1 简介
Redis是一个基于内存的非关系型的键值对数据库。
Redis读写性能优异、数据类型丰富,常用于热点数据的缓存、计数器、分布式锁等场景。
2 安装
1 下载redis镜像

2 使用外部配置文件启动
[root@localhost ~]# cd /www/server/[root@localhost server]# mkdir -p /redis/conf[root@localhost server]# mkdir -p /www/server/redis/conf
然后从http://download.redis.io/redis-stable/redis.conf拷贝redis.conf,上传至/www/server/redis/conf目录
将protected-mode 修改为 no,默认为yes 开启保护模式
将bind 127.0.0.1注释掉 或改为0.0.0.0 允许外部访问
将daemonize 改为no 关闭守护进程方式启动, yes 使用外部配置文件会启动失败
修改redis.conf的权限
chmod -R 777 redis.conf
3 创建容器
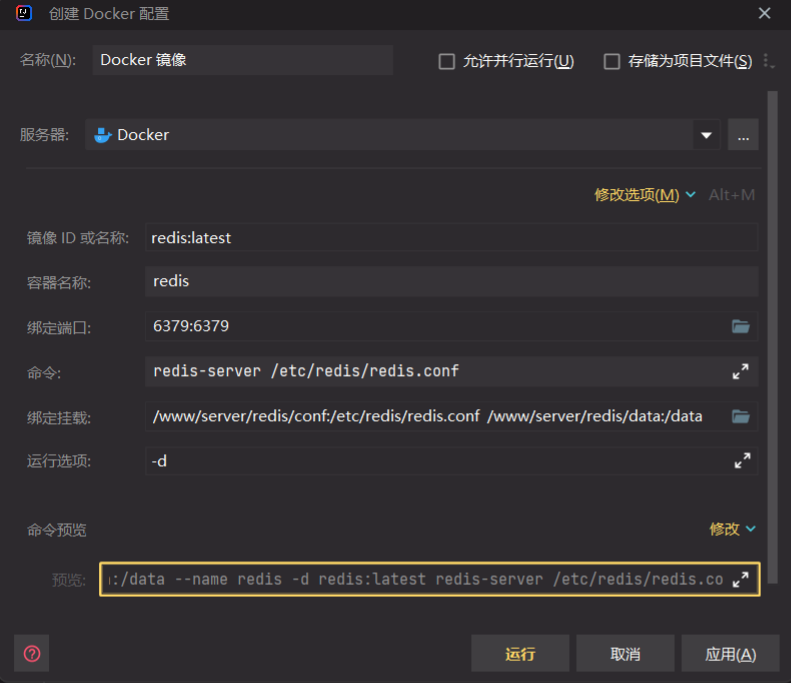
docker run redis # 从redis镜像运行容器
-p 6379:6379 # 映射本地6379端口到容器6379端口,前为本地端口
