 缓存流 | BufferedInputStream等 | 支持缓存 |
|---|---|---|
| 基本类型流 | DataInputStream等 | 读取的数据解析为基本类型 |
| 对象流 | ObjectInputStream等 | 读取的数据反序列化为对象 |
| 打印流 | PrintStream等 | 将数据按照一定的格式,转化为字符串,写入到输出流 |
2、nio
NIO 支持面向缓冲区(Buffer)的、基于通道(Channel) IO 操作。
1.1 类库
1)Buffer
缓冲区负责数据的存储,本质就是数组。
用于存储不同类型的数据,通过allocate()获取缓冲区。
2)Channel
通道为源节点和目标节点的连接,本身不存储数据与缓冲区结合使用。可以理解通道为铁轨,缓冲区为火车。
有两种运行模式:阻塞模式和非阻塞模式。
文件是没有非阻塞模式的,而网络、标准输入输出、管道都存在阻塞和非阻塞两种模式。
3)Selector
选择器
4)Asynchronous
假设你去一家餐厅就餐,因为就餐的人太多,需要取号等位。取号之后,如果你站在餐厅门口一直等待被叫号,啥都不干,那么,这就是阻塞模式。如果你先去商场里逛一逛,一会回来看一下有没有轮到你,没有就继续再去逛,那么,这就是非阻塞模式。
如果你在取号时,登记了手机号码,那么你就可以放心去逛商场了,等叫到你的号时,服务员会打电话通知你,这就是异步模式。相反,如果需要自己去查看有没有轮到你,不管是阻塞模式还是非阻塞模式,都是同步模式。
实际上,异步模式下也可以有阻塞和非阻塞之分。如果在没有收到通知时,尽管你可以去干其他事情,但你偏偏就啥都不干,就站在门口等着被叫号,那么这就是阻塞异步模式,如果你选择享受通知服务,去干其他事情,那么这就是非阻塞异步模式。
从上面的解释,我们可以发现,同步、异步跟阻塞、非阻塞没有直接关系。
1.2 模型
1)阻塞I/O模型(BIO)
阻塞I/O模型指的是利用阻塞模式来实现服务器。
2)非阻塞I/O模型(NIO)
非阻塞I/O模型指的是利用非阻塞模式来开发服务器
3)异步I/O模型(AIO)
当有连接建立、数据读取完成、数据写入完成时,底层会通过线程池执行对应的回调函数。这种服务器的实现方式叫做异步I/O模型。
1.3 原理
1)用户态和内核态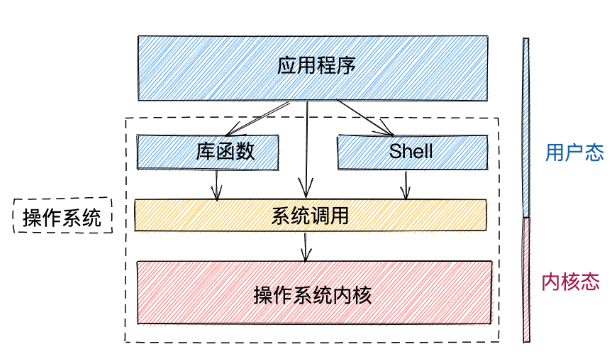
2)系统调用与上下文切换
当应用程序调用操作系统的系统调用时,CPU从用户态切换到内核态,当系统调用执行完成之后,CPU又从内核态切换到用户态。我们把这种状态的切换叫做上下文切换。上下文切换会消耗时间
- 寄存器保存与恢复耗时
- 缓存失效带来的性能损耗
3)系统调用与上下文切换实现原理
4)mmap
mmap(memory-mapped file,内存映射文件)是提高文件读写性的有效技术,mmap一般用于文件。
mmap相当于直接将数据在磁盘和用户空间之间互相拷贝,相对于使用read()、write()系统调用读写文件,数据拷贝次数由2次减少为1次。除此,之外,使用mmap读写文件,只需要在开始时,调用一次mmap()系统调用,建立好映射关系,之后读写文件就像读写内存一样,并不需要使用read()、write()系统调用,这也减/少系统调用引起的用户态和内核态上下文切换的耗时。
5)零拷贝
零拷贝(Zro-Copy)技术主要用于两个N/O设备之间互相传输数据,特别是在将文件中的数据发送到网络或者将从网络接收的数据存储到文件这一场景中,经常会用到零拷贝技术。
八、动态编程
1、反射
1.1 反射的作用
3种创建Class对象的方法
通过类名获取:Class c1 = Student.class;
通过对象获取:Class c2 = stu.getClass();
通过全类名获取:Class c3 = Class.forName(“全限定类名”);
Class对象可以通过newlnstance()来创建对象
2)Constructor
获取构造函数的信息。
Class类上的newlnstance()只能通过无参构造函数来创建对象,如果想要使用有参构造函数创建对象,要使用
Constructor的newlnstance()
3)Method
获取方法的信息。
调用invoke()可以执行对应方法。
4)Field
获取成员变量的信息
1.3 反射的原理
使用反射来创建对象,要比使用new创建对象,要慢很多。反射和new创建对象流程大体一致,通过new来创建对象是在代码编写时确定的,而通过反射来创建对象是在运行是确定的。反射需要在安全性检查,类、方法查找上花费额外的时间。
2、注解
九、函数式编程
十、网络编程

若有收获,就点个赞吧
0 人点赞