--name redis # 设置容器名称为redis,方便以后使用docker ps进行管理
-v /docker/redis/redis.conf:/etc/redis/redis.conf # 关联本地/docker/redis/redis.conf文件到容器中/etc/redis/redis.conf,同样,前为本地
-v /docker/redis/data:/data # 关联本地/docker/redis/data到容器内/data目录,此为存放redis数据的目录,为方便以后升级redis,而数据可以留存
-d # 后台启动,使用此方式启动,则redis.conf中daemonize必须设置为no,否则会无法启动
redis-server /etc/redis/redis.conf # 在容器内启动redis-server的命令,主要是为了加载配置
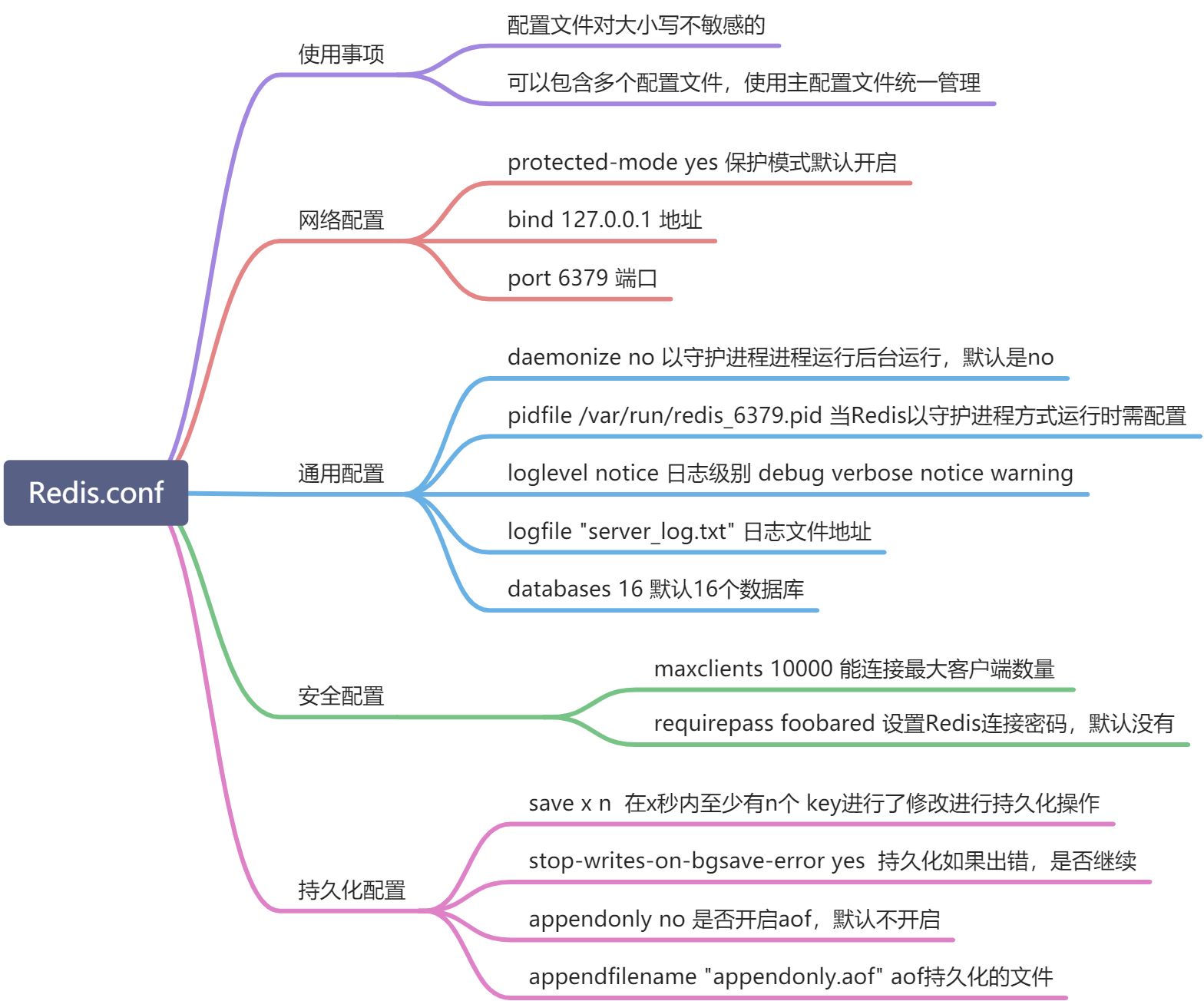
4 . redis.conf详解
3 基本架构
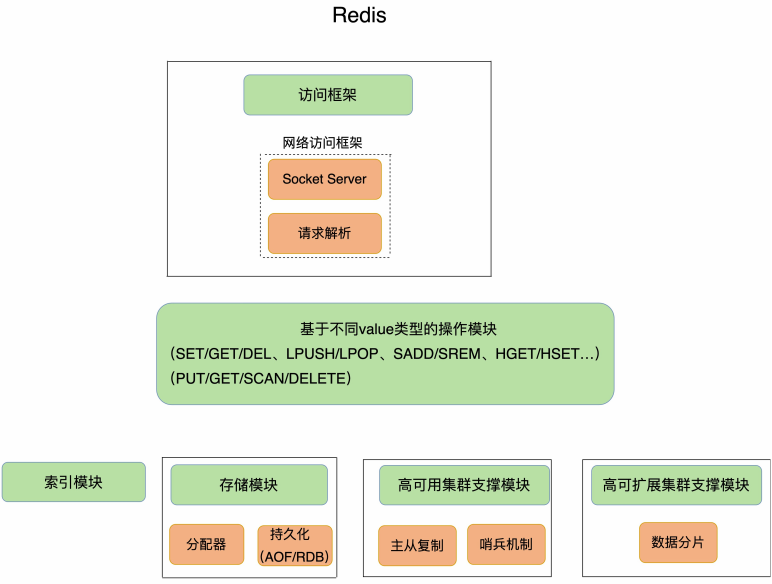
Redis 是单线程,主要是指 Redis 的网络 IO 和键值对读写是由一个线程来完成的,这也是 Redis 对外提供键值存储服务的主要流程。
但 Redis 的其他功能,比如持久化、异步删除、集群数据同步等,其实是由额外的线程执行的。
Redis 为什么用单线程 :(1)多线程切换的开销(2)共享资源并发
单线程 Redis 为什么那么快:(1)内存操作(2)高效的数据结构(3)多路复用IO
4 数据类型
1 分类
Redis的key(键)都是字符串,数据类型都是针对值来说。
查询Redis命令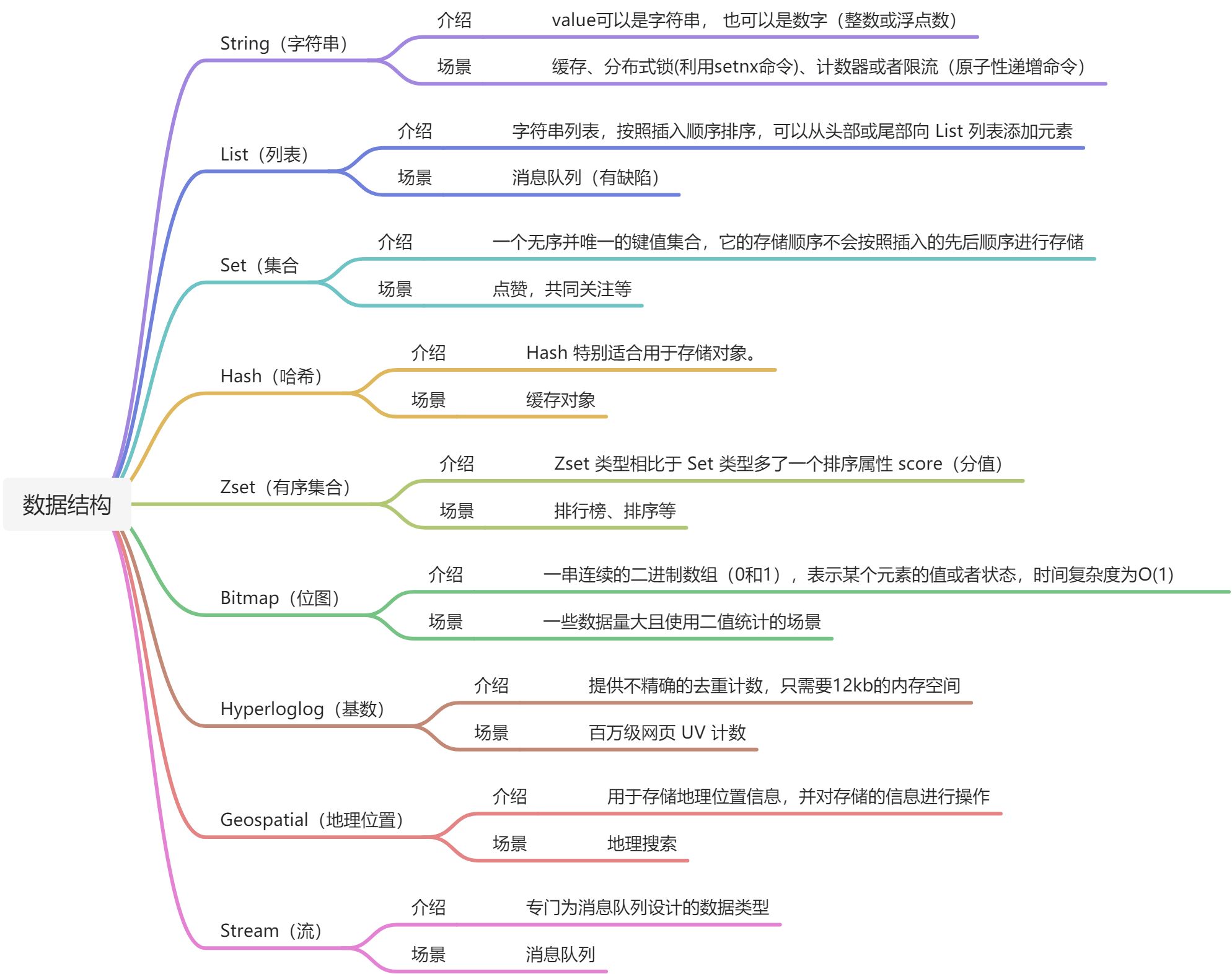
2 底层实现
Redis 使用了一个哈希表来保存所有键值对。
和java的HashMap类似,全局哈希表计算键的哈希值,就可以知道它所对应的哈希桶位置,然后就可以访问相应的 entry 元素。
Redis 解决哈希冲突的方式,就是链式哈希。同一个哈希 桶中的多个元素用一个链表来保存,它们之间依次用指针连接。
Redis 默认使用了两个全局哈希表:哈希表 1 和哈希表 2来进行rehash操作。渐进式 rehash,把拷贝数据分摊到了多次处理请求的过程中,避免了耗时操
作,保证了数据的快速访问。
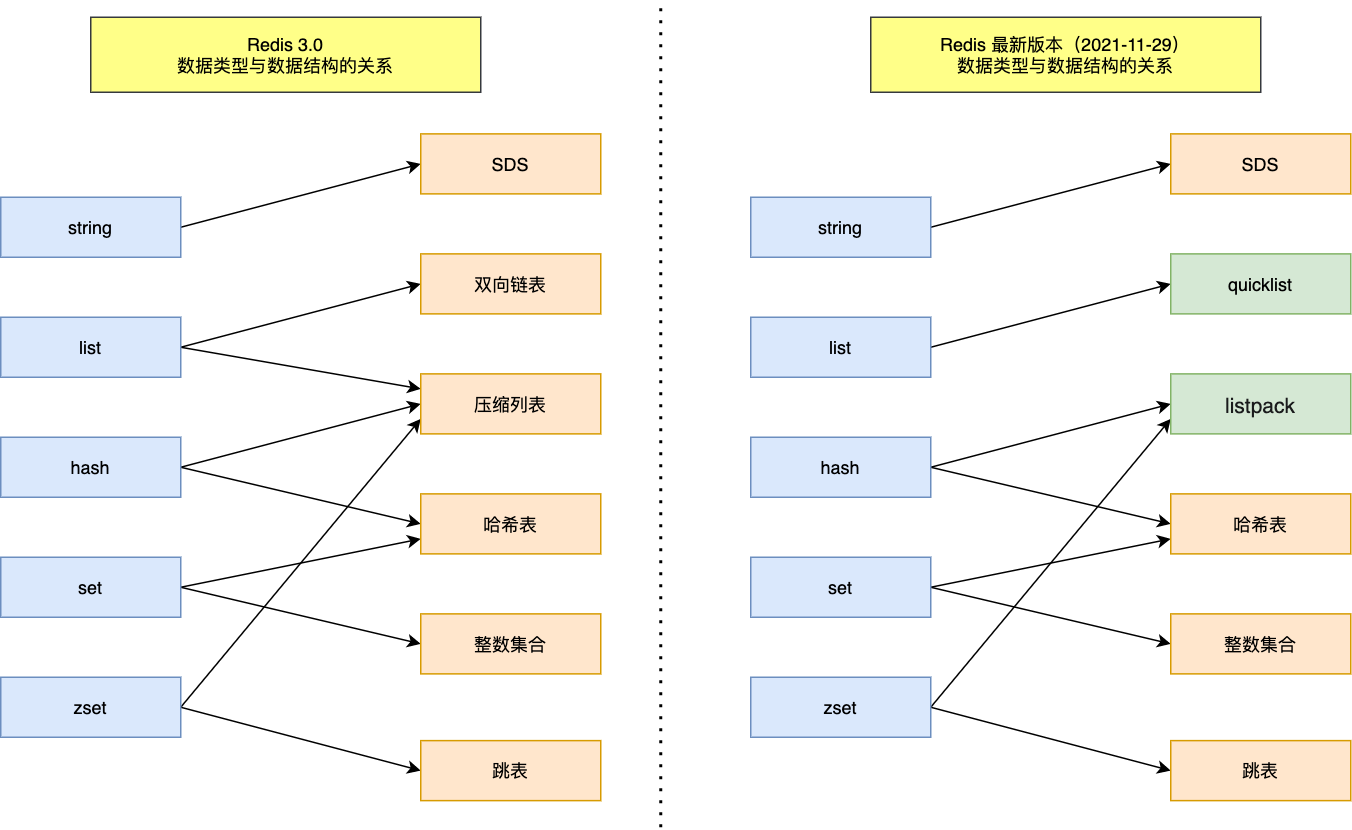
- 在 Redis 3.0 版本中 List 对象的底层数据结构由「双向链表」或「压缩表列表」实现,但是在 3.2 版本之后,List 数据类型底层数据结构是由 quicklist 实现的;
- 在最新的 Redis 代码中,压缩列表数据结构已经废弃了,交由 listpack 数据结构来实现了
参考:https://xiaolincoding.com/redis/data_struct/data_struct.html
5 持久化
1 AOF日志(Append Only File)
1 简介
Redis执行的每次写命令记录到单独的日志文件中,当重启Redis会重新将持久化的日志中文件恢复数据。
AOF是写后日志,Redis 是先执行命令,把数据写入内存,然后才记录日志。
好处:(1)避免出现记录错误命令(2)不会阻塞当前的写操作
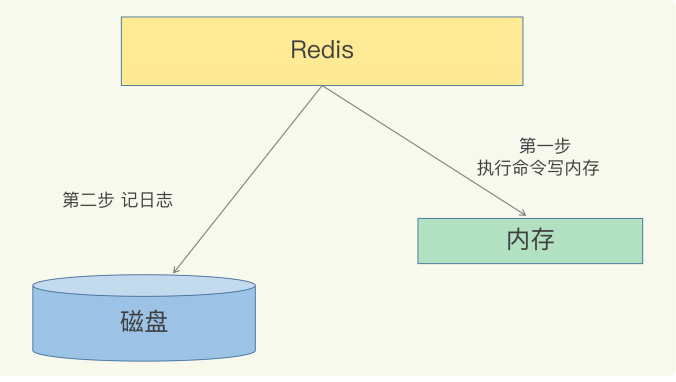
2 写回策略
| 配置项 | 时机 | 说明 | 特点 |
|---|---|---|---|
| Always | 同步写回 | 立马同步地将日志写回磁盘 | 性能较差,可靠性高基本不会丢失数据 |
| Everysec | 每秒写回 | 写到 AOF 文件的内存缓冲区,每隔一秒把缓冲区中的内容写入磁盘 | 性能适中,宕机丢失1秒内数据 |
| No | 自动写回 | 写到 AOF 文件的内存缓冲区,由操作系统决定何时将缓冲区内容写回磁盘 | 性能好,宕机丢失数据较多 |
3 重写机制
AOF 日志由主线程写回,重写过程是由后台线程 bgrewriteaof 来完成,避免了阻塞主线程。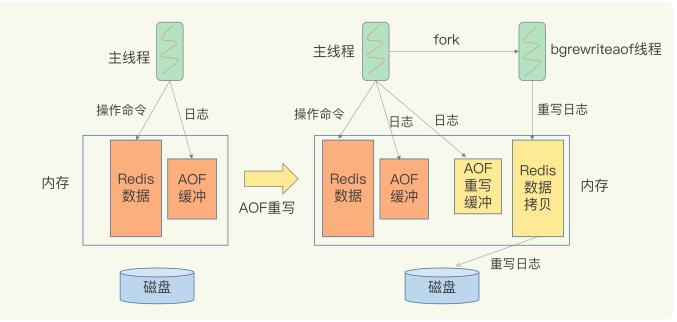
4 优缺点
优点:
- AOF可以更好的保护数据不丢失,一般AOF会每隔1秒,通过一个后台线程执行一次fsync操作,最多丢失1秒钟的数据。
缺点:
- 相对于数据文件来说,aof远远大于 rdb,修复的速度也比 rdb慢!
Aof 运行效率也要比 rdb 慢,所以我们redis默认的配置就是rdb持久化
2 RDB快照(Redis DataBase)
1 简介
RDB是Redis默认的持久化方式。按照一定的时间将内存的数据以快照的形式保存到硬盘中,对应产生的数据文件为dump.rdb。
Redis 提供了两个命令来生成 RDB 文件,分别是 save 和 bgsave。
手动触发:
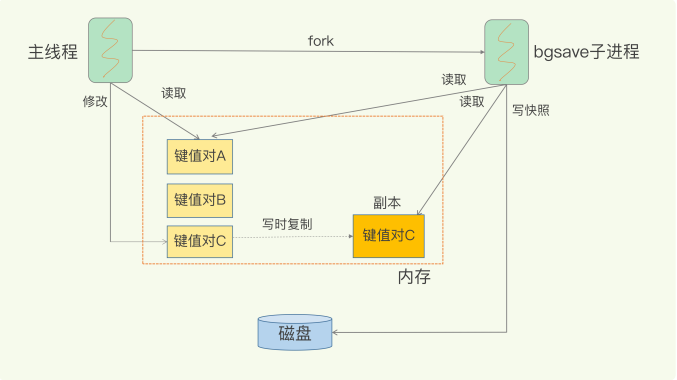
save-在主线程中执行,会导致阻塞;
bgsave-创建一个子进程,专门用于写入 RDB 文件,避免了主线程的阻塞,这也是Redis RDB 文件生成的默认配置。
自动触发:
redis.conf中配置save m n,即在m秒内有n次修改时,自动触发bgsave生成rdb文件;
主从复制时,从节点要从主节点进行全量复制时也会触发bgsave操作,生成当时的快照发送到从节点;
执行debug reload命令重新加载redis时也会触发bgsave操作;
默认情况下执行shutdown命令时,如果没有开启aof持久化,那么也会触发bgsave操作;2 写时复制技术
3 优缺点
优点:
RDB文件是某个时间节点的快照,默认使用LZF算法进行压缩,压缩后的文件体积远远小于内存大小,适用于备份、全量复制等场景;
- Redis加载RDB文件恢复数据要远远快于AOF方式;
缺点:
- RDB方式实时性不够,无法做到秒级的持久化;
- 每次调用bgsave都需要fork子进程,fork子进程属于重量级操作,频繁执行成本较高;
- RDB文件是二进制的,没有可读性,AOF文件在了解其结构的情况下可以手动修改或者补全;
-
6 高可用
1 主从复制
1 概念
主从复制,是指将一台Redis服务器的数据,复制到其他的Redis服务器。前者称为主节点,后者称为从节点;数据的复制是单向的,只能由主节点到从节点。
主要作用: 数据冗余:主从复制实现了数据的热备份,是持久化之外的一种数据冗余方式。
- 故障恢复:当主节点出现问题时,可以由从节点提供服务,实现快速的故障恢复;实际上是一种服务的冗余。
- 负载均衡:在主从复制的基础上,配合读写分离,可以由主节点提供写服务,由从节点提供读服务(即写Redis数据时应用连接主节点,读Redis数据时应用连接从节点),分担服务器负载;尤其是在写少读多的场景下,通过多个从节点分担读负载,可以大大提高Redis服务器的并发量。
- 高可用(集群)基石:除了上述作用以外,主从复制还是哨兵和集群能够实施的基础,因此说主从复制是Redis高可用的基础。
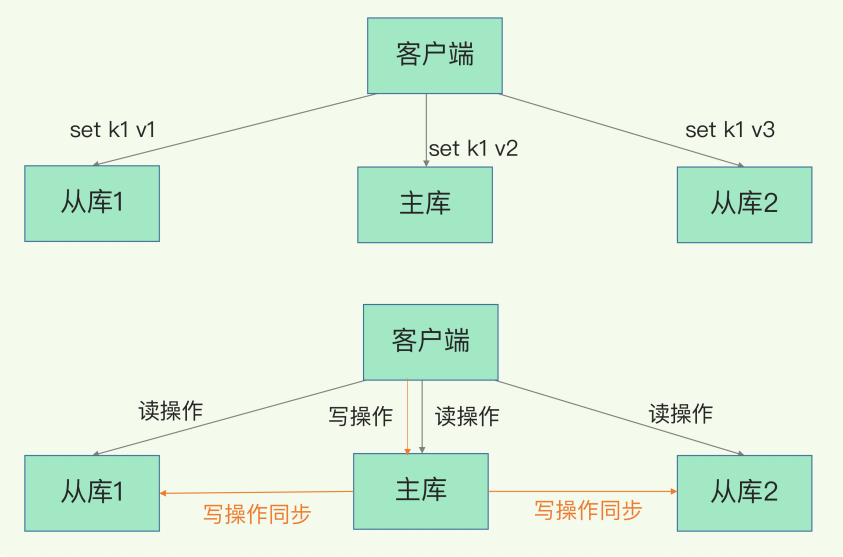
2 原理

- 第一阶段:从库和主库建立起连接,发送 psync 命令,主库收到命令返回 FULLRESYNC 响应
- 第二阶段:主库执行 bgsave 命令生成RDB 文件发送到从库,从库会先清空当前数据库,然后加载 RDB 文件。
- 第三阶段:主库会在内存中用专门的 replication buffer,记录 RDB 文件生成后收到的所有写操作,再发送给从库。
3 问题

4 脑裂
脑裂发生的原因主要是原主库发生了假故障
(1)和主库部署在同一台服务器上的其他程序临时占用了大量资源(例如 CPU 资源),导致 主库资源使用受限,短时间内无法响应心跳。其它程序不再使用资源时,主库又恢复正常
(2)主库自身遇到了阻塞的情况,短时间内无法响应心跳,等主库阻塞解除后,又恢复正常的请求处理了。
为了应对脑裂,可以在主从集群部署时,通过合理地配置参数 min-slaves-to-write 和 min-slaves-max-lag,来预防脑裂的发生。2 哨兵机制
1 概念
哨兵其实就是一个运行在特殊模式下的 Redis 进程,主从库实例运行的同时,它也在运 行。哨兵主要负责的就是三个任务:监控、选主和通知。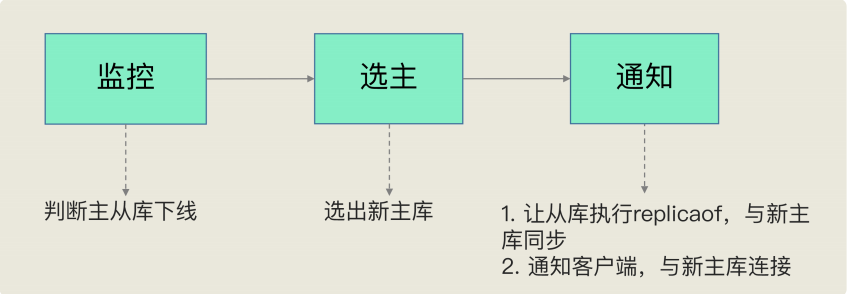
2 功能详解
(1)监控
哨兵进程会使用 PING 命令检测它自己和主、从库的网络连接情况,用来判断实例的状 态。
主观下线:某个哨兵认定下线
客观下线:集群中多数哨兵认定下线
(2)选主
跟据一定的筛选条件和打分规则选出主库
筛选:检查从库的当前在线状态,还要判断它之前的网络连接状态
打分:配置文件中优先级最高的从库得分高,和旧主库同步程度最接近的从库得分高,ID 号小的从库得分高
(3)通知
通知从库和客户端3 哨兵集群
基于 pub/sub 机制的哨兵集群组成,哨兵只要和主库建立起了连接,就可以在主库上发布消息了,比如说发布它自己的连接信 息(IP 和端口)。同时,它也可以从主库上订阅消息,获得其他哨兵发布的连接信息。当 多个哨兵实例都在主库上做了发布和订阅操作后,它们之间就能知道彼此的 IP 地址和端口。哨兵又通过 INFO 命令,获得 了从库连接信息,也能和从库建立连接,并进行监控了。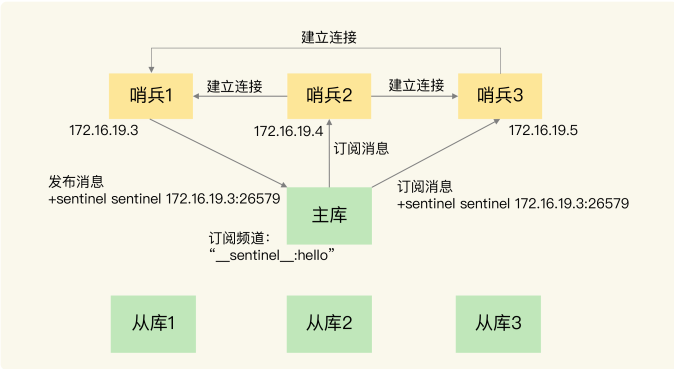
在进行主从切换的时候,集群经过投票选举-一个 Leader 出来,由它负责实际的主从切换,即由它来完成新主库的选择以及通知从库与客户端。7 高拓展
1 拓展
纵向扩展:升级单个 Redis 实例的资源配置,包括增加内存容量、增加磁盘容量、使用更高配置的 CPU。
横向扩展:横向增加当前 Redis 实例的个数。2 Redis Cluster
Redis Cluster 方案采用哈希槽(Hash Slot,接下来我会直接称之为 Slot), 来处理数据和实例之间的映射关系。在 Redis Cluster 方案中,一个切片集群共有 16384 个哈希槽,这些哈希槽类似于数据分区,每个键值对都会根据它的 key,被映射到一个哈希槽中。8 事务
Redis事务就是一次性、顺序性、排他性的执行一个队列中的一系列命令。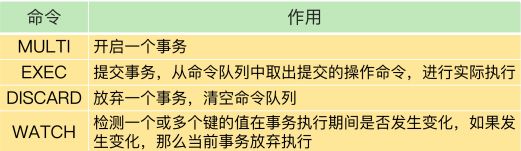
Redis 的事务机制可以保证一致性和隔离性,但是无法保证持久性。原子性的情况比较复杂,只有当事务中使用的命令语法有误时,原子性得不到保证,在其它情况下,事务都可以原子性执行。
9 调优
10 缓存异常
1 缓存和数据库的数据不一致
读写缓存
读写请求都在redis中进行,redis的数据是最新数据,会有数据丢失的风险。
写入数据库有两种策略,同步直写策略优先保证数据可靠性,而异步写回策略优先提供快速响应。
只读缓存
读请求在redis,写请求会直接发往后端的数据库,在数据库中增删改。但会出现缓存和数据库的数据不一致的问题。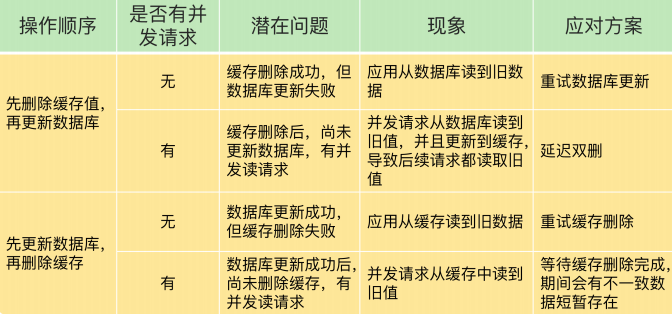
重试机制:通过消息队列来删除
延时双删:先删除缓存,在 更新完数据库值先 sleep 一小段时间,在进行删除
优先使用先更新数据库再删除缓存的方法
- 先删除缓存值再更新数据库,有可能导致请求因缓存缺失而访问数据库,给数据库带来压力;
- 如果业务应用中读取数据库和写缓存的时间不好估算,那么,延迟双删中的等待时间就不好设置。
2 缓存穿透(查不到)
| 原因 | 方案 | | —- | —- | | (1)业务层误操作:缓存中的数据和数据库中的数据被误删除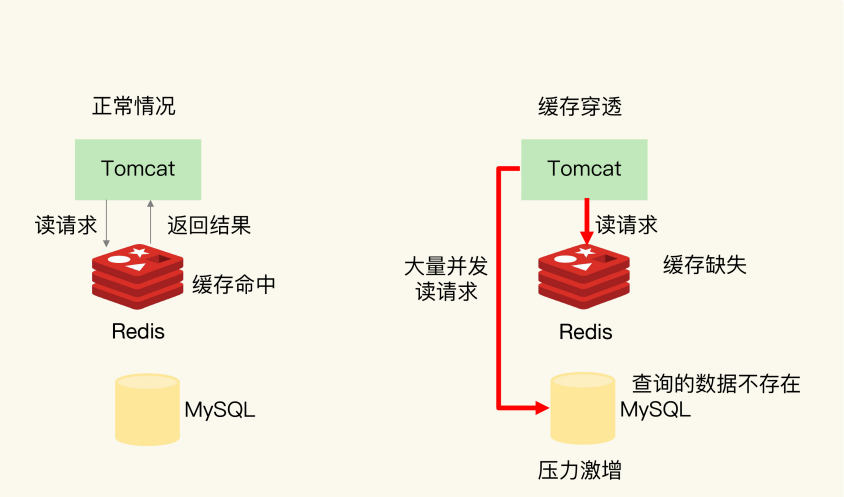
(2)恶意攻击:专门访问数据库中没有的数据 | (1)缓存空值或缺省值
(2)布隆过滤器
(3)接口请求合法性校验 |
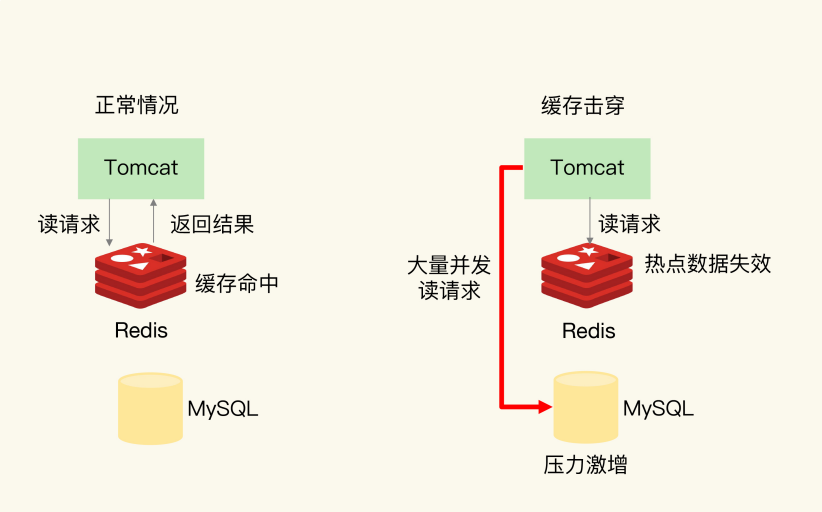
3 缓存击穿
| 原因 | 方案 |
|---|---|
| 热点数据缓存过期,所有请求直接访问数据库 | (1)设置热点数据永远不过期 |
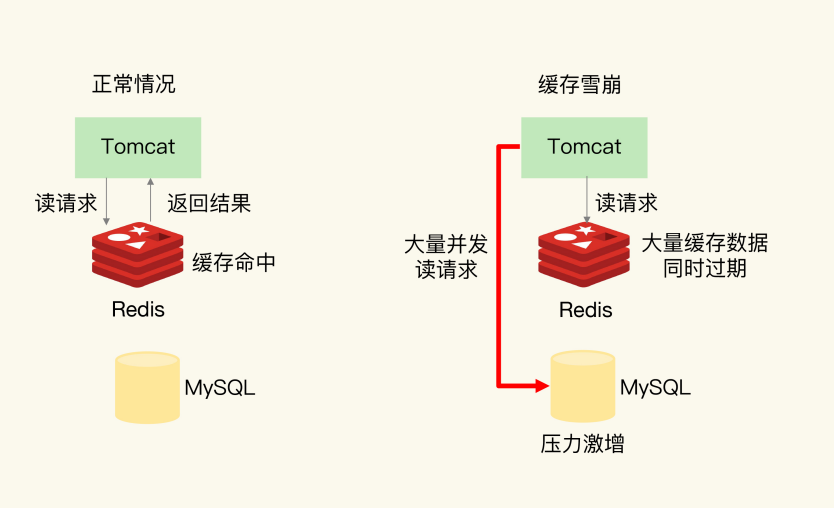
4 缓存雪崩
| 原因 | 方案 |
|---|---|
| 缓存中有大量数据同时过期,导致大量请求无法得到处理 | (1)避免给大量的数据设置相同的过期时间, 设置过期时间增加较小的随机数 (2)服务降级,非核心数据暂时停止从缓存中查询数据,直接返回预定义信息、空值或是错误信息 |
| Redis 实例宕机 | (1)请求限流机制或服务熔断机制,减少/暂停业务应用对缓存服务的访问 (2)搭建集群 |
5 缓存污染
缓存中一些只会被访问一次或者几次的的数据,被访问完后,再也不会被访问到,但这部分数据依然留存在缓存中,消耗缓存空间。共支持八种淘汰策略。
| 淘汰策略 | 方案 |
|---|---|
| noeviction | 不淘汰,v4.0后默认的 |
| volatile-ttl | 对设置了过期时间(所有)数据中按过期时间淘汰 |
| volatile(allkeys)-random | 对设置了过期时间(所有)数据中进行随机淘汰 |
| volatile(allkeys)-lru | 对设置了过期时间(所有)数据中,用lru算法淘汰,关注数据的时效性 |
| volatile(allkeys)-lfu | 对设置了过期时间(所有)数据中,用lfu算法淘汰,更加关注数据的访问频次 |
11 并发访问
1 原子操作
redis是单线程的,单个操作就可以原子性地执行,不过实际数据修改时可能包含多个操作,至少包括读数据、数据增减、写回数据三个操作。
简单操作: INCR/DECR 命令可以对数据进行增值 / 减值操作。
复杂操作:可以使用lua脚本
2 锁
1 基于单个 Redis 节点实现分布式锁
/*
* 加锁,
NX:只有在键值对不存在时,才会进行设置,否则不做赋值操作,
PX:过期时间,防止客户端没有进行解锁
unique_value作为客户端唯一性的标识,防止其他客户端误解锁操作
*/
SET lock_key unique_value NX PX 10000
//释放锁 比较unique_value是否相等,避免误释放
if redis.call("get",KEYS[1]) == ARGV[1] then return redis.call("del",KEYS[1]) elsereturn 0 end
redis-cli --eval unlock.script lock_key , unique_value
2 基于多个 Redis 节点实现高可靠的分布式锁
Redlock

若有收获,就点个赞吧
0 人点赞
